HIVE简单数据查询
1.where
WHERE + 过滤条件
between/ in / is NULL / IS NOT NULL / > < = ! ...
如果多个存在多个过滤条件 可以用 AND OR 进行条件关联 或者是用NOT 进行条件结果取反
2.JOIN
JOIN 内连接 左外连接 右外连接 自连接 满连接
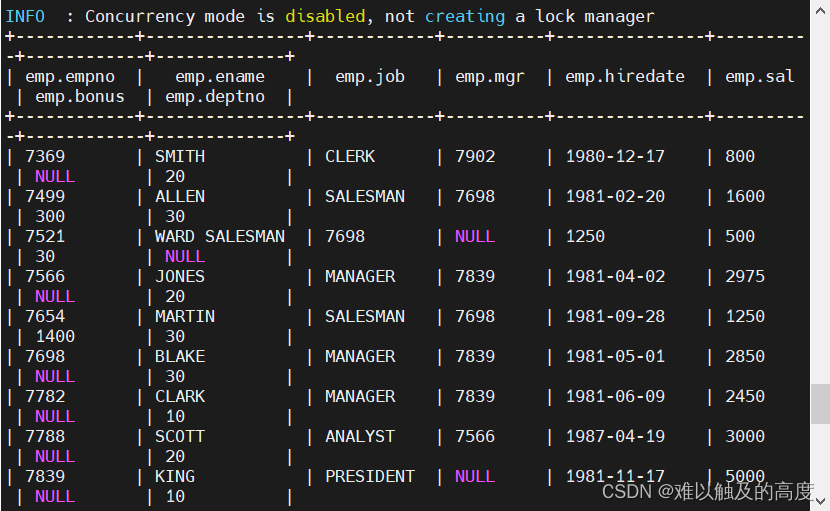
创建部门表:
create table learn2.emp(
EMPNO int
,ENAME string
,JOB string
,MGR int
,HIREDATE string
,SAL int
,BONUS int
,DEPTNO int
)
row format delimited
fields terminated by ',';
load data local inpath "/usr/local/soft/hive-3.1.2/data/emp.txt" into table learn2.emp;
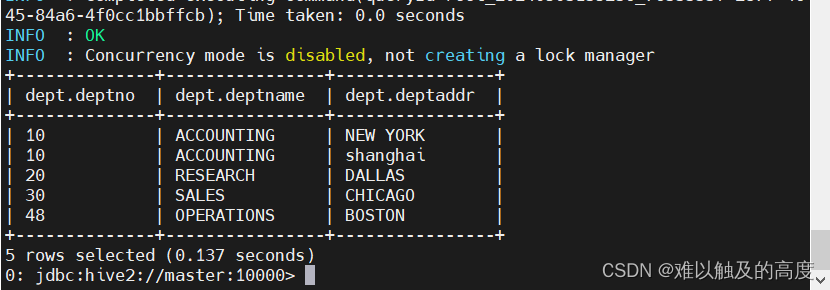
创建部门表:
create table learn2.dept(
DEPTNO int
,DEPTNAME string
