大模型微调之 在亚马逊AWS上实战LlaMA案例(十)
训练数据集格式
SageMaker JumpStart 目前支持域适应格式和指令调整格式的数据集。在本节中,我们指定两种格式的示例数据集。有关更多详细信息,请参阅附录中的数据集格式化部分。
域适应格式
文本生成 Llama 2 模型可以在任何特定领域的数据集上进行微调。在特定领域的数据集上进行微调后,该模型有望生成特定领域的文本,并通过少量提示解决该特定领域中的各种 NLP 任务。对于此数据集,输入由 CSV、JSON 或 TXT 文件组成。例如,输入数据可能是亚马逊向 SEC 提交的文本文件:
This report includes estimates, projections, statements relating to our
business plans, objectives, and expected operating results that are “forward-
looking statements” within the meaning of the Private Securities Litigation
Reform Act of 1995, Section 27A of the Securities Act of 1933, and Section 21E
of the Securities Exchange Act of 1934. Forward-looking statements may appear
throughout this report, including the following sections: “Business” (Part I,
Item 1 of this Form 10-K), “Risk Factors” (Part I, Item 1A of this Form 10-K),
and “Management’s Discussion and Analysis of Financial Condition and Results
of Operations” (Part II, Item 7 of this Form 10-K). These forward-looking
statements generally are identified by the words “believe,” “project,”
“expect,” “anticipate,” “estimate,” “intend,” “strategy,” “future,”
“opportunity,” “plan,” “may,” “should,” “will,” “would,” “will be,” “will
continue,” “will likely result,” and similar expressions.
指令调整格式
在指令微调中,模型针对使用指令描述的一组自然语言处理(NLP)任务进行微调。这有助于通过零样本提示提高模型针对看不见的任务的性能。在指令调整数据集格式中,您指定template.json描述输入和输出格式的文件。例如,文件中的每一行train.jsonl如下所示:
{"instruction": "What is a dispersive prism?",
"context": "In optics, a dispersive prism is an optical prism that is used to disperse light, that is, to separate light into its spectral components (the colors of the rainbow). Different wavelengths (colors) of light will be deflected by the prism at different angles. This is a result of the prism material's index of refraction varying with wavelength (dispersion). Generally, longer wavelengths (red) undergo a smaller deviation than shorter wavelengths (blue). The dispersion of white light into colors by a prism led Sir Isaac Newton to conclude that white light consisted of a mixture of different colors.",
