目录
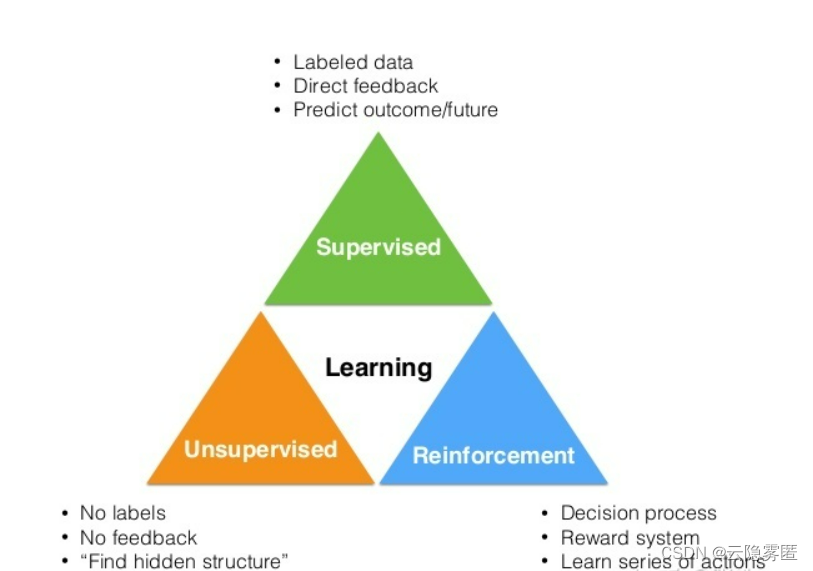
一、监督学习
二、半监督学习
三、无监督学习
3.1.聚类算法
3.2.降维算法
3.3.异常检测
3.4.自动编码器
3.5.生成模型
3.6.关联规则学习
3.7.自组织映射(SOM)
四、自监督学习
4.1. 基于上下文(Context based)
4.2. 基于时序(Temporal Based)
4.3. 基于对比(Contrastive Based)
五、强化学习
六、对比学习
6.1 Momentum Contrast
6.2 SimCLR
本文为阶段性总结,挑重点阅读即可!
一、监督学习
监督学习最大的特点就是其数据集带有标签。换句话来说,监督学习就是在带有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。具体点来说,该数据集中的标签就像是作业的标准答案,而我们预测的标签则是我们给出的答案。如果我们的答案和标准答案不同,老师和父母就会来纠正,我们会进行学习,对题目的理解就会加深,正确率就会越来越高。
常见算法:分类算法(KNN、朴素贝叶斯、SVM、决策树、随机森林、BP神经网络算法等)和回归算法(逻辑回归、线性回归等)。
应用场景:分类和回归的场景,如垃圾邮件分类、心脏病预测等。
二、半监督学习
让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是半监督学习。
在许多实际应用中,很容易找到海量的无类标签的样例,但需要使用特殊设备或经过昂贵且用时非常长的实验过程进行人工标记才能得到有类标签的样本,由此产生了极少量的有类标签的样本和过剩的无类标签的样例。因此,人们尝试将大量的无类标签的样例加入到有限的有类标签的样本中一起训练来进行学习,期望能对学习性能起到改进的作用,由此产生了半监督学习(Semi-supervised Learning),如如图1所示。半监督学习(Semi-supervised Learning)避免了数据和资源的浪费,同时解决了监督学习(Supervised Learning)的 模型泛化能力不强和无监督学习(Unsupervised learning)的模型不精确等问题。
半监督学习可进一步划分为纯(pure)半监督学习和直推学习(transductive learning),前者假定训练数据中的未标记样本并非待测的数据,而后者则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。

一般来说,半监督学习算法可分为:self-training(自训练算法)、Graph-based Semi-supervised Learning(基于图的半监督算法)、Semi-supervised supported vector machine(半监督支持向量机,S3VM)。简单介绍如下:
1.简单自训练(simple self-training):用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(pseudo label)或软标签(soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则),把选出来的无标签样本用来训练分类器。
2.协同训练(co-training):其实也是 self-training 的一种,但其思想是好的。假设每个数据可以从不同的角度(view)进行分类,不同角度可以训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。由于这些分类器从不同角度训练出来的,可以形成一种互补,而提高分类精度;就如同从不同角度可以更好地理解事物一样。
3.半监督字典学习:其实也是 self-training 的一种,先是用有标签数据作为字典,对无标签数据进行分类,挑选出你认为分类正确的无标签样本,加入字典中(此时的字典就变成了半监督字典了)
4.标签传播算法(Label Propagation Algorithm):是一种基于图的半监督算法,通过构造图结构(数据点为顶点,点之间的相似性为边)来寻找训练数据中有标签数据和无标签数据的关系。是的,只是训练数据中,这是一种直推式的半监督算法,即只对训练集中的无标签数据进行分类,这其实感觉很像一个有监督分类算法...,但其实并不是,因为其标签传播的过程,会流经无标签数据,即有些无标签数据的标签的信息,是从另一些无标签数据中流过来的,这就用到了无标签数据之间的联系
5.半监督支持向量机:监督支持向量机是利用了结构风险最小化来分类的,半监督支持向量机还用上了无标签数据的空间分布信息,即决策超平面应该与无标签数据的分布一致(应该经过无标签数据密度低的地方)(这其实是一种假设,不满足的话这种无标签数据的空间分布信息会误导决策超平面,导致性能比只用有标签数据时还差)
应用场景:一些标记数据比较难获取的场景。
三、无监督学习
无监督学习的特点是,模型学习的数据没有标签,因此无监督学习的目标是通过对这些无标签样本的学习来揭示数据的内在特性及规律,其代表就是聚类。与监督学习相比,监督学习是按照给定的标准进行学习(这里的标准指标签),而无监督学习则是按照数据的相对标准进行学习(数据之间存在差异)。以分类为例,小时候你在区分猫和狗的时候,别人和你说,这是猫,那是狗,最终你遇到猫或狗你都能区别出来(而且知道它是猫还是狗),这是监督学习的结果。但如果小时候没人教你区别猫和狗,不过你发现猫和狗之间存在差异,应该是两种动物(虽然能区分但不知道猫和狗的概念),这是无监督学习的结果。其典型算法包括:
3.1.聚类算法
该算法用于根据样本的相似性将样本分组到集群中。聚类的目标是将数据分成几组,使得每组中的示例彼此之间的相似性高于其他组中的示例。
