参考链接为:https://hands1ml.apachecn.org/1/
机器学习可以根据训练时监督的量和类型进行分类。主要有四类:监督学习、非监督学习、半监督学习和强化学习。
本文将简单介绍监督学习和非监督学习
监督学习
在监督学习中,用来训练算法的训练数据包含了答案,称为标签(label)
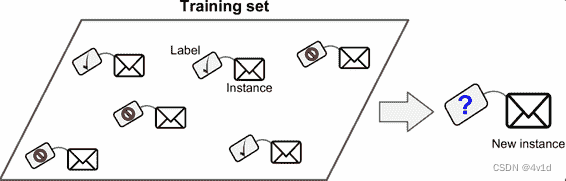
一个典型的监督学习任务是分类。
如上图所示,垃圾邮件过滤器就是一个很好的例子:用许多带有归类(垃圾邮件或普通邮件)的邮件样本进行训练,过滤器必须还能对新邮件进行分类。
那么label就是垃圾邮件和普通邮件,机器通过识别标签来学习不同类别的邮件,也即训练过程
这样训练之后的机器在面对一个没有标签的新例子(New instance)的时候就有一定的能力对它进行判断,作出是否过滤的决定
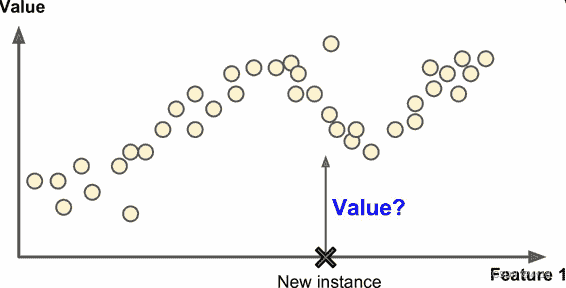
另一个典型任务是预测目标数值。
例如给出一些特征(里程数、车龄、品牌等等)称作预测值,来预测一辆汽车的价格。这类任务称作回归。
要训练这个系统,你需要给出大量汽车样本,包括它们的预测值和标签(即,它们的价格)。
以下是一些重要的监督学习算法
K 近邻算法
线性回归
逻辑回归
支持向量机(SVM)
决策树和随机森林
神经网络
非监督学习
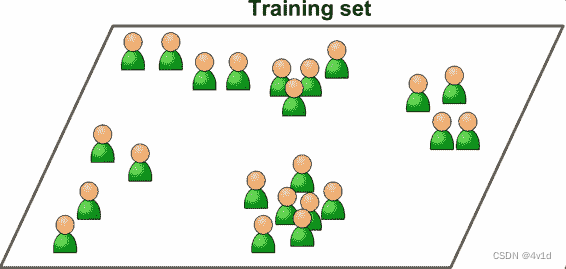
在非监督学习中,你可能猜到了,训练数据是没有加标签的。
这意味着机器需要自己分类判断,比如下图这样,将训练集中,一些相近的训练集数据聚集在一起,作为一个类别
现在举一个例子,假设你有一份关于你的博客访客的大量数据。
而你想运行一个聚类算法,检测相似访客的分组,如下图。
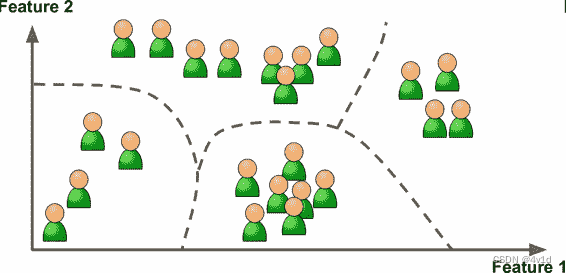
不过你不会告诉算法某个访客属于哪一类,而是让它自己找出关系,无需帮助。
例如,算法可能注意到 40% 的访客是喜欢漫画书的男性,通常是晚上访问,20% 是科幻爱好者,他们是在周末访问等等。如果你使用层次聚类分析,它可能还会细分每个分组为更小的组。这可以帮助你为每个分组定位博文。
同样,可视化算法也是极佳的非监督学习案例。
给算法大量复杂的且不加标签的数据,算法输出数据的 2D 或 3D 图像。算法会试图保留数据的结构(即尝试保留输入的独立聚类,避免在图像中重叠),这样就可以明白数据是如何组织起来的,也许还能发现隐藏的规律。
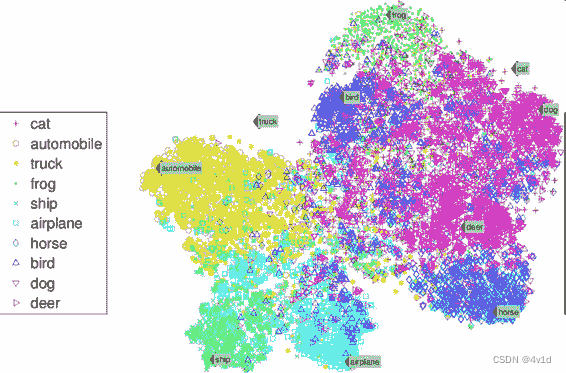
上图为SNE 可视化案例,突出了聚类(注:注意动物是与汽车分开的,马和鹿很近、与鸟距离远,以此类推)
与此有关联的任务是降维,降维的目的是简化数据、但是不能失去大部分信息。做法之一是合并若干相关的特征。
例如,汽车的里程数与车龄高度相关,降维算法就会将它们合并成一个,表示汽车的磨损。这叫做特征提取。
另一个重要的非监督任务是异常检测(anomaly detection)。
例如,检测异常的信用卡转账以防欺诈,检测制造缺陷,或者在训练之前自动从训练数据集去除异常值。
异常检测的系统使用正常值训练的,当它碰到一个新实例,它可以判断这个新实例是像正常值还是异常值。

最后,另一个常见的非监督任务是关联规则学习,它的目标是挖掘大量数据以发现属性间有趣的关系。
例如,假设你拥有一个超市。在销售日志上运行关联规则,可能发现买了烧烤酱和薯片的人也会买牛排。因此,你可以将这些商品放在一起。
下面是一些最重要的非监督学习算法:
聚类
K 均值
层次聚类分析(Hierarchical Cluster Analysis,HCA)
期望最大值
可视化和降维
主成分分析(Principal Component Analysis,PCA)
核主成分分析
局部线性嵌入(Locally-Linear Embedding,LLE)
t-分布邻域嵌入算法(t-distributed Stochastic Neighbor Embedding,t-SNE)
关联性规则学习
Apriori 算法
Eclat 算法