一、论文简述
1. 第一作者:Zhaoyang Huang、Xiaoyu Shi
2. 发表年份:2022
3. 发表期刊:ECCV
4. 关键词:光流、代价体、Transformer、GRU
5. 探索动机:现有的方法对代价体的信息利用有限。
6. 工作目标:是否可以结合transFormer和代价体的优势?
We therefore raise a question: can we enjoy both advantages of transformers and the cost volume from the previous milestones? Such a question calls for designing novel transformer architectures for optical flow estimation that can effectively aggregate information from the cost volume.
7. 核心思想:提出了FlowFormer。
- 提出了一种新颖的基于Transformer 的神经网络架构 FlowFormer,用于光流估计,它实现了最先进的流估计性能;
- 设计了一种新颖的代价体编码器,有效地将代价信息聚合成紧凑的潜在代价tokens;
- 提出了一种循环代价解码器,它通过动态位置代价查询反复解码代价特征,以迭代地改进估计的光流;
- 本文第一次验证了imagenet预训练的transformer有利于光流的估计。
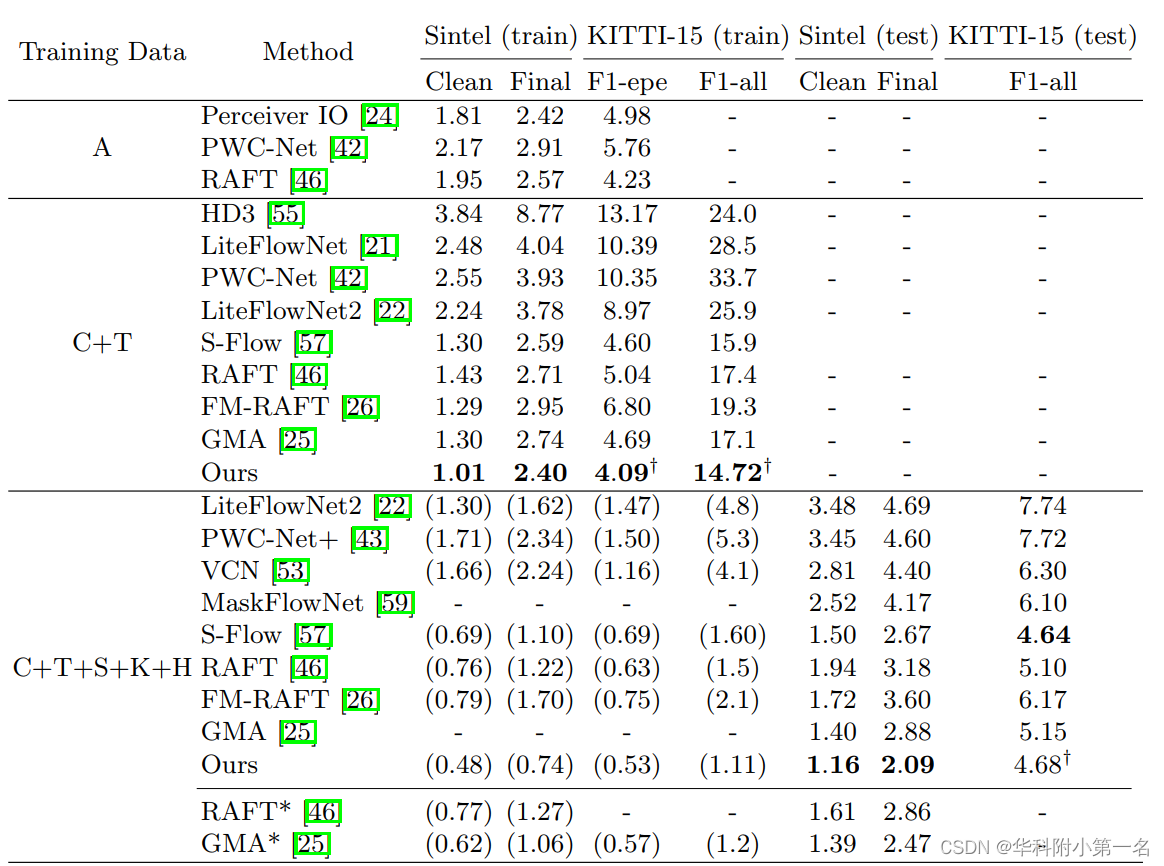
8. 实验结果:SOTA
On the Sintel benchmark, FlowFormer achieves 1.159 and 2.088 average end-point-error (AEPE) on the clean and final pass, a 16.5% and 15.5% error reduction from the best published result (1.388 and 2.47). Besides, FlowFormer also achieves strong generalization performance. Without being trained on Sintel, FlowFormer achieves 1.01 AEPE on the clean and pass of Sintel training set, outperforming the best published result (1.29) by 21.7%.
