目录
内容来源:
【GUN】【sort】指令介绍
【busybox】【sort】指令介绍
【linux】【sort】指令介绍
使用示例:
排序 - 默认排序
排序 - 检查所给文件是否已经排序
排序 - 输出已经排序过的文件,不会重新排序
排序 - 忽略每行前面的空格
排序 - 排序时忽略除字母、数字和空格以外的所有字符
排序 - 将小写字符视为相同的大写字符
排序 - 把每行前缀转为数字进行排序
排序 - 把每行前缀转为数字进行排序,同时也判断后缀
排序 - 把每行前缀转为数字进行排序2
排序 - 显示详细的排序过程,用于调试
排序 - 反向输出排序结果
排序 - 指定排序字段
排序 - 将结果输出到指定文件
排序 - 使用给定大小的主内存排序缓冲区,默认1024字节
排序 - 忽略非打印字符
排序 - 排序月份
排序 - 指定分割符
排序 - 结果去掉重复行
常用组合指令:
指令不常用/组合用法还需继续挖掘:
内容来源:
GUN : Coreutils - GNU core utilities
busybox v1.36.1 : 【busybox记录】【shell指令】基于的Busybox的版本和下载方式-CSDN博客
【GUN】【sort】指令介绍
sort:对文本文件排序
sort 对给定文件中的所有行进行排序、合并或比较,如果没有给出标准输入,则对` - `文件进行标准输入。默认情况下,sort将结果写入标准输出。
简介:
sort [option]... [file]...
有很多选项会影响sort的行比较方式;如果结果出乎意料,试试 --debug选项,看看发生了什么。
对行进行如下比较:
sort根据相关的排序选项,按照命令行上指定的顺序比较每一对字段(参见--key),直到找到差异或没有字段。
如果没有指定键字段,sort将使用整行的默认键。最后,当比较的所有键都相等时,作为最后的手段,sort会对整行进行比较,就好像除了--reverse (-r)之外没有指定其他排序选项一样。
--stable (-s)选项会禁用这种最后的比较,这样所有字段比较结果都相等的行就会按照原始的相对顺序排列。
--unique (-u)选项也禁用了最后的比较。
除非另有指定,否则所有比较都使用 LC_COLLATE 区域设置指定的字符排序序列一行末尾的换行符不是用于比较的行。如果输入文件的最后一个字节不是换行符,GNU sort会默默提供换行符。
GNU sort(所有GNU实用程序都指定)对输入行长度没有限制,对行内允许的字节数也没有限制。
sort有三种操作模式:排序(默认)、合并和检查顺序。
修改操作模式的选项包括:
‘-c’
‘--check’
‘--check=diagnose-first’
检查给定的文件是否已经排序:如果没有全部排序,则打印一个包含第一个乱序行的诊断结果,并以状态1退出。否则,退出成功。最多只能提供一个输入文件。
‘-C’
‘--check=quiet’
‘--check=silent’
如果给定的文件已经排序,则退出成功,否则以状态1退出。最多只能提供一个输入文件。这类似于-c,只不过它不打印诊断结果。
‘-m’
‘--merge’
将给定的文件按组排序合并。每个输入文件必须总是单独排序。它总是排序而不是合并;提供合并是因为在它工作的情况下,它更快。退出状态:
0 如果没有错误发生
1 如果使用-c或-c调用,并且输入未排序
2 如果出现错误
如果设置了环境变量 TMPDIR, sort将其值作为临时文件的目录,而不是/tmp。--temporary-directory (-T)选项则覆盖环境变量。
以下选项影响输出行的顺序。它们可以全局指定,也可以作为特定关键字段的一部分。如果没有指定关键字段,全局选项将应用于整行比较;否则,全局选项将由没有指定任何自己的特殊选项的关键字段继承。
在posix之前的sort版本中,全局选项只影响后面的关键字段,所以可移植的shell脚本应该首先指定全局选项。
‘-b’
‘--ignore-leading-blanks’
在每一行中查找排序键时,忽略前导空格。默认情况下,空白是空格或制表符,但 LC_CTYPE 区域设置可以改变这一点。空格可能会被区域设置的排序规则忽略,但是如果没有这个选项,它们对于键中指定的-k选项中的字符位置将是重要的。
‘-d’
‘--dictionary-order’
按电话簿顺序排序:排序时忽略除字母、数字和空格以外的所有字符。默认情况下,字母和数字是ASCII,空白是空格或制表符,但 LC_CTYPE 区域设置可以改变这一点。
‘-f’
‘--ignore-case’
在比较时,将小写字符折叠为相同的大写字符,例如,`b`和`B`排序时是相等的。LC_CTYPE 区域设置决定了字符类型。当使用--unique时,那些小写的等价行将被丢弃。(目前还没有办法丢弃对应的大写字母。(在丢弃之后,任何 --reverse 给出只会影响最终结果。)
