文章目录
- 第一章 SparkCore
- 1.1. Spark环境部署
- 1.1.1. Spark介绍
- 1.1.1.1. 什么是Spark
- 1.1.1.2. Spark与MapReduce的对比
- 框架对比
- 运行流程对比
- 1.1.1.3. Spark的组件
- 1.1.1.4. Spark的特点
- 1.1.2. Spark的安装部署
- 1.1.2.1. Spark安装包下载
- 1.1.2.2. Spark部署模式介绍
- 1.1.2.3. Local模式部署
- local模式启动spark-shell
- local模式启动pyspark
- 1.1.2.4. Standalone模式
- 集群规划
- 准备条件
- 安装Spark
- 启动spark-shell
- 启动pyspark
- 提交任务到集群运行
- 配置历史日志服务
- 1.1.2.5. YARN模式
- 1.1.3. Spark作业提交
- 1.1.3.1. Standalone模式提交
- 1.1.3.2. YARN-Client模式
- 1.1.3.3. YARN-Cluster模式
- 1.1.3.4. Yarn-Client与Yarn-Cluster的区别
- 1.2. SparkCore编程
- 1.2.1. RDD介绍
- 1.2.1.1. RDD概念
- 1.2.1.2. RDD做了什么
- 1.2.1.3. RDD五大特征
- 1.2.1.4. RDD的弹性
- 1.2.2. RDD创建
- 1.2.2.1. 第三方库安装
- 1.2.2.2. SparkCore程序的结构
- 1.2.2.3. RDD的创建
- 1.4.4. RDD的基本操作
- 1.4.5. RDD的案例
- 1.4.5.1. 案例:词频统计
- 1.4.5.2. 案例:算子实战
- 1.4.5.3. 案例:基站停留时间 TopN
- 1.3. SparkCore高级
- 1.3.1. RDD依赖关系
- 1.3.1.1. 血统与容错
- 1.3.1.2. 窄依赖
- 1.3.1.3. 宽依赖
- 1.3.1.4. 宽窄依赖的区别
- 1.3.2. RDD的任务
- 1.3.2.1. RDD 的任务划分
- 1.3.2.2. DAG 有向无环图
- 1.3.2.3. Stage 划分
- 1.3.2.4. Task 划分
- 1.3.2.5. WebUI 查看
- 1.3.3. RDD的持久化机制
- 1.3.3.1. RDD 缓存
- 1.3.3.2. Checkpoint 检查点机制
- 1.3.3.3. 缓存和检查点的区别
- 1.3.3.4. 什么时候使用cache或checkpoint
- 1.3.4. Accumulator累加器
- 1.3.5. Broadcast广播变量
- 1.3.5.1. 本地变量在 Task 中使用的问题
- 1.3.5.2. 广播变量的原理
- 1.3.5.3. 广播变量的使用
- 1.3.6. Shuffle原理
- 1.3.6.1. 什么是 Shuffle
- 1.3.6.2. ShuffleManager 的实现
- 1.3.6.3. 未经优化的 HashShuffleManager
- 1.3.6.4. 优化后的 HashShuffleManager
- 1.3.6.5. SortShuffleManager
- 1.3.6.6. By-Pass机制
- 1.3.6.7. 常见的 Shuffle 调优参数
第一章 SparkCore
1.1. Spark环境部署
1.1.1. Spark介绍
1.1.1.1. 什么是Spark

Apache Spark 是一种快速、通用、可扩展的大数据分析引擎。于2009年诞生于加州大学伯克利分校AMPLab,2012年开源,2013年6月成为了Apache孵化项目,2014年成为了Apache顶级项目。项目使用Scala语言进行编写,并提供了包括Scala、Python、Java在内的多种语言的编程接口。
- 2012年,开源
- 2013年,Apache孵化项目
- 2014年,Apache顶级项目
- 2014年5月,Spark 1.0.0 版本发布
- 2016年1月,Spark 1.6.0 版本发布
- 2016年7月,Spark 2.0.0 版本发布
- 2020年6月,Spark 3.0.0 版本发布
总结:
Apache Spark就是一个计算引擎,可以对大数据平台上的数据进行计算处理。
1.1.1.2. Spark与MapReduce的对比
在大数据的生态圈中有很多的计算引擎,我们学习过的Hadoop,其中就包括了一个分布式计算引擎MapReduce。那么MapReduce和Spark有什么区别?
框架对比
| MapReduce | Spark | |
|---|---|---|
| 起源时间 | 2005年 | 2009年 |
| 起源地 | MapReduce(Google)、Hadoop(Yahoo) | University of California, Berkeley |
| 数据处理引擎 | Batch | Batch |
| 处理速度 | Slower than Spark and Flink | 100x Faster than Hadoop |
| 编程语言 | Java、C、C++、Ruby、Groovy、Perl、Python | Java、Scala、Python、R |
| 编程模型 | MapReduce | Resilient Distributed Datasets(RDD) |
| 内存管理 | Disk Based | JVM Managed |
| 延迟 | High | Medium |
| 吞吐量 | Medium | High |
| 优化机制 | Manual | Manual |
| API | Low-Level | High-Level |
| 流处理支持 | N/A | Spark Streaming、Structured Streaming |
| SQL支持 | Hive、Impala | Spark SQL |
| Graph支持 | N/A | GraphX |
| 机器学习支持 | N/A | SparkMLlib |
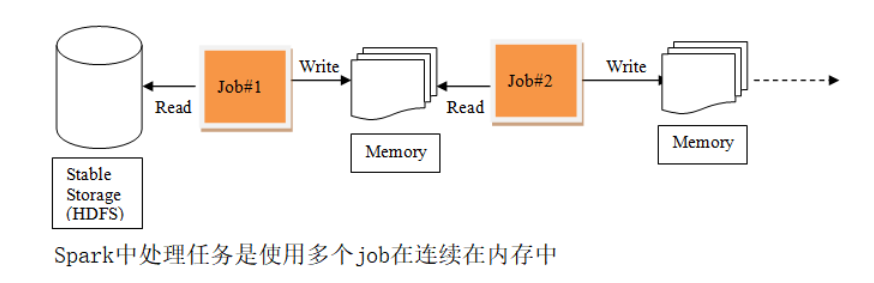
运行流程对比
MapReduce中的运行流程
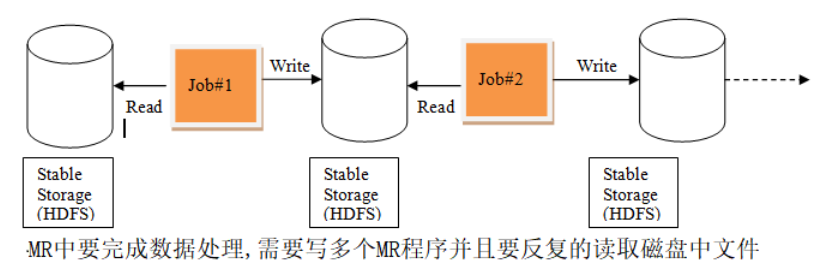
Spark中的运行流程
MapReduce在计算过程中,MapTask会将计算结果落地到磁盘,由ReduceTask去拉取数据继续计算。最终的计算结果也会落地在磁盘上。如果涉及到比较复杂的计算,需要多个Job串联的时候,每一个Job都得从磁盘拉取数据开始。在这个过程中会产生大量的磁盘IO,非常消耗时间。
Spark在计算过程中,会将计算过程中产生的数据保存在内存中,不会落地磁盘。后续的计算任务直接从内存中拉取数据,计算速度非常快。但是Spark比起MapReduce来说,会占用更高的内存。
1.1.1.3. Spark的组件
| Spark组件 | 组件的描述 |
|---|---|
| Spark Core | 实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。 Spark Core中还包含了对弹性分布式数据集的API定义。 弹性分布式数据集:Resilient Distributed Dataset,简称RDD |
| Spark SQL | 是Spark用来操作结构化数据的程序包。 通过Spark SQL,我们可以使用SQL或者Apache Hive版本的HQL来查询数据。 Spark SQL支持多种数据源,比如Hive表、Parquet、CSV、JSON等。 |
| Spark Streaming | 是Spark提供的对实时数据进行流式计算的组件。 提供了用来操作数据流的API,并且与Spark Core中的RDD API高度对应。 |
| Structured Streaming | 结构化流,是一个构建在Spark SQL引擎上的可伸缩、可容错的流式处理引擎。 在内部,默认情况下,结构化流式处理查询使用微批次处理引擎进行处理。 该引擎将数据流作为一系列小批处理作业进行处理, 从而实现低致100毫秒的端到端延迟,并且只保证一次容错。 |
| Spark MLlib | 提供常见的机器学习功能的程序库。 包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。 |
| Spark GraphX | 在Spark基础上提供了一站式的数据解决方案,可以高效的完成t图建算的完整流水作业。 GraphX是用于图计算和并行图计算的Spark API。 通过引入弹性分布式属性图(Resilient Distributed Property Graph、 移动顶点和边都带有属性的有向多重图),拓展了Spark RDD。 |
1.1.1.4. Spark的特点

-
Simple
简单。Spark支持Java、Python和Scala的API,还支持超过80种高级算法,是用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便的在这些Shell中使用Spark集群来验证解决问题的方法。
-
Fast
快速。与Hadoop的MapReduce相比,Spark基于内存的计算要快100倍以上,基于磁盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
-
Scalable
可伸缩性。在遇到计算资源不足的时候,可以简简单单的通过扩展集群规模来实现计算能力的扩展。
-
Unified
统一性。Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming、Structured Streaming)、机器学习(Spark MLlib)、图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
1.1.2. Spark的安装部署
1.1.2.1. Spark安装包下载
在安装部署Spark的时候,首先需要下载Spark的安装包。在下载的时候,推荐到官网进行下载。
Spark的官网地址:http://spark.apache.org
TIPS:
Apache所有的顶级项目的官网地址都是固定的格式:项目名称.apache.org
例如:Hadoop是Apache的顶级项目,因此Hadoop的官网地址就是 http://hadoop.apache.org
Spark也是Apache的顶级项目,因此Spark的官网地址就是 http://spark.apache.org
由此可以推测出其他的顶级项目的官网,例如Hive的官网就是 http://hive.apache.org
 | 01. 打开Spark的官网,默认显示主页。点击上方的Download按钮,跳转到下载页面。 |
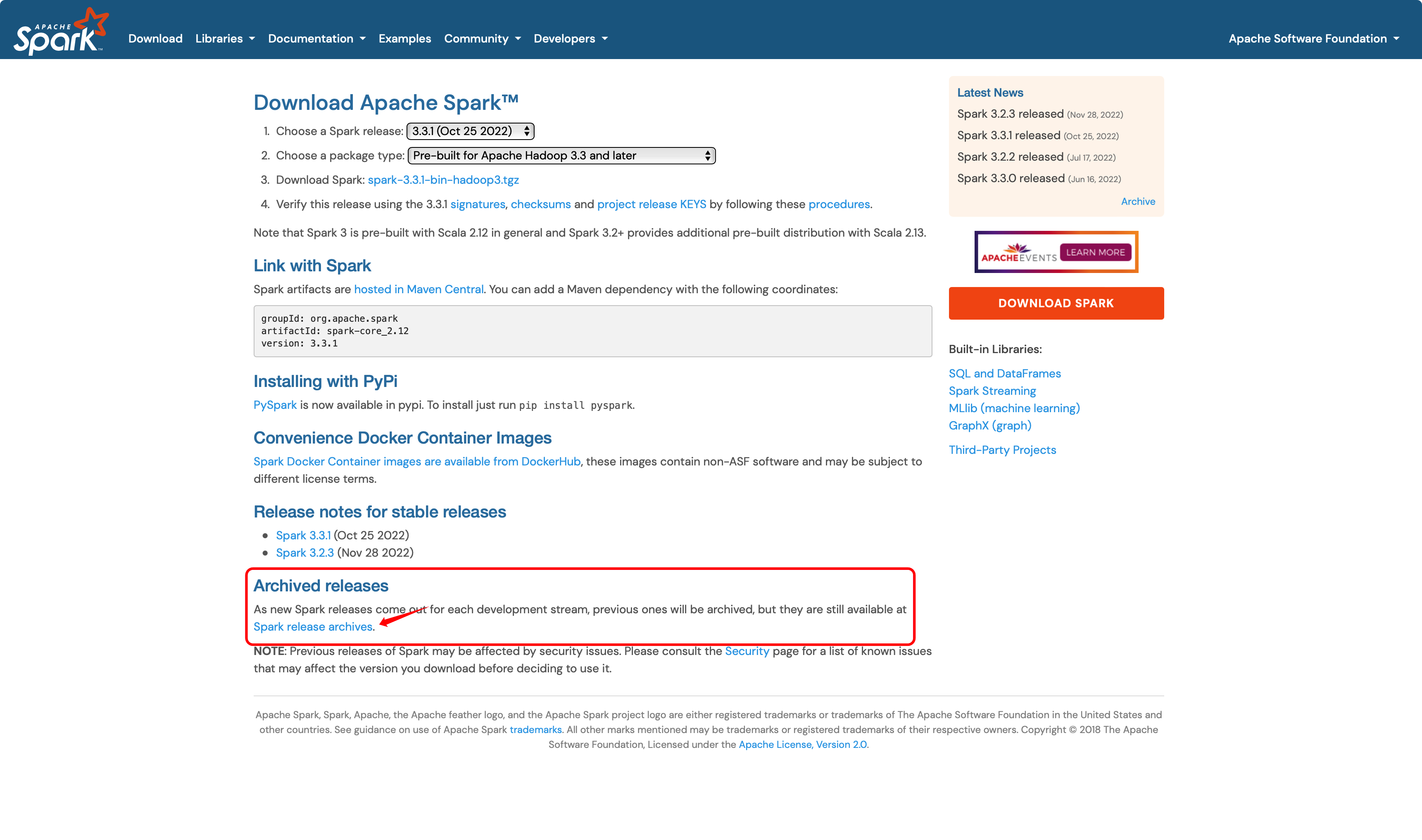 | 02. 官网上显示的是最新的3.3.1版本的下载。如果想要下载历史的版本,需要点击图中圈起来的“Spark release archives” |
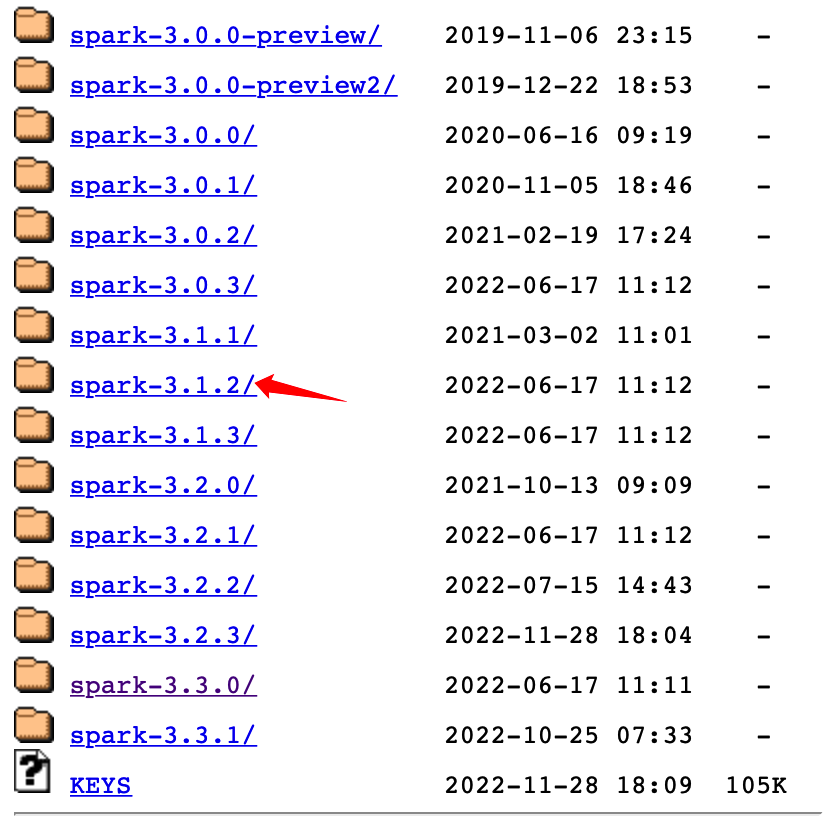 | 03. 找到指定的版本,点击进去即可。在这里我们选择下载3.1.2的版本 |
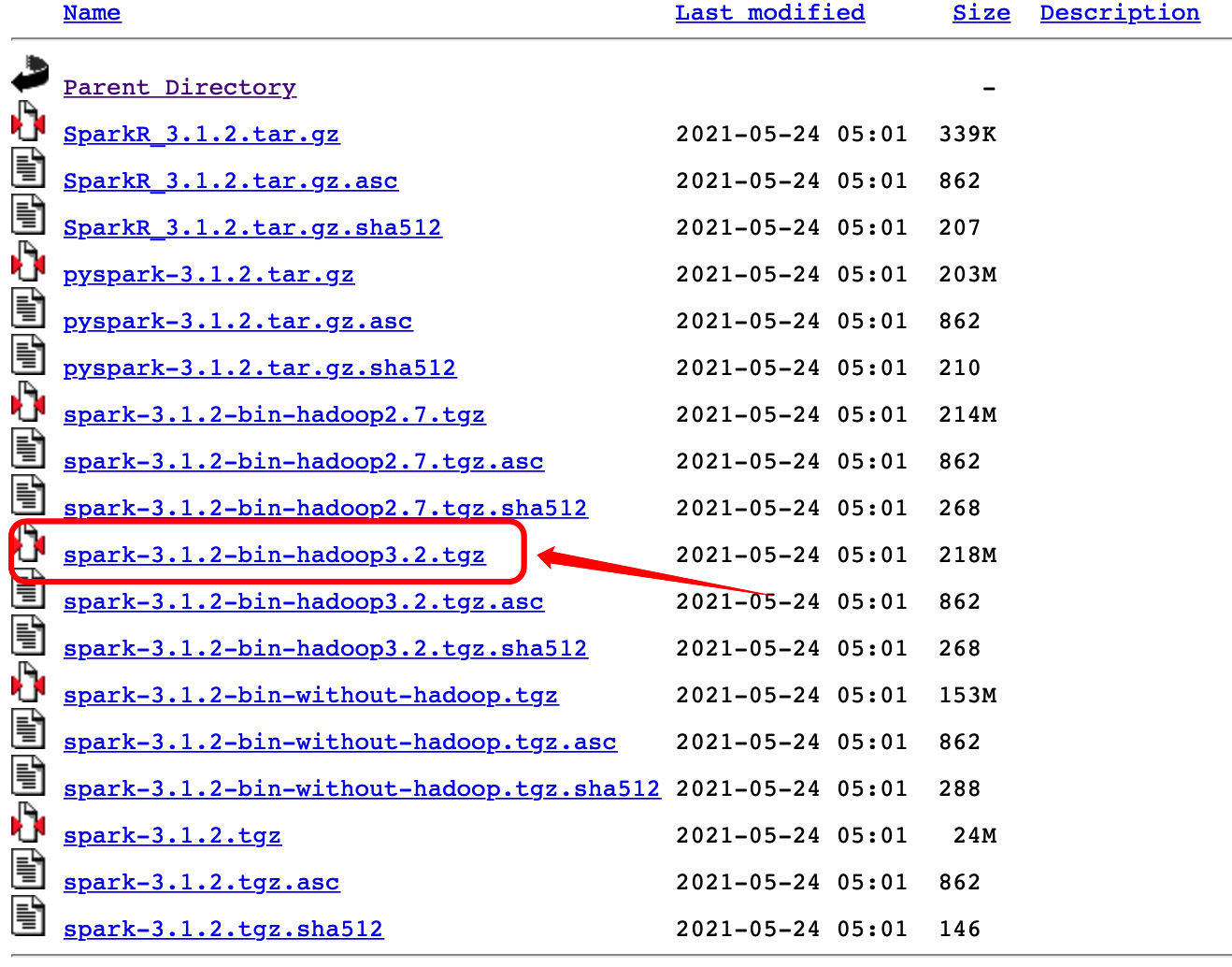 | 04. 点击如图所示的文件进行下载即可。 |
Spark安装包命名说明:
在上述第4步中,可以发现Spark提供了很多的文件。在下载Spark的时候,一定要选择到正确的安装包。
pyspark-3.1.2.tar.gz:
我们的课程体系是Python体系,指的是使用Python语言来操作Spark。这里的pyspark只是一个用来使用python来操作Spark的第三方组件,也可以直接使用pip来安装。这里不去下载。
spark-3.1.2-bin-hadoop3.2.tgz:
Spark只是一个计算引擎,并不负责数据的存储。很多时候我们需要使用Spark处理的数据是存储于HDFS之上的,而且Spark的运行模式中,也可以使用YARN来做资源的调度(SparkOnYARN)。因此Spark对Hadoop是有要求的这里的命名中的hadoop3.2指的就是这个版本是直接支持Hadoop3.2及其以上的版本的,可以直接对接HDFS、YARN。
最后,懒人直达版!点我下载!
