一、引入
通用版能解决百分之八九十的任务,剩下的部分任务需要进行定制。
先说明通用版本和定制版本有什么不同,通用版本就是只管大的数据类型,将数据处理为对应的类型入库,而定制版本会考虑局部列的数据类型,。举个简单的例子,比如说飞书编号为 2 的数据类型,它实际上包含了整数和小数,在通用版本,会把它处理为 double 或 float 类型以便保留小数的精度,但是定制版本可能会把整数列单独处理,入库为 int 数据类型类型。
二、常见场景及处理方法
针对定制列,本文提供的处理思想是在原有的基础上叠加一层处理,具体来讲,就是新增一个函数,将extract_key_fields()和generate_create_ddl()这两个函数分别返回的值df_return和cre_ddl作为参数传递给新的函数,然后在新函数中对需要定制的列进行处理,并将处理结果返回。
下面列举 4 个常用的场景来做演示。
- 场景一:把数字列入库为 int 类型
- 场景二:把日期列入库为 date 类型
- 场景三:日期列给定默认最大值
- 场景四:公式列保留具体值
2.1 场景一:把数字列入库为 int 类型
需求:将数字列(field_number)入库为 int 类型
前面在extract_key_fields()中已经对数字列的值提取出来,只不过统一存为 float 数据类型,这里只是将入库数据类型进行修改,所以修改建表的 DDL 即可。
根据前面generate_create_ddl()函数生成建表语句的规则,直接识别field_number float,然后替换为field_number int即可,参考代码如下:
def custom_field(df_return, cre_ddl):
# 2.1 场景一:把数字列入库为 int 类型
# 修改 SQL 即可
cre_ddl = cre_ddl.replace('field_number float','field_number int')
print('定制函数打印数据和建表语句')
print('----------------------------------------------\n', df_return[['field_number']].head(5))
print('----------------------------------------------\n', cre_ddl)
return df_return, cre_ddl
2.2 场景二:把日期列入库为 date 类型
需求:将创建时间列(field_createdtime)入库为 date 类型。
这个需求也是直接修改 SQL 即可,虽然创建时间列带有时间,入库的时候会被截掉。当然想将时间截掉再入库也可以。参考代码如下:
def custom_field(df_return, cre_ddl):
# 2.2 场景二:把日期列入库为 date 类型
# 修改 df,使用 datetime 试试行不行,不行再使用 date,随便一个 datetime 是否直接截断?
# 修改 SQL
cre_ddl = cre_ddl.replace('field_createdtime datetime','field_createdtime date')
print('定制函数打印数据和建表语句')
print('----------------------------------------------\n', df_return[['field_number','field_createdtime','field_date','field_numformula']].head(5))