有许多聚类方法,包括基于质心的方法、基于密度的方法和分层方法。基于质心的方法,例如k-means,将数据划分为K个簇,其中每个簇由质心定义(即,代表性示例)。基于密度的方法,例如DBSCAN,根据示例的密度将数据划分为聚类。层次方法,例如凝聚聚类,构建了一个层次结构的聚类,其中每个示例最初被认为是它自己的聚类,然后聚类根据它们的相似性合并在一起。
3.2.降维算法
降维算法用于减少数据集中的特征数量,同时保留尽可能多的信息。机器学习中经常使用降维来提高学习算法的性能,因为它可以降低数据的复杂性并防止过度拟合。它对于数据可视化也很有用,因为它可以将维度的数量减少到更易于管理的大小,从而允许在较低维度的空间中绘制数据。
降维的方法有很多,包括线性方法和非线性方法。线性方法包括诸如主成分分析(PCA)和线性判别分析(LDA)之类的技术,这些技术可以找到捕获数据中最大方差的特征的线性组合。非线性方法包括t-SNE和ISOMAP等技术,它们保留了数据的局部结构。
除了线性和非线性方法之外,还有特征选择方法(选择最重要特征的子集)和特征提取方法(将数据转换到维度更少的新空间)。
3.3.异常检测
这是一种无监督学习,涉及识别与其余数据相比不寻常或意外的示例。异常检测算法通常用于欺诈检测或识别故障设备。异常检测有很多方法,包括统计方法、基于距离的方法和基于密度的方法。统计方法涉及计算数据的统计特性,例如均值和标准差,以及识别超出特定范围的示例。基于距离的方法涉及计算示例与大部分数据之间的距离,并识别距离太远的示例。基于密度的方法涉及识别数据低密度区域中的示例
3.4.自动编码器
自动编码器是一种用于降维的神经网络。它的工作原理是将输入数据编码为低维表示,然后将其解码回原始空间。自动编码器通常用于数据压缩、去噪和异常检测等任务。它们对于高维且具有大量特征的数据集特别有用,因为它们可以学习捕获最重要特征的数据的低维表示。
3.5.生成模型
这些算法用于学习数据的分布并生成与训练数据相似的新示例。一些流行的生成模型包括生成对抗网络(GAN)和变分自动编码器(VAE)。生成模型有很多应用,包括数据生成、图像生成和语言建模。它们还用于风格转换和图像超分辨率等任务。
3.6.关联规则学习
该算法用于发现数据集中变量之间的关系。它通常用于购物车分析,以识别经常购买的商品。一种流行的关联规则学习算法是Apriori算法。
3.7.自组织映射(SOM)
自组织映射(SOM)是一种用于可视化和特征学习的神经网络架构。它们是一种无监督学习算法,可用于发现高维数据中的结构。SOM通常用于数据可视化、聚类和异常检测等任务。它们对于可视化二维空间中的高维数据特别有用,因为它们可以揭示原始数据中可能不明显的模式和关系。
应用场景:聚类场景,如聚合新闻网站。
四、自监督学习
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
