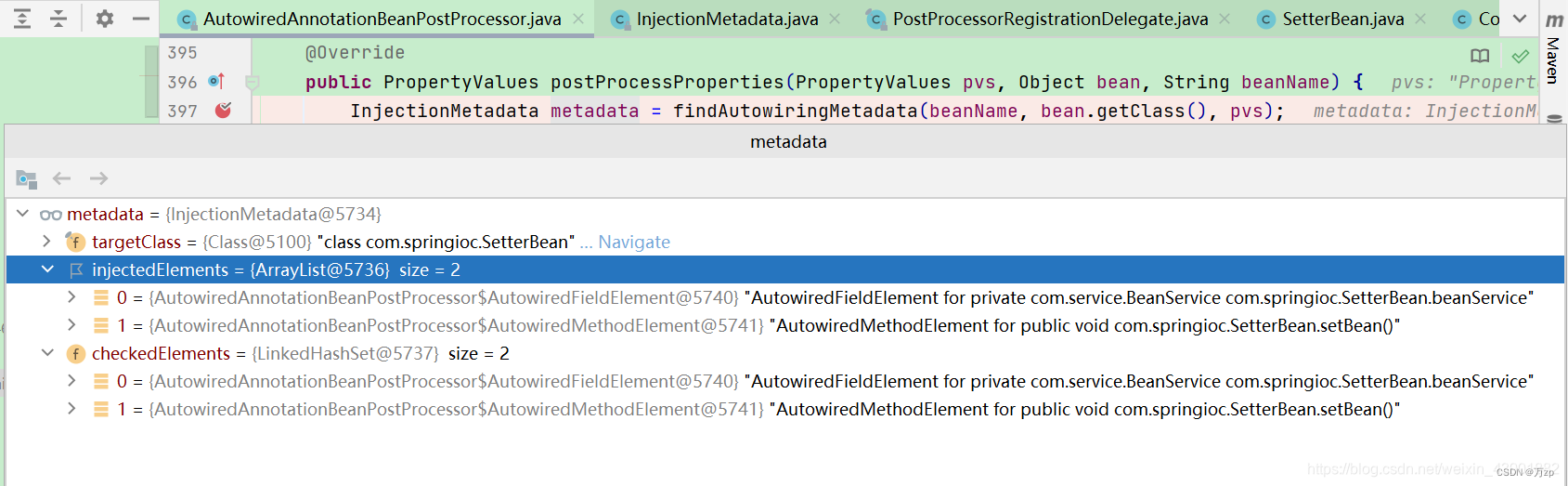
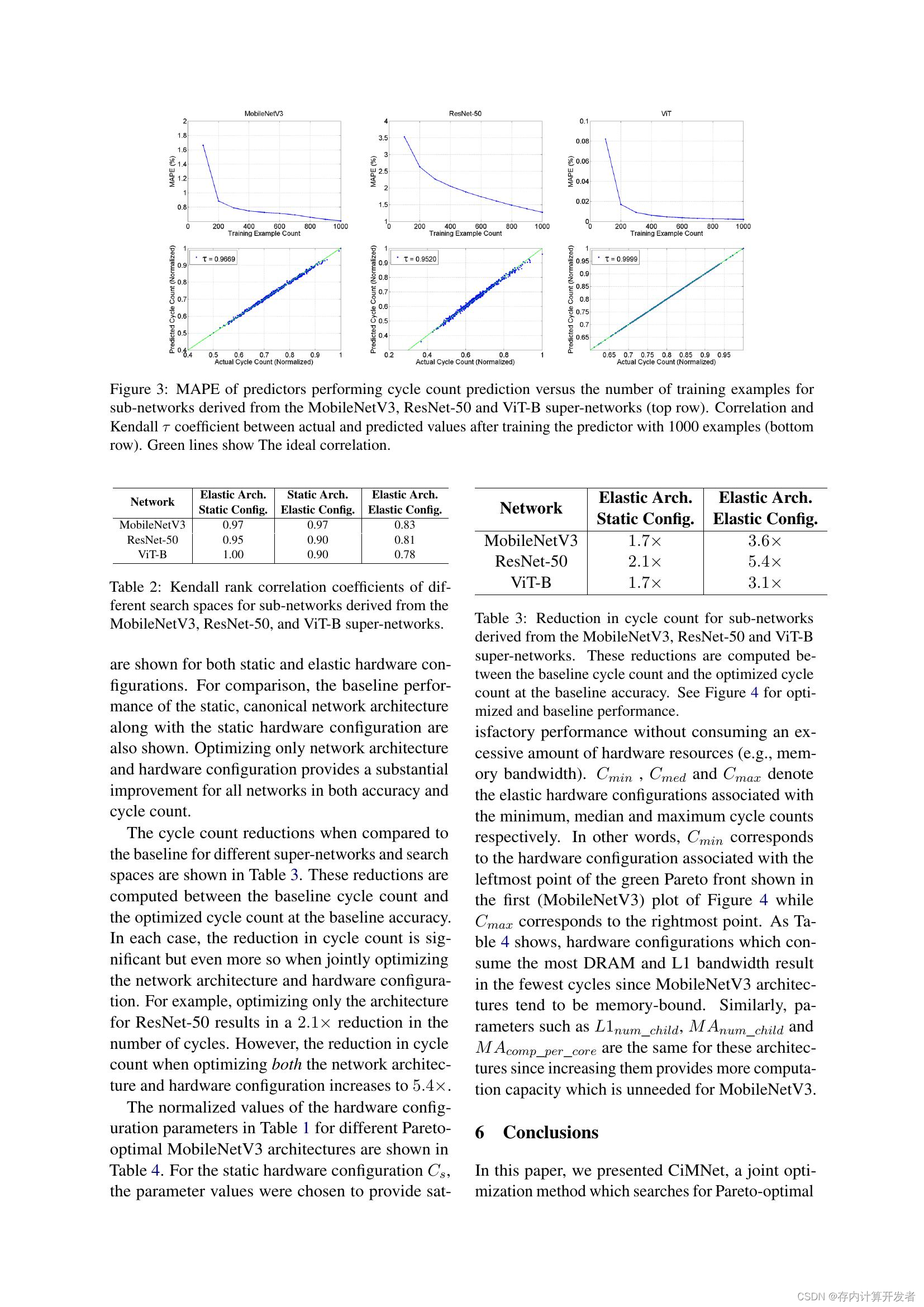
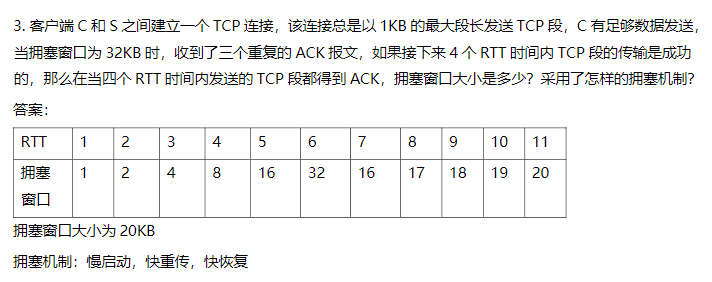
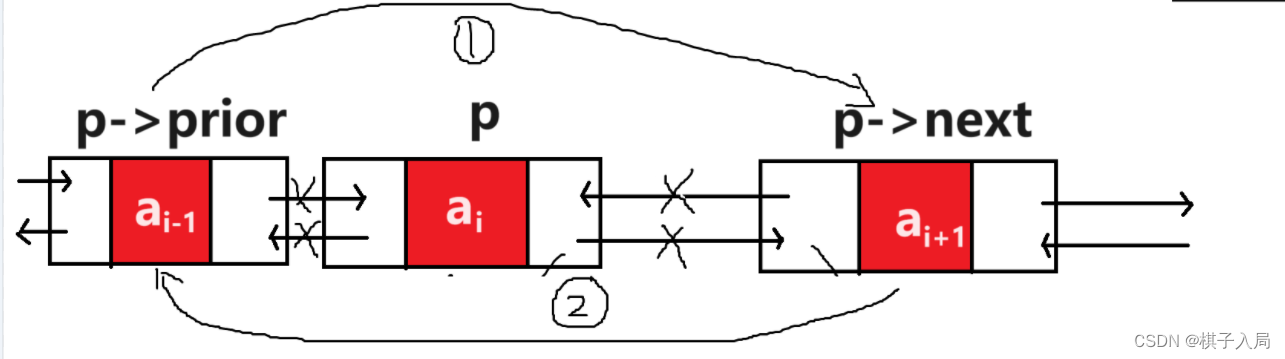
此文作为学习stl的笔记,许多普及、概念性的知识点将不再罗列(如stl的发展、背景等)
便于读者作为复习等方法了解。
0.STL简介(笔记向)
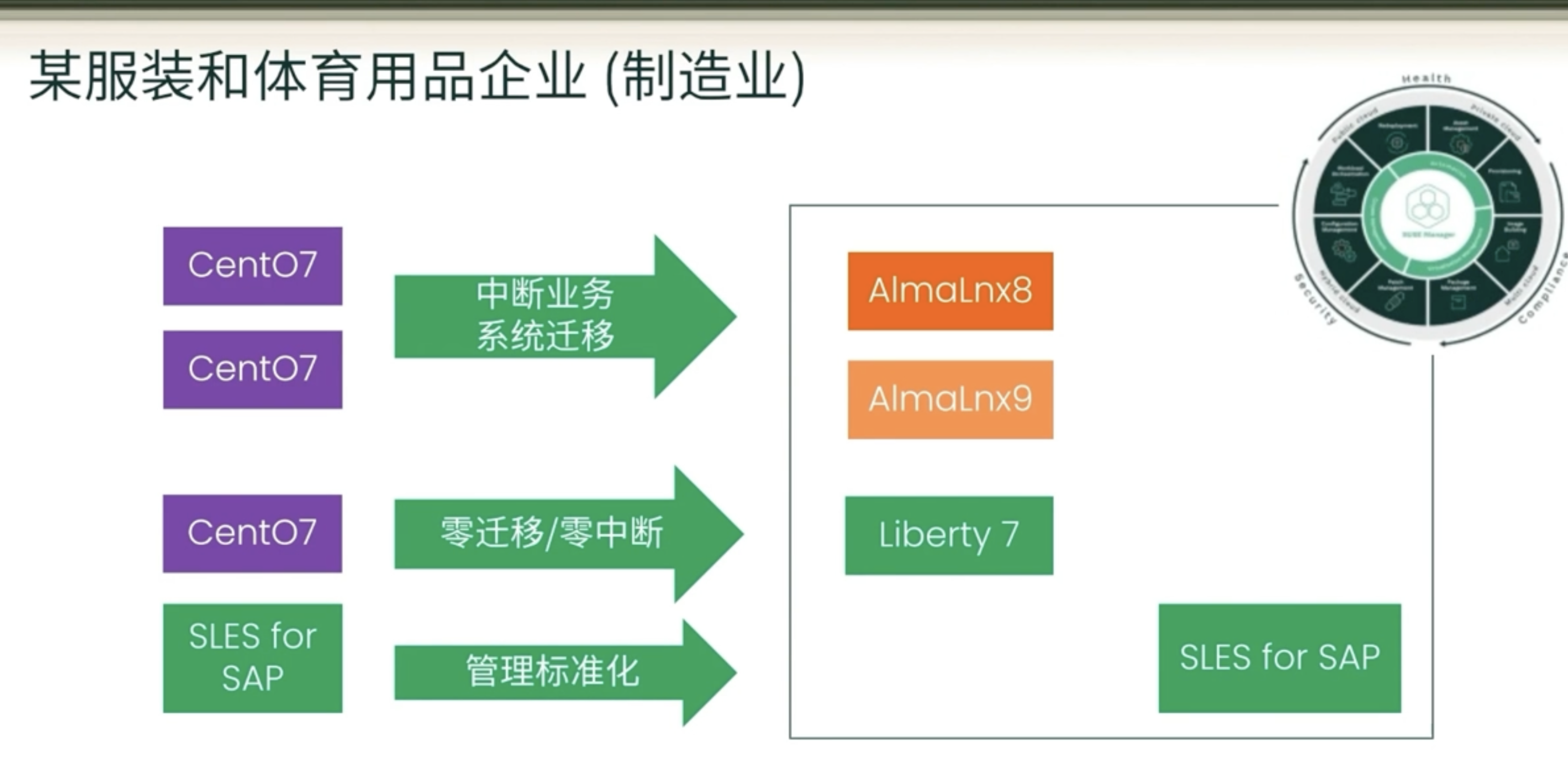
STL不是祖师爷本贾尼实现的,是在惠普实验室中实现的。其作为一个数据结构与算法的库(主要是数据结构),现在有很多商业公司开发的目的,有的开源有的收费,目前使用最多的是(也是我们使用的)继承自HP版本的SGI版本。
学习STL有三重境界:能用、明理、能扩展(如自己扩展B树等)
此篇我们介绍string的运用。
目录
0.STL简介(笔记向)
1.string
2.string的构造函数(constructor,重点是"abcde"会被当作const char*)
3.string的运算符重载[ ](两种重载,带const和不带const)
4.string的遍历
5.string在VS编译器下的大小(了解)
6.将string按照字典序排序
7.string的插入和修改
7.1 push_back 和 append
7.2更常用的添加方法:运算符重载 +=