print('----------------------------------------------\n', cre_ddl)
return df_return, cre_ddl
2.3 场景三:日期列给定默认最大值
需求:将日期列(field_date)为空的值替换为“2222-01-01 00:00:00”。
这个需求的处理方式跟前面反过来,入库数据类型不变,只处理 pandas 的 DataFrame 列即可。因为在extract_key_fields()中已经对日期列的空值做了填充,所以此处需要通过掩码识别填充值,然后再对填充值进行替换。参考代码如下:
def custom_field(df_return, cre_ddl):
# 2.3 场景三:日期列给定默认最大值
# 修改 df 即可
#默认值改为 2222-01-01 00:00:00
mask = df_return['field_date'] == pd.Timestamp('1970-01-01 08:00:01')
df_return.loc[mask, 'field_date'] = pd.Timestamp('2222-01-01 00:00:00')
print('定制函数打印数据和建表语句')
print('----------------------------------------------\n', df_return[['field_number','field_createdtime','field_date','field_numformula']].head(5))
print('----------------------------------------------\n', cre_ddl)
return df_return, cre_ddl
2.4 场景四:公式列保留具体值
需求:将公式列(field_numformula)的数字提取出来,入库为 int 类型。
该需求相对复杂一些,需要处理 DataFrame 列和修改建表语句。在提取公式列的数据时,有一个关键的步骤就是将列值从 json 类型转回字典和列表嵌套的结构,使用json.loads()来实现。转换之后,再根据返回值的结构,将“value”取出再取第 0 个索引。修改建表语句则和前面 2.1 和 2.2 类似,参考代码如下:
def custom_field(df_return, cre_ddl):
# 2.4 场景四:公式列保留具体值
# 修改 df
# 修改 SQL
df_return['field_numformula'] = df_return['field_numformula'].apply(lambda x:json.loads(x)['value'][0])
cre_ddl = cre_ddl.replace('field_numformula varchar(256)','field_numformula int')
print('定制函数打印数据和建表语句')
print('----------------------------------------------\n', df_return[['field_number','field_createdtime','field_date','field_numformula']].head(5))
print('----------------------------------------------\n', cre_ddl)
return df_return, cre_ddl
