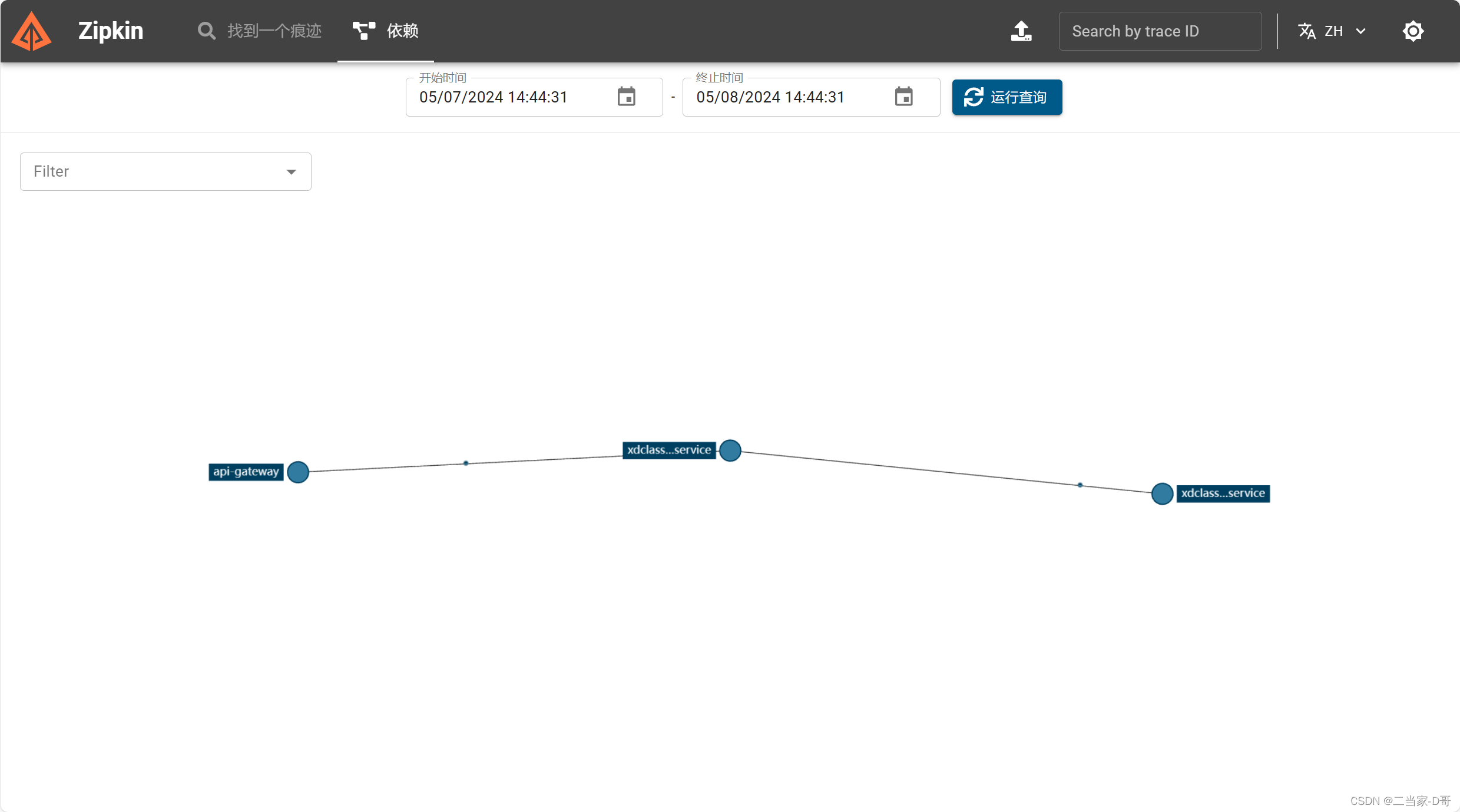
前言
打算新开一个笔记系列,基于国防科技大学 丁兆云老师的《数据挖掘》
数据挖掘
1、数据类型与统计

