前沿
本文介绍6D位姿估计的直接回归方法GDR-Net,它从单个RGB图像中确定物体在三维空间中的位置和方向。
它是一个端到端模型,与传统的间接方法不同,GDR-Net可以通过反向传播完全训练,简化了训练过程。
论文地址:GDR-Net(CVPR2021)
代码地址:https://github.com/THU-DA-6D-Pose-Group/GDR-Net

一、模型框架
模型的框架结构,如下图所示:

- 输入RGB图片。
- 在训练阶段,识别和放大物体所在区域;推理阶段,检测物体所在的区域,设置为3x256x256固定大小的特征图。
- 物体所在区域的图像,经过ResNet34提取图中特征。
- 然后通过解码器,分别输出表面区域注意力特征、2D-3D转换特征M2D-3D、物体掩码特征MSRA。
- 结合表面区域注意力特征和2D-3D转换特征,通过3层卷积层,进一步提取特征;
- 接着,用2层全连接层,进行位姿信息转换,包括R旋转和t平移。
- 输出6D位姿信息,包括3D位置信息和3D方向信息。
关键点:
- M2D-3D:这是2D图像和3D模型之间密集对应关系的中间特征表示。它包含了图像中每个像素点和物体模型之间的对应关系。
- MSRA:表面区域注意力模块,它聚焦于图像中物体表面的特定区域,为位姿估计提供更加精细的几何线索。
- Patch-PnP:是位姿估计的最终步骤,它使用从CNN中提取的密集对应关系和表面注意力特征来回归物体的6D位姿。
二、思路流程
GDR-Net用于从单张RGB图像中,直接回归物体的6D位姿的过程,如下图所示。

