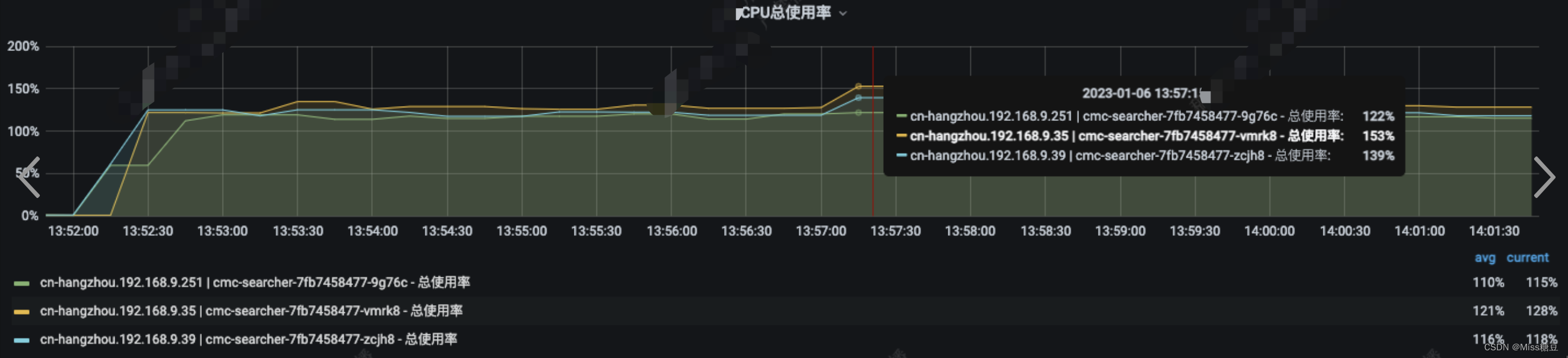
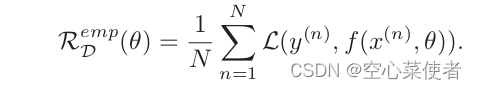Transformer
首先我们来回顾一下Transformer
模型架构图

对于Transformer从宏观角度可以可以理解为6个Encoder+6个Decoder组成
各部分介绍
输入部分
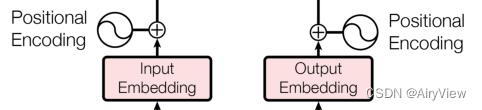
主要就是词嵌入+位置编码
对于词嵌入比较简单,就是对一个句子里的每个词做一个嵌入操作映射到相应的维度。一般来说就是先把句子中的词转为对应的数字索引,然后根据这个索引做embedding操作得到一个相应维度的向量。
对于位置编码,Transformer这里的位置编码是不可学习的(不会更新),直接用公式计算出来的。

