截图文字怎么识别?在数字化时代,信息的快速处理和转换成为了提高工作效率的关键。截图文字识别技术,作为连接视觉信息与数字文本的桥梁,极大地便利了我们的工作和生活。它允许用户从图像中提取文字内容,进而编辑、搜索或存储,使得信息更加灵活易用。因此,本文将详细介绍三种常见的截图文字识别方法。

方法一:光学字符识别(OCR)
光学字符识别(Optical Character Recognition, OCR)是一种通过扫描或拍摄图片中的文字,并将其转换为可编辑和可搜索的电子文本的技术。并且,现在有许多结合了OCR和深度学习技术的软件,它们能够识别多种字体、大小和布局的文字,甚至支持多语种识别,例如一键识别王、迅捷OCR文字识别软件等。
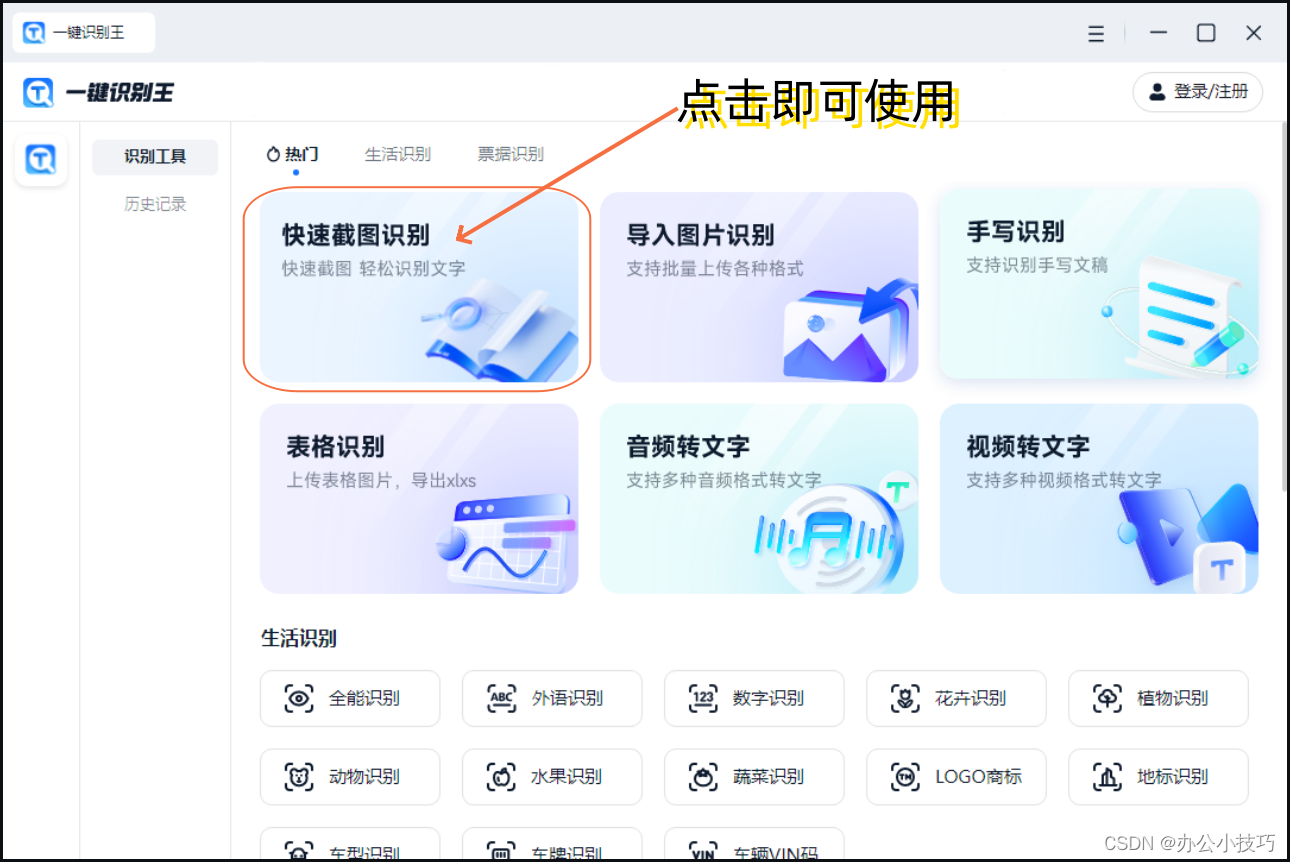
在一键识别王中,我们对应使用快速截图识别功能。而使用其功能很简单,只要上传图片并点击识别按钮即可。这类方法的优点是具有广泛适用性、高度自动化,以及灵活性。但也有缺点,那就是在低质量图像、艺术字体或复杂布局的情况下,OCR的识别准确率仍可能下降。
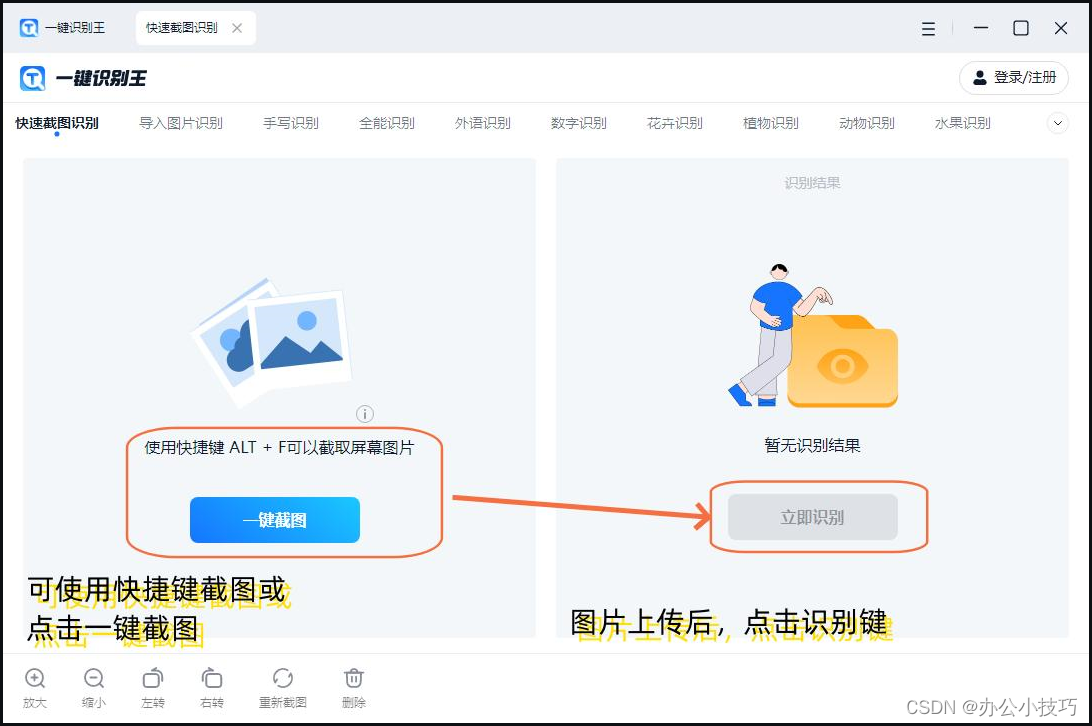
方法二:智能截图工具