1.1.2.2. Spark部署模式介绍
在部署Spark的时候,可以分为不同的模式,大体来说可以有如下几种模式:
-
Local模式:
即本地模式,在这种模式下,没有分布式的思想,所有的工作都在一个节点上完成。在这个机器上开启一个独立的进程工作,其中会开启指定数量的线程,来模拟分布式的思想,完成计算的任务。通常情况下只是用来做本地的测试工作、验证工作。
-
Standalone模式:
Standalone是Spark内置的资源调度框架,在这种模式下,Spark中的各个角色以独立的进程存在,如Master、Worker等。支持完全分布式模式。
-
YARN模式:
YARN是大数据生态圈中的一个资源调度框架,Spark也是可以基于YARN进行资源调度,完成计算任务的。在这种模式下,Spark中的各个角色都运行在YARN的Container内。
Spark常见的部署模式为Standalone模式与YARN模式,因为这两种模式下可以支持完全分布式集群,可以充分利用集群中所有机器的性能完成计算任务。同时也可以基于Spark的可伸缩性,当计算资源不足的时候,只需要简简单单的扩展节点,即可拓展计算能力。当然,除了Standalone和YARN模式之外,还有其他的资源调度框架,例如:Mesos、Kubernetes等,而Spark也是支持这样的资源调度框架的。
1.1.2.3. Local模式部署
Local模式不需要怎么搭建,直接将Spark的安装包解压出来即可使用。
在Local模式下,没有集群的概念,没有分布式的思想,所有的计算工作都在一台节点上完成。在这种模式下,Spark会启动一个单独的进程来执行任务。在这个进程中,会启动若干数量的线程,模拟分布式的思想,完成计算的任务。而这个线程的数量是可以设置的:
- local : 开启一个线程,相当于local[1]。
- local[N] : 自己设定线程的数量为N个,例如local[2]就表示使用2个线程。
- local[*] : 按照CPU的核数来设置线程数量。
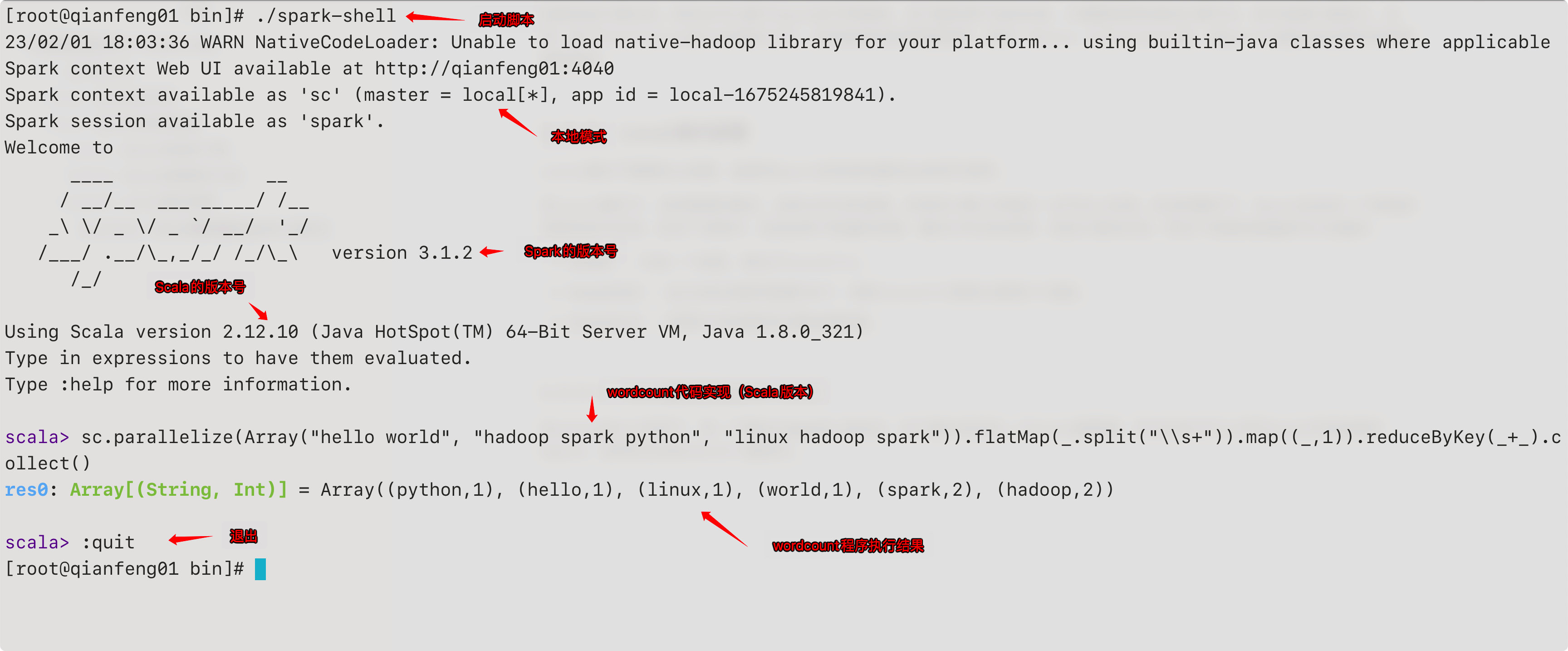
local模式启动spark-shell
在spark的bin目录下,有一个脚本为spark-shell,这个脚本会启动一个Scala解释器,可以在命令行上书写Scala代码来操作Spark,这种交互式的shell了解即可。
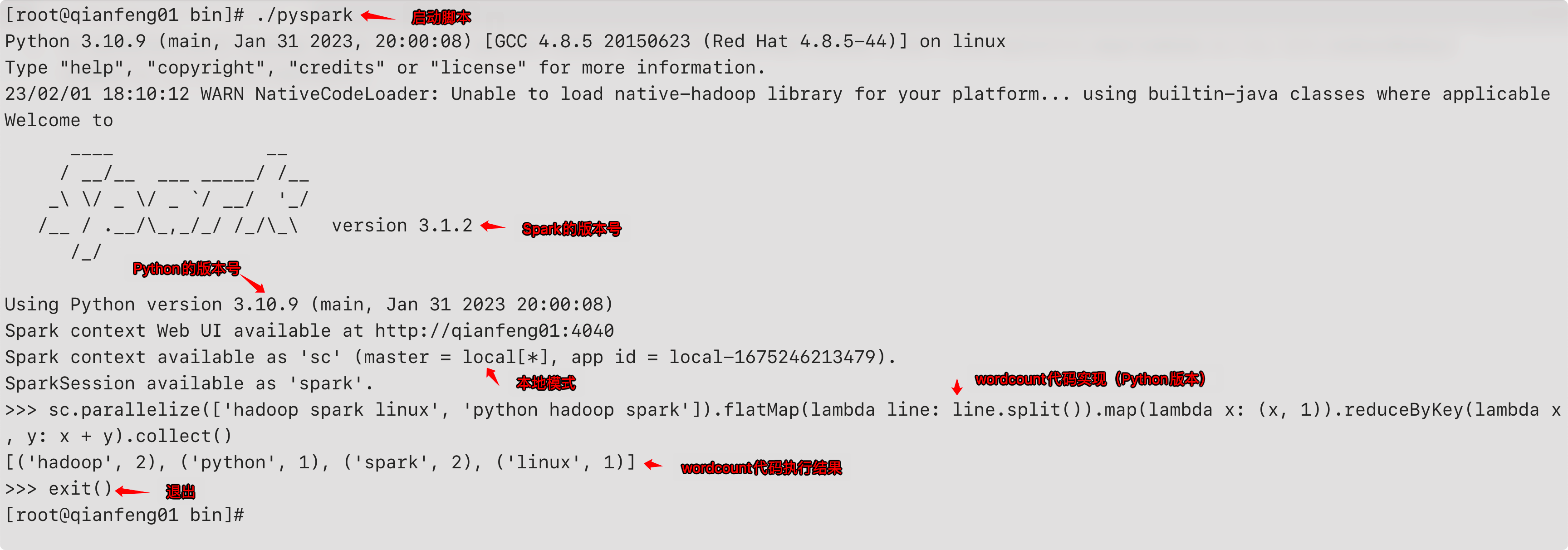
local模式启动pyspark
在spark的bin目录下,有一个脚本为pyspark,这个脚本会启动一个Python解释器,可以在命令行上书写Python代码来操作Spark
需要注意:这里的pyspark只是一个脚本的名字,与我们后续要使用的PySpark库是不同的。
1.1.2.4. Standalone模式
Spark在运行的时候,会存在几个角色,其中最重要的是这几个:
- **Client:**客户端进程。负责提交作业到Master。
- **Master:**主控节点。负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
- **Worker:**工作节点、从节点。负责管理本节点上的资源,定期向Master汇报心跳,接收Master的命令,启动Executor。
- **Driver:**作业的主进程。负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler和TaskScheduler。
- DAGScheduler:实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中。
- TaskScheduler:实现Task分配到Executor上执行
- **Executor:**计算真正执行的地方。一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task。
Standalone模式是Spark自身节点运行的集群模式,也就是所谓的独立部署模式。Spark的Standalone模式体现了非常经典的Master-Slave模式。在Standalone模式下,Master和Worker都会单独的存在于一个进程去执行。
集群规划
| Master | Worker | |
|---|---|---|
| qianfeng01(192.168.10.101) | yes | yes |
| qianfeng02(192.168.10.102) | yes | |
| qianfeng02(192.168.10.103) | yes |
准备条件
在搭建Spark集群的时候,需要准备的条件有如下几种:
- 节点之间时间同步
- 节点之间免密登录
- 每一个节点的防火墙关闭
- 每一个节点安装JDK8
安装Spark
-
解压Spark安装包到指定的软件安装路径。
-
通过SSH工具将下载好的Spark的安装包上传到Linux。
-
使用tar命令进行解压,将其解压到 /usr/local 目录下。
# 解压 tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C /usr/local # 解压之后的文件夹名字太长了,不方便后续的使用,修改解压之后的文件夹的名字 mv /usr/local/spark-3.1.2-bin-hadoop3.2 /usr/local/spark-3.1.2 -
配置环境变量
export SPARK_HOME=/usr/local/spark-3.1.2 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
-
-
修改配置文件:workers
在这个文件中定义Spark集群中所有的Worker节点是谁。这个文件是不存在的,在Spark的安装路径下的
conf文件夹中有一个叫做workers.template的模板文件,需要对这个文件进行重命名,在此模板文件上进行修改。# 进入Spark的配置文件所在的目录 cd /usr/local/spark-3.1.2 # 修改workers.template模板文件的命名 mv workers.template workers # 修改这个文件,在其中添加需要指定的worker节点 vi workers # 注意:这个文件中默认包含了一个localhost,这个一定要删除掉! qianfeng01 qianfeng02 qianfeng03 -
修改配置文件:spark-env.sh
在这个文件中定义Spark集群运行时环境所需要依赖的环境。这个文件是不存在的,在Spark的安装路径下的
conf文件夹中有一个叫做spark-env.sh.template的模板文件,需要对这个文件进行重新命名,在此模板文件上进行修改。# 进入Spark的配置文件所在的目录 cd /usr/local/spark-3.1.2 # 修改spark-env.sh.template模板文件的命名 mv spark-env.sh.template spark-env.sh # 修改这个文件,在其中添加如下配置 export JAVA_HOME=/usr/local/jdk export HADOOP_CONF_DIR=/usr/local/hadoop-3.3.1/etc/hadoop export YARN_CONF_DIR=/usr/local/hadoop-3.3.1/etc/hadoop SPARK_MASTER_HOST=qianfeng01 SPARK_MASTER_PORT=7077 -
修改启停脚本
# Spark集群的启停脚本存放于$SPARK_HOME的sbin目录下 # 启动脚本: start-all.sh 停止脚本: stop-all.sh # 但是这两个脚本与Hadoop中的脚本名字冲突了,因此在这里将Spark的启停脚本的名字修改一下 cd /usr/local/spark-3.1.2/sbin mv start-all.sh start-spark-all.sh mv stop-all.sh stop-spark-all.sh -
分发配置到其他节点
# 切换到/usr/local的路径下 cd /usr/local scp -r spark-3.1.2 qianfeng02:$PWD scp -r spark-3.1.2 qianfeng03:$PWD -
启动集群
# 启动集群 ./start-spark-all.sh -
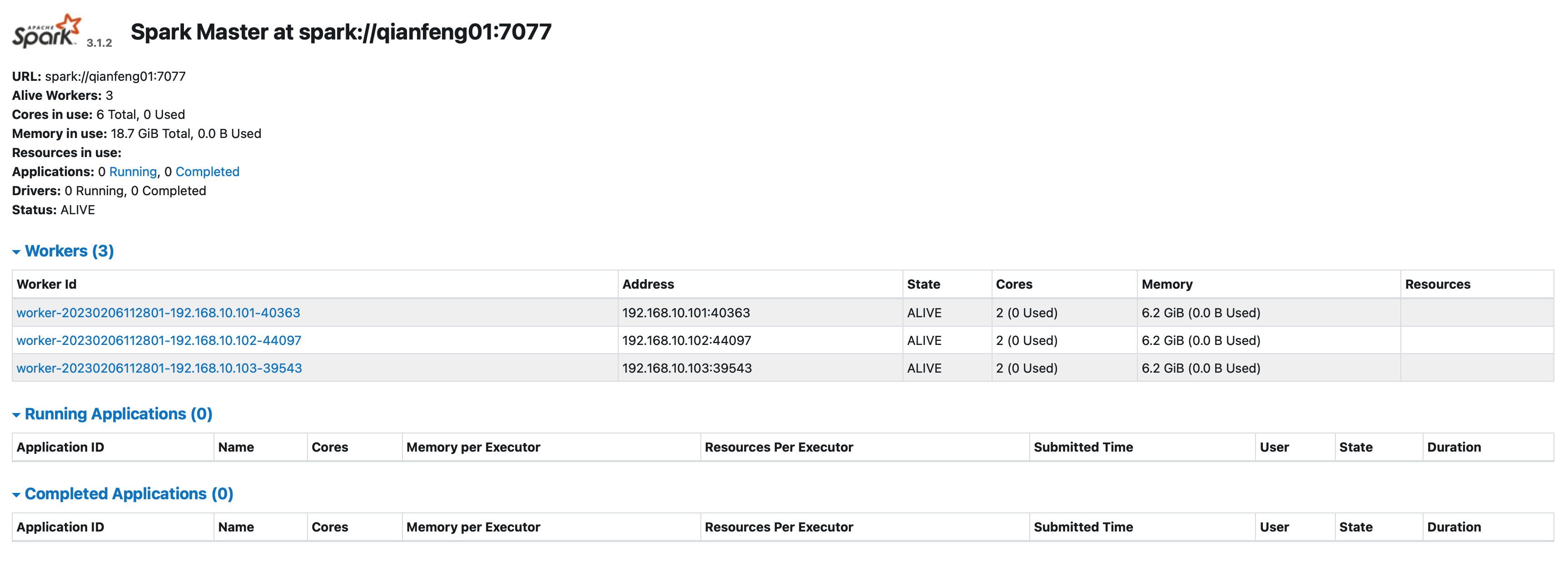
查看WebUI
与Hadoop类似,Spark在启动起来之后,可以使用WebUI查看集群的信息。使用的端口是8080端口。
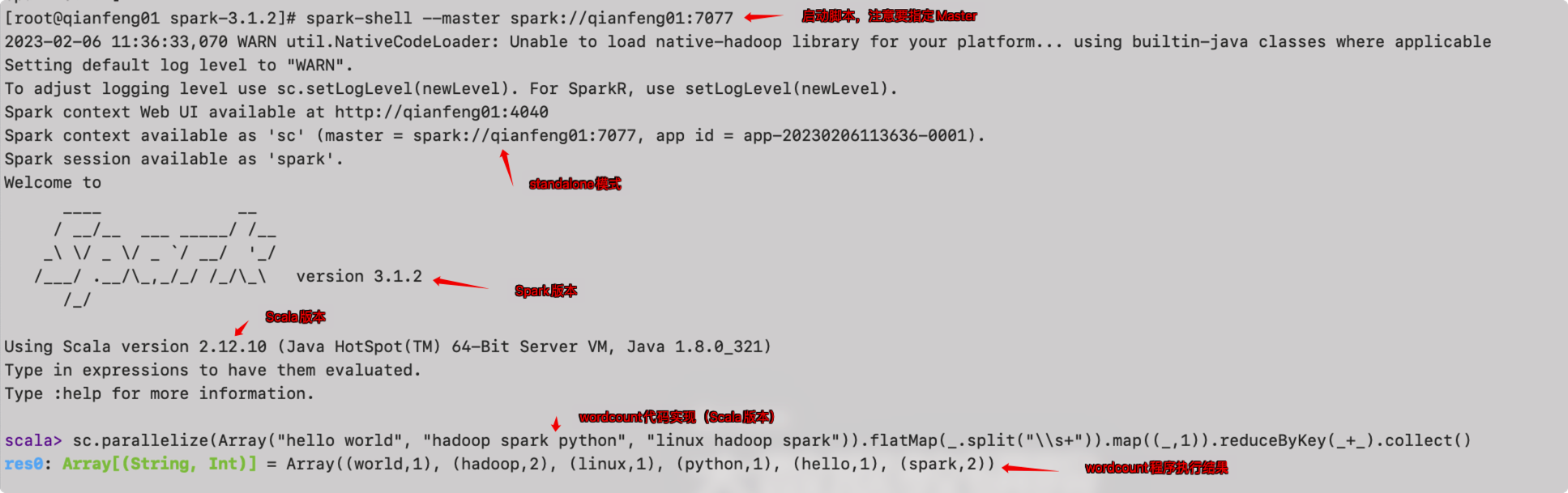
启动spark-shell
在spark的bin目录下,有一个脚本为spark-shell,这个脚本会启动一个Scala解释器,可以在命令行上书写Scala代码来操作Spark,这种交互式的shell了解即可。
注意:启动的时候,需要指定--master spark://qianfeng01:7077来指定Master,否则启动的依然是local模式。
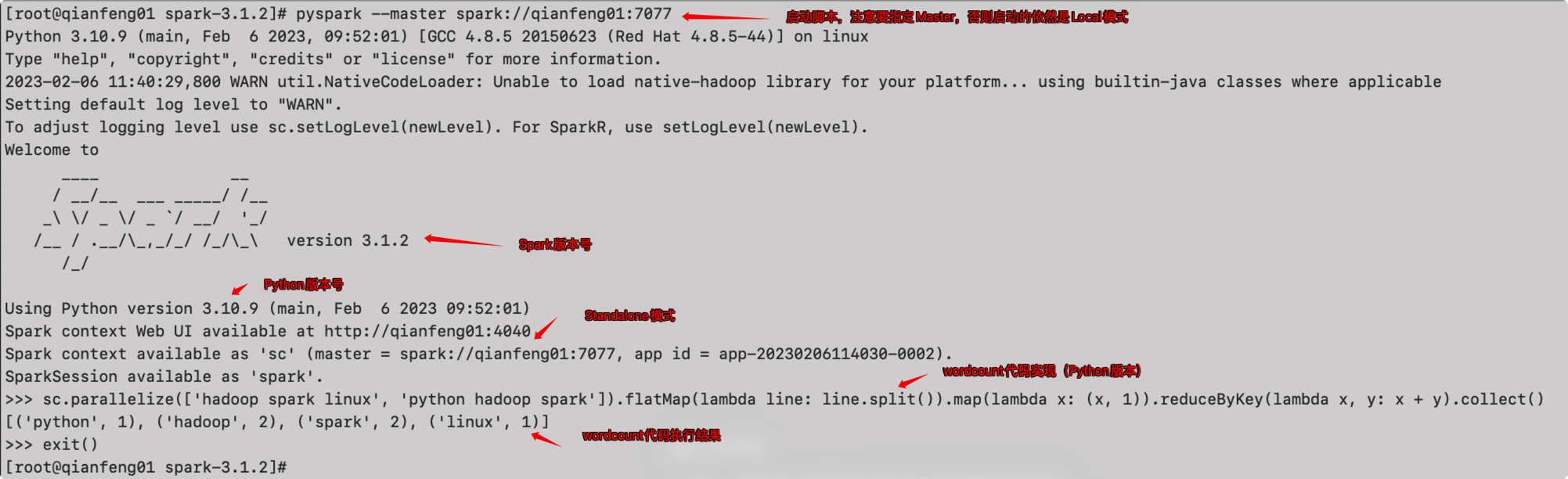
启动pyspark
在spark的bin目录下,有一个脚本为pyspark,这个脚本会启动一个Python解释器,可以在命令行上书写Python代码来操作Spark
注意:这里的pyspark只是一个脚本的名字,与我们后续要使用的PySpark库是不同的。
注意:启动的时候,需要指定--master spark://qianfeng01:7077来指定Master,否则启动的依然是local模式。
提交任务到集群运行
Spark集群已经部署完成,我们可以在解释器中完成小批量的任务的开发,但是涉及到较大的任务处理,直接在解释器中写代码的话就非常不方便了。这个时候,我们就需要使用自己的工具来书写代码。例如用IDEA编写Java、Scala的代码,用PyCharm编写Python的代码。但是编写好的代码如何提交到Spark集群去运行呢?
Spark提供了一个spark-submit的脚本,可以让我们提交自己的代码到集群去运行。同时还可以去指定提交时候的一些参数。
-
Java、Scala代码
Java和Scala的代码需要打成一个jar包去执行,因此在执行的时候需要指定这个包

- Python代码

配置历史日志服务
Spark任务在执行的过程中,我们可以在WEB UI上看到任务执行的细节。但是如果这个任务已经执行结束了,那么我们将无法在页面上看到历史任务的运行情况,所以在开发时都会配置历史服务器来记录任务运行情况。
-
修改spark.defaults.conf.template文件,重命名为spark.defaults.conf
cd /usr/local/spark-3.1.2/conf mv spark.defaults.conf.template spark.default.conf -
修改spark.defaults.conf文件,配置日志存储路径
spark.eventLog.enabled true spark.eventLog.dir hdfs://qianfeng01:9820/directoryspark.eventLog.dir 历史日志保存的位置,因此需要首先在HDFS上创建这个路径:hdfs dfs -mkdir /directory
-
修改spark-env.sh文件,添加日志配置
export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://qianfeng01:9820/directory -Dspark.history.retainedApplications=30 "参数一:Web UI访问的端口号位18080
参数二:指定历史服务器日志保存路径
参数三:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
注意:
上述配置的历史服务器是非HA模式的Hadoop,如果是HA模式的Hadoop,需要将HDFS的路径信息修改即可,例如:
spark.eventLog.dir hdfs://supercluster/directory