其中dmodel是词嵌入得到单个词的向量的维度大小;
pos表示词的位置,比如"我爱学习啊"这句话有5个词,其位置就分别为0,1,2,3,4;
2i和2i+1分别表示在维度的偶数位置和奇数位置(i表示的是维度,这个维度的大小是dmodel,假如dmodel的大小为512,那么维度位置取值为0~511,那么i的取值为0~255,2i的取值为0,2,4···510,2i+1的取值为1,3,5···511),也就是说在偶数位置使用sin,奇数位置使用cos;
最后得到的每个词的位置编码维度大小和其词嵌入维度大小一样(均为dmodel),因此将每个词的位置编码和词嵌入加起来得到最终输入。
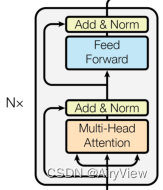
Encoder
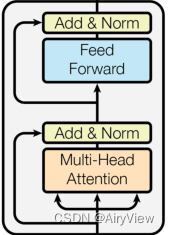
主要包含多头注意力和前馈神经网络。
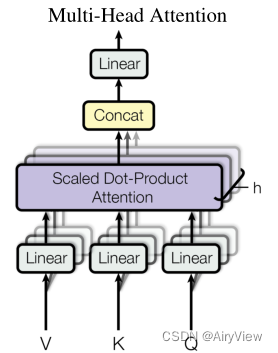
首先是Muti-Head Attention,其包含多个Scaled Dot-Product Attention,将多个Scaled Dot-Product Attention的输出结果拼接在一起然后传入Linear层将其映射为和输入矩阵维度一样。
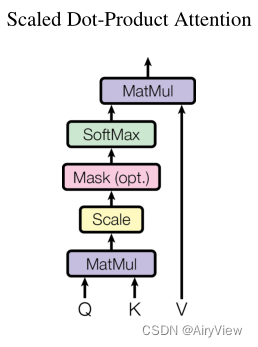
其次对于Scaled Dot-Product Attention则是重点了。图中的Q、K、V是由该模块输入X分别乘WQ,WK,WV得到的,而WQ,WK,WV是随机初始化得到并在训练过程和其他参数一样根据梯度下降进行更新。那么Attention的计算公式如下(dk是Q矩阵的列数):
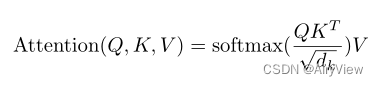
简单来说就是Q乘K的转置然后除以根号dk来防止内积过大并做softmax操作得到概率最后乘V得到单词之间的Attention系数。

然后Add & Norm比较好理解,第一个Add & Norm就是应用了残差连接将Multi-Head Attention的输入和输出相加然后做layerNorm操作(一种将每一层神经元的输入都转成均值方差都一样的归一化操作);第二个Add & Norm同理将FeedForward的输入和输出相加然后做layerNorm操作。


最后是Feed Forward层,比较简单,主要就是两个linear层。
Decoder
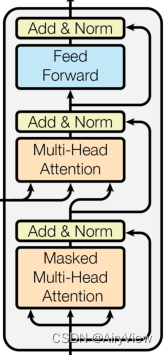
基本和Encoder大差不差。主要的几点不同如下:
第一个Muti-Head Attention多了个Masked,该操作在Scaled Dot-Product Attention中的Attention计算公式的softmax操作之前使用。该操作就是屏蔽单词后面的内容,使得训练的时候与预测时都不能看到之后的单词信息而保持一致。
第二个Muti-Head Attention的K、V矩阵则是由Encoder的输出提供的,其输入只生成Q矩阵。
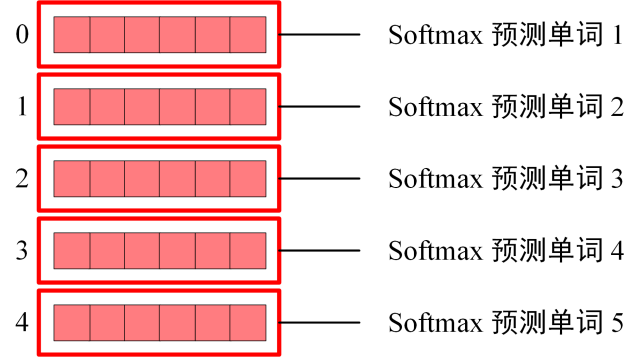
输出部分

一般来说就是通过linear层将其映射到词表维度,最后做softmax求各个词的概率。
GPT
GPT的核心思想是把Transformer的decoder拿出来在没有标号的大量文本数据上训练一个语言模型来获得一个预训练模型,然后用其在子任务上做微调得到每一个任务所需的分类器。
模型架构图
其由12个Transformer中的Decoder模块经修改后组成,相比于原始的Decoder其去掉了第二个Muti-Head Attention。由于语言模型是利用上文预测下一个单词的,那么就保留采用Mask Multi-Head Attention,其中的Masked会对单词的下文遮挡。

