昨天的文章中,我们回顾了 YOLO 家族的前 9 个架构。本文中将继续总结最后3个框架,还有本月最新发布的YOLO V8.

YOLOR
Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao
“You Only Learn One Representation: Unified Network for Multiple Tasks”2021/05, https://arxiv.org/pdf/2105.04206.pdf
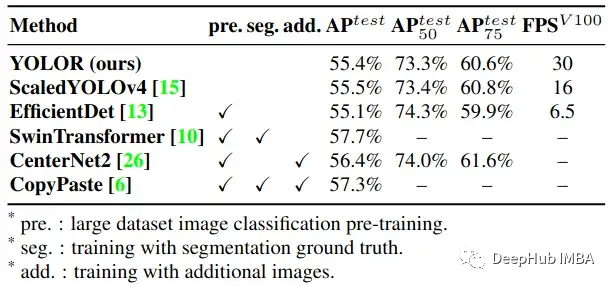
这个名称的翻译可能会有不同,“你只学习一种表示”。作者说这与之前的YOLO版本无关,概念也与YOLO有所不同。
因为有隐性知识(以前经验的概括)和显性知识(通过感官感知)。所以理解图片中显示的内容的人比不理解的普通神经网络能够更好地处理。
卷积神经网络通常执行一个单个的特定的任务, 而 YOLOR 的目标是同时可以训练它们同时解决多个任务,在他们学习解析输入以获得输出的同时,YOLOR 试图迫使卷积网络做两件事:
- 了解如何获得输出
- 试图确定所有不同的输出可能是什么。
所以模型有多个输出,而不是一个输出。
