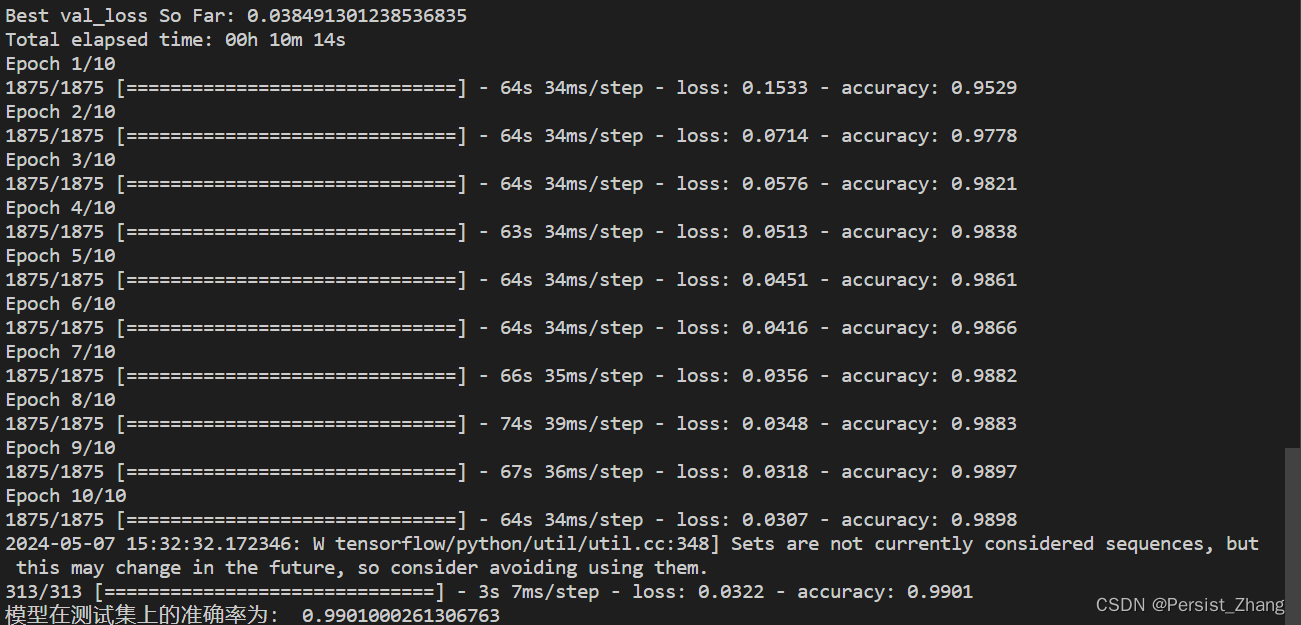
官网下载链接:https://www.tableau.com/zh-cn/support/releases
学生账户申请链接:https://www.tableau.com/zh-cn/academic/students。直接去学信网下载学籍在线验证作为申请证明。
目录
1、可视化原理
2、基础图表制作
2.1 对比分析(比大小)
2.1.1柱状图
2.1.2条形图
2.1.3 热力图
2.1.4气泡图
2.1.5词云
2.2 变化分析(看趋势)
2.2.1折线图
2.2.2面积图
2.3 构成分析(看占比)
2.3.1饼图
2.3.2 树堆图
2.3.3堆积图
2.4 关系分布(看位置)
2.4.1散点图
2.4.2聚类分析
2.4.3直方图
2.4.4地图
1、可视化原理
1)导入数据,并建立连接:
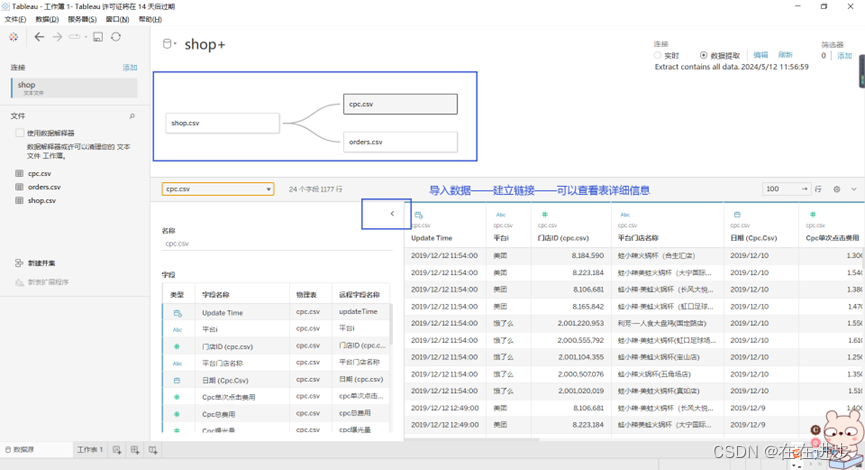