也就是说,自监督学习不需要任何的外部标记数据,这些标签是从输入数据自身中得到的。自监督学习的模式仍然是Pretrain-Fintune的模式,即先在pretext上进行预训练,然后将学习到的参数迁移到下游任务网络中,进行微调得到最终的网络。
自监督学习的方法主要可以分为 3 类:
4.1. 基于上下文(Context based)
基于数据自身的上下文信息可以构造很多任务。以拼图的方式构造pretext,比如将一张图分成9个部分,通过预测这几个部分的相对位置来产生损失;以抠图的方式构造pretext,随机将图片的一部分删掉,用剩余的部分预测扣掉的部分;预测图片的颜色,比如输入图像的灰度图,预测图片的色彩。
论文一:《S4L: Self-Supervised Semi-Supervised Learning》
自监督和半监督学习(大量数据没有标签,少量数据有标签)也可以进行结合,对于无标记的数据进行自监督学习(旋转预测),和对于有标记数据,在进行自监督学习的同时利用联合训练的想法进行有监督学习。通过对 imagenet 的半监督划分,利用 10% 或者 1% 的数据进行实验,最后分析了一些超参数对于最终性能的影响。
对于标记数据来说,模型会同时预测旋转角度和标签,对于无标签数据来说,只会预测其旋转角度,预测旋转角度”可以替换成任何其它无监督task(作者提出了两个算法,一个是 S^4L-Rotation,即无监督损失是旋转预测任务;另一个是S^4L-Exemplar,即无监督损失是基于图像变换(裁切、镜像、颜色变换等)的triplet损失)
总的来说,需要借助于无监督学习,为无标注数据创建一个pretext task,这个pretext task能够使得模型利用大量无标注学习一个好的feature representation

4.2. 基于时序(Temporal Based)
样本间其实也是具有很多约束关系的,这里我们来介绍利用时序约束来进行自监督学习的方法。最能体现时序的数据类型就是视频了(video)。
论文二:《Time-Contrastive Networks: Self-Supervised Learning from Video》
第一种思想是基于帧的相似性,对于视频中的每一帧,其实存在着特征相似的概念,简单来说我们可以认为视频中的相邻帧特征是相似的,而相隔较远的视频帧是不相似的,通过构建这种相似(position)和不相似(negative)的样本来进行自监督约束。【如下图所示】
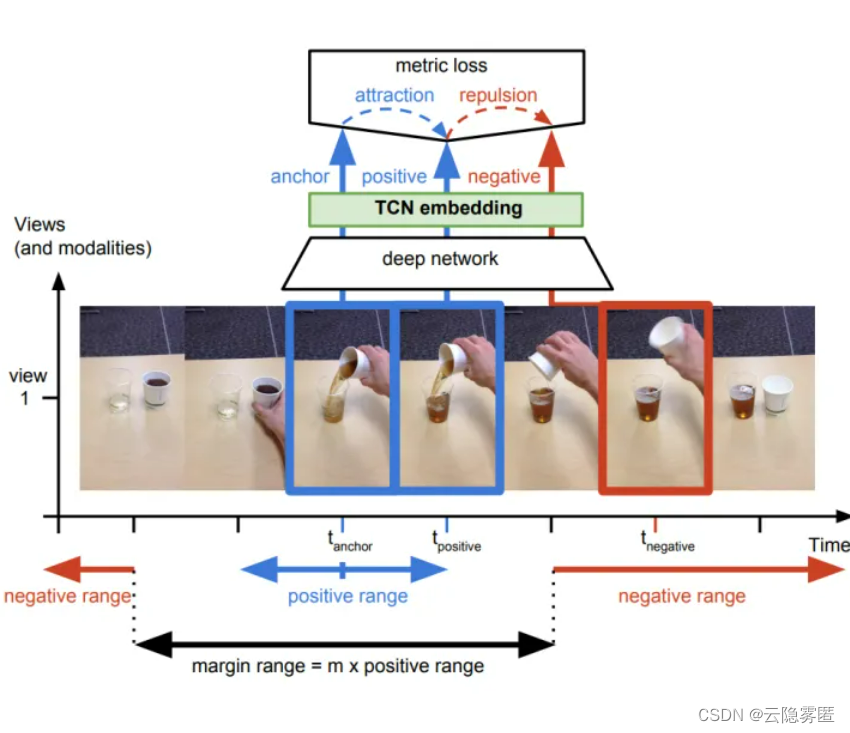
另外,对于同一个物体的拍摄是可能存在多个视角(multi-view),对于多个视角中的同一帧,可以认为特征是相似的,对于不同帧可以认为是不相似的。【如下图所示】
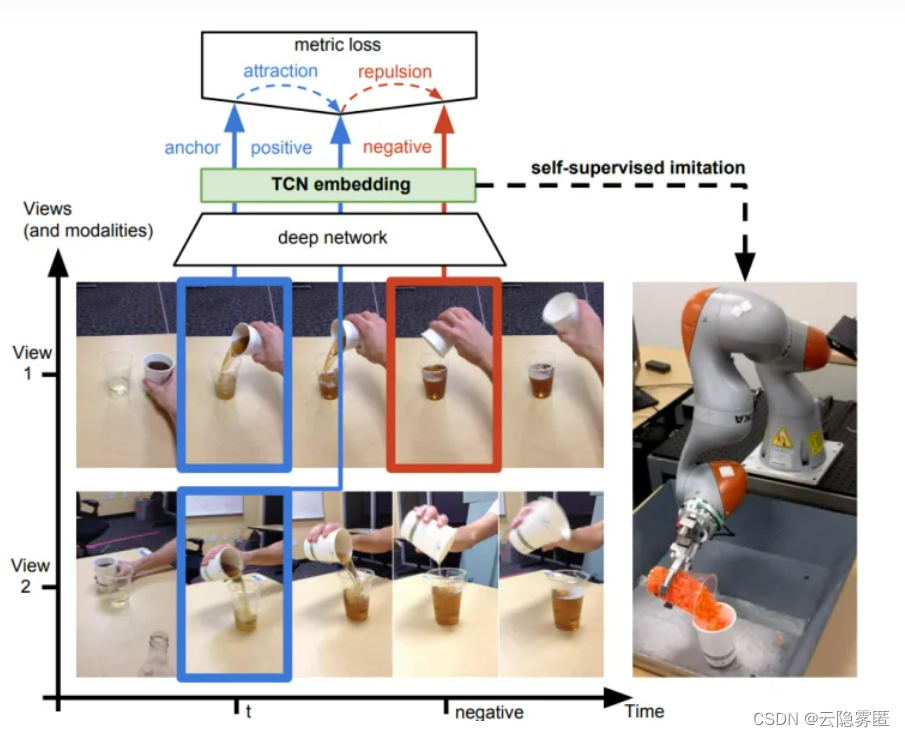 论文三:《Unsupervised Learning of Visual Representations Using Videos》