"response": "A dispersive prism is an optical prism that disperses the light's different wavelengths at different angles. When white light is shined through a dispersive prism it will separate into the different colors of the rainbow."}
附加文件template.json如下所示:
{
"prompt": "Below is an instruction that describes a task, paired with an input that provides further context. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Input:\n{context}\n\n",
"completion": " {response}",
}
支持的训练超参数
Llama 2 微调支持许多超参数,每个超参数都会影响微调模型的内存需求、训练速度和性能:
- epoch – 微调算法通过训练数据集的次数。必须是大于 1 的整数。默认值为 5。
- Learning_rate – 在完成每批训练示例后更新模型权重的速率。必须是大于 0 的正浮点数。默认值为 1e-4。
- instructions_tuned – 是否对模型进行指令训练。必须是“ True”或“ False”。默认为“ False”。
- per_device_train_batch_size – 用于训练的每个 GPU 核心/CPU 的批量大小。必须是正整数。默认值为 4。
- per_device_eval_batch_size – 用于评估的每个 GPU 核心/CPU 的批量大小。必须是正整数。默认值为 1。
- max_train_samples – 出于调试目的或加快训练速度,请将训练示例的数量截断为此值。值-1表示使用所有训练样本。必须是正整数或-1。默认值为-1。
- max_val_samples – 出于调试目的或加快训练速度,请将验证示例的数量截断为此值。值 -1 表示使用所有验证样本。必须是正整数或-1。默认值为-1。
- max_input_length – 标记化后的最大总输入序列长度。超过此长度的序列将被截断。如果为 -1,则max_input_length设置为最小值 1024 和分词器定义的最大模型长度。如果设置为正值,则 max_input_length设置为提供的值和model_max_length分词器定义的最小值。必须是正整数或-1。默认值为-1。
- validation_split_ratio – 如果验证通道为none,则从训练数据中分割训练验证的比率必须在 0–1 之间。默认值为 0.2。
- train_data_split_seed – 如果验证数据不存在,这会将输入训练数据随机分割为算法使用的训练和验证数据。必须是整数。默认值为 0。
- preprocessing_num_workers – 用于预处理的进程数。如果None,则主进程用于预处理。默认为None.
- lora_r – Lora R。必须是正整数。默认值为 8。
- lora_alpha – 必须是正整数。默认值为 32
- lora_dropout – 必须是 0 到 1 之间的正浮点数。默认值为 0.05。
- int8_quantization – 如果True,则模型加载 8 位精度进行训练。 7B 和 13B 的默认值为False。 70B 的默认值为True。
- enable_fsdp – 如果True,训练使用 FSDP。 7B 和 13B 的默认值为True。 70B 的默认值为False。请注意,int8_quantizationFSDP 不支持此功能。
实例类型和兼容的超参数
微调期间的内存要求可能会因以下几个因素而有所不同:
- 型号类型– 7B 型号的 GPU 内存需求最少,70B 的内存需求最大
- 最大输入长度——较高的输入长度值会导致一次处理更多的标记,因此需要更多的 CUDA 内存
- 批处理大小– 较大的批处理大小需要更大的 CUDA 内存,因此需要更大的实例类型
- Int8 量化– 如果使用 Int8 量化,模型会加载到低精度,因此需要更少的 CUDA 内存
为了帮助入门,我们提供了一组可以成功微调的不同实例类型、超参数和模型类型的组合。你可以根据要求和实例类型的可用性选择配置。我们在 Dolly 数据集的子集上使用三个时期的各种设置对所有三个模型进行了摘要示例的微调。
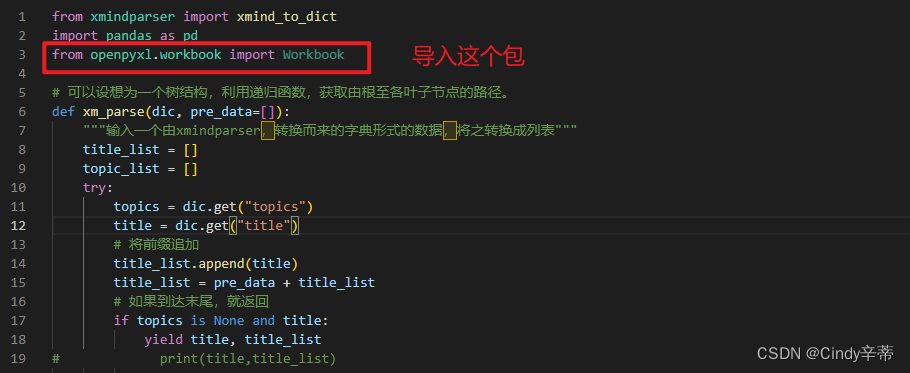
Llama 7B 模型的微调选项
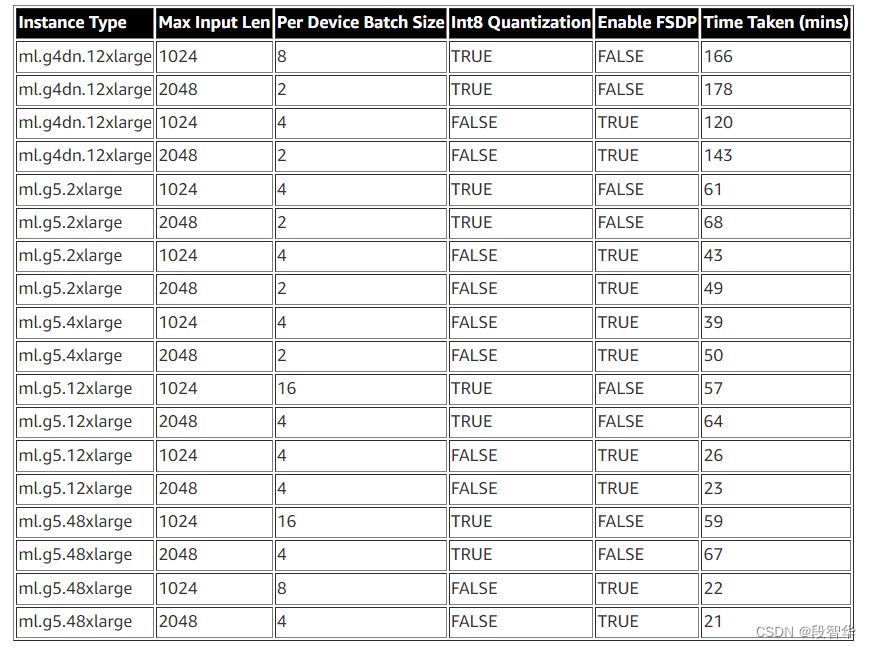
Llama 13B 模型的微调选项
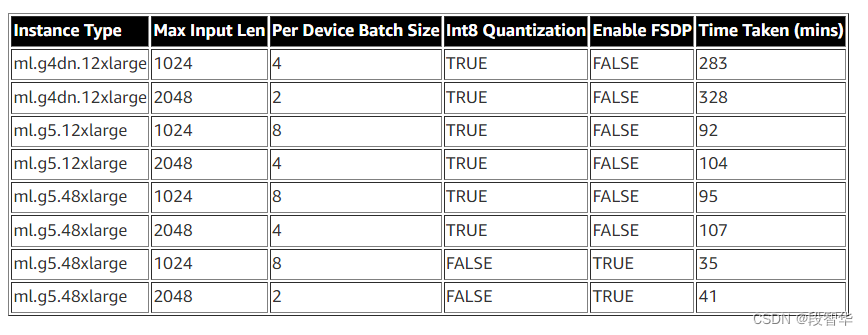
Llama 70B 模型的微调选项