2)度量默认聚合:
注意复制数值到其他位置需要按住Ctrl,否则就是移动不是复制

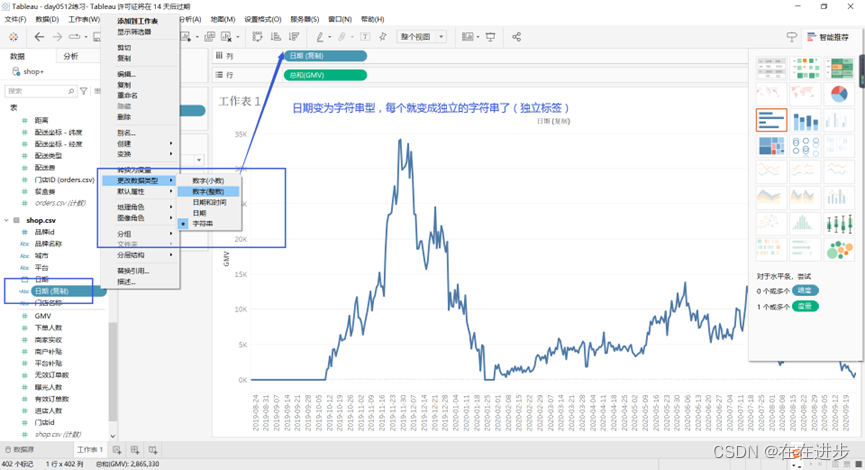
3)为便于可视化,数据类型可改变:
4)饼图:数量(度量属性)对应的是饼图的“角度”或“大小”,类别对应的是不同“颜色”。
图表分为有轴图表,和无轴图表(如饼图、气泡图、词云等)
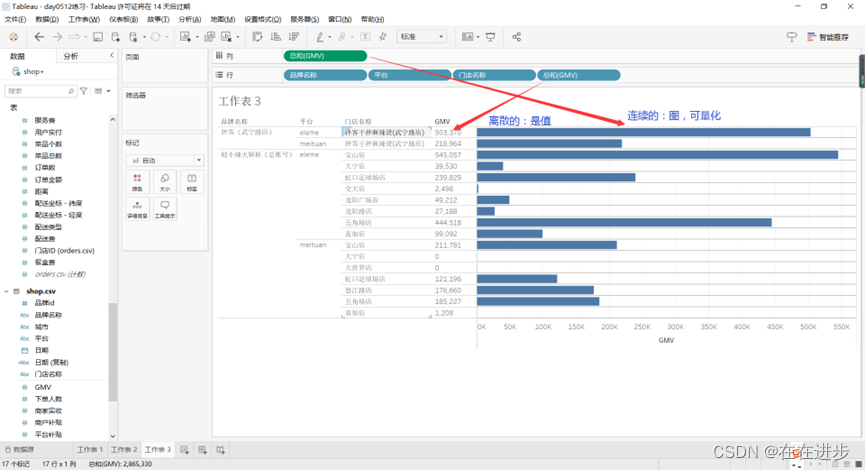
5)离散形成标签、连续形成数轴:
度量值分为离散和连续的,若设置为离散的,则跟维度属性一样,不能可视化。
2、基础图表制作
2.1 对比分析(比大小)
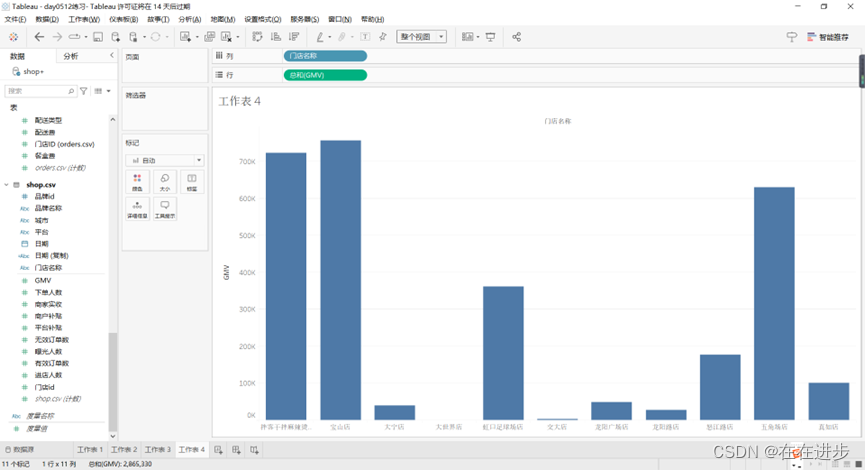
2.1.1柱状图
放好离散、连续属性的位置就行:
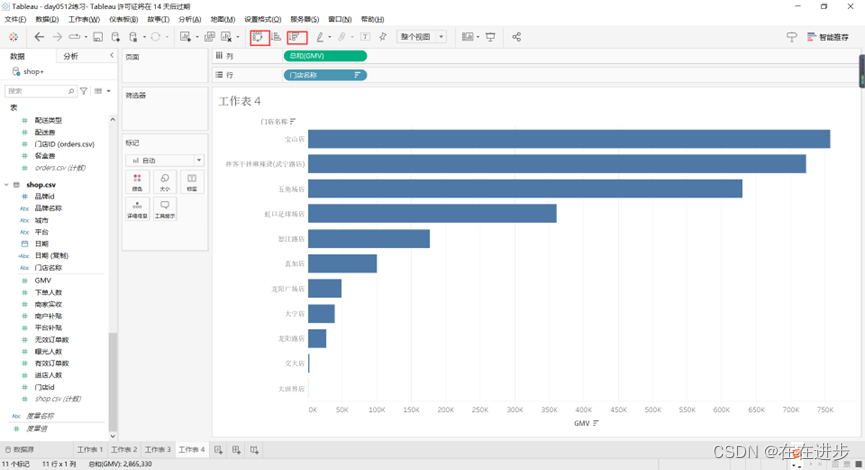
2.1.2条形图
在柱状图的基础上,转置,排序:
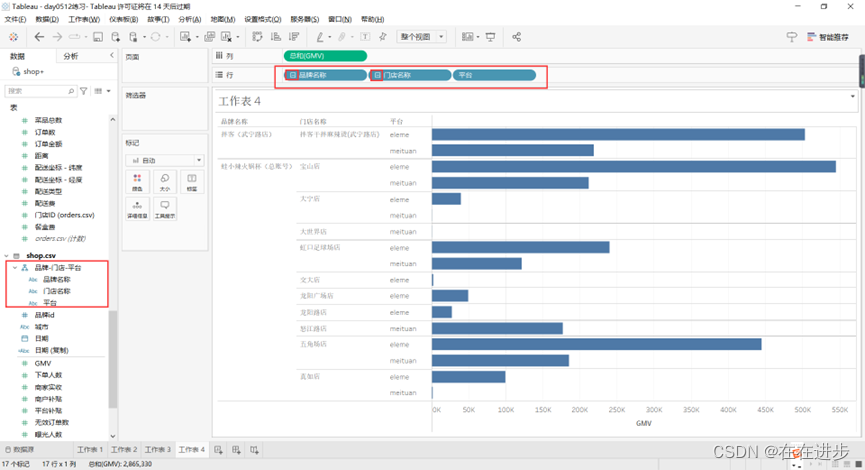
