集成学习案例一 (幸福感预测)
背景介绍
此案例是一个数据挖掘类型的比赛——幸福感预测的baseline。比赛的数据使用的是官方的《中国综合社会调查(CGSS)》文件中的调查结果中的数据,其共包含有139个维度的特征,包括个体变量(性别、年龄、地域、职业、健康、婚姻与政治面貌等等)、家庭变量(父母、配偶、子女、家庭资本等等)、社会态度(公平、信用、公共服务)等特征。
数据信息
赛题要求使用以上 139 维的特征,使用 8000 余组数据进行对于个人幸福感的预测(预测值为1,2,3,4,5,其中1代表幸福感最低,5代表幸福感最高)。 因为考虑到变量个数较多,部分变量间关系复杂,数据分为完整版和精简版两类。可从精简版入手熟悉赛题后,使用完整版挖掘更多信息。在这里我直接使用了完整版的数据。赛题也给出了index文件中包含每个变量对应的问卷题目,以及变量取值的含义;survey文件中为原版问卷,作为补充以方便理解问题背景。
评价指标
最终的评价指标为均方误差MSE,即:
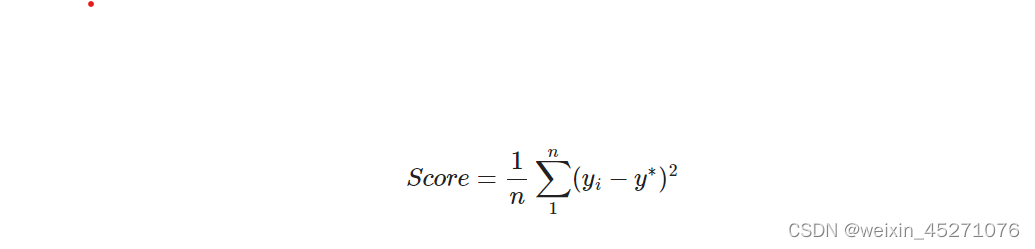
import os
import time
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
from datetime import datetime
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score, roc_curve, mean_squared_error,mean_absolute_error, f1_score
import lightgbm as lgb
import xgboost as xgb
from sklearn.ensemble import RandomForestRegressor as rfr
from sklearn.ensemble import ExtraTreesRegressor as etr
from sklearn.linear_model import BayesianRidge as br
from sklearn.ensemble import GradientBoostingRegressor as gbr
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import LinearRegression as lr
from sklearn.linear_model import ElasticNet as en
from sklearn.kernel_ridge import KernelRidge as kr
from sklearn.model_selection import KFold, StratifiedKFold,GroupKFold, RepeatedKFold
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn import preprocessing
import logging
import warnings
warnings.filterwarnings('ignore') #消除warning
#parse_dates将Date列设置为时间类型
#index_col将Date列设置为索引
#latin-1向下兼容ASCII
train=pd.read_csv("D:\caicai_sklearn\others\happyiness_datasets\happiness_train_complete.csv",
parse_dates=['survey_time'],encoding='latin-1')
test=pd.read_csv("D:\caicai_sklearn\others\happyiness_datasets\happiness_test_complete.csv",
parse_dates=['survey_time'],encoding='latin-1')
train=train[train['happiness']!=-8].reset_index(drop=True)
#二、使用reset_index(drop=True)
#drop=True表示删除原索引,不然会在数据表格中新生成一列’index’数据
train_data_copy=train.copy()
target_col='happiness'
target=train_data_copy[target_col]
del train_data_copy[target_col]#去除目标列
data=pd.concat([train_data_copy,test],axis=0,ignore_index=True)
#当 ignore_index=True 时,表示在合并数据的同时忽略原始数据的索引(index),新生成的合并后的数据会重新生成一个默认的整数索引。
#make feature +5
#csv中有复数值:-1、-2、-3、-8,将他们视为有问题的特征,但是不删去
def getres1(row):
return len([x for x in row.values if type(x)==int and x<0])
def getres2(row):
return len([x for x in row.values if type(x)==int and x==-8])
def getres3(row):
return len([x for x in row.values if type(x)==int and x==-1])
def getres4(row):
return len([x for x in row.values if type(x)==int and x==-2])
def getres5(row):
return len([x for x in row.values if type(x)==int and x==-3])
#检查数据
data['neg1'] = data[data.columns].apply(lambda row:getres1(row),axis=1)
data.loc[data['neg1']>20,'neg1'] = 20 #平滑处理
data['neg2'] = data[data.columns].apply(lambda row:getres2(row),axis=1)
data['neg3'] = data[data.columns].apply(lambda row:getres3(row),axis=1)
data['neg4'] = data[data.columns].apply(lambda row:getres4(row),axis=1)
data['neg5'] = data[data.columns].apply(lambda row:getres5(row),axis=1)
#填充缺失值,在这里我采取的方式是将缺失值补全,使用fillna(value),其中value的数值根据具体的情况来确定。
#例如将大部分缺失信息认为是零,将家庭成员数认为是1,将家庭收入这个特征认为是66365,即所有家庭的收入平均值。
#部分实现代码如下:
#可以根据业务来填充
data['work_status']=data['work_status'].fillna(0)
data['work_yr'] = data['work_yr'].fillna(0)
data['work_manage'] = data['work_manage'].fillna(0)
data['work_type'] = data['work_type'].fillna(0)
data['edu_yr'] = data['edu_yr'].fillna(0)
data['edu_status'] = data['edu_status'].fillna(0)