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://qianfeng01:9820/directory
-Dspark.history.retainedApplications=30
" -
分发配置文件
cd /usr/local/spark-3.1.2 scp -r conf qianfeng02:$PWD scp -r conf qianfeng03:$PWD -
重新启动集群和历史服务
stop-spark-all.sh start-spark-all.sh start-history-server.sh -
重新执行任务
spark-submit \ --master spark://qianfeng01:7077 \ /usr/local/spark-3.1.2/examples/src/main/python/pi.py 100 -
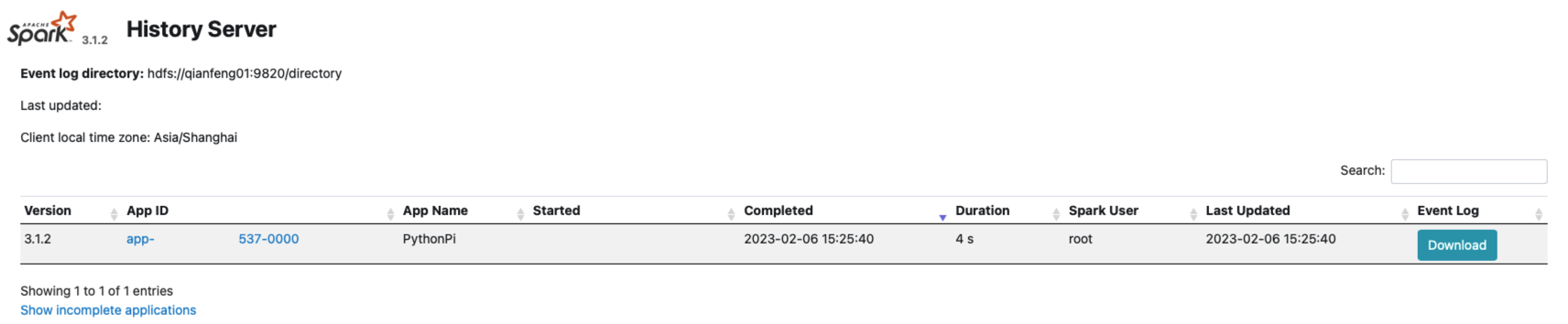
查看历史服务 http://qianfeng01:18080
1.1.2.5. YARN模式
独立部署(Standalone)模式是由Spark自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是Spark主要是计算框架,而并不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以可以使用Hadoop生态中的YARN进行资源调度。
其实所谓的YARN模式,其实就是使用YARN来进行Spark计算任务的资源调度。并没有什么搭建的过程,Standalone模式搭建完成之后即可。不过在这里,如果要使用YARN来进行资源调度的话,还是需要进行一点修改操作的。
修改Hadoop配置文件中的yarn-site.xml文件
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
修改完成之后,将这个文件分发到不同的节点,然后重启YARN即可。
1.1.3. Spark作业提交
Spark是一个计算框架,我们可以使用代码编写计算程序,使用Spark这个框架对数据进行计算。而Spark虽然是使用Scala这门编程语言来开发的,在支持了Scala作为编程语言的同时,也支持了很多其他的编程语言,例如Python。而且在新的版本中,Spark已经逐渐的将Python作为首选的开发语言了。我们使用python编写好的程序,需要提交到Spark集群中进行执行,此时就需要使用如下的命令来提交代码去运行。
spark提交作业的语法:
spark-submit \
--master <master-url> \
... <other options>
<python file> <application-arguments>
| 参数 | 解释 |
|---|---|
| –class | Spark程序中包含住函数的类。 |
| –master | Spark程序运行的模式(Local、Standalone、YARN) |
| –deploy-mode | master设置为YARN之后,使用的client或者cluster模式 |
| –driver-cores | master设置为YARN之后,设置driver端的cores个数 |
| –driver-memory | master设置为YARN之后,用于设置driver进程的内存(单位G或者M) |
| –num-executors | master设置为YARN之后,用于设置Spark作业共需要多少Executor进程来执行 |
| –executor-memory | 指定每个Executor可用内存(单位G或者M) |
| –total-executor-cores | 指定所有Executor使用的CPU核数 |
| –executor-cores | 指定每个Executor使用的CPU核数 |
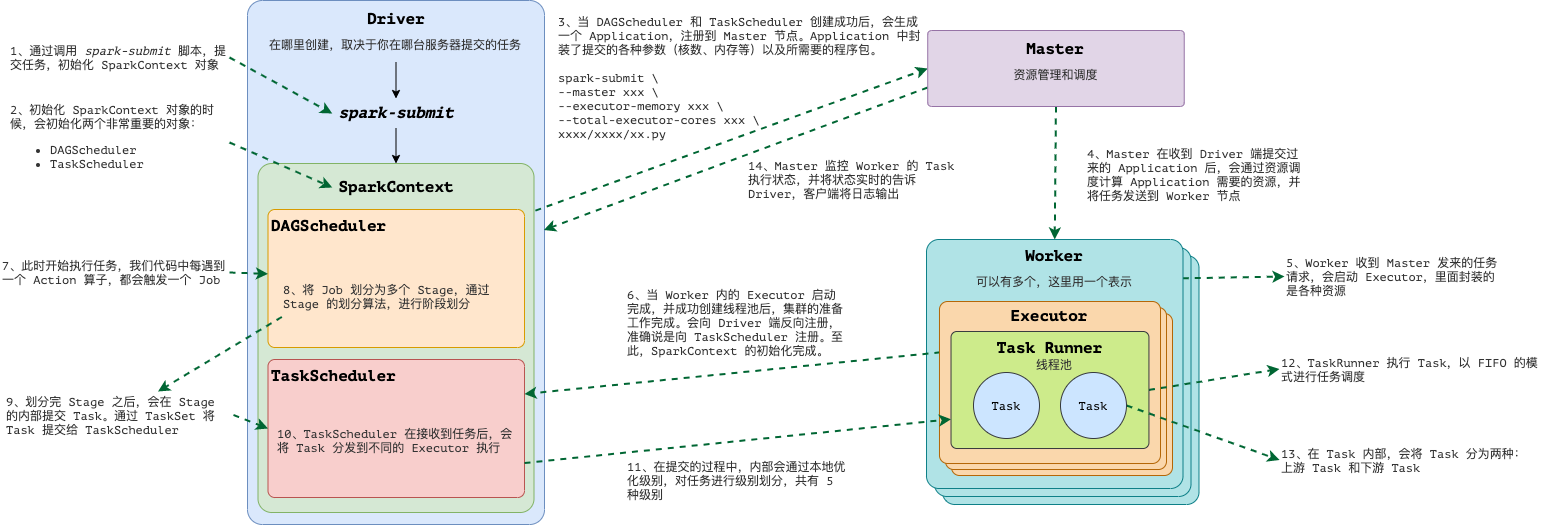
1.1.3.1. Standalone模式提交
spark-submit \
--master spark://qianfeng01:7077 \
/usr/local/spark-3.1.2/examples/src/main/python/pi.py 10
1.1.3.2. YARN-Client模式
spark-submit \
--master yarn \
--deploy-mode client \
--driver-cores 1 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 2 \
/usr/local/spark-3.1.2/examples/src/main/python/pi.py 10
- Spark Yarn Client向Yarn的ResourceManager申请启动Application Master。同时在SparkContext初始化中将创建DAGScheduler和TaskScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend。
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与Yarn-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分配。
- Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container)。
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task。
- Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
客户端的Driver将应用提交给Yarn之后,Yarn会先后启动ApplicationMaster和Executor,另外ApplicationMaster和Executor都是装载在Container里运行,Container默认的内存是1G,ApplicationMaster分配的内存是driver-memory,Executor分配的内存是executor-memory。同时,因为Driver在客户端,所以程序的运行结果可以在客户端显示,Driver以进程名为SparkSubmit的形式存在。
注意:因为是与Client端通信,所以Client不能关闭。
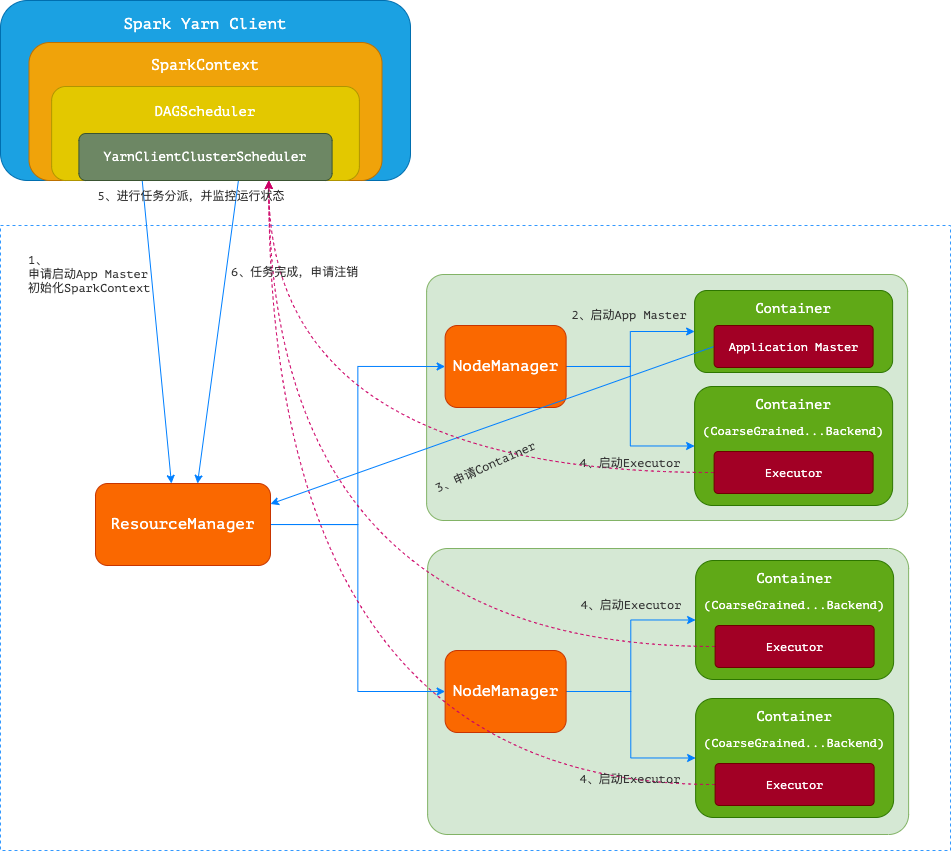
1.1.3.3. YARN-Cluster模式
spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-cores 1 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 2 \
/usr/local/spark-3.1.2/examples/src/main/python/pi.py 10
-
- Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等。
-
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化。
-
- ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束。
-
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,而Executor对象的创建及维护是由CoarseGrainedExecutorBackend负责的,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等。
-
- ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
-
- 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
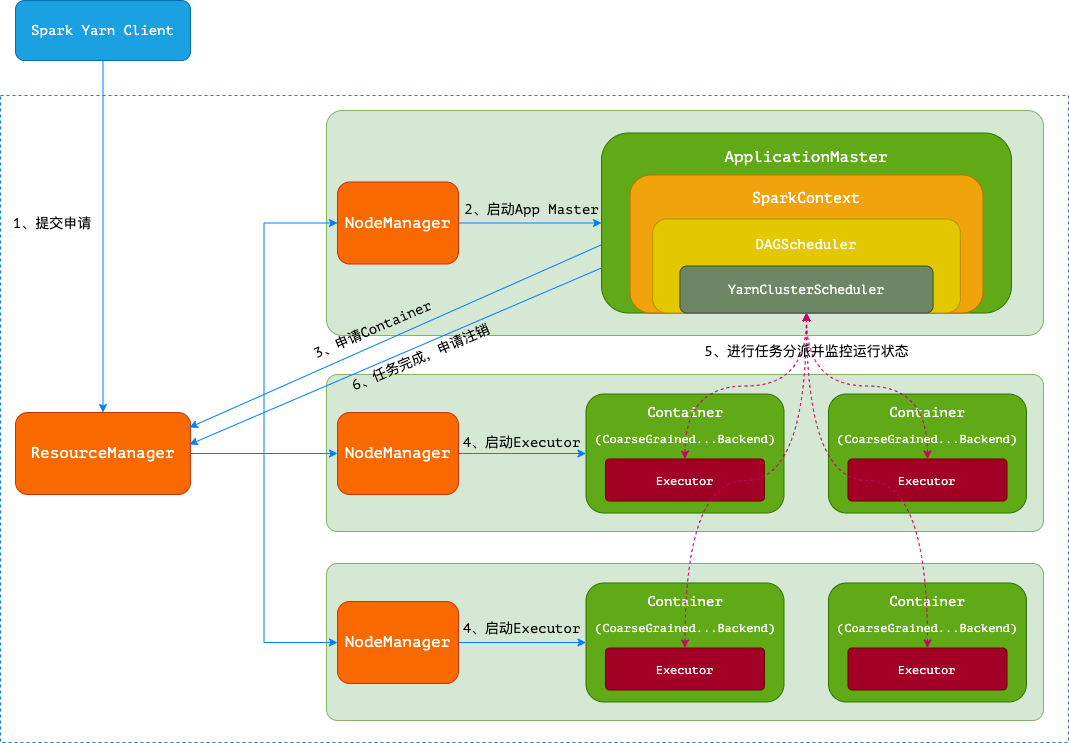
1.1.3.4. Yarn-Client与Yarn-Cluster的区别
- 理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别
- YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业
- YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开
总结:
(1)Yarn-Cluster的Driver是在集群的某一台NM上,但是Yarn-Client就是在RM的机器上;
(2)Driver会和Executors进行通信,所以Yarn_Cluster在提交App之后可以关闭Client,而Yarn-Client不可以;
(3)Yarn-Cluster适合生产环境,Yarn-Client适合交互和调试。
1.2. SparkCore编程
1.2.1. RDD介绍
1.2.1.1. RDD概念
RDD是 Resilient Distributed Dataset 的简称,叫做“弹性分布式数据集”,是在 Spark 中的最基本的数据抽象。它代表了一个不可变、可分区、元素可以并行计算的集合。RDD 具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD 允许用户在执行多个查询时显式的讲工作集缓存在内存中,后续的查询能够重用工作集,这极大地提高了查询的速度。
在之前学习 MapReduce 的时候对数据是并没有进行抽象的,而在 Spark 中对数据进行了抽象,提供了一系列处理方法,也就是说 RDD 是 Spark 计算的基石,为用户屏蔽了底层对数据的复杂的抽象和处理,为用户提供了一组方便的数据转换和求值的方法。
现在开发的过程中都是面向对象的编程思想,那么我们创建类的时候,会对类封装一些属性和方法,那么创建出来的对象就具备着这些属性和方法,类也属于对数据的抽象。而 Spark 中的 RDD 就是对操作数据的一个抽象。
- 弹性:
- 存储的弹性:内存与磁盘的自动切换
- 容错的弹性:数据丢失可以自动恢复
- 计算的弹性:计算出错重试机制
- 分片的弹性:可以根据需求重新分片
- **分布式:**数据存储在大数据集群的不同节点上
- **数据集:**RDD 封装的是计算逻辑,并不保存数据
- **数据抽象:**RDD 是一个抽象类,需要子类具体实现
- **不可变:**RDD 封装的计算逻辑是不可变的。想要改变的话,只能产生新的 RDD,在新的 RDD 中封装新的计算逻辑
- **可分区:**可以进行并行计算
总结:
在 Spark 中,对数据的所有操作不外乎是创建 RDD、转换已有的 RDD、调用 RDD 操作进行求值。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。RDD 具有数据流模型的特点:自动容错、位置感知性调度、可伸缩性。RDD 允许用户在执行多个查询时显式的将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
1.2.1.2. RDD做了什么
从计算的角度来讲,数据处理过程中需要计算资源(CPU & 内存)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务分发到已经分配资源的计算节点上,按照指定的计算模型进行数据计算。最后得到计算结果。
RDD 是 Spark 框架中用于数据处理的核心模块,例如在 SparkShell 中执行如下命令:
sc.textFile("hdfs://qianfeng01:9820/spark/wc-in") \
.flatMap(lambda x: x.split()) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda x, y: x + y) \
.saveAsTextFile('hdfs://qianfeng01:9820/spark/wc-out')