YOLOR 试图结合显性和隐性知识。对于神经网络,它们的显性知识存储在靠近输入的层中,而隐性知识存储在较远的层中。YOLOR 成为一个统一的神经网络。
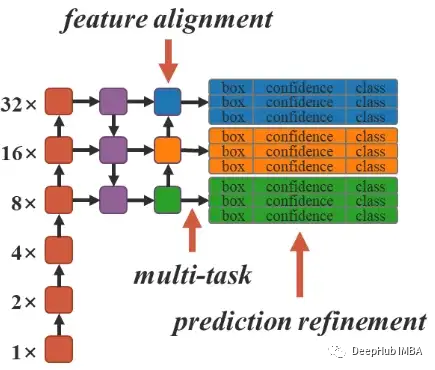
论文介绍了神经网络中内隐性知识与显性知识整合过程中的关键问题:
在隐式知识的学习过程中引入了核空间对齐、预测细化和多任务学习等方法。向量、神经网络和矩阵分解是用来建模隐性知识和分析其有效性的方法。
优点
发布时的检测精度和检出率高于竞争对手
YOLOv6 / MT-YOLOv6
Meituan, China.
“YOLOv6: A Single-Stage Object Detection Framework for IndustrialApplications”2022/09, https://arxiv.org/pdf/2209.02976.pdf
美团的博客地址:https://tech.meituan.com/2022/06/23/yolov6-a-fast-and-accurate-target-detection-framework-is-opening-source.html

v6的改进主要集中在三个方面:
- backbone 和 neck部分对硬件进行了优化设计
- forked head 更准确
- 更有效的训练策略