,DEPTADDR string
)
row format delimited
fields terminated by ',';
load data local inpath "/usr/local/soft/hive-3.1.2/data/dept.txt" into table learn2.dept;
1)内连接
注意:关联时一定要跟上关联条件
select t1.ename,t2.deptno,t2.deptname from learn2.emp t1 join learn2.dept t2 on t1.deptno=t2.deptno;

2)左外连接
select t1.ename,t2.deptno,t2.deptname from learn2.emp t1 left join learn2.dept t2 on t1.deptno=t2.deptno;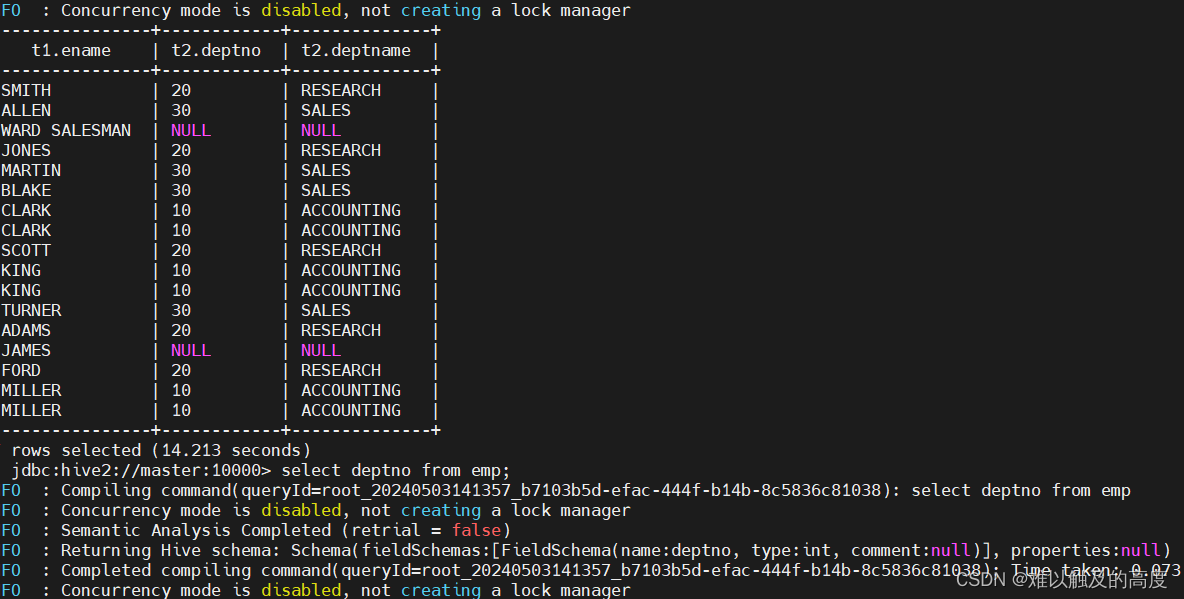
3)右外连接
select t1.ename,t2.deptno,t2.deptname from learn2.emp t1 right join learn2.dept t2 on t1.deptno=t2.deptno;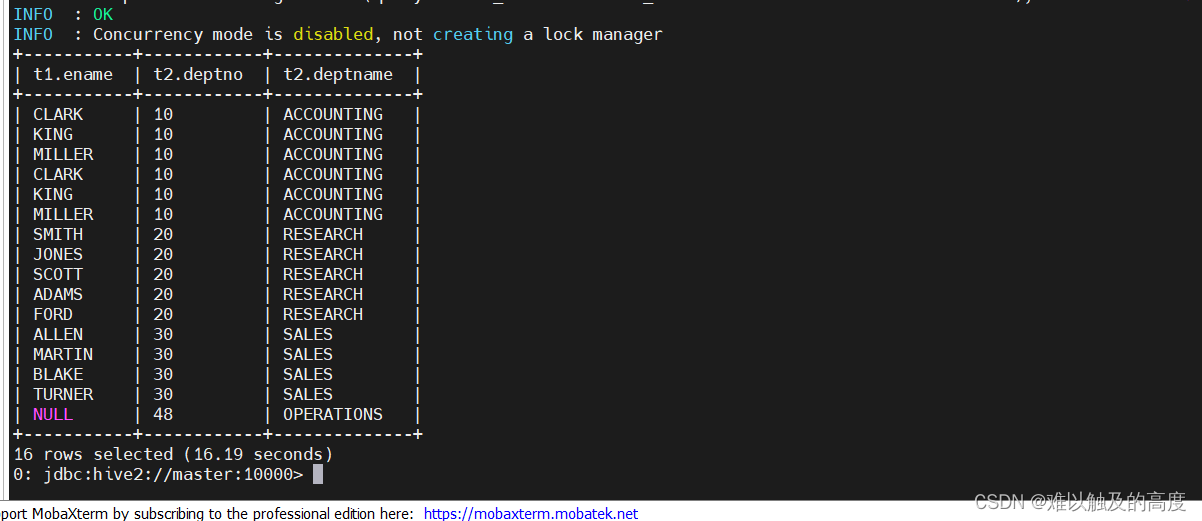