data['s_work_type'] = data['s_work_type'].fillna(0)
data['s_work_status'] = data['s_work_status'].fillna(0)
data['s_political'] = data['s_political'].fillna(0)
data['s_hukou'] = data['s_hukou'].fillna(0)
data['s_income'] = data['s_income'].fillna(0)
data['s_birth'] = data['s_birth'].fillna(0)
data['s_edu'] = data['s_edu'].fillna(0)
data['s_work_exper'] = data['s_work_exper'].fillna(0)
data['minor_child'] = data['minor_child'].fillna(0)
data['marital_now'] = data['marital_now'].fillna(0)
data['marital_1st'] = data['marital_1st'].fillna(0)
data['social_neighbor']=data['social_neighbor'].fillna(0)
data['social_friend']=data['social_friend'].fillna(0)
data['hukou_loc']=data['hukou_loc'].fillna(1) #最少为1,表示户口
data['family_income']=data['family_income'].fillna(66365) #删除问题值后的平均值
bins=[0,17,26,34,50,63,100]#人工分好箱子
data['age_bin']=pd.cut(data['age'],bins,labels=[0,1,2,3,4,5])
‘’'一、column_stack方法的基本原理
column_stack方法的主要作用是将两个或更多的一维或二维数组沿着列方向(即第二个轴)堆叠起来。这种方法在需要将多个数组的数据组合成一个更大的数组时非常有用。不同于hstack方法,column_stack要求输入的数组至少为二维,或者是一维数组但能够升维成二维。如果输入的是一维数组,column_stack会在堆叠前将它们转换为列向量。
二、column_stack方法的参数详解
column_stack方法接受一个元组作为输入,该元组包含要堆叠的数组。这些数组可以是一维的也可以是二维的,但它们的行数必须相同,以便在列方向上堆叠。下面是一个参数详解:
tup:一个元组,包含要堆叠的数组。这些数组可以是一维的也可以是二维的,但它们的第一维度(行数)必须相同。
值得注意的是,column_stack方法在内部实际上是使用concatenate函数来实现的,其等价于np.concatenate((a, b), axis=1),其中a和b是要堆叠的数组。
三、column_stack方法的使用示例’‘’
数据增广
这一步,我们需要进一步分析每一个特征之间的关系,从而进行数据增广。经过思考,这里我添加了如下的特征:第一次结婚年龄、最近结婚年龄、是否再婚、配偶年龄、配偶年龄差、各种收入比(与配偶之间的收入比、十年后预期收入与现在收入之比等等)、收入与住房面积比(其中也包括10年后期望收入等等各种情况)、社会阶级(10年后的社会阶级、14年后的社会阶级等等)、悠闲指数、满意指数、信任指数等等。除此之外,我还考虑了对于同一省、市、县进行了归一化。例如同一省市内的收入的平均值等以及一个个体相对于同省、市、县其他人的各个指标的情况。同时也考虑了对于同龄人之间的相互比较,即在同龄人中的收入情况、健康情况等等。具体的实现代码如下:
#第一次结婚年龄 147
data['marital_1stbir'] = data['marital_1st'] - data['birth']
#最近结婚年龄 148
data['marital_nowtbir'] = data['marital_now'] - data['birth']
#是否再婚 149
data['mar'] = data['marital_nowtbir'] - data['marital_1stbir']
#配偶年龄 150
data['marital_sbir'] = data['marital_now']-data['s_birth']
#配偶年龄差 151
data['age_'] = data['marital_nowtbir'] - data['marital_sbir']
#收入比 151+7 =158
data['income/s_income'] = data['income']/(data['s_income']+1) #同居伴侣
data['income+s_income'] = data['income']+(data['s_income']+1)
data['income/family_income'] = data['income']/(data['family_income']+1)
data['all_income/family_income'] = (data['income']+data['s_income'])/(data['family_income']+1)
data['income/inc_exp'] = data['income']/(data['inc_exp']+1)
data['family_income/m'] = data['family_income']/(data['family_m']+0.01)
data['income/m'] = data['income']/(data['family_m']+0.01)
#收入/面积比 158+4=162
data['income/floor_area'] = data['income']/(data['floor_area']+0.01)
data['all_income/floor_area'] = (data['income']+data['s_income'])/(data['floor_area']+0.01)
data['family_income/floor_area'] = data['family_income']/(data['floor_area']+0.01)
data['floor_area/m'] = data['floor_area']/(data['family_m']+0.01)
#class 162+3=165
data['class_10_diff'] = (data['class_10_after'] - data['class'])
data['class_diff'] = data['class'] - data['class_10_before']
data['class_14_diff'] = data['class'] - data['class_14']
#悠闲指数 166
leisure_fea_lis = ['leisure_'+str(i) for i in range(1,13)]
data['leisure_sum'] = data[leisure_fea_lis].sum(axis=1) #skew
#满意指数 167
public_service_fea_lis = ['public_service_'+str(i) for i in range(1,10)]
data['public_service_sum'] = data[public_service_fea_lis].sum(axis=1) #skew
#信任指数 168
trust_fea_lis = ['trust_'+str(i) for i in range(1,14)]