backbone 和 neck的设计是利用硬件方面的优势,如处理器核心的计算特性,内存带宽等,以进行有效的推理。
backbone
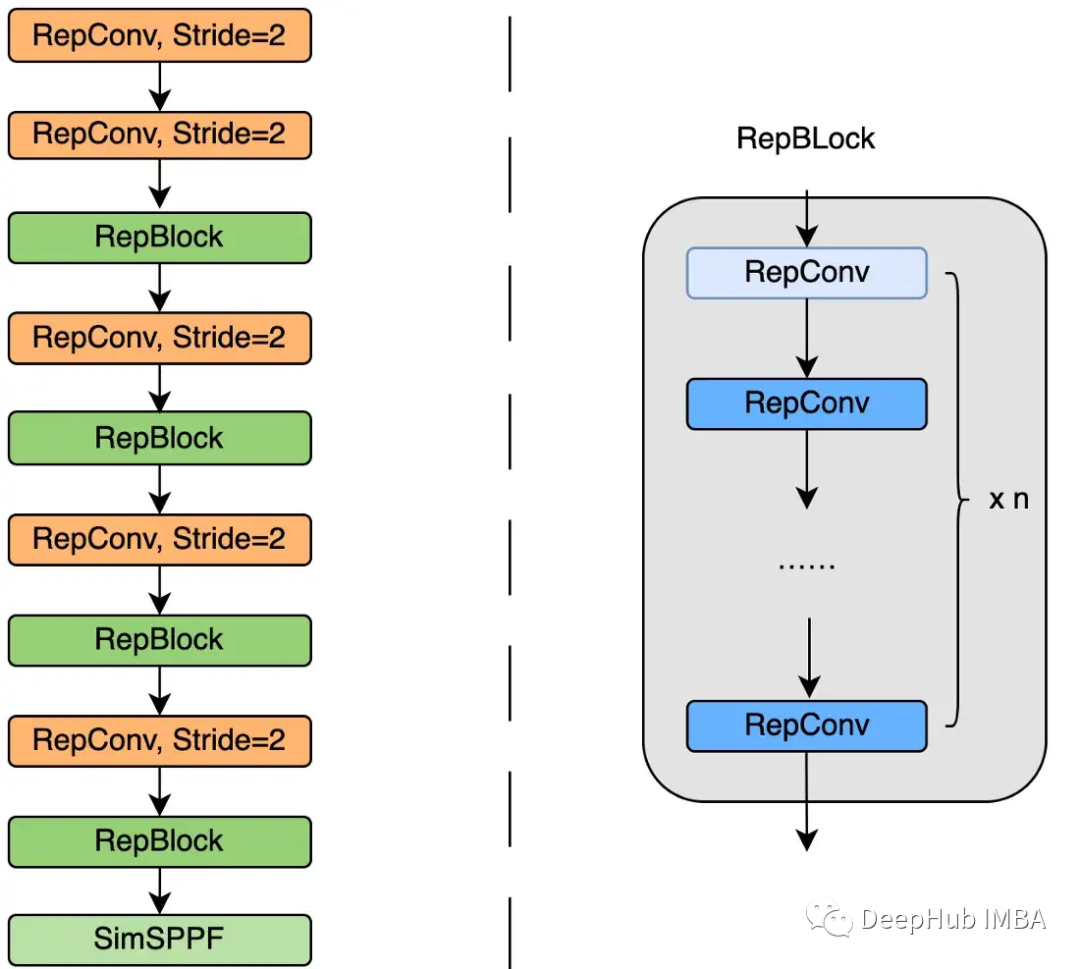
neck
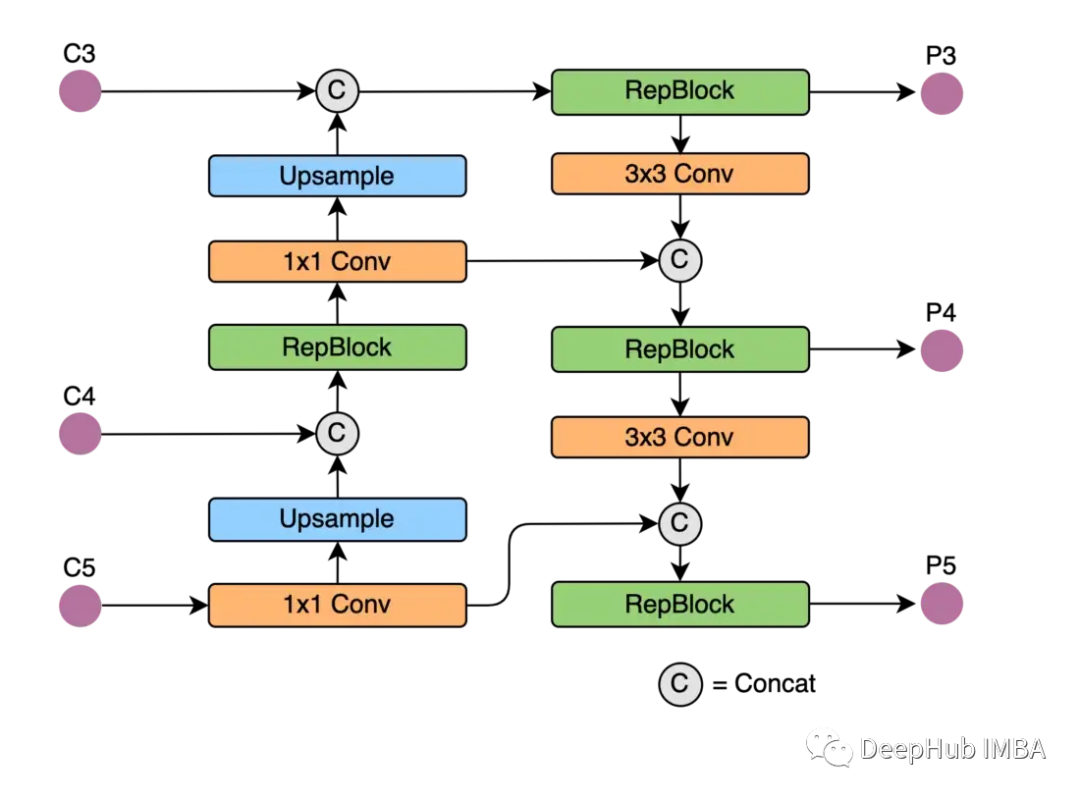
作者分别使用Rep-Pan和EfficientRep块重新设计了架构的部分。
美团团队进行的实验表明,计算延迟和检测精度显著降低。特别是,与YOLOv6-nano模型相比,YOLOv6-nano模型的速度提高了21%,精度提高了3.6%。
头部解耦
分叉头第一次出现在V5中。它用于网络分类部分和回归部分的分离计算。在v6中,这种方法得到了改进。
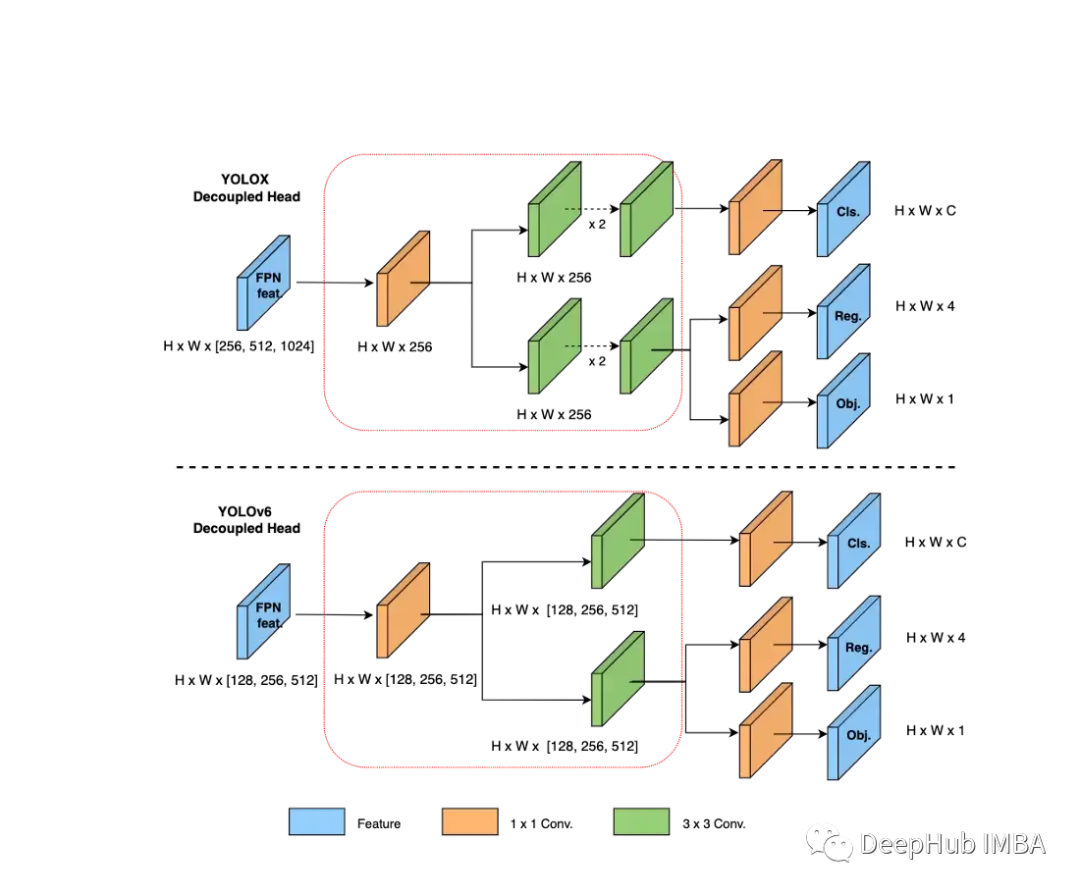
训练的策略包括:
- anchorless
- SimOTA标记策略
- SIoU盒回归的损失
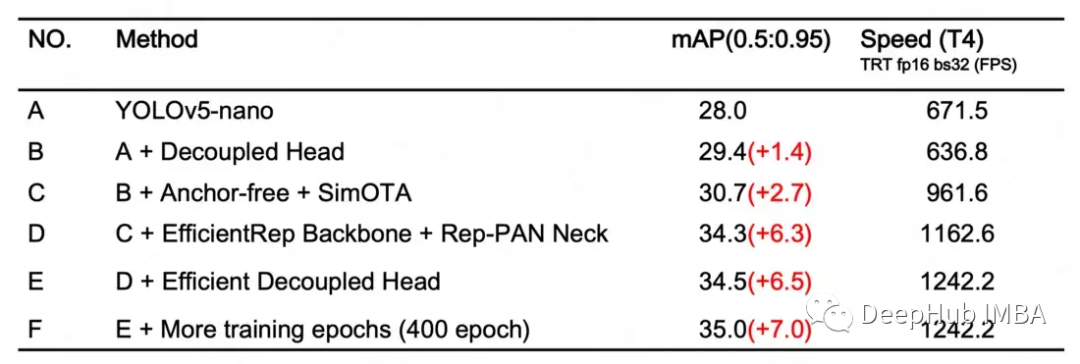
优点
检测精度和检出率高于竞争对手
使用标准的PyTorch框架,可以方便的进行微调
YOLOv7
Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao.