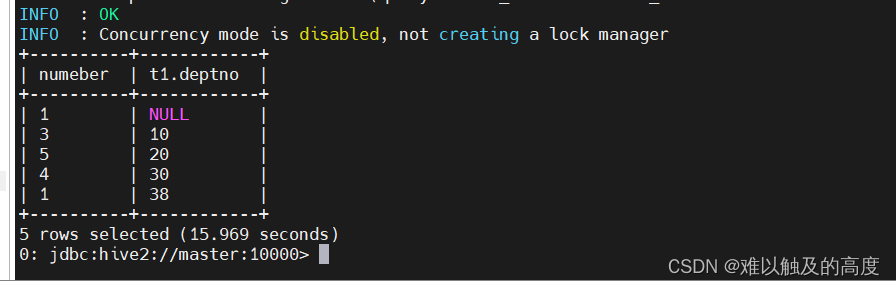
select count(t1.ename) numeber,t1.deptno from emp t1 group by t1.deptno;
select count(1) numeber,t1.deptno from emp t1 group by t1.deptno;
3.排序
1)order by
select t1.deptno,t1.sal from emp t1 order by t1.sal;
select t1.deptno,t1.sal from emp t1 order by t1.sal desc; 倒序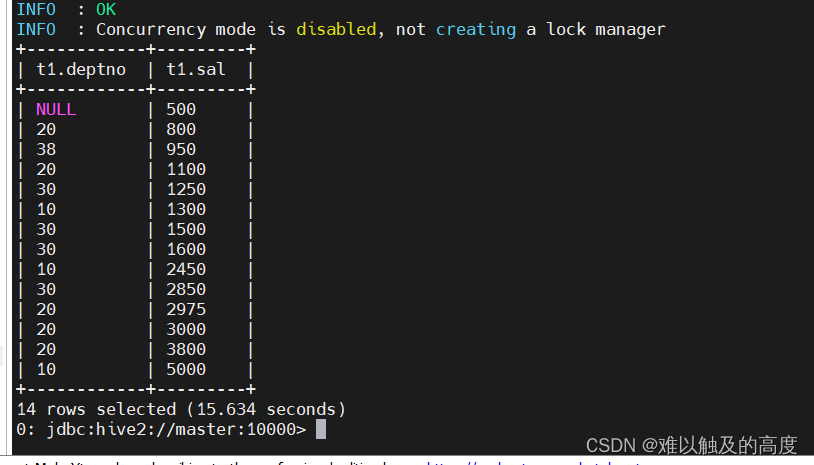
通过查看MAPREDUCE日志 可以看到 Reduce: 1 ORDER BY 中默认的reduce数量只能为1
那么为什么Reduce数量只有一个
在实际处理数据过程中,要尽量避免使用全局排序
**** set mapreduce.job.reduces; 表示查看当前reduce数量
**** set mapreduce.job.reduces = 3;表示设置当前reduce数量为3
2)sort by