论文三:《Unsupervised Learning of Visual Representations Using Videos》
还有一种想法是来自 ICCV 2015 Unsupervised Learning of Visual Representations Using Videos的基于无监督追踪方法,首先在大量的无标签视频中进行无监督追踪,获取大量的物体追踪框。那么对于一个物体追踪框在不同帧的特征应该是相似的(positive),而对于不同物体的追踪框中的特征应该是不相似的(negative)。
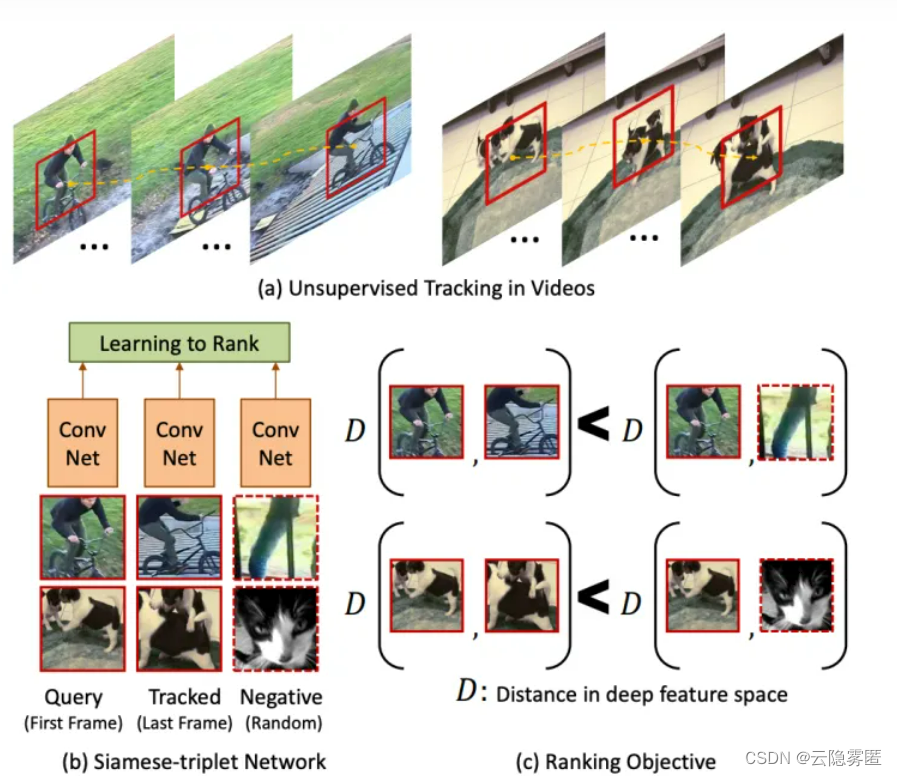
论文四:《Shuffle and Learn:unsupervised learning using temporal order verification》
除了基于特征相似性外,视频的先后顺序也是一种自监督信息。比如ECCV 2016, Misra, I. Shuffle and Learn:unsupervised learning using temporal order verification等人提出基于顺序约束的方法,可以从视频中采样出正确的视频序列和不正确的视频序列,构造成正负样本对然后进行训练。简而言之,就是设计一个模型,来判断当前的视频序列是否是正确的顺序。

4.3. 基于对比(Contrastive Based)
通过学习对两个事物的相似或不相似进行编码来构建表征,即通过构建正负样本,然后度量正负样本的距离来实现自监督学习。核心思想样本和正样本之间的相似度远远大于样本和负样本之间的相似度。
论文五:《Representation Learning with Contrastive Predictive Coding》
我们引入 ICLR 2019 的 DIM,DIM 的具体思想是对于隐层的表达,我们可以拥有全局的特征(编码器最终的输出)和局部特征(编码器中间层的特征),模型需要分类全局特征和局部特征是否来自同一图像。所以这里 x 是来自一幅图像的全局特征,正样本是该图像的局部特征,而负样本是其他图像的局部特征。这个工作的开创性很强,已经被应用到了其他领域,比如 graph 。
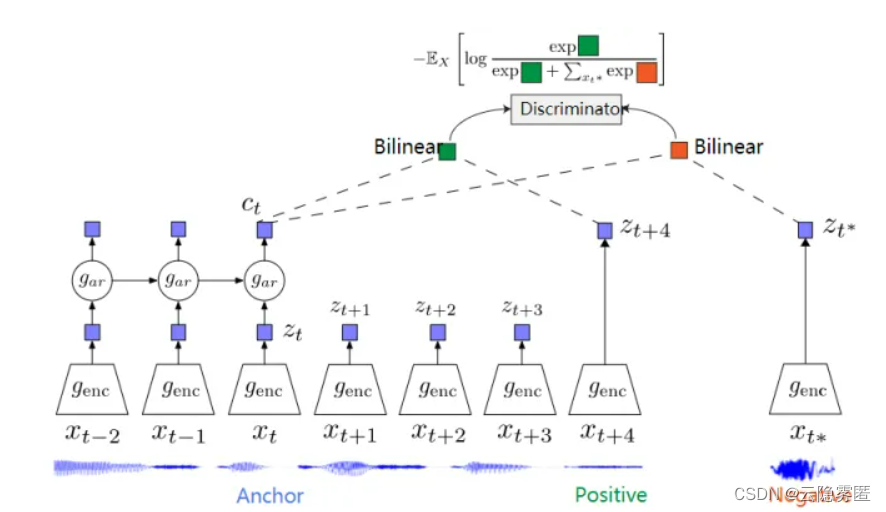
CPC是一个基于对比约束的自监督框架,可以适用于文本、语音、视频、图像等任何形式数据的对比方法(图像可以看作为由像素或者图像块组成的序列)。
CPC通过对多个时间点共享的信息进行编码来学习特征表达,同时丢弃局部信息。这些特征被称为“慢特征”:随时间不会快速变化的特征。比如说:视频中讲话者的身份,视频中的活动,图像中的对象等。
CPC 主要是利用自回归的想法,对相隔多个时间步长的数据点之间共享的信息进行编码来学习表示,这个表示 c_t 可以代表融合了过去的信息,而正样本就是这段序列 t 时刻后的输入,负样本是从其他序列中随机采样出的样本。CPC的主要思想就是基于过去的信息预测的未来数据,通过采样的方式进行训练。