作者与YOLOv4的团队相同,可以认为是YOLO的官方发布。
“YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors”2022/07, https://arxiv.org/pdf/2207.02696.pdf
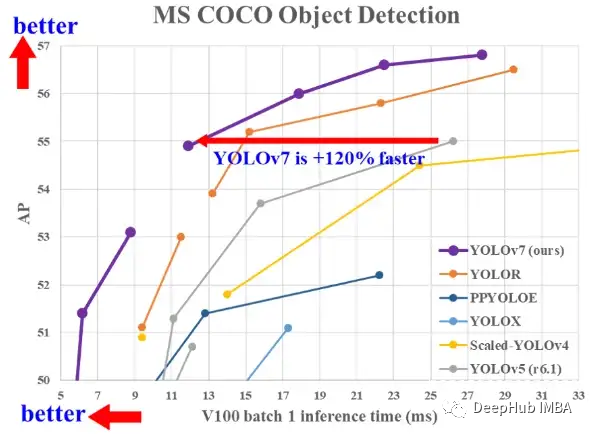
与其他实时模型相比,所提出的方法达到了最先进的性能。
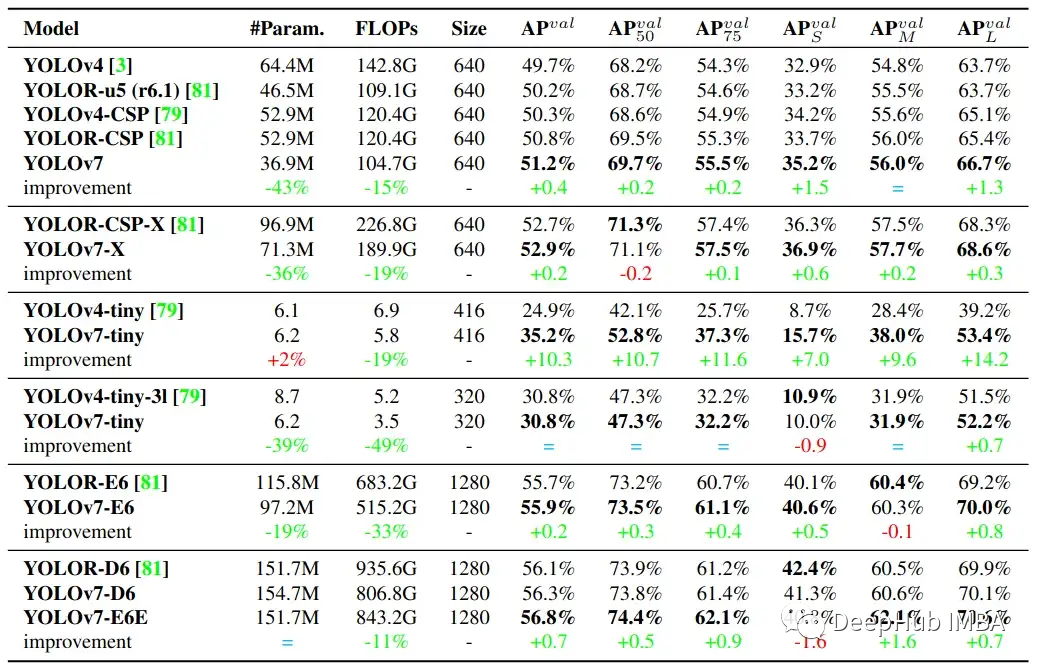
主要计算单元是E-ELAN(扩展高效层聚合网络)

它的设计考虑了以下影响计算精度和速度的因素:
- 内存访问成本
- I / O比率
- element-wise操作
- 激活
- 梯度路径
不同的应用需要不同的模型。在某些情况下检测精度是更重要的-那么模型应该有更多的可训练参数。在其他情况下,速度更重要模型应该更小,以便推理得更快。
在缩放v7时,需要考虑以下超参数:
- 输入分辨率
- 宽度(通道数)
- 深度(层数)
- 级联(特征金字塔的数量)
下图显示了一个同步模型扩展的示例。


论文还讨论了一套可以在不增加训练成本的情况下提高模型性能的方法。
再参数化是在训练后应用于改进模型的技术。它增加了训练时间,但提高了推理性能。有两种类型的重新参数化,模型级和模块级。
模型重新参数化可以通过两种方式完成:
- 使用不同的训练数据,训练多个设置相同模型。然后平均它们的权重得到最终模型。
- 平均模型不同训练轮次权重。
模块化再参数化在研究中较为常用。该方法将模型训练过程划分为大量的模块。对输出进行集成以得到最终模型。
在v7体系结构中,可以有多个头来执行不同的任务,每个头都有自己的损失。标签分配器是一种考虑网络预测和真实预测并分配软标签的机制。它生成软标记而不是硬标记。
