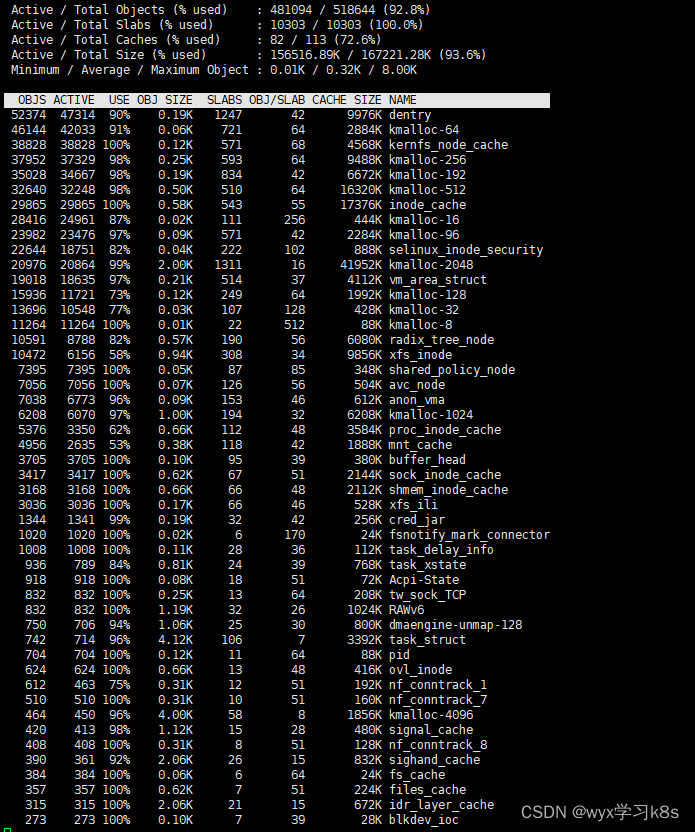
两个集群 两个库 两个表
- 搭建数据库服务
- 使用docker启动两个mysql 3506 3507
- 连接MyCat创建两个数据源
- 连接MyCat创建集群
- mycat创建逻辑库
- MyCat创建全局表广播表
- 创建分片表
- mycat逻辑库
- MyCat插入数据
- mycat查看数据
- 物理库3506查看数据
- 物理库3507查看数据
- ER表
- 创建ER表
- mycat插入数据
- mycat查询数据
- 物理节点3506数据分布
- 物理节点3507数据分布
- join关联查询
相关文档
MyCat安装
搭建数据库服务
使用docker启动两个mysql 3506 3507
version: '3'
services:
lx-one:
image: mysql:8.0.29
restart: always
environment:
MYSQL_ROOT_PASSWORD: 123456
MYSQL_PASSWORD: 123456
ports:
- 3506:3306
container_name: "lx-one"
lx-two:
image: mysql:8.0.29
restart: always
environment:
MYSQL_ROOT_PASSWORD: 123456
MYSQL_PASSWORD: 123456
ports:
- 3507:3306
container_name: "lx-two"
连接MyCat创建两个数据源
/*+ mycat:createDataSource{
"name":"dw0",
"url":"jdbc:mysql://172.23.85.23:3506",
"user":"root",
"password":"123456"
} */;
/*+ mycat:createDataSource{
"name":"dr0",
"url":"jdbc:mysql://172.23.85.23:3506",
"user":"root",