应用场景:语义分割、目标检测、图像分类和人体动作识别等
五、强化学习
强化学习(Reinforcement learning,RL)讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的 环境(environment) 里面去极大化它能获得的奖励。通过感知所处环境的 状态(state) 对 动作(action) 的 反应(reward), 来指导更好的动作,从而获得最大的 收益(return),这被称为在交互中学习,这样的学习方法就被称作强化学习。
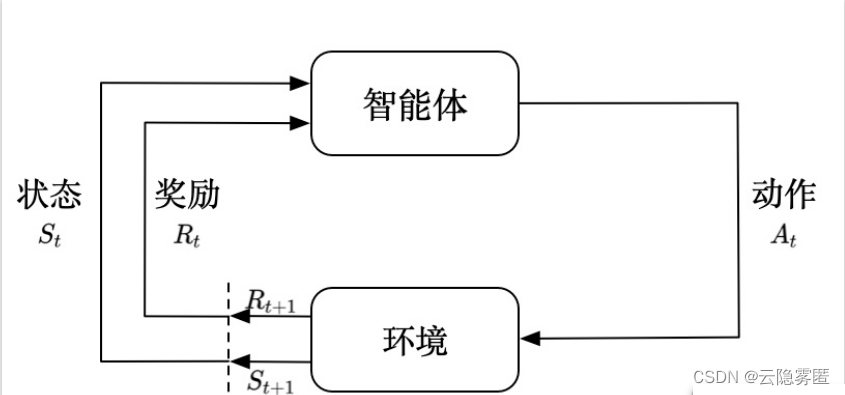
在强化学习过程中,智能体跟环境一直在交互。智能体在环境里面获取到状态,智能体会利用这个状态输出一个动作,一个决策。然后这个决策会放到环境之中去,环境会根据智能体采取的决策,输出下一个状态以及当前的这个决策得到的奖励。智能体的目的就是为了尽可能多地从环境中获取奖励。
强化学习主要有以下几个特点:
1.试错学习:强化学习一般没有直接的指导信息,Agent 要以不断与 Environment 进行交互,通过试错的方式来获得最佳策略(Policy)。
2.延迟回报:强化学习的指导信息很少,而且往往是在事后(最后一个状态(State))才给出的。比如 围棋中只有到了最后才能知道胜负。
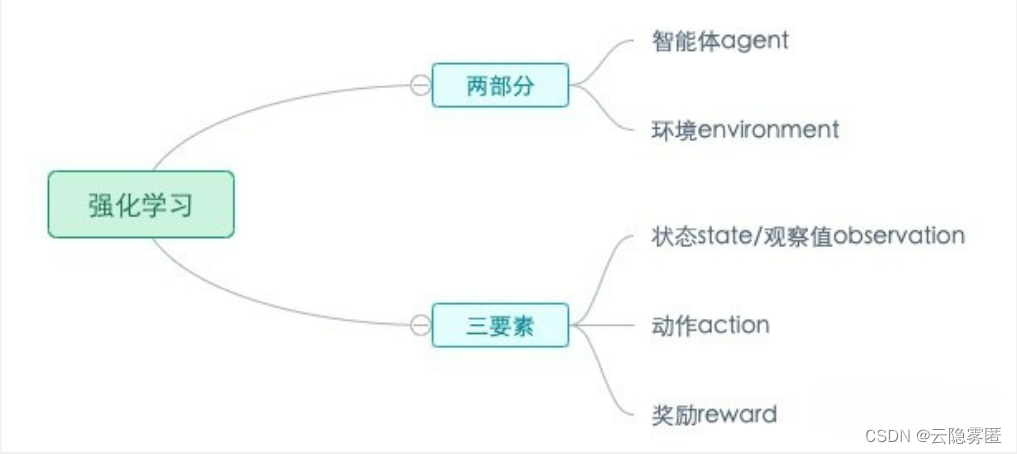
1.环境(Environment) 是一个外部系统,智能体处于这个系统中,能够感知到这个系统并且能够基于感知到的状态做出一定的行动。
2.智能体(Agent) 是一个嵌入到环境中的系统,能够通过采取行动来改变环境的状态。
3.状态(State)/观察值(Observation):状态是对世界的完整描述,不会隐藏世界的信息。观测是对状态的部分描述,可能会遗漏一些信息。
4.动作(Action):不同的环境允许不同种类的动作,在给定的环境中,有效动作的集合经常被称为动作空间(action space),包括离散动作空间(discrete action spaces)和连续动作空间(continuous action spaces),例如,走迷宫机器人如果只有东南西北这 4 种移动方式,则其为离散动作空间;如果机器人向 360◦ 中的任意角度都可以移动,则为连续动作空间。
5.奖励(Reward):是由环境给的一个标量的反馈信号(scalar feedback signal),这个信号显示了智能体在某一步采 取了某个策略的表现如何。
常见算法:隐马尔科夫、蒙特卡罗。
应用场景:针对流程中需要不断推理的场景,如无人汽车驾驶、阿尔法狗下围棋等。
六、对比学习