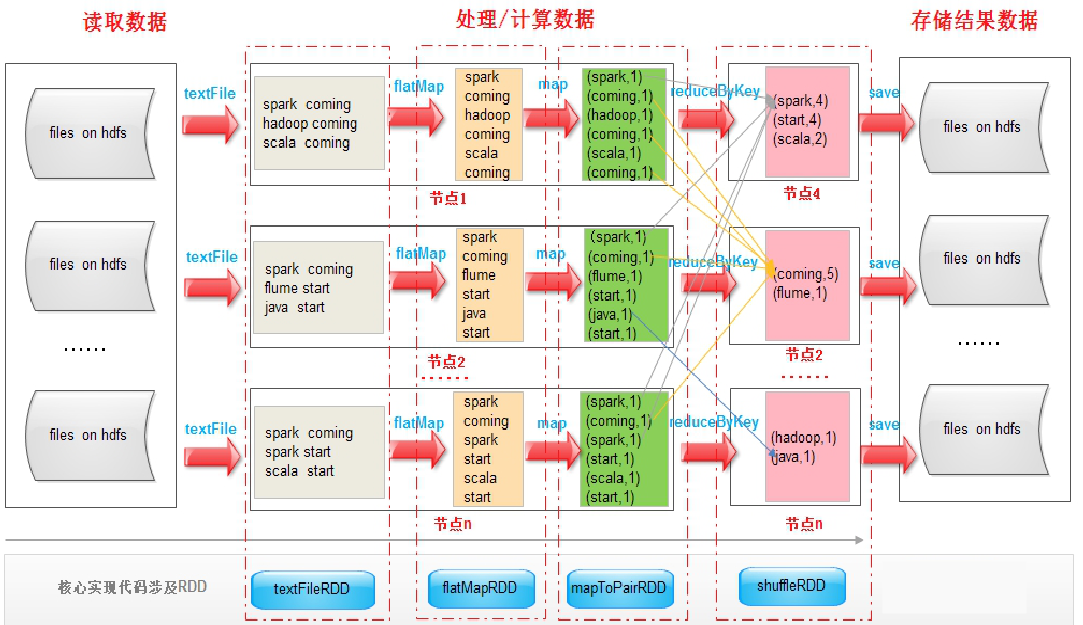
从以上的流程可以看出 RDD 在整个流程中,主要是用于将逻辑进行封装。
RDD 的创建 -> RDD 的转换 -> RDD 的行动(输出数据)
1.2.1.3. RDD五大特征
在 RDD 的源码中提供了 RDD 的特性说明:

-
一组分区:
即数据集的基本组成单位。 对于RDD来说,每个分区都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分区个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。 RDD数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。 -
一个计算每个分区的函数:
Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。 Spark在计算时,是使用分区函数对每一个分区进行计算 -
RDD 之间的依赖关系:
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。 RDD是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个RDD建立依赖关系 -
一个 Partitioner,即 RDD 的分片函数:
当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分区数量,也决定了parent RDD Shuffle输出时的分片数量。 当数据为KV类型数据时,可以通过设定分区器自定义数据的分区 -
一个列表,存储存取每个 Partition 的优先位置:
对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。 计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
注意事项:RDD 本身是不存储数据的,可以看到 RDD 本身是一个引用数据
1.2.1.4. RDD的弹性
-
自动进行内存和磁盘数据存储的切换
Spark 优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换。
-
基于血统的高效容错机制
在 RDD 进行转换和动作的时候,会形成 RDD 的 Lineage 依赖链,当某一个 RDD 失效的时候,可以通过重新计算上游的 RDD 来重新生成丢失的 RDD 数据。
-
Task 如果失败会自动进行特定次数的重试
RDD 的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是 4 次。
-
Stage 如果失败会自动进行特定次数的重试
如果 Job 的某个 Stage 阶段计算失败,框架也会自动进行任务的重新计算,默认次数也是 4 次。
-
Checkpoint 和 Persist 可主动或被动触发
RDD 可以通过 Persist 持久化将 RDD 缓存到内存或者磁盘,当再次用到该 RDD 时直接读取就行。也可以将 RDD 进行检查点设置,检查点会将数据存储在 HDFS 中,该 RDD 的所有父 RDD 依赖都会被移除。
-
数据调度弹性
Spark 把这个 Job 执行模型抽象为通用的有向无环图 DAG,可以将多个 Stage 的任务串联或并发执行,调度引擎自动处理 Stage 的失败以及 Task 的失败。
总结:
存储的弹性:内存与磁盘的
自动切换容错的弹性:数据丢失可以
自动恢复计算的弹性:计算出错重试机制
分区的弹性:根据需要重新分区
1.2.2. RDD创建
1.2.2.1. 第三方库安装
Spark本身是使用Scala语言来编写的,原生支持Scala、Java编程语言。而我们现在需要使用Python来进行操作,就需要下载安装第三方库pyspark,这个库是Spark官方发布的一个专门使用Python来操作Spark的库,我们直接使用pip就可以安装。
pip install pyspark==3.1.2
**注意:**在安装的时候,一定要与你的Spark的版本是一致的,否则会出现兼容性的问题。
**注意:**你的代码需要在哪里执行,就需要在哪里安装这个库。
例如:
- 你的代码需要在 Windows 本地运行,那就需要在 Windows 上安装 pyspark
- 你的代码需要在 Mac 本地运行,那就需要在 Mac 上安装 pyspark
- 你的代码需要提交到 Linux 虚拟机中运行,那就需要在 Linux 虚拟机上安装 pyspark
**注意:**这里安装的 pyspark 是一个用来操作 Spark 的三方库,并不是 Spark 计算框架。如果需要使用本地模式进行程序的开发,需要在本地配置好 Spark 的环境。
例如:
你在 Windows 中,使用本地模式进行代码的开发,那就需要在 Windows 上安装 Spark,并配置好环境变量。
你在 Mac 中,使用本地模式进行代码的开发,那就需要再 Mac 上安装 Spark,并配置好环境变量。
1.2.2.2. SparkCore程序的结构
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
# SparkCore编程实现
# SparkContext是Spark Core程序的入口,需要导入对应的模块
from pyspark import SparkContext
# 创建SparkContext对象,作为程序的入口
sc = SparkContext(master="local[*]", appName="spark-core")
# 中间的数据处理
# 结束程序,释放资源
sc.stop()
1.2.2.3. RDD的创建
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
# RDD: 弹性分布式数据集,是SparkCore中的基础编程模型
# RDD的创建方式有两种:
# 1、通过数据集合创建
# 2、通过外部文件创建
# 创建SparkContext,作为SparkSQL程序的入口
sc = SparkContext(master="local[*]", appName="rdd")
# 1. 通过数据集合,创建RDD对象
# 此时的RDD描述的就是这三行数据(列表中的一个元素,可以视为一行数据)
rdd1 = sc.parallelize(['hello world', 'python scala java', 'hadoop spark spark'])
rdd1.foreach(lambda e: print(e))
# 2. 通过读取外部文件,创建RDD对象
rdd2 = sc.textFile("../../../sql/people.txt")
rdd2.foreach(lambda e: print(e))
# 3. 可以对RDD描述的数据进行简单处理
rdd3 = rdd2.map(lambda x: x.split(", "))
rdd3.foreach(lambda e: print(e))
# end: 释放资源
sc.stop()
1.4.4. RDD的基本操作
RDD类中封装了很多的函数,可以实现对所描述的数据进行各种的处理。这些函数称为“算子“。在RDD中的算子,被分为两类:
- **转换算子(Transformation):**转换算子可以对数据进行各种各样的扭转,返回值也是一个RDD对象。
- **行动算子(Action):**计算链的最终环节,对前面的各种转换算子进行的操作做最终的处理。
| 转换算子(Transformation) | |
|---|---|
| 算子 | 解释 |
| filter | 对数据进行过滤,保留满足条件的数据 |
| distinct | 对源RDD进行去重后返回一个新的RDD |
| map | 对数据进行映射,使用新的元素替换原来的元素 |
| flatMap | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素 |
| groupByKey | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey | 使用指定的reduce函数,将相同key的值聚合到一起 |
| sortByKey | 在一个(K,V)的RDD上调用,对数据按照 K 进行排序 |
| sortBy | 对数据按照指定的字段进行排序 |
| coalesce | 重新分区,适合于缩小分区数量,用于大数据集过滤之后,提高小数据集的执行效率 |
| repartition | 重新分区,适合于扩大分区,会强制触发 Shuffle 操作 |
| 行动算子(Action) | |
| 算子 | 解释 |
| foreach | 在数据集的每一个元素上,运行函数func进行更新。 |
| count | 返回RDD的元素个数 |
| take | 返回一个由数据集的前n个元素组成的数组 |
| saveAsTextFile | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统 |
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
# 1. 创建SparkContext对象
sc = SparkContext(master="local[*]", appName="rdd")
# 2. 创建RDD
rdd = sc.parallelize(['python Spark hadoop', 'hadoop Linux flink', '123 Spark Python'])
# 3. map:一对一的映射,将每一个单词转换成首字母大写的
rdd1 = rdd.map(lambda x: x.title())
# 4. flatMap:扁平映射,提取出每一个单词
rdd2 = rdd1.flatMap(lambda x: x.split())
# 5. filter:过滤,保留满足条件的数据
rdd3 = rdd2.filter(lambda x: not x.isdigit())
rdd3.foreach(lambda x: print(x))
sc.stop()
1.4.5. RDD的案例
1.4.5.1. 案例:词频统计
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
sc = SparkContext(master="local[*]", appName="wordcount")
sc.textFile("../../../data/words") \ # 读取外部文件
.flatMap(lambda x: x.split()) \ # 扁平映射,将每一行的数据按照空白进行切割,并进行扁平映射
.map(lambda x: (x, 1)) \ # 对每一个单词进行映射,映射为单词与数字1组成的元组
.reduceByKey(lambda x, y: x + y) \ # 将相同单词对应的所有的值聚合到一起,聚合到时候使用加法运算相加
.foreach(lambda x: print(x)) # 遍历输出每一个统计结果
sc.stop()
1.4.5.2. 案例:算子实战
给定数据如下:
班级ID 姓名 年龄 性别 科目 成绩
12 张三 25 男 chinese 50
12 张三 25 男 math 60
12 张三 25 男 english 70
12 李四 20 男 chinese 50
12 李四 20 男 math 50
12 李四 20 男 english 50
12 王芳 19 女 chinese 70
12 王芳 19 女 math 70
12 王芳 19 女 english 70
13 张大三 25 男 chinese 60
13 张大三 25 男 math 60
13 张大三 25 男 english 70
13 李大四 20 男 chinese 50
13 李大四 20 男 math 60
13 李大四 20 男 english 50
13 王小芳 19 女 chinese 70
13 王小芳 19 女 math 80
13 王小芳 19 女 english 70
需求如下:
1. 一共有多少人参加三门考试?
