下面是音视频开发面试题精选:
- 1、纹理抗锯齿有哪些算法?各有哪些利弊?
- 2、使用 OpenGL PBO 为什么能提高效率?
- 3、iOS 如何使用分段转码,如何设置分片大小?
- 4、VideoToolbox 中是不是不存在平面格式(planar)对应的 YUV420、YUV422 和 YUV444 的 OSType 常量?
- 5、为什么在 YUV 转 RGB 转换中 UV 分量要减去 0.5?
- 6、在编辑 SDK 中的播放器对 OpenGL 的使用有哪些进阶的用法,和播放 SDK 中的视频播放存在哪些区别呢?
- 7、如何获取视频流中的 QP 值?
- 8、视频编码对 QP 值的控制有哪些?
1、纹理抗锯齿有哪些算法?各有哪些利弊?
纹理抗锯齿主要是指在计算机图形学中,减少或消除图像中由于纹理映射导致的锯齿效应的技术。常见的有以下几种:
- FXAA(快速近似抗锯齿):
- FXAA 是一种后处理技术,主要通过在像素着色器中应用边缘检测算法,对边缘附近的像素进行模糊处理,以减少锯齿。
- 它对显卡的要求不高,不依赖于额外的采样,因此性能消耗相对较低。
- FXAA 可以提供较快的处理速度,但可能会导致一些细节丢失,图像看起来可能会有些模糊。
- SSAA(超级采样抗锯齿):
- SSAA 是一种全场景抗锯齿技术,它通过在更高的分辨率下渲染整个场景,然后将其缩放到最终输出的分辨率,以获得更平滑的边缘。
- 这种方法可以在不损失细节的情况下提供非常高质量的图像,但性能消耗很高,因为它需要渲染更多的像素。
- SSAA 通常用于离线渲染,而不是实时渲染,因为它对硬件资源的要求非常高。
- MSAA(多重采样抗锯齿):
- MSAA 是一种在渲染过程中应用的抗锯齿技术,它只对每个像素的多个样本进行计算,而不是对整个像素进行计算。这可以减少几何锯齿,但对纹理锯齿的效果有限。
- MSAA 主要针对多边形边缘进行抗锯齿处理。相比 SSAA、MSAA 的性能消耗要低得多,因为它不需要渲染额外的像素,但可能在画质上略有妥协。
2、 使用 OpenGL PBO 为什么能提高效率?
为什么能提高效率:
- 减少 CPU 等待:PBO 支持异步传输,这意味着 CPU 在发起传输请求后不必等待 GPU 完成传输,可以继续执行其他任务。
- 减少数据拷贝:使用 PBO 可以减少从 CPU 内存到 GPU 内存的数据拷贝次数。例如,当更新纹理时,可以先将数据复制到 PBO,然后由 GPU 直接从 PBO 读取,而不是每次都从 CPU 内存中复制。
- 提高带宽利用:PBO 允许更有效地利用内存带宽,因为它减少了 CPU 和 GPU 之间的数据传输量。
- 优化显存利用:使用 PBO 可以避免在每次更新纹理时销毁和重新创建纹理内存,从而优化显存的利用率。
- 双缓冲或多缓冲技术:通过使用两个或多个 PBO,可以在一个 PBO 进行 GPU 操作的同时,使用 CPU 填充另一个 PBO,从而实现更高效的流水线操作。
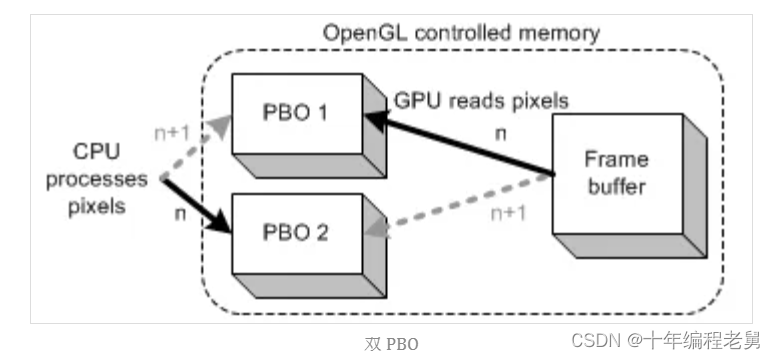
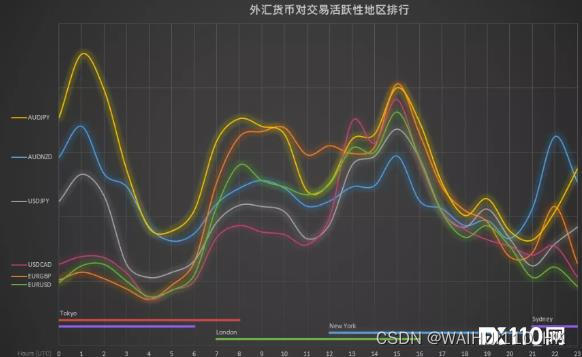
