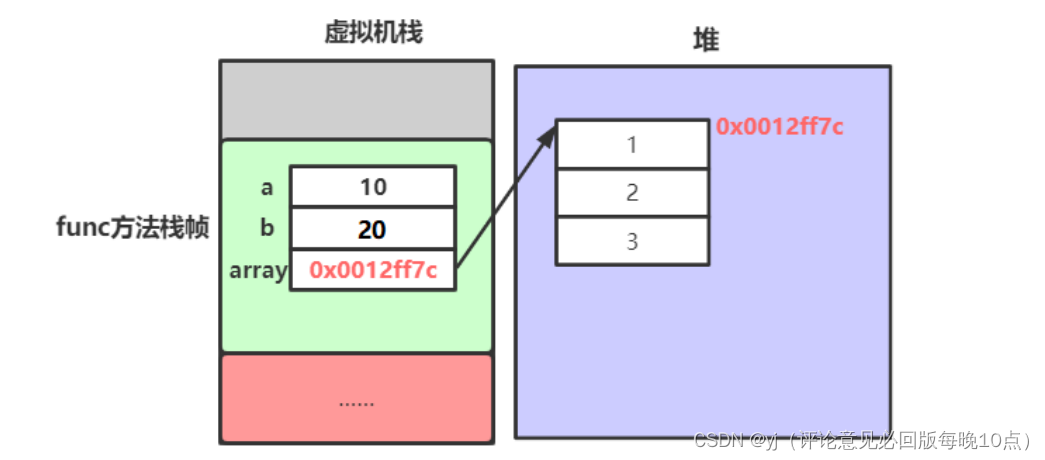
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、爬取的源网站
- 二、爬取过程详解
- 1.首先我们需要解析网站的源码,按F12,在Elements下查看网站的源码
- 2.获取视频的页数
- 3.获取每一页所哟视频的详情页面的url,注意这不是最终的下载视频的url
- 4.获取视频的下载url
- 解决方法
- 三、完整的实现代码
- 总结
一、爬取的源网站
http://www.lzizy9.com/
在这里以电影片栏下的动作片为例来爬取。
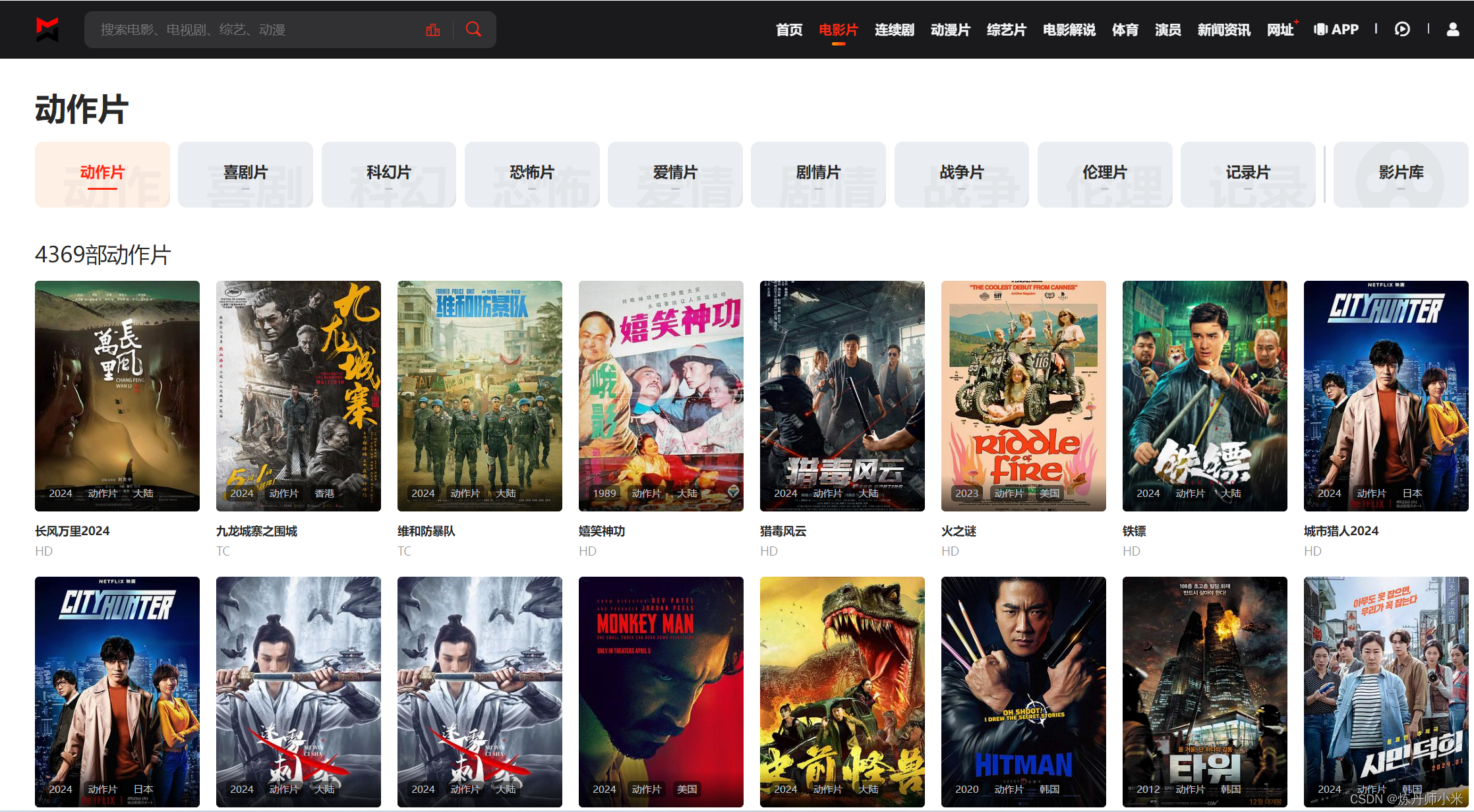
可以看到视频有多页,因此需要多页爬取。
二、爬取过程详解
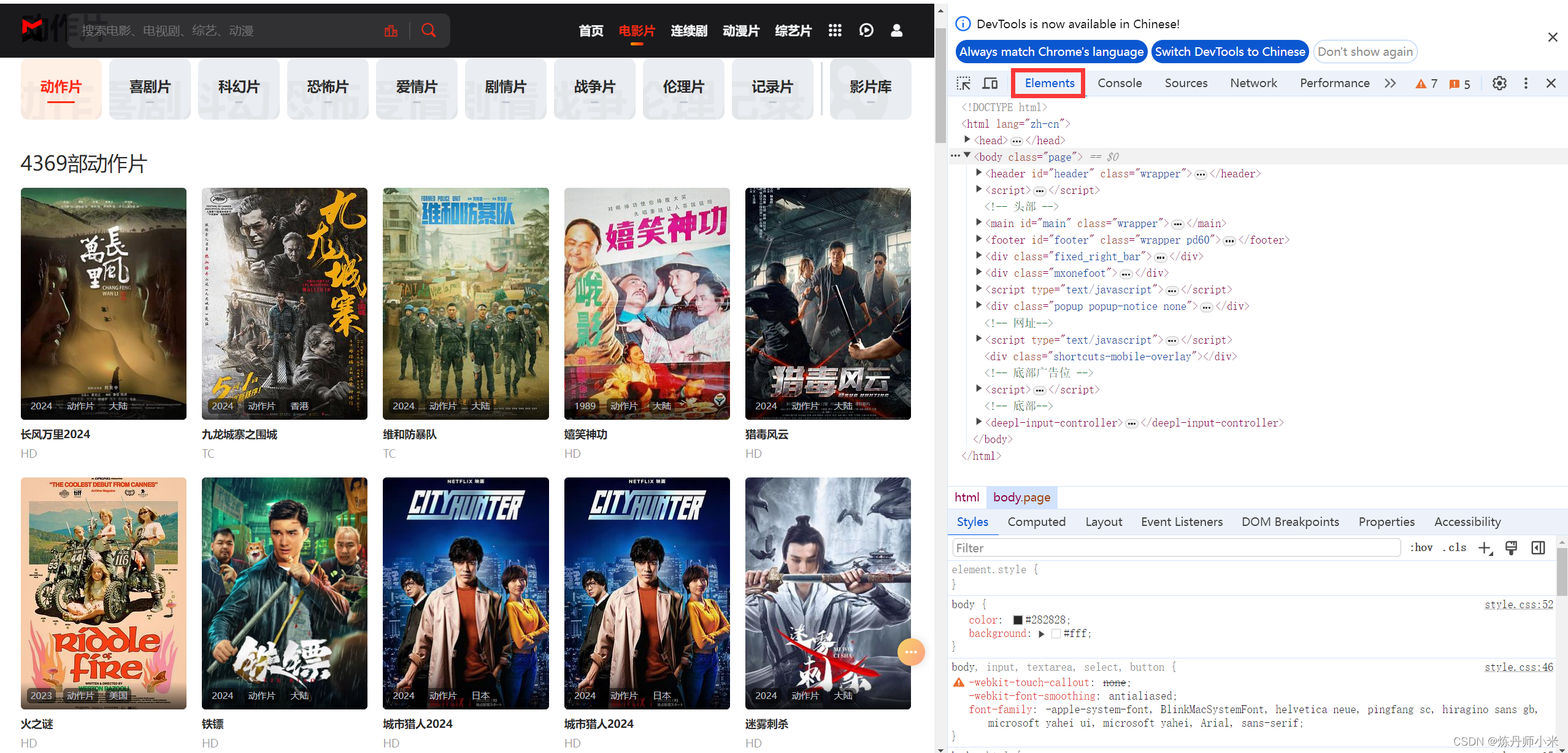
1.首先我们需要解析网站的源码,按F12,在Elements下查看网站的源码
2.获取视频的页数
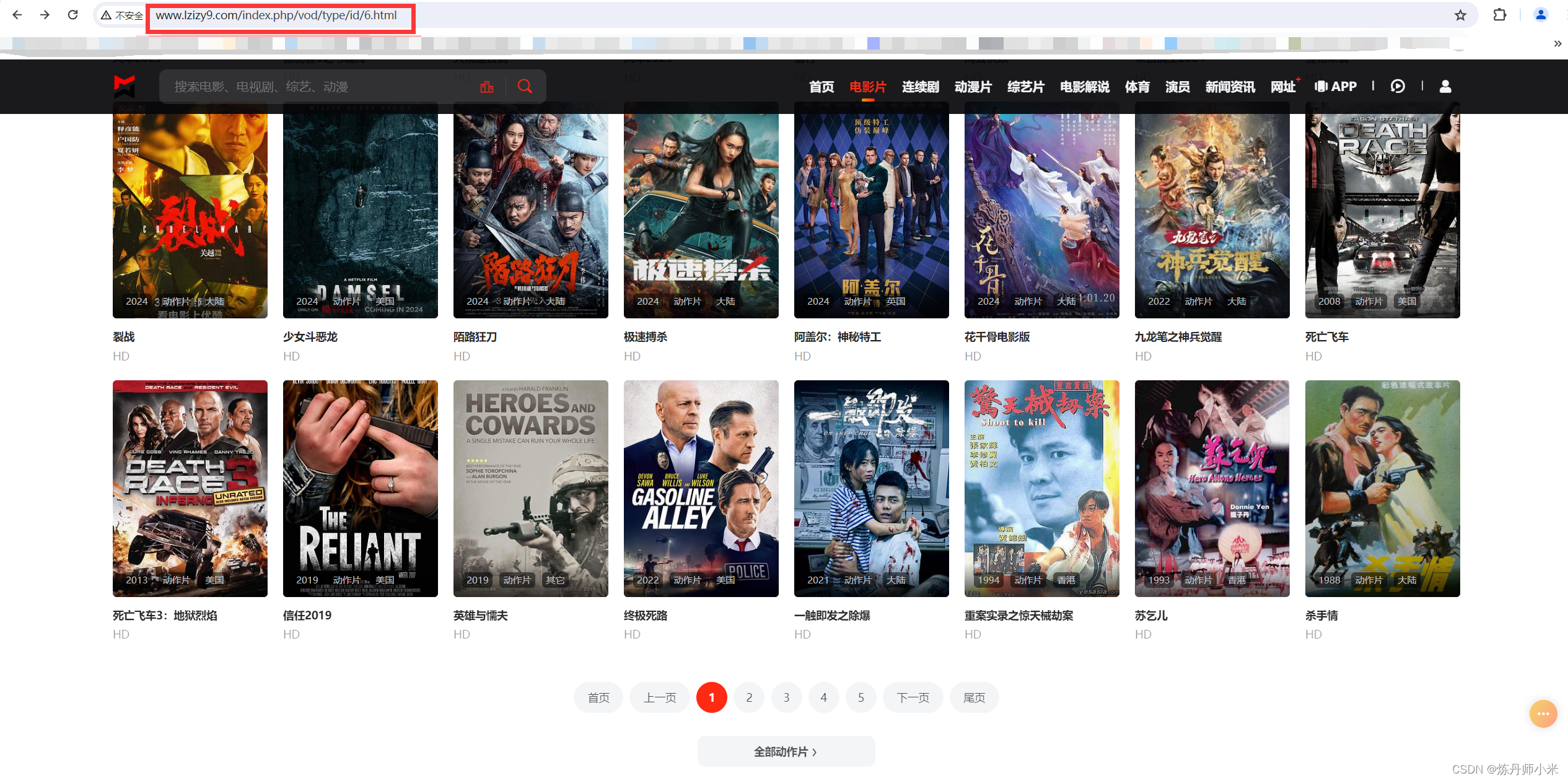
往往,视频一个网站的url是有规律可循的,这样可以方便我们的爬取操作,比如视频的第一页的url为http://www.lzizy9.com/index.php/vod/type/id/6.html
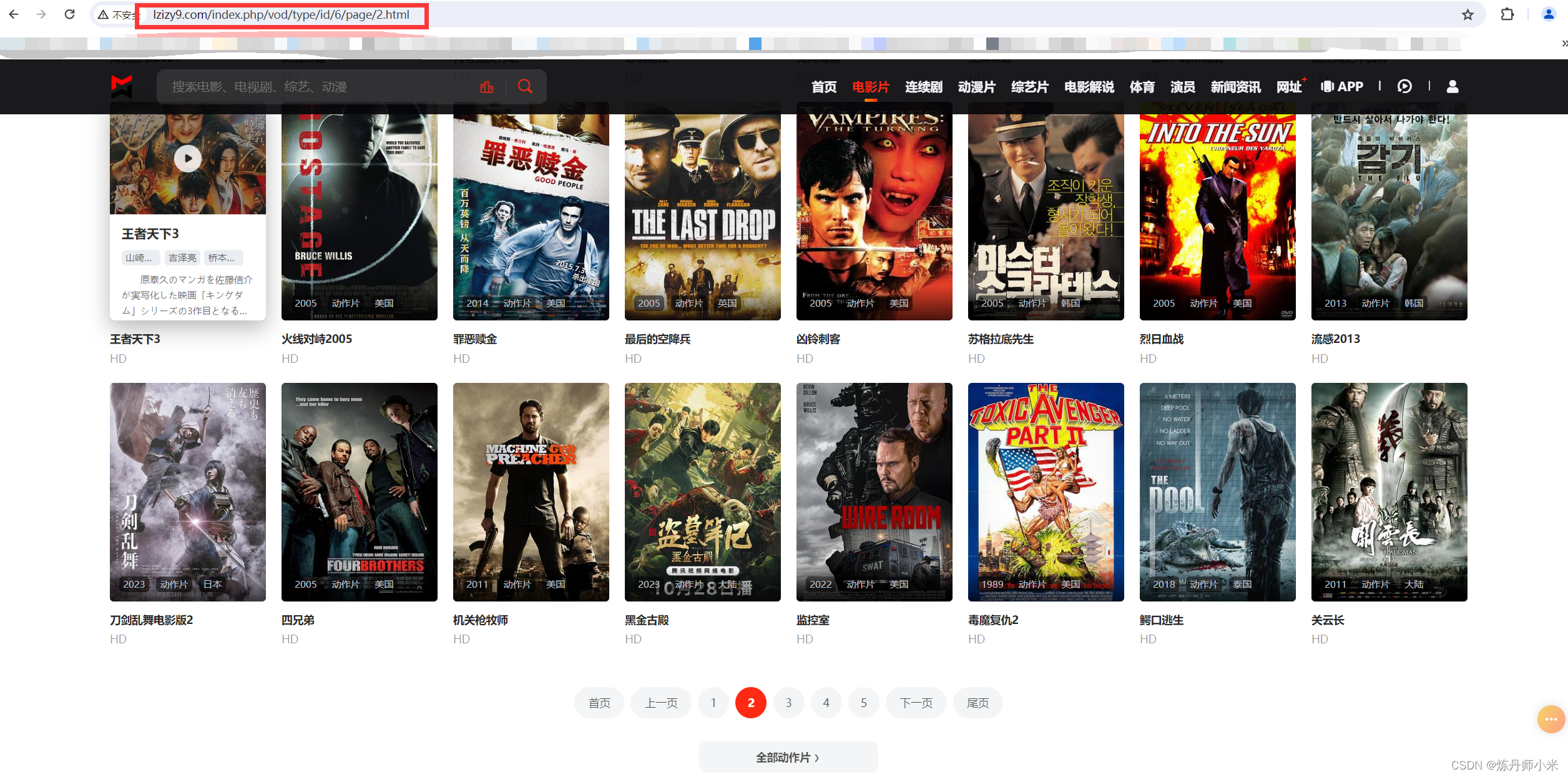
然后我们查看视频的第二页的url,
http://www.lzizy9.com/index.php/vod/type/id/6/page/2.html
后面的第三页url为http://www.lzizy9.com/index.php/vod/type/id/6/page/3.html,从中我们可以找到规律为第几页最后就是几。