"password":"123456"
} */;
/*+ mycat:createDataSource{
"name":"dw1",
"url":"jdbc:mysql://172.23.85.23:3507",
"user":"root",
"password":"123456"
} */;
/*+ mycat:createDataSource{
"name":"dr1",
"url":"jdbc:mysql://172.23.85.23:3507",
"user":"root",
"password":"123456"
} */;

连接MyCat创建集群
/*! mycat:createCluster{"name":"c0","masters":["dw0"],"replicas":["dr0"]}*/;
/*!mycat:createCluster{"name":"c1","masters":["dw1"],"replicas":["dr1"]}*/;
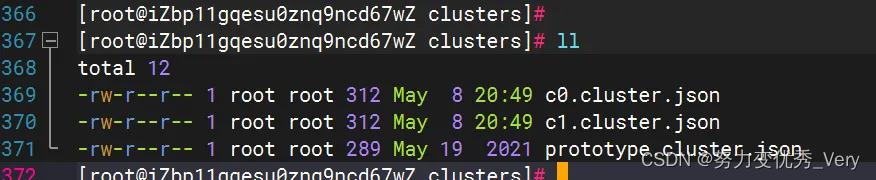
c0.cluster.json
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"dw0"
],
"maxCon":2000,
"name":"c0",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"dr0"
],
"switchType":"SWITCH"
}
c1.cluster.json
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"dw1"
],
"maxCon":2000,
"name":"c1",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"dr1"
],
"switchType":"SWITCH"
}
集群文件名称规范是 c0.cluster.json 、 c1.cluster.json 、 c2.cluster.json,以此类推,mycat启动的时候才会自动识别集群配置文件。
