逻辑回归是一种广泛用于分类任务的统计模型,尤其是用于二分类问题。在逻辑回归中,我们预测的是观测值属于某个类别的概率,这通过逻辑函数(或称sigmoid函数)来实现,该函数能将任意值压缩到0和1之间。
逻辑回归的基本原理
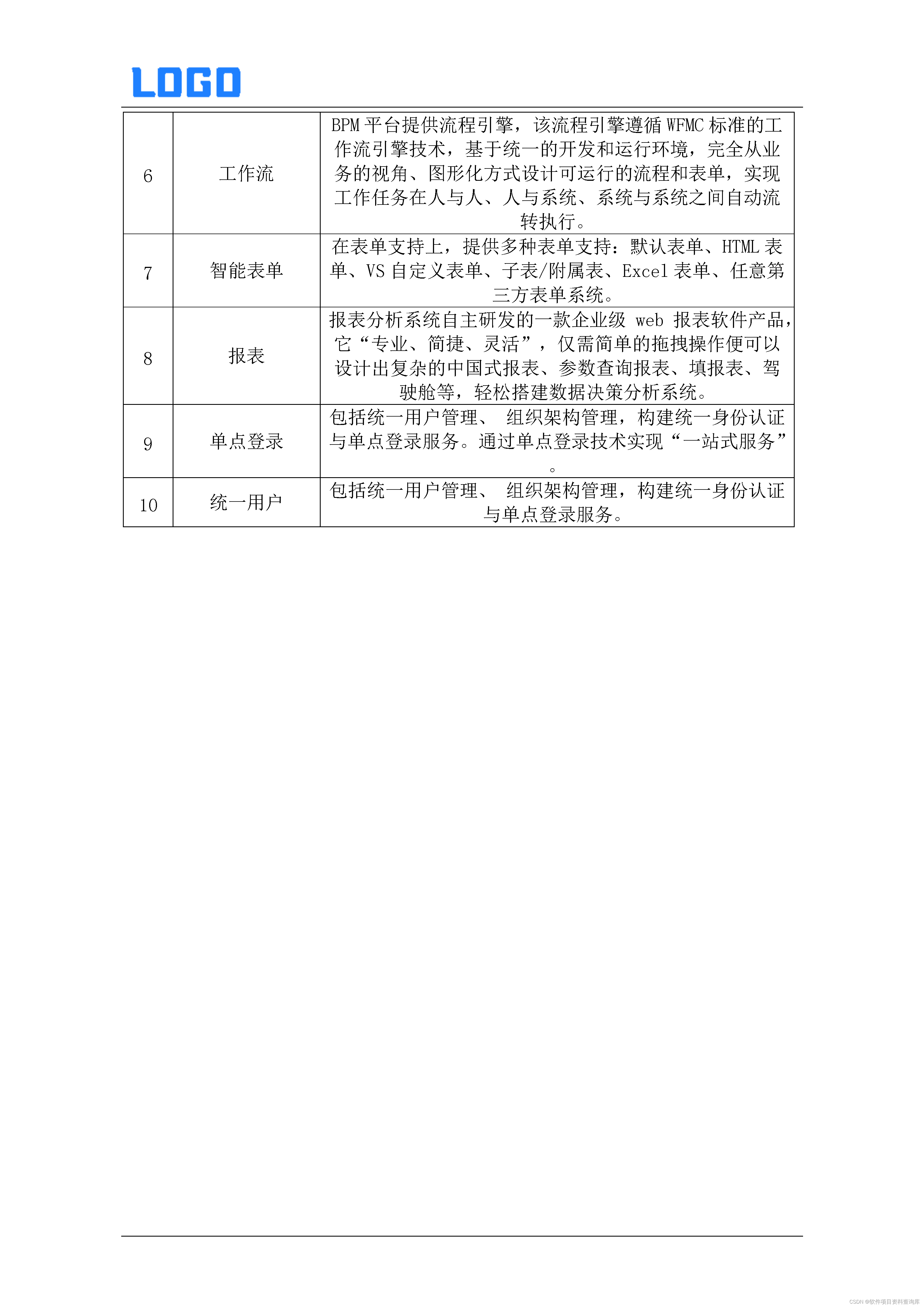
逻辑回归模型的输出是通过逻辑函数转换的线性方程的结果,公式如下:
其中:
- 𝑝是给定观测属于正类的概率。
- 𝑏0,𝑏1 等是模型参数。
- 𝑥 是输入特征。
模型通过最大化似然函数(或等价地最小化成本函数,如交叉熵损失)来学习参数。
Python 实现逻辑回归
在Python中,我们可以使用scikit-learn库中的LogisticRegression类来实现逻辑回归模型。以下是一个具体案例,展示了如何使用逻辑回归来分类鸢尾花数据集中的花朵类型。
案例分析:鸢尾花数据集分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
# 加载数据
data = load_iris()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建逻辑回归模型
model = LogisticRegression(max_iter=200) # 增加迭代次数以确保收敛
model.fit(X_train, y_train)
# 进行预测
predictions = model.predict(X_test)
# 输出性能评估
print("Classification Report:")
print(classification_report(y_test, predictions))
print("Confusion Matrix:")
print(confusion_matrix(y_test, predictions))
这段代码首先加载了鸢尾花数据集,这是一个包含150个样本的多分类数据集,每个样本有4个特征和3种可能的输出类别。代码接着将数据分为训练集和测试集,然后创建了一个逻辑回归模型,训练这个模型,并在测试集上进行预测。最后,代码打印了分类报告和混淆矩阵,以评估模型性能。
高级应用:正则化
在逻辑回归中,为了防止过拟合,通常会加入正则化项。scikit-learn的LogisticRegression默认使用L2正则化。可以通过调整C参数(正则化强度的倒数)来控制正则化的程度。
# 创建带L2正则化的逻辑回归模型
model = LogisticRegression(C=0.1, max_iter=200) # 较小的C表示较强的正则化
model.fit(X_train, y_train)
# 进行预测和性能评估
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
通过调整C的值,我们可以找到防止过拟合同时保持模型准确性的最佳平衡点。这种技术尤其在特征数量很多的情况下非常重要,可以显著提高模型的泛化能力。
如果我们想进一步探索逻辑回归在更复杂的数据集和不同的应用场景中的应用,以及提高模型性能的高级技术,可以从以下几个方面展开:
处理非线性问题:特征工程
逻辑回归本质上是一个线性分类器,这意味着它在处理非线性可分的数据时可能效果不佳。通过特征工程,例如增加多项式特征,可以帮助逻辑回归模型捕捉到数据中的非线性关系。
实例:使用多项式特征
from sklearn.datasets import make_circles
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
# 创建一个非线性可分的数据集
X, y = make_circles(n_samples=100, factor=0.5, noise=0.1, random_state=42)
