连续活跃天数统计
需求说明
什么是连续出现?
假设有如下日期信息: 20230401,20230402,20230403,20230405,20230406,20230407,20230410,20230411
则:
20230401-20230403 为一次连续出现,连续出现天数为 3
20230405-20230407 为一次连续出现,连续出现天数为 3
20230410-20230411 为一次连续出现,连续出现天数为 2
在一些业务场景下,我们需要找符合类似规则的的对象。这里基于Python和SQL尝试进行解决。
python版本解决方案
import pandas as pd
# 计算连续出现天数
def calculate_consecutive_days(df):
results = []
df['日期'] = pd.to_datetime(df['日期'], format='%Y%m%d')
df = df.sort_values(by=['对象ID', '日期'])
# 遍历每个号码
for number, group in df.groupby('对象ID''):
consecutive_days = 1
start_date = group['日期'].iloc[0]
prev_date = group['日期'].iloc[0]
details = []
# 遍历每个日期
for date in group['日期'].iloc[1:]:
if date == prev_date + pd.Timedelta(days=1):
consecutive_days += 1
else:
if consecutive_days > 1:
details.append((start_date, prev_date, consecutive_days))
consecutive_days = 1
start_date = date
prev_date = date
# 添加最后一个连续天数
if consecutive_days > 1:
details.append((start_date, prev_date, consecutive_days))
# 添加结果
for start, end, days in details:
results.append({
'对象ID': number,
'连续出现天数': days,
'首次发现日期': start.strftime('%Y%m%d'),
'末次发现日期': end.strftime('%Y%m%d'),
'连续天数详情': f"{start.strftime('%Y%m%d')}-{end.strftime('%Y%m%d')}"
})
return results
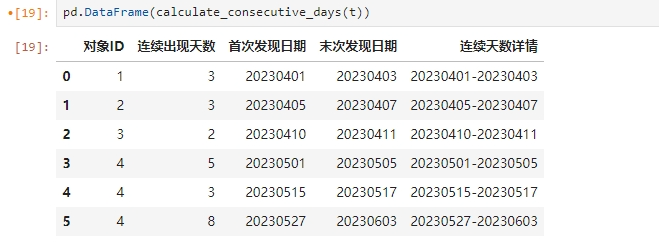
模拟数据这里就不提供了,下面是运行结果。
SQL版本解决方案
【基于mysql8+版本,用到了一些mysql5版本不支持的语法~】
创建模拟数据
CREATE TABLE OccurrenceDays (
uid VARCHAR(100),
dt DATE );
INSERT INTO OccurrenceDays (uid, dt) VALUES
('1234567890', '2023-04-01'),
('1234567890', '2023-04-02'),
('1234567890', '2023-04-03'),
('1234567890', '2023-04-05'),
('1234567890', '2023-04-06'),
('1234567890', '2023-04-07'),
('1234567890', '2023-04-10'),
('1234567890', '2023-04-11'),
('9876543210', '2023-04-02'),
('9876543210', '2023-04-03'),
('9876543210', '2023-04-04');
查询脚本:
WITH RankedDays AS (
SELECT
uid,
dt,
DATE_SUB(dt, INTERVAL ROW_NUMBER() OVER (PARTITION BY uid ORDER BY dt) DAY) AS grp
FROM
OccurrenceDays
),
GroupedDays AS (
SELECT
uid,
MIN(dt) AS start_dt,
MAX(dt) AS end_dt,
COUNT(*) AS consecutive_days
FROM
RankedDays
GROUP BY
uid, grp
HAVING
COUNT(*) > 1
),
ConsecutiveDetails AS (
SELECT
g.uid,
g.consecutive_days,
g.start_dt,
g.end_dt,
GROUP_CONCAT(od.dt ORDER BY od.dt SEPARATOR ',') AS consecutive_details
FROM
GroupedDays g
JOIN
OccurrenceDays od ON g.uid = od.uid AND od.dt BETWEEN g.start_dt AND g.end_dt
GROUP BY
g.uid, g.consecutive_days, g.start_dt, g.end_dt
)
SELECT
uid,
consecutive_days,
DATE_FORMAT(start_dt, '%Y%m%d') AS first_discovery_date,
DATE_FORMAT(end_dt, '%Y%m%d') AS last_discovery_date,
consecutive_details
FROM
ConsecutiveDetails
ORDER BY
uid, start_dt;
查询结果:
| uid | consecutive_days | first_discovery_date | last_discovery_date | consecutive_details |
|---|---|---|---|---|
| 1234567890 | 3 | 20230401 | 20230403 | 2023-04-01,2023-04-02,2023-04-03 |
| 1234567890 | 3 | 20230405 | 20230407 | 2023-04-05,2023-04-06,2023-04-07 |
| 1234567890 | 2 | 20230410 | 20230411 | 2023-04-10,2023-04-11 |
| 9876543210 | 3 | 20230402 | 20230404 | 2023-04-02,2023-04-03,2023-04-04 |
