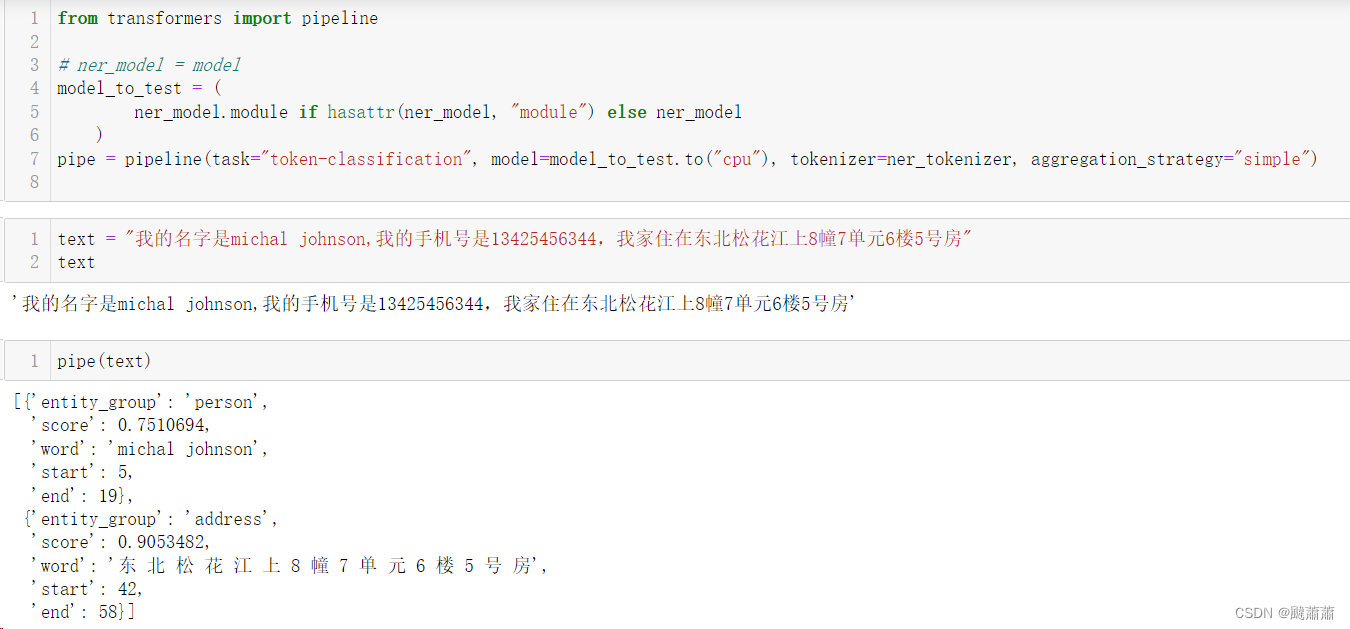
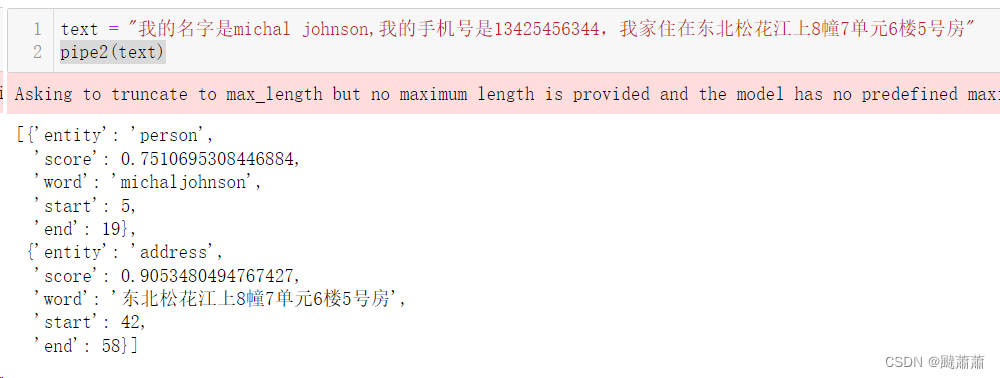
from transformers import AutoTokenizer, AutoModel, AutoConfig
NER_MODEL_PATH = './save_model'
ner_tokenizer = AutoTokenizer. from_pretrained( NER_MODEL_PATH)
ner_config = AutoConfig. from_pretrained( NER_MODEL_PATH)
ner_model = AutoModelForTokenClassification. from_pretrained( NER_MODEL_PATH)
ner_model. eval ( )
import onnxruntime
from itertools import chain
from transformers. onnx. features import FeaturesManager
config = ner_config
tokenizer = ner_tokenizer
model = ner_model
output_onnx_path = "bert-ner.onnx"
onnx_config = FeaturesManager. _SUPPORTED_MODEL_TYPE[ 'bert' ] [ 'sequence-classification' ] ( config)
dummy_inputs = onnx_config. generate_dummy_inputs( tokenizer, framework= 'pt' )
torch. onnx. export(
model,
( dummy_inputs, ) ,
f= output_onnx_path,
input_names= list ( onnx_config. inputs. keys( ) ) ,
output_names= list ( onnx_config. outputs. keys( ) ) ,
dynamic_axes= {
name: axes for name, axes in chain( onnx_config. inputs. items( ) , onnx_config. outputs. items( ) )
} ,
do_constant_folding= True ,
use_external_data_format= onnx_config. use_external_data_format( model. num_parameters( ) ) ,
enable_onnx_checker= True ,
opset_version= onnx_config. default_onnx_opset,
)
from onnxruntime import SessionOptions, GraphOptimizationLevel, InferenceSession
class PipeLineOnnx :
def __init__ ( self, tokenizer, onnx_path, config) :
self. tokenizer = tokenizer
self. config = config
options = SessionOptions( )
options. graph_optimization_level = GraphOptimizationLevel. ORT_ENABLE_ALL
self. session = InferenceSession(
onnx_path, sess_options= options, providers= [ "CPUExecutionProvider" ]
)
self. session. disable_fallback( )
def __call__ ( self, text) :
inputs = self. tokenizer( text, padding= True , truncation= True , return_tensors= 'pt' )
ids = inputs[ "input_ids" ]
inputs_offset = self. tokenizer. encode_plus( text, return_offsets_mapping= True ) . offset_mapping
inputs_detach = { k: v. detach( ) . cpu( ) . numpy( ) for k, v in inputs. items( ) }
output = self. session. run( output_names= [ 'logits' ] , input_feed= inputs_detach) [ 0 ]
logits = torch. tensor( output)
num_labels = len ( self. config. label2id)