数据统计
最大值,最小值,平均值,中位数,位数,方差等统计指标
df.describe()
#当调用df.describe()时,它会计算DataFrame中数值列的统计指标,并返回一个包含以下统计信息的新DataFrame:
计数(count):每列非缺失值的数量。
平均值(mean):每列的平均值。
标准差(std):每列的标准差。
最小值(min):每列的最小值。
四分位数(25%,50%,75%):每列的第25%,第50%,和第75%的百分位数。
最大值(max):每列的最大值。
异常值可视化分析
箱线图、直方图、散点图
箱线图(Box Plot)、直方图(Histogram)和散点图(Scatter Plot)是常用的数据可视化工具,可以用于异常值检测。
- 箱线图:箱线图通过展示数据的分布情况来检测异常值。它将数据分为四分位数,并根据四分位数的范围绘制一个箱体,箱体中的中位数标记为一条线。在箱体上方和下方绘制了称为"whiskers"的线段,用于表示数据的分布范围。超出"whiskers"范围的点被认为是异常值。因此,箱线图可以通过观察超出箱体范围的点来检测异常值。
- 直方图:直方图可以显示数据的分布情况。它将数据划分为一系列的区间(称为"bin"),并计算每个区间中数据点的数量。直方图可以帮助我们观察数据是否呈现正态分布或偏态分布。异常值通常在直方图中表现为与主要数据分布不一致的极端值。
- 散点图:散点图可以展示两个变量之间的关系。通过绘制数据点的坐标,我们可以观察数据的分布模式。在散点图中,异常值通常是与其他数据点明显分离的点,远离其他数据点的位置。另外还可以用来观察相关性分布

数据相似性

二值属性:
对于二值属性(Binary Attribute),可以使用以下方法进行邻近度(Proximity)测量:
- 汉明距离(Hamming Distance):汉明距离是衡量两个等长字符串之间的差异的度量。对于二值属性,可以将其表示为由0和1组成的字符串。汉明距离是指在相同位置上不同的位数。例如,对于属性A和属性B,A的取值为[0, 1, 1, 0],B的取值为[1, 0, 1, 1],它们之间的汉明距离为2,因为有两个位置上的值不同。
- 杰卡德相似系数(Jaccard Similarity Coefficient):杰卡德相似系数用于衡量两个集合的相似性。对于二值属性,可以将其视为集合,其中1表示属性存在,0表示属性不存在。杰卡德相似系数定义为两个属性同时存在的比例除以两个属性中任何一个存在的比例。例如,对于属性A和属性B,A的取值为[0, 1, 1, 0],B的取值为[1, 0, 1, 1],通过计算它们的交集数量和并集数量,杰卡德相似系数为0.33。
- 包含关系(Containment):对于二值属性,可以检查两个属性之间的包含关系。如果一个属性的取值完全包含在另一个属性的取值中,那么它们的包含关系为真。例如,属性A的取值为[0, 1, 0, 1],属性B的取值为[0, 1, 0, 1, 1],属性A包含于属性B。
数值属性
对于数值属性(Numeric Attribute),可以使用以下方法进行邻近度(Proximity)测量:
- 欧氏距离(Euclidean Distance):欧氏距离是最常用的距离度量方法,用于衡量数值属性之间的差异。对于两个数值属性,欧氏距离定义为它们在每个维度上差值的平方和的平方根。例如,对于属性A和属性B,它们的取值分别为a和b,则欧氏距离为√((a₁ - b₁)² + (a₂ - b₂)² + … + (aₙ - bₙ)²)。
- 曼哈顿距离(Manhattan Distance):曼哈顿距离也称为城市街区距离,用于衡量数值属性之间的差异。对于两个数值属性,曼哈顿距离定义为它们在每个维度上差值的绝对值之和。例如,对于属性A和属性B,它们的取值分别为a和b,则曼哈顿距离为|a₁ - b₁| + |a₂ - b₂| + … + |aₙ - bₙ|。
- 闵可夫斯基距离(Minkowski Distance):闵可夫斯基距离是欧氏距离和曼哈顿距离的推广形式,可以根据参数p的不同取值来衡量数值属性之间的差异。当p=2时,闵可夫斯基距离等同于欧氏距离;当p=1时,闵可夫斯基距离等同于曼哈顿距离。
- 切比雪夫距离(Chebyshev Distance):切比雪夫距离用于衡量数值属性之间的最大差异。对于两个数值属性,切比雪夫距离定义为它们在每个维度上差值的绝对值的最大值。例如,对于属性A和属性B,它们的取值分别为a和b,则切比雪夫距离为max(|a₁ - b₁|, |a₂ - b₂|, …, |aₙ - bₙ|)。
余弦相似性
余弦相似性(Cosine Similarity)是一种常用的相似性度量方法,用于衡量两个向量之间的方向相似程度,特别适用于文本或高维度数据的相似性计算。
在信息检索、推荐系统、文本聚类等领域,余弦相似性常被用于计算文本或高维度数据之间的相似性或相关性。