实现过程与原理
其主要分为两个阶段:无监督Pre-training和有监督Fine-tuning。
无监督Pre-training
对于第一个阶段。假设有一个未标记的文本u,其中每个词表示为ui,从u1一直到un,取一个超参数k,代表上下文窗口大小(或输入序列的长度)。既然要预测第i个出现的概率,第i个词表示为ui,通过下面公式即使用模型 通过ui前面的k个词来预测ui的概率,并把所有的i得到的概率加起来,由于做了log操作,所以相当于所有词出现的概率相乘即这个文本出现的联合概率。总的来说就是训练一个模型使其能够最大概率的输出跟我的文本长得一样的文本。
通过ui前面的k个词来预测ui的概率,并把所有的i得到的概率加起来,由于做了log操作,所以相当于所有词出现的概率相乘即这个文本出现的联合概率。总的来说就是训练一个模型使其能够最大概率的输出跟我的文本长得一样的文本。
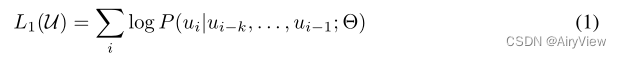
使用的模型则是上面说transformer的decoder变种。假如我们要预测词u的概率,将其前k个词记为U,将其做一个词嵌入的投影并加上位置信息的编码得到h0(We是词的Embedding矩阵,Wp是位置编码的Embedding矩阵),后面n层每一层的输入来自上一层的输出,最后一层输出做一个词嵌入的投影并通过softmax得到概率分布。

有监督Fine-tuning
对于第二个阶段。假设一个集合输入一个C集合 ,
,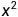 到
到 ,其输出为一个分类y的标号,将该集合输入到训练好的模型中得到其中transformer_block最后一层的输出
,其输出为一个分类y的标号,将该集合输入到训练好的模型中得到其中transformer_block最后一层的输出 ,然后乘以参数Wy(预测输出时的参数,该参数随着微调过程会调整)做一个softmax操作就可以得到概率了
,然后乘以参数Wy(预测输出时的参数,该参数随着微调过程会调整)做一个softmax操作就可以得到概率了
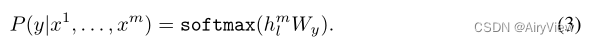
那么基于上述把所有带标号的序列输入进去后计算其是真实分类标号的联合概率,那么微调的时候应该使结果L2更大,即联合概率更大。

不仅需要调整参数使得L2更大,结合考虑之前预训练的L1可以提高模型泛化性和加速收敛。也就是在微调时考虑两个目标函数,即不仅需要给定一个序列预测序列的下一个词还需要给定一个完整序列预测其对应的标号。通过一个超参数 将这两个目标函数联系起来。不过注意这里的L1使用的是和L2一样的集合C,只是不需要使用到标号y。
将这两个目标函数联系起来。不过注意这里的L1使用的是和L2一样的集合C,只是不需要使用到标号y。
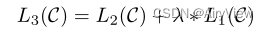
关于GPT-2和GPT-3
GPT-2在模型方面和GPT差不多,主要不同的地方是在子任务的处理时不提供任何相关的训练样本而是直接用预训练的模型去对子任务做预测,精炼点说就是用无监督的预训练模型去做有监督任务。GPT2.0旨在通过一个数量更大更丰富广泛通用性强质量高的无监督训练数据训练更好更大的预训练模型,把GPT第二阶段Fine-tuning有监督地做下游任务换成了无监督地做下游任务。总的来说GPT模型其发展倾向于用更少的有监督数据+更多的无监督数据去训练模型。
GPT-1在子任务上使用训练样本微调更新参数,GPT-2则不使用相关训练样本,而GPT-3则在子任务上使用少量的相关训练样本但不更新参数。为了更好的了解GPT-2和GPT-3的区别,我们要解释两个概念,“zero-shot”表示不提供样本,“few-shot”表示每个子任务提供10-100个训练样本。那么GPT-2就是一个参数量较小的zero-shot,而GPT-3就是一个参数量更大的few-shot。当然更具体的可以去看论文,这里就不多赘述了
BERT
模型架构图
BERT主要使用了Transformer的Encoder架构,将多个Encoder堆叠在一起,其中 使用了12个Encoder,
使用了12个Encoder,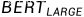 使用了24个Encoder。
使用了24个Encoder。
修改点
输入部分
BERT相对于GPT系列的单向采用双向表示,使得其对于文本生成类任务不太适用了,并且ICLR2020这篇Incorporating BERT into Neural Machine Translation也尝试了简单的用bert做机器翻译也不会得到好的效果。虽然不适合上述任务,但其可以很好的用于比如NSP(Next Sentence Prediction )任务,一般包含问答(QA)和自然语言推理(NLI)等等。而这类任务一般包含一个句子对的输入。那么每个句子对的开头用一个特殊的分类标记([CLS]),然后用一个特殊的标记([SEP])将句子分开。
相对于原始的Transformer的输入部分,主要有两处修改:
①位置编码被修改为了可学习的位置嵌入;
②新增了段嵌入以表明该词属于哪个句子。