‘-g’
‘--general-numeric-sort’
‘--sort=general-numeric’
按数字排序,将每行的前缀转换为长双精度浮点数。参见第2.12节[浮点数],第10页。不要报告溢出、下溢或转换错误。使用下面的排序顺序:
不以数字开头的行(都认为是相等的)。
NaNs (IEEE浮点运算中的“非数”值)以一致但与机器相关的顺序排列。
负无穷。
有限个数字按升序排列(−0和+0相等)。
正无穷。
只有在没有其他选择时才使用这个选项;它比--numeric-sort (-n)慢得多,并且在转换为浮点数时可能会丢失信息。
你可以使用此选项对以`0x`或`0X`为前缀的十六进制数字进行排序,这些数字的宽度不是固定的,或者大小写不同。
然而,对于一致情况的十六进制数字,并用`0`填充到一致的宽度,标准的字典排序将更快。
‘-h’
‘--human-numeric-sort’
‘--sort=human-numeric’
按数字排序,首先按数字符号排序(负、零或正);
然后通过 SI 后缀(空,或'k'或'K',或'MGTPEZYRQ'中的一个,按此顺序;参见第2.2节[块大小],第3页);
最后是数值。例如,`1023M`排序在`1G`之前,因为`M` (mega)作为SI后缀在`G` (giga)之前。
该选项对始终缩放到最近后缀的值进行排序,无论后缀表示1000或1024的幂次,因此它对df、du或ls命令的任何单一调用的输出进行排序,这些调用使用它们的--human-readable或--si选项进行调用。
数字排序的语法与--numeric-sort选项相同;SI后缀必须紧跟在数字后面。为了更精确地排序,可以在排序后使用numfmt命令将数字重新格式化为人类格式。
‘-i’
‘--ignore-nonprinting’
忽略非打印字符。LC_CTYPE 区域设置决定了字符类型。如果还提供了更强的--dictionary-order (-d)选项,则此选项无效。
‘-M’
‘--month-sort’
‘--sort=month’
初始字符串由任意数量的空格组成,后面是一个月份名称的缩写,将被折叠为大写,并按顺序进行比较'JAN' < 'FEB' < … < 'DEC'。
无效名称与有效名称相比比较低。LC_TIME 区域设置类别确定月份拼写。默认情况下,空白是空格或制表符,但LC_CTYPE区域设置可以改变这一点。
‘-n’
‘--numeric-sort’
‘--sort=numeric’
数值。该数字以每一行开始,由可选的空格、可选的`-`符号和可能由数千分隔符分隔的零位或多个数字组成,可选的后面是一个小数点字符和零位或多个数字。
一个空数字被视为`0`。0和前导0的符号不影响顺序。比较是精确的;没有舍入误差。LC_CTYPE 区域设置指定哪些字符是空格,LC_NUMERIC 区域设置指定千位分隔符和小数点字符。
在C语言环境中,空格和制表符是空格,没有千位分隔符和'.'是小数点。开头的`+`和指数符号都不被识别。要从数字上比较这些字符串,可以使用--general-numeric-sort (-g)选项。
‘-V’
‘--version-sort’
按版本名和版本号排序。它的行为与标准排序类似,只是每个十进制数字序列都被视为索引/版本号。(参见第30章[版本排序],第253页。)
‘-r’
‘--reverse’
反转比较的结果,使键值大的行出现在输出的前面,而不是后面。
‘-R’
‘--random-sort’
‘--sort=random’
通过对输入键进行散列,然后对散列值进行排序。随机选择散列函数,确保它不会发生冲突,使得不同的键具有不同的散列值。这类似于输入的随机排列(参见7.2节[shuf调用]),只不过具有相同值的键会排序在一起。
如果指定多个随机排序字段,则对所有字段使用相同的随机散列函数。要对不同的字段使用不同的随机散列函数,可以多次调用sort。
散列函数的选择受到--random-source选项的影响。
其他选项有:
‘--compress-program=prog’
用prog程序压缩任何临时文件。在没有参数的情况下,prog必须将标准输入压缩为标准输出,而在提供-d选项时,它必须将标准输入解压为标准输出。如果prog以非零状态退出,则终止错误。空格和反斜杠字符不应该出现在prog中;它们被保留以供将来使用。
‘--files0-from=file’
不允许处理在命令行中命名的文件,而是处理在file file中命名的文件;每个名称都以0字节(ASCII NUL)结尾。当文件名列表太长以至于可能超过命令行长度限制时,这很有用。
在这种情况下,通过xargs运行sort是不可取的,因为它将列表分成几部分,并让sort打印出每个子列表的有序输出,而不是整个列表。