mycat创建逻辑库
CREATE DATABASE db1

db1.shema.json内容
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"db1",
"shardingTables":{},
"views":{}
}
MyCat创建全局表广播表
CREATE TABLE db1.`travelrecord` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` varchar(100) DEFAULT NULL,
`traveldate` date DEFAULT NULL,
`fee` decimal(10,0) DEFAULT NULL,
`days` int DEFAULT NULL,
`blob` longblob,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;
查看db1.schema.json变化
{
"customTables":{},
"globalTables":{
"travelrecord":{
"broadcast":[
{
"targetName":"c1"
},
{
"targetName":"c0"
}
],
"createTableSQL":"CREATE TABLE db1.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{},
"schemaName":"db1",
"shardingTables":{},
"views":{}
}
不需要自己指定targetName,创建全局表之后 会自动指定targetName。可能是自动识别了集群配置文件。因为全局表是每个库都要有的。所以mycat需要知道有哪些数据库
两个数据库3506、3507物理表有什么变化呢
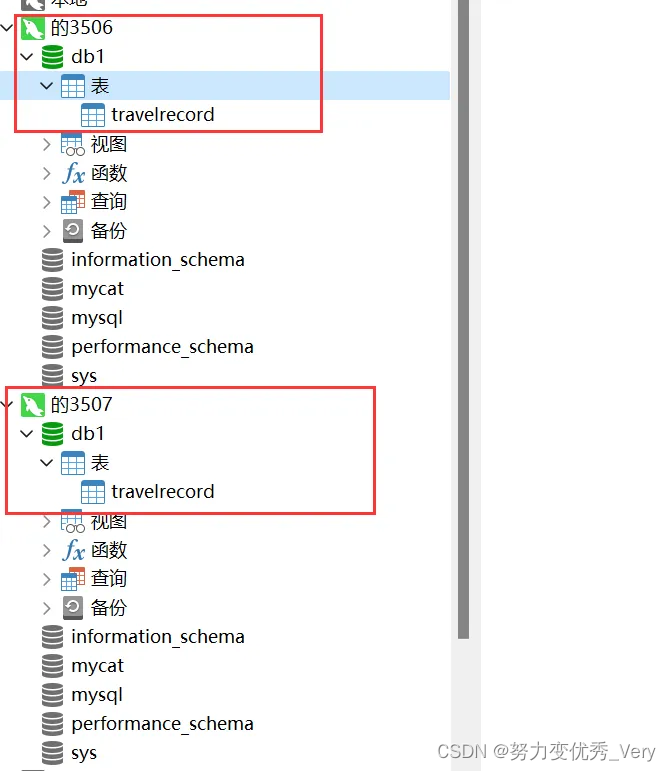