select t1.ename,t1.sal from emp t1 sort by t1.sal desc;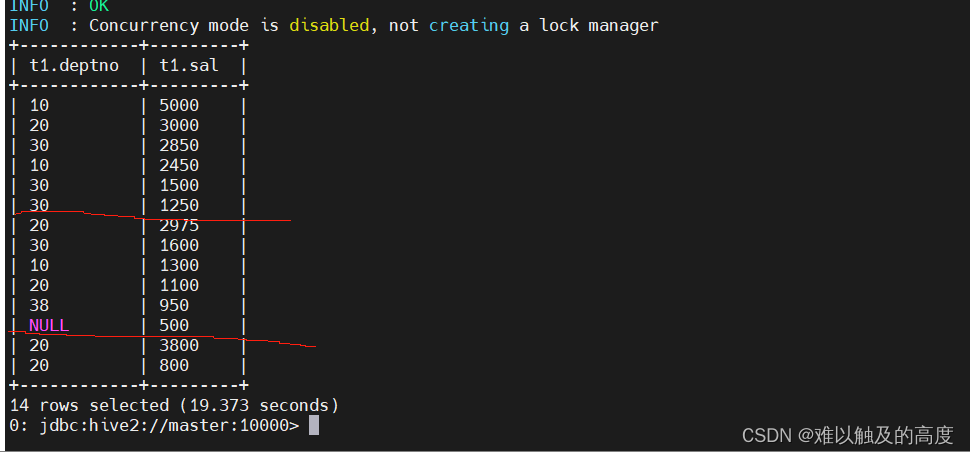
通过设置reduce数量为3 查询出的整体结果为乱序 局部为倒序
导出一下数据

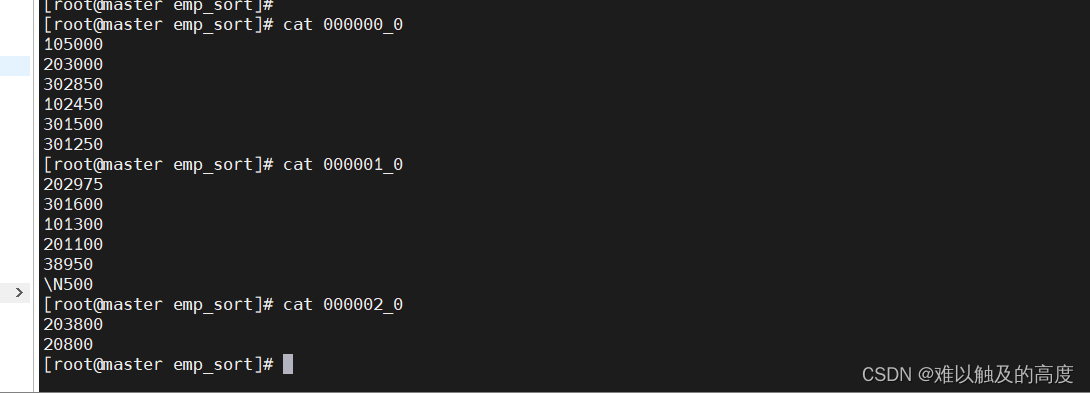
通过输出的结果中三个文件可以看出 sort by 是分区内有序
3)多字段排序
1)order by 多字段排序
select t1.deptno,t1.sal from emp t1 order by t1.deptno,t1.sal desc;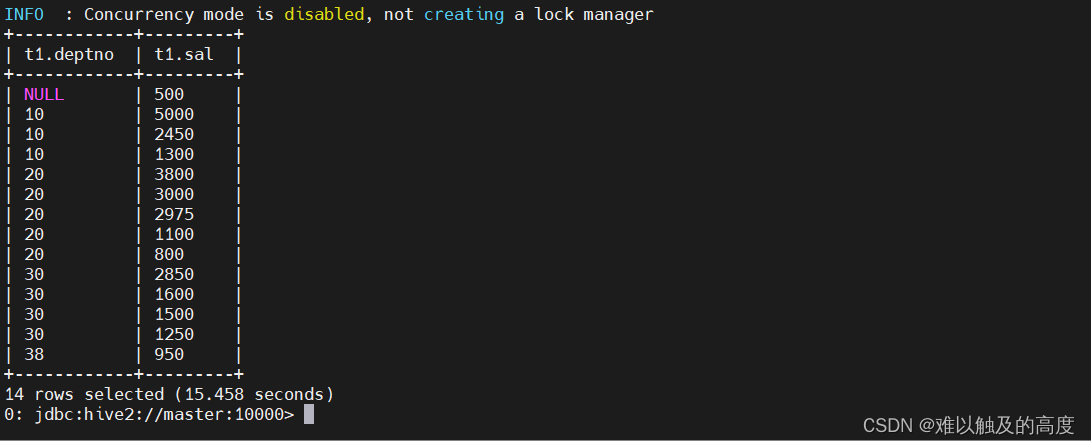
2)sortby 多字段排序
select t1.deptno,t1.sal from emp t1 sort by t1.deptno,t1.sal desc;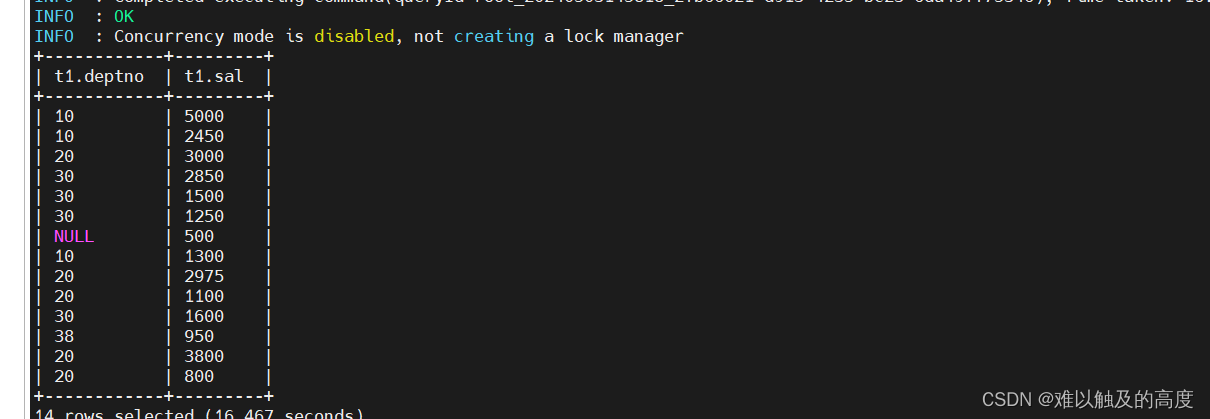
-- 结果也是分区间无序,分区内有序
4)distribute by + sort by
搭配使用进行排序
distribute by:指定按某列数据进行分区操作,和之前MR学习中的自定义分区类似
select t1.deptno,t1.sal from emp t1 sort by t1.sal desc;
