一、机器学习的基本要素
-
机器学习的基本要素: 模型 学习准则 优化算法
其中模型分为线性和非线性。学习准则有用损失函数来评价模型的好坏,还有经验风险最小化准则,大概意思就是在平均损失函数中获得最小的损失函数,但是因为样本可能很小,不全面,会造成过拟合问题,因此引入结构风险最小化准则,也就是参数的正则化来限制模型能力,防止模型过拟合。 -
模型定义: 通过学习算法在训练集上进行优化参数 θ \theta θ,能够获得在测试集合上与真实值接近的映射关系的函数 f ( x , θ ) f(x,\theta) f(x,θ)就是模型。
-
不同深度学习的任务区别就是输出的区间不同: 如二分类,多分类以及回归问题(连续输出)
-
在名为模型的 f ( x , θ ) f(x,\theta) f(x,θ)中, x x x为输入的测试集, θ \theta θ为可优化的参数,而 m m m为参数的个数
-
模型分为线性和非线性两种。
-
分布的相似性用KL散度和交叉熵损失来描述
-
损失函数为非负实函数,用来描述模型预测和实际的标签之间的差异
-
损失函数有:0-1损失函数、平方损失函数、交叉熵损失函数、Hinge损失函数。其中0-1损失函数数学性质不好,导数为0且不连续。 平方损失函数用来预测,交叉熵损失函数用来分类,Hinge函数用来二分类。
-
经验风险:训练集上的平均损失 也即是所有验证集的损失和取平均。其函数表达式如下
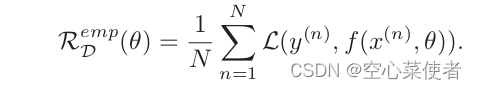
-
Empirical–经验的。
-
经验风险最小化(Empirical Risk Minimization,ERM)准则 也就是找到一组参数,使得经验风险最小化。
-
未解决经验风险最小化过程中的过拟合问题,引入参数正则化来限制模型的能力。
-
限制模型能力,使其不要过度地最小化经验风险。这种准则就是结构风险最小化(Structure Risk Minimization,SRM)准则。
-
机器学习的训练过程其实就是最优化问题的求解过程。
-
验证数据集(validation dataset)是模型训练过程中留出的样本集,它可以用于调整模型的超参数和评估模型的能力。
-
但测试数据集(test dataset)不同,虽然同是模型训练过程中留出的样本集,但它是用于评估最终模型的性能,帮助对比多个最终模型并做出选择。https://cloud.tencent.com/developer/article/1119094
-
小批量随机梯度下降方法有收敛快,计算开销小的优点,因此逐渐成为大规模的机器学习中的主要优化算法。
-
线性回归(Linear Regression)是机器学习和统计学中最基础和广泛应用的模型,是一种对自变量和因变量之间关系进行建模的回归分析。自变量数量为 1 时称为简单回归,自变量数量大于 1 时称为多元回归。
-
⊕ 定义为两个向量的拼接操作
机器学习的简单示例:线性回归
- 规定一组样本,我们希望学习到最优的线性回归模型的参数 w w w,我们有四种参数估计的方法:经验风险最小化,结构风险最小化,最大似然估计,最大后验估计。