目录
1-1.西瓜书
1-2.课程定位
1-3.机器学习
1-4.典型的机器学习过程
1-5.机器学习理论
1-6.基本术语
1-7.归纳偏好
1-8.NFL定理
1-1.西瓜书
建议使用方式
1.初学机器学习的第一本书:通读、速读;细节不懂处略过,了解机器学习的疆域和基本思想,理解基本概念“观其大略”
2.阅读其他关于机器学习具体分支的读物(三月、半年)
3.再读、对“关键点”的理解:理解技术细冗后的本质,升华认识“提纲挈领”
4.对机器学习多个分支有所了解(1-3年)
5.再读、细思:
不同内容的联系,不同的描述方式、出现位置蕴涵的意义、……个别字句的启发可能自行摸索数年不易得
“疏通经络”

1-2.课程定位
科学:是什么,为什么
技术:怎么做
工程:怎么样做的多快好省
应用:理论方法使用

主要讲科学和技术,工程较少,应用最少
1-3.机器学习
经典定义:利用经验改善系统自身的性能

1-4.典型的机器学习过程
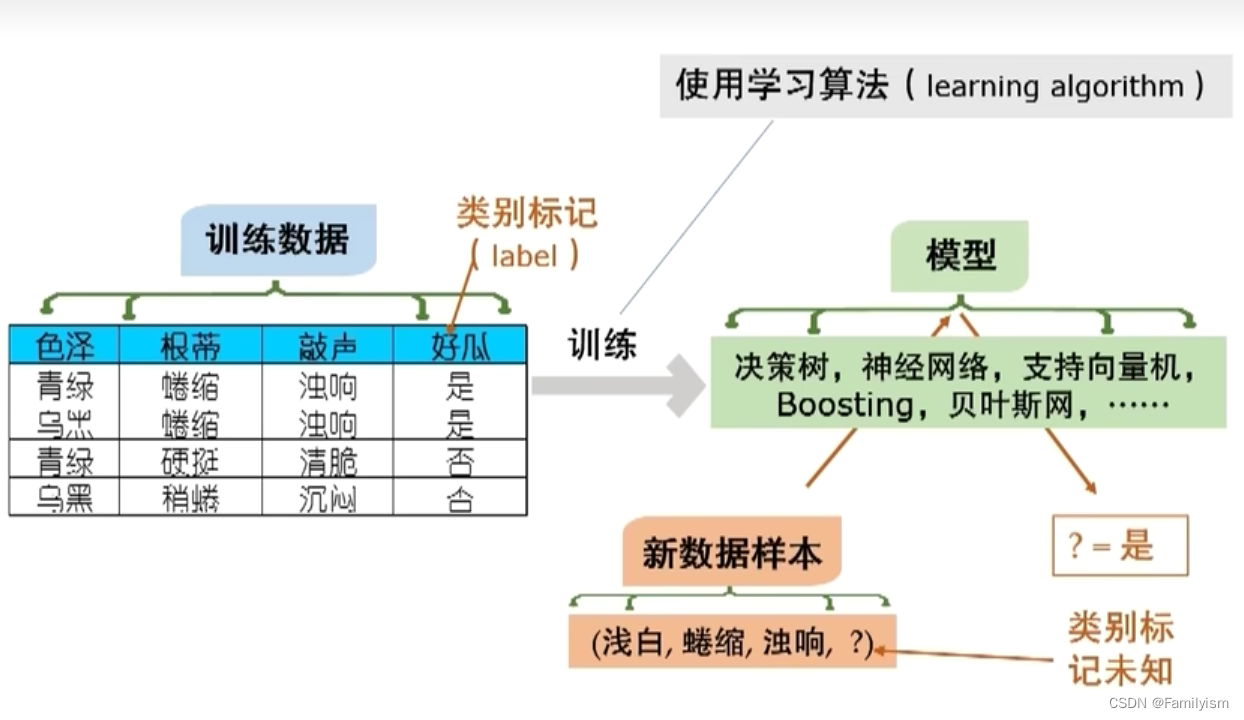
1-5.机器学习理论
最重要的理论模型:PAC
x:样本,f:模型,f(x):预测的结果,y:真实的结果
期待以一个很高的概率得到一个一个准确的结果。
reason:1.机器学习研究的问题具有高度的不确定性。2.p?np

