优质博文:IT-BLOG-CN
一、MyBatis 与 JDBC 的区别
【1】JDBC 是 Java 提供操作数据库的 API;MyBatis 是一个持久层 ORM 框架,底层是对 JDBC 的封装。
【2】使用 JDBC 需要连接数据库,注册驱动和数据库信息工作量大,每次都要去创建、关闭、获取JDBC 编程可能的异常进行捕获处理,并正确关闭资源对象关闭映射(ORM)。操作 Connection,打开 Statement 对象。通过 Statement 执行 SQL 返回结果到 ResultSet 对象,然后通过代码转化为具体的 POJO 对象。关闭数据库的相关资源等。MyBatis 使用已有的连接池管理,避免浪费资源,提高程序可靠性。
//JDBC 操作数据库时,部分代码
conn = (Connection) DriverManager.getConnection(DB_URL, USER, PASS);
// 执行查询
stmt = (Statement) conn.createStatement();
String sql = "SELECT * FROM xtb";
//获取到的ResultSet需要一个个的get属性,并赋给返回值对象
ResultSet rs = stmt.executeQuery(sql);
//......
// 完成后关闭
rs.close();
stmt.close();
conn.close();
【3】MyBatis 提供了 Dao 层自动生成工具(mybatis-generator),提高了编码效率和准确性。
【4】MyBatis 提供了一级和二级缓存,提高了程序的性能。
【5】MyBatis 支持动态 SQL 语句编写,提高了 SQL 维护和防止 SQL 注入。
【6】MyBatis 提供映射标签,对数据库操作结果进行自动映射到 POJO对象或 Map中,支持对象与数据库的 ORM 映射关系。
【7】MyBatis 将 SQL 语句写入 xml 中,便于统一管理和优化,解除了 SQL与程序代码的耦合。
【8】JDBC 向 SQL语句传参数麻烦,因为 SQL语句的 Where条件不一定,可能多也可能少,占位符需要和参数一一对应。Mybatis 会自动将 Java 对象映射至 SQL语句(比如查询的时候,用户输入了什么参数就是用什么作为条件,没输入的参数就应当过滤掉等)。
二、Mybatis 与 Hibernate 的区别
【1】Hibernate 是一个标准的 ORM 框架,面向对象开发,不需要写 SQL语句,维护数据表关系比较复杂,SQL 语句自动生成,对 SQL语句优化,修改比较困难。如果进行数据库迁移不需要修改 SQL语句,只需要修改一下方言。缺点是完全由 Hibernate来管理数据表的关系,对于我们来说完全是透明的,不易维护。Hibernate 自动生成 SQL语句,比较复杂,比较难挑错。Hibernate 由于是面向对象开发,不能开发比较复杂的业务。
应用场景:适合需求变化较少的项目,比如 ERP,CRM 等等;
【2】Mybatis 框架对 JDBC框架进行封装,屏蔽了JDBC的缺点,开发简单。Mybatis 只需要程序员关注 SQL本身,不需要过多的关注业务。对 SQL的优化,修改比较容易。
适应场景:适合需求变化多端的项目,比如:互联网项目;
三、MyBatis 中 #{} 与 ${} 的区别
它们都在 SQL 中动态的传入值,能用 #{} 就不要用 ${}。
【1】#{} 解析之后会将 String类型的数据自动加上引号,其他数据类型不会;常用与where 条件,例如#{name}解析之后就可能为#{‘zzx’} 。而
解析之后是什么就是什么,他不会当做字符串处理,一般用于传入数据库对象,常用与传入表名和
o
r
d
e
r
b
y
条件,例如:
{} 解析之后是什么就是什么,他不会当做字符串处理,一般用于传入数据库对象,常用与传入表名和 order by 条件,例如:
解析之后是什么就是什么,他不会当做字符串处理,一般用于传入数据库对象,常用与传入表名和orderby条件,例如:{column} 解析之后就是 order by id 。
【2】#{} 解析为一个 JDBC 预编译语句(prepared statement)的参数标记符,一个 #{} 被解析为一个参数占位符《?》;而 ${} 仅仅为一个纯碎的 String 替换,在动态 SQL解析阶段将会进行变量替换。
【3】基于【2】,#{} 很大程度上可以防止 SQL注入(SQL注入是发生在编译的过程中,因为恶意注入了某些特殊字符,最后被编译成了恶意的执行操作);而 ${} 主要用于 SQL拼接的时候,有很大的 SQL注入隐患。
四、MyBatis 的一级、二级缓存
【1】一级缓存: MyBatis 的一级缓存是 SqlSession级别的,当 Session flush 后 close 之后,该 Session 中的所有 Cache 就将清空,默认一级缓存是打开的。与有没有配置无关,只要 SqlSession 存在,MyBastis 一级缓存就存在。
【一级缓存失效原因】: ① 是否在同一个 SqlSession 连接中;② 如果进行了增删改操作程序会 clear 缓存。③ 手动清空缓存数据。调用 sqlsession.clearCache();④ 执行语句的参数不同,缓存中也不存在数据。因为 map 的 key 是根据 mapperStatment 对象的 id、以及 sql、以及传入的参数生成 cacheKey 对象的。