7.3 assign函数
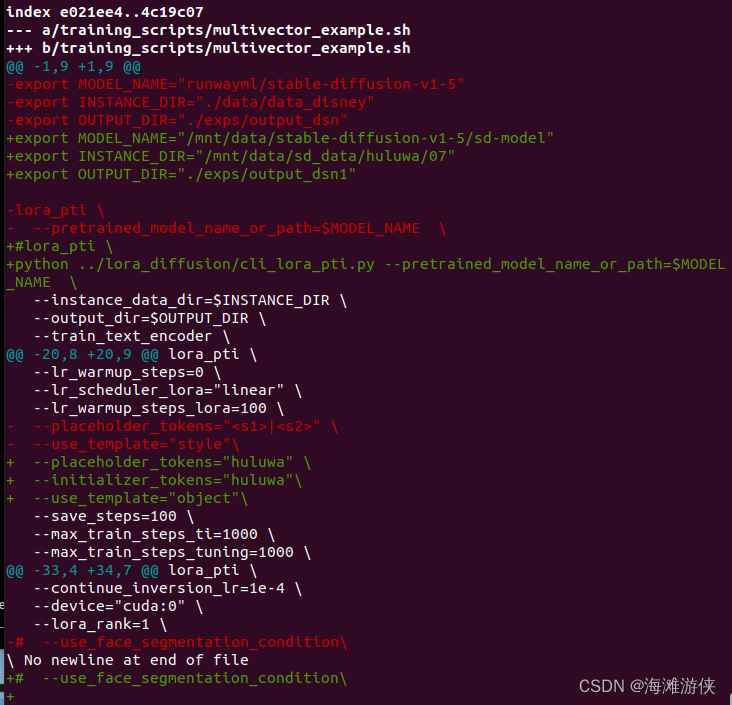
7.4 重点: insert 与 erase
7.5 replace替换函数 (注意两个迭代器传参时的左闭右开)
8.小试牛刀
9.capacity大类
编辑 9.1 max_size(了解)
9.2clear
9.3扩容
9.4 resize和reserve ★★
9.5 shrink_to_fit
9.6 at
9.7 c_str
10.find
11. string相关的部分外部函数
12.编码表UNICODE
1.string
string,也就是常说的数据结构“串”。string出现的比stl早,所以有一些功能较冗杂
C 语言中,字符串是以 '\0' 结尾的一些字符的集合,为了操作方便, C 标准库中提供了一些 str 系列的库函数, 但是这些库函数与字符串是分离开的,不太符合OOP(面向对象编程) 的思想,而且底层空间需要用户自己管理,稍不留神可 能还会越界访问。比如 strcpy和strcat,你需要自己管理空间大小、是否有/0、操作的方法。。。。非常麻烦。许多都需要使用string存储,如身份证号码(数据很大,用int存储很不划算,并且还有可能带X)
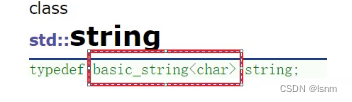
string也叫basic_string,并且被默认为管理char类型数据的容器。
还可以管理wchar:

wchar是一种 双字节 字符
在大多数情况下,我们可以认为string就是一个char类型的数组、顺序表。
string - C++ Reference (cplusplus.com)
string一共一百二十个左右的成员函数,其实很多函数是冗余的。
2.string的构造函数(constructor,重点是"abcde"会被当作const char*)
我们要学会通过文献来使用函数

掌握默认构造、拷贝构造、带参构造、其他的会查网站看明白即可。
第一个是默认构造,第二个是我们最常用的常量区赋值:
string s="abcdefg";如果我们定义一个空字符串 string str1; 那么str1中是包含了\0的
默认构造出的s2中间不是乱码,而是什么都没有。
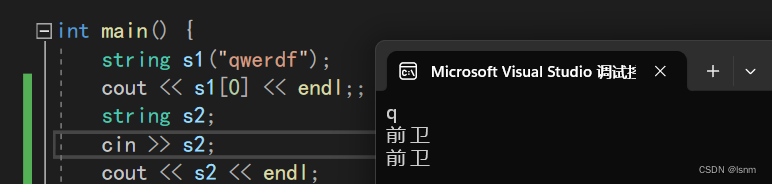
s可以直接被cout输出,也可以通过cin直接获得内容。甚至可以使用中文。
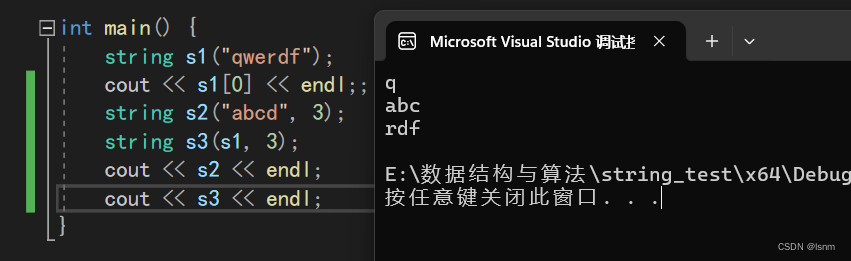
第三种初始化substring是按照使用者主观定制长度拷贝,第一个参数是数组名(字符串名字),第二个是开始拷贝的位置(包括该位置,数据结构喜欢左闭右开),第三个是拷贝的长度。长度的默认参数是npos
成员变量npos:

注意:npos是无符号整形size_t,所以npos其实是四十二亿左右。当然,一个string没有那么长。

(其中str is too short的意思是相对于我传的参数len,str可以被拷贝的内容太短了)

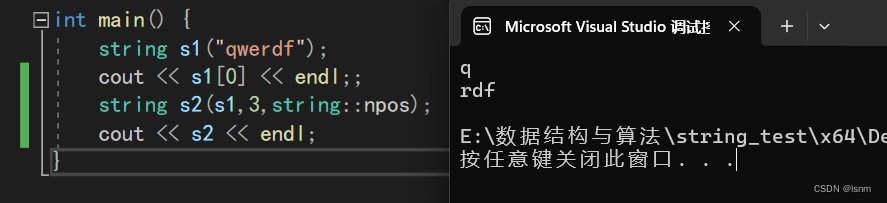
(不传参或者写npos就相当于直接拷贝到末尾,都属于str is too short)
同样的,学会通过英文来了解含义:


常量字符串被认为是const char*,调用的是第五个构造:
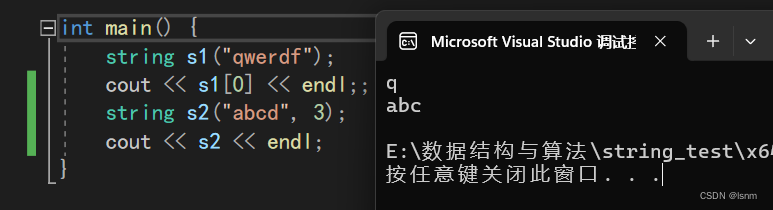
这种直接常量字符串接数字表示前三个字符,如果是一个string接数字表示从第数字个位置开始,省略了一个要打印个数的参数。
如下,单参数构造函数的隐式类型转换:const char* 转化成string,中间会生成一个临时变量string(构造),再加上一个拷贝构造(有时候直接优化成一次构造)

因此对于引用:

string s4 = "abcdw";//涉及隐式类型转换,"abcdw"被当作char*3.string的运算符重载[ ](两种重载,带const和不带const)
size和length在此处是相同的作用,length是一开始被设计的,size是在之后stl设计时从整体角度考虑的,便于和其他stl统一。
size和length都不会计算'\0'
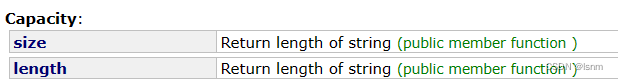


使用较少的调用方法:
![]()
这样,我们的自定义类型就能像数组一样使用。
作为自定义、尤其是一些需要深拷贝的类型,我们可以传引用返回来减少拷贝次数以提升效率,那么此处的运算符重载[ ]为什么也要使用传引用返回?拷贝几个字节很费劲吗?
我们先只看第一排的重载:
!!! 传引用返回的第二大作用得以体现:可修改容器中的返回值:

string底层开的空间在堆上。
并且由于string的底层的越界检查很多都是使用assert,所以错误都能检查出来。
那么。面对不希望被修改的字符串,如下图的被const修饰的常量字符串(string底层开的空间在堆上)
我们再观察之前的声明,[ ]有两种运算符重载,相互构成函数重载:第一种的参数不含const,也就是刚刚提到的展示引用返回作用的重载;还有一种是参数带const的,那么我们对返回值也进行const的修饰,使常量字符串不得被修改。