9.论文&代码下载:
https://arxiv.org/pdf/2203.16194.pdf
https://github.com/drinkingcoder/FlowFormer-Official
二、实现过程
1. 概述
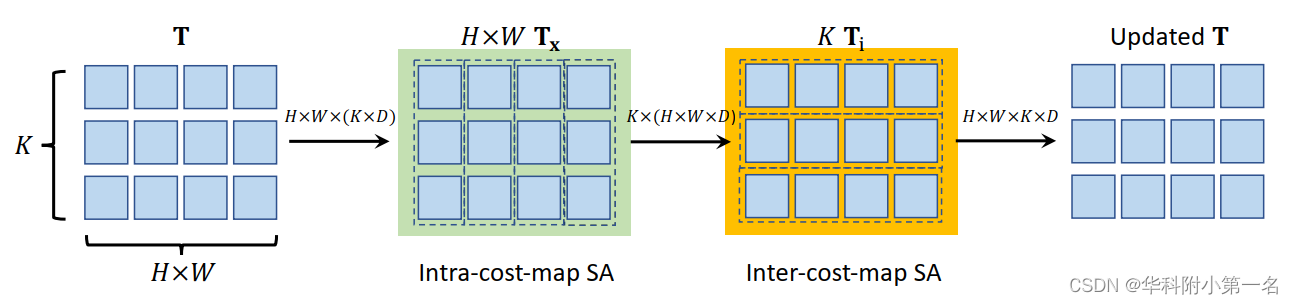
光流估计的任务是输出像素位移场f,将源图像Is的每个二维位置映射到目标图像It的对应二维位置p=x+f(x)。FlowFormer是基于transFormer的结构,对4D代价体进行编码和解码,以实现精确的光流估计。结构分为三个步骤,如下图:
- 通过siamese结构,得到图像特征,构建4D代价体;
- 代价体编码器,将4D代价体编码到潜在空间中以形成代价记忆;
- 循环transformer解码器,用基于编码的代价记忆和上下文特征预测像素位移场。

2. 构建4D代价体
主干网络从输入的HI×WI×3 RGB图像中提取H×W×Df特征图,其中通常设置(H, W) = (HI/8,WI/8)。提取源图像和目标图像的特征图后,计算源图像和目标图像所有像素对的点积相似性,构建4D代价体(H×W×H×W)。
3. 代价体编码器
为了估计光流,需要根据4D代价体中编码的源-目标视觉相似性来识别源像素在目标图像中的对应位置。构建的4D代价体可以被视为一系列大小为H×W的2D代价图,每个代价图都测量单个源像素和所有目标像素之间的视觉相似性。我们将源像素x的代价图表示为Mx∈H×W。在这样的代价图中找到相应的位置通常是具有挑战性的,因为两幅图像中可能存在重复模样和不可分辨的区域。当只考虑图的局部窗口的代价时,任务变得更具挑战性,就像之前基于CNN的光流估计方法一样。即使是估计单个源像素的精确位移,考虑其上下文的源像素的代价图也是有益的。
基于transFormer的代价体编码器,将整个代价体编码成代价记忆。代价体编码器由三个步骤组成:1)代价图分块,2)代价图像块Token嵌入,3)代价记忆编码。这三个步骤详述如下。
代价图分块。延续现有的视觉transformer,对每个源像素x的代价图Mx∈H×W进行跨步幅卷积,得到一系列的代价块嵌入。具体来说,给定一个H×W代价图,首先在其右侧和底部填充零,使其宽和高都是8的倍数。然后,通过三个步幅为2的卷积(加上ReLU),将填充的代价图转换为特征图Fx∈⌈H/8⌉×⌈W/8⌉×Dp。特征图中的每个特征表示输入代价图中的一个8×8的图像块。三个卷积的输出通道分别为Dp/4、Dp/2、Dp。
