相关代码地址见文末
1.数据读取
数据采用的是电影推荐的数据集,movies.csv文件存储为电影及其题材。

ratings.csv下存储为用户对电影的评分。
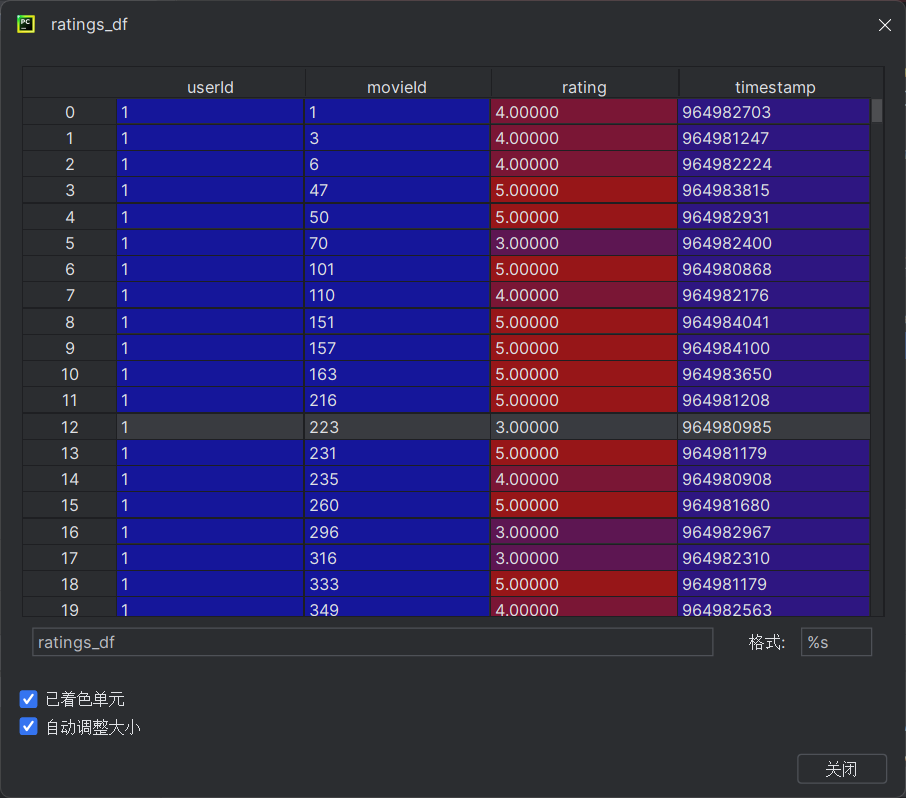
数据集的读取流程为:
- 首先,读取movies.csv并将题材根据词的出现,转换为one-hot编码的形式
- 读取ratings.csv,将movie_id和user_id映射为从0开始
代码如下:
import pandas as pd
import torch
from torch_geometric.data import HeteroData
import torch_geometric.transforms as T
from torch_geometric.nn import SAGEConv, to_hetero
from torch import Tensor
import tqdm
import torch.nn.functional as F
# Load the entire movie data frame into memory:
movies_df = pd.read_csv('./ml-latest-small/movies.csv', index_col='movieId')
# Split genres