SC和TSO都被称之为强(strong)保序模型;
- because the global memory order of each model usually respects (preserves) per-thread program order;
- 回想一下,对于load和store的所有四种组合(Load -> Load、Load -> Store、Store -> Store 和 Store -> Load),SC 保留了来自同一线程的两个内存操作的所有顺序,而 TSO 保留了除 Store -> Load 顺序外的前三个顺序。
因此,我们需要一种更宽松的memory consistency model,这些模型试图只保留程序员“需要”的顺序。
- 这种方法的主要好处是,通过允许更多的硬件和软件(编译器和运行时系统)优化,要求更少的顺序约束可以促进更高的性能。
- 主要缺点是,当“需要”顺序时,宽松模型必须形式化,并为程序员或低层次软件提供机制以将这种顺序传达给实现,并且供应商未能就统一的宽松模型达成一致,从而损害了可移植性。
研究更宽松的模型的动机是什么?
 这段顺序,SC和TSO模型都能保证r2/r3的值,是符合程序员预期的,即:
这段顺序,SC和TSO模型都能保证r2/r3的值,是符合程序员预期的,即:
- 对于r2, S1 -> S3 -> L1 loads SET -> L2.
- 对于r3, S2 -> S3 -> L1 loads SET -> L3.
但是:除了上面这两个预期的顺序,SC 和 TSO 还需要顺序 S1 -> S2 和 L2 -> L3。保留这些附加顺序可能会限制实现优化以提高性能,但程序不需要这些附加顺序来进行正确操作。
再考虑如下的场景:
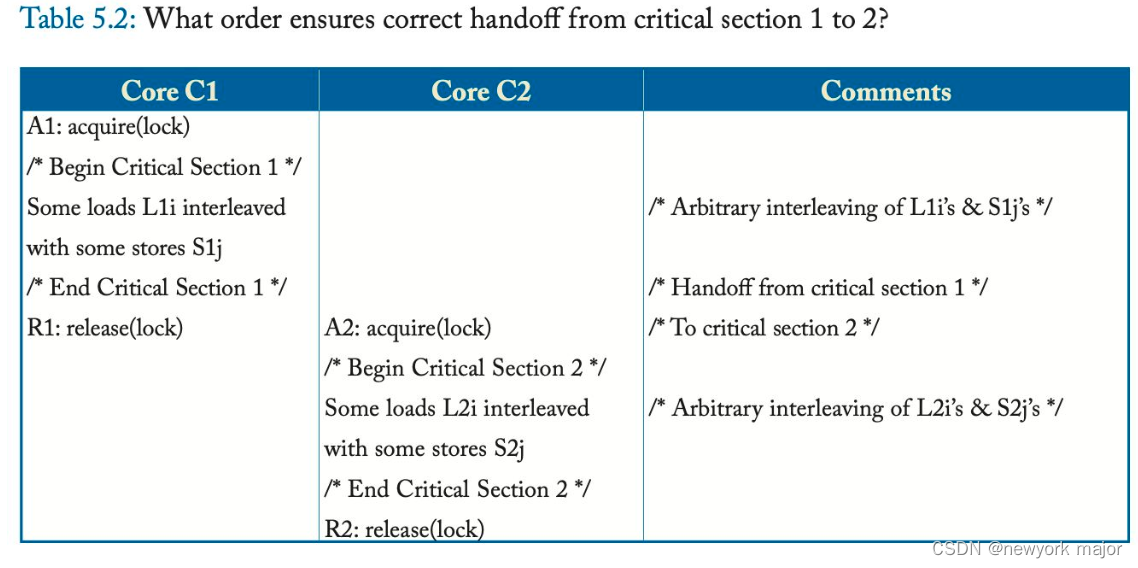
表 5.2 描述了using the same lock在两个临界区 (critical section) 之间进行切换的更一般情况。假设硬件支持锁获取 (acquire)(例如,使用 test-and-set 执行 read-modify-write 并循环直到成功)和锁释放 (release)(例如,store the value 0)。让core C1 获取锁,执行临界区 1,任意交织load (L1i) 和store (S1j),然后释放锁。类似地,让core C2 执行临界区 2,包括load (L2i) 和store (S2j) 的任意交织。
从临界区 1 到临界区 2 的切换的正确操作取决于这些操作的顺序:
- All L1i, All S1j -> R1 -> A2 -> All L2i, All S2j.
