LLMs:《Better & Faster Large Language Models via Multi-token Prediction》翻译与解读
目录
《Better & Faster Large Language Models via Multi-token Prediction》翻译与解读
Abstract
2、Method方法
Memory-efficient implementation 高效内存实现
Inference推理
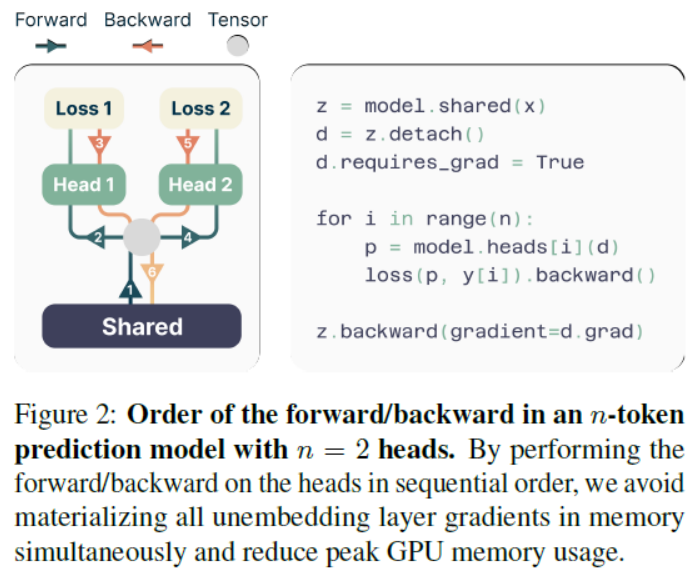
Figure 2: Order of the forward/backward in an n-token prediction model with n = 2 heads. By performing the forward/backward on the heads in sequential order, we avoid materializing all unembedding layer gradients in memory simultaneously and reduce peak GPU memory usage.图2:在n = 2个头的n个标记预测模型中向前/向后的顺序。通过在头部上按顺序执行向前/向后操作,我们避免了同时在内存中实现所有非嵌入层梯度,并减少了GPU内存的峰值使用。
7、Conclusion结论
《Better & Faster Large Language Models via Multi-token Prediction》翻译与解读
| 地址 | 论文地址:https://arxiv.org/abs/2404.19737 |
| 时间 | 2024年4月30日 |
| 作者 | Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, Gabriel Synnaeve |
| 总结 | 文章提出了一种新的训练语言模型的方法:多词预测。 背景痛点:当前语言模型主要采用下一词预测训练方式,但是这种方式容易过于局部化,忽略了更长程的依赖关系。下一词预测训练方式在训练和inference阶段上存在分布不匹配,训练时采用teacher forcing的方式,而inference时采用自回归生成方式,这会造成模型基础上预测能力的下降。 解决方案: >> 提出将语言模型训练任务从预测下一词扩展成预测多个下n词。在每个训练样本位置,语言模型需要同时预测下n个词。 >> 使用多头预测结构,共享主干网络提取上下文特征,每个词使用独立头进行预测。 >> 优化实现方式,采用顺序执行前向后向传播的方式,减小 GPU 内存占用。 核心特点: >> 相比下一词预测,多词预测任务可以强制模型学习长程依赖和选择性关键位置的信息。 >> 多词预测隐式上赋予关键选择位置更高权重,降低随机性,提高生成质量。 >> 从信息论角度看,多词预测任务强调了词与词之间的互信息,缓解了训练与inference阶段的分布不匹配问题。 优势: >> 在各种代码任务上效果明显,对大模型效果更佳,性能提升百分之几至十几点。 >> 可以在推理时利用多头实现自推测解码,速度可提升2-3倍。 >> 对小规模算法性任务也有明显帮助,优于单纯增加模型规模。 >> 在自然语言处理任务上,多词预测预训练模型在生成任务上优于下一词预测,在选择型任务上效果一致。 总之,这篇文章提出了一种简单而有效的多词预测训练任务,可以有效解决当前语言模型训练的一些问题,在很多下游任务上获得明显性能提升。 |
持续更新中……
Abstract
| Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language mod-els to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token pre-diction as an auxiliary training task, we measure improved downstream capabilities with no over-head in training time for both code and natural language models. The method is increasingly use-ful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are es-pecially pronounced on generative benchmarks like coding, where our models consistently out-perform strong baselines by several percentage points. Our 13B parameter models solves 12 %more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Ex-periments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3× faster at inference, even with large batch sizes. | 像GPT和Llama这样的大型语言模型是用下一个令牌预测损失来训练的。在这项工作中,我们建议训练语言模型一次预测多个未来标记可以提高样本效率。更具体地说,在训练语料库中的每个位置,我们要求模型使用n个独立的输出头,基于共享的模型主干预测接下来的n个词元。将多词元预测视为一项辅助训练任务,我们对代码和自然语言模型在没有训练时间开销的情况下改进的下游能力进行了度量。这种方法对于更大的模型尺寸非常有用,并且在多次训练时期保持其吸引力。在诸如编码等生成性基准测试中,我们的模型比强基线模型性能高出几个百分点。我们的130亿参数模型在HumanEval上解决问题的能力提高了12%,在MBPP上提高了17%,超过了类似的下一个词元模型。在小型算法任务上的实验表明,多词元预测有利于归纳头和算法推理能力的发展。作为一个额外的好处,使用4个令牌预测训练的模型在推理时速度提高了3倍,即使是在大批量的情况下。 |
2、Method方法
| Standard language modeling learns about a large text corpus x1, . . . xT by implementing a next-token prediction task. Formally, the learning objective is to minimize the cross-entropy loss where Pθ is our large language model under training, as to maximize the probability of xt+1 as the next future token, given the history of past tokens xt:1 = xt, . . . , x1. | 标准语言建模学习一个大型文本语料库x1,…通过实现下一个令牌预测任务。形式上,学习目标是最小化交叉熵损失 其中Pθ是我们在训练中的大型语言模型,为了最大化xt+1作为下一个未来标记的概率,给定过去标记xt的历史:1 = xt,…x1。 |