发现两个MySQL服务也都有了db1 库和表
创建分片表
CREATE TABLE db1.orders(
id BIGINT NOT NULL AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id),
KEY `id` (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(customer_id) tbpartition BY mod_hash(customer_id)
tbpartitions 1 dbpartitions 2;
查看db1.schema.json变化
{
"customTables":{},
"globalTables":{
"travelrecord":{
"broadcast":[
{
"targetName":"c1"
},
{
"targetName":"c0"
}
],
"createTableSQL":"CREATE TABLE db1.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{},
"schemaName":"db1",
"shardingTables":{
"orders":{
"createTableSQL":"CREATE TABLE db1.orders (\n\tid BIGINT NOT NULL AUTO_INCREMENT,\n\torder_type INT,\n\tcustomer_id INT,\n\tamount DECIMAL(10, 2),\n\tPRIMARY KEY (id),\n\tKEY `id` (`id`)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(customer_id) DBPARTITIONS 2\nTBPARTITION BY mod_hash(customer_id) TBPARTITIONS 1",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/db1_${dbIndex}/orders_${index}",
"tableNum":"1",
"tableMethod":"mod_hash(customer_id)",
"storeNum":2,
"dbMethod":"mod_hash(customer_id)"
}
},
"shardingIndexTables":{}
}
},
"views":{}
}
文件解释
- shardingTables :分片表规则
- shardingTables.properties: 分片配置
- dbNum:分库数量
- dbMethod(customer_id) :库的分片算法,以及根据的字段
- tableNum:分表数量
- tableMethod(customer_id) :表的分片算法,以及根据的字段
mycat逻辑库

物理库 两个MySQL 服务也都分了库和表
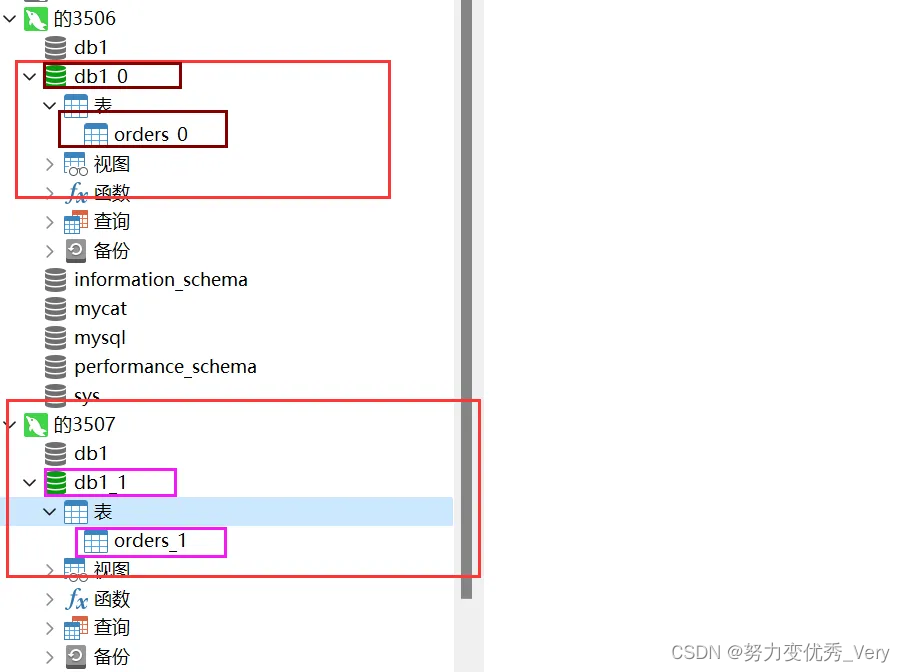
为什么出现了db1_0和db1_1
因为在创建表的时候指定了数据库分片规则和数据表的分片规则
dbpartition BY mod_hash(customer_id) tbpartition BY mod_hash(customer_id)
tbpartitions 1 dbpartitions 2;
MyCat插入数据
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(6,102,100,100020);
mycat查看数据
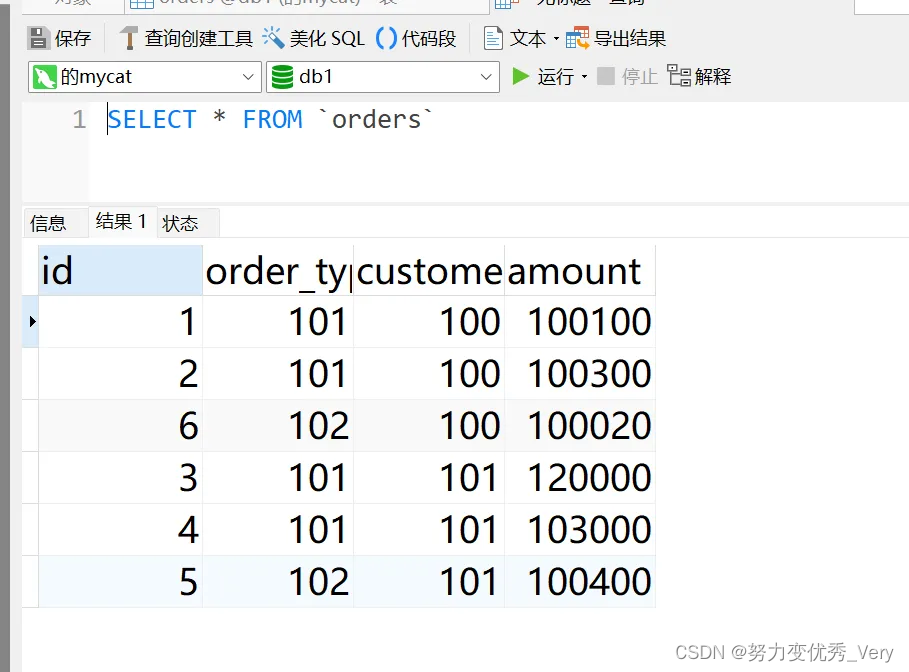
物理库3506查看数据
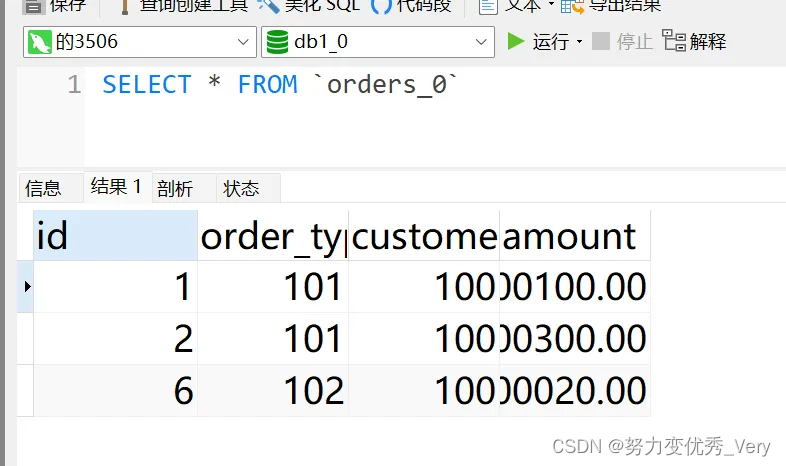
物理库3507查看数据
发现每个物理库根据分片字段存储数据库是不一样的,
ER表
与分片表关联的表如何分表,也就是 ER 表如何分表,
创建ER表
CREATE TABLE orders_detail(