select t1.deptno,t1.sal from emp t1 distribute by t1.deptno sort by t1.sal desc;5) cluster by
也表示排序操作 但是不能对数据做倒序, cluster by 表示对一个列数据进行分区排序
cluster by = distribute by + sort by
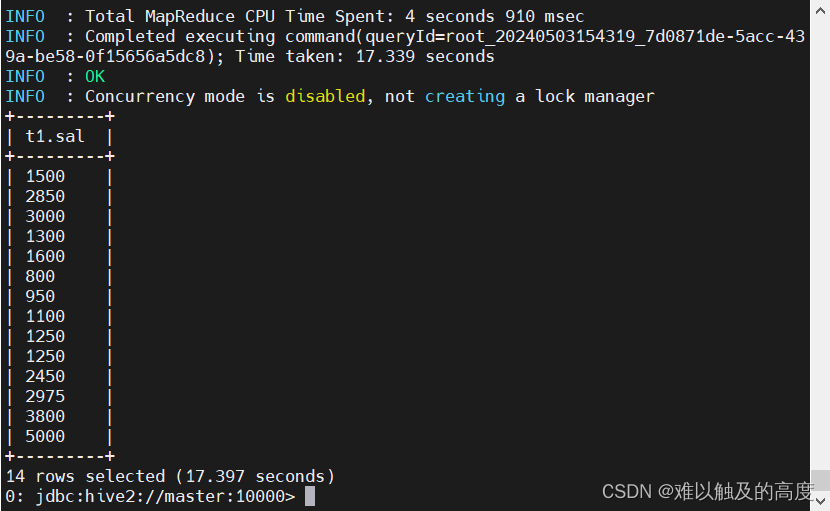
SELECT
T1.SAL
FROM learn2.emp T1 cluster by T1.SAL ;
+---------+
| t1.sal |
+---------+
| 300 |
| 1500 |
| 2850 |
| 3000 |
| 3000 |
| 1300 |
| 1600 |
| 800 |
| 950 |
| 1100 |
| 1250 |
| 1250 |
| 2450 |
| 2975 |
| 5000 |
SELECT
T1.SAL
FROM learn2.emp T1 distribute by T1.SAL SORT BY T1.SAL;
+---------+
| t1.sal |
+---------+
| 300 |