# 使用多项式特征和逻辑回归的管道
model = make_pipeline(PolynomialFeatures(degree=3), LogisticRegression(max_iter=200))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model.fit(X_train, y_train)
# 进行预测和评估
predictions = model.predict(X_test)
print("Classification Report:")
print(classification_report(y_test, predictions))
这个例子通过PolynomialFeatures生成了数据的多项式组合,从而允许逻辑回归模型学习复杂的非线性决策边界。
处理类别不平衡问题
在现实世界的数据中,经常会遇到类别不平衡问题,这可能导致模型过度拟合多数类而忽视少数类。针对这一问题,逻辑回归模型可以通过调整类权重来处理。
示例:使用类权重
# 创建逻辑回归模型时使用类权重
model = LogisticRegression(class_weight='balanced', max_iter=200)
model.fit(X_train, y_train)
# 预测和评估
predictions = model.predict(X_test)
print("Classification Report:")
print(classification_report(y_test, predictions))
在LogisticRegression中设置class_weight='balanced'可以让模型更加关注少数类,从而改善在不平衡数据上的表现。
应用于文本数据:文本分类
逻辑回归是自然语言处理中常用的基线模型之一,尤其是在文本分类任务中。结合词袋模型或TF-IDF转换器,逻辑回归能够提供强大的性能。
示例:文本分类
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.datasets import fetch_20newsgroups
# 加载数据
categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
newsgroups_train = fetch_20newsgroups(subset='train', categories=categories)
newsgroups_test = fetch_20newsgroups(subset='test', categories=categories)
# 文本向量化
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(newsgroups_train.data)
X_test = vectorizer.transform(newsgroups_test.data)
y_train, y_test = newsgroups_train.target, newsgroups_test.target
# 训练模型
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# 预测和评估
predictions = model.predict(X_test)
print("Classification Report:")
print(classification_report(y_test, predictions))
在这个例子中,TfidfVectorizer将文本数据转换为TF-IDF特征矩阵,逻辑回归模型使用这些特征进行学习和预测。
总结
逻辑回归虽然简单,但通过合理的数据预处理、特征工程和模型调整,它能够处理广泛的问题,从简单的二分类到复杂的多类文本分类。在实际应用中,通过理解数据特性和适当的模型调整,逻辑回归可以成为一种强大且高效的工具。
深入探讨逻辑回归在特殊情况下的应用和高级特性
逻辑回归虽然是一种相对简单的模型,但在特定情境下,通过适当的技术可以极大地扩展其应用范围和性能。下面,我们将探索一些逻辑回归的高级应用和技术,以及在特殊数据类型上的应用。