但是看似第一个好像没有序号,我们在点第一页回来看看,会发现第一页也有了序号,其实这是因为第一页默认的没有显示罢了,其实第一页的url也就是http://www.lzizy9.com/index.php/vod/type/id/6/page/1.html,这样我们就可以找到页的url的规律了。
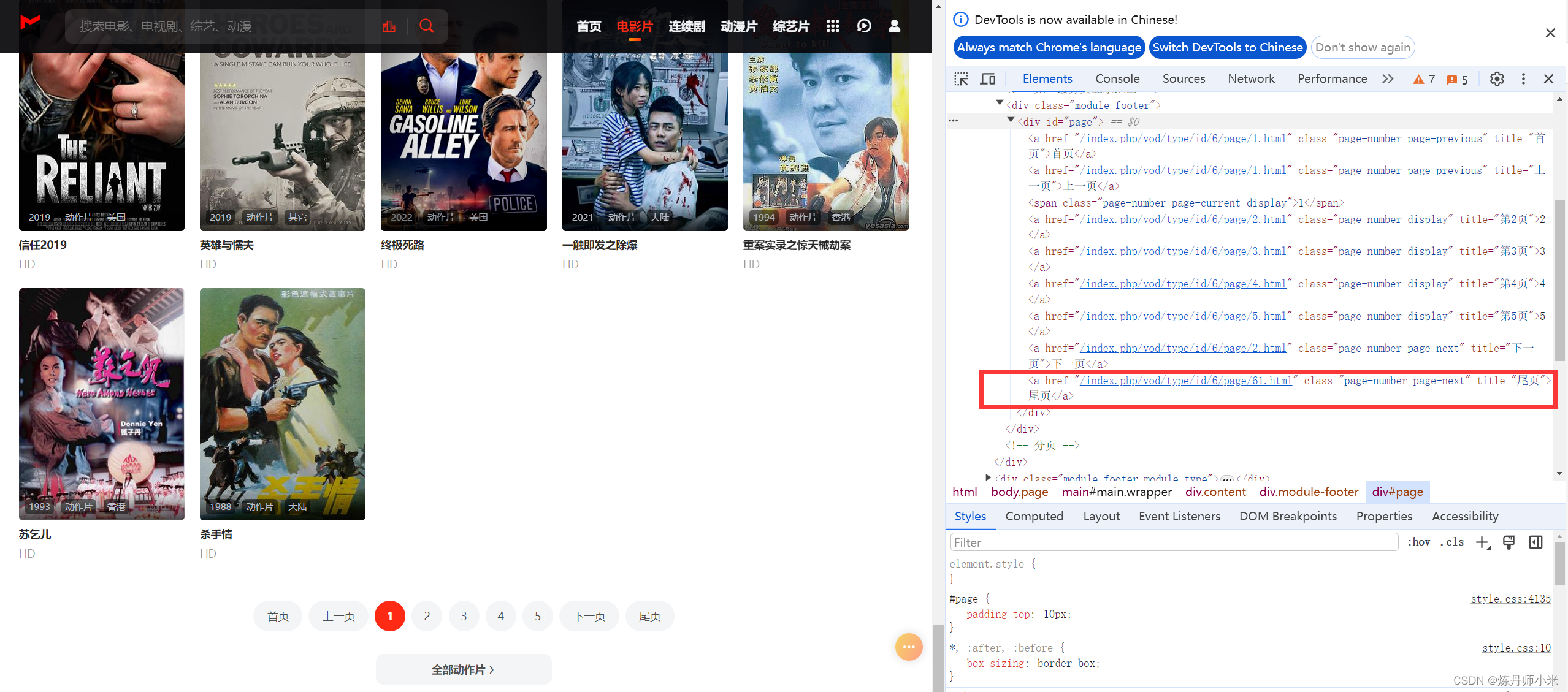
然后解析网站的源码来获取页数,可以看到图中标红框的部分就是我们要获取的视频的最后一页的信息,其中/index.php/vod/type/id/6/page/61.html中的61就是要页数了。
获得页数的代码如下:
# 通过requests.get方法可以发送GET请求
html_doc = requests.get(f"http://www.lzizy9.com/index.php/vod/type/id/6/page/1.html", headers=headers)
# BeautifulSoup将复杂的HTML文件转化为一个Python对象,使得用户可以更方便地解析、搜索和修改HTML内容。
# html_doc.text获取网页的HTML内容
soup = BeautifulSoup(html_doc.text, 'html.parser')
# 使用findALL提取网页中的信息,其返回的是一个可迭代的对象,具体的用法自行搜索
# 我们要爬取所有的视频,需要识别视频一共有多少页,其返回结果为['/index.php/vod/type/id/6/page/61.html'],根据参数我们得知一共有61页视频
href_values = [link['href'] for link in soup.findAll('a', title='尾页')]