| 1500 |
| 2850 |
| 3000 |
| 3000 |
| 1300 |
| 1600 |
| 800 |
| 950 |
| 1100 |
| 1250 |
| 1250 |
| 2450 |
| 2975 |
| 5000 |
+---------+
4.去重
select distinct t1.deptno from emp t1;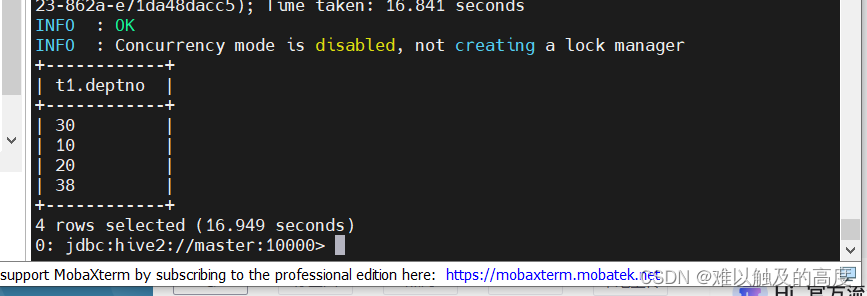
5.分桶操作
1)创建分桶表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
--根据 给定的列进行 分桶排序 指定存入 N 个桶中
-- 需求:
将bucket.txt中的数据分成4个桶进行存储
CREATE TABLE IF NOT EXISTS learn2.bucket_table(
id int,name STRING
)
CLUSTERED BY(id) INTO 4 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ",";2)插入数据
load data local inpath "/usr/local/soft/hive-3.1.2/data/bucket.txt" into table learn2.bucket_table;我们在插入数据时 出现了报错信息