基本思想是提供一组负样本和正样本。损失函数的目标是找到表示以最小化正样本之间的距离,同时最大化负样本之间的距离。图像被编码后的距离可以通过点积计算,这正是我们想要的!那么这是否意味着计算机视觉中的 SSL 现在已经解决了?其实还没有完全解决。
为什么这么说呢?因为图像是非常高维的对象,在高维度下遍历所有的负样本对象是几乎不可能的,即使可以也会非常低效,所以就衍生出了下面的方法。
在描述这方法之前,让我们首先来讨论对比损失这将会帮助我们理解下面提到的算法。我们可以将对比学习看作字典查找任务。想象一个图像/块被编码(查询),然后与一组随机(负 - 原始图像以外的任何其他图像)样本+几个正(原始图像的增强视图)样本进行匹配。这个样本组可以被视为一个字典(每个样本称为一个键)。假设只有一个正例,这意味着查询将很好地匹配其中一个键。这样对比学习就可以被认为是减少查询与其兼容键之间的距离,同时增加与其他键的距离。
目前对比学习中两个关键算法如下:
6.1 Momentum Contrast
MoCo是由Kaiming He的团队发表在CVPR2020的工作,MoCo通过对比学习的方法,将无监督学习在ImageNet的分类的效果超过有监督学习的性能。MoCo关注的重点是样本数量对学习到的质量的影响。MoCo使用的正负样例生成方法中,正样本生成方法:随机裁剪,生成两个区域,同一张图片的两个区域是正样本,不同图片的两个区域是负样本,即判断两个区域是否为同一张图片。首先介绍简单的end-to-end模型结构,如下图:
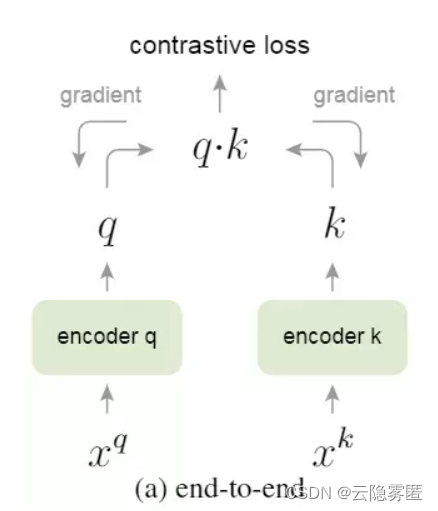
定义 q 、 k 分别为正负样本的key, xq 和 xk 分别为正负样本,end-to-end模型可以使用同一个 encoder或两个encoder来编码xq和xk , 然后通过内积计算 Loss。 需要注意的是, 在end-to-end 模型中, dictionary size即为mini-batch size, 每个batch内的负样本也会对 Loss 产生贡献,反 向传播过程中会有梯度回传给需要学习的encoder函数 f(), 因此在实现的时候,负样本数量必然 会受到batch_size大小的限制,从而限制影响模型的性能。针对这个问题,作者介绍了Memory Bank和MoCo模型, 结构如下图所示:

Memory Bank模型解耦合dictionary size与mini-batch size,即负样本不在每个batch中进行选取,而是在所有样本的特征组成的bank中进行采样,通过随机采样,一定程度上可以认为一个query采样的负样本能代表所有样本,但是带来的问题是每个mini-batch的反向传播都会更新encoder参数,如果每一次更新重新encode一次所有样本,内存需求较大,如果只是更新下一次采样的k个样本,得到的表示和参数更新存在一定的滞后。