也就是说最终输入为词嵌入+段嵌入+可学习的位置嵌入
词嵌入比较简单,不多赘述。
对于段嵌入,比如图中[CLS] my dog is cute [seq]为第一句话,he likes play ##ing{其实##代表ing是play后缀,所以实际为playing,不过因为play比较常见,所以进行了拆分} [seq]为第二句话,也就是说总共有两段,那么这里可以理解为对这两段做embedding操作,所以得到的结果中处于同一段(句)的词的段嵌入一定相同。
对于位置嵌入,可以理解为对每个词在原来句子中的位置做embedding操作,其实这三个操作的实现几乎一样,都是基于Embedding,只不过嵌入字典的大小不同,说这么多可能还是有点晦涩难懂,看一下代码实现保证你就懂了,如下图:

预训练
没有使用传统的从左到右或从右到左的语言模型来预训练BERT,而是使用两个无监督任务预训练BERT,即MLM和NSP。
GPT是典型的自回归模型(AR,autoregressive),只考虑单侧信息,而BERT是自编码模型(AE,autoencoding),可以利用上下文信息从损坏的输入数据中预测重建原始数据。
MLM
那么BERT是如何损坏文本信息,然后让其重建呢?主要是用到了MASK操作。又因为[MASK]在微调期间不会出现,所以会在预训练和微调之间造成了不匹配。为了缓解这一点,我们并不总是用实际的[MASK]替换单词。
mask操作的策略如下:
首先随机选取15%的词进行MASK(但实际上这15%并不是全部MASK,呼应了前面的那句话),对于这15%的词,再进行如下操作权衡:
80%替换为[MASK];
10%替换成随机词(ps:有很小概率随机到自己);
10%不变
所以总得来说MLM任务类似于把文本随机挖空一些词然后做完形填空。比如输入是一句话“新年快乐”。
对于上面提到的GPT模型其优化目标为:
P(新年快乐)=P(新)P(年|新)P(快|新年)P(乐|新年快);那么此时BERT的MLM任务的优化目标:
假如经过MASK操作后变为“新[MASK]快乐”
P(新年快乐|新[MASK]快乐)=P([MASK]=年|新[MASK]快乐)NSP
为了训练一个能够理解句子关系的模型,我们对一个二元化的NSP任务进行了预训练,该任务可以从任何单语言语料库中简单地生成。具体来说,在为每个预训练例子选择句子A和B时,50%的情况下B是A之后的实际下一句句子(标记为IsNext,即正样本), 另外50%的情况下B是语料库中的随机句子(标记为NotNext,即负样本)。如下图所示,C用于NSP(就是用得到的[CLS]表示来做二分类任务)。