通过潜在归纳将图像块特征变为Token。尽管对每个源像素进行图像块化处理,得到了一系列代价块特征向量,但这种块特征的数量仍然很大,影响了信息在不同源像素之间的传播效率。实际上,代价图是非常冗余的,因为只有少数高代价是最具信息量的。为了获得更紧凑的代价特征,我们进一步通过K个潜在的编码字C∈K×D归纳了每个源像素x的图像块特征Fx。确切地说,潜码字通过点积注意力机制,查询每个源像素的代价块特征,进一步将每个代价图归纳为K个D维的潜在向量。潜码字C∈RK×D是随机初始化的,通过反向传播进行更新,并在所有源像素之间共享。归纳Fx的潜在表示Tx为

在投影代价块特征Fx以获得键Kx和值Vx之前,将块特征与位置嵌入序列连接PE∈⌈H/8⌉×⌈W/8⌉×Dp。给定一个2D位置p,将其编码为长度为Dp的位置嵌入。最后,通过有查询、键和值进行多头点积注意力,可以将源像素x的代价图归纳为K个潜在表示Tx∈K×D。一般来说,K×D≪H× W,因此,对于每个源像素x,潜在的总结图Tx比每个H×W代价图提供更紧凑的表示。对于图像中的所有源像素,总共有(H×W)个2D代价图,因此,转换为潜在的4D代价体T∈H×W×K×D。
潜在代价空间注意力。上述两个阶段将原始的4D代价体转化为潜在且紧凑的4D代价体T。但是,直接对4D体中的所有向量应用自注意力成本仍然过于高,因为计算代价会随着token数量的增加而成倍增加。如图2所示,提出了一个交替分组transformer层(AGT),以两种相互正交的方式对token进行分组并在两组中交替应用注意力,这降低了注意力的代价,同时仍然能够在所有token之间传播信息。
对每个源像素进行第一次分组,即每个Tx∈=K×D组成一个组,在组内进行自注意力。
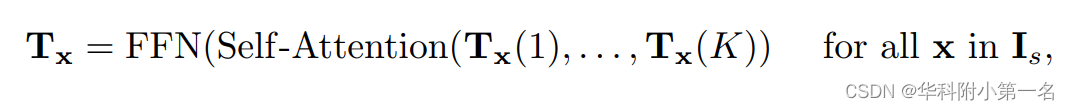
其中Tx(i)表示用于编码源像素x的代价图的第i个潜在表示。在每个源像素x的K个潜在token之间进行自注意力后,更新后的Tx通过前馈网络(FFN)进一步转换,然后重新组织,形成更新后的4D代价体T。自注意力和FFN子层均采用transFormer残差连接和层归一化的通用设计。这种自注意力操作在每个代价图中传播信息,将其命名为代价图内自注意力。
第二种方法根据K个不同的潜在表示,将所有的潜在代价tokenT∈H×W ×K×D分成K组。因此,每个组都有D维的(H×W)token,用于通过Twins中提出的空间可分离的自注意力(SS-SelfAttention)在空间域中传播信息。

这里稍微滥用了符号,将Ti∈(H×W)×D表示为第i组。然后将更新后的Ti重新组织,得到更新后的4D潜在代价体T。此外,视觉上相似的源像素应该具有一致的光流。因此,在生成查询和键时,通过连接源图像的上下文特征t与代价token,将不同源像素之间的外观相似性集成到SS-SelfAttention中。此层称为代价映射间自注意力层,因为它在不同的源像素之间传播代价体信息。