而文章提出的MoCo则是融合了end-to-end和Memory Bank,并解决了之前存在的问题,添加了momentum encoder,将dictionary作为一个动态进出的队列,目标是构建一个大的且能在训练过程中保持一致性的dictionary,作者用该队列维护最近几个mini-batch中样本特征表示,并将队列作为所有样本采样的子集,对于负样例的encoder参数 θk, 采用Momentum update方法, 复制正例encoder的参数 θq, 公式为:
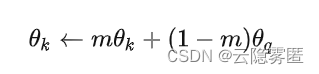
总结:这个想法是要学习良好的表示,需要一个包含大量负样本的大型字典,同时保持字典键的编码器尽可能保持一致。这种方法的核心是将字典视为队列而不是静态内存库或小批量的处理。这样可以为动态字典提供丰富的负样本集,同时还将字典大小与小批量大小解耦,从而根据需要使负样本变得更大。
6.2 SimCLR
SimCLR是由Ting Chen等人发表在ICML2020的工作,与MoCo相比,SimCLR关注的重点是正负样例的构建方式,同时SimCLR还探究了非线性层在对比学习中的作用,并分析了batch_size大小、训练轮数等超参数对对比学习的影响。SimCLR模型结构图如下所示:

给定输入的锚点数据为 x ,首先通过数据增强(随机裁剪、颜色失真、高斯模糊等)生成正负样本对,采用ResNet50作为encoder,即函数 f() ,在编码得到表示后通过MLP将表示映射到对比学习损失的空间,目标是希望同一张图片的不同augmentation表示相近,与mini-batch中其他图片的augmentation表示较远。
作者在数据增强的步骤中通过如下方式生成:

作者实验了多种数据增强方法,最终得出结论:数据增强对对比学习效果提升有明显作用,并且多种数据增强的组合效果更好;数据增强对对比学习的提升比对有监督学习的提升高。此外,通过在得到编码表示后添加非线性变化,发现encoder编码后的 h 会保留和数据增强变换相关的信息,而非线性层的作用就是去掉这些信息,让表示回归数据的本质,提高对比学习效果。作者未使用memory bank等方法,仅通过增大batch_size至8192(使用128块TPU)及增大训练轮数等,验证得到更大的batch_size和更长的训练时间对对比学习提升的效果显著。最终SimCLR的实验效果可以达到在ImageNet上超过MoCo 7%。
总结:SimCLR - 核心思想是使用更大的批大小(8192,以获得丰富的负样本集),更强的数据增强(裁剪,颜色失真和高斯模糊),并在相似性匹配之前嵌入的非线性变换,使用更大模型和更长的训练时间。这些都是需要反复试验的显而易见的事情,该论文凭经验表明这有助于明显的提高性能。
但是对比学习也有局限性:
1.需要大量的负样本来学习更好的表示。
2.训练需要大批量或大字典。
3.更高的维度上不能进行缩放。
4.需要某种不对称性来避免常数解。
应用场景:人脸识别、NLP等