注意:公式列返回值如果是数字,定制化入库为 int 类型时,要注意公式正确,把可能导致公式出错的情况先处理掉,避免出来公式错误导致入库失败。举个例子:0 不能作为除数,所以在写数字公式时,先判断除数列是不是 0,为 0 的时候给一个正常的返回值,比如 0,而不是 0 的之后才正常相除。
三、最终效果展示
将四种场景的代码进行整合,看看最终效果是什么样。
整合代码:
def custom_field(df_return, cre_ddl):
# 2.1 场景一:把数字入库为 int 类型
# 修改 SQL 即可
cre_ddl = cre_ddl.replace('field_number float','field_number int')
# 2.2 场景二:把日期入库为 date 类型
# 修改 df,使用 datetime 试试行不行,不行再使用 date,随便一个 datetime 是否直接截断?
# 修改 SQL
cre_ddl = cre_ddl.replace('field_createdtime datetime','field_createdtime date')
# 2.3 场景三:日期给定默认最大值
# 修改 df 即可
#默认值(未离组)改为 2222-01-01 00:00:00
mask = df_return['field_date'] == pd.Timestamp('1970-01-01 08:00:01')
df_return.loc[mask, 'field_date'] = pd.Timestamp('2222-01-01 00:00:00')
# 2.4 场景四:公式保留具体值
# 修改 df
# 修改 SQL
df_return['field_numformula'] = df_return['field_numformula'].apply(lambda x:json.loads(x)['value'][0])
cre_ddl = cre_ddl.replace('field_numformula varchar(256)','field_numformula int')
print('定制函数打印数据和建表语句')
print('----------------------------------------------\n', df_return[['field_number','field_createdtime','field_date','field_numformula']].head(5))
print('----------------------------------------------\n', cre_ddl)
return df_return, cre_ddl
然后将上面代码放入上小结最终的代码中,放置方法如下: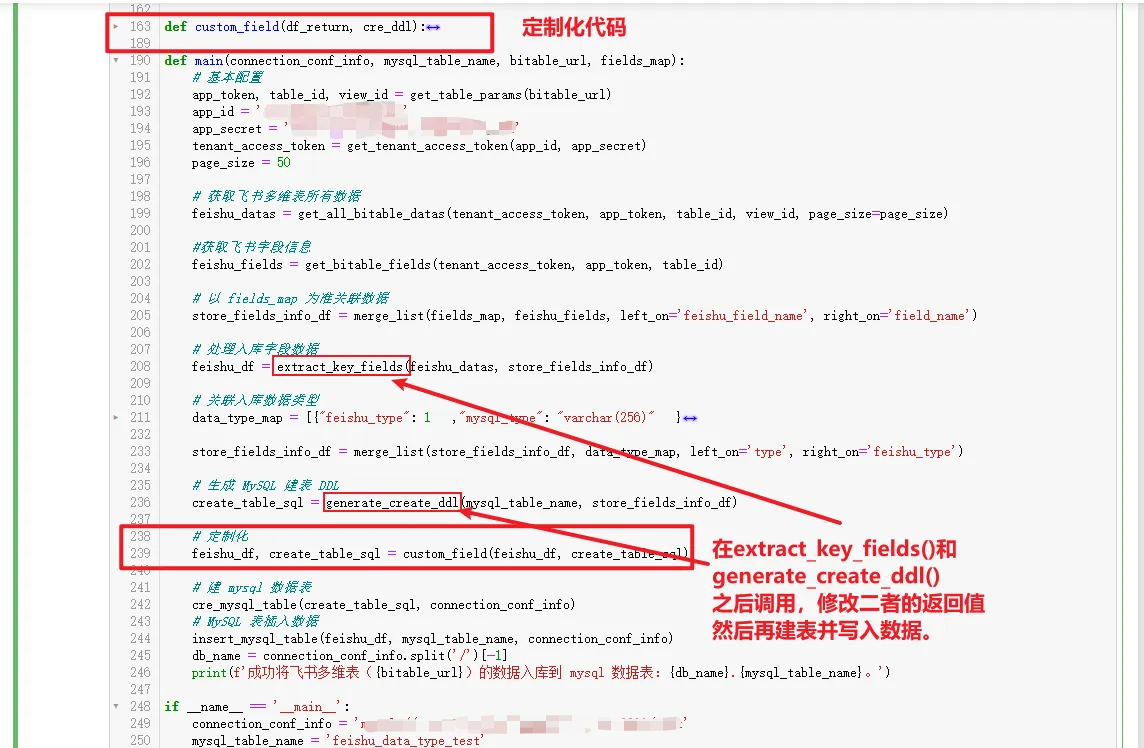
最终代码执行结果如下: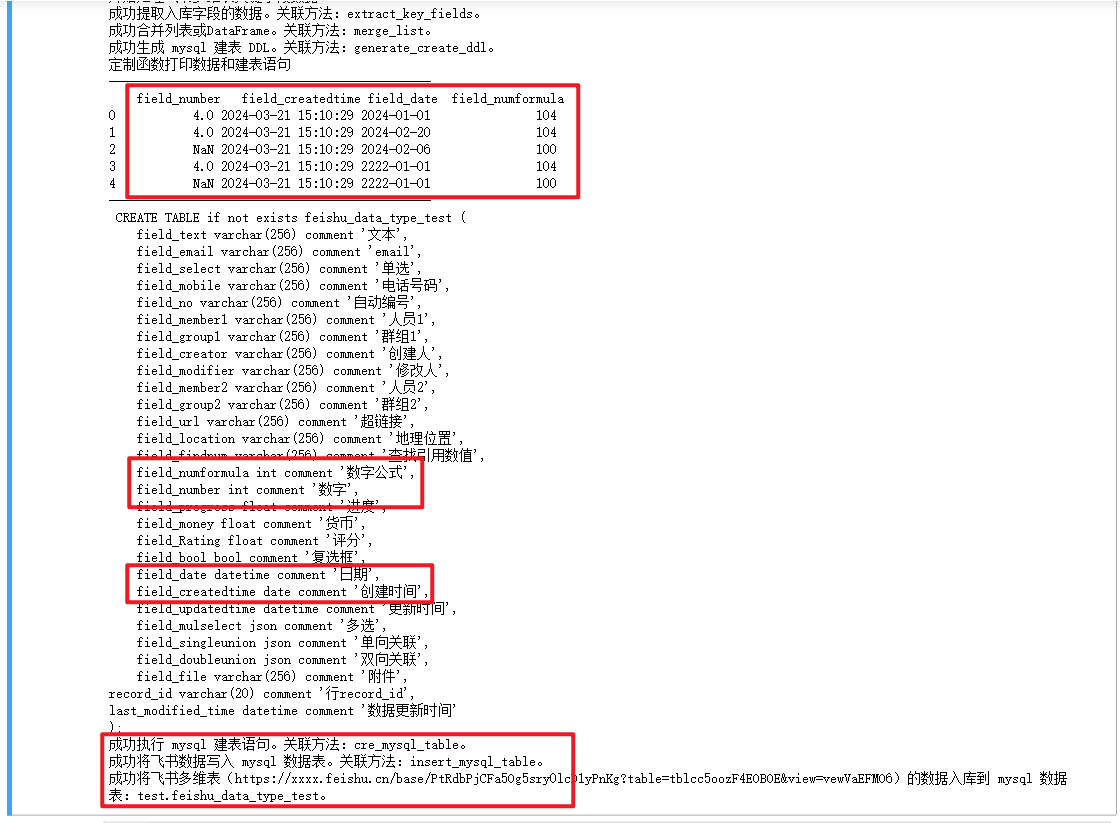
登录 MySQL 再查查入库的数据的数据类型(如下),结果符合预期。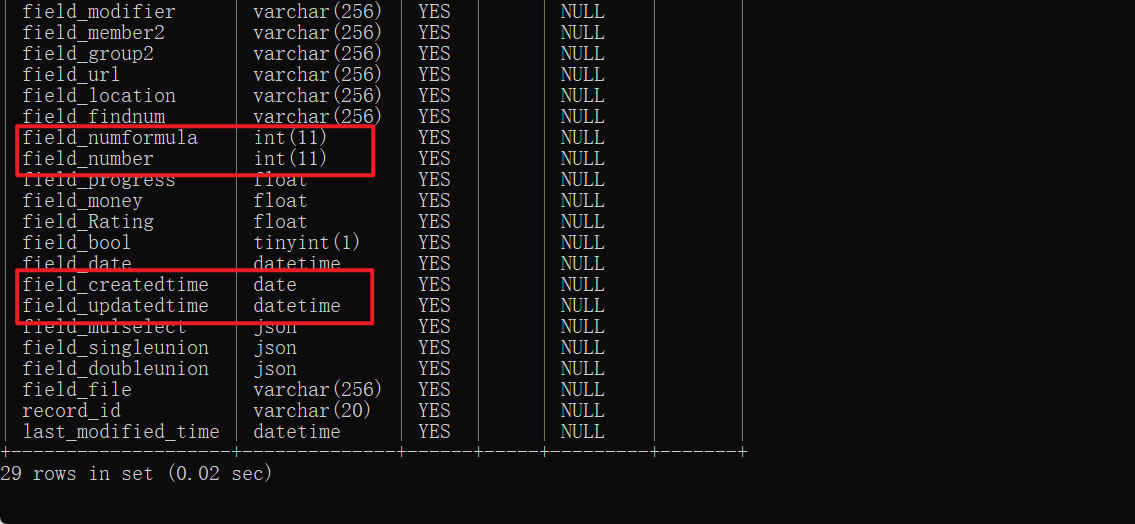
再看看入库的数据(如下),也符合定制化需求。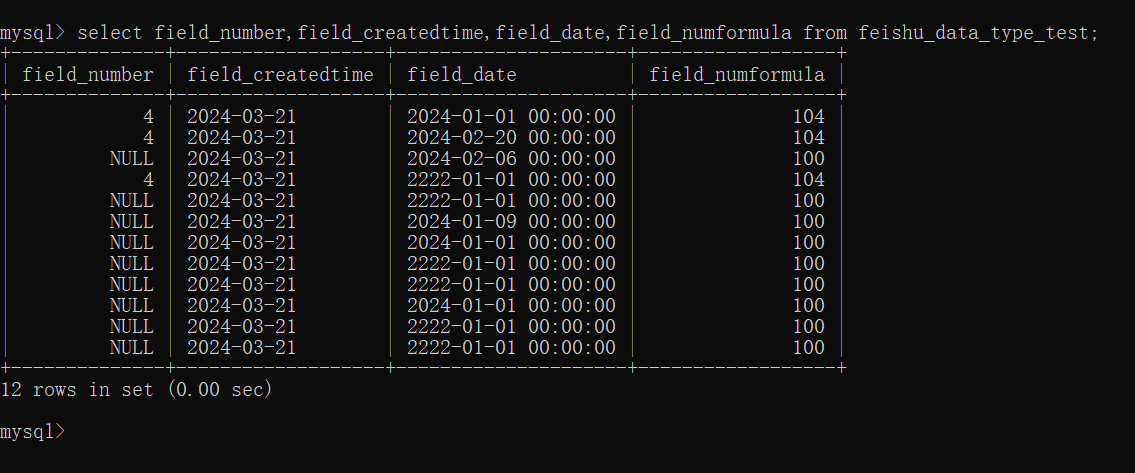
最终完整代码如下:
import requests
import json
import datetime
import pandas as pd
from sqlalchemy import create_engine, text
from urllib.parse import urlparse, parse_qs
