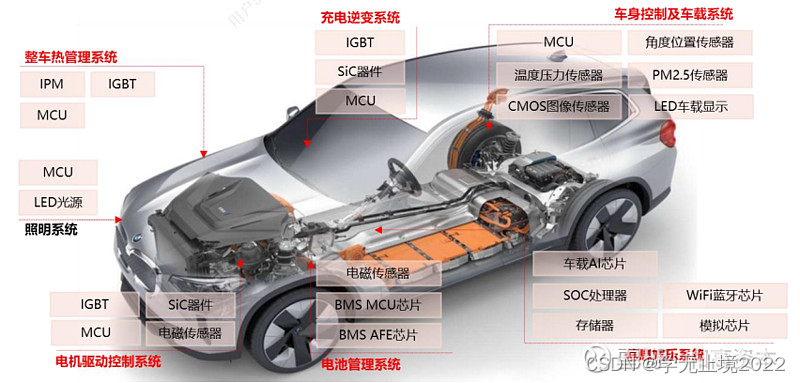
前馈全连接神经网络对鸢尾花数据集进行分类
- 1.导入所需要的包
- 2.打印训练集和测试集二维数组
- 3.定义模型
- 4.打印模型信息
- 5.权重和偏执
- 6.编译网络和训练网络
- 7.打印二维数据表格
- 8.绘制图像
- 9.查看准确率
1.鸢尾花数据集可以用 from sklearn.datasets import load_iris 方式获取,并将获取的数据划分为训练集、验证集、测试集 。
2. 构建一个10层网络,隐藏层每层对应16个神经元,激活函数都是relu函数,输入输出神经元自己判断 3. 为提高准确率,可以在全连接层后加dropout层,防止过拟合。添加方式:keras.layers.Dropout(rate=0.2)。
1.导入所需要的包
numpy:
numpy 是一个用于科学计算的 Python 库,提供了强大的多维数组和矩阵操作功能。
pandas:
pandas 是一个用于数据分析和数据处理的 Python 库,提供了 DataFrame 和 Series 两种数据结构。
它用于数据导入、数据清洗、数据转换、数据分析和数据可视化等。
matplotlib.pyplot:
matplotlib 是 Python 的一个绘图库,用于数据可视化。
pyplot 是 matplotlib 的一个接口,提供了一系列的函数来绘制图表,如折线图、散点图、直方图等。
sklearn.datasets:
sklearn.datasets 是 scikit-learn 库的一部分,提供了各种机器学习算法所需的示例数据集。
它包括分类、回归、聚类、文本和图像数据集。
sklearn.model_selection:
sklearn.model_selection 是 scikit-learn 库的一部分,提供了用于模型训练和评估的各种功能。
它包括数据划分、交叉验证、网格搜索等。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
2.打印训练集和测试集二维数组
iris = load_iris()
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=23)
X_train,X_valid,y_train,y_valid = train_test_split(x_train,y_train,test_size=0.2,random_state=12)
print(X_valid.shape)
print(X_train.shape)
运行结果:
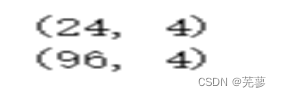
3.定义模型
先下载tensorflow包,在终端输入conda install tensorflow
如果下载不了的话,请按照资源文档操作。
TensorFlow:
tensorflow 是 TensorFlow 的官方 Python 库,它提供了一个用于构建和训练深度学习模型的框架。
它包括数据处理、模型构建、训练、评估和预测等功能。
Keras:
tf.keras 是 TensorFlow 的一个高级 API,它是一个简单易用的神经网络 API,可以运行在 TensorFlow、Theano 或 CNTK 之上。
它提供了模型构建、编译、训练和评估的简洁接口。
tf.keras 支持各种类型的模型,包括卷积神经网络 (CNN)、循环神经网络 (RNN)、长短期记忆网络 (LSTM) 等。
import tensorflow as tf
from tensorflow import keras
导入这个包的过程需要很久,请耐心等待
构建的深度学习模型
model = keras.models.Sequential([
#Flatten Layer: 输入层,形状为 [4]。这个层将输入数据展平为一维数组,对于分类问题,通常输入是一个形状为 [样本数, 特征数] 的二维数组,所以这里的 4 可能是输入特征的数量。
keras.layers.Flatten(input_shape=[4]),