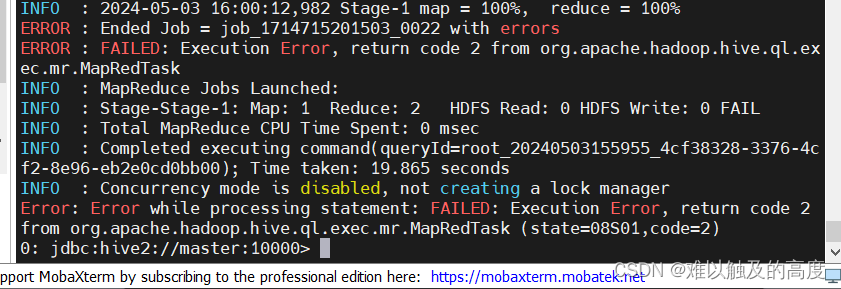
所以 我们要开启分桶操作
--启用桶表
set hive.enforce.bucketing=true;
--限制对桶表进行load操作
set hive.strict.checks.bucketing = false;
如果加载数据的时候提示文件不存在,那么可以将数据先上传至HDFS,
之后再去加载数据至表中,同时需要开启桶表的支持,对桶表的load操作
dfs -put /usr/local/soft/hive-3.1.2/data/bucket.txt /data/
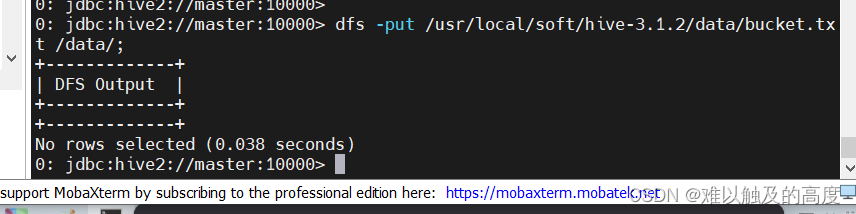
再次运行发现还是会报错 我们将Reduce数量设置为-1
load data inpath "/data/bucket.txt" into table learn2.bucket_table;
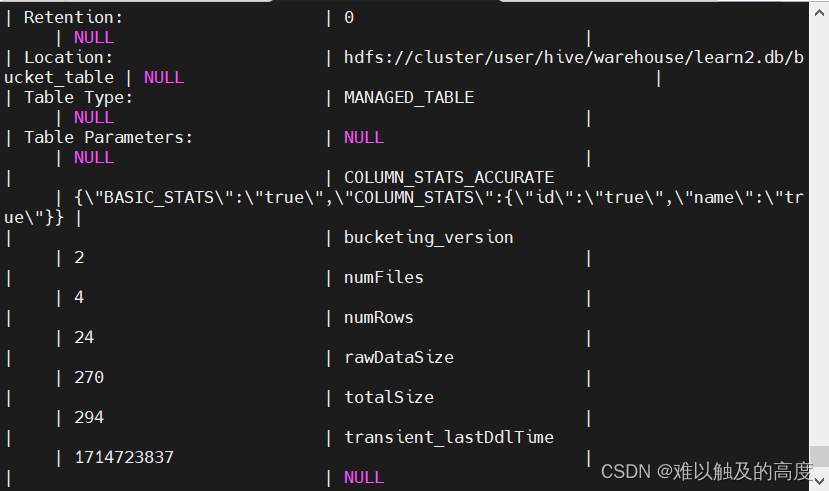
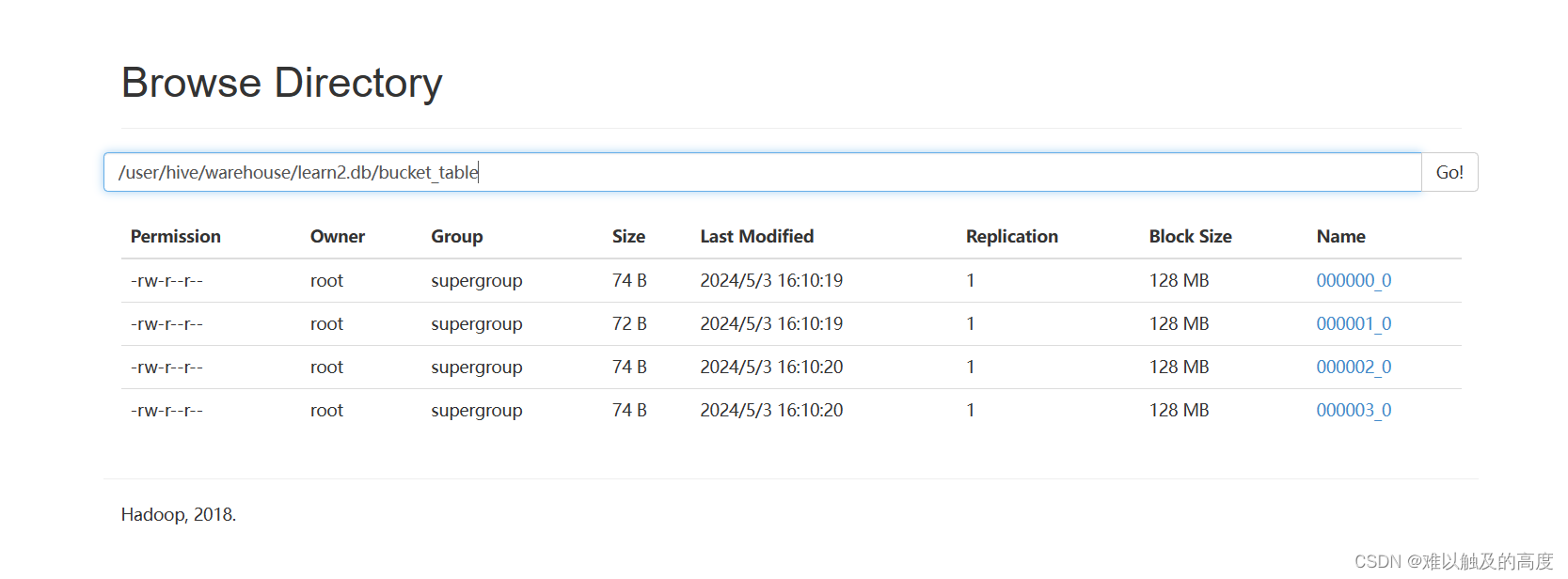
通过查看表对应HDFS上的路径 可以看到数据分为4分,这样有什么好处?