2. 一共有多少个小于20岁的人参加考试?
3. 一共有多个男生参加考试?
4. 13班有多少人参加考试?
5. 语文科目的平均成绩是多少?
6. 12班平均成绩是多少?
7. 全校英语成绩最高分是多少?
8. 13班数学最高成绩是多少?
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
"""
1. 一共有多少人参加三门考试?
2. 一共有多少个小于20岁的人参加考试?
3. 一共有多个男生参加考试?
4. 13班有多少人参加考试?
5. 语文科目的平均成绩是多少?
6. 12班平均成绩是多少?
7. 全校英语成绩最高分是多少?
8. 13班数学最高成绩是多少?
"""
from pyspark import SparkContext
from collections import namedtuple
sc = SparkContext(master="local[*]", appName="exercise")
# 准备工作:对每一行的数据进行转换,字符串 -> 数据模型
student = namedtuple("Student", ["cid", "name", "age", "gender", "subject", "score"])
def map_function(line):
array = line.split()
if len(array) != 6:
return None
return student(array[0], array[1], int(array[2]), array[3], array[4], int(array[5]))
rdd = sc.textFile("./data/score/score").map(map_function).filter(lambda x: x is not None)
# 1. 一共有多少人参加三门考试?
print("===== 1. 一共有多少人参加三门考试? ======")
rdd.map(lambda x: (x.name, 1))\
.reduceByKey(lambda x, y: x + y)\
.filter(lambda x: x[1] == 3)\
.map(lambda x: x[0])\
.foreach(print)
# 2. 一共有多少个小于20岁的人参加考试?
print("===== 2. 一共有多少个小于20岁的人参加考试? ======")
res = rdd.filter(lambda x: x.age < 20)\
.map(lambda x: x.name)\
.distinct()\
.count()
print(res)
# 3. 一共有多个男生参加考试?
print("===== 3. 一共有多个男生参加考试? ======")
res = rdd.filter(lambda x: x.gender == '男')\
.map(lambda x: x.name)\
.distinct()\
.count()
print(res)
# 4. 13班有多少人参加考试?
print("===== 4. 13班有多少人参加考试? ======")
res = rdd.filter(lambda x: x.cid == "13")\
.map(lambda x: x.name)\
.distinct()\
.count()
print(res)
# 5. 语文科目的平均成绩是多少?
print("===== 5. 语文科目的平均成绩是多少? ======")
res = rdd.filter(lambda x: x.subject == "chinese")\
.map(lambda x: (x.score, 1))\
.reduce(lambda x, y: (x[0] + y[0], x[1] + y[1]))
print(res[0] / res[1])
# 6. 12班平均成绩是多少?
print("===== 6. 12班平均成绩是多少? ======")
res = rdd.filter(lambda x: x.cid == "12")\
.map(lambda x: (x.score, 1))\
.reduce(lambda x, y: (x[0] + y[0], x[1] + y[1]))
print(res[0] / res[1])
# 7. 全校英语成绩最高分是多少?
print("===== 7. 全校英语成绩最高分是多少? ======")
res = rdd.filter(lambda x: x.subject == "english")\
.map(lambda x: x.score)\
.max()
print(res)
# 8. 13班数学最高成绩是多少?
print("===== 8. 13班数学最高成绩是多少? ======")
res = rdd.filter(lambda x: x.cid == "13" and x.subject == "math")\
.map(lambda x: x.score)\
.max()
print(res)
sc.stop(
1.4.5.3. 案例:基站停留时间 TopN
根据用户产生日志的信息,在那个基站停留时间最长
19735E1C66.log 这个文件中存储着日志信息
文件组成:手机号,时间戳,基站ID 连接状态(1连接 0断开)
lac_info.txt 这个文件中存储基站信息
文件组成 基站ID, 经,纬度
在一定时间范围内,求所用户经过的所有基站所停留时间最长的Top2
思路:
1.获取用户产生的日志信息并切分
2.用户在基站停留的总时长
3.获取基站的基础信息
4.把经纬度的信息join到用户数据中
5.求出用户在某些基站停留的时间top2
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
def handle_lac_info(lac_line: str) -> tuple:
"""
对文件中的每一行数据进行处理,映射
:param lac_line: 每一条记录
:return: 处理、映射
"""
array = lac_line.split(',')
phone = array[0] # 用户手机号
timestamp = int(array[1]) # 记录的时间戳
lac_id = array[2] # 基站 ID
status = int(array[3]) # 记录状态码:1 代表进入这个基站,0 代表离开这个基站
# 因为我们要统计一个手机号码在这个基站中停留了多长时间,因此需要用离开的时间减去进入的时间
# 可是一行数据中只包含了一种状态和一个时间,没有办法直接做减法
# 解决方案:如果是进入的时间,将 timestamp 修改为负值,最后在累加即可得到停留时间
duration = -timestamp if status == 1 else timestamp
# 数据扭转
return (phone, lac_id), duration
with SparkContext(master='local[*]', appName='exercise') as sc:
# 读取用户数据文件
rdd = sc.textFile('./data/lacduration/log')
# 对其中的数据进行处理
duration_rdd = rdd \
.map(lambda x: handle_lac_info(x)) \
.reduceByKey(lambda x, y: x + y) \
.map(lambda t: (t[0][1], (t[0][0], t[1])))
# 读取基站信息
lac_info = sc.textFile('./data/lacduration/lac_info.txt') \
.map(lambda x: x.split(','))\
.map(lambda t: (t[0], (t[1], t[2])))\
# join
res = duration_rdd.join(lac_info)\
.map(lambda x: (x[1][0][0], (x[0], x[1][1], x[1][0][1])))\
.groupByKey() \
.mapValues(lambda x: [i for i in x])\
.sortBy(lambda x: x[1][2], ascending=False)\
.take(2)
for r in res:
print(r)
1.3. SparkCore高级
1.3.1. RDD依赖关系
1.3.1.1. 血统与容错
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,他可以根据这些信息来重新运算和恢复丢失的数据分区。
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
with SparkContext(master='local[*]', appName='lineage') as sc:
file_rdd = sc.textFile('./data/words')
word_rdd = file_rdd.flatMap(lambda x: x.split())
pair_rdd = word_rdd.map(lambda x: (x, 1))
result_rdd = pair_rdd.reduceByKey(lambda x, y: x + y)
print(result_rdd.collect())

RDD 和它依赖的父 RDD 的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
1.3.1.2. 窄依赖
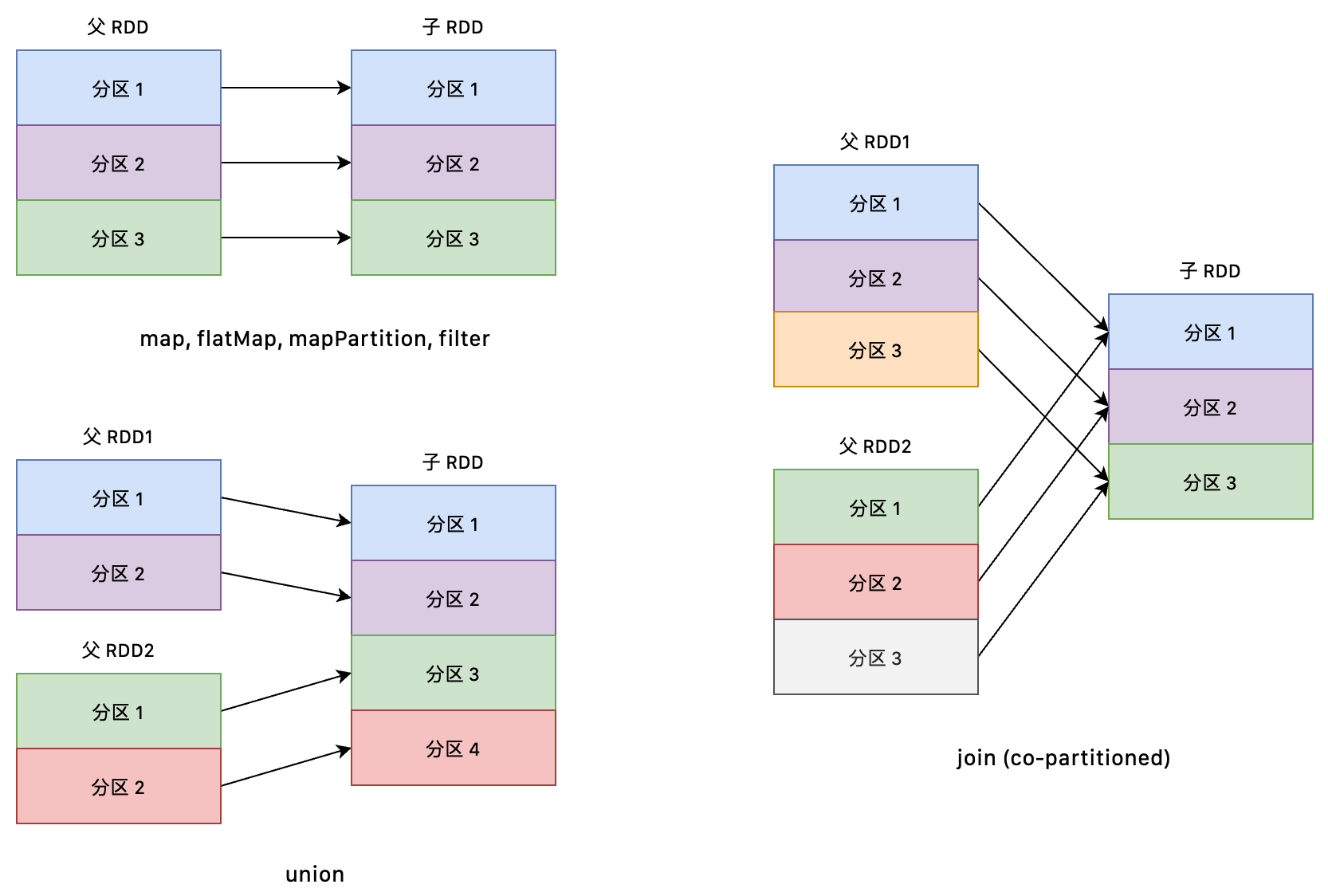
窄依赖:父 RDD 的每个分区只被一个子 RDD 分区使用一次
窄依赖可以分为两种:
- 一对一的依赖,即 OneToOneDependency
- 范围的依赖,即 RangeDependency。这种依赖仅仅被
org.apache.spark.rdd.UnionRDD使用,UnionRDD 是把多个 RDD 合成一个 RDD,这些 RDD 是被拼接而成的,每个父 RDD 的分区的相对顺序不会变,只不过每个父 RDD 在 UnionRDD 中的分区的起始位置不同。
窄依赖的算子包括:map, flatMap, mapPartition, filter, union, join(co-partitioned)等
join 是一个比较特殊的算子,既可以是窄依赖,也可以是宽依赖。当 join 的输入是 co-partitioned,则是窄依赖,否则是宽依赖。或者可以认为 co-partitioned 表示 join 的父 RDD 是经过了 Hash 分区的。
1.3.1.3. 宽依赖
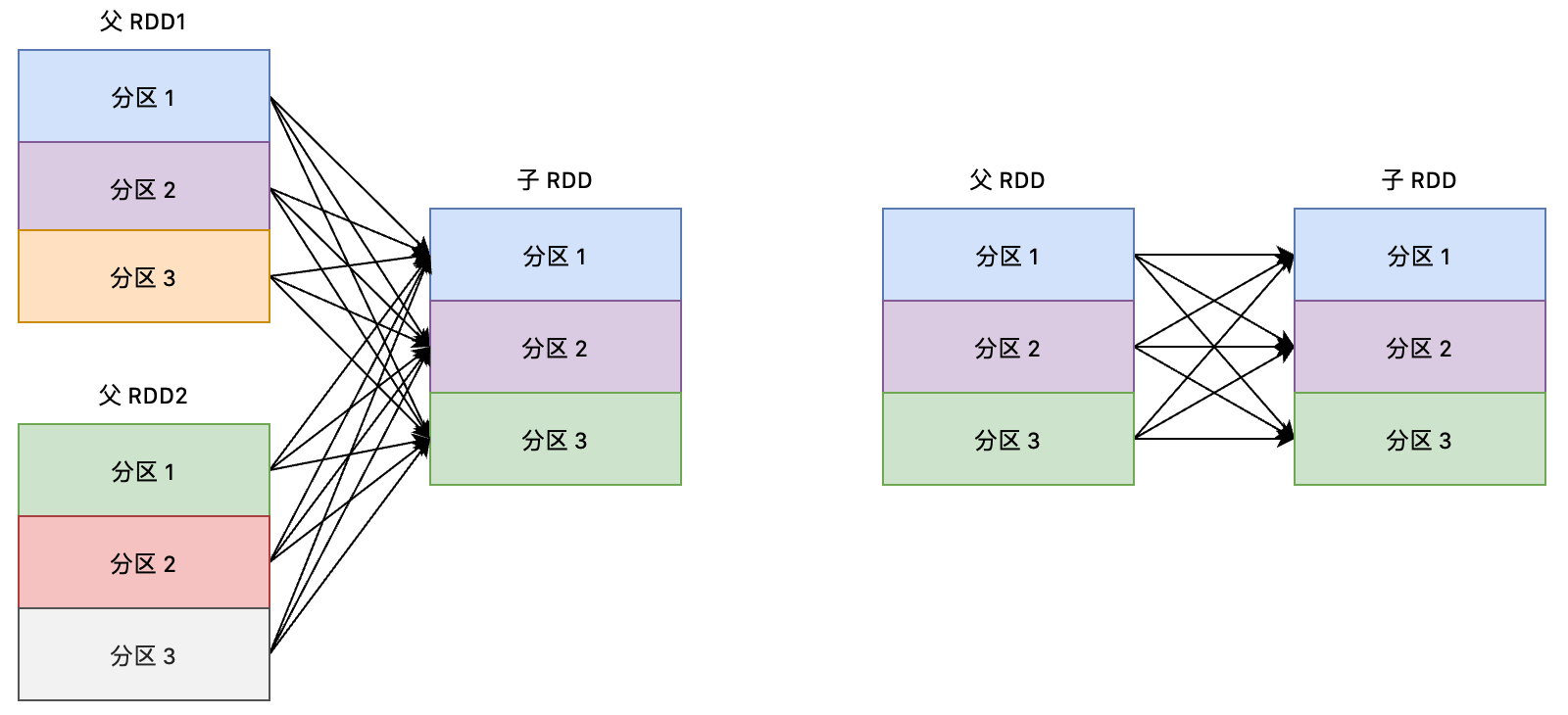
宽依赖:多个子 RDD 的 Partition 会依赖同一个父 RDD 的 Partition。
宽依赖的算子包括:reduceByKey, groupBy, groupByKey, aggregateByKey, distinct, join (join with inputs not co-partitioned) 等
1.3.1.4. 宽窄依赖的区别
宽依赖一定会触发 Shuffle 操作!