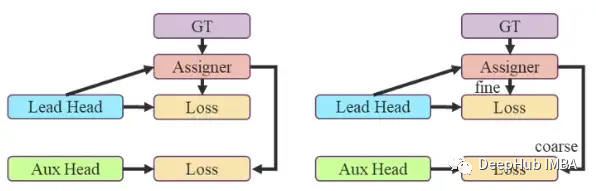
优点
发布时检测精度和检出率高于竞争对手
使用标准的PyTorch框架,可以方便的进行微调
前期模型总结
在介绍V8之前,我们再总结一下以前的模型
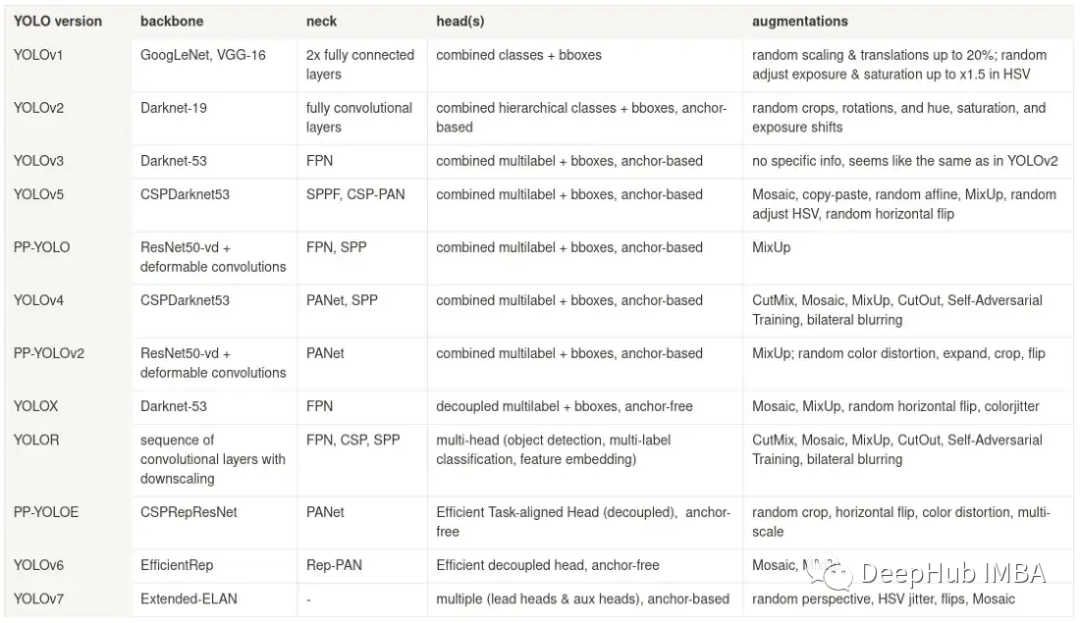
虽然上表并未提及所有提高性能的改进和发现。但是YOLO的发展我们可以看到一些模式。
Backbone 最初由一个分支(GoogLeNet、VGG、Darknet)组成,然后过渡到包含跳跃连接的架构(Cross-Stage Partial connections — CSPDarknet、CSPRepResNet、Extended-ELAN)。
Neck 最初也由一个分支组成,然后以特征金字塔网络的各种修改形式逐步发展,这样可以在不同尺度下保持物体检测的准确性。
Head:在早期版本中只有一个 head,它包含所有输出参数——分类、bbox 的坐标等。后面的研究发现将它们分成不同的头会更有效率。从基于锚点到无锚点也发生了转变(v7 除外——出于某种原因,它仍然有锚点)。
数据增强:仿射变换、HSV 抖动和曝光变化等早期增强非常简单,不会改变对象的背景或环境。而最近的一些——MixUp、Mosaic、CutOut 等改变了图像的内容。平衡这两个方向增强的比例对于神经网络的有效训练都很重要。
YOLO v8
YOLOv3之前的所有YOLO对象检测模型都是用C语言编写的,并使用了Darknet框架,Ultralytics发布了第一个使用PyTorch框架实现的YOLO (YOLOv3),YOLOv3发布后不久,Joseph Redmon就离开了计算机视觉研究社区。