# 获取页数,并将字符串string转化为int整数
end_page = int(href_values[0][30:32])
3.获取每一页所哟视频的详情页面的url,注意这不是最终的下载视频的url
以第一个视频为例,可以看到视频跳转到的界面的url的信息为/index.php/vod/detail/id/79854.html,实则网站的链接为http://www.lzizy9.com/index.php/vod/detail/id/73135.html,其省略了http://www.lzizy9.com而已。
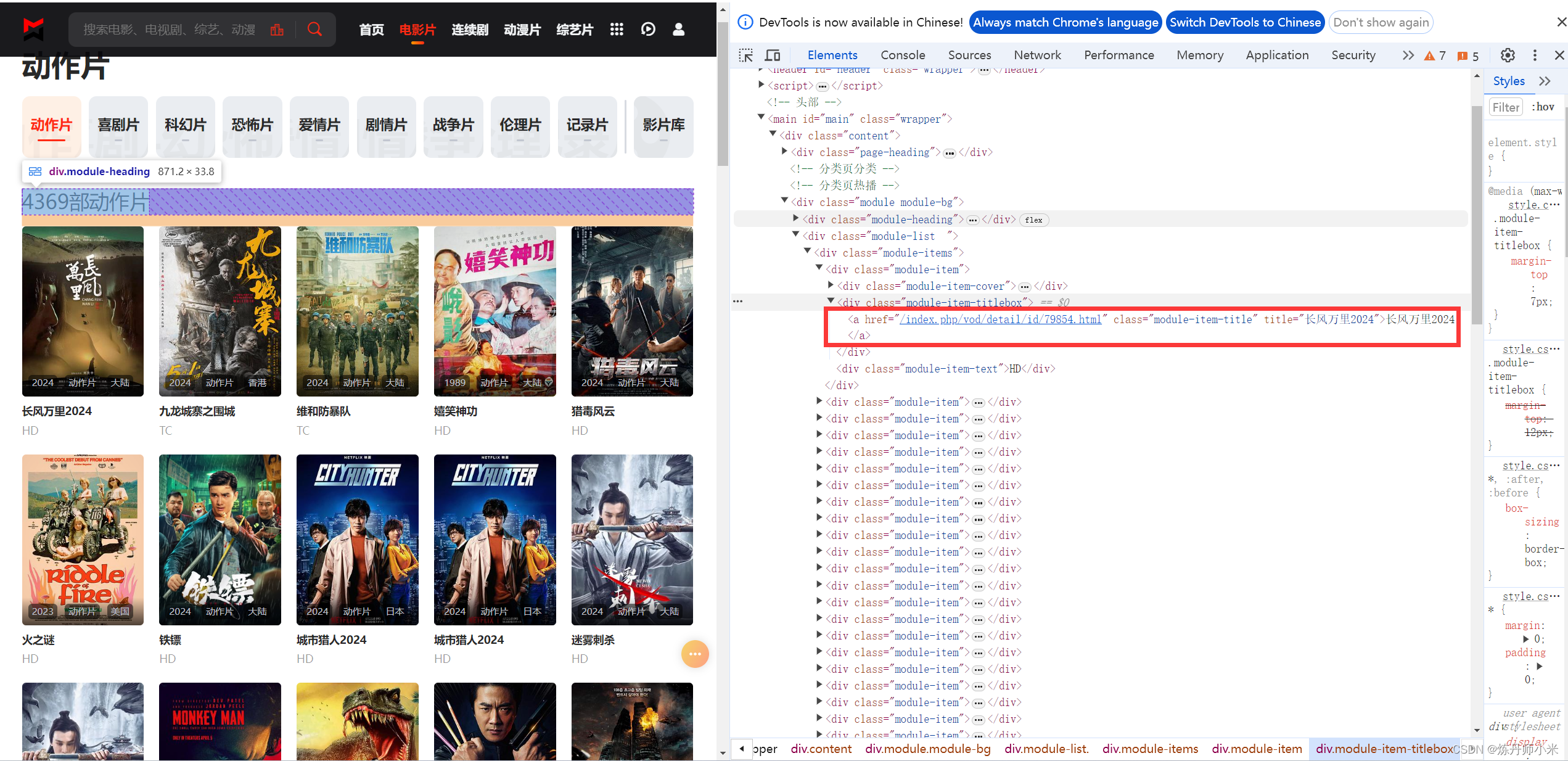
我们对其进行定位,可以看到其在a标签下,class属性为module-item-title,这样我们就可以定位下来视频的详情界面的url了
html_page = requests.get(f"http://www.lzizy9.com/index.php/vod/type/id/6/page/{page}.html", headers=headers)
page_values = BeautifulSoup(html_page.text, "html.parser")
# 找视频播放的链接,其在标签为a,class为"module-item-title"的下面
href_players = [link['href'] for link in page_values.findAll('a', attrs={"class": "module-item-title"})]
4.获取视频的下载url
在视频的详情页,点击播放,然后按F12,从源码中寻找视频的下载的url,然后我们可以定位到这里