生成ASCII以NUL结尾的文件名列表的一种方法是使用GNU find,使用它的-print0谓词。如果file为'-',则从标准输入中读取ASCII NUL结尾的文件名。
‘-k pos1[,pos2]’
‘--key=pos1[,pos2]’
指定一个排序字段,该字段由pos1和pos2之间的行(或者行尾,如果省略pos2)组成,包括。
在最简单的形式中,pos指定了一个字段编号(从1开始),字段之间由一系列空白字符分隔,默认情况下,这些空白字符会包含在每个字段开始的比较中。要调整对空白字符的处理,请参阅-b和-t选项。
更一般地说,每个pos都有 ‘f[.c][opts]’ 的形式,其中f是要使用的字段的数字,c是字段开始后第一个字符的数字。字段和字符位置从1开始编号;
pos2中的字符位置为0表示字段的最后一个字符。如果pos1中省略了'.c',则默认值为1(字段的起始位置);
如果从pos2中省略,默认为0(字段的结尾)。Opts对选项进行排序,允许根据不同的规则对单个键进行排序;详情见下文。键可以跨越多个字段。
例如:对第二个字段进行排序,使用 --key=2,2 (-k 2,2).
有关键的更多说明和更多示例,请参见下文。另请参阅--debug选项,以帮助确定在排序中使用的是哪一行。
‘--debug’
突出每行中用于排序的部分。还对标准错误的可疑用法发出警告。
‘--batch-size=nmerge’
最多一次合并nmerge输入,当sort需要合并多个nmerge输入时,它会以nmerge为一组进行合并,并将结果保存在一个临时文件中,然后将该文件作为后续合并的输入。
较大的nmerge值可能会提高合并性能,并以增加内存使用和I/O为代价降低临时存储利用率。
相反,较小的nmerge值可能会减少内存需求和I/O,但会牺牲临时存储消耗和合并性能。
nmerge的值必须至少为2。当前的默认值是16,但这取决于具体实现,将来可能会改变。nmerge的值可能受到打开文件描述符的资源限制。
命令`ulimit -n`或`getconf OPEN_MAX`可以显示您系统的限制;如果你的程序已经打开了一些文件,或者操作系统对打开文件的数量有其他限制,那么这些限制可能会被进一步修改。
如果nmerge的值超过了资源限制,sort会静默地使用一个较小的值。
‘-o output-file’
‘--output=output-file’
将输出写入输出文件,而不是标准输出。通常,sort在打开输出文件之前读取所有输入,因此您可以使用 'sort -o F F' 和 'cat F | sort -o F' 这样的命令对文件进行原位排序。
不过,通常将结果输出到未使用的文件会更安全,因为在对文件进行排序时,如果系统崩溃,或者排序遇到I/O或其他严重错误,数据可能会丢失。
此外,sort使用 --merge (-m)可以在读取所有输入之前打开输出文件,因此像 'cat F | sort -m -o F - G' 这样的命令是不安全的,因为sort可能在cat完成读取F之前开始写入F。
在较新的系统上,如果设置了POSIXLY_CORRECT, -o不能出现在输入文件之后,例如,'sort F -o F'。可移植脚本应该在任何输入文件之前指定-o output-file。
‘--random-source=file’
使用file作为随机数据的来源,用于确定与-R选项一起使用的随机散列函数。参见第2.5节[随机来源],第7页。
‘-s’
‘--stable’
通过禁用排序的最后比较,使其稳定。如果除 --reverse (-r)之外没有指定任何字段或全局排序选项,则此选项无效。
‘-S size’
‘--buffer-size=size’
使用给定大小的主内存排序缓冲区。默认情况下,size的单位是1024字节。
添加'%'会导致size被解释为物理内存的百分比。
添加'K'会将size乘以1024(默认值),'M'乘以1,048,576,'G'乘以1,073,741,824,依次类推,` T `、` P `、` E `、` Z `、` Y `、` R `和` Q `。
添加'b'会导致size被解释为字节计数,而没有乘法。
这个选项可以通过使用比默认值更大或更小的排序缓冲区来提高排序的性能。但该选项只影响初始缓冲区大小。如果排序遇到大于size的输入行,则缓冲区会超过size。
‘-t separator’
‘--field-separator=separator’
在每行查找排序键时,使用字符分隔符作为字段分隔符。默认情况下,字段由非空字符和空字符之间的空字符串分隔。
默认情况下,空白是空格或制表符,但LC_CTYPE区域设置可以改变这一点。也就是说,给定输入行'foo bar', sort将它分成`foo`和`bar`两个字段。
字段分隔符不被认为是字段前半部分或字段后半部分的一部分,因此使用' sort -t " " ',同一输入行有三个字段:一个空字段,`foo`和`bar`。
