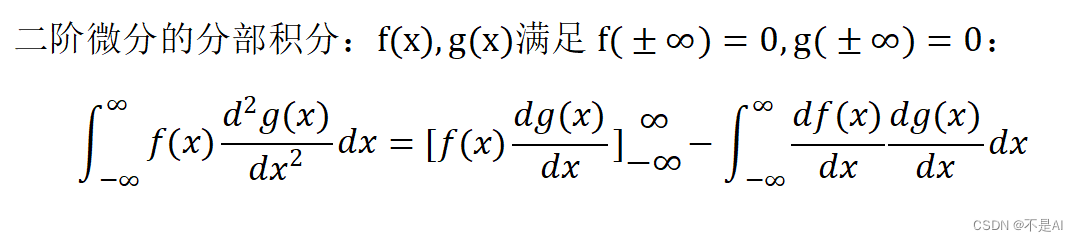1、技术原理及架构图
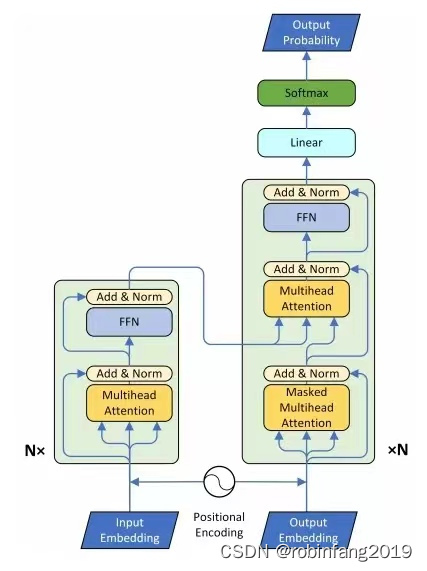
Transformer-TTS主要通过将Transformer模型与Tacotron2系统结合来实现文本到语音的转换。在这种结构中,原始的Transformer模型在输入阶段和输出阶段进行了适当的修改,以更好地处理语音数据。具体来说,Transformer-TTS利用自注意力机制来处理序列数据,这使得模型能够并行处理输入序列,从而提高训练效率。此外,Transformer-TTS还采用了自回归误差方法来优化模型性能。
2、在中文语音合成中的应用效果
- 语音自然度:Transformer-TTS由于其自注意力机制,能够较好地捕捉文本中长距离的依赖关系,这对于生成自然流畅的语音非常重要。它能够在不同的上下文中合理地预测语音特征,从而生成听起来更自然的语音。
- 合成速度:Transformer-TTS可以并行处理数据,这使得它在语音合成速度上具有优势。相比于传统的基于RNN的TTS系统,它能够更快速地完成语音合成任务。
- 模型泛化能力:Transformer-TTS模型通常具有良好的泛化能力,能够适应不同的语音和文本数据。这意味着它不仅可以处理标准的普通话语音合成,还可以推广到不同的方言或者具有特定语音特征的说话人。
- 适应性:Transformer-TTS模型可以通过微调适应特定的说话风格或者语音特性,例如通过使用少量目标说话人的语音数据进行微调,以模仿特定说话人的声音。
2.1 使用WaveGlow作为声码器的模型
WaveGlow是一个基于流的声码器模型,用于将声学特征(如梅尔频谱图)转换为可听的语音波形。WaveGlow模型由NVIDIA研究小组开发,它结合了Glow和WaveNet的技术,提供了一种快速、高效且高质量的音频合成方法,且不需要自回归过程。
- 快速合成:WaveGlow能够生成高采样率的音频,速度远超实时,这使得它非常适合实时应用。
- 高音质:在众包平均意见得分(MOS)测试中,WaveGlow提供的音频质量与公开的最佳WaveNet实现相当。
- 简单实现:与需要两个网络(教师网络和学生网络)的方法相比,WaveGlow只需要一个网络和一个损失函数,简化了训练过程。
- 可逆网络结构:WaveGlow使用可逆的1x1卷积结构,这使得它能够高效地生成语音,并且保持了结构的简单性。
- 基于流的模型:WaveGlow是一个基于流的生成模型,它通过从简单的分布(如高斯分布)采样并逐步转换为复杂的输出分布来生成语音。
2.2 mandarin-tts
Mandarin-TTS是一个专注于中文普通话语音合成的开源项目,基于Tacotron 2和WaveGlow模型构建,由Ranch Lai创建并维护。该项目旨在提供高质量、自然流畅的中文语音合成服务,适用于多种应用场景,如智能助手、有声读物、语音导航等。
下载地址:https://gitcode.com/ranchlai/mandarin-tts
2.3 主要挑战
在中文语音合成中,Transformer-TTS面临的主要挑战包括训练和推理效率低,以及难以利用现有的递归神经网络(RNNs)。此外,尽管Transformer-TTS在一定程度上解决了Tacotron2中的问题,但仍存在一些问题,如训练时的效率问题。
下面几种解决方案有助于优化上述挑战:
- 并行处理:使用Transformer可以实现并行提供解码器输入序列的帧,这样可以通过取代循环连接来进行并行训练,从而提高训练和推理的效率。