可创建分层结构:实现数据钻取
右键创建分层,就可以展开了(用完了可以右键移除分层结构)
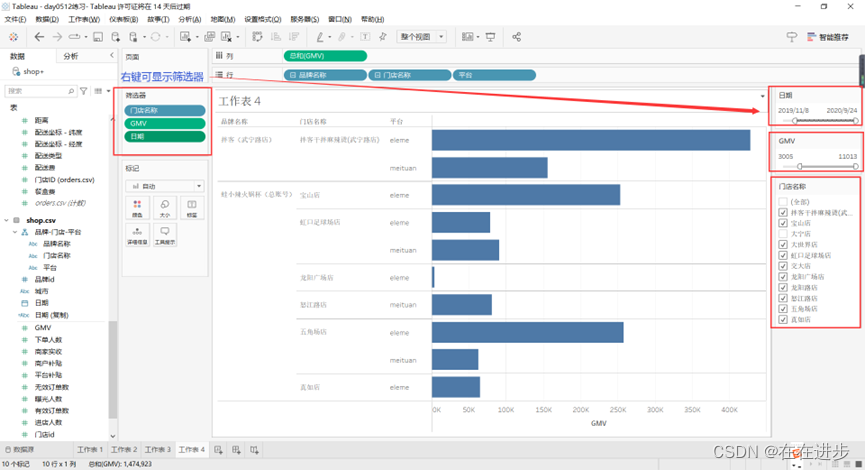
添加筛选器:实现数据选取
离散属性可以设置单选、多选等,数量和日期都是拉动选择范围。
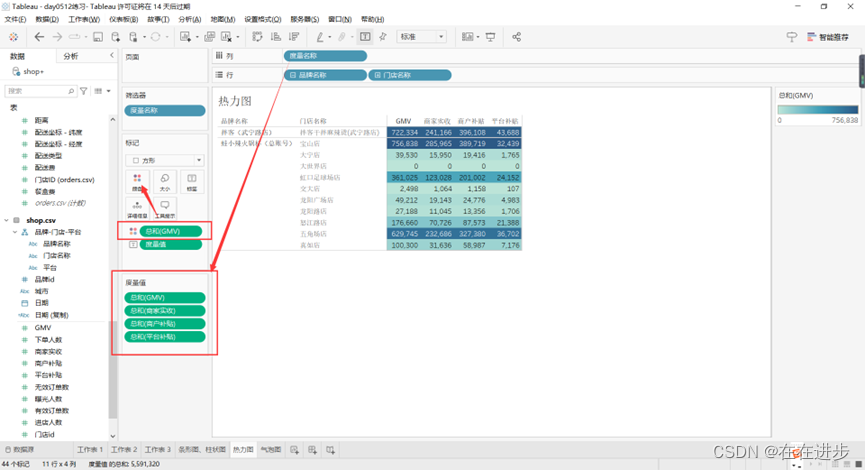
2.1.3 热力图
热力图=突出显示表
门店数据按门店名称等展开,突出显示GMV,最后直接将度量值GMV拖拽至颜色
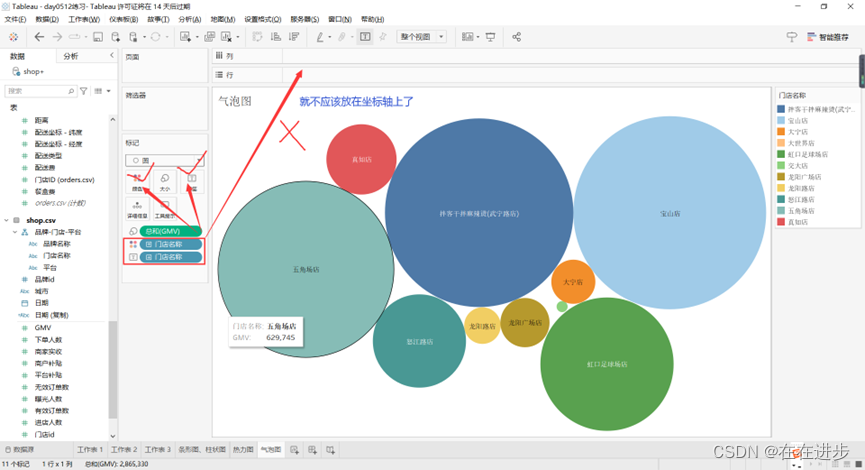
2.1.4气泡图
度量值区分气泡大小,维度区分颜色和显示标签就行,这个貌似没有坐标轴。
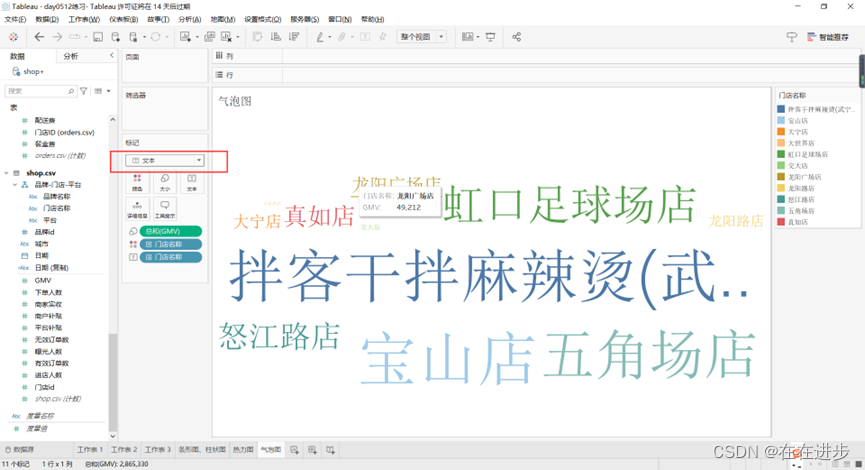
2.1.5词云
在气泡图的基础上改“圆”——“文本”
2.2 变化分析(看趋势)
2.2.1折线图
两种类型的日期,还是有点迷迷瞪瞪?