微调

上图分别是在各种下游任务(句子对分类任务、单个句子分类任务、问答任务、序列标注任务)上微调BERT。
对于每个任务,我们只需将特定于任务的输入和输出插入BERT,并对所有端到端的参数进行微调。在输出端,词表示被送入输出层用于词级别的任务,例如序列标记或问答,而[CLS]表示被送入输出层用于分类任务,例如包含或情感分析。
与预训练相比,微调成本相对较低。
从完全相同的预训练模型开始,本文中的所有结果可以在一个云TPU上花费最多1小时复现,或者在一个GPU上花几个小时。
扩展

文中提到了和的参数量,我们不妨借助下面的图计算推导一下:

首先嵌入层的字典大小就是词表大小,为30k(ps:这里的k不是指参数,就是千的意思),然后映射到的维度是H;
然后多头自注意力层,对于每个头得到Q、K、V需要
 进行映射,其大小均为H*64,由于有A个头,且A*64=H,所以把它们在每个头之间合并起来就相当于3个H*H的矩阵,之后还需要对输出做一个Linear层,其参数大小为H*H,所以总共是
进行映射,其大小均为H*64,由于有A个头,且A*64=H,所以把它们在每个头之间合并起来就相当于3个H*H的矩阵,之后还需要对输出做一个Linear层,其参数大小为H*H,所以总共是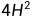 ;
;
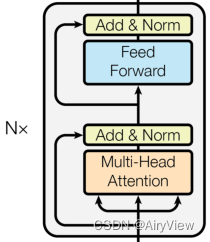
最后是前馈神经网络层,主要就是两个Linear,第一个Linear输入是H,输出是4H,第二个Linear输入是4H,输出是H,那么总共是
 。
。
所以说总的参数个数为30k*H +  *L
*L
那么把和的H和L分别代入得到:
30000*768+12*768*768*12=107,974,656≈110M
30000*1024+12*1024*1024*24=332,709,888≈340M
VIT
模型架构图
VIT(Vision Transformer)就是将多个Encoder堆叠起来,不过根据下面的图来看其Encoder和我们认识中的传统的Transformer的Encoder有细微的差别,具体的留到下面小节分析。
修改点
输入部分
之前的Transformer架构相关模型都是用在NLP领域,所以输入都是由多个词组成的句子,而现在的输入变成了由多个像素组成的图片,那么自然第一想法就是把像素类比为词输入进去,但是一张图片的像素个数往往远大于句子的长度,这样会导致输入的序列长度非常长,所以显然是不行的。
VIT的思想是把图片切成一个个patch,一个patch含有多个像素,对应句子中的token。

假如图像为HxWxC,其中H为高,W为宽,C为通道数,我们把其切为N个大小为PxPxC的patch,其中N=HW/P^2,N就是Transformer输入的实际有效序列长度;
在Transformer块中使用的隐向量大小为dmodel,那么需要通过一个线性投影将patch展平然后映射到dmodel维度;
类似于BERT,开头也加上了[class],所以需要得到其词嵌入,此时序列长度为N+1;
对整个序列使用标准的可学习1D位置嵌入得到各个“词”的位置嵌入(可以理解为nn.Embedding(N+1,d_model)),其中[class]的词嵌入与其位置嵌入相加,其余patch通过步骤2得到的dmodel维度结果与其位置嵌入相加。得到的最终结果就是真正的输入了。
Encoder部分
传统的Encoder
VIT中的Encoder

在该Encoder部分,无论是多头自注意力层还是MLP层,其都把norm操作提前了。
我个人认为是在做NLP时最开始生成的embedding都是归一化过的,现在改成图像了,所以需要先把图像中每个patch对应的输入先做归一化。
Swin Transformer
模型架构图