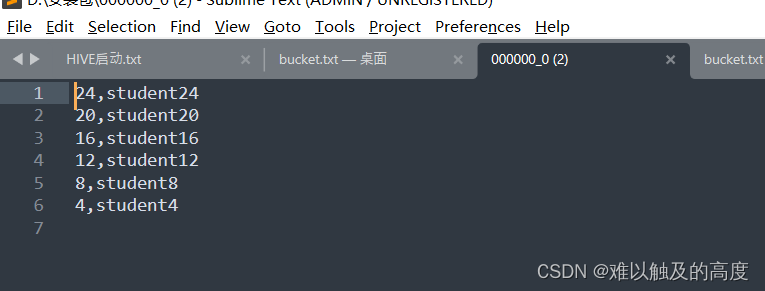
通过查看000000_0文件数据可以看到,ID列中对4取余都为0
通过查看000001_0文件数据可以看到,ID列中对4取余都为1
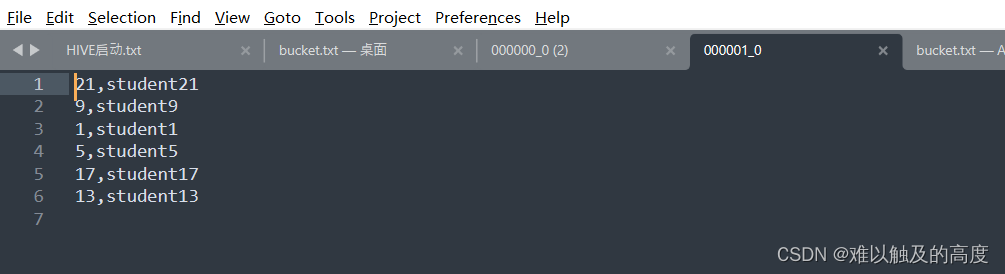
这样我们后面去表中取数据,如果对id进行过滤,如下SQL语句
SELECT * FROM learn2.bucket_table WHERE id in ('4','1');
那么它的执行逻辑为: 对需要查找的 id ('4','1') 进行取余,
如果余数为0那么就去000000_0文件中加载数据
如果余数为1那么就去000001_0文件中加载数据
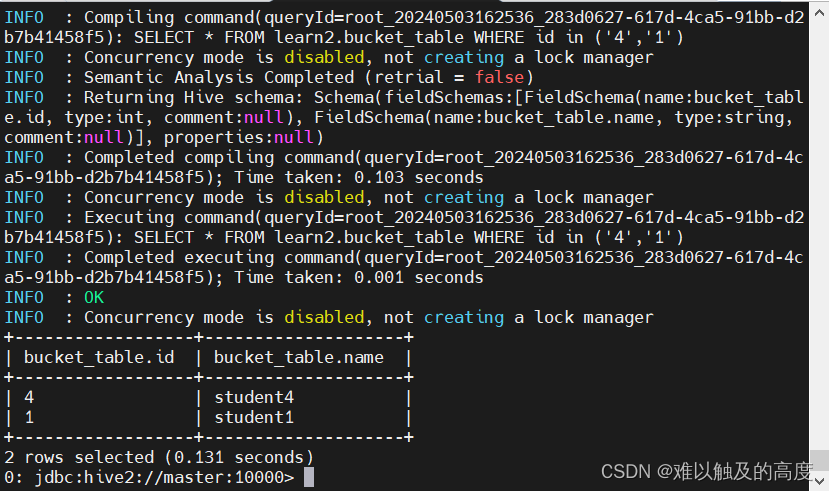
这样就可以避免加载不必要的数据,提高执行效率
2> 查看桶的数量
DESC FORMATTED learn2.bucket_table; 中的 Num Buckets: 4 参数查看具体对应的桶数