在运行过程中需要将同一个父 RDD 的分区的数据传入到不同的子 RDD 分区中。中间可能涉及到在多个节点之间的数据传输。
而窄依赖的每个父 RDD 的分区只会传入到一个子 RDD 分区中,通常可以在一个节点内就可以完成了。
1.3.2. RDD的任务
1.3.2.1. RDD 的任务划分
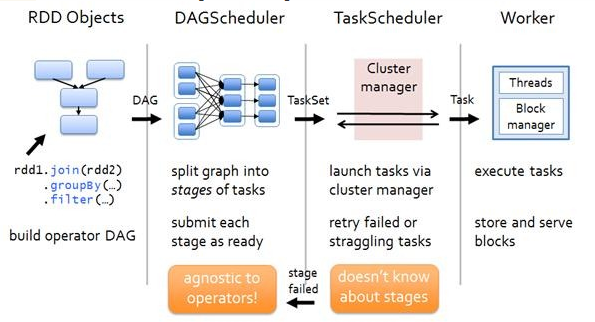
RDD 任务切分中分为:
- **Application:**初始化一个 SparkContext 对象,即生成一个 Application
- **Job:**一个 Action 算子就会生成一个 Job
- **State:**Stage 等于宽依赖的个数相加
- **Task:**一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数
注意事项:Application -> Job -> Stage -> Task 每一层都是 1 对 N 的关系。
1.3.2.2. DAG 有向无环图
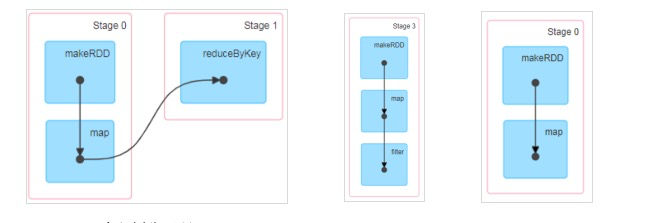
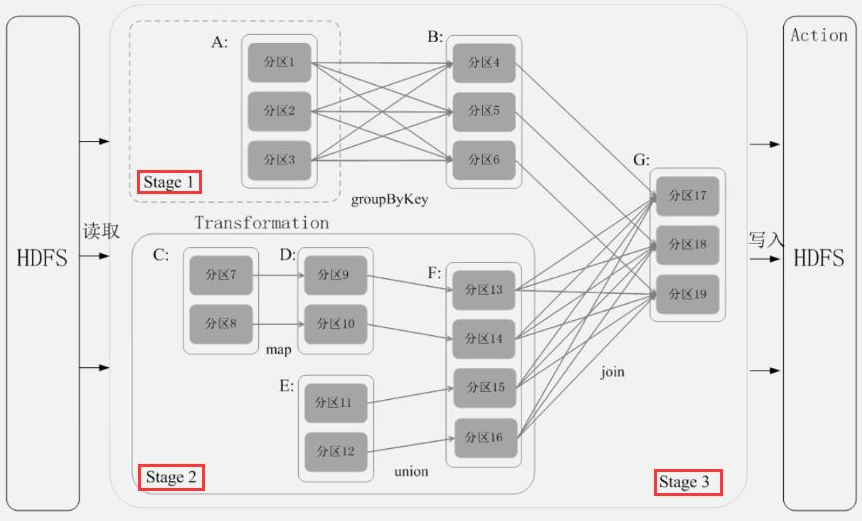
DAG(Directed Acyclic Graph)叫做有向无环图,原始的 RDD 通过一系列的转换就形成了 DAG。根据 RDD 之间的依赖关系的不同,将 DAG 划分成不同的 Stage,对于窄依赖,Partition 的转换处理在 Stage 中完成计算;对于宽依赖,由于有 Shuffle 的存在,只能在 parent RDD 处理完成后,才能开始接下来的计算,因此宽依赖是划分 Stage 的依据。有向无环图是由点和线组成的拓扑图行,该图形具有方向,不会闭环。例如,DAG 记录了 RDD 的转换过程和任务的阶段:
1.3.2.3. Stage 划分
- 从后向前推理,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到 Stage 中。
- 每个 Stage 里面的 Task 的数量是由该 Stage 中最后一个 RDD 的 Partition 数量决定的。
- 最后一个 Stage 里面的人物的类型是 ResultTask,前面所有其他 Stage 里面的任务类型都是 ShuffleMapTask。
- 代表当前 Stage 的算子一定是该 Stage 的最后一个计算步骤。
**总结:**由于 Spark 中的 Stage 的划分是根据 Shuffle 来划分的,而宽依赖必然有 Shuffle 过程。因此可以说 Spark 是根据款窄依赖来划分 Stage 的。
1.3.2.4. Task 划分
输入可能以多个文件的形式存储在 HDFS 上,每个 File 都包含了很多块,称为 Block。
当 Spark 读取这些文件作为输入时,会根据具体数据格式对应的 InputFormat 进行解析,一般是将若干个 Block 合并成一个输入分片,称为 InputSplit,注意 InputSplit 不能跨越文件。
随后将为这些输入分片生成具体的 Task。InputSplit 与 Task 是一一对应的关系。
随后和谐具体的 Task 每个都会被分配到集群上的某个节点的某个 Executor 去执行。
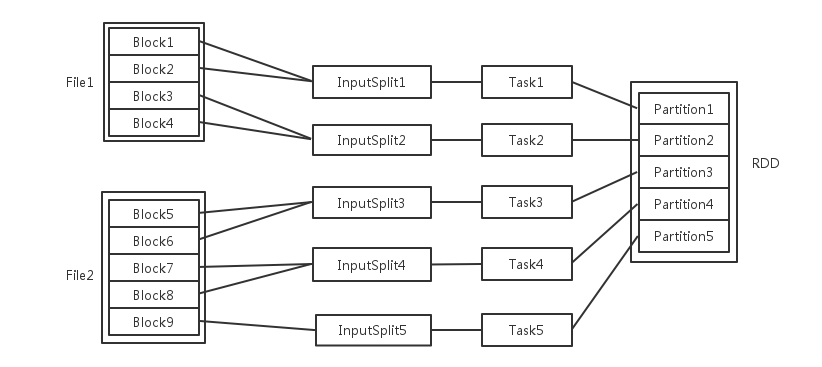
- 每个节点都可以有一个或多个 Executor。
- 每个 Executor 由若干 Core 组成,每个 Executor 的每个 Core 一次只能执行一个 Task。
- 每个 Task 执行的结果就是生成了目标 RDD 的一个 Partition。
**注意:**这里的 Core 是虚拟的,并不是机器的物理 CPU 核心,可以理解为就是 Executor 的一个工作线程。
而 Task 被执行的并发度 = Executor 数目(SPARK_EXECUTOR_INSTANCES)* 每个 Executor 核数(SPARK_EXECUTOR_CORES)
**总结:**RDD 在计算的时候,每个分区都会起一个 Task,所以 RDD 的分区数量决定了总的 Task 数量。
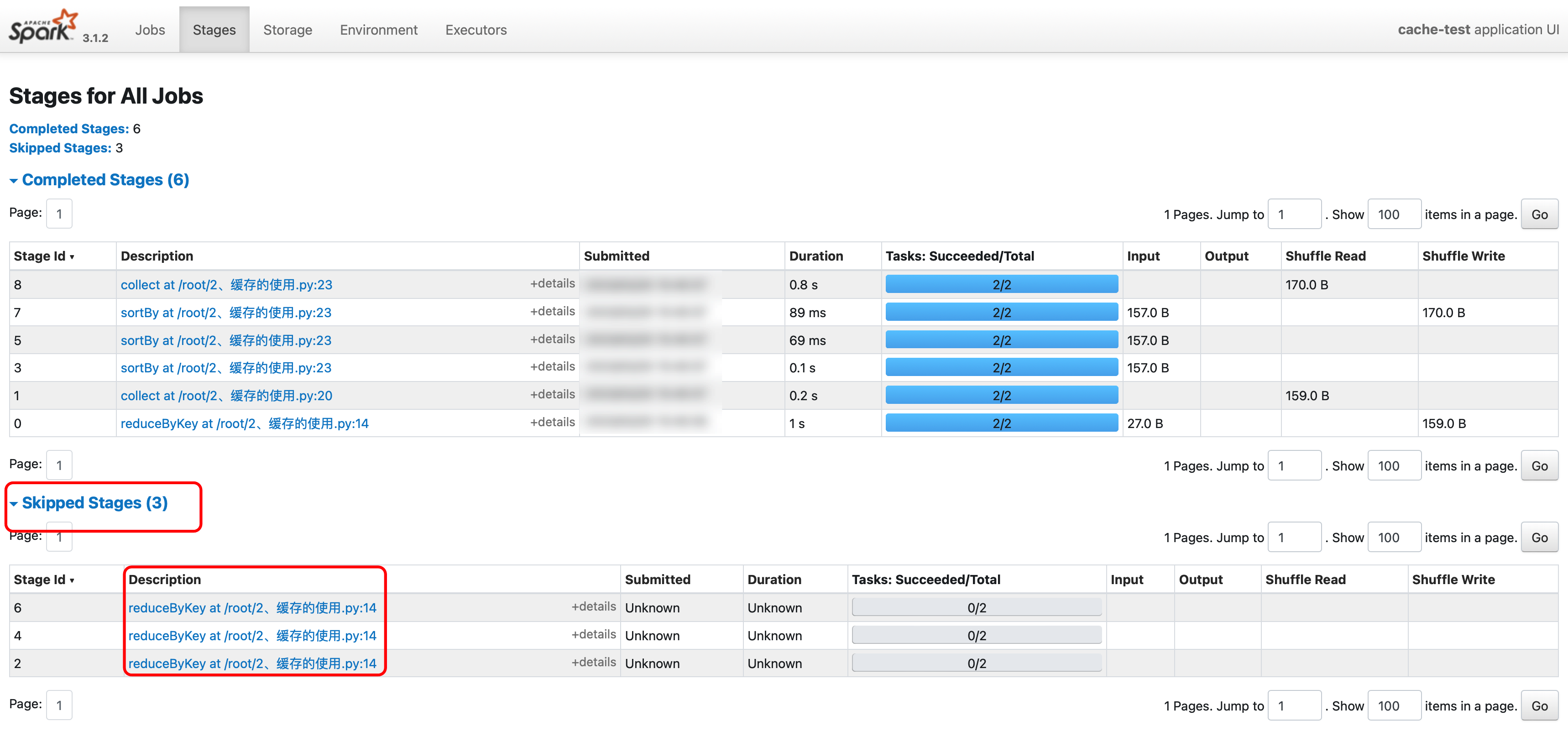
1.3.2.5. WebUI 查看
在 Shell 客户端运行:
sc.textFile('hdfs://qianfeng01:9820/input').flatMap(lambda x: x.split()).map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y).collect()


如果出现 skipped 那么就会减少对应的 Task,但是这是没有问题的,并且是对的。任务出现 skipped 是正常的,之所以出现 skipped 是因为要计算的数据已经缓存到了内存,没有必要再重复计算。出现 skipped 对结果没有影响,并且也是一种计算的优化。
在发生 shuffle 的过程中,会发生 shuffle write 和 shuffle read。
- **shuffle write:**发生在 shuffle 之前,把要 shuffle 的数据写到磁盘,这样可以保证数据的安全性,避免占用大量的内存。
- **shuffle read:**发生在 shuffle 之后,下游 RDD 读取上游 RDD 的数据的过程。
1.3.3. RDD的持久化机制
1.3.3.1. RDD 缓存
Spark 速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存多个数据集。当持久化某个 RDD 后,每一个节点都将把计算的分片结果保存在内存中,并且对此 RDD 或者衍生出的 RDD 进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD 相关的持久化和缓存,是 Spark 最重要的特性之一。可以说,缓存是 Spark 构建迭代是算法和快速交互式查询的关键。如果一个有持久化数据的节点发生故障,Spark 会在需要用到缓存的数据的时候重新计算丢失的数据分区。如果希望节点故障的情况不会拖累我们的执行速度,可以把数据备份到多个节点上。
在代码中,我们可以使用 persist 或者 cache 函数,对前面的计算结果进行缓存。但是并不是这两个被调用时立即缓存,而是触发后面的 Action 时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
- **persist:**可以自己选择缓存的级别
- **cache:**使用的是默认的缓存级别(StorageLevel.MEMORY_ONLY),不能修改
常用的缓存级别如下:
- **DISK_ONLY:**只缓存在磁盘中,保存一份副本
- **DISK_ONLY_2:**只缓存在磁盘中,保存两份副本
- **DISK_ONLY_3:**只缓存在磁盘中,保存三份副本
- **MEMORY_ONLY:**只缓存在内存中,保存一份副本
- **MEMORY_ONLY_2:**只缓存在内存中,保存两份副本
- **MEMORY_AND_DISK:**缓存在内存和磁盘中,保存一份副本
- **MEMORY_AND_DISK_2:**缓存在内存和磁盘中,保存两份副本
- **OFF_HEAP:**使用堆外内存
MEMORY_ONLY、DISK_ONLY、MEMORY_AND_DISK的区别:
- DISK_ONLY 顾名思义就是只缓存数据到磁盘中。
- MEMORY_ONLY 顾名思义就是只缓存数据到内存中。但是内存是有限的,超出的部分将不会被缓存。超出部分的数据再被使用到的时候会重新计算。
- MEMORY_AND_DISK 先缓存到内存中,当内存空间不足时,再缓存到磁盘上。
堆外内存:
堆外内存是相对于堆内内存而言,堆内内存是由JVM管理的,在平时java中创建对象都处于堆内内存,并且它是遵守JVM的内存管理规则(GC垃圾回收机制),那么堆外内存就是存在于JVM管控之外的一块内存,它不受JVM的管控约束缓存容易丢失,或者存储在内存的数据由于内存存储不足可能会被删掉.RDD的缓存容错机制保证了即缓存丢失也能保证正确的的计算出内容,通过RDD的一些列转换,丢失的数据会被重算,由于RDD的各个Partition是独立存在,因此只需要计算丢失部分的数据即可,并不需要计算全部的Partition
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
"""
缓存:把 RDD 计算出来的结果缓存起来,后续再使用的时候,可以直接从缓存中读取数据
"""
from pyspark import SparkContext,StorageLevel
with SparkContext(appName="cache-test") as sc:
# 读取数据源中的数据
rdd = sc.textFile("hdfs://qianfeng01:9820/input")
# 处理数据
wc_rdd = rdd.flatMap(lambda x: x.split()).map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
# 缓存起来
wc_rdd.persist(StorageLevel.DISK_ONLY)
print("========== 未排序的 ==========")
print(wc_rdd.collect())
print("========== 排序的 ==========")
print(wc_rdd.sortBy(lambda x: x[1], ascending=False).collect())
1.3.3.2. Checkpoint 检查点机制
Spark 中对于数据的保存除了缓存之外,还提供了一种检查点的机制。检查点的本质是通过将 RDD 写入 Disk 做检查点,是为了通过 Lineage 做容错的辅助。Lineage 过长会造成容错成本过高,这样就不如在中间阶段做检查点容错。如果之后有节点出现问题而丢失分区,从做检查点的 RDD 开始重做 Lineage,就会减少开销。检查点通过将数据写入到 HDFS 文件系统而实现的。
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
with SparkContext(appName="checkpoint-test") as sc:
# 读取数据源中的数据
rdd = sc.textFile("hdfs://qianfeng01:9820/input")
# 做检查点之前,要设置保存的目录
sc.setCheckpointDir('hdfs://qianfeng01:9820/spark-ckpt')
# 处理数据
wc_rdd = rdd.flatMap(lambda x: x.split()).map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
wc_rdd.checkpoint()
print("========== 未排序的 ==========")
print(wc_rdd.collect())
print("========== 排序的 ==========")
print(wc_rdd.sortBy(lambda x: x[1], ascending=False).collect())
1.3.3.3. 缓存和检查点的区别
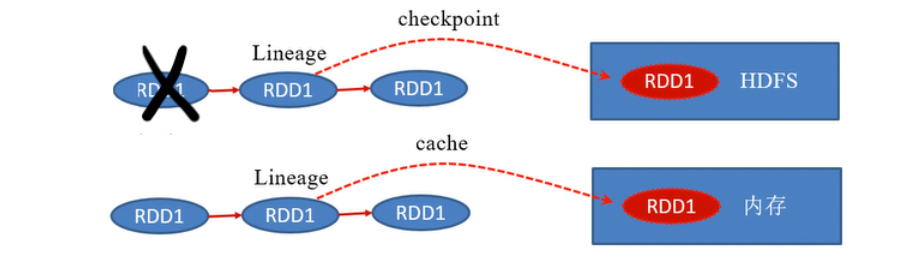
- 缓存只是将数据保存起来,不切断血缘依赖。检查点会切断血缘依赖。
- 缓存的数据通常存储在磁盘、内存等地方,可靠性低。检查点的数据通常存储在 HDFS 等高容错、高可用的文件系统,可靠性高。
- 缓存的数据在任务结束后会自动清除。检查点的数据需要手动清除。
1.3.3.4. 什么时候使用cache或checkpoint
- 某步骤的计算特别耗时
- 计算链条特别长
- 发生shuffle之后
建议使用 cache 或者 persist 进行缓存,因为不需要创建存储位置,并且默认存储到内存中计算速度快。而 Checkpoint 需要手动创建存储位置和手动删除数据。若数据量非常庞大建议改用 Checkpoint。
1.3.4. Accumulator累加器
累加器用来对数据进行聚合,通常在向 Spark 传递函数时,例如 map 函数,或者用 filter 传条件时,可以使用 Driver 中定义的变量。但是急群众运行的每个人物都会得到这些变量的一份新的副本。此时更新这些副本的值不会影响 Driver 端对应的变量的值。如果我们想实现所有分片处理的时候更新共享变量的功能,那么累加器可以实现我们想要的效果。
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
with SparkContext(master="local[*]", appName="accumulator") as sc:
# 提供数据 RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 定义一个用来"累加"的变量
s = 0
def accu(n):
global s
s += n
print("在foreach中的 s 是:", s)
rdd.foreach(accu)
print("最终的结果 s 是:", s)
最终打印的结果是 0
任务在执行的时候,Executor 端会拷贝一个变量 s 过去,对拷贝后生成的新的变量 s 进行累加。
但是最终打印的时候,打印的是 Driver 端的变量 s,与 Executor 中拷贝的副本没有任何关系!