再加上匹配机制(优先匹配最合适的),为了让不能被修改的就一直不被修改,可以修改的就可以修改,所以我们需要实现两个重载。(只使用带const的重载也可以调用非常量字符串,但是这样的话非常量字符串也不能修改, 不太方便。但是大部分函数用const修饰是只有好处没有坏处的,这样的观念我们在前文提到过)
所以,到底提供几个const,需要在实战中按照实际需要来确定。
4.string的遍历
根据刚才的size功能和运算符重载,我们可以通过循环实现数组的遍历。
for (size_t i = 0; i < s4.size(); i++) {
cout << s4[i] << " ";
}C++还有一种方法遍历:迭代器 iterator。
首先,iterator是定义在类域中的,必须在string域中使用。
string::iterator it1 = s4.begin(); while (it1 != s4.end()) { cout << *it1 << " "; it1++; }那什么又是begin和end呢?
最重要的概念:所有容器的begin和end都满足左闭右开
begin()返回首字符“指针”,end()返回最后一个有效字符的下一个的“地址”
迭代器就可以看做是类似指针的东西。但是其本质不一定是指针。
我们可以利用typeid来看一下其类型,非常奇怪。
(typeid还可以将被typedef的类型的原名称给显式出来)
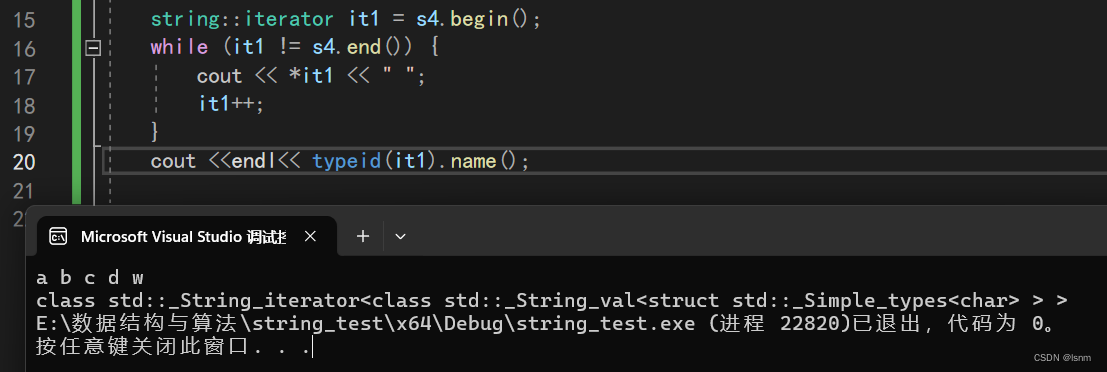

it1被当作指针一样,想访问其对应的内容就直接解引用。
就对于string而言, 直接使用[ ]下标访问 更方便,但是对于大部分数据结构,iterator更加主流。
上文中的begin和end的用法也都符合所有的容器。
利用范围for遍历(C++11才支持):
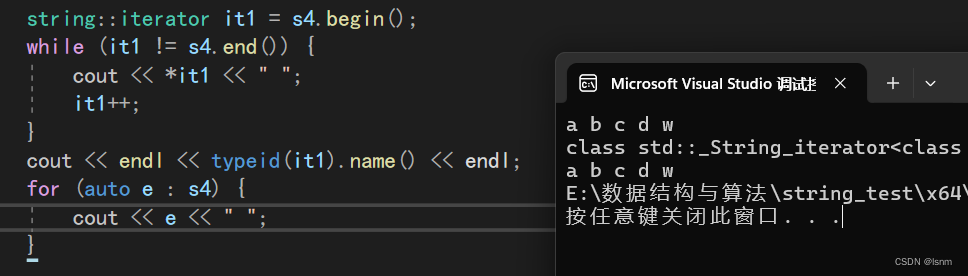
e是赋值拷贝,对e++或者--等操作不会实际影响s4中的字符大小。
但是范围for的自动循环在编译时其实和迭代器的底层是几乎一样的,所以对于容器的学习主要掌握迭代器版本。
5.begin等函数的重载

const string s1("abcdefg");由匹配规则我们知道,当s1被const修饰时,如果再调用begin,会调用下面那个重载。
(定义s1使用的const对应的是const_iterator begin() const中后面的那个const,有const修饰和没const修饰的被认为是两种参数类型)
然后返回一个const类型的iterator,这样返回的iterator就是只读的。
细心的读者可能已经发现了,为什么不是const iterator,而是const_iterator?
const限定的是迭代器所指向的内容,迭代器指向的内容不能修改不代表迭代器本身不能修改。
如果迭代器本身都被限制,得到的迭代器甚至不能++,无法遍历。
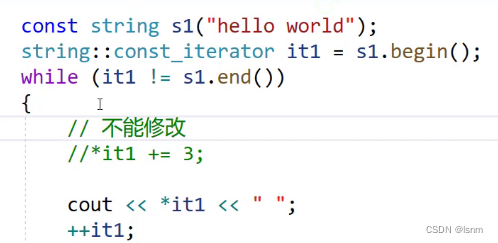
此处的差距就可以类比于指针的const的不同的修饰:
string :: const_iterator

const string :: iterator(这种我们一般不使用),更多使用string :: iterator和string :: const_iterator
还可以通过auto来减少输入量。

除了iterator和const_iterator,还有反向迭代器(用得不多):
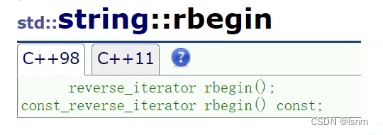

此时对反向迭代器++就是向左走,--就是向右走。他同样有两种:带const的和不带const的。带const的同样不能通过迭代器修改迭代器所指向的参数。
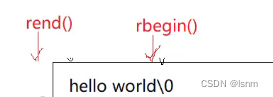
因为可以用方括号遍历的缘故,string其实很少这样遍历。直接循环即可。
string::reverse_iterator re_it2= s2.rbegin();
while (re_it2 != s2.rend()) {
cout << *re_it2 << " ";
re_it2++;
}一共四种迭代器,在之后的容器中都是同样的作用。
5.string在VS编译器下的大小(了解)

第一点,不同的编译器的计算出的大小是不一样的,此处只针对vs2019进行学习:
string是一个字符串数组,按理来说其由 _str _size _capacity三部分组成,在x86也就是32位环境下,应该是一个指针 两个int,一共是12。但是其实string中还有一个大小为16的buffer数组,当字符串数量小于16时,直接存在string内,不存在堆中,因此大小为28
6.将string按照字典序排序
首先明确,字典序就是ASCII的顺序。
其次,此处我们需要引入一个新的头文件<algorithm>,并利用其中的算法:sort
sort是一个函数模板,他不是属于容器string的类函数。sort函数的参数是各种类型的迭代器。
原文介绍如下:
Sort elements in range
Sorts the elements in the range
[first,last)into ascending order.
The elements are compared usingoperator<for the first version, and comp for the second.
Equivalent elements are not guaranteed to keep their original relative order stable_sort可以直接排序vector等,不过链表暂时不能直接排序。
底层是快速排序,不具有稳定性。

传参时,任然要遵守左闭右开:
如果要全部排列,直接使用迭代器的begin和end
如果只排前n个,则直接让begin+n即可,因为类似于数组,begin返回的是0位置。
(由于0的存才si,begin()+5其实指的是第六个字符)
7.string的插入和修改
7.1 push_back 和 append
首先介绍老朋友:push_back