- 其中逗号 (",") 分隔未指定顺序的操作。
正确的操作不依赖于每个临界区中load和store的任何顺序——除非操作是针对相同的地址(在这种情况下需要顺序以保持连续的处理器顺序)。即:
所有 L1i 和 S1j 可以以任何顺序相互关联,并且所有 L2i 和 S2j 可以以任何顺序相互关联
如果正确的操作不依赖于许多load和store之间的顺序,也许可以通过放宽它们之间的顺序来获得更高的性能,因为load和store通常比锁获取和释放要频繁得多。这就是宽松或弱模型所做的。
OPPORTUNITIES TO EXPLOIT REORDERING
现在假设一个relaxed memory consistency model,that allows us to reorder any memory operations unless there is a FENCE between them。这种宽松的模型迫使程序员推断需要对哪些操作进行保持顺序,这是一个缺点,但它也启用了许多可以提高性能的优化。
在这里,我们讨论了一些常见且重要的优化;
- Non-FIFO, Coalescing Write Buffer
- TSO 启用了 FIFO write buffer,它通过隐藏提交store的部分或全部延迟来提高性能。
- 尽管 FIFO write buffer提高了性能,但更优化的设计将使用允许合并写入的非 FIFO write buffer(即,在程序顺序上不连续的两个store可以写入write buffer中的同一个表项)
- 非 FIFO 合并write buffer通常违反 TSO,因为 TSO 要求store按程序顺序出现。我们的示例宽松模型允许store在非 FIFO write buffer中合并,只要store没有被 FENCE 分隔
2. Simpler Support for Core Speculation
在具有强一致性模型的系统中,core可能会在准备好提交之前推测性地执行超出程序顺序的load。
- R10000 通过将逐出缓存块的地址与core已推测load但尚未提交的地址列表(即内核load队列的内容)进行比较来检查推测。
- 在具有宽松内存一致性模型的系统中,core可以不按程序顺序执行load,而无需将这些load的地址与传入的coherence请求的地址进行比较;
3. CouplingConsistency andCoherence
我们之前提倡将一致性和连贯性解耦以管理劳神的复杂性。或者,通过“打开coherence魔盒”,宽松模型可以提供比强模型更好的性能。
- For example, an implementation might allow a subset of cores to load the new value from a store even as the rest of the cores can still load the old value, temporarily breaking coherence’s single-writer–multiple-reader invariant.
- This situation can occur, for example, when two thread contexts logically share a per-core write buffer or when two cores share an L1 data cache.
然而,“打开cohenrence魔盒”会带来相当大的劳神工作和验证复杂性,GPU 和异构处理器为何以及如何在强制一致性的同时打开cohenrence魔盒暂且不论,我们先考虑不打开coherence的魔盒;
宽松一致性模型 (XC) 示例
基本思想
- XC 提供了 FENCE 指令,以便程序员可以指示何时需要顺序;
- 否则,默认情况下,load和store是无序的;
- FENCE指令的作用:
- 让core Ci 执行一些load和/或store Xi,然后是 FENCE 指令,然后再执行一些load和/或store Yi。
- FENCE 确保内存顺序将所有 Xi 操作排序在 FENCE 之前,而 FENCE 又在所有 Yi 操作之前。
- 同一core的两个 FENCE 也保持有序;
- 但是,FENCE 不会影响其他core的内存操作顺序(这就是为什么 "FENCE" 可能是比 "barrier" 更好的名称)
- FENCE指令还有多个子指令,可以指令fence指令的类型,比如,read/read fence, store/store fence等,此处进讨论对所有操作进行排序的FENCE;
- XC memory order遵循的program order如下:
- Load -> FENCE
- Store -> FENCE
- FENCE -> FENCE
- FENCE -> Load
- FENCE -> Store
- XC 保持了TSO针对于同一地址的访问的ordering;
- Load -> Load to the same address
- Load -> Store to the same address
- Store -> Store to the same address
These rules enforce the sequential processor model (i.e., sequential core semantics) and prohibit behaviors that might astonish(疑惑) programmers.