YOLOv3之后,Ultralytics发布了YOLOv5,在2023年1月,Ultralytics发布了YOLOv8。
YOLOv8包含五个模型,用于检测、分割和分类。YOLOv8 Nano是其中最快和最小的,而YOLOv8 Extra Large (YOLOv8x)是其中最准确但最慢的,具体模型见后续的图。
YOLOv8附带以下预训练模型:
- 目标检测在图像分辨率为640的COCO检测数据集上进行训练。
- 实例分割在图像分辨率为640的COCO分割数据集上训练。
- 图像分类模型在ImageNet数据集上预训练,图像分辨率为224。

与之前的YOLO模型相比,YOLOv8模型似乎表现得更好。不仅是YOLOv5,YOLOv8也领先于YOLOv7和YOLOv6等
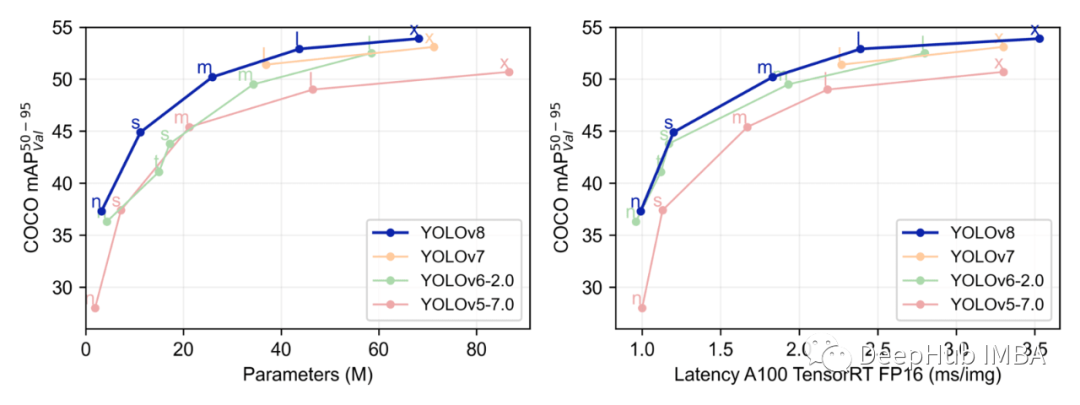
与其他在640图像分辨率下训练的YOLO模型相比,所有YOLOv8模型在参数数量相似的情况下都具有更好的吞吐量。
下面我们看看模型到底更新了什么
YOLOv8尚未发表论文,所以我们无法得到构建时的研究方法和消融研究的详细信息。但是我们可以从代码中看到他的改进,下面这张图是由GitHub用户rangging制作,展示了网络架构的详细可视化。
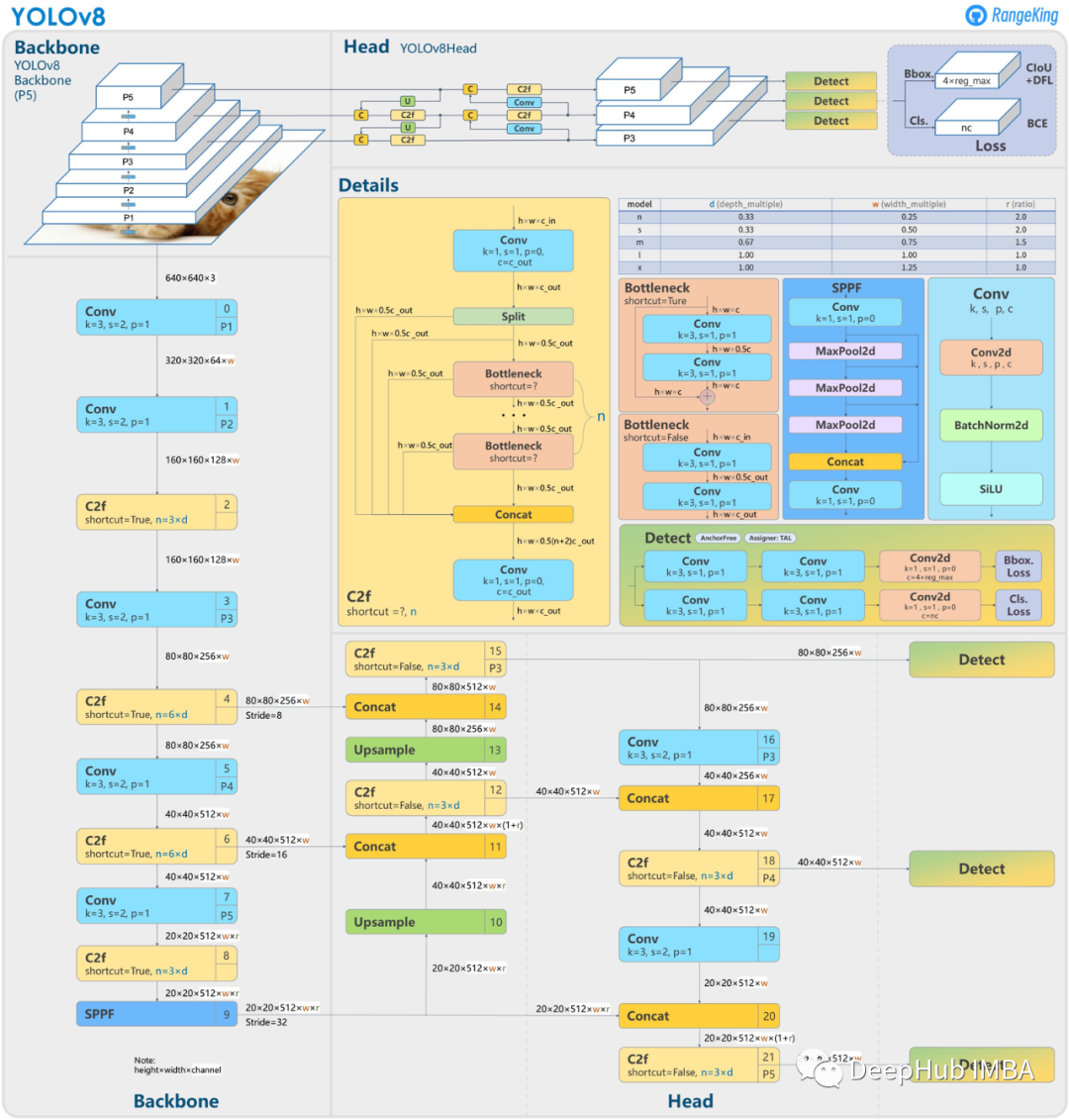
YOLOv8是一种无锚点模型,这意味着它直接预测对象的中心,而不是已知锚框的偏移量。锚点是早期YOLO模型中众所周知的很麻烦的部分,因为它们可能代表目标基准框的分布,而不是自定义数据集的分布。
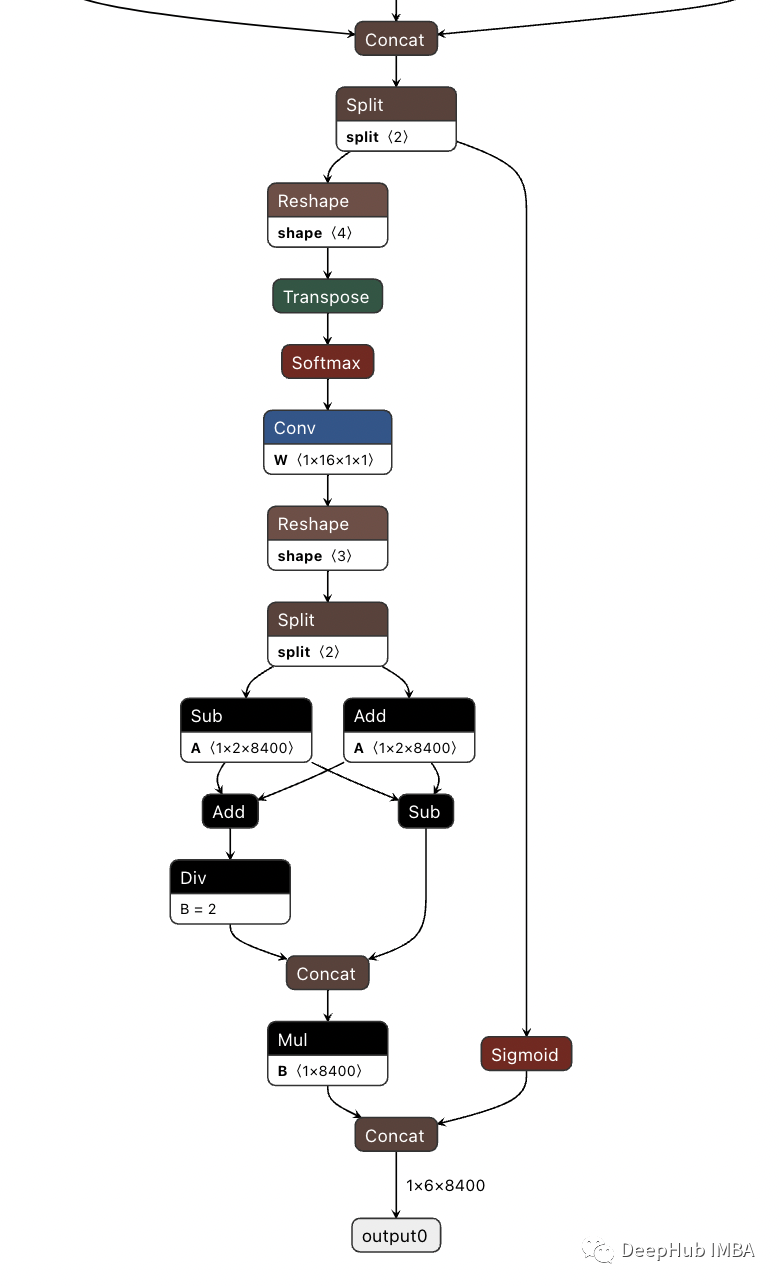
无锚点减少了预测框的数量,从而加快了非最大抑制(NMS)的速度。下图为V8的检测头部分的可视化
新的卷积