def get_table_params(bitable_url):
# bitable_url = "https://feishu.cn/base/aaaaaaaa?table=tblccc&view=vewddd"
parsed_url = urlparse(bitable_url) #解析url:(ParseResult(scheme='https', netloc='feishu.cn', path='/base/aaaaaaaa', params='', query='table=tblccc&view=vewddd', fragment='')
query_params = parse_qs(parsed_url.query) #解析url参数:{'table': ['tblccc'], 'view': ['vewddd']}
app_token = parsed_url.path.split('/')[-1]
table_id = query_params.get('table', [None])[0]
view_id = query_params.get('view', [None])[0]
print(f'成功解析链接,app_token:{app_token},table_id:{table_id},view_id:{view_id}。关联方法:get_table_params。')
return app_token, table_id, view_id
def get_tenant_access_token(app_id, app_secret):
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
payload = json.dumps({
"app_id": app_id,
"app_secret": app_secret
})
headers = {'Content-Type': 'application/json'}
response = requests.request("POST", url, headers=headers, data=payload)
tenant_access_token = response.json()['tenant_access_token']
print(f'成功获取tenant_access_token:{tenant_access_token}。关联函数:get_table_params。')
return tenant_access_token
def get_bitable_datas(tenant_access_token, app_token, table_id, view_id, page_token='', page_size=20):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search?page_size={page_size}&page_token={page_token}&user_id_type=user_id"
payload = json.dumps({"view_id": view_id})
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(f'成功获取page_token为【{page_token}】的数据。关联函数:get_bitable_datas。')
return response.json()