- 2D-3D转换稠密特征:2D图像平面上的特征点与3D模型坐标之间的对应关系。这些对应关系为物体在三维空间中的定位提供了关键线索。
- 表面区域注意力特征:网络还关注物体的不同表面区域。这可以帮助模型更准确地理解物体的三维形状和其在图像中的表现,进而更准确地预测其位姿。
- Patch-PnP学习:这一步是GDR-Net的创新之处,通过Patch-PnP,网络不仅仅是识别图像中的关键点,而且还能学习如何利用这些关键点来计算物体的位姿。与传统的PnP算法不同,Patch-PnP是可学习的,通过反向传播进行优化。
三、6D位姿估计方法
通常6D位姿估计方法主要分为两类:间接方法和直接方法。
间接方法:
- 这些方法首先在图像平面和物体坐标系统之间建立2D-3D对应关系。通常通过检测图像中的关键点并将它们与物体上已知的3D位置相关联来实现。
- 之后,使用透视N点—PnP算法的变体来估计位姿,通常结合随机样本一致性RANSAC算法。这种方法因其鲁棒性和准确性而占主导地位。
- 然而,一个显著的缺点是该流程不是端到端可训练的。这种局限性是因为PnP/RANSAC步骤不可微分,意味着不能通过反向传播直接优化,使其难以与需要微分操作的深度学习框架集成。
直接方法:
-
这些方法尝试通过回归直接从图像学习6D位姿。
-
这通常通过训练神经网络直接输出位姿参数来完成。主要优势是这些方法可以端到端训练。
-
然而,直接回归方法的性能上一直不如基于几何的间接方法。
-
挑战在于模型从仅有的2D数据中推断复杂的3D结构和空间关系的能力。
GDR-Net提出一种几何引导的直接回归模型,结合间接方法和直接方法的优势,实现端到端训练。
四、关键内容——M2D-3D(2D-3D转换稠密特征)
这是2D图像和3D模型之间密集对应关系的中间特征表示, 这些对应关系为物体在三维空间中的定位提供了关键线索。
计算方法:
- 首先,为了构建Dense Correspondences Maps(M2D-3D),需要估计底层的Dense Coordinates Maps(Mxyz)。
- M2D-3D可以通过将Mxyz叠加到相应的2D像素坐标上来获得。
- 具体来说,给定一个物体的CAD模型,可以通过在给定关联姿态的情况下渲染模型的3D对象坐标来获取Mxyz。
归一化输出:
- 网络预测的是一个标准化的表示形式,其中每个通道的Mxyz在[0,1]的范围内被标准化,标准化的基准是CAD模型的相应紧密3D包围盒的大小(lx, ly, lz)。
- 这种标准化有助于网络学习如何解释不同尺寸的物体,并且保持姿态估计的一致性。
M2D-3D特点:
-
不仅是2D-3D对应:M2D-3D不只是编码了2D到3D的对应关系,它还明确地反映了物体的几何形状信息。
-
这意味着这些映射中包含了物体表面的结构信息,为位姿估计提供了额外的几何线索。
-
利用于6D位姿学习:由于M2D-3D在图像中是规则排列的,可以通过一个简单的2D卷积神经网络(即Patch-PnP)来学习6D物体位姿。
-
这一点突出了GDR-Net的一个关键优势——能够以一种结构化和有效的方式将复杂的3D信息编码进2D图像,并利用这些信息直接回归出物体的位姿。
这些Dense Correspondences Maps (M2D-3D) 是GDR-Net核心部分之一,因为它们为从单个RGB图像中直接回归出精确的6D物体位姿提供了必要的几何信息。
通过这种方式,GDR-Net能够结合深度学习的强大能力和3D几何信息的精确性,从而提供一个既有效又准确的位姿估计方法。
五、关键内容——MSRA(表面区域注意力特征)
-
灵感来源:MSRA受到前人工作的启发,使网络能够预测物体表面区域作为额外的模糊性感知监督。这一点体现了网络设计中对于物体表面区域特性的认识,以及这些特性如何影响位姿估计的准确性。
-
与RANSAC的区别:与RANSAC(一种常用的鲁棒性估计算法)相结合的传统方法不同,MSRA被直接集成到Patch-PnP框架内。这意味着MSRA是作为网络学习过程的一部分来实现的,而不是作为一个后处理步骤。
MSRA算法思路:
-
MSRA的真值区域是通过采用最远点采样(farthest points sampling)方法从Mxyz导出的。
-
这种采样方法有助于确定物体表面上最重要的特征点,为位姿估计提供关键的几何线索。
-
对于每个像素,网络将对应的区域进行分类,从而预测的MSRA中的概率隐含地表示了物体的对称性。
例如,如果一个像素因对称平面而可能被分配给两个不同的区域碎片,最小化这种分配会返回每个碎片的概率为0.5。
MSRA的应用和优势:
-
对称性识别:利用MSRA,网络不仅减少了模糊性的影响,而且还在M3D上增加了一个辅助任务。有助于解决由于物体对称性导致的位姿估计中的不确定性问题。
-
简化学习过程:通过首先定位粗略的区域然后再回归更细的坐标,MSRA简化了M3D的学习过程。这意味着网络可以更系统地学习复杂的位姿估计任务,从宏观到微观逐步解决问题。
-
引导Patch-PnP的学习:MSRA作为一种对称性感知的注意力机制,指导了Patch-PnP模块的学习。这强调了注意力机制在提高位姿估计性能方面的作用,尤其是在处理具有复杂对称性的物体时。
MSRA表面区域注意力特征,不仅提供了对物体表面区域的深入理解,而且还增强了网络对物体对称性的识别能力,最终提高了位姿估计的准确性和鲁棒性。
## 物体对称性补充:
如果物体有对称性,某些像素可能在视觉上对应于物体的多个不同的表面区域。例如,考虑一个正中间有一条对称线的物体,两边看起来几乎一样。在这种情况下,位于对称线一边的像素点可能和另一边的对应点有着相同的外观,但实际上属于不同的物体表面区域。
为了解决这种歧义,网络需要学会识别这些对称性,并通过分类来为每个像素点分配正确的表面区域。在训练过程中,这种分类任务会帮助网络更好地理解物体的三维结构。
最终,这种按像素点分类的方法能够提高网络预测物体位姿的准确性,因为它给予了网络额外的几何信息,帮助它更好地理解物体表面的布局。
## 最远点采样补充:
- 最远点采样(Farthest Point Sampling, FPS)是一种在处理点云数据时常用的抽样技术,它的目的是从一个较大的点集中选取一个包含代表性点的较小子集。
- 这种方法通过迭代地选取当前最远的点来确保采样的点能够广泛地覆盖整个数据集。
- 在3D几何处理和计算机视觉中,FPS可以用来有效地提取出一个物体表面的关键特征点。
- 通过选择分布在物体表面关键位置的点,间接帮助网络在处理对称物体时,更好地理解其几何结构,并对这种结构进行建模。通过这种方式,MSRA能够辅助网络在识别和处理物体对称性时减少歧义。
六、关键内容——Patch-PnP模块
结合表面区域注意力特征和2D-3D转换特征,输入到Patch-PnP模块,经过三个卷积层进一步提取特征;
接着,用2层全连接层,进行位姿信息转换,包括R旋转和t平移。
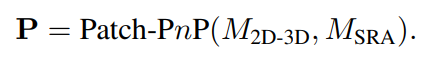
- Patch-PnP模块的设计采用了三个卷积层,每个层后都跟随了组归一化(Group Normalization)和ReLU激活函数。
- 然后,两个全连接(FC)层被应用于扁平化的特征,从而将特征维度从8192降至256。
- 最终,两个并行的FC层分别输出6D位姿的旋转(R_6d)和平移(t_trans)参数。
Patch-PnP模块是一个创新点,它允许网络以一种可微分的方式学习位姿估计,从而使得整个网络能够端到端训练。
补充信息:
- 两阶段训练,GDR-Net实现为一个两阶段方法,即首先检测物体,然后估计位姿。
- 模型使用L1损失来优化归一化的M2D-3D和可见掩码Mvis,同时使用交叉熵损失来优化MSRA。
分享完成~
本文先介绍到这里,后面会分享“6D位姿估计”的其它数据集、算法、代码、具体应用示例。