插入常量字符串使用append
插入常量字符(只插入一个字符)使用push_back

append有多种重载,风格非常类似构造函数。
因此,还需要再注意常量字符串是const char*的问题。
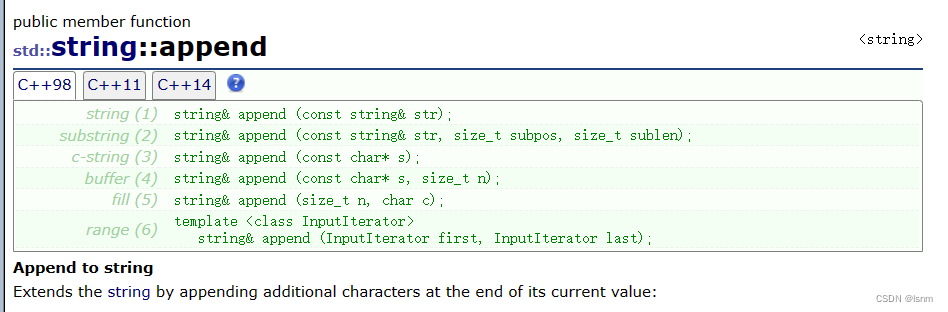
可以从指定的位置加入指定数量的字符、全部用某个字符去“覆盖式加入”、使用迭代器区间去添加。
如从指定位置开始的指定个数(注意一定使用string类型变量,不要用常量字符串等const char*类型变量):
 同样可能用到npos,在无符号整形中这就是最大的数据。
同样可能用到npos,在无符号整形中这就是最大的数据。
7.2更常用的添加方法:运算符重载 +=
对于运算符+=的运算符重载:

更加形象,更易理解。
而且+=后面既可以是单个字符,也可以是字符串。
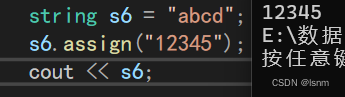
7.3 assign函数
其本质是一种赋值,会先清空本来有的内容
![]()
则s1中原先的内容会被改为111111。
7.4 重点: insert 与 erase
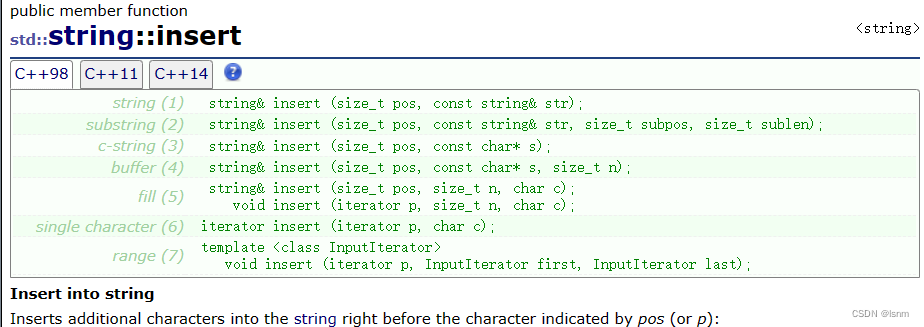
insert的第一个参数都是与位置相关的,下标或者迭代器。

但是insert能少用就少用,因为其时间复杂度是O(n),每次插入都需要把被插入位置之后的所有元素平移。
但是不支持只在某个位置只插入一个字符:
这样是不可以的:
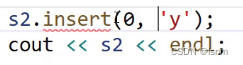
这样是可以的:

但是给y加上一个双引号呢?(应该是没问题的)但是必须有支持单个字符的情况,否则无法应对诸多情况(如字符作为变量):

毕竟字符串不可能完全替代字符的插入。
如下,4的意思是在第四个字符的位置插入(包括0),会将位置4之后的元素都平移。

频繁使用平移插入时需要注意效率。
此处只实现第三种(对应的是方法7)就好,也就是通过迭代器加入对应的区间中的字符串。 

不过还是那句话,insert的时间复杂度不低,慎用。
erase同样时间复杂度为O(n),也要慎用。
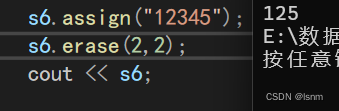
关于erase,共有三种用法,一种是关于下标的,从pos位置删len个。还有两种是迭代器版本的。

我们观察第一个重载,默认是从0位置开始,删除size_t类npos个数据(很多个),也就是如果什么都不传就会全部删完。 同理,如果还是"is too short",依然是有多少删多少。
长度超了就自动删完,但是下标超了或者迭代器超了,就会报错。下标和迭代器必须合法!
7.5 replace替换函数 (注意两个迭代器传参时的左闭右开)