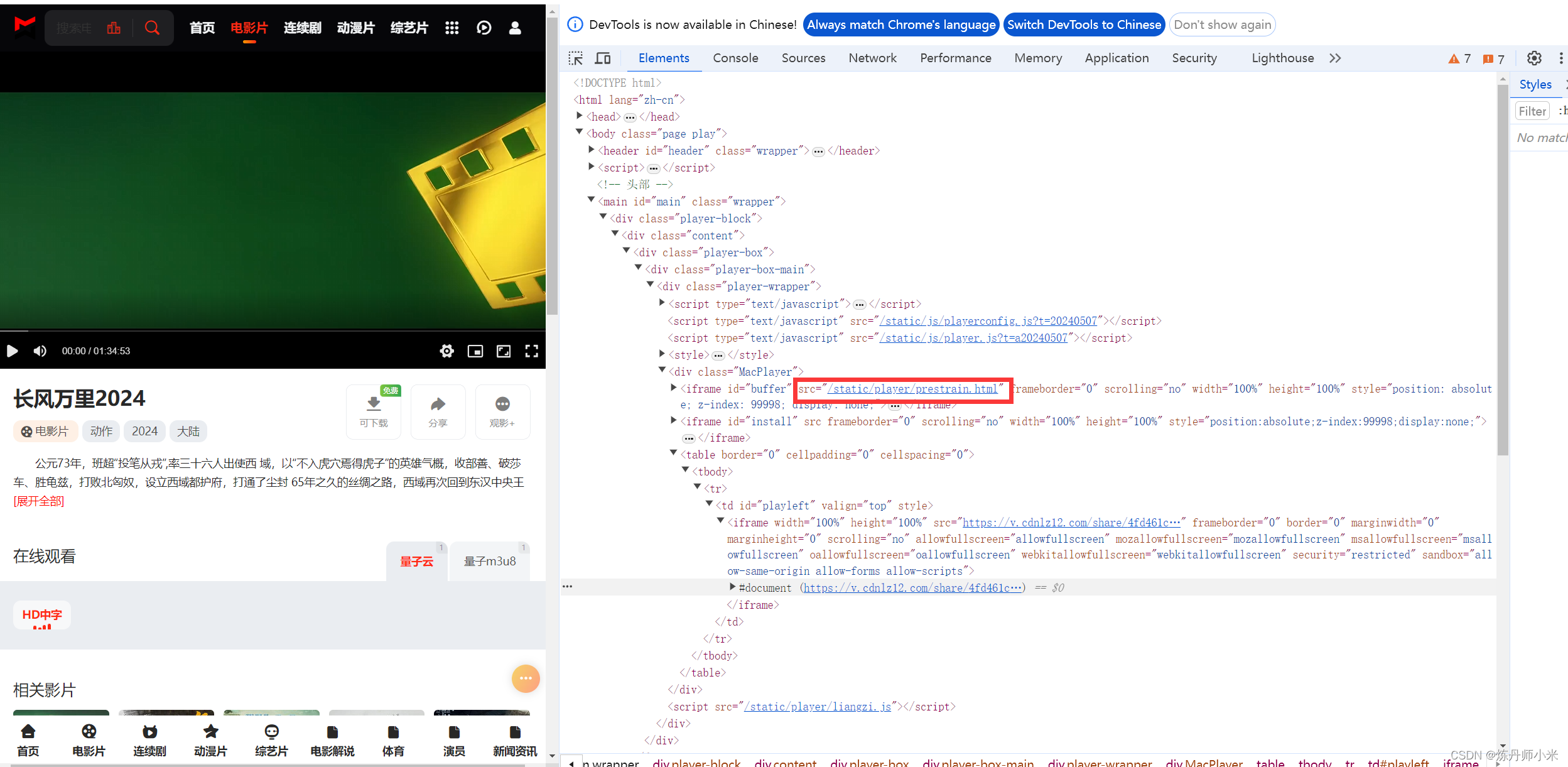
确认是否是可以下载的url的办法就是,我们把这个链接打开,发现其完全是一个播放的视频就是可以下载的url,如下。
网页里面除了一个视频其他的什么都没有。

然后我们定位这个链接的位置,发现其在iframe下面,然后继续使用findAll来寻找这个标签,发现现在返回的是空的。
这是因为这一部分的内容在JavaScript的代码中,为了能让我们看到其中的内容,浏览器会对JavaScript代码进行渲染,得到其中的内容后再呈现到我们面前。然而,爬虫程序无法对HTML文件中的JavaScript代码进行渲染。因此,如果我们的目标镶嵌在JavaScript中,那么我们爬到的数据往往就会缺少目标内容。
因此用下面的方法是无效的了
html_player = requests.get(url, headers=headers)
player_values = BeautifulSoup(html_player.text, "html.parser")
href_video = player_values.findAll('iframe') # 注意这里是没有获取到信息的,因为HTML源码中的iframe标签是js加载的,因此通过requests无法获取,这里大家可以想别的办法获取视频的真实链接
解决方法
requests-html是一个轻量级的HTML解析模块,可以让我们模仿浏览器的行为,隐式地渲染js内容(即打开浏览器,渲染,点击等动作不会在前台展示过程,类似于selenium,只不过更轻量级)
安装模块:
pip install requests-html