| In this work, we generalize the above by implementing a multi-token prediction task, where at each position of the training corpus, the model is instructed to predict n future tokens at once. This translates into the cross-entropy loss To make matters tractable, we assume that our large lan-guage model Pθ employs a shared trunk to produce a latent representation zt:1 of the observed context xt:1, then fed into n independent heads to predict in parallel each of the n future tokens (see Figure 1). This leads to the follow-ing factorization of the multi-token prediction cross-entropy loss: | 在这项工作中,我们通过实现一个多标记预测任务来推广上述内容,其中在训练语料库的每个位置,指示模型一次预测n个未来的标记。这转化为交叉熵损失 为了使问题易于处理,我们假设我们的大型语言模型Pθ使用共享主干来产生观察到的上下文xt:1的潜在表示zt:1,然后将其输入n个独立的头部,以并行地预测n个未来标记(见图1)。这导致了以下多标记预测交叉熵损失的分解: |
| In practice, our architecture consists of a shared transformer trunk fs producing the hidden representation zt:1 from the observed context xt:1, n independent output heads imple-mented in terms of transformer layers fhi , and a shared unembedding matrix fu. Therefore, to predict n future tokens, we compute: for i = 1, . . . n, where, in particular, Pθ(xt+1 | xt:1) is our next-token prediction head. See Appendix B for other variations of multi-token prediction architectures. | 在实践中,我们的体系结构包括一个共享的变压器主干fs,从观察到的上下文xt:1产生隐藏表示zt:1, n个根据变压器层fhi实现的独立输出头,以及一个共享的非嵌入矩阵fu。因此,为了预测n个未来的代币,我们计算: 对于I = 1,…n,其中,特别地,Pθ(xt+1 | xt:1)是我们的下一个标记预测头。参见附录B了解多令牌预测架构的其他变体。 |
Memory-efficient implementation 高效内存实现
| One big challenge in training multi-token predictors is reducing their GPU mem-ory utilization. To see why this is the case, recall that in current LLMs the vocabulary size V is much larger than the dimension d of the latent representation—therefore, logit vectors become the GPU memory usage bottleneck. Naive implementations of multi-token predictors that materialize all logits and their gradients, both of shape (n, V ), severely limit the allowable batch-size and average GPU memory utilization. Because of these reasons, in our architecture we propose to carefully adapt the sequence of forward and backward operations, as illustrated in Figure 2. In particular, after the forward pass through the shared trunk fs, we se-quentially compute the forward and backward pass of each independent output head fi, accumulating gradients at the trunk. While this creates logits (and their gradients) for the output head fi, these are freed before continuing to the next output head fi+1, requiring the long-term storage only of the d-dimensional trunk gradient ∂Ln/∂fs. In sum, we have reduced the peak GPU memory utilization from O(nV + d) to O(V + d), at no expense in runtime (Table S5). | 训练多令牌预测器的一大挑战是降低它们的GPU内存利用率。要了解为什么会出现这种情况,回想一下,在当前的llm中,词汇表大小V远大于潜在表示的维数d——因此,logit向量成为GPU内存使用的瓶颈。多标记预测器的朴素实现将所有logits及其梯度(形状都是(n, V))物化,严重限制了允许的批处理大小和平均GPU内存利用率。由于这些原因,在我们的体系结构中,我们建议仔细调整向前和向后操作的顺序,如图2所示。特别地,在前向通过共享干线fs后,我们依次计算每个独立输出头fi的前向和后向通过,在干线处累积梯度。虽然这会为输出头fi创建logits(及其梯度),但在继续到下一个输出头fi+1之前,这些logits会被释放,只需要长期存储d维主干梯度∂Ln/∂fs。总而言之,我们已经将GPU内存利用率峰值从0 (nV + d)降低到0 (V + d),而在运行时没有任何开销(表S5)。 |