实例类型和超参数建议
微调模型的准确性时,请记住以下几点:
- 70B 等较大型号提供比 7B 更好的性能
- 没有 Int8 量化的性能优于有 INT8 量化的性能
请注意以下训练时间和 CUDA 内存要求:
- 设置int8_quantization=True减少了内存需求并导致更快的训练。
- 减少per_device_train_batch_size并max_input_length减少内存需求,因此可以在较小的实例上运行。但是,设置非常低的值可能会增加训练时间。
- 如果您不使用 Int8 量化 ( int8_quantization=False),请使用 FSDP ( enable_fsdp=True) 进行更快、更高效的训练。
选择实例类型时,请考虑以下因素:
- G5 实例提供支持的实例类型中最高效的训练。因此,如果您有可用的 G5 实例,则应该使用它们。
- 训练时间很大程度上取决于 GPU 数量和可用 CUDA 内存。因此,在具有相同 GPU 数量的实例(例如 ml.g5.2xlarge 和 ml.g5.4xlarge)上进行训练大致相同。因此, 可以使用更便宜的实例进行训练(ml.g5.2xlarge)。
- 使用 p3 实例时,将以 32 位精度进行训练,因为这些实例不支持 bfloat16。因此,与 g5 实例相比,在 p3 实例上训练时,训练作业将消耗双倍的 CUDA 内存。
- 要了解每个实例的训练成本,请参阅Amazon EC2 G5 实例。
如果数据集采用指令调优格式,并且输入+完成序列很小(例如 50-100 个单词),那么高值max_input_length会导致性能非常差。该参数的默认值为-1,对应于max_input_lengthLlama模型的2048。因此,我们建议如果您的数据集包含小样本,请使用较小的值max_input_length(例如 200–400)。
由于 G5 实例的高需求,您所在区域中的这些实例可能不可用,并出现错误。“CapacityError: Unable to provision requested ML compute capacity. Please retry using a different ML instance type.”如果您遇到此错误,请重试训练作业或尝试其他区域。
微调非常大的模型时出现的问题
- 禁用输出压缩
默认情况下,训练作业的输出是经过训练的模型,在上传到 Amazon S3 之前以 .tar.gz 格式压缩。但是,由于模型尺寸较大,此步骤可能需要很长时间。例如,压缩并上传70B模型可能需要4个多小时。为了避免此问题,您可以使用 SageMaker 训练平台支持的禁用输出压缩功能。在这种情况下,模型上传时不进行任何压缩,并进一步用于部署:
estimator = JumpStartEstimator(
model_id=model_id, environment={"accept_eula": "true"}, disable_output_compression=True
)
- SageMaker Studio 内核超时问题
由于 Llama 70B 模型的大小,训练工作可能需要几个小时,并且 SageMaker Studio 内核可能会在训练阶段挂掉。然而,在此期间,训练仍在 SageMaker 中运行。如果发生这种情况,您仍然可以使用训练作业名称和以下代码来部署端点:
from sagemaker.jumpstart.estimator import JumpStartEstimator
training_job_name = <<<INSERT_TRAINING_JOB_NAME>>>
attached_estimator = JumpStartEstimator.attach(training_job_name, model_id)
attached_estimator.logs()
attached_estimator.deploy()
要查找训练作业名称,请导航到 SageMaker 控制台,然后在导航窗格中的Training下,选择Training jobs。确定训练作业名称并将其替换为前面的代码。
https://aws.amazon.com/blogs/machine-learning/fine-tune-llama-2-for-text-generation-on-amazon-sagemaker-jumpstart/

大模型技术分享



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。


举办《Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战》线上高级研修讲座













![[C++核心编程-07]----C++类和对象之友元应用](https://img-blog.csdnimg.cn/direct/345181c2380d4814b73f8911bd17784d.png)







![P8803 [蓝桥杯 2022 国 B] 费用报销](https://img-blog.csdnimg.cn/direct/34735bd34483409680b598639616ab7d.png)