data['trust_sum'] = data[trust_fea_lis].sum(axis=1) #skew
#province mean 168+13=181
data['province_income_mean'] = data.groupby(['province'])['income'].transform('mean').values
data['province_family_income_mean'] = data.groupby(['province'])['family_income'].transform('mean').values
data['province_equity_mean'] = data.groupby(['province'])['equity'].transform('mean').values
data['province_depression_mean'] = data.groupby(['province'])['depression'].transform('mean').values
data['province_floor_area_mean'] = data.groupby(['province'])['floor_area'].transform('mean').values
data['province_health_mean'] = data.groupby(['province'])['health'].transform('mean').values
data['province_class_10_diff_mean'] = data.groupby(['province'])['class_10_diff'].transform('mean').values
data['province_class_mean'] = data.groupby(['province'])['class'].transform('mean').values
data['province_health_problem_mean'] = data.groupby(['province'])['health_problem'].transform('mean').values
data['province_family_status_mean'] = data.groupby(['province'])['family_status'].transform('mean').values
data['province_leisure_sum_mean'] = data.groupby(['province'])['leisure_sum'].transform('mean').values
data['province_public_service_sum_mean'] = data.groupby(['province'])['public_service_sum'].transform('mean').values
data['province_trust_sum_mean'] = data.groupby(['province'])['trust_sum'].transform('mean').values
#city mean 181+13=194
data['city_income_mean'] = data.groupby(['city'])['income'].transform('mean').values #按照city分组
data['city_family_income_mean'] = data.groupby(['city'])['family_income'].transform('mean').values
data['city_equity_mean'] = data.groupby(['city'])['equity'].transform('mean').values
data['city_depression_mean'] = data.groupby(['city'])['depression'].transform('mean').values
data['city_floor_area_mean'] = data.groupby(['city'])['floor_area'].transform('mean').values
data['city_health_mean'] = data.groupby(['city'])['health'].transform('mean').values
data['city_class_10_diff_mean'] = data.groupby(['city'])['class_10_diff'].transform('mean').values
data['city_class_mean'] = data.groupby(['city'])['class'].transform('mean').values
data['city_health_problem_mean'] = data.groupby(['city'])['health_problem'].transform('mean').values
data['city_family_status_mean'] = data.groupby(['city'])['family_status'].transform('mean').values
data['city_leisure_sum_mean'] = data.groupby(['city'])['leisure_sum'].transform('mean').values
data['city_public_service_sum_mean'] = data.groupby(['city'])['public_service_sum'].transform('mean').values
data['city_trust_sum_mean'] = data.groupby(['city'])['trust_sum'].transform('mean').values
#county mean 194 + 13 = 207
data['county_income_mean'] = data.groupby(['county'])['income'].transform('mean').values
data['county_family_income_mean'] = data.groupby(['county'])['family_income'].transform('mean').values
data['county_equity_mean'] = data.groupby(['county'])['equity'].transform('mean').values
data['county_depression_mean'] = data.groupby(['county'])['depression'].transform('mean').values
data['county_floor_area_mean'] = data.groupby(['county'])['floor_area'].transform('mean').values
data['county_health_mean'] = data.groupby(['county'])['health'].transform('mean').values
data['county_class_10_diff_mean'] = data.groupby(['county'])['class_10_diff'].transform('mean').values
data['county_class_mean'] = data.groupby(['county'])['class'].transform('mean').values