但是,扩展到行尾的字段,如-k 2,或由范围组成的字段,如-k 2,3,保留了范围端点之间的字段分隔符。
要指定ASCII中的NUL作为字段分隔符,可以使用两个字符的字符串'\0',例如' sort -t '\0' '。
‘-T tempdir’
‘--temporary-directory=tempdir’
使用目录tempdir来存储临时文件,覆盖了环境变量TMPDIR。如果多次指定该选项,则临时文件存储在指定的所有目录中。
如果你有一个受 I/O 限制的大排序或合并,你通常可以通过使用这个选项来指定不同文件系统上的目录来提高性能。
‘--parallel=n’
将并行运行的排序次数设置为n。默认情况下,n设置为可用处理器的数量,但限制为8,因为在此之后性能将下降。使用n个线程会增加log n倍的内存使用。请参见21.3节[nproc调用],第203页。
‘-u’
‘--unique’
通常,只输出比较结果相等的行序列中的第一行。对于--check (-c或-c)选项,检查是否没有相邻的行比较相等。此选项还禁用默认的最后比较。
sort -u 命令和 sort | uniq 命令是等价的,但这种等价并不适用于任意排序选项。
例如,sort -n -u 在检查唯一性时只检查初始数值字符串的值,而 sort -n | uniq 会检查整行。参见第7.3节[uniq调用],第59页。
‘-z’
‘--zero-terminated’
用0字节而不是换行符分隔项(ASCII LF)。例如,将输入视为用ASCII NUL分隔的项目,并以ASCII NUL终止输出项目。
此选项可以与`perl -0`或`find -print0`和`xargs -0`一起使用,它们的作用相同,以便可靠地处理任意文件名(即使是包含空格或其他特殊字符的文件名)。
sort的历史实现(BSD和System V)对某些选项的解释有所不同,特别是-b、-f和-n。GNU排序遵循POSIX行为,这通常(但并不总是!)类似于System V的行为。根据POSIX, -n不再意味着-b。为了保持一致性,-M也做了相同的修改。在晦涩的情况下,这可能会影响字段规范中字符位置的含义。唯一的解决方法是显式地添加-b。
用-k指定的排序字段中的位置可以附加任何一个选项字母`MbdfghinRrV`,在这种情况下,该特定字段不会继承任何全局排序选项。
选项-b可以独立地附加到字段规范的起始和结束位置,也可以同时附加到这两个位置。如果选项继承自全局选项,那么-b选项会同时附加到这两个位置。
如果输入行可以包含前导或相邻的空格,并且不使用-t,那么-k通常与-b结合使用,或者使用一个隐式忽略前导空格的选项(' Mghn '),否则字段中不同数量的前导空格可能会导致混淆的结果。
如果排序字段说明符中的起始位置落在行尾或结束字段之后,则该字段为空。如果指定了-b选项,则字段规范中的` .c `部分从字段的第一个非空白字符开始计数。
在不符合POSIX 1003.1-2001的系统上,sort支持传统的零源语法` +pos1 [-pos2] `来指定排序键。传统的命令` sort +a。x - b。Y `等价于` sort -k a+1。X +1,b `如果y为` 0 `或不存在,否则它等价于` sort -k a+1. X +1,b+1.y `。
这种传统的行为可以用_POSIX2_VERSION环境变量控制(参见2.13节);当没有设置POSIXLY_CORRECT时,也可以使用传统的` -pos2 `语法来启用它。
打算在标准主机上使用的脚本应该避免使用传统语法,而应该使用-k。例如,避免使用` sort +2 `,因为它可能被解释为` sort ./+2 `或` sort -k 3 `。如果你的脚本必须运行在只支持传统语法的主机上,它可以使用类似` If sort -k 1 </dev/null >/dev/null 2>&1;然后……`来决定使用哪种语法。
这里有一些例子来说明各种选项的组合。
按数字降序(反向)排序。
sort -n -r
使用10M的缓冲区,并发排序不超过4次。
sort --parallel=4 -S 10M
按字母顺序排序,省略第一、第二个字段以及第三个字段开头的空格。它使用一个键,键由字段3中第一个非空字符开始,一直到每行结束的字符组成。
sort -k 3b
对第二个字段按数字排序,对第5个字段的第三和第4个字符按字母顺序排序。使用`:`作为字段分隔符。
sort -t : -k 2,2n -k 5.3,5.4
如果使用-k 2n而不是-k 2,那么2n排序将使用从第二个字段开始一直到行尾的所有字符作为主键。
对于大多数应用程序来说,将跨越多个字段的键作为数值处理不会达到预期效果。
此外,`n`修饰符应用于第一个键的字段结束说明符。它等价于指定-k 2n,2或者-k 2n,2n。除了'b',所有修饰符都应用于相关字段,无论修饰符字符是否附加到键说明符的字段起始和/或字段结束部分。