那么我们应该怎么样实现累加的操作呢?累加器!
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
with SparkContext(master="local[*]", appName="accumulator") as sc:
# 提供数据 RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 定义一个累加器变量
accu = sc.accumulator(0)
# 遍历、累加
rdd.foreach(lambda x: accu.add(x))
# 输出最后累加的结果
# 累加器用来把 Executor 端的变量信息聚合在 Driver 端,
# 在 Driver 端定义的变量,在 Executor 端的每一个 Task 都会得到一个变量的新的副本。
# 每个 Task 更新这些副本值之后,传回 Driver 端进行 Merge。
print(accu.value)
累加器在使用时候的注意事项:
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
with SparkContext(master="local[*]", appName="accumulator") as sc:
# 提供数据 RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 定义一个累加器变量,累加器的生命周期为当前的会话
accu = sc.accumulator(0)
def acc_map(n):
global accu
accu += n
rdd2 = rdd.map(acc_map)
# 触发了 Action 算子,这一条计算链已经结束了
rdd2.collect()
print(accu.value)
# rdd3 没有与 rdd2 产生血缘依赖,因此累加器的值依然是上述累加完成之后的值
rdd3 = rdd.map(lambda x: x).collect()
print(accu.value)
# 与 rdd2 产生血缘依赖,需要按照之前的计算逻辑重新计算
# 这样就把上述的 map 又执行了一遍,累加器自然也就又加了一遍,结果为 30
rdd4 = rdd2.map(lambda x: x).collect()
print(accu.value)
那么应该如何避免这个问题呢?可以使用缓存或者检查点来解决!
1.3.5. Broadcast广播变量
1.3.5.1. 本地变量在 Task 中使用的问题
广播变量用来高效的分发较大的对象。向所有的工作节点发送一个较大的只读的值,以供一个或多个 Spark 操作使用。比如如果你的应用需要向所有节点发送一个较大的只读的查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
with SparkContext(master="local[*]", appName="broadcast") as sc:
# 创建一个本地变量,此时这个变量是创建在 Driver 端的
black_list = ['hadoop', 'spark', 'context', 'yarn']
# 读取文件中的内容
rdd = sc.textFile('./data/words')
# 对数据进行处理
filtered_rdd = rdd.flatMap(lambda x: x.split()).filter(lambda x: x not in black_list)
# 处理之后的结果
print(filtered_rdd.collect())
在上述代码中,实现了对数据进行的简单过滤。但是这段代码存在一个隐藏的问题:
container 是创建在 Driver 端的,但是需要在 Executor 端使用。所以 Driver 端会把 container 以 Task 的形式发送给 Executor 端,也就是相当于在 Executor 端需要复制一个 container 的副本。
如果有很多个 Task,就会有很多个 Executor 端携带多个 container 的副本。那么如果 container 比较大的话,会造成较大的 IO 占用,甚至有可能会出现内存溢出。
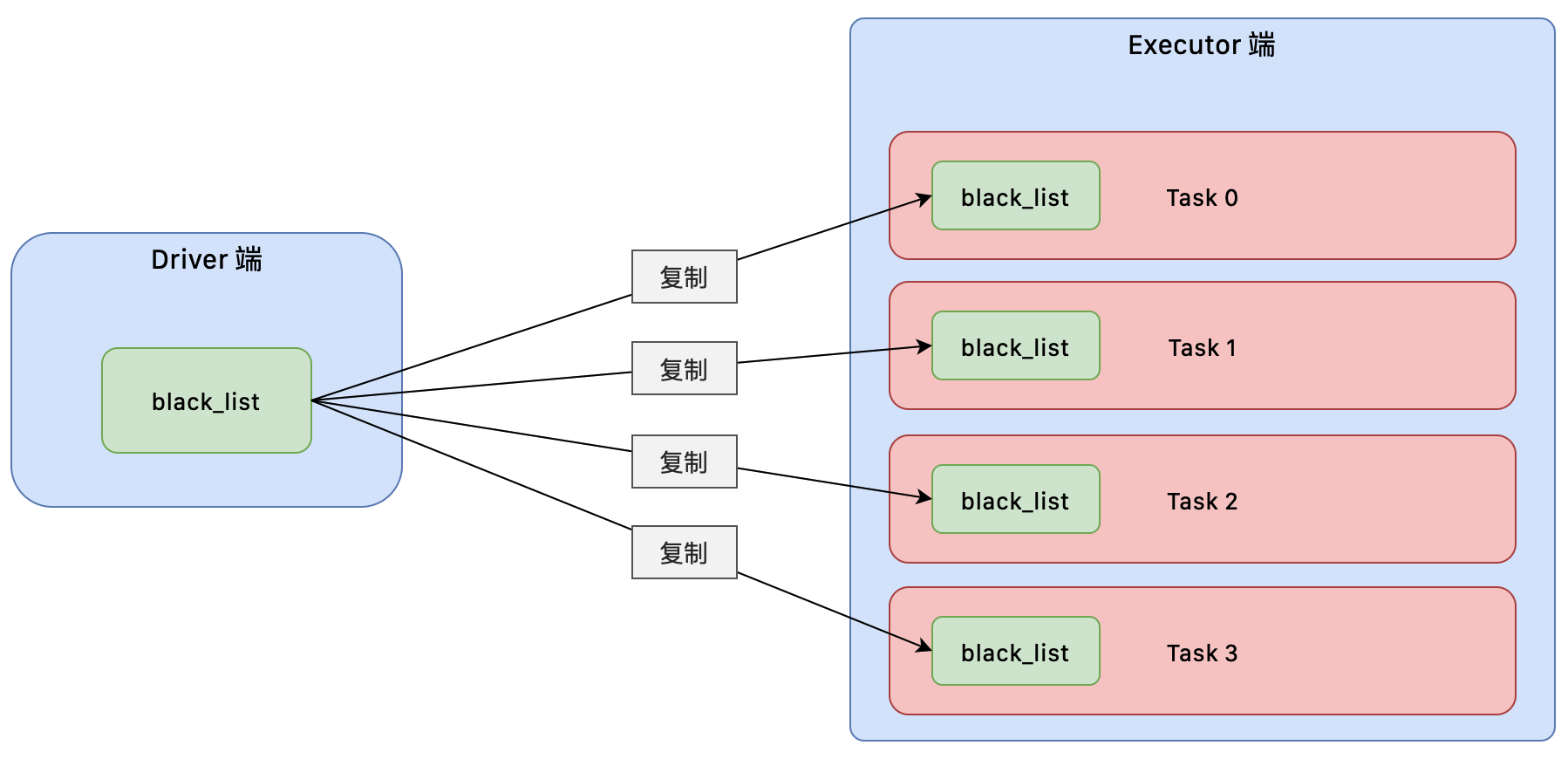
如果 Executor 频繁的向 Driver 拉取本地变量,就会出现一些问题:
- 大量网络 IO(多次向 Driver 端来拉取本地变量)
- Executor 端拉取本地变量相当于是复制,所以若一个 Executor 中多次使用这个变量,就会出现多个重复的变量值。这样会造成 Worker 中的内存消耗过高,甚至会内存溢出
1.3.5.2. 广播变量的原理
使用广播变量的好处,不是每个 Task 任务就会去拉取一个 Driver 端的本地变量的副本,而是变成每个节点的 Executor 才一个副本。这样既可以减少网络 IO,也可以减少 Executor 中副本数量。
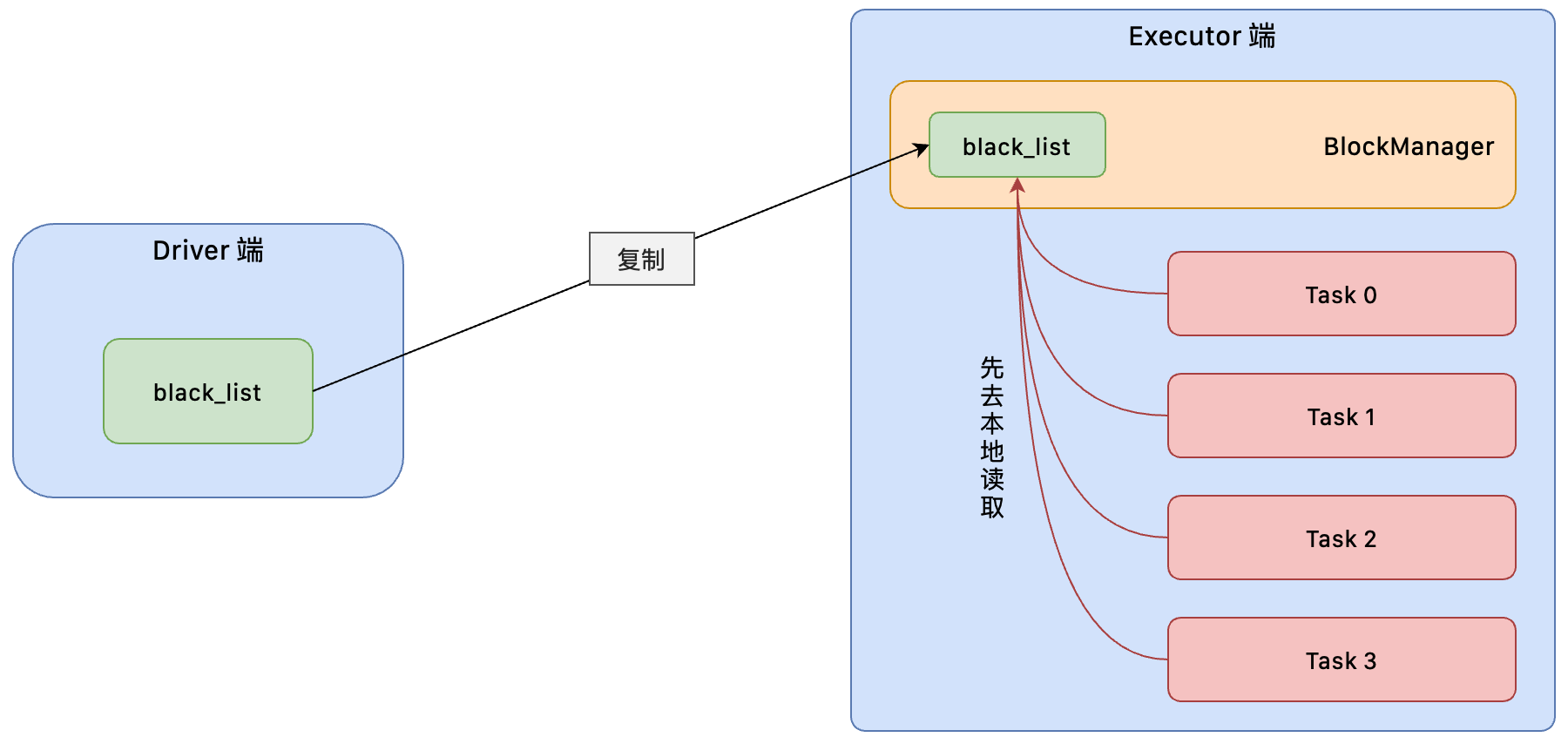
新角色BlockManager:负责管理某个 Executor 对应的内存和磁盘上的数据。
- Task 在运行的时候,想要使用广播变量中的数据,会首先在本地的 Executor 对应的 BlockManager 中尝试获取变量副本。
- 如果本地没有,那么就会从 Driver 端远程拉取变量副本,并保存在本地的 BlockManager 中。
- 此后这个 Executor 上的 Task,都会直接使用本地的 BlockManager 中的副本。
- Executor 的 BlockManager 除了从 Driver 上拉取,也可能从其他节点的 BlockManager 上拉取变量副本。
以如下场景为例:
50 个 Executor,1000 个 Task。一个 Driver 端本地的变量有 10M。
默认情况下,1000 个 Task,1000 份副本。会有 10G 的数据传输,在集群中会耗费 10G 的内存资源。
如果使用了广播变量,50 个 Executor,50 个副本。500M 的数据传输,而且不一定都是从 Driver 传输到每一个节点的,还可能就是从最近的节点的 Executor 的 BlockManager 上拉取的变量副本,网络传输速度大大增加;500M 的内存消耗。
从 10G 到 500M,降低了 20 倍的网络传输性能消耗,20 倍的内存消耗!对性能的提升和影响还是很客观的。
虽然说,不一定会对性能产生决定性的作用。比如运行 30 分钟的 Spark 作业,可能做了广播变量以后,速度快了 2 分钟,或者 5 分钟。但是一点一滴的调优,积少成多,最后还是会有效果的。
1.3.5.3. 广播变量的使用
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
from pyspark import SparkContext
with SparkContext(master="local[*]", appName="broadcast") as sc:
# 创建一个本地变量,此时这个变量是创建在 Driver 端的
black_list = ['hadoop', 'spark', 'context', 'yarn']
# 读取文件中的内容
rdd = sc.textFile('./data/words')