data['county_health_problem_mean'] = data.groupby(['county'])['health_problem'].transform('mean').values
data['county_family_status_mean'] = data.groupby(['county'])['family_status'].transform('mean').values
data['county_leisure_sum_mean'] = data.groupby(['county'])['leisure_sum'].transform('mean').values
data['county_public_service_sum_mean'] = data.groupby(['county'])['public_service_sum'].transform('mean').values
data['county_trust_sum_mean'] = data.groupby(['county'])['trust_sum'].transform('mean').values
#ratio 相比同省 207 + 13 =220
data['income/province'] = data['income']/(data['province_income_mean'])
data['family_income/province'] = data['family_income']/(data['province_family_income_mean'])
data['equity/province'] = data['equity']/(data['province_equity_mean'])
data['depression/province'] = data['depression']/(data['province_depression_mean'])
data['floor_area/province'] = data['floor_area']/(data['province_floor_area_mean'])
data['health/province'] = data['health']/(data['province_health_mean'])
data['class_10_diff/province'] = data['class_10_diff']/(data['province_class_10_diff_mean'])
data['class/province'] = data['class']/(data['province_class_mean'])
data['health_problem/province'] = data['health_problem']/(data['province_health_problem_mean'])
data['family_status/province'] = data['family_status']/(data['province_family_status_mean'])
data['leisure_sum/province'] = data['leisure_sum']/(data['province_leisure_sum_mean'])
data['public_service_sum/province'] = data['public_service_sum']/(data['province_public_service_sum_mean'])
data['trust_sum/province'] = data['trust_sum']/(data['province_trust_sum_mean']+1)
#ratio 相比同市 220 + 13 =233
data['income/city'] = data['income']/(data['city_income_mean'])
data['family_income/city'] = data['family_income']/(data['city_family_income_mean'])
data['equity/city'] = data['equity']/(data['city_equity_mean'])
data['depression/city'] = data['depression']/(data['city_depression_mean'])
data['floor_area/city'] = data['floor_area']/(data['city_floor_area_mean'])
data['health/city'] = data['health']/(data['city_health_mean'])
data['class_10_diff/city'] = data['class_10_diff']/(data['city_class_10_diff_mean'])
data['class/city'] = data['class']/(data['city_class_mean'])
data['health_problem/city'] = data['health_problem']/(data['city_health_problem_mean'])
data['family_status/city'] = data['family_status']/(data['city_family_status_mean'])
data['leisure_sum/city'] = data['leisure_sum']/(data['city_leisure_sum_mean'])
data['public_service_sum/city'] = data['public_service_sum']/(data['city_public_service_sum_mean'])
data['trust_sum/city'] = data['trust_sum']/(data['city_trust_sum_mean'])
#ratio 相比同个地区 233 + 13 =246
data['income/county'] = data['income']/(data['county_income_mean'])
data['family_income/county'] = data['family_income']/(data['county_family_income_mean'])
data['equity/county'] = data['equity']/(data['county_equity_mean'])
data['depression/county'] = data['depression']/(data['county_depression_mean'])
data['floor_area/county'] = data['floor_area']/(data['county_floor_area_mean'])
data['health/county'] = data['health']/(data['county_health_mean'])
data['class_10_diff/county'] = data['class_10_diff']/(data['county_class_10_diff_mean'])
data['class/county'] = data['class']/(data['county_class_mean'])
data['health_problem/county'] = data['health_problem']/(data['county_health_problem_mean'])
data['family_status/county'] = data['family_status']/(data['county_family_status_mean'])