宏观来看主要是使用到了多个transformer的encoder部分,首先从上面图可以看出这里encoder的归一化LN操作也提前了且对传统的多头自注意力层做了修改,其次相对于前面谈到的模型,encoder块之间不是简单的堆叠,而是中间穿插了Patch Merging操作。
流程剖析
Patch Partition
这一步的思路和VIT相似,就是把图片切成一个个4x4的patch(VIT中是16x16)。由于输入图片高H、宽W以及通道数3,所以切分后,一个patch就是4x4x3,有HW/16个patch,对应图中表示的维度为 。
。
Linear Embedding
这层比较简单,就是应用了线性嵌入层,将其投影到任意维度(记为C),经过这一层得到的维度为 。
。
Swin Transformer Block
窗口多头自注意力(W-MSA)
相比于VIT中把含有多个patch的图片类比为含有多个token的句子输入到transformer块中,Swin Transfomer主要是把一个图片分为多个window(一个window中有多个patch),也就是说每次输入到transformer块中的东西变为了一个含有多个patch的window,而一张图片中的多个window就类比为了多个句子,更进一步类比为输入的批。
假设一个图片有hxw个patch(那么类比为输入到transformer块中的序列长度为hw),C为transformer块中的隐层维度,我们来计算一下W-MSA和VIT中MSA的复杂度:
首先对于VIT中的MSA:
输入X分别与参数
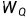 、
、 、
、 相乘得到Q、K、V。其中X维度为(hw,C),、、的维度均为(C,C)(ps:由于有多头,假设有A个头,使得实际单个头里这些W的维度是(C,B),但由于A*B=C,把各个头的W矩阵拼接起来就是维度(C,C)了,那么等价于我们忽略多头来估算处理的情况,下面第2步涉及到C的也是用到了类似思想)。此时复杂度为
相乘得到Q、K、V。其中X维度为(hw,C),、、的维度均为(C,C)(ps:由于有多头,假设有A个头,使得实际单个头里这些W的维度是(C,B),但由于A*B=C,把各个头的W矩阵拼接起来就是维度(C,C)了,那么等价于我们忽略多头来估算处理的情况,下面第2步涉及到C的也是用到了类似思想)。此时复杂度为 。
。
对于attention公式,涉及到
 以及softmax操作后与V相乘,第一个矩阵乘法的左右乘数的矩阵维度为(hw,C)和(C,hw),那么复杂度为
以及softmax操作后与V相乘,第一个矩阵乘法的左右乘数的矩阵维度为(hw,C)和(C,hw),那么复杂度为 ,第二个矩阵乘法的左右乘数的矩阵维度为(hw,hw)和(hw,c),那么复杂度为。这一步总复杂度为
,第二个矩阵乘法的左右乘数的矩阵维度为(hw,hw)和(hw,c),那么复杂度为。这一步总复杂度为
最后结果(维度是(hw,C))还需要过一个(C,C)的Linear层得到attention层输出,复杂度为
 。
。
所以VIT中W-MSA总的复杂度为:

其次对于W-MSA:
VIT中一次输入一个图片,patch个数为hw,类比为序列长度为hw,那么W-MSA一次输入一个窗口,patch个数为 ,一个图片中有
,一个图片中有 个windows,所以可以理解为批量为的"序列长度"为版本的MSA。式(1)中hw替换为,然后整个结果乘,即
个windows,所以可以理解为批量为的"序列长度"为版本的MSA。式(1)中hw替换为,然后整个结果乘,即
 ,化简之后得到复杂度如下:
,化简之后得到复杂度如下:

根据公式很明显得出,如果M*M<hw,那么W-MSA的复杂度比MSA更小。
移动窗口多头自注意力(SW-MSA)
W-MSA缺乏跨窗口之间的通信,这限制了它的建模能力。为了引入跨窗口间通信,同时保持非重叠窗口的高效计算。因此提出了SW-MSA,该方法在连续Swin Transformer块中的两个分区配置之间交替(如下图,也就是说每两个encoder块中第一个使用W-MSA,第二个使用SW-MSA)。