【2】二级缓存: 与一级缓存的不同之处在于其存储作用域为 Mapper(Namespace) ,多个 SqlSession去操作同一个 Mapper的 sql 语句,多个 SqlSession可以共用二级缓存。MyBatis 二级缓存读取优先级高于 MyBatis一级缓存。关闭 sqlsession后,会把该 sqlsession一级缓存中的数据添加到 namespace 的二级缓存中。MyBatis 二级缓存的生命周期即整个应用的生命周期,应用不结束,定义的二级缓存都会存在在内存中。从这个角度考虑,为了避免 MyBatis二级缓存中数据量过大导致内存溢出,MyBatis在配置文件中给我们增加了很多配置例如 size(缓存大小)、flushInterval(缓存清理时间间隔)、eviction(数据淘汰算法)来保证缓存中存储的数据不至于太过庞大。
【二级缓存使用】: ① 开启全局二级缓存配置 setting 配置文件中添加:
<setting name="cacheEnabled" value="true"/>
② 去 mapper.xml 中配置使用二级缓存:
<cache eviction="FIFO" flushInterval="60000" readOnly="false" size="1024"></cache>
● eviction(回收策略):LRU 最近最少使用、FIFO 先进先出、SOFT 软引用,移除基于垃圾回收器状态和软引用规则的对象。 WEAK 弱引用,移除基于垃圾回收器状态和弱引用规则的对象。
● flushInterval(刷新间隔):可以被设置为任意的正整数(60601000这种形式是不允许的),而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
● size(引用数目) :设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
● readOnly(只读)属性可以被设置为 true或 false。只读的缓存会给所有调用者返回缓存对象的相同实例,因此这些对象不能被修改,这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过发序列化)。这会慢一些,但是安全,因此默认是 false。
③ 我们的 POJO 需要实现序列化接口;
【二级缓存弊端】: 二级缓存是建立在同一个 namespace 下的,如果对表的操作查询可能有多个 namespace,那么就可能会出现脏读的数据。举个栗子:例如存在两个表“student” 和 “teacher”,在 student 表中关联查询 teacher 表,就会将结果存放在 student 表的 namespace 中。问题来了,如果此时修改了 teacher 表,只会对 teacher 表中的 namespace 缓存进行清空,并不会影响 student 表中的缓存。因此 student 表中缓存的 teacher 信息就有可能是脏数据(好好琢磨一下)。
【二级缓存使用注意事项】: ① 对该表的查询与增删改操作都放在同一个 namespace 中,其它的 namespace 如果有操作,就会出现脏读的数据。② 对关联表的查询,关联的所有表的操作都必须在同一个 namespace 下。
五、Mybatis 动态 Sql 都有哪些
其实动态 sql 语句的编写往往就是一个拼接的问题,为了保证拼接准确,我们最好首先要写原生的 sql 语句出来,然后在通过 mybatis 动态sql 对照着改,防止出错。
【1】if 与 where 标签: parmaeterType 中基本数据类型可直接写类型(Integer、String、Map 等),如果标签返回的内容是以 AND 或 OR 开头的,则它会剔除掉。
<select id="selectUserByUsernameAndSex" resultMap="user" parameterType="com.pojo.User">
select * from user
<where>
<if test="username != null">
username=#{username}
</if>
<!--如果标签返回的内容是以AND 或OR 开头的,则它会剔除掉。-->
<if test="username != null">
and sex=#{sex}
</if>
</where>
</select>
【2】 if 与 set 标签: 如果标签返回的内容是逗号结尾的,则它会剔除掉逗号。
<update id="updateUserById" parameterType="com.pojo.User">
update user u
<set>
<if test="username != null and username != ''">
u.username = #{username},
</if>
<if test="sex != null and sex != ''">
u.sex = #{sex}
</if>
</set>
where id=#{id}
</update>
【3】choose、when 和 otherwise 标签: 选择其中的一个查询条件,一个满足即可,类似于 Java 的 switch 语句。
<select id="selectUserByChoose" resultType="com.pojo.User" parameterType="com.pojo.User">
select * from user
<where>
<choose>
<when test="id !='' and id != null">
id=#{id}
</when>