def get_all_bitable_datas(tenant_access_token, app_token, table_id, view_id, page_token='', page_size=20):
has_more = True
feishu_datas = []
while has_more:
response = get_bitable_datas(tenant_access_token, app_token, table_id, view_id, page_token, page_size)
if response['code'] == 0:
page_token = response['data'].get('page_token')
has_more = response['data'].get('has_more')
# print(response['data'].get('items'))
# print('\n--------------------------------------------------------------------\n')
feishu_datas.extend(response['data'].get('items'))
else:
raise Exception(response['msg'])
print(f'成功获取飞书多维表所有数据,返回 feishu_datas。关联函数:get_all_bitable_datas。')
return feishu_datas
def get_bitable_fields(tenant_access_token, app_token, table_id, page_size=500):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/fields?page_size={page_size}"
payload = ''
headers = {'Authorization': f'Bearer {tenant_access_token}'}
response = requests.request("GET", url, headers=headers, data=payload)
field_infos = response.json().get('data').get('items')
print('成功获取飞书字段信息,关联函数:get_bitable_fields。')
return field_infos
def merge_list(ls_from, ls_join, on=None, left_on=None, right_on=None):
"""将两个[{},{}]结构的数据合并"""
df_from = pd.DataFrame(ls_from)
df_join = pd.DataFrame(ls_join)
if on is not None:
df_merge = df_from.merge(df_join, how='left', on=on)
else:
df_merge = df_from.merge(df_join, how='left', left_on=left_on, right_on=right_on) # , suffixes=('', '_y')
print(f'成功合并列表或DataFrame。关联方法:merge_list。')
return df_merge
def extract_key_fields(feishu_datas, store_fields_info_df):
"""处理飞书数据类型编号的数据"""
print('开始处理飞书多维表关键字段数据...')