data['leisure_sum/county'] = data['leisure_sum']/(data['county_leisure_sum_mean'])
data['public_service_sum/county'] = data['public_service_sum']/(data['county_public_service_sum_mean'])
data['trust_sum/county'] = data['trust_sum']/(data['county_trust_sum_mean'])
#age mean 246+ 13 =259
data['age_income_mean'] = data.groupby(['age'])['income'].transform('mean').values
data['age_family_income_mean'] = data.groupby(['age'])['family_income'].transform('mean').values
data['age_equity_mean'] = data.groupby(['age'])['equity'].transform('mean').values
data['age_depression_mean'] = data.groupby(['age'])['depression'].transform('mean').values
data['age_floor_area_mean'] = data.groupby(['age'])['floor_area'].transform('mean').values
data['age_health_mean'] = data.groupby(['age'])['health'].transform('mean').values
data['age_class_10_diff_mean'] = data.groupby(['age'])['class_10_diff'].transform('mean').values
data['age_class_mean'] = data.groupby(['age'])['class'].transform('mean').values
data['age_health_problem_mean'] = data.groupby(['age'])['health_problem'].transform('mean').values
data['age_family_status_mean'] = data.groupby(['age'])['family_status'].transform('mean').values
data['age_leisure_sum_mean'] = data.groupby(['age'])['leisure_sum'].transform('mean').values
data['age_public_service_sum_mean'] = data.groupby(['age'])['public_service_sum'].transform('mean').values
data['age_trust_sum_mean'] = data.groupby(['age'])['trust_sum'].transform('mean').values
# 和同龄人相比259 + 13 =272
data['income/age'] = data['income']/(data['age_income_mean'])
data['family_income/age'] = data['family_income']/(data['age_family_income_mean'])
data['equity/age'] = data['equity']/(data['age_equity_mean'])
data['depression/age'] = data['depression']/(data['age_depression_mean'])
data['floor_area/age'] = data['floor_area']/(data['age_floor_area_mean'])
data['health/age'] = data['health']/(data['age_health_mean'])
data['class_10_diff/age'] = data['class_10_diff']/(data['age_class_10_diff_mean'])
data['class/age'] = data['class']/(data['age_class_mean'])
data['health_problem/age'] = data['health_problem']/(data['age_health_problem_mean'])
data['family_status/age'] = data['family_status']/(data['age_family_status_mean'])
data['leisure_sum/age'] = data['leisure_sum']/(data['age_leisure_sum_mean'])
data['public_service_sum/age'] = data['public_service_sum']/(data['age_public_service_sum_mean'])
data['trust_sum/age'] = data['trust_sum']/(data['age_trust_sum_mean'])
cat_fea = ['survey_type','gender','nationality','edu_status','political','hukou','hukou_loc','work_exper','work_status','work_type',
'work_manage','marital','s_political','s_hukou','s_work_exper','s_work_status','s_work_type','f_political','f_work_14',
'm_political','m_work_14'] #已经是0、1的值不需要onehot
noc_fea = [clo for clo in use_feature if clo not in cat_fea]
onehot_data = data[cat_fea].values
enc = preprocessing.OneHotEncoder(categories = 'auto')
oh_data=enc.fit_transform(onehot_data).toarray()
oh_data.shape #变为onehot编码格式
X_train_oh = oh_data[:train_shape,:]
X_test_oh = oh_data[train_shape:,:]
X_train_oh.shape #其中的训练集
X_train_383 = np.column_stack([data[:train_shape][noc_fea].values,X_train_oh])#先是noc,再是cat_fea
X_test_383 = np.column_stack([data[train_shape:][noc_fea].values,X_test_oh])
X_train_383.shape




![[公开课学习]台大李宏毅-自注意力机制 Transformer](https://img-blog.csdnimg.cn/direct/a37043ac6d2149c3a637c1fa97c9be36.png)