智能截图工具是集成OCR功能的截图软件,它们通常提供一键截图、区域选择、编辑标注等多种功能,并且能够在截图后直接识别并提取其中的文字。这些工具利用内置的OCR引擎,简化了从截图到文本的转换过程。它的优点是便捷高效,集成了编辑功能,并且对用户友好。缺点是其识别精度和格式支持可能有限,并且用户需注意个人数据的安全和隐私保护。

方法三:云服务API
云服务提供商如Google Cloud Vision API、Microsoft Azure OCR等,提供了基于云端的OCR服务。开发者可以通过调用API,将图片上传至云端服务器,由服务商的高级OCR技术进行处理,并返回识别结果。这种方式充分利用了云平台的强大计算能力,支持高并发和大规模数据处理。它的优点是高性能、易集成,还能持续更新。而缺点是它依赖于稳定的网络连接,对于大量或频繁的使用,可能会产生较高的费用。

综合截图文字怎么识别?所述,截图文字识别技术通过OCR、智能截图工具和云服务API等形式,为用户提供了从视觉信息到可编辑文本的高效转化路径。不同的方法各有优势,用户可以根据具体需求选择最合适的技术方案,以实现信息处理的最优化。







![[C++核心编程-07]----C++类和对象之友元应用](https://img-blog.csdnimg.cn/direct/345181c2380d4814b73f8911bd17784d.png)