- For example, the Store -> Store rule pre vents a critical section that performs “A = 1” then “A = 2” from completing strangely with A set to 1.
- Likewise, the Load -> Load rule ensures that if B was initially 0 and another thread performs “B = 1,” then the present thread cannot perform “r1 = B” then “r2 = B” with r1 getting 1 and r2 getting 0, as if B’s value went from new to old.
XC 确保load由于它们自己的store而立即看到更新(如 TSO 的write buffer bypassing)。该规则保留了单线程的顺序性,也避免了程序员的惊讶。
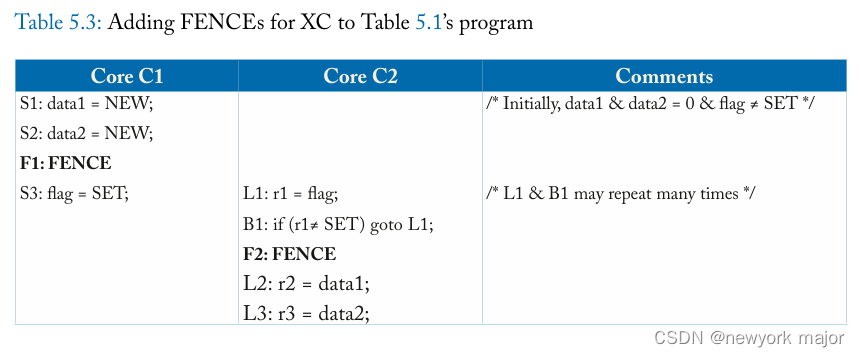
在 XC 下使用 Fence 的示例
这些 FENCE 确保:S1, S2 -> F1 -> S3 -> L1 loads SET -> F2 -> L2, L3.
XC规则形式化
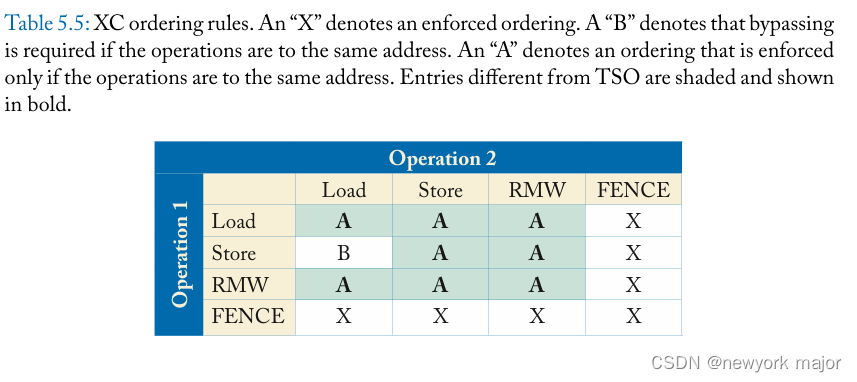
在这里,我们以与前两章的符号和方法一致的方式将 XC 形式化。再一次,让 L(a) 和 S(a) 分别代表load和store,地址是 a。命令 <p 和 <m 分别定义了per-processor program order和 global memory order。
更正式地说,XC 执行需要以下内容。
1. 所有core都将它们的load、store和 FENCE 插入到 <m 的顺序中:
If L(a) <p FENCE => L(a) <m FENCE /* Load -> FENCE */
If S(a) <p FENCE => S(a) <m FENCE /* Store -> FENCE */
If FENCE <p FENCE => FENCE <m FENCE /* FENCE -> FENCE */
If FENCE <p L(a) => FENCE <m L(a) /* FENCE -> Load */
If FENCE <p S(a) => FENCE <m S(a) /* FENCE -> Store */
2. 所有core将它们的load和store插入到相同的地址到 <m 的顺序中:
If L(a) <p L’(a) => L(a) <m L’ (a) /* Load -> Load to same address */
If L(a) <p S(a) => L(a) <m S(a) /* Load -> Store to same address */
If S(a) <p S’(a) => S(a) <m S’ (a) /* Store -> Store to same address */
3. 每个load从它之前的最后一个store中获取它的值到相同的地址:
Value of L(a) = Value of MAX <m {S(a) | S(a) <m L(a) or S(a) <p L(a)} /* Like TSO */
我们在表 5.5 中总结了这些顺序规则。该表与 SC 和 TSO 的类似表有很大不同。从视觉上看,该表显示仅对相同地址的操作或使用 FENCE 的操作强制保持执行顺序。和 TSO 一样,如果操作 1 是“store C”,操作 2 是“load C”,则store可以在load后进入全局顺序,但load必须已经看到新store的值。
Animplementation that allows only XC executions is an XC implementation.