多标签分类
逻辑回归通常用于二分类或多类分类问题,但通过一些修改,它也可以用于多标签分类问题,其中一个实例可以同时属于多个类别。
示例:多标签分类
from sklearn.datasets import make_multilabel_classification
from sklearn.multioutput import MultiOutputClassifier
# 创建多标签数据集
X, y = make_multilabel_classification(n_samples=1000, n_features=20, n_classes=3, n_labels=2, random_state=42)
# 划分训练和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用逻辑回归进行多标签分类
model = MultiOutputClassifier(LogisticRegression(max_iter=200))
model.fit(X_train, y_train)
# 预测和评估
predictions = model.predict(X_test)
print("Sample of predicted labels:", predictions[:5])
在这个例子中,MultiOutputClassifier包装器被用来扩展逻辑回归,使其能处理多标签输出。每个标签的分类问题都被独立处理。
处理稀疏数据
在处理高维度的稀疏数据时,如文本数据或某些类型的用户交互数据,逻辑回归表现尤为出色,特别是在配合L1正则化时,可以帮助进行特征选择,减少模型的复杂性。
示例:使用L1正则化处理稀疏数据
from sklearn.feature_extraction.text import CountVectorizer
# 假设已有文本数据:newsgroups_train.data
vectorizer = CountVectorizer(max_features=10000)
X_train = vectorizer.fit_transform(newsgroups_train.data)
# 训练带L1正则化的逻辑回归模型
model = LogisticRegression(penalty='l1', solver='liblinear', max_iter=1000)
model.fit(X_train, newsgroups_train.target)
# 检查非零权重的数量,了解特征被选择的情况
non_zero_weights = np.sum(model.coef_ != 0, axis=1)
print("Number of features used:", non_zero_weights)
在这种情况下,L1正则化有助于模型只选择最重要的特征,从而提高模型的解释性和预测效率。
序列数据和时间依赖性
虽然逻辑回归本身不处理时间序列数据,通过适当的数据转换和特征工程,逻辑回归可以应用于预测时间序列数据中的事件或状态改变。
示例:时间窗口特征
import pandas as pd
# 假设有一个时间序列数据集 df,包含时间戳和一些测量值
features = pd.DataFrame({
'mean_last_3': df['value'].rolling(window=3).mean(),
'max_last_3': df['value'].rolling(window=3).max(),
'min_last_3': df['value'].rolling(window=3).min()
})
features.fillna(method='bfill', inplace=True)
# 使用逻辑回归预测基于滑动窗口特征的事件
model = LogisticRegression(max_iter=200)
model.fit(features[:-1], df['event'][1:])