代码如下,具体的findALL的寻找方法就不再赘述了,大家可以自行搜索怎么使用findALL来定位要获取的内容。
session = HTMLSession()
first_page = session.get(url)
first_page.html.render(sleep=0.5) # 留出网页渲染的时间
soup = BeautifulSoup(first_page.html.html, features="lxml") # 这里要用lxml
# 注意要关闭session,要不然会不断的打开session,使得资源得不到释放,导致内存爆掉
session.close()
video_url = soup.findAll('td', attrs={'id': 'playleft'})
video_name = soup.findAll('h1', attrs={'class': 'page-title'})
video_url = video_url[0].contents[0]['src']
video_name = video_name[0].contents[0].text
在这里这段代码first_page.html.render(sleep=0.5)可能会报错下载失败,解决方案可以看我的另一篇博客。
三、完整的实现代码
import requests
from bs4 import BeautifulSoup
import os
from requests_html import HTMLSession
import requests_html
import time
if __name__=='__main__':
# 爬取的视频的信息的保存地址
path = "D:\project\爬虫\爬取的视频"
# headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。
# 对反爬虫网页,设置headers的信息可以让我们的爬取操作模拟成浏览器取访问网站。
# 当访问太频繁的时候,容易被服务器禁止访问,这时可以设置多个代理头,通过随机选择某一个代理头来爬取数据,这样可以避免使用同一个头频繁访问的封禁问题。
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
# 通过requests.get方法可以发送GET请求
html_doc = requests.get(f"http://www.lzizy9.com/index.php/vod/type/id/6/page/1.html", headers=headers)
# BeautifulSoup将复杂的HTML文件转化为一个Python对象,使得用户可以更方便地解析、搜索和修改HTML内容。
# html_doc.text获取网页的HTML内容
soup = BeautifulSoup(html_doc.text, 'html.parser')
# 使用findALL提取网页中的信息,其返回的是一个可迭代的对象,具体的用法自行搜索
# 我们要爬取所有的视频,需要识别视频一共有多少页,其返回结果为['/index.php/vod/type/id/6/page/61.html'],根据参数我们得知一共有61页视频
href_values = [link['href'] for link in soup.findAll('a', title='尾页')]
# 获取页数,并将字符串string转化为int整数
end_page = int(href_values[0][30:32])