将第五个位置开始的一个元素换成后面的内容(此处为const char*)
对于迭代器版本:i1和i2依然指的是一个左闭右开的空间。
针对是char* 还是string&的问题 ,之前的解释都没有错,但是只实现一个string版本的就可以了,因为string类型可以用char* 去自动构造,只是在char*和string都存在时,会使用更匹配的那个。
之前的构造函数中需要注意两种参数的不一样是因为 char*作为参数和string作为参数的功能是不一样的(前者表示前n个,后者表示从下标为n的位置开始的)。这次是一样的,所以只用实现一个。
但是隐式类型转换又会一定程度上较低效率,而c++就是以效率著称的语言.......
比如我们想实现一个功能,将给出的string 类型的s中的所有空格都替换为%20:
string& DeleteSpace(string& s) {
for (auto it = s.begin(); it != s.end();) {
if (*it == ' ') {
s.replace(it, it+1, "%20");
it += 3;
}
else {
++it;
}
}
return s;
}如果写成s.replace(it,it,"%20"),就会不停的在第一个空格处加上%20。左闭右开的目的就是从 左边的闭区间开始替换,但是不替换右边开区间那个位置,因此会不停的替换直到溢出。
使用迭代器时(尤其是两个迭代器)都要注意左闭右开的问题。
(replace处也可以直接使用下标版本)
但是这样效率并不高,
除非替换的内容相互一样长(将三个元素换成另外三个元素)。
否则每次都涉及平移后面的全部内容。
可以用空间换时间的做法:
string QuickDeleteSpace(string& s) {
string ret;
for (auto ch : s) {
if (ch != ' ') {
ret += ch;
}else{
ret += "%20";
}
}
return ret;
}但是此处的ret是临时变量,不能再返回引用,而应该传值返回。
8.小试牛刀
917. 仅仅反转字母 - 力扣(LeetCode)
class Solution {
public:
bool IsLetter(char c){
return ('a'<=c&&'z'>=c)||
('A'<=c&&'Z'>=c);
}
string reverseOnlyLetters(string s) {
size_t left=0,right=s.size()-1;
while(left<right){
//让左右两个下标都找到是字母的位置。
while(!IsLetter(s[left])&&left<right)
left++;
while(!IsLetter(s[right])&&left<right)
right--;
swap(s[left],s[right]);
left++;
right--;
}
return s;
}
};类似于快排中每一次单趟的方法。
387. 字符串中的第一个唯一字符 - 力扣(LeetCode)
利用计数统计,建立哈希映射,两次遍历。
new的开辟是利用了初始化的int数组值都为0
初始化的char数组值都为'\0'
class Solution {
public:
int firstUniqChar(string s) {
int* arr=new int[26]{0};
for(auto e : s){
arr[e-'a']++;
}
for(int i=0;i<s.size();i++){
if(arr[s[i]-'a']==1){
delete[] arr;
return i;
}
}
delete[] arr;
return -1;
}
};在vs中,作为内置类型char的数组,delete delete[] free都可以用于释放new出来的数组,但是在leetcode中只能使用delete[]
125. 验证回文串 - 力扣(LeetCode)
125. 验证回文串 - 力扣(LeetCode)
回文判断都是头尾指针。
此题最大的坑在于:‘0’+32是P,所以直接用32加减的方法不妥。需要加上判断语句。
class Solution {
public:
bool IsLetterOrNumber(char& ch){
if(ch>='A' && ch<='Z'){
ch+=32;
return true;
}
return (ch>='a' && ch<='z')||(ch>='0'&&ch<='9');
}
bool isPalindrome(string s) {
int left=0,right=s.size()-1;
while(left<right){
while(left<right && !IsLetterOrNumber(s[left]))
left++;
while(left<right && !IsLetterOrNumber(s[right]))
right--;
if(s[left]!=s[right]){
return false;
}
left++,right--;
}
return true;
}
};难点:大数运算之字符串加减:
415. 字符串相加 - 力扣(LeetCode)
class Solution {
public:
string addStrings(string num1, string num2) {
int pcur1=num1.size()-1;
int pcur2=num2.size()-1;
string ans;
ans.reserve(max(num1.size(),num2.size()));
int next=0;
while(pcur1>=0||pcur2>=0){
int x1= pcur1 >= 0 ? num1[pcur1]-'0' : 0;
int x2= pcur2 >= 0 ? num2[pcur2]-'0' : 0;
next=x1+x2+next;
ans.insert(0,1,next%10+'0');
next/=10;
--pcur1,--pcur2;
}
if(next){
ans.insert(0,1,'1');
}
return ans;
}
};此处的reverse是用来先调整capacity大小,目的是提升效率,不加这一句也能跑过。但是不能乱使用resize。如果胡乱加大了size空间,ans串中可能有其他意想不到的值
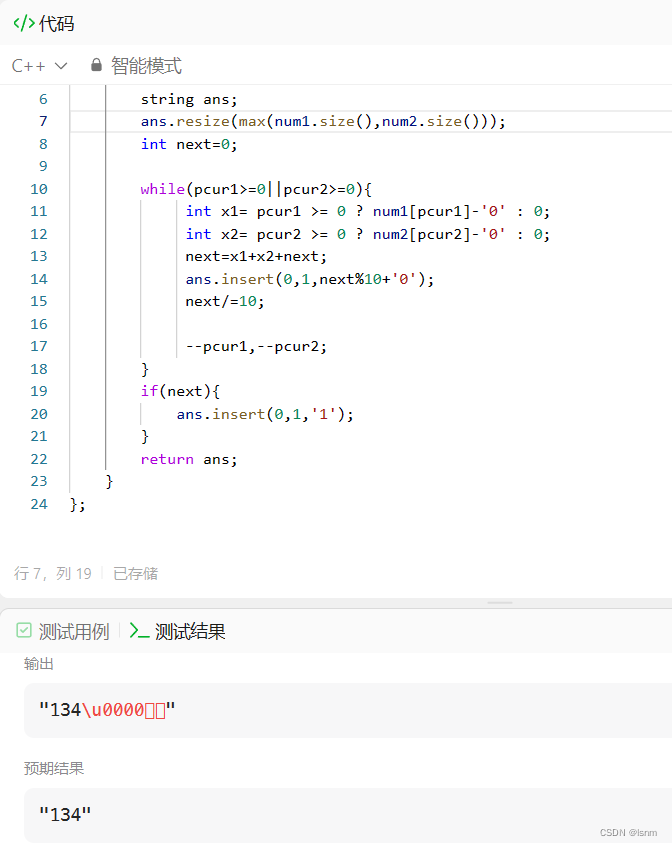
我们进一步优化我们的算法,计算此时的时间复杂度:
算时间复杂度时需要联系每个接口来计算,此处消耗最大的就是每一次的insert(不想使用第二个参数也可以使用iterator版本)。如此处的头插复杂度就是n^2.
所以可以使用尾差加逆置(使用algorithm中的reverse,使用方法直接查cpp官网)的方法,复杂度就是O(n)
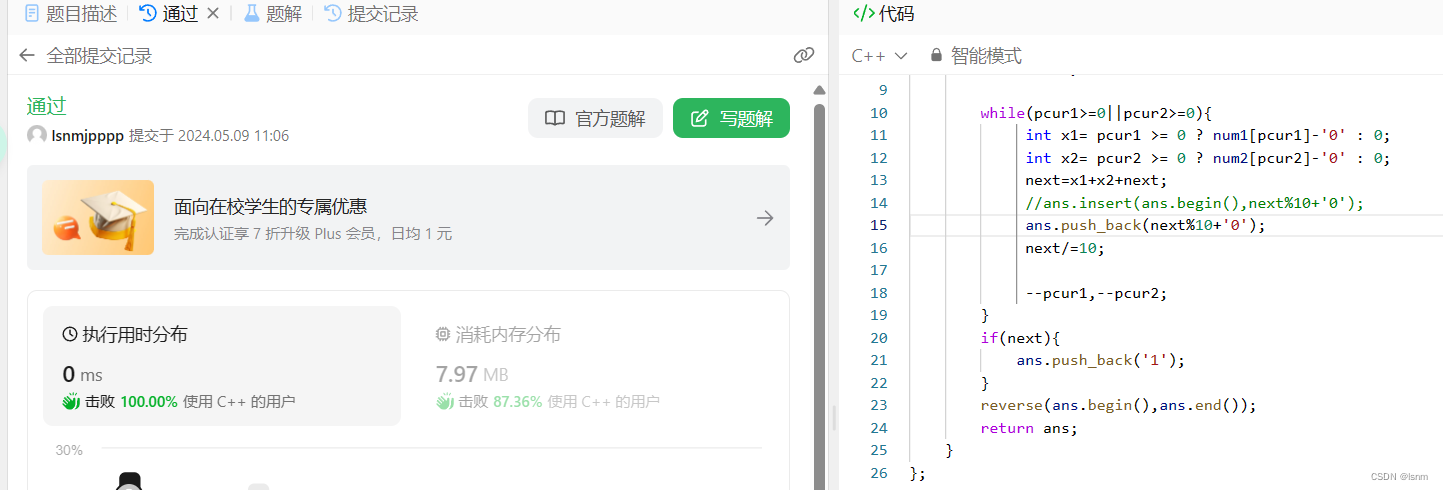
class Solution {
public:
string addStrings(string num1, string num2) {
int pcur1=num1.size()-1;
int pcur2=num2.size()-1;
string ans;
ans.reserve(max(num1.size(),num2.size()));
int next=0;
while(pcur1>=0||pcur2>=0){
int x1= pcur1 >= 0 ? num1[pcur1]-'0' : 0;
int x2= pcur2 >= 0 ? num2[pcur2]-'0' : 0;
next=x1+x2+next;
//ans.insert(ans.begin(),next%10+'0');
ans.push_back(next%10+'0');
next/=10;
--pcur1,--pcur2;
}
if(next){
ans.push_back('1');
}
reverse(ans.begin(),ans.end());
return ans;
}
};9.capacity大类
capacity表示当前string实际开出的空间大小,这一点有别于size,size表示的是此时已有字符串所占用空间的大小。
 9.1 max_size(了解)
9.1 max_size(了解)
max_size没什么用,目的就是告诉你理论上最多能开出多大的空间。