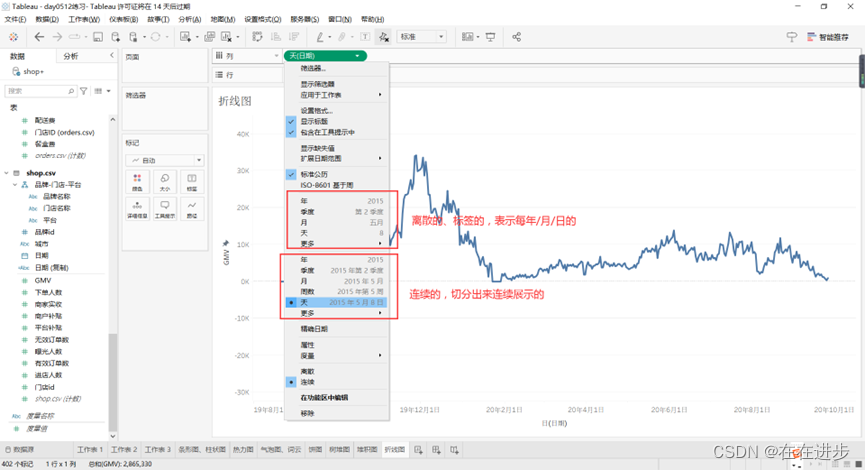
连续的月份可以预测:
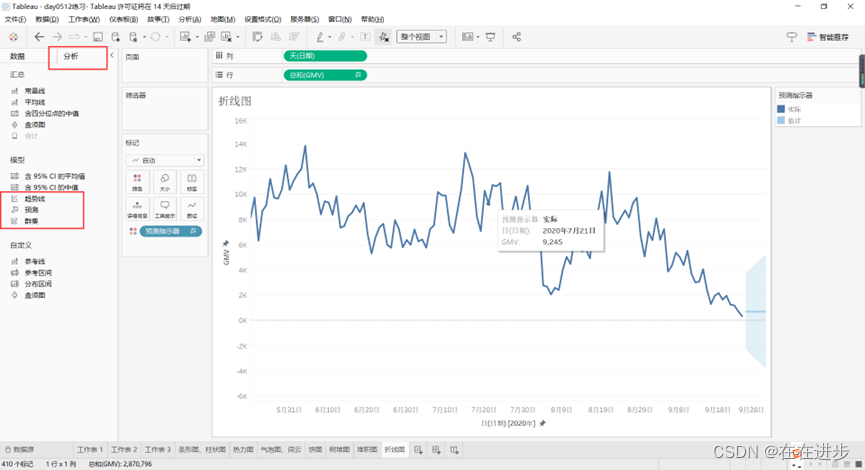
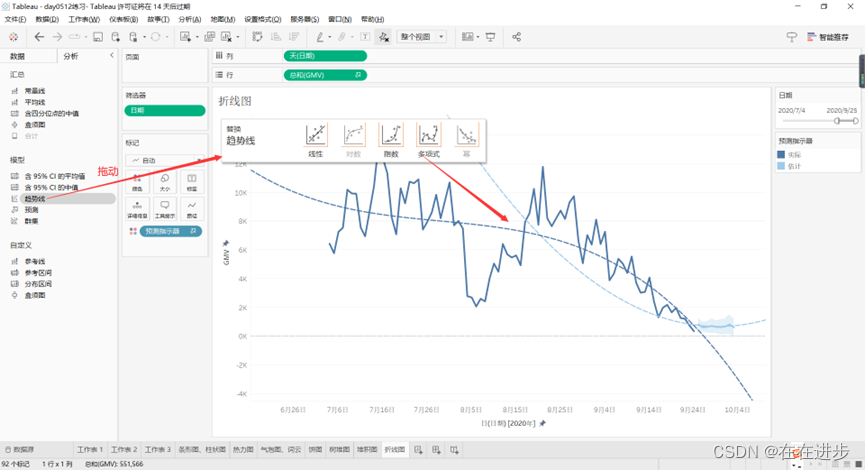
也可以设置趋势线:
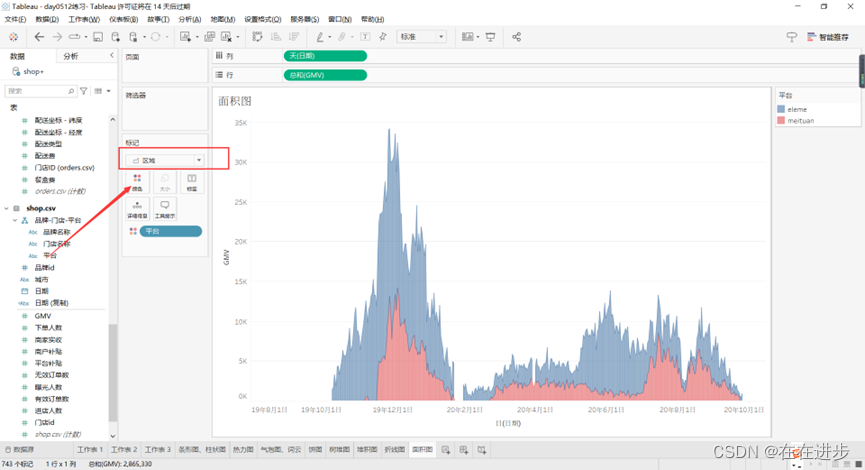
2.2.2面积图
● 使用场景
有内部累计关系的值随时间变化
不强调趋势,强调绝对值
● 图表逻辑
在折线图的基础上选择面积作为视觉影射
如:要看每天每个平台的GMV差异
2.3 构成分析(看占比)
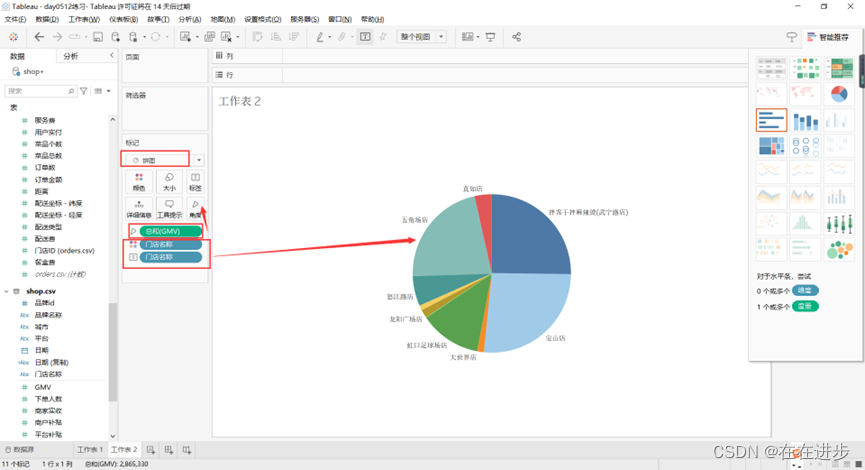
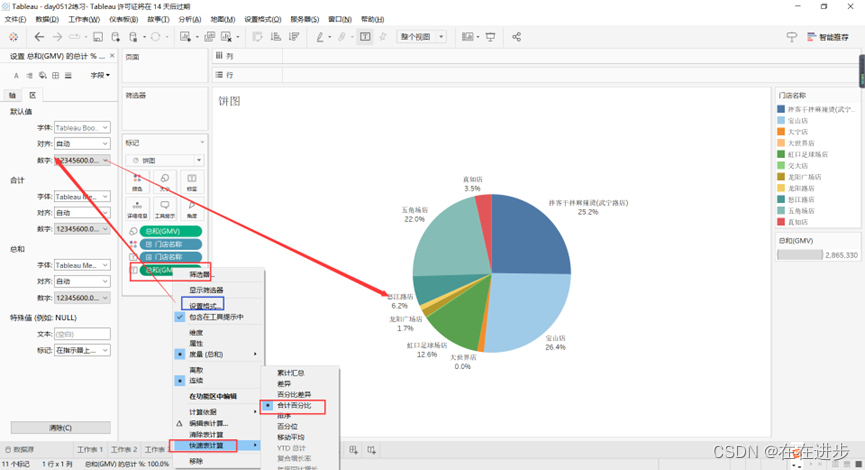
2.3.1饼图
门店——GMV占比:
【维度】代表各扇区的颜色,【度量】代表饼图中各扇区角度的大小。
【度量】和【维度】拖拽至标记显示数值,但饼图一般不标记绝度值,只标记百分比。