<when test="username !='' and username != null">
and username=#{username}
</when>
<otherwise>
and sex=#{sex}
</otherwise>
</choose>
</where>
</select>
【4】trim 标签: 标记是一个格式化的标记,可以完成 set 或者是 where 标记的功能,prefix:前缀 、suffix:后缀。prefixoverride:去掉第一个配置的值,suffixoverride:去掉最后一个配置的值。
<select id="selectUserByUsernameAndSex" resultType="user" parameterType="com.pojo.User">
select * from user
<trim prefix="where" prefixOverrides="and | or">
<if test="username != null">
and username=#{username}
</if>
<if test="sex != null">
and sex=#{sex}
</if>
</trim>
</select>
【5】sql 与 include 标签: 有时候可能某个 sql 语句我们用的特别多,为了增加代码的重用性,简化代码,我们需要将这些代码抽取出来,然后使用时直接调用。
<!-- 定义 sql 片段 -->
<sql id="columns">
name,age
</sql>
<!-- 引入sql代码块-->
<select id="selectUser" resultMap="com.pojo.User" >
select <include refid="columns"/> from User
</select>
【6】foreach 标签: 当传入参数为数组或者集合时需要通过标签进行遍历。
<select id="selectUserByListId" parameterType="com.ys.vo.UserVo" resultType="com.ys.po.User">
select * from user
<where>
<!--
collection:指定输入对象中的集合属性
item:每次遍历生成的对象
open:开始遍历时的拼接字符串
close:结束时拼接的字符串
separator:遍历对象之间需要拼接的字符串
select * from user where 1=1 and id in (1,2,3)
-->
<foreach collection="ids" item="id" open="and id in (" close=") " separator=",">
#{id}
</foreach>
</where>
</select>
六、Mybatis 有几种执行器
SqlSession 是 Mybatis 最重要的构建之一,可以简单的认为 Mybatis一系列的配置目的是生成类似 JDBC 生成的Connection 对象的 SqlSession 对象,这样才能与数据库开启“沟通”,通过 SqlSession 可以实现增删改查。
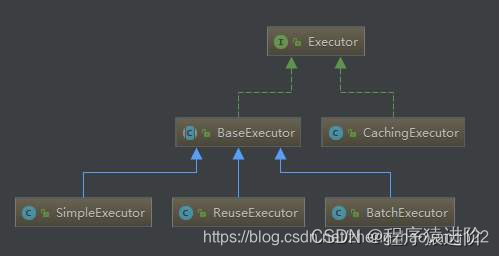
Executor 是 MyBatis 是核心接口之一,其中定义了数据库操作的基本方法。在实际应用中经常涉及的 SqlSession 接口的功能,都是基于 Executor 接口实现的。UML 类图关系如下:接口实现中涉及两种设计模式,分别是模板模式和装饰器模式。CachingExecutor 扮演了装饰器的角色,为 Executor 添加了二级缓存的功能。这里主要说 SimpleExecutor、ReuseExecutor、BatchExecutor 三种执行器。
BaseExecutor 是一个抽象类,实现了 Executor 的大部分方法,其中使用模板模式。BaseExecutor 中主要提供了缓存管理(一级缓存)和事务管理的基本方法,继承 BaseExecutor 的子类只要实现四个基本方法来完成数据库的相关操作。
七、MyBatis 注解与 xml 的优缺点
【1】mapper.xml: 跟接口分离、统一管理。复杂的语句可以不影响接口的可读性。 缺点:过多的 xml文件;
【2】Annotation: 接口就能看到 sql 语句,可读性高,不需要找 xml 文件,方便,优先级高于xml。 缺点:复杂的联合查询不好维护,代码可读性差,不能复用 sql 语句;
八、MyBatis 是如何调用存储过程的
<!-- statementType 声明指向的是什么类型,其中CALLABLE是执行存储过程和函数的-->
<select id="getXXX" parameterType="map" useCache="false" statementType="CALLABLE">
<![CDATA[
CALL 存储过程名称(
--parameterType="map" 使用map封装参数,直接输入key名称就可以获取到
--mode=IN 输入参数
#{iPageSize, jdbcType=DOUBLE, mode=IN}, --条数
--mode=OUT 返回结果
#{iTotalRecords, jdbcType=DOUBLE, mode=OUT}, --总条数
--resultMap 映射实体类或用LinkedHashMap接收
#{vCursor, mode=OUT, jdbcType=CURSOR, resultMap=cursorMap})
]]>
</select>
```