具体做法就是对原始图片进行循环移位,比如下图中,把原图的A、B、C部分(其中A的高或宽为M/2)进行了移位得到了新的图像矩阵,对新的图像进行窗口划分即可,这样巧妙的引入了跨窗口间的通信,但又带来了新的问题,即一个窗口中可能包含原本不相邻的patch,这些不相邻的patch不应该一起做自注意力的,因为它们之间没有太大联系且这个移位操作是我们人为引入的,模型不应该学习它们的关系。那么如下图所示需要给含有不相邻patch的窗口引入掩码模板以便在计算attention的softmax操作之前把不相邻的部分变成一个很小的负值,使得其在softmax操作中几乎对其他项没有影响。最后需要把循环移位还原回去,因为我们需要保持原来图片的相对位置,保持其整体图片的语义信息,如果没有这一步,那么图片会在操作过程中一直往右下角移,最终导致其语义信息被破坏掉。

掩码模板就是把不相邻的不需要的那部分设置为-100,其他需要的为0,这样和原始softmax操作之前的矩阵结果加起来,使得不需要的部分数值非常小,经过softmax操作后变为0。这些掩码模板官方给出了很好的示例,具体如下:

第一个窗口不存在不相邻patch,所以掩码模板全为0,其他窗口都存在不相邻patch,所以有特定的掩码模板(模板大小就是seq_len*seq_len,其中seq_len是输入到transformer块中的序列长度,可以理解为一个窗口中的patch数量)。
图中例子图片大小是14x14,一个窗口有7x7个patch(可以类比为每次输入序列长度为49),即M=7,所以移动的部分shift为M/2=3。
掩码模板的更具体实现可参考官方issuehttps://github.com/microsoft/Swin-Transformer/issues/38
相对位置编码
上面说到一个窗口中有多个patch,可以类比为一个序列中有多个token,也就是每次输入到块中的是一个含有多个patch的窗口,显然需要为窗口中的patch加上位置编码,而该模型使用的是相对位置编码,并且不是在输入的时候加上位置编码,而是在计算attention的公式中在进行softmax操作之前得到矩阵上加上位置编码,如下图中的B。
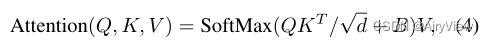
假如一个窗口有MxM个patch(可以类比为NLP中一句话有MxM个token,所以相当于序列长度为),显然B矩阵的形状为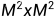 。
。
那么B如何得到呢?具体举例如下:
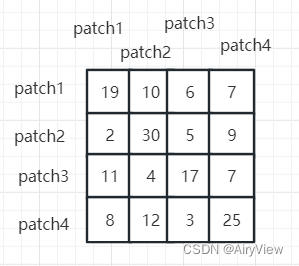
为了方便举例画图,假设一个窗口有4个patch,那么可以类比为序列长度为4,那么此时通过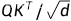 得到的结果矩阵维度是4x4,假设其如下:
得到的结果矩阵维度是4x4,假设其如下:
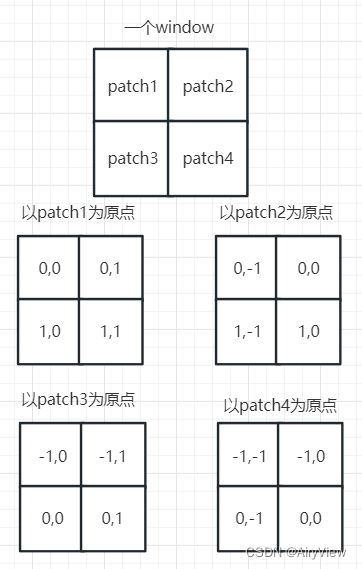
分别以patch1、patch2、patch3、patch4为(0,0)原点得到的二维相对位置分别如下:
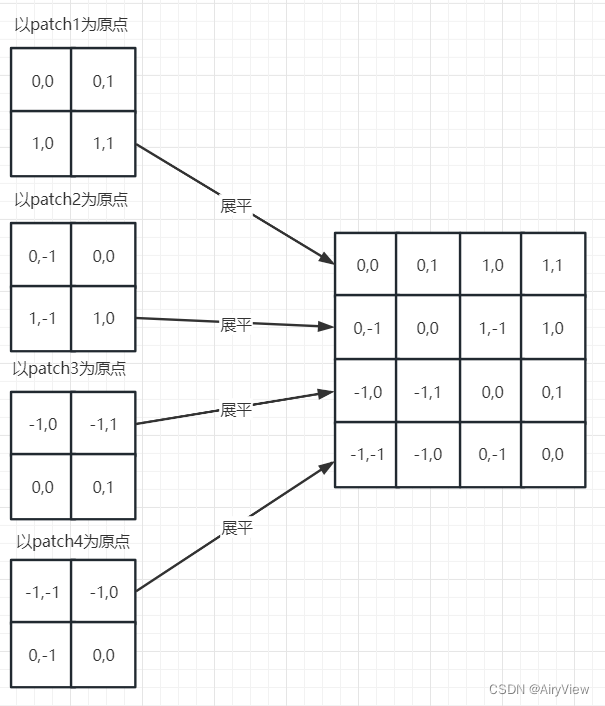
然后分别把得到的四个矩阵展平为一行,拼接成新的4x4的矩阵:
然后设一个window中有MxM个patch,这个例子中我们M=2,那么操作如下,最终得到4x4的索引矩阵