# 遍历每一页来获取视频的url链接
for page in range(1, end_page+1):
# 此处获取网页信息与上面类似
html_page = requests.get(f"http://www.lzizy9.com/index.php/vod/type/id/6/page/{page}.html", headers=headers)
page_values = BeautifulSoup(html_page.text, "html.parser")
# 找视频播放的链接,其在标签为a,class为"module-item-title"的下面
href_players = [link['href'] for link in page_values.findAll('a', attrs={"class": "module-item-title"})]
for href in href_players:
try:
# 寻找播放界面的规律,发现其除了id号不同以外,其他的都一样,从上面获取的视频播放链接中提取id号
id = href[25:30]
url = f"http://www.lzizy9.com/index.php/vod/play/id/{id}/sid/1/nid/1.html"
# html_player = requests.get(url, headers=headers)
# player_values = BeautifulSoup(html_player.text, "html.parser")
# href_video = player_values.findAll('iframe') # 注意这里是没有获取到信息的,因为HTML源码中的iframe标签是js加载的,因此通过requests无法获取,这里大家可以想别的办法获取视频的真实链接
# print(href_video)
# 由于使用requests无法获得js加载的内容,使用下面的方法可以解决这个问题
session = HTMLSession()
first_page = session.get(url)
first_page.html.render(sleep=0.5) # 留出网页渲染的时间
soup = BeautifulSoup(first_page.html.html, features="lxml") # 这里要用lxml
video_url = soup.findAll('td', attrs={'id': 'playleft'})
video_name = soup.findAll('h1', attrs={'class': 'page-title'})
print(video_url[0].contents[0]['src'])
print(video_name[0].contents[0].text)
video_url = video_url[0].contents[0]['src']
video_name = video_name[0].contents[0].text
with open(os.path.join(path, video_name), 'w', encoding='utf-8') as file:
# 将url写入text文件
file.write(video_url)
except:
print('没有片源')
在这里加了一个try异常处理,因为有的视频没有片源,导致在抓取的时候会报错,加一个异常测试可以自动跳过没有片源的视频继续爬取有片源的视频。
总结
视频的名字和url都保存进了以视频名字命名的text文件中。