实际上是不可能开出这么大空间的(这已经是九百万TB了)
9.2clear
就是全部清空,类似于不传参的erase

9.3扩容
在vs上,因为buffer数组的存在:
第一次严格意义不算扩容,因为刚开始都是存在buffer数组上的。
第一次change之后就开始在堆上存放数据了。
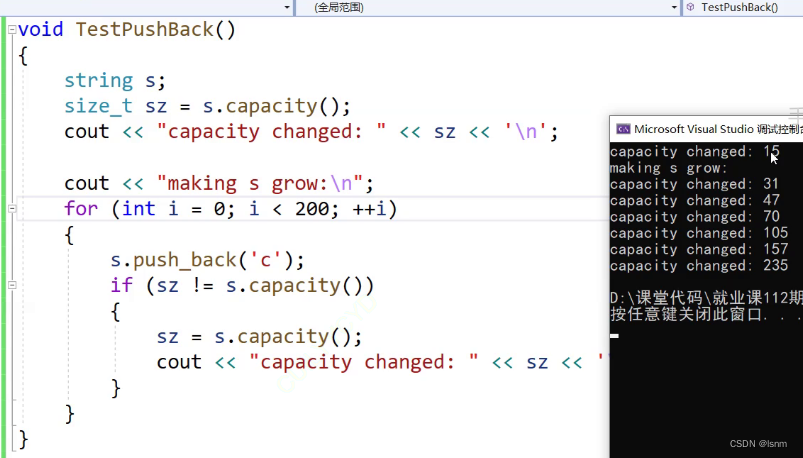
void TestOfCapacity(string& s) {
size_t sz = s.capacity();
cout << "the primary size :" << sz << endl;
for (int i = 200; i >= 0; i--) {
s.push_back('p');
if (sz != s.capacity()) {
sz = s.capacity();
cout << "now the size of capacity is : " << sz << endl;
}
}
}capacity显式出来的比实际的capacity的空间少一个,会预留一个给\0
在vs2019中:刚开始是二倍扩容,后面是接近一点五倍扩容
在linux中:
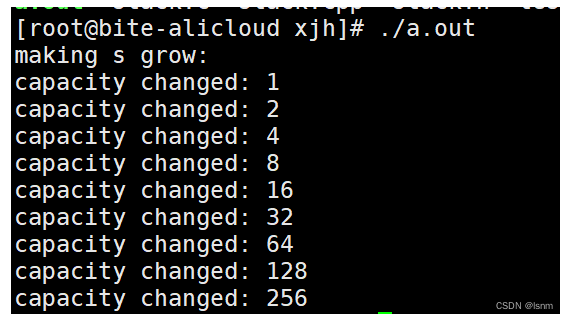
明显没有buffer数组 ,并且每次都是2倍扩容。
g++编译器更加直观,vs的编译器封装更加全面,有其自己的想法。
不过无论g++还是vs,capacity都没有计算斜杠零。
9.4 resize和reserve ★★
reserve(保留,意为保留一定量的空间,区分于逆置reverse)和resize,分别用来管理capacity和size

但是两者的影响范围又稍有不同:
reserve只影响capacity,resize主要目标是影响size,但是因为影响了size所以也会影响capacity。
reserve:
在vs中:
你需要n个空间,他可能开的比n多。

对于reserve缩容,不同的平台有不同的实现(所以不建议使用)。
 并且vs中的string有一个buffer数组,所以再怎么变都不会小于15 (真实大小是16,还有一个位置留给\0)
并且vs中的string有一个buffer数组,所以再怎么变都不会小于15 (真实大小是16,还有一个位置留给\0)
reserve的真正作用是在知道大致需要多少空间时,节省扩容的动作:

提升了效率。
不过依然有一个问题:
这样操作会越界,编译器会报错。
operator []只能访问size以内的部分,而reserve不会改变size,所以超过size的部分依然不能被使用。因此在reserve之后是不能实现从尾部开始使用的,任然只能使用原size以内的部分。

resize:
如果不给值,默认值就是ASCII值为0的‘\0’


在已有空间上使用resize并且初始化内容:
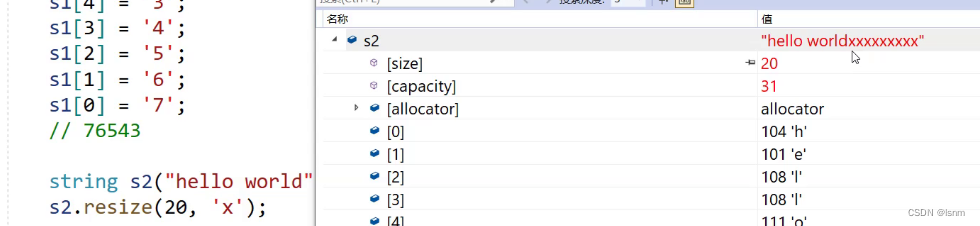
不会改变原空间内容,但是会同时对capacity和size造成影响。
练一练:
//下面程序的输出结果是:
int main()
{
string str("Hello Bit.");
str.reserve(111);
str.resize(5);
str.reserve(50);
cout<<str.size()<<":"<<str.capacity()<<endl;
return 0;
}在vs2022中,最后输出的结果是 5 :11
分析:
str.reserve(111); //调整容量为 111
str.resize(5); //调整元素个数为 5
str.reserve(50); //调整容量为 50,由于调整的容量小于已有空间容量,故容量不会减小
所以size=5 capacity=111
9.5 shrink_to_fit
该函数是专门用来缩空间的。

但是空间在底层是不能分段释放的。
所以其本质是开一个更小的空间,把已有内容拷贝过去。本质是时间换空间的做法,代价较大。
//调用方法:
str.shrink_to_fit();9.6 at
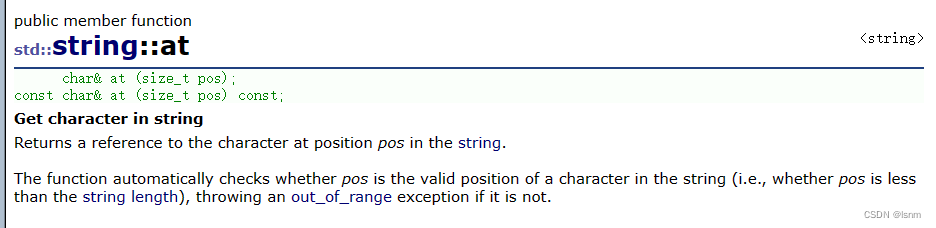 功能与重载的[]类似,区别在于检查方面:[ ]用assert检查,会直接报错,而at可以在抛异常时捕获。
功能与重载的[]类似,区别在于检查方面:[ ]用assert检查,会直接报错,而at可以在抛异常时捕获。
但是只有下标版本,没有迭代器版本。
9.7 c_str
string是可以由char*作为参数来构造的,但是char* 不能通过string来构造。
作用是将string转换到c语言中的标准字符串。
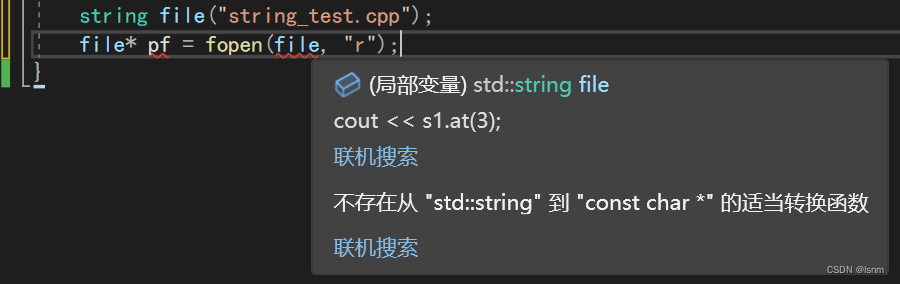