`id` BIGINT NOT NULL AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(order_id) tbpartition BY mod_hash(order_id)
tbpartitions 1 dbpartitions 2;
mycat显示

物理库3506显示
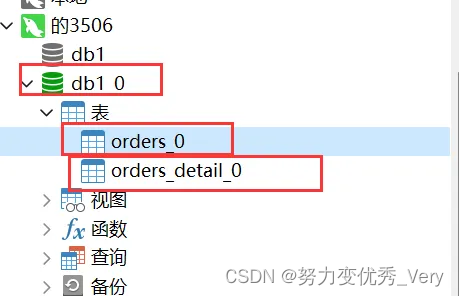
物理库3507显示
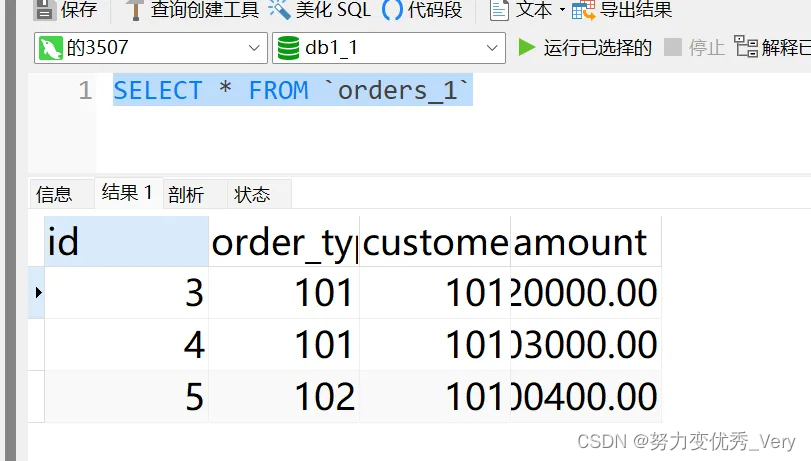
mycat插入数据
INSERT INTO orders_detail(id,detail,order_id) VALUES(1,'detail1',1);
INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2);
INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3);
INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4);
INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5);
INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);
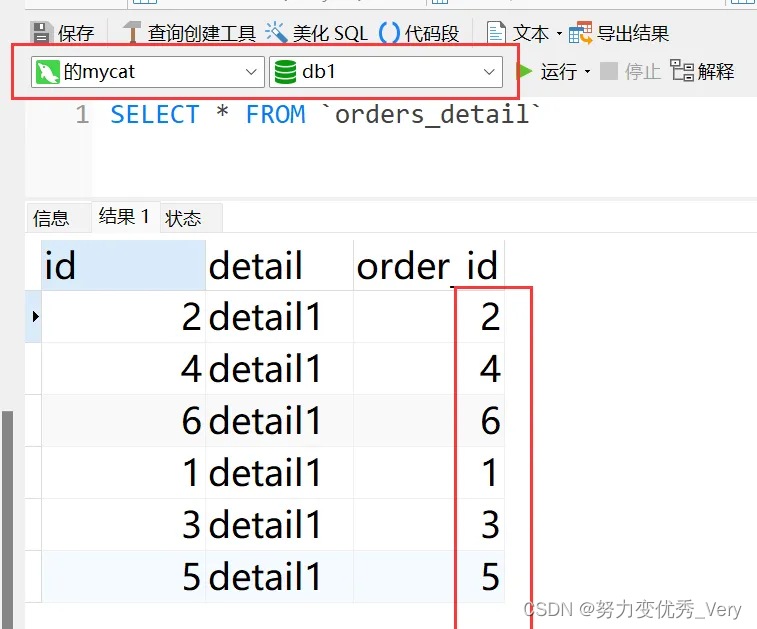
mycat查询数据
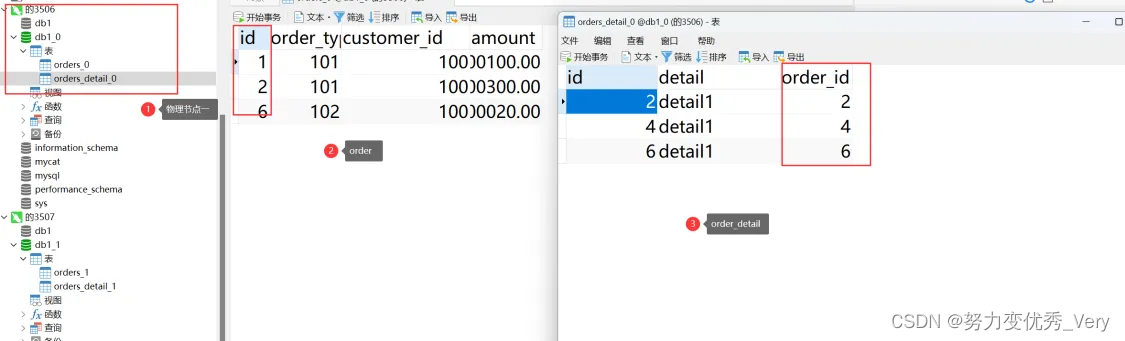
物理节点3506数据分布
物理节点3507数据分布
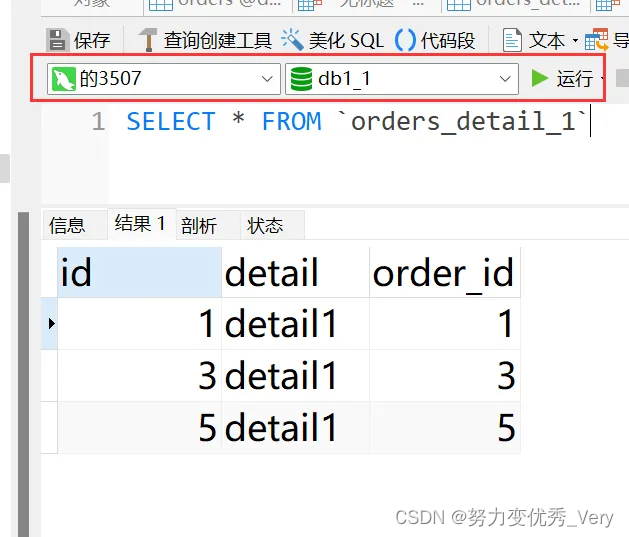
join关联查询
SELECT * FROM orders o INNER JOIN orders_detail od ON od.order_id=o.id;
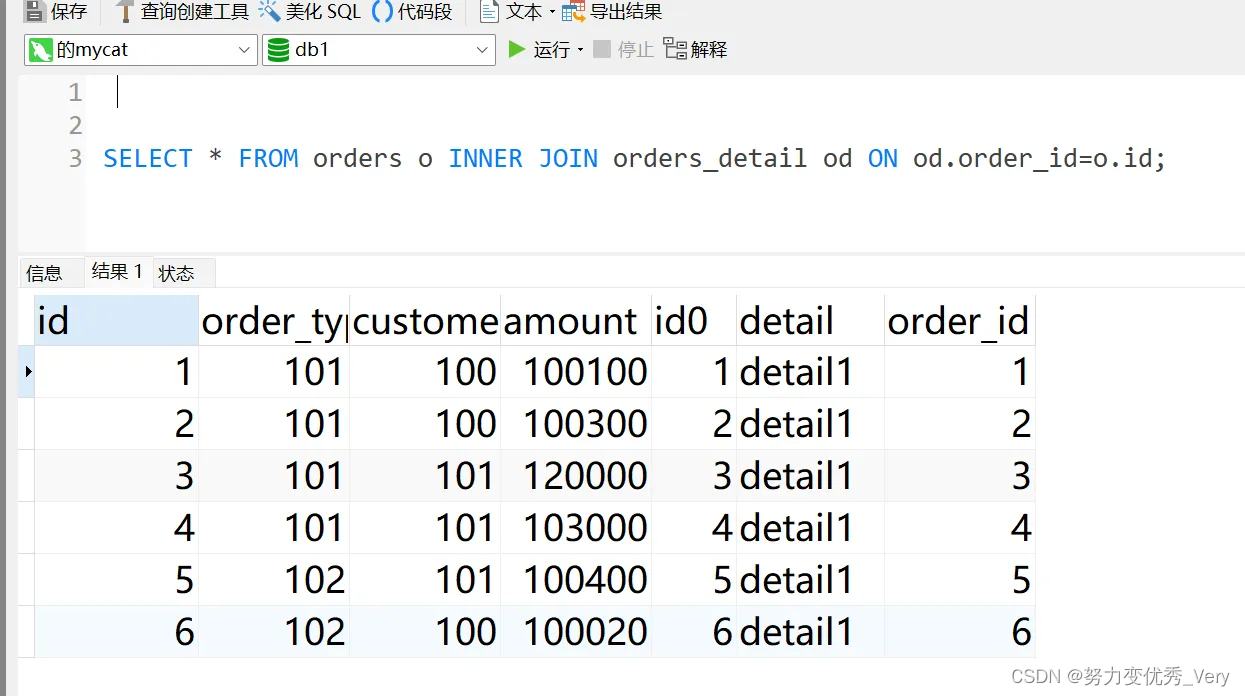
看一下具体物理划分到底是不是数据都划分到一块了呢?