- 优化技术:例如,可以使用Optimum和Accelerate这两个生态系统库来优化模型,这些库提供了多种优化技巧,可以帮助提高模型的性能和效率。
- 鲁棒性增强:通过对Transformer-TTS模型进行修改,可以获得更加鲁棒的系统。实验结果显示,在合成语音质量相等的情况下,系统变得更加稳定和可靠。
2.3.1 Optimum是一个深度学习模型优化库,它旨在帮助研究人员和开发人员提高深度学习模型的效率和性能。提供了一系列工具和接口,以便于集成到现有的深度学习工作流中。
2.3.2 Accelerate是一个由Hugging Face提供的开源库,它旨在简化在不同深度学习框架(如PyTorch和TensorFlow)中实现模型训练和优化的过程。Accelerate的主要目标是提供一个统一的API,使得开发者能够轻松地在不同框架之间迁移和测试代码。
3、Transformer-TTS的优化
- 鲁棒性优化:通过构建概率性场景来防止离散不确定性集合内的对抗性扰动,这种方法可以提高模型的鲁棒性,使其在不同的输入条件下都能保持较好的性能。
- 数据驱动的优化:利用大量的数据进行训练,可以帮助模型更好地理解和生成语音,从而提高转换的准确性和自然度。
- 多头注意力机制:在Transformer TTS中,引入多头注意力机制替代了传统的RNN结构和单一的注意力网络。
- 保存和重用注意力矩阵:在处理快速语音合成时,生成的梅尔谱程序和注意力矩阵应该被保存并在后续处理中重用。这样可以减少计算资源的消耗,并加快处理速度。
- 优化模型配置:通过设置合适的参数,如teacher_path,并在指定目录中准备对齐项和目标,可以进一步优化模型的训练过程和结果。
-
4、Transformer-TTS部分代码
class TransformerTTS(nn.Module):
""" TTS model based on Transformer """
def __init__(self, num_mel=80, embedding_size=512):
super(TransformerTTS, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.postnet = PostNet()
self.stop_linear = Linear(embedding_size, 1, w_init='sigmoid')
self.mel_linear = Linear(embedding_size, num_mel)
def forward(self, src_seq, src_pos, tgt_seq, tgt_pos, mel_tgt, return_attns=False):
encoder_output = self.encoder(src_seq, src_pos)
decoder_output = self.decoder(
tgt_seq, tgt_pos, src_seq, encoder_output[0], mel_tgt)
decoder_output = decoder_output[0]
mel_output = self.mel_linear(decoder_output)
mel_output_postnet = self.postnet(mel_output) + mel_output
stop_token = self.stop_linear(decoder_output)
stop_token = stop_token.squeeze(2)
return mel_output, mel_output_postnet, stop_token