# 需要record_id 和 订单号,用于和数据库数据匹配
df_feishu = pd.DataFrame(feishu_datas)
df_return = pd.DataFrame()
#根据列的数据类型,分别处理对应的数据。注意:仅返回以下列举的数据类型,如果fields_map的内容包含按钮、流程等数据类型的飞书列,忽略。
for index, row in store_fields_info_df.iterrows():
if row['type'] == 1: #文本
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name'],[{}])[0].get('text'))
elif row['type'] in (2, 3, 7, 13, 1005): #数字、单选、复选框、手机号、自动编号
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name']))
elif row['type'] in (5, 1001, 1002): #日期(包含创建和更新),需要加 8 小时,即 8*60*60*1000=28800 秒
df_return[row['tb_field_name']] = pd.to_datetime(df_feishu['fields'].apply(lambda x:28800 + int(x.get(row['field_name'],1000)/1000)), unit='s')
elif row['type'] in(11, 23, 1003, 1004): #人员、群组、创建人、修改人,遍历取name
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x: ','.join([i.get('name') for i in x.get(row['field_name'],[{"name":""}])])) # 需要遍历
elif row['type'] == 15: #链接
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name'],{}).get('link'))
elif row['type'] == 17: #附件,遍历取url
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:json.dumps([i.get('url') for i in x.get(row['field_name'],[{}])])) #需要遍历
elif row['type'] in(18, 21): #单向关联、双向关联,取link_record_ids
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:json.dumps(x.get(row['field_name'],{}).get('link_record_ids')))
elif row['type'] in(4, 19, 20): #多选、查找引用和公式
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:json.dumps(x.get(row['field_name'])))
elif row['type'] == 22: #地理位置
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name'],{}).get('location'))
#加上record_id
df_return['record_id'] = df_feishu.record_id
#加上表更新字段
df_return['last_modified_time'] = datetime.datetime.now()
print(f'成功提取入库字段的数据。关联方法:extract_key_fields。')
return df_return
def generate_create_ddl(db_table_name, store_fields_info_df):
""""""
# 代码一:生成DDL语句
cre_ddl = f"CREATE TABLE if not exists {db_table_name} (\n"
for index, row in store_fields_info_df.iterrows():
cre_ddl += f" {row['tb_field_name']} {row['mysql_type']} comment '{row['feishu_field_name']}',\n"
default_fields = "record_id varchar(20) comment '行record_id',\nlast_modified_time datetime comment '数据更新时间' \n);"
# cre_ddl = cre_ddl[:-2] + "\n);"
cre_ddl = cre_ddl + default_fields
print(f'成功生成 mysql 建表 DDL。关联方法:generate_create_ddl。')
return cre_ddl
def cre_mysql_table(create_table_sql, connection_conf_info):
"""注意:该函数支持执行任意SQL,而不仅仅是建表 SQL。"""
# from sqlalchemy import create_engine, text
# 创建 SQLAlchemy engine 对象,这里以 MySQL 为例
# engine = create_engine('mysql://username:password@host:port/dbname')
# engine = create_engine('mysql://root:password@127.0.0.1:3306/test')
engine = create_engine(connection_conf_info)
# 定义一个建表的 SQL 语句
# create_table_sql = ''''''
# 使用 execute() 方法执行 SQL 语句
with engine.connect() as connection:
connection.execute(text(create_table_sql))
print(f'成功执行 mysql 建表语句。关联方法:cre_mysql_table。')
def insert_mysql_table(feishu_df, table_name, connection_conf_info):
# from sqlalchemy import create_engine
# 创建 SQLAlchemy engine 对象,这里以 MySQL 为例
# engine = create_engine('mysql://username:password@host:port/dbname')
# engine = create_engine('mysql://root:password@127.0.0.1:3306/test')
engine = create_engine(connection_conf_info)
# 将 DataFrame 直接写入 MySQL 数据库
feishu_df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
print(f'成功将飞书数据写入 mysql 数据表。关联方法:insert_mysql_table。')
def custom_field(df_return, cre_ddl):
# 2.1 场景一:把数字入库为 int 类型
# 修改 SQL 即可
cre_ddl = cre_ddl.replace('field_number float','field_number int')