stem 的第一个 6x6 conv 变为 3x3,主要构建块也使用C2f 取代了 C3。该模块总结如下图,其中“f”是特征数,“e”是扩展率,CBS是由Conv、BatchNorm和后面的SiLU组成的块。
在 C2f 中,Bottleneck 的所有输出(两个具有剩余连接的 3x3 卷积)都被连接起来。而在 C3 中,仅使用了最后一个Bottleneck 的输出。

Bottleneck 与YOLOv5中相同,但第一个conv核大小从1x1更改为3x3。我们可以看到YOLOv8开始恢复到2015年定义的ResNet块。
neck部分,特征直接连接,而不强制相同的通道尺寸。这减少了参数计数和张量的总体大小。
Mosaic 增强
深度学习研究往往侧重于模型架构,但YOLOv5和YOLOv8中的训练过程是它们成功的重要组成部分。
YOLOv8在在线训练中增强图像。在每个轮次,模型看到的图像变化略有不同。
Mosaic增强,将四张图像拼接在一起,迫使模型学习新位置,部分遮挡和不同周围像素的对象。
经验表明,如果在整个训练程序中进行这种增强会降低性能。在最后10个训练轮次关闭它则提高了性能。
以下性能来自Ultralytics的github

可以看到,目前来说YOLOv8 的精度和推理延迟都是最先进的。
YOLOv8代码结构
YOLOv8模型利用了与YOLOv5类似的代码,但采用了新的结构,其中使用相同的代码来支持分类、实例分割和对象检测等任务类型。模型仍然使用相同的YOLOv5 YAML格式初始化,数据集格式也保持不变。
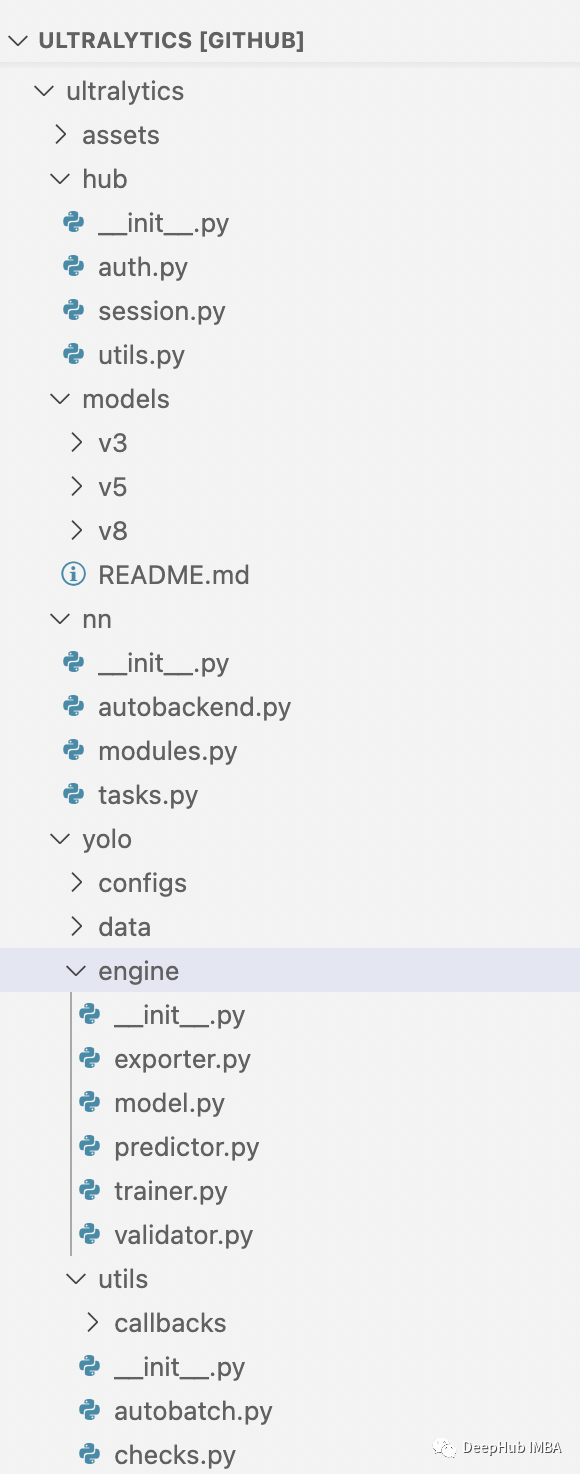
ultralytics还提供了通过命令,许多YOLOv5用户应该对此很熟悉,其中训练、检测和导出交互可以通过CLI完成的。
yolo task=detect mode=val model={HOME}/runs/detect/train/weights/best.pt data={dataset.location}/data.yaml
PIP包也可以很简单的让我们进行定制的开发和微调训练:
fromultralyticsimportYOLO
# Load a model
model=YOLO("yolov8n.yaml") # build a new model from scratch
model=YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
results=model.train(data="coco128.yaml", epochs=3) # train the model
results=model.val() # evaluate model performance on the validation set
results=model("https://ultralytics.com/images/bus.jpg") # predict on an image
success=YOLO("yolov8n.pt").export(format="onnx") # export a model to ONNX format
这使得可以方便使用我们的数据集进行训练,具体训练的方式有很多文章,我们这里就不说明了。
有兴趣的可以看看官方说明(有中文哦):https://avoid.overfit.cn/post/7596c1ba2d9544189f46e1abf6445c60





![[审核]因为审核人员不了解苹果登录被拒](https://img-blog.csdnimg.cn/4ebf700ae49c4b1f8f20213acf7784b6.png)