● 【快速表计算】
右键标签度量选择快速表计算,合计百分比计算各数值的百分比占比
最后右键标记的数值设置格式,区,第一个,设置为为1位数百分比
帮助右下角可以调整视图的显示方式
2.3.2 树堆图
在饼图的基础上,切换为“方形”。
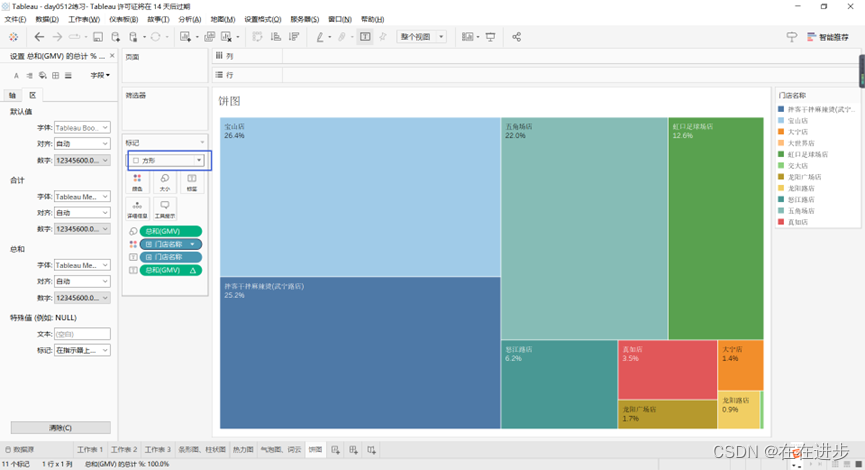
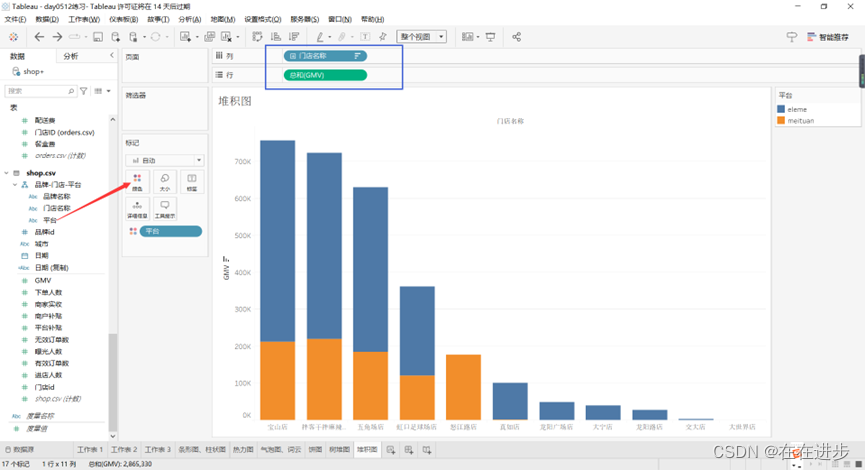
2.3.3堆积图
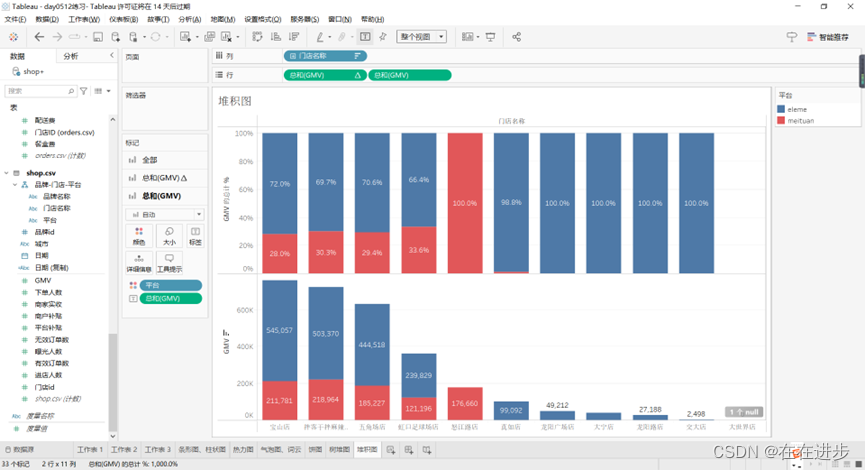
堆积图=看内部占比
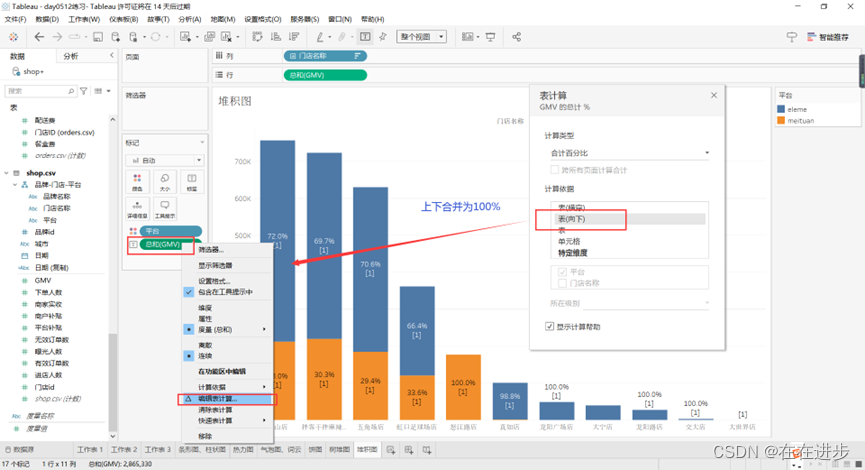
对数值进行百分比计算,看每个门店各平台的实际占比:编辑表计算
对坐标轴也进行百分比计算:
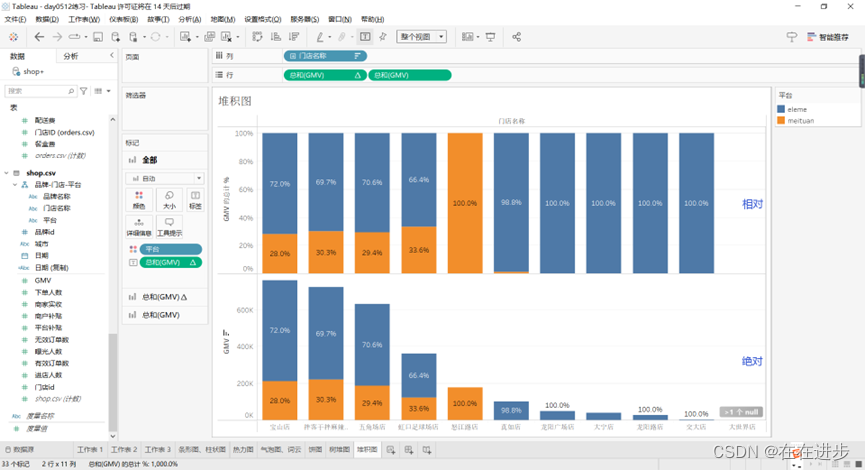
可以又看相对又看绝对:
2.4 关系分布(看位置)
2.4.1散点图
● 使用场景