物理节点3506数据分布
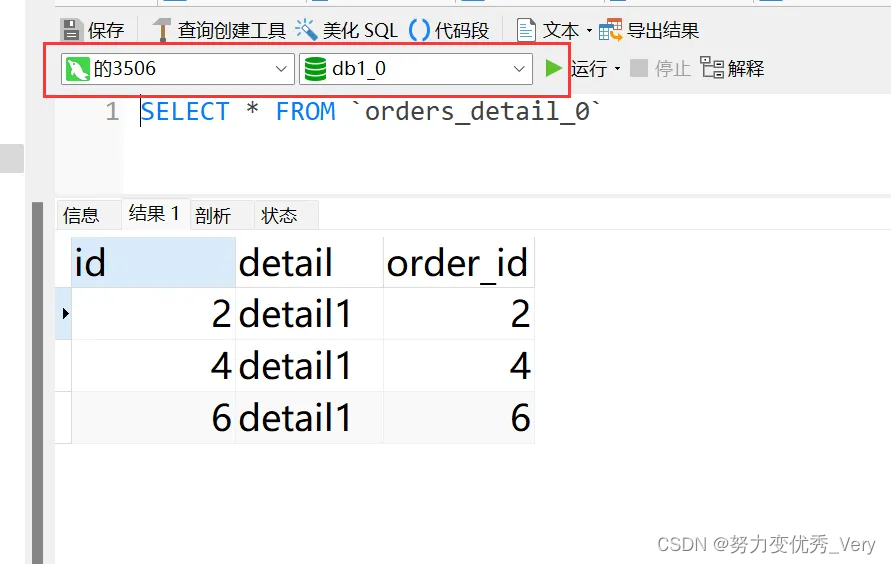
物理节点3507数据分布
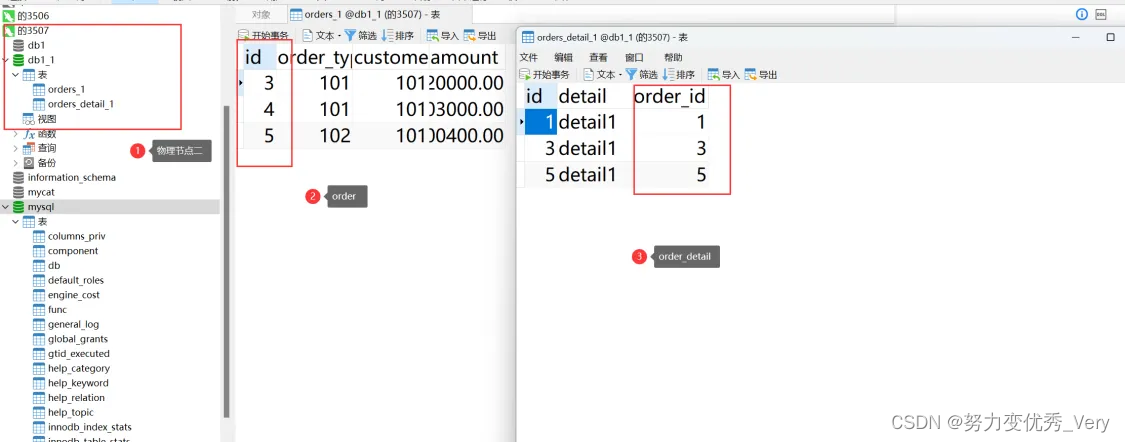
发现两个数据有的不是在同一个数据库 怎么查询出来的呢?

原理:
mycat作为一个中间件,根据查询的SQL语句进行分片分析,找到对应的实际物理数据库节点,然后把数据合并之后再返回。
查看配置的表是否具有 ER 关系(父表和子表的关系),使用
/*+ mycat:showErGroup{}*/

一个是db1下的orders,一个是db1下的orders_detail都属于一个groupId
#group_id 表示相同的组,该组中的表具有相同的存储分布,运行关联语句的时候,就会把相同组的表自动进行关联