#Dense Layer 1: 第一个全连接层,有 16 个神经元,使用 ReLU 激活函数。
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(16,activation='relu'),
#Dropout Layer: 包含一个 Dropout 层,其 rate 参数设置为 0.2,意味着每个神经元被随机丢弃的概率是 20%。
keras.layers.Dropout(rate=0.2),
#Dense Layer 11: 最后一个全连接层,有 3 个神经元,使用 softmax 激活函数。由于使用了 softmax 激活函数,这通常意味着这是一个多分类问题,其中 3 表示可能的类别数。
keras.layers.Dense(3,activation='softmax'),
])
4.打印模型信息
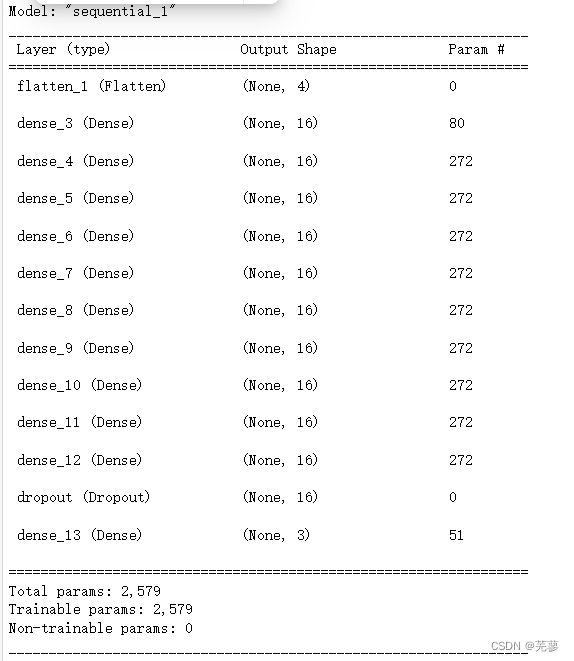
model.summary() 方法用于打印模型的摘要信息,包括层数、每个层的参数数量、层的形状等。
model.summary()
5.权重和偏执
get_weights() 方法来获取一个层的权重和偏置
model.layers[1]
weight_1,bias_1 = model.layers[1].get_weights()
print(weights_1.shape)
print(bias_1.shape)

6.编译网络和训练网络
model.compile():用于指定模型的损失函数、优化器和评估指标
loss='sparse_categorical_crossentropy':模型的损失函数为
optimizer=‘sgd’:这行代码指定模型的优化器为sgd
metrics=[‘accuracy’]:这行代码指定模型的评估指标为accuracy
model.compile(loss='sparse_categorical_crossentropy',
optimizer='sgd',metrics=["accuracy"])
model.fit()是一个函数,用于使用训练数据来训练模型
X_train:训练数据的输入特征,
y_train:训练数据的标签
batch_size=32:每次梯度下降更新时使用的样本数量
epochs=30:训练过程将运行的完整周期数。
validation_data=(X_valid, y_valid):验证数据的输入特征和标签。
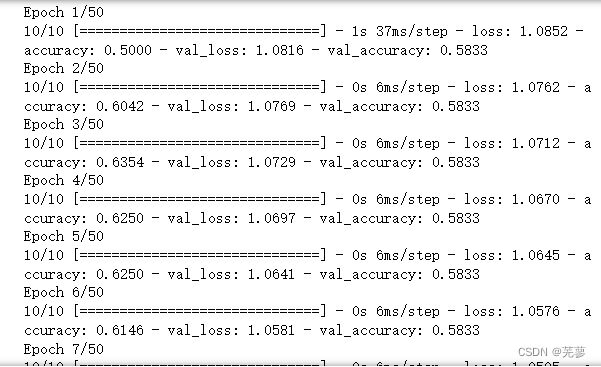
h = model.fit(X_train,y_train,batch_size=10,epochs=50,validation_data=(X_valid,y_valid))
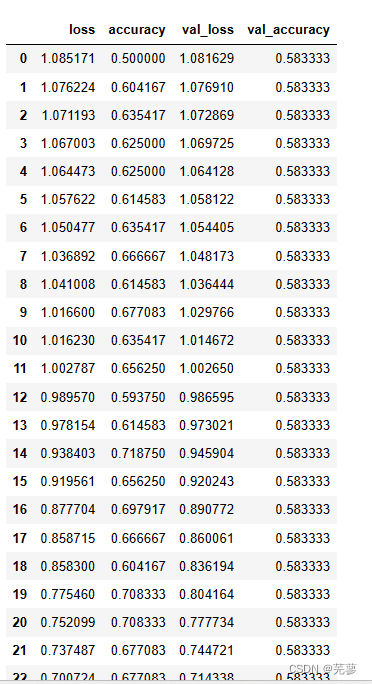
7.打印二维数据表格
随着迭代次数的增加,损失函数的数值loss越来越小,而在验证集上的准确率accuracy越来越高,这些信息都保存在h.history中
pd.DataFrame(h.history)
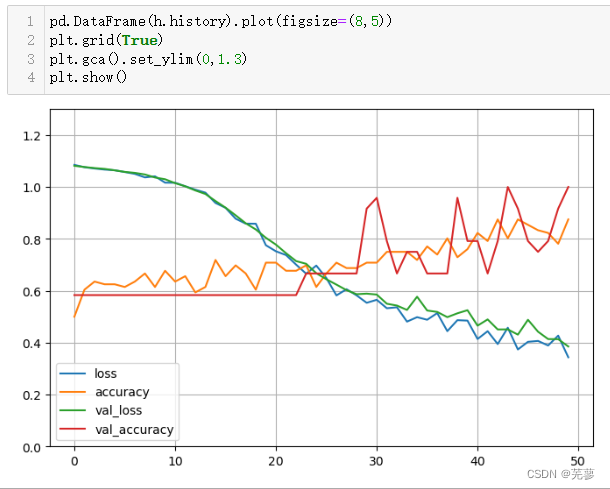
8.绘制图像
首先将h.history字典转换为一个Pandas DataFrame。
h.history通常包含在训练过程中收集的损失(loss)和准确度(accuracy)等指标,它们是训练周期的迭代结果。
figsize=(8,5)指定了图表的尺寸,其中8表示宽度,5表示高度。
pd.DataFrame(h.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1.3)
plt.show()
9.查看准确率
model.evaluate()是一个函数,用于评估模型的性能
X_test:这是测试数据的输入特征
y_test:这是测试数据的标签
batch_size=1:这行代码指定评估过程中每次评估的样本数量。
model.evaluate(x_test,y_test,batch_size = 1)