分析某一【维度】变量在两个【度量】下的分布和变量之间的相关性
产品的销售额和所得利润之间的关系(正相关、弱相关、不相关)
● 图表逻辑
横纵轴各代表一个【度量】,【维度】中的变量则作为一个点,根据横纵轴上的度量值大小确认位置
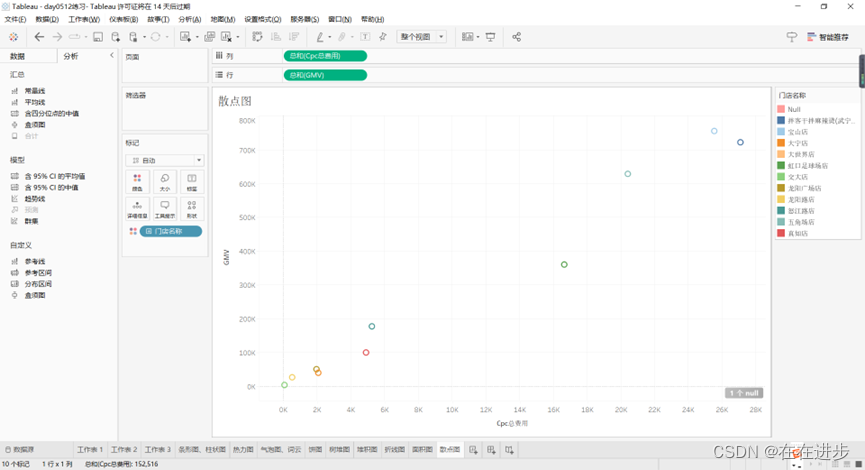
如:看各门店在cpc总费用和GMV下的相关性。
如下是各门店的投入产出比:
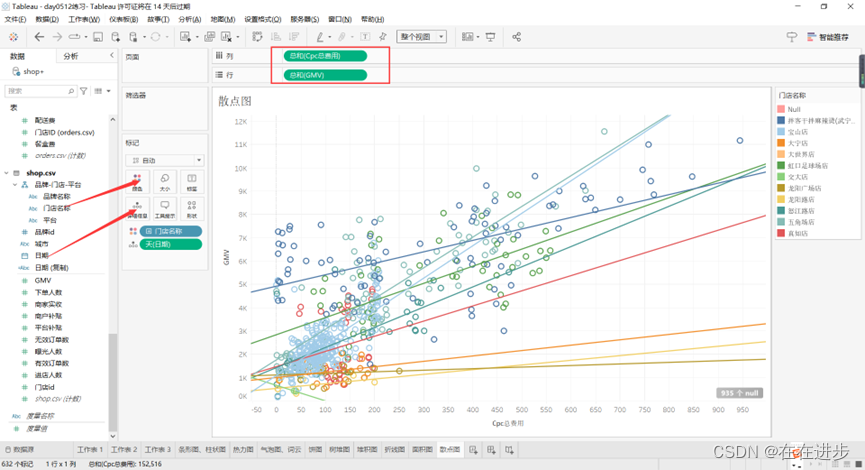
如下是每天、各平台的投入产出比:
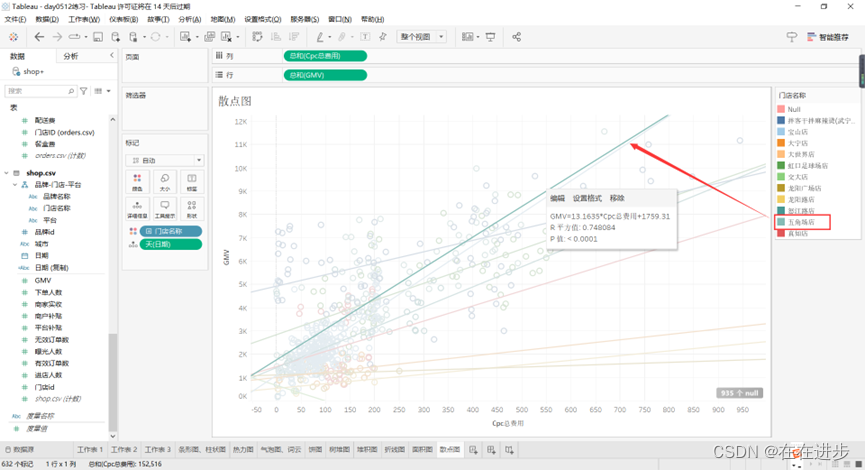
趋势线越陡峭,说明投入产出比越高。
2.4.2聚类分析
此处使用“群集”功能:
● 分析-群集即可对变量进行聚类分析,具有相同分布特征的变量会被分为一类
● K-means聚类算法,基于欧式距离计算
门店:根据投入产出比,将门店分为黄色、蓝色2类
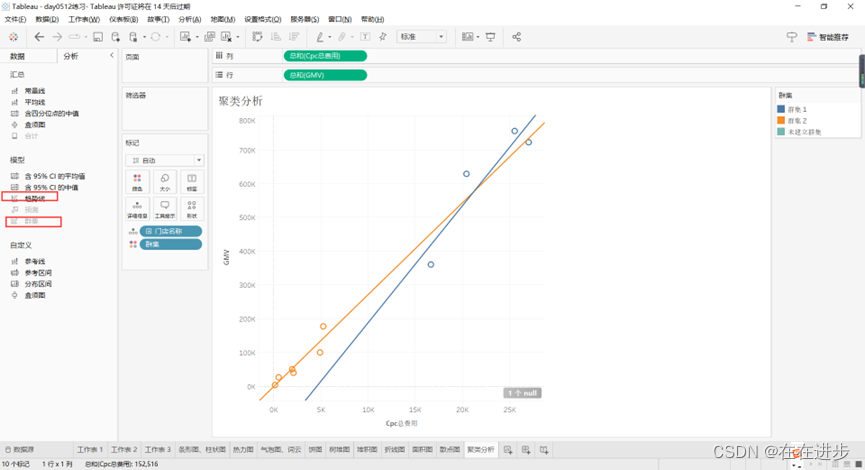