# 创建一个广播变量存储这个本地变量
broadcast = sc.broadcast(black_list)
# 对数据进行处理,在 Task 中使用广播变量的数据
filtered_rdd = rdd.flatMap(lambda x: x.split()).filter(lambda x: x not in broadcast.value)
# 处理之后的结果
print(filtered_rdd.collect())
1.3.6. Shuffle原理
1.3.6.1. 什么是 Shuffle
Shuffle 是分布式计算不可或缺的一部分,同时是分布式计算性能消耗最大的一个部分,原因就在于发送的数据和网络传输。
Shuffle 是一个过程,如果我们把分布式计算理解为总-分-总,第一个总,是统一加载外部数据,做统一作业的拆分;分,便是处理每一个独立的 Task 任务;第二个总,便是各个独立的 Task 任务运行完毕之后进行的汇总,汇总的数据便是各个独立的 Task 任务计算之后的数据。显然是在不同的节点之上,往某几个节点汇总,汇总的这个过程便是 Shuffle。其中 Shuffle 又分为了 Shuffle-Write 的过程,和 Shuffle-Read 的过程。汇总的过程涉及到数据的重新分布,所以 Shuffle,就是一个数据打乱重排的过程。
1.3.6.2. ShuffleManager 的实现
Spark 最早的 Shuffle 处理方式,就是 HashShuffleManager。在 Spark0.8 的版本中出现了优化后的 HashShuffleManager,同时在 Spark1.2 的版本中出现的 SortShuffleManager 成为了默认的 Shuffle 处理方式。目前的版本就只有一个 SortShuffleManager。但是 SortShuffleManager 也有普通的和排序的之分。
如何指定 Shuffle 处理方式呢,Spark 中有一个参数:spark.shuffle.manager=hash|sort(默认)
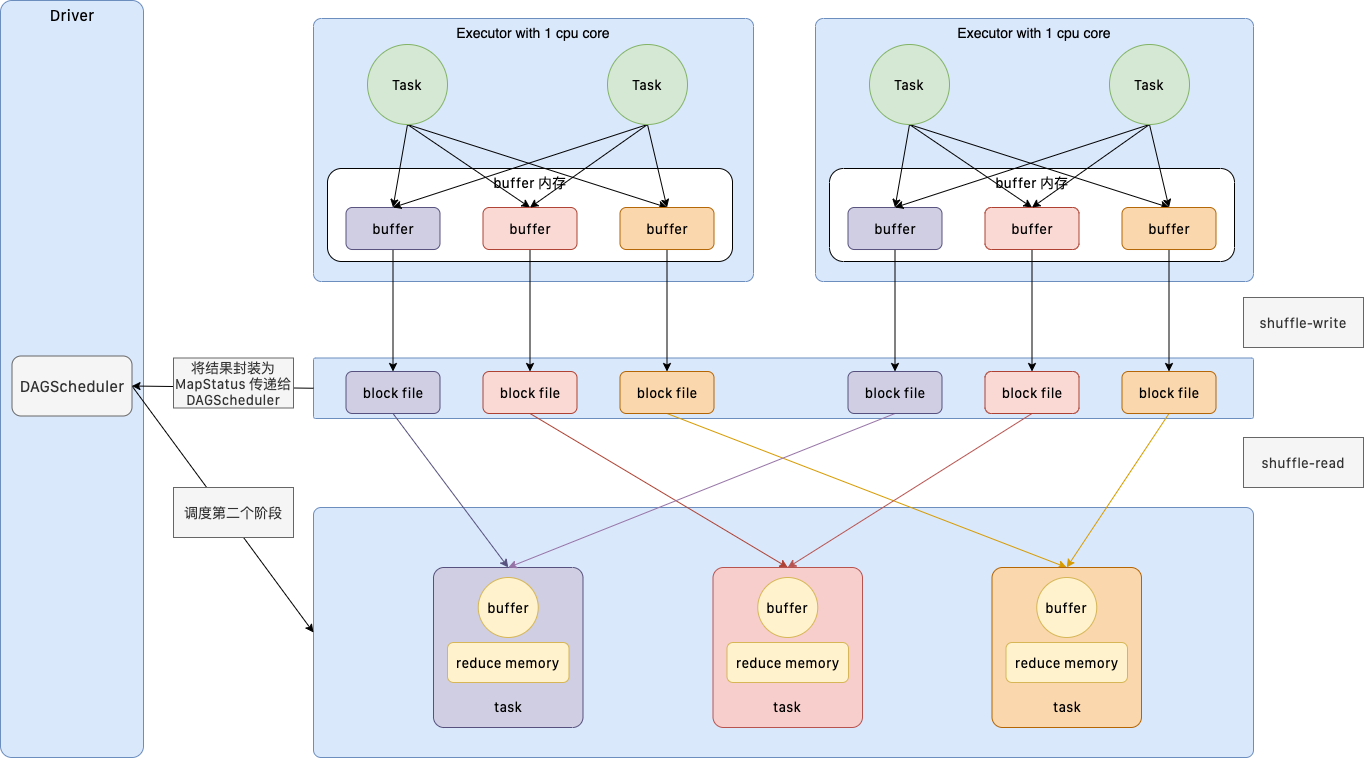
1.3.6.3. 未经优化的 HashShuffleManager
这种未经优化的 HashShuffleManager,每一个 ShuffleMapTask 都会为下游的 ReduceTask 生成一个磁盘 BlockFile 文件。所以,如果上游有 1000 个 ShuffleMapTask,下游有 100 个 ReduceTask,会生成 1000*100=10W 个磁盘文件,所以这种 Shuffle 操作,会生成大量的磁盘文件,性能很差。所以在 Spark0.8 的版本中做了性能优化:ShuffleGroup。
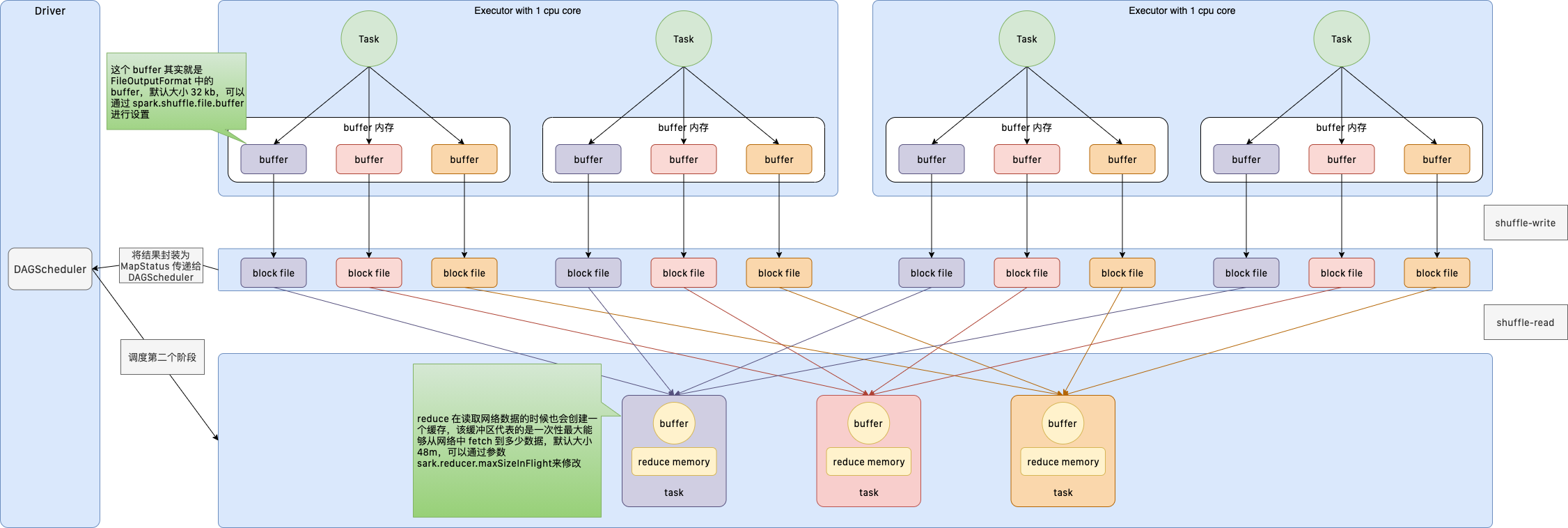
1.3.6.4. 优化后的 HashShuffleManager
经过优化之后的 HashShuffleManager 处理过程,是有每一个 CPUCore 上面运行的多个 ShuffleMapTask,为下游的一个 ReduceTask 创建一个 Buffer 缓冲区,一个磁盘文件,多次写入的都会被合并。所以,此时上游有 1000 个 ShuffleMapTask,CPU Core 50个,ReduceTask 还是 100 个,生成的磁盘文件 50*100 = 5000 个,生成的磁盘文件数量要比第一种少很多。同时把在一个 CPU Core 处理的过程,我们称之为一个 Shuffle-Group。
1.3.6.5. SortShuffleManager
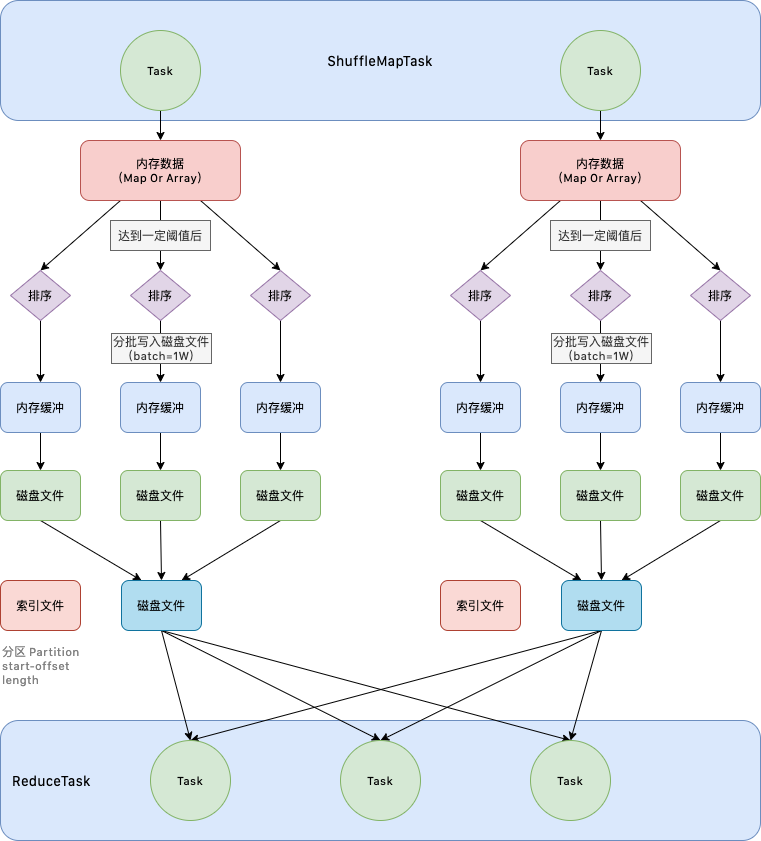
为了处理那些在 Shuffle 过程中需要进行排序的操作,SortShuffleManager 一开始并没有直接将数据从缓冲区送出,落地到磁盘;而是先根据下游的 ReduceTask 的个数,进行内存级别的分区,针对这多个分区进行排序,将排序之后的结果批量写入到内存缓冲区域中,缓冲区域写满之后落地到磁盘文件。一个缓冲区对应一个磁盘文件,此时就和未经优化的 HashShuffleManager 没有什么两样,所以对这些磁盘文件做了合并,合并成为一个磁盘文件。同时为了标识清楚合并之后的结果中,哪一部分的数据对应哪一个 ReduceTask,会生成一个索引文件,ReduceTask 便可以通过这个索引文件读取数据。这种情况下,生成的磁盘文件个数就是 CPU-Core 的个数。
1.3.6.6. By-Pass机制
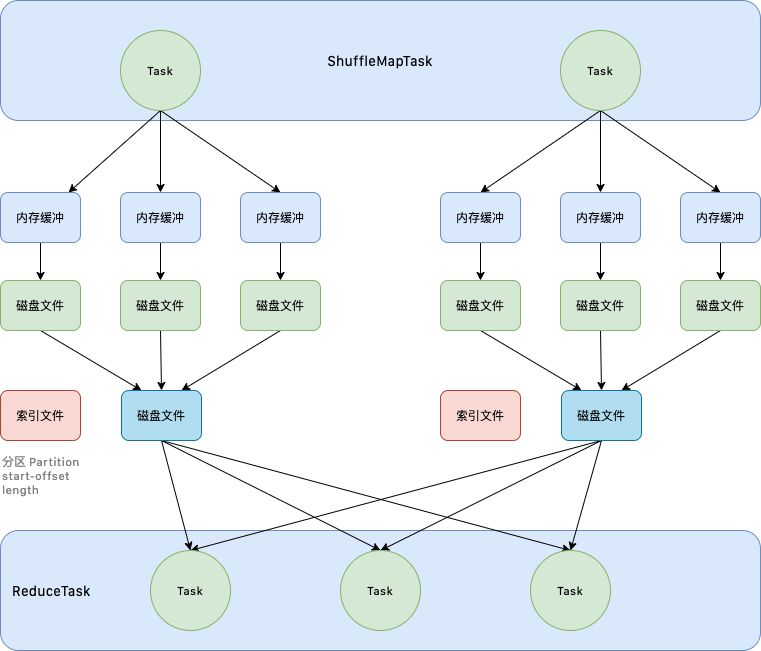
并不是所有的 Shuffle 操作都需要进行排序,对于那些不需要排序的 Shuffle 操作,使用上一种普通的 SortShuffleManager,性能反而不高,因为做了不必要的排序操作。所以 Spark 便在 SortShuffleManager 基础上提供了一个 By-Pass 机制。如果不需要进行排序,我们就可以开启 By-Pass 机制,在 Shuffle 的过程中跳过排序。
如何开启这个 ByPass 机制呢?
spark.shuffle.sort.bypassMergeThreshold=200
这里参数指定的是开启 By-Pass 的最大分区数。也就是说当 Spark 作业的并行度或者分区数高于 200 的时候,就会走普通的 SortShuffleManager 过程,低于 200 的时候执行 By-Pass 机制。所以如果不想执行排序操作,应该尽可能的调大这个参数。
1.3.6.7. 常见的 Shuffle 调优参数
| 参数 | 默认值 | 描述 |
|---|---|---|
| spark.reducer.maxSizeInFlight | 48M | 每一次reduce拉取的数据的最大值,默认值48m,如果网络ok、spark数据很多,为了较少拉取的次数,可以适当的将这个值调大,比如96m。 |
| spark.shuffle.compress | true | shuffle-write输出到磁盘的文件是否开启压缩,默认为true,开启压缩,同时配合spark.io.compression.codec(压缩方式)使用。 |
| spark.shuffle.file.buffer | 32k | shuffle过程中,一个磁盘文件对应一个缓存区域,默认大小32k,为了较少写磁盘的次数,可以适当的调大该值,比如48k,64k都是可以。 |
| spark.shuffle.io.maxRetries | 3 | shuffle过程中为了避免失败,会配置一个shuffle的最大重试次数,默认为3次,如果shuffle的数据比较多,就越容易出现失败,此时可以调大这个值,比如10次。 |
| spark.shuffle.io.retryWait | 5s | 两次失败重试之间的间隔时间,默认5s,如果多次失败,显然问题在于网络不稳定,所以我们为了保证程序的稳定性,调大该参数的值,比如30s,60s都是可以。 |
| spark.shuffle.sort.bypassMergeThreshold | 200 | 是否开启byPass机制的阈值。 |
| spark.shuffle.memoryFraction | 0.2 | 在executor中进行reduce拉取到的数据进行reduce聚合操作的内存默认空间大小,默认占executor的20%的内存,如果持久化操作相对较少,shuffle操作较多,就可以调大这个参数,比如0.3。 |