最后根据这个矩阵中的各个索引去做嵌入操作得到值组成的4x4矩阵就是我们公式中的B矩阵。
其中嵌入操作可以理解为nn.Embedding((2M-1)*(2M-1), 1),相当于对这些索引做一个词典大小为(2M-1)*(2M-1),嵌入向量维度大小为1的嵌入操作,当然了,由于这个索引是不可学习的,考虑到自注意力机制都是多头的,假设有num_heads个头,一般为了方便,可以一次生成所有头的B矩阵(此时维度是4x4xnum_heads),因此嵌入操作修改为nn.Embedding((2M-1)*(2M-1), num_heads)。
Patch Merging
顾名思义就是把邻近的小patch合并成一个patch,是一个下采样的过程。假设原始张量维度为HxWxC,这里为了方便假设C为1,本文中主要是下采样两倍,那么就每隔一个点选一个组成patch,使得原始张量变为了4个,维度变为了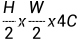 ,然后用2C个1x1的卷积核操作把通道数变为了2C,最后维度为
,然后用2C个1x1的卷积核操作把通道数变为了2C,最后维度为 。具体变换过程如下图:
。具体变换过程如下图:

MAE
模型架构与流程
MAE(Masked Autoencoders)用到了Transformer中的encoder和decoder,不同于之前的模型,大部分都只用到了两者中的一个。该模型主要就是抽取图像特征并进行图像重建恢复。

将图像划分为多个patch(这一步借鉴于VIT),然后随机mask掉75%的patch;
然后把未mask的剩余patch作为序列输入到encoder中(这里使用的是前面讲的VIT模型,所以对于输入的处理也相同,即线性投影和位置嵌入);
因为transformer块的输入和输出形状相同,所以将encoder输出与之前mask掉的patch按照原图的顺序拼接起来作为decoder的输入(对于输入处理当然还是需要加入位置嵌入的);
decoder输出后,最后一层是线性投影,其输出通道的数量等于一个patch中的像素值的数量,以便于重建图像。损失函数则是在像素空间中计算重建图像和原始图像之间的均方误差(MSE),这里只计算被mask的patch上的损失。
其中MAE的解码端只在预训练期间用于执行图像重建任务,在下游任务微调不需要使用。


![一篇文章彻底搞懂折半查找法[二分查找法]算法~](https://img-blog.csdnimg.cn/65bdadcf26ec4504be70c3b4da0d050b.png)