日期:根据投入产出比,将日期分为黄色、蓝色2类。
可以看出后期投入产出比更高?
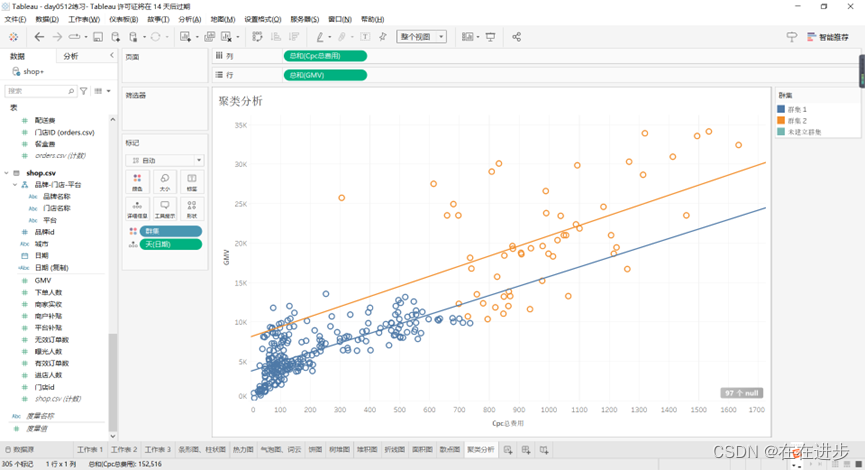
不大懂啥意义。。。
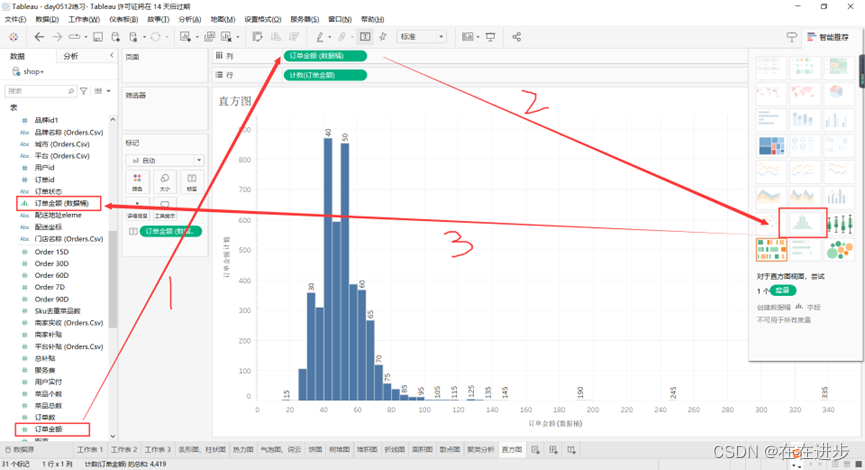
2.4.3直方图
直方图 = 数据桶 = 对数据进行分类再计数
● 使用场景
查看单一度量下的数据分布
常见分布:
2/8法则
马太效应
40-20-10
如果你想让你的APP保持增长势头,那么你的新用户次日留存率,7天留存率和30天留存率应该分别维持在40%、20%和10%左右
● 图表逻辑:将度量下数据分组计数
方法1:直接偷懒用智能推荐
下图说明订单金额主要集中在40-50比较多。
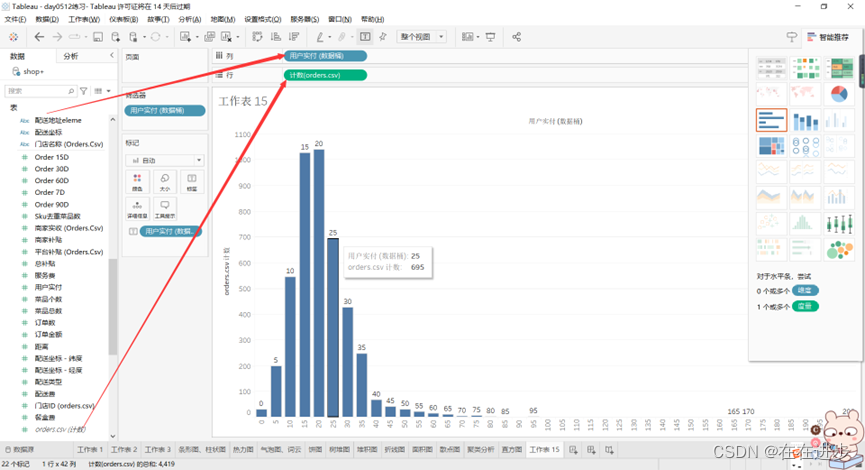
方法2:右键创建——数据桶——拖入坐标
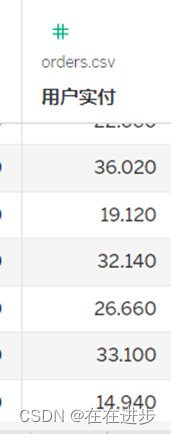