例如上图所示,利用 2 个 PBO 从帧缓冲区读回图像数据,使用 glReadPixels 通知 GPU 将图像数据从帧缓冲区读回到 PBO1 中,同时 CPU 可以直接处理 PBO2 中的图像数据。
通过交换 PBO 的方式进行拷贝和传送,可以实现这两步操作同时进行。
- 内存映射:PBO 的内存映射机制允许 CPU 直接访问 GPU 的缓冲区,这样可以更快速地传输数据,因为它避免了常规内存访问的开销。
- 适用场景:对于需要频繁更新或读取大量像素数据的应用程序,如图像处理、计算机视觉或大规模渲染任务,PBO 可以显著提高性能。
3、iOS 如何使用分段转码,如何设置分片大小?
初始化 AVAssetWriter 时可以设置 outputFileTypeProfile = AVFileTypeProfileMPEG4AppleHLS 即可打开 MP4 分段转码。
通过 preferredOutputSegmentInterval 设置转码后的每片大小。如果想手动切片,需要设置 preferredOutputSegmentInterval = kCMTimeIndefinite,并且在每次想要切片的位置调用 flushSegment 接口强制分片,注意调用接口的时机必须是 Sync 帧前。即每片的开始帧都是 Sync 帧。
分片的结果会通过设置的 AVAssetWriterDelegate 内部方法返回。
assetWriter_ = [[AVAssetWriter alloc] initWithContentType:[UTType typeWithIdentifier:AVFileTypeMPEG4]]; // 不能设置输出文件因为已经分段
assetWriter_.outputFileTypeProfile = AVFileTypeProfileMPEG4AppleHLS;
assetWriter_.preferredOutputSegmentInterval = CMTimeMake(5, 1); // 5s 一段
assetWriter_.initialSegmentStartTime = kCMTimeZero; // 开始时间,必设
assetWriter_.delegate = self; 4、VideoToolbox 中是不是不存在平面格式(planar)对应的 YUV420、YUV422 和 YUV444 的 OSType 常量?
iOS 的 API 中能找到的平面格式有:kCVPixelFormatType_420YpCbCr8Planar、kCVPixelFormatType_420YpCbCr8PlanarFullRange,这两种平面格式分别对应 y420 和 f420。对这两种格式测试下来,目前系统播放器支持,系统相机不支持。yuv422 和 yuv444 的平面格式目前没找到。
此外,iOS 的 API 中能找到的半平面格式有:kCVPixelFormatType_420YpCbCr8BiPlanarVideoRange、kCVPixelFormatType_422YpCbCr8BiPlanarVideoRange、kCVPixelFormatType_444YpCbCr8BiPlanarVideoRange 这些。

5、为什么在 YUV 转 RGB 转换中 UV 分量要减去 0.5?