Inference推理
| During inference time, the most basic use of the proposed architecture is vanilla next-token autoregressive prediction using the next-token prediction head Pθ(xt+1 |xt:1), while discarding all others. However, the additional output heads can be leveraged to speed up decoding from the next-token prediction head with self-speculative decoding methods such as blockwise parallel decoding (Stern et al., 2018)—a variant of speculative decoding (Leviathan et al., 2023) without the need for an additional draft model—and speculative decoding with Medusa-like tree attention (Cai et al., 2024). | 在推理期间,所提出的架构的最基本用途是使用下一个令牌预测头Pθ(xt+1 |xt:1)进行vanilla下一个令牌自回归预测,同时丢弃所有其他令牌。然而,可以利用额外的输出头来加速从下一个令牌预测头的解码,使用自推测解码方法,如块并行解码(Stern等人,2018)-一种推测解码的变体(Leviathan等人,2023),而不需要额外的草案模型-以及具有类似美杜莎树注意力的推测解码(Cai等人,2024)。 |
Figure 2: Order of the forward/backward in an n-token prediction model with n = 2 heads. By performing the forward/backward on the heads in sequential order, we avoid materializing all unembedding layer gradients in memory simultaneously and reduce peak GPU memory usage.图2:在n = 2个头的n个标记预测模型中向前/向后的顺序。通过在头部上按顺序执行向前/向后操作,我们避免了同时在内存中实现所有非嵌入层梯度,并减少了GPU内存的峰值使用。
7、Conclusion结论
| We have proposed multi-token prediction as an improvement over next-token prediction in training language models for generative or reasoning tasks. Our experiments (up to 7B pa-rameters and 1T tokens) show that this is increasingly useful for larger models and in particular show strong improve-ments for code tasks. We posit that our method reduces distribution mismatch between teacher-forced training and autoregressive generation. When used with speculative de-coding, exact inference gets 3 times faster. | 我们提出了多标记预测作为下一个标记预测的改进,用于生成或推理任务的训练语言模型。我们的实验(多达7B个参数和1T个令牌)表明,这对更大的模型越来越有用,特别是对代码任务有了很大的改进。我们假设我们的方法减少了教师强迫训练和自回归生成之间的分布不匹配。当与推测解码一起使用时,精确推理速度提高了3倍。 |
| In future work we would like to better understand how to au-tomatically choose n in multi-token prediction losses. One possibility to do so is to use loss scales and loss balanc-ing (Défossez et al., 2022). Also, optimal vocabulary sizes for multi-token prediction are likely different from those for next-token prediction, and tuning them could lead to better results, as well as improved trade-offs between compressed sequence length and compute-per-byte expenses. Finally, we would like to develop improved auxiliary prediction losses that operate in embedding spaces (LeCun, 2022). | 在未来的工作中,我们希望更好地理解如何在多令牌预测损失中自动选择n。这样做的一种可能性是使用损失尺度和损失平衡(dsamossez et al., 2022)。此外,多标记预测的最佳词汇表大小可能与下一个标记预测的最佳词汇表大小不同,对它们进行调优可能会产生更好的结果,并改进压缩序列长度和每字节计算费用之间的权衡。最后,我们希望开发在嵌入空间中运行的改进的辅助预测损失(LeCun, 2022)。 |