XC操作实例详解


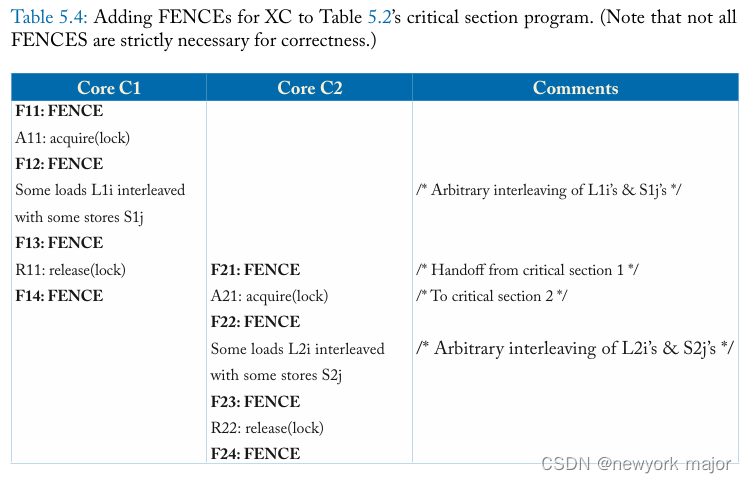
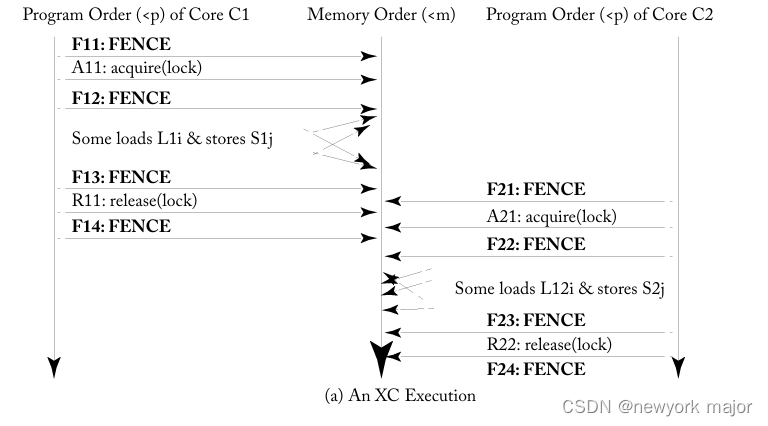
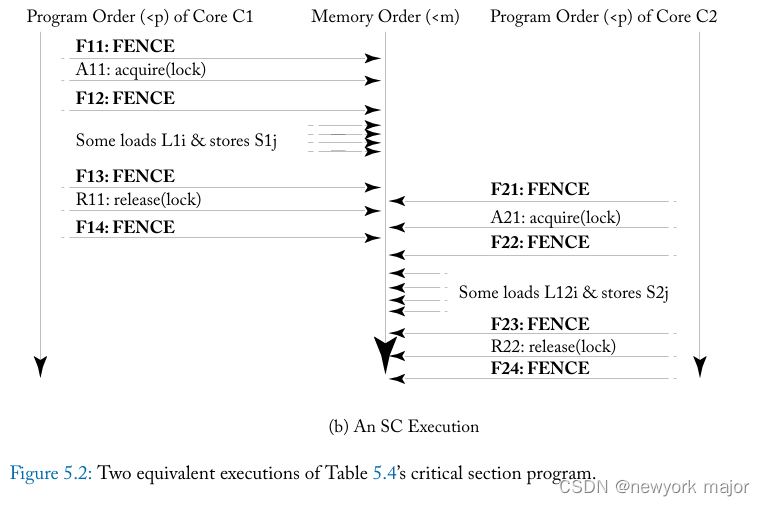
类似地,图 5.2a 描述了表 5.4 中临界区示例的执行,其中core C1 的load L1i 和store S1j 相互重新排序,core C2 的load L2i 和store S2j 也是如此。再一次,这些重新排序不会影响程序的结果。因此,就程序员所知,这种 XC 执行等同于图 5.2b 中描述的 SC 执行,其中没有重新排序load或store。
这些例子表明,如果有足够的 FENCE,像 XC 这样的宽松模型可以在程序员看来就像 SC。
XC实现原理
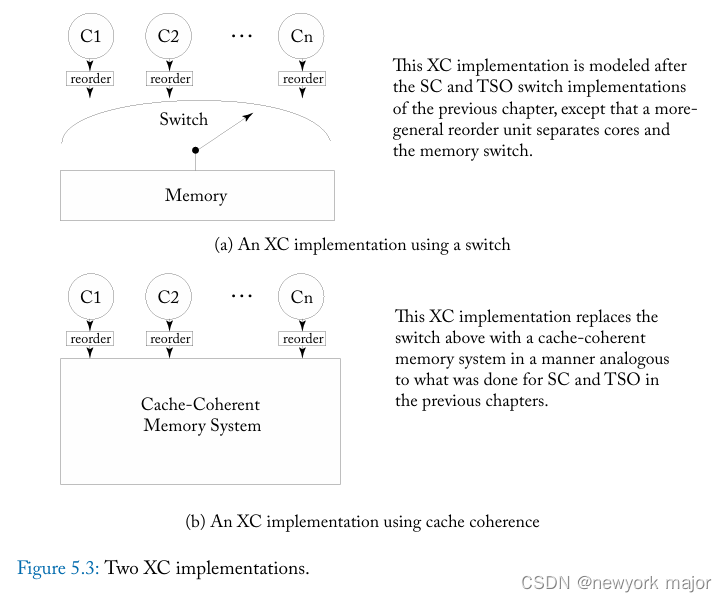
-
load、store和 FENCE 按照po的顺序,离开each core, and enter the tail of Ci’s reorder unit.
-
Ci 的重新排序单元对操作进行排队,并将它们从尾部传递到头部 (head),按照程序顺序或按照下面指定的规则重新排序。当 FENCE 到达重新排序单元的头部时,它会被丢弃。
reorder的规则:
1. FENCE 可以通过几种不同的方式实现(参见第 5.3.2 节),但它们必须强制执行。具体来说,无论地址如何,重新排序单元都可能不会重新排序:
Load -> FENCE
Store -> FENCE
FENCE -> FENCE
FENCE -> Load
FENCE -> Store
2. 同一地址,重新排序单元都可能不会重新排序:
Load -> Load
Load -> Store
Store -> Store (to the same address)
3. 重新排序单元必须确保load由于它们自己的store而立即看到更新。