上述自注意力操作的参数在不同的组间共享,并按顺序进行,形成交替组注意力层。通过多次堆叠交替组transFormer层,潜在代价token可以有效地跨源像素和跨潜在表示交换信息,以更好地编码4D代价体。代价体编码器将H×W×H×W 4D代价体转换为H×W×K个长度为D的潜在token。将最终得到的H×W×K个token作为代价记忆,对其进行解码,用于光流估计。
4. 光流估计的代价记忆解码器
与以往寻找抽象语义特征的视觉transFormer不同,光流估计需要从代价记忆中恢复稠密的对应关系。受RAFT的启发,提出使用代价查询从代价记忆中检索代价特征,并使用循环注意力解码器层改进光流预测。
代价记忆聚合。为了预测H×W源像素的光流,生成了一个(H×W)代价查询序列,每个代价查询都负责通过代价记忆的共同注意力来估计单个源像素的光流。为了生成源像素x的代价查询Qx,首先计算其在目标图像中的对应位置,给定其当前估计流f(x),即p= x+f(x)。然后,通过在代价图Mx上以p为中心的9×9局部窗口内裁剪代价,检索一个局部9×9代价图块qx=Crop9×9(Mx, p)。然后根据局部代价Qx编码的特征FFN(Qx)和p的位置嵌入PE(p)来制定代价查询Qx, 通过交叉注意力可以聚合源像素x的代价记忆Tx的信息,
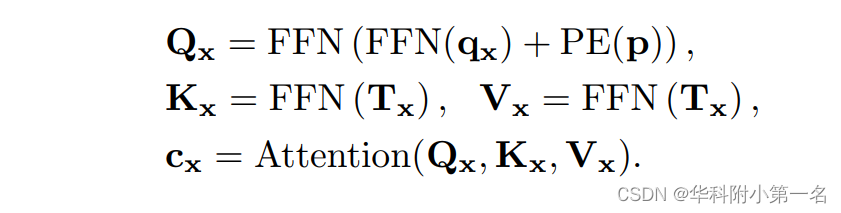
交叉注意力从代价记忆中归纳每个源像素的信息,以预测其光流。由于Qx在每次迭代中都是动态更新的,因此称之为动态位置代价查询。键和值可以在开始时生成,并在后续迭代中重复使用,这是循环解码器的一个好处,可以节省计算。
循环光流预测。代价解码器迭代回归光流残差∆f(x),将每个源像素x的光流改进为f(x)←f(x) +∆f(x)。采用了ConvGRU模块,并采用了与GMA-RAFT相似的设计进行光流改进。但是,循环模块的关键区别在于使用代价查询自适应地聚合来自代价记忆的信息,更准确的光流估计。具体而言,在每次迭代中,ConvGRU单元将检索到的代价特征和代价图的块的连接Concat(cx, qx)、上下文网络的源图像上下文特征tx和当前估计光流f的连接作为输入,并输出预测的光流残差如下:

每次迭代生成的光流通过凸上采样器上采样到源图像的大小,并在循环迭代中伴随增加权重由真实光流监督。
5. 实验
5.1. 数据集
Sintel,the KITTI-2015,FlyingChairs,FlyingThings and HD1K
5.2. 实现
FlowFormer的图像特征编码器是imagenet预训练的Twins-SVT的前两个阶段,将图像编码为源图像大小1/8的通道Df为256的特征图。代价体编码器将每个代价图分块为Dp=64通道的特征图,并进一步将特征图归纳为K=128维的N=8个代价token。然后,代价体编码器用3层AGT编码代token。
5.3. 基准结果:SOTA
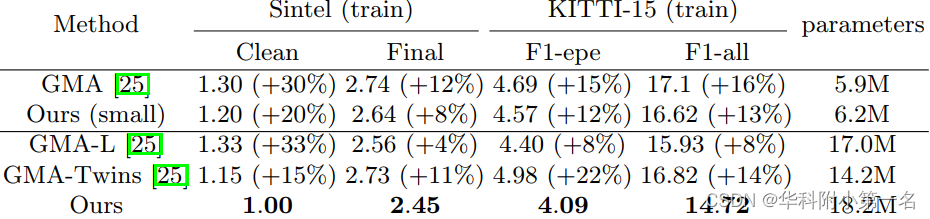
5.4. 参数量