在这个例子中,我们创建了基于过去三个时间点的统计特征,用于预测下一个时间点的事件。这种方法虽然简单,但对于某些类型的时间依赖问题来说可能已经足够。
结论
逻辑回归的应用远不止于其最基本的形式。通过适当的技术和方法,它可以适用于多种复杂的实际问题。无论是处理非线性数据、类别不平衡、高维稀疏数据还是时间序列数据,逻辑回归都可以通过一些智能的策略和特征工程被有效地应用。在实践中,理解数据的本质和需求,选择适合的模型和策略是设计有效机器学习系统的关键。
继续深入逻辑回归模型的应用和探索,我们可以考虑更多高级的统计分析方法,集成学习策略,以及逻辑回归在特定领域中的创新应用。下面我们将展开讨论这些主题。
增强逻辑回归的统计分析能力
逻辑回归不仅是一个预测模型,它也是一个强大的统计工具,用于估计变量之间的关系强度和方向。通过更细致的统计分析,我们可以提高模型的解释性和准确性。
示例:变量显著性测试和置信区间
使用统计软件包,如statsmodels,来进行逻辑回归,可以让我们不仅得到预测模型,还能进行假设检验和置信区间的估计。
import statsmodels.api as sm
# 假设X和y已经定义并且是适合进行逻辑回归的数据
X = sm.add_constant(X) # 添加常数项
logit_model = sm.Logit(y, X)
result = logit_model.fit()
print(result.summary())
statsmodels的输出提供了每个系数的P值、置信区间和其他统计指标,这有助于我们了解哪些变量是统计显著的,从而提供更深入的数据洞察。
集成学习中的逻辑回归
虽然单一的逻辑回归模型有时可能不够强大,但它可以被集成到更复杂的机器学习框架中,如随机森林或梯度提升机中的弱分类器。
示例:使用逻辑回归作为弱学习器
在集成学习中,逻辑回归可以与其他类型的分类器结合,以提高预测性能。
from sklearn.ensemble import AdaBoostClassifier
# 创建逻辑回归作为基学习器的AdaBoost实例
base_lr = LogisticRegression(solver='liblinear', penalty='l1')
ada_boost = AdaBoostClassifier(base_estimator=base_lr, n_estimators=50, learning_rate=0.5)
ada_boost.fit(X_train, y_train)
# 评估模型
predictions = ada_boost.predict(X_test)
print("Classification Report:")
print(classification_report(y_test, predictions))
通过AdaBoost算法增强逻辑回归模型,我们可以有效地结合多个逻辑回归模型的决策力,以达到更高的分类准确率。
特定领域中的逻辑回归应用
逻辑回归由于其模型简单和结果易于解释的特性,在医学、金融和社会科学等领域有广泛应用。
示例:信用评分模型
在金融领域,逻辑回归是构建信用评分模型的常用技术之一。
from sklearn.preprocessing import StandardScaler
# 假设X_train和X_test包含信用评分的特征
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
model = LogisticRegression()
model.fit(X_train_scaled, y_train)
# 获取预测概率
probabilities = model.predict_proba(X_test_scaled)[:, 1]
在信用评分模型中,逻辑回归帮助银行预测某个客户违约的概率,这是金融机构决策过程中一个关键的因素。
结论
逻辑回归的应用非常广泛且多样。通过对模型进行适当的调整和扩展,逻辑回归不仅能提供良好的预测性能,还能提供有价值的数据洞察和决策支持。在实际应用中,逻辑回归模型应结合具体领域的需求和数据特性进行优化,以实现最佳的效果。