# 2.2 场景二:把日期入库为 date 类型
# 修改 df,使用 datetime 试试行不行,不行再使用 date,随便一个 datetime 是否直接截断?
# 修改 SQL
cre_ddl = cre_ddl.replace('field_createdtime datetime','field_createdtime date')
# 2.3 场景三:日期给定默认最大值
# 修改 df 即可
#默认值(未离组)改为 2222-01-01 00:00:00
mask = df_return['field_date'] == pd.Timestamp('1970-01-01 08:00:01')
df_return.loc[mask, 'field_date'] = pd.Timestamp('2222-01-01 00:00:00')
# 2.4 场景四:公式保留具体值
# 修改 df
# 修改 SQL
df_return['field_numformula'] = df_return['field_numformula'].apply(lambda x:json.loads(x)['value'][0])
cre_ddl = cre_ddl.replace('field_numformula varchar(256)','field_numformula int')
print('定制函数打印数据和建表语句')
print('----------------------------------------------\n', df_return[['field_number','field_createdtime','field_date','field_numformula']].head(5))
print('----------------------------------------------\n', cre_ddl)
return df_return, cre_ddl
def main(connection_conf_info, mysql_table_name, bitable_url, fields_map):
# 基本配置
app_token, table_id, view_id = get_table_params(bitable_url)
app_id = 'your_app_id'
app_secret = 'your_app_secret'
tenant_access_token = get_tenant_access_token(app_id, app_secret)
page_size = 50
# 获取飞书多维表所有数据
feishu_datas = get_all_bitable_datas(tenant_access_token, app_token, table_id, view_id, page_size=page_size)
#获取飞书字段信息
feishu_fields = get_bitable_fields(tenant_access_token, app_token, table_id)
# 以 fields_map 为准关联数据
store_fields_info_df = merge_list(fields_map, feishu_fields, left_on='feishu_field_name', right_on='field_name')
# 处理入库字段数据
feishu_df = extract_key_fields(feishu_datas, store_fields_info_df)
# 关联入库数据类型
data_type_map = [{"feishu_type": 1 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 2 ,"mysql_type": "float" }
,{"feishu_type": 3 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 4 ,"mysql_type": "json" }
,{"feishu_type": 5 ,"mysql_type": "datetime" }
,{"feishu_type": 7 ,"mysql_type": "bool" }
,{"feishu_type": 11 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 13 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 15 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 17 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 18 ,"mysql_type": "json" }
,{"feishu_type": 19 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 20 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 21 ,"mysql_type": "json" }
,{"feishu_type": 22 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 23 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 1001,"mysql_type": "datetime" }
,{"feishu_type": 1002,"mysql_type": "datetime" }
,{"feishu_type": 1003,"mysql_type": "varchar(256)" }
,{"feishu_type": 1004,"mysql_type": "varchar(256)" }
,{"feishu_type": 1005,"mysql_type": "varchar(256)" }]
store_fields_info_df = merge_list(store_fields_info_df, data_type_map, left_on='type', right_on='feishu_type')
# 生成 MySQL 建表 DDL
create_table_sql = generate_create_ddl(mysql_table_name, store_fields_info_df)