active_logits = logits. view( - 1 , num_labels)
softmax = torch. softmax( active_logits, axis= 1 )
scores = torch. max ( softmax, axis= 1 ) . values. cpu( ) . detach( ) . numpy( )
flattened_predictions = torch. argmax( active_logits, axis= 1 )
tokens = self. tokenizer. convert_ids_to_tokens( ids. squeeze( ) . tolist( ) )
token_predictions = [ self. config. id2label[ i] for i in flattened_predictions. cpu( ) . numpy( ) ]
wp_preds = list ( zip ( tokens, token_predictions) )
ner_result = [ { "index" : idx, "word" : i, "entity" : j, "start" : k[ 0 ] , "end" : k[ 1 ] , "score" : s} for idx, ( i, j, k, s) in enumerate ( zip ( tokens, token_predictions, inputs_offset, scores) ) if j != 'O' ]
return post_process( ner_result)
def allow_merge ( a, b) :
a_flag, a_type = a. split( '-' )
b_flag, b_type = b. split( '-' )
if b_flag == 'B' or a_flag == 'E' :
return False
if a_type != b_type:
return False
if ( a_flag, b_flag) in [
( "B" , "I" ) ,
( "B" , "E" ) ,
( "I" , "I" ) ,
( "I" , "E" )
] :
return True
return False
def divide_entities ( ner_results) :
divided_entities = [ ]
current_entity = [ ]
for item in sorted ( ner_results, key= lambda x: x[ 'index' ] ) :
if not current_entity:
current_entity. append( item)
elif allow_merge( current_entity[ - 1 ] [ 'entity' ] , item[ 'entity' ] ) :
current_entity. append( item)
else :
divided_entities. append( current_entity)
current_entity = [ item]
divided_entities. append( current_entity)
return divided_entities
def merge_entities ( same_entities) :
def avg ( scores) :
return sum ( scores) / len ( scores)
return {
'entity' : same_entities[ 0 ] [ 'entity' ] . split( "-" ) [ 1 ] ,
'score' : avg( [ e[ 'score' ] for e in same_entities] ) ,
'word' : '' . join( e[ 'word' ] . replace( '##' , '' ) for e in same_entities) ,
'start' : same_entities[ 0 ] [ 'start' ] ,
'end' : same_entities[ - 1 ] [ 'end' ]
}
def post_process ( ner_results) :
return [ merge_entities( i) for i in divide_entities( ner_results) ]
from transformers import AutoTokenizer, AutoConfig
NER_MODEL_PATH = './save_model'
ner_tokenizer = AutoTokenizer.from_pretrained(NER_MODEL_PATH)
ner_config = AutoConfig.from_pretrained(NER_MODEL_PATH)
pipe2 = PipeLineOnnx(ner_tokenizer, "bert-ner.onnx", config=ner_config)