下图说明用户实付金额主要集中在15-20比较多。

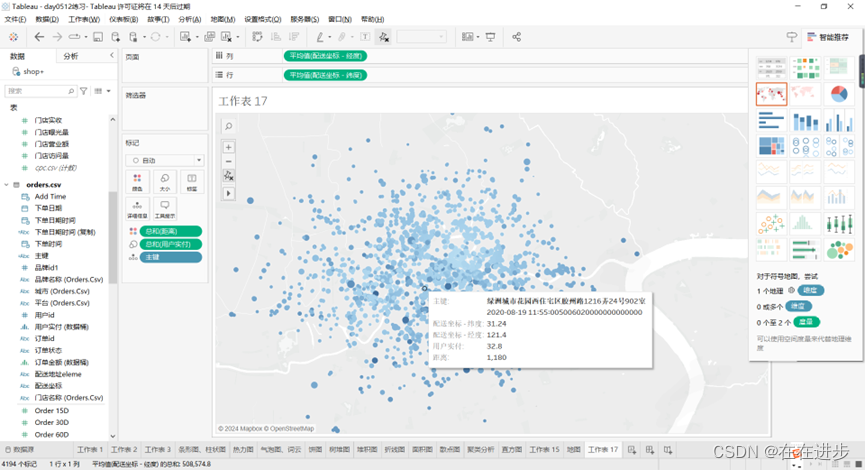
2.4.4地图
● 使用场景
基于地理位置的数据分析
● 图表逻辑
以地理位置为店,用点大小、颜色展示度量值大小等特征
图像放缩问题!!!已经成功可视化了看到只是一个点,放大说不定内容就出来了!!!!!!
下面这个经纬度确定的门店位置,但是颜色表示的距离不对,可能存在多个订单重合的情况。
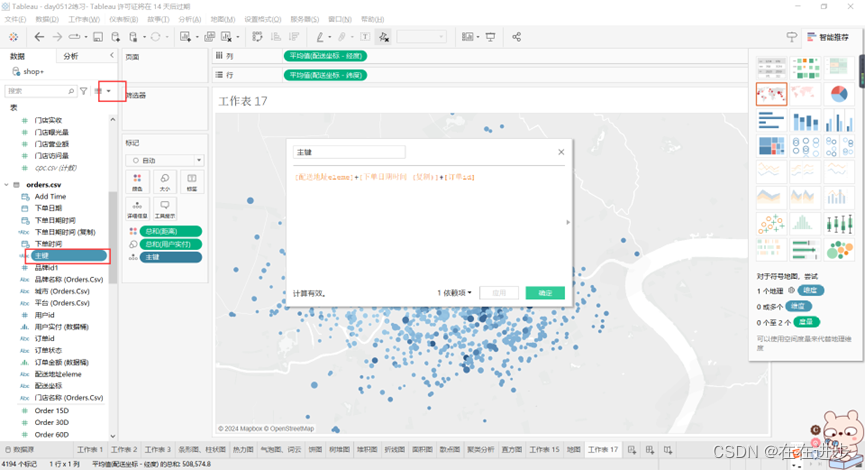
其中:主键是自己创建的计算字段
综合几个独一无二的信息属性进行可靠的区分。
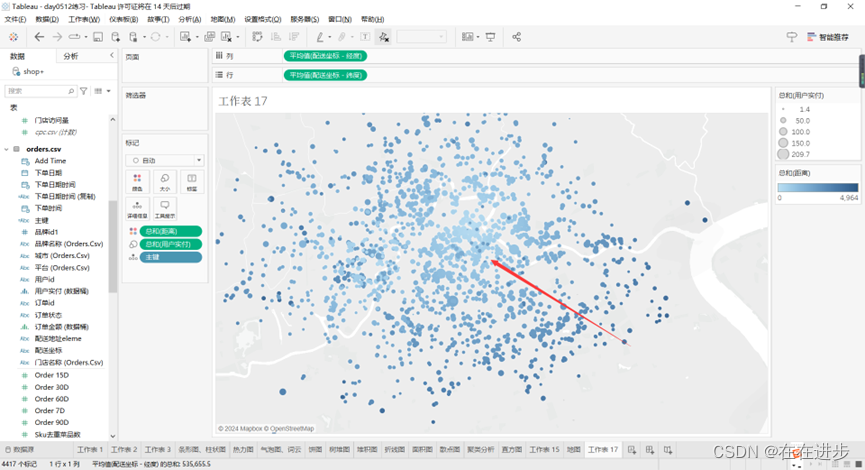
可以看出颜色最浅(距离最近)的地方就是这个经纬度确定门店位置。
数据下载:
链接:https://pan.baidu.com/s/1HSPTOZshZW0NED3TelpvSg?pwd=4pr4
提取码:4pr4