# 定制化
feishu_df, create_table_sql = custom_field(feishu_df, create_table_sql)
# 建 mysql 数据表
cre_mysql_table(create_table_sql, connection_conf_info)
# MySQL 表插入数据
insert_mysql_table(feishu_df, mysql_table_name, connection_conf_info)
db_name = connection_conf_info.split('/')[-1]
print(f'成功将飞书多维表({bitable_url})的数据入库到 mysql 数据表:{db_name}.{mysql_table_name}。')
if __name__ == '__main__':
connection_conf_info = 'mysql://root:password@127.0.0.1:3306/test'
mysql_table_name = 'feishu_data_type_test'
bitable_url = "https://xxxx.feishu.cn/base/PtRdbPjCFa5Og5sry0lcD1yPnKg?table=tblcc5oozF4EOBOE&view=vewVaEFMO6"
fields_map = [{'tb_field_name': 'field_text','feishu_field_name': '文本'}
,{'tb_field_name': 'field_email','feishu_field_name': 'email'}
,{'tb_field_name': 'field_select','feishu_field_name': '单选'}
,{'tb_field_name': 'field_mobile','feishu_field_name': '电话号码'}
,{'tb_field_name': 'field_no','feishu_field_name': '自动编号'}
,{'tb_field_name': 'field_member1','feishu_field_name': '人员1'}
,{'tb_field_name': 'field_group1','feishu_field_name': '群组1'}
,{'tb_field_name': 'field_creator','feishu_field_name': '创建人'}
,{'tb_field_name': 'field_modifier','feishu_field_name': '修改人'}
,{'tb_field_name': 'field_member2','feishu_field_name': '人员2'}
,{'tb_field_name': 'field_group2','feishu_field_name': '群组2'}
,{'tb_field_name': 'field_url','feishu_field_name': '超链接'}
,{'tb_field_name': 'field_location','feishu_field_name': '地理位置'}
,{'tb_field_name': 'field_findnum','feishu_field_name': '查找引用数值'}
,{'tb_field_name': 'field_numformula','feishu_field_name': '数字公式'}
,{'tb_field_name': 'field_number','feishu_field_name': '数字'}
,{'tb_field_name': 'field_progress','feishu_field_name': '进度'}
,{'tb_field_name': 'field_money','feishu_field_name': '货币'}
,{'tb_field_name': 'field_Rating','feishu_field_name': '评分'}
,{'tb_field_name': 'field_bool','feishu_field_name': '复选框'}
,{'tb_field_name': 'field_date','feishu_field_name': '日期'}
,{'tb_field_name': 'field_createdtime','feishu_field_name': '创建时间'}
,{'tb_field_name': 'field_updatedtime','feishu_field_name': '更新时间'}
,{'tb_field_name': 'field_mulselect','feishu_field_name': '多选'}
,{'tb_field_name': 'field_singleunion','feishu_field_name': '单向关联'}
,{'tb_field_name': 'field_doubleunion','feishu_field_name': '双向关联'}
,{'tb_field_name': 'field_file','feishu_field_name': '附件'}
]
main(connection_conf_info, mysql_table_name, bitable_url, fields_map)
四、小结
本文介绍了如何对上一小节的通用版本的代码进行定制化修改列的值和数据类型。
基本思想就是不动原来的结构,直接叠加一层(新增一个函数)来处理,通过一个函数对数据列的不同需求进行定制化修改。
四种常用的场景的处理方式小结如下:
| 场景 | 处理方式 |
|---|---|
| 场景一:把数字列入库为 int 类型 | 修改 DDL:指定列的 float 类型改为 int 类型 |
| 场景二:把日期列入库为 date 类型 | 修改 DDL:指定列的 datetime 类型改为 date 类型 |
| 场景三:日期列给定默认最大值 | 修改 DataFrame,将默认值改为指定值 |
| 场景四:公式列保留具体值 | 修改 DataFrame,取出公式返回的具体值 修改 DDL:指定列的 string 类型改为 int 类型(根据需求修改,如果返回的时文本类型,可以不用修改,如果是时间类型,可改为 datetime 类型) |




![[OpenGL高级光照] 阴影改善](https://img-blog.csdnimg.cn/direct/d3a9559607394c1f85c1c1ccb771c95b.png)