按第5个字段排序密码文件,忽略前导空格。对第3个数字用户ID的第5个字段中值相等的行进行排序。字段由`:`分隔。
sort -t : -k 5b,5 -k 3,3n /etc/passwd
sort -t : -n -k 5b,5 -k 3,3 /etc/passwd
sort -t : -b -k 5,5 -k 3,3n /etc/passwd
这三个命令具有相同的效果。第一个参数指定第一个键的起始位置忽略前导空格,第二个键按数字排序。另外两个命令依赖于全局选项,这些全局选项由缺少修饰符的排序键继承。
在这种情况下,继承可以工作,因为 -k 5b,5b 和 -k 5b,5 是等效的,因为缺少'.c'字符位置的字段端位置不受初始空格是否被跳过的影响。
对一组日志文件进行排序,主要按IPv4地址排序,其次按时间戳排序。如果两行的主键和次键相同,则按照输入的顺序输出。日志文件中包含的行如下所示:
4.150.156.3 - - [01/Apr/2020:06:31:51 +0000] message 1
211.24.3.231 - - [24/Apr/2020:20:17:39 +0000] message 2
字段由一个空格分隔。IPv4地址按字典序排序,例如,212.61.52.2排序在212.129.233.201之前,因为61小于129。
sort -s -t ' ' -k 4.9n -k 4.5M -k 4.2n -k 4.14,4.21 file*.log | sort -s -t '.' -k 1,1n -k 2,2n -k 3,3n -k 4 4n
这个例子不能用单一的POSIX排序调用完成,因为IPv4地址组件由'.'而约会就在空格之后。
因此它被分解为两次sort调用:第一次按时间戳排序,第二次按IPv4地址排序。时间戳按年、月、日排序,最后按时、分、秒字段排序,使用-k隔离每个字段。
除了小时分秒,没有必要指定每个关键字段的结尾,因为`n`和`M`修饰符是基于不能跨越字段边界的前导前缀排序的。IPv4地址按字典序排列。
第二种排序使用`-s`,这样与主键的关联会被辅键打破;第一种排序使用`-s`,这样两种排序的组合是稳定的。作为一个GNU扩展,上面的例子可以通过使用` V `版本类型(如` -k1,1V `)对IPv4地址字段进行排序,在单个sort调用中实现。
按照不区分大小写的顺序生成标签文件。
find src -type f -print0 | sort -z -f | xargs -0 etags --append
这里使用了-print0、-z和-0,这意味着排序操作不会打断包含空格或其他特殊字符的文件名。
使用常用的DSU、Decorate Sort Undecorate习语根据长度对线条进行排序。
awk '{print length, $0}' /etc/passwd | sort -n | cut -f2- -d' '
一般来说,这种技术可以用于sort命令不支持的数据排序,或者直接排序效率不高的数据排序。
打乱目录列表,但保留每个目录中文件的顺序。例如,人们可以使用它来生成一个音乐播放列表,其中专辑被打乱,但每个专辑的歌曲是按顺序播放的。
ls */* | sort -t / -k 1,1R -k 2,2【busybox】【sort】指令介绍
NA
【linux】【sort】指令介绍
[root@localhost bin]# sort --help
用法:sort [选项]... [文件]...
或:sort [选项]... --files0-from=F
Write sorted concatenation of all FILE(s) to standard output.
如果没有指定文件,或者文件为"-",则从标准输入读取。
必选参数对长短选项同时适用。
排序选项:
-b, --ignore-leading-blanks 忽略前导的空白区域
-d, --dictionary-order 只考虑空白区域和字母字符
-f, --ignore-case 忽略字母大小写
-g, --general-numeric-sort compare according to general numerical value
-i, --ignore-nonprinting consider only printable characters
-M, --month-sort compare (unknown) < 'JAN' < ... < 'DEC'
-h, --human-numeric-sort 使用易读性数字(例如: 2K 1G)
-n, --numeric-sort compare according to string numerical value
-R, --random-sort shuffle, but group identical