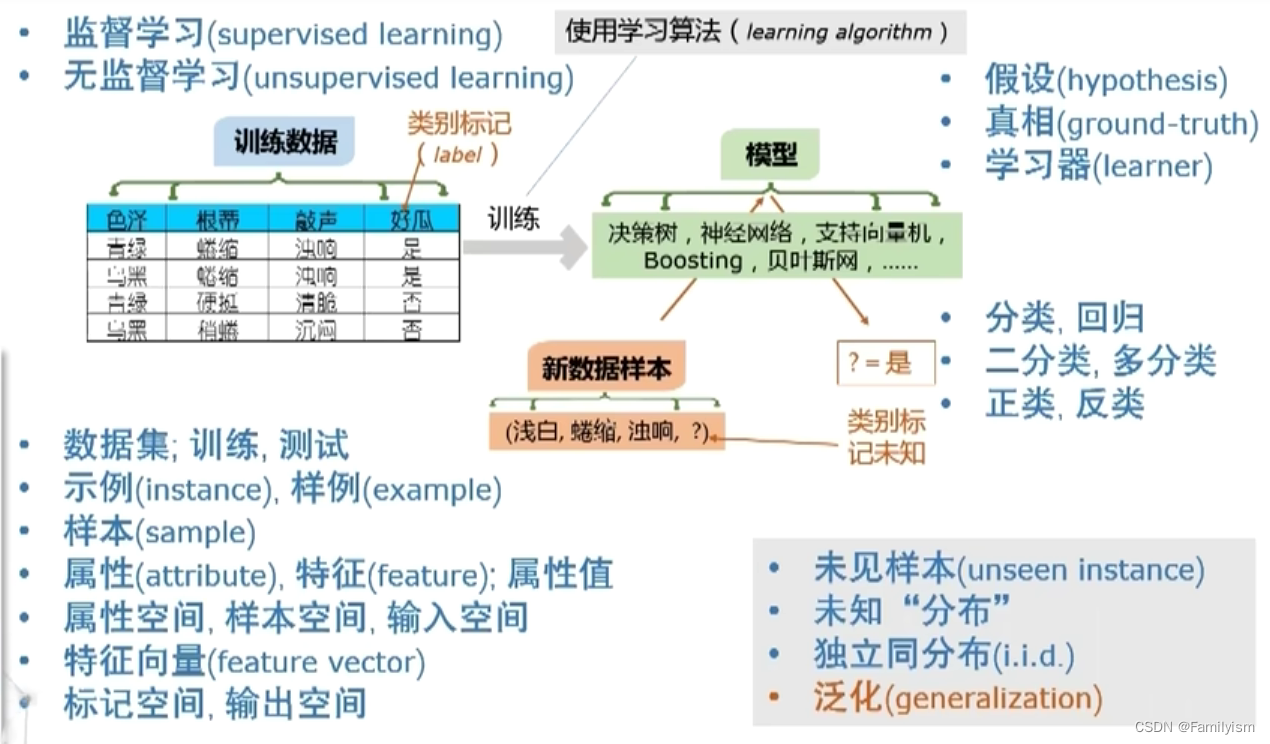
1-6.基本术语
数据集;训练,测试(通常训练数据和测试数据是分开的)
示例,样本(无结果),样例(有结果)
属性,特征(反映事件或对象在某个方面的表现或性质);属性值(属性上的取值)
属性空间,样本空间,输入空间(属性张成的空间)
特征向量(一个示例对应的坐标向量)
标记向量,输出空间
假设(模型学到的东西)
真相(真实的东西)
学习器(学到的模型)
分类(预测的是离散值),回归(预测的是连续值)
二分类(只涉及两个类别),多分类(涉及多个类别)
正类,反类(一个类为正类,另一个类为反类)
监督学习,无监督学习(根据训练数据是否拥有标记信息)
未见样本(未来的新数据)
未知“分布”(假定数据背后的规律)
独立同分布(每个样本都是独立的)
泛化(学到模型适用于新样本的能力)
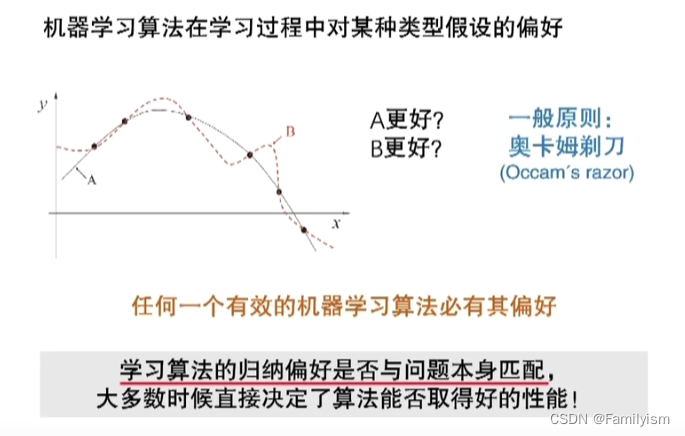
1-7.归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好
一般原则:奥卡姆剃刀(若非必要,勿增实体)
任何一个有效的机器学习算法必有其归纳偏好
学习算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能
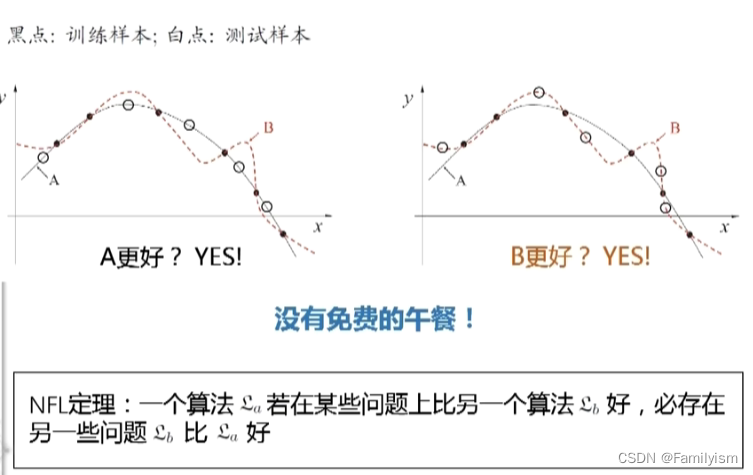
1-8.NFL定理
NFL(no free lunch)
NFL定理的重要前提:所有问题出现的机会相同,或所有问题同等重要
实际情形并非如此,我们通常只关注自己正在试图解决的问题
具体问题,具体分析
现实机器学习应用