在 YUV 到 RGB 的转换公式中,U 和 V 分量减去 0.5 的原因与 YUV 颜色空间的编码方式有关。YUV 格式通常用于视频压缩,其中 Y 代表亮度(luminance),而 U 和 V 代表色度(chrominance),也就是颜色信息。在某些 YUV 格式中,U 和 V 的取值范围是标准化的,例如在 8 位颜色深度中,U 和 V 的取值范围是从 -128 到 127。这种表示方法将色度的中心点设在了 0,使得色度信号可以表示正负偏差。
在进行 YUV 到 RGB 的转换时,为了将 U 和 V 的取值范围从对称的 -128 到 127 归一化为非对称的 0 到 255,并且将中心点从 128 移动到 0,需要对 U 和 V 进行偏移量的减法操作。具体来说,通过减去 0.5(或 128 对应的小数形式),可以将 U 和 V 的取值范围转换为 0 到 255,从而与 RGB 的取值范围相匹配。
例如,如果使用如下的转换公式:
[ R = Y + 1.4075 * (V - 128) ]
[ G = Y - 0.34414 * (U - 128) - 0.71414 * (V - 128) ]
[ B = Y + 1.772 * (U - 128) ]
在这个公式中,U 和 V 减去 128 实际上就是将色度信号的中心从 128 移动到 0,然后再进行缩放操作以匹配 RGB 的取值范围。如果不进行这个减法操作,色度信号将不会正确地转换为 RGB 颜色空间,导致颜色失真。
总结来说,U 和 V 分量后面减去 0.5 是为了将色度信号的表示方式从 YUV 颜色空间转换为 RGB 颜色空间,确保颜色信息的准确传递。
6、在编辑 SDK 中的播放器和播放 SDK 中的视频播放存在哪些区别呢?编辑场景的播放器对 OpenGL 的使用有哪些进阶的用法?
剪辑方向的视频播放与播放器的视频播放相比最大的区别就是:需要处理更复杂渲染场景。
编辑场景的播放器可以注意下面这些点:
- 处理复杂的输入和渲染。特效的输入可能是多个视频多个参数,因此需要对顶点着色器、片段着色器、渲染管道有更深的理解。例如,转场特效有两个视频输入、旋转特效的顶点函数设置需要考虑透视矩阵等。
- 处理多线程渲染。因为多个特效的加入需要对渲染的流程做优化可能会引入多线程渲染。多线程渲染需要考虑的问题如下:
- 每个线程通常需要自己的 OpenGL 上下文(除非是在共享列表中共享)。创建和销毁 OpenGL 上下文需要谨慎处理,以避免资源泄露和上下文不一致的问题。
- 资源共享。在多线程渲染中,需要处理好 OpenGL 资源(如纹理、缓冲区对象等)的共享问题。要注意 FBO 和 VAO 是不能共享。
- 同步问题。确保线程间的渲染命令顺序正确。OpenGL 的同步机制(如 glFinish)太慢可考虑 glFence 等。
- 避免状态冲突。在一个线程中修改 OpenGL 状态,在另一个线程中可能会导致不可预测的结果。需要同步的状态应考虑同步机制,不需要同步的状态应该在切换之前将状态恢复。
- 多线程环境中,资源的创建和销毁需要特别注意。确保在所有线程中正确地清理和释放资源,避免内存泄漏和其他资源管理问题。
- 避免频繁的上下文切换。频繁切换 OpenGL 上下文是一个非常耗时的操作,尤其是当涉及到多个线程时。应该尽可能地减少上下文切换,或者设计合理的上下文使用策略,以提高性能。
- 渲染流程结构可以做优化设计。
- 有可异步处理的效果可以异步线程处理。
- 如果有缩小特效可以将缩小特效放在前面,这样后面的特效处理所需的数据大小将会降低。
- 何时将解码数据转换为纹理,避免 GPU 和 CPU 之间数据拷贝。
- 调试和报错。glGet 拿到关键状态,在关键节点 glGetError 以及处理这些报错。
7、如何获取视频流中的 QP 值?