不使用CTE语法
drop table OccurrenceDays;
CREATE TABLE OccurrenceDays (
uid VARCHAR(100),
dt VARCHAR(100)
);
-- 模拟数据
INSERT INTO OccurrenceDays (uid, dt) VALUES ('1234567890', '20230401');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('1234567890', '20230402');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('1234567890', '20230403');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('1234567890', '20230405');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('1234567890', '20230406');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('1234567890', '20230407');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('1234567890', '20230410');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('1234567890', '20230411');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('9876543210', '20230402');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('9876543210', '20230403');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('9876543210', '20230404');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('9876543210', '20230405');
INSERT INTO OccurrenceDays (uid, dt) VALUES ('9876543210', '20230406');
-- 查询脚本
SELECT
uid,
COUNT(*) AS consecutive_days,
MIN(dt) AS first_occurrence_date,
MAX(dt) AS last_occurrence_date,
GROUP_CONCAT(dt ORDER BY dt) AS consecutive_days_detail
FROM (
SELECT
uid,
dt,
dt - ROW_NUMBER() OVER (PARTITION BY uid ORDER BY STR_TO_DATE(dt, '%Y%m%d')) AS grp
FROM
OccurrenceDays
) AS ranked_dates
GROUP BY
uid, grp
HAVING
COUNT(*) > 1
ORDER BY
uid, MIN(dt);
输出结果:
| uid | consecutive_days | first_occurrence_date | last_occurrence_date | consecutive_days_detail |
|---|---|---|---|---|
| 1234567890 | 3 | 20230401 | 20230403 | 20230401,20230402,20230403 |
| 1234567890 | 3 | 20230405 | 20230407 | 20230405,20230406,20230407 |
| 1234567890 | 2 | 20230410 | 20230411 | 20230410,20230411 |
| 9876543210 | 5 | 20230402 | 20230406 | 20230402,20230403,20230404,20230405,20230406 |
补充:模拟数据生成脚本
import random
import datetime
def generate_sql_inserts(uid):
# 获取当前日期
today = datetime.date.today()
# 设定近3个月的开始日期
start_date = today - datetime.timedelta(days=90)
# 初始化SQL语句列表
sql_inserts = []
# 设定要插入的数据条数,这里可以调整
num_inserts = 30
# 用于追踪连续日期的计数器
consecutive_counter = 0
last_date = None
for _ in range(num_inserts):
# 生成随机日期,在最近三个月内
random_date = start_date + datetime.timedelta(days=random.randint(0, (today - start_date).days))
random_date_str = random_date.strftime('%Y%m%d')
# 以一定概率生成连续日期
if last_date and random.random() < 0.5: # 假设有50%的概率生成连续日期
random_date_str = (last_date + datetime.timedelta(days=1)).strftime('%Y%m%d')
consecutive_counter += 1
else:
consecutive_counter = 0
last_date = datetime.datetime.strptime(random_date_str, '%Y%m%d').date()
# 生成SQL INSERT语句
sql_insert = f"INSERT INTO OccurrenceDays (uid, dt) VALUES ('{uid}', '{random_date_str}');"
sql_inserts.append(sql_insert)
return "\n".join(sql_inserts)
# 示例使用
uid = "a"
sql_script = generate_sql_inserts(uid)
print(sql_script)