目的是与只能编C的接口兼容,如fopen不能使用str,只能使用char* , 此时就能发挥c_str的作用。
string file("string_test.cpp");
FILE* pf = fopen(file.c_str(), "r");注意,c_str返回的类型是const char* 所以对于下题:
string a="hello world";
string b=a;
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;a和b的内容虽然一样,但是存放的地址不一样,所以应该输出false。
10.find

由缺省参数为0可知,find函数默认都是从头开始找。给了数字之后就可以从数字对应的位置开始找。
可以找单个字符也可以找一个句子。
若想从尾部开始找,可使用refind。
比如我们想取出一个后缀名suffix:

此时又涉及一个操作:substr

将pos位置开始长度为len的内容拷贝到一个新生成的字符串中去。
记住substr的两个参数都是整数即可,前一个是位置,后一个是长度。
string file("string_test.cpp");
size_t pos=file.find('.');
string suffix = file.substr(pos, file.size() - 1);
cout << suffix << endl;再比如,
希望用find分别得到一个网址的协议,域名,端口 。
网址:
https://leetcode.cn/problems/add-strings/description/string url("https://leetcode.cn/problems/add-strings/description/");
size_t pos1 = url.find(':',0);
string url1 = url.substr(0, pos1 - 0);
size_t pos2 = url.find('/', pos1 + 3);//从leetcode的l处开始寻找
string url2 = url.substr(pos1 + 3, pos2 - (pos1 + 3));
string url3 = url.substr(pos2 + 1, url.size() - (pos2 + 1));
cout << url1 << endl << url2 << endl << url3 << endl;此处选取pos时依然利用左闭右开的好处:直接做减法就能获得长度len
find_first_of 四兄弟 (类似于strtok) ,了解即可


使用一个string类型对象调用该函数时,他能正向(或逆向)找出 (非)你给出的参数中第一个与string对象中所包含元素一样的位置。所以最坏时间复杂度是两个串的长度之积,O(m*n)
官网解释:
Searches the string for the first character that matches any of the characters specified in its arguments.(功能)
When pos is specified, the search only includes characters at or after position pos, ignoring any possible occurrences before pos.(第二个参数pos的作用)
Notice that it is enough for one single character of the sequence to match (not all of them). See string::find for a function that matches entire sequences.(与find区分)

find_last_of的实际作用:
比如在一个项目中,需要处理不同系统下的多个文件路径,但是由于Linux中的文件分隔符是右斜杠/,windows中的文件分隔符是左斜杠\ ,如果使用find函数查找这两个·会去找这两个一起出现的字符串(当然找不到),此时就需要find_first_of来发挥作用
void SplitFilename(const std::string& str)
{
std::cout << "Splitting: " << str << '\n';
std::size_t found = str.find_last_of("/\\");
std::cout << " path: " << str.substr(0, found) << '\n';
std::cout << " file: " << str.substr(found + 1) << '\n';
}
int main()
{
std::string str1("/usr/bin/man");
std::string str2("c:\\windows\\winhelp.exe");
cout << str2 << endl;
SplitFilename(str1);
SplitFilename(str2);
return 0;
}左斜杠\\需要多加一个表示转义字符,而右斜杠/不用,在windows中的操作要注意这个。
转义字符仍然只是一个字符。
11. string相关的部分外部函数
11.1 operator +
为什么+不能写成成员函数,而是全局重载:

原因就在于最后这种,无法通过成员函数实现。

除了char* + char*没有实现,其他都能直接加。
11.2 operator < > ==
类似于strcmp,按照字典序比较两个字符串相应位置的ASCII码值。
成立返回1,不成立返回0。
流插入的优先级较高,需要加括号。

11.3 getline
getline:
想获取一行中包含空格的串,不能直接使用流提取,需要使用getline
![]()
字符串最后一个单词的长度_牛客题霸_牛客网 (nowcoder.com)
#include <iostream>
using namespace std;
int main() {
string s;
getline(cin,s);
int pos=s.rfind(' ');
cout<<s.size()-(pos+1);
return 0;
}持续获取:
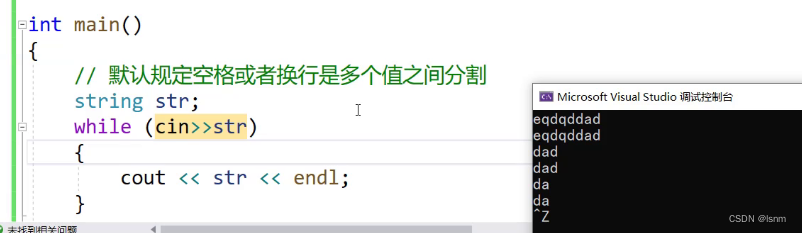
你如果一次输入按下三次空格再回车,其实这个循环就走了三次,空格作为分隔符,将之后的内容都存在缓存区,cout的时候会输出全部,再等待下次输出。
使用 ctrl+Z+回车 可以终止这个程序。
11.4 字符串和int类型的转换
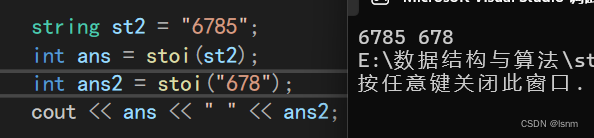
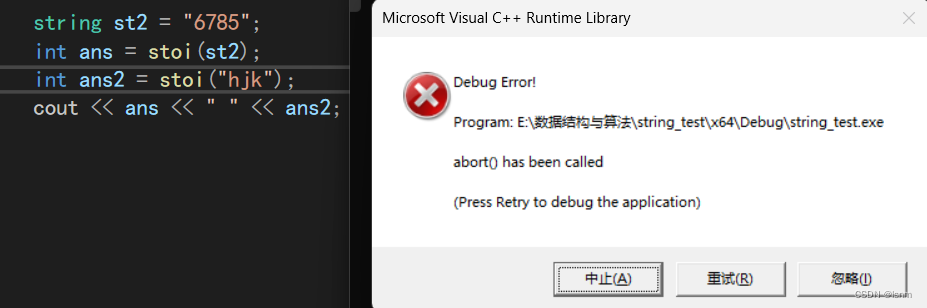
to_string和stoi(类比于C语言的atoi itoa a to i ASCII到int i to a int 到ASCII)
但是stoi(string to int)不能处理大数运算,串长之后就会爆,放不下。
12.编码表UNICODE
string的底层是如何装汉字的呢?
计算机中的编码除了ASCII编码,还有万国码(UNICODE)。
万国码支持ASCII编码,并以此为基础增加了世界上绝大多数国家的语言文字。
大部分汉字编入两个字节的部分,部分生僻的编入3字节或者4字节
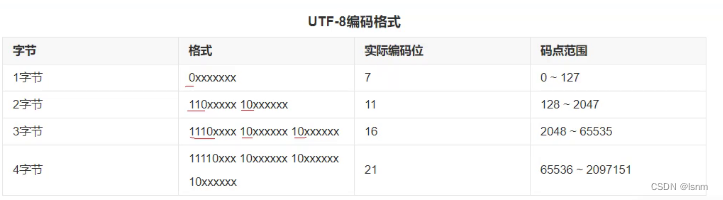
因此有可能一个字节表示,有可能两个字节表示,有可能三个字节去表示。
string默认支持UTF8,还有默认支持UTF16和UTF32、以及双字符的wstring
所有的string都是以basic_string为模版实现的。

还有一种库叫GBK库,由于万国码在中文一些方面优化的不够好,这一套GBK作为国标也被很多系统支持,如windows等,更适合中国宝宝的体质。