在 H.264 中,量化参数(QP)的获取涉及到几个层级:
- 图像参数集(PPS):包含初始量化参数 pic_init_qp_minus26,其取值范围是 -26 到 +25。
- 片头(Slice Header):每个片(Slice)都有自己的片头,其中包含 slice_qp_delta,表示当前片所有宏块的量化参数初始值 QPy Slice,计算公式为:QPy Slice = 26 + pic_init_qp_minus26 + slice_qp_delta,其取值范围是 0 到 51。
- 宏块(Macroblock, MB):宏块是编码的基本单元,宏块量化参数偏移值 mb_qp_delta 表示前后两个宏块之间的偏移,取值范围是 -26 到 +25。第一个宏块的 QP 值等于片头的 QP 值,后续宏块的 QP 值计算方式为 QP = (QPprev + mb_qp_delta + 52) % 52。
要从 H.264 码流中提取 QP 值,需要执行以下步骤:
- 1、解析 NALU:首先需要定位并提取 NALU,因为 QP 值信息分布在 PPS 和 Slice Header 中。
- 2、解析 PPS:找到 PPS NALU 并解析出 pic_init_qp_minus26。
- 3、解析 Slice Header:对于每个 Slice,解析 Slice Header 以获取 slice_qp_delta。
- 4、计算 QP 值:根据上述解析出的参数和宏块信息,计算每个宏块的 QP 值。
使用工具:可以使用如 ffmpeg 等工具来辅助解析码流和提取 QP 值。例如,ffmpeg 提供了 -showqp 选项来显示量化参数。
编程实现:也可以通过编程方式,如使用 Python 结合相关库来解析 H.264 码流并提取 QP 值。
在实际应用中,可能需要结合具体的编码场景和需求来选择合适的工具和方法,以实现对 H.264 码流中 QP 值的提取。
8、视频编码对 QP 值的控制有哪些?
在视频编码中,QP(Quantization Parameter)值是一个重要的概念,它对编码后视频的质量和码率有着直接的影响。视频编码中的量化步骤是将像素值映射到一个较小的数值范围内,这一步骤会损失一些图像细节,但可以显著减少编码后视频的数据量。
QP 值决定了量化过程中的量化步长,从而影响量化的精度。较小的 QP 值意味着量化步长较小,量化过程更精细,编码后的视频质量更高,但同时也会导致码率增加; 较大的 QP 值意味着量化步长较大,量化过程更粗糙,编码后的视频质量较低,但码率会减少。
对于部分软编库来说是可以设置平均/最大/最小 QP 值的。下面我们重点说下客户端如何设置 QP。
- 在 iOS 中使用 VideoToolbox 编码视频时通过属性值设置最大 QP 和最小 QP 值。属性 key 为 kVTCompressionPropertyKey_MinAllowedFrameQP、kVTCompressionPropertyKey_MaxAllowedFrameQP。 这样编码器就会保证是编码出来的文件 QP 值在这个范围。其次如果你设置了码率,他也会在这个范围内尽量使用你设置的码率。但是如果你设置的码率过高或者过低,QP 值无法满足时,编码器则根据优先以 QP 值自动调整码率。
- Android 部分机型的编码器可以开启质量编码模式,即 KEY_BITRATE_MODE 为 BITRATE_MODE_CQ。质量可以通过设置参数 KEY_VIDEO_QP_MAX、KEY_VIDEO_QP_MIN、KEY_VIDEO_QP_P_MAX、KEY_VIDEO_QP_P_MIN、KEY_VIDEO_QP_B_MAX、KEY_VIDEO_QP_B_MIN 等一系列参数来控制帧的 QP 值。


![[C++核心编程-01]----C++内存四区详细解析](https://img-blog.csdnimg.cn/direct/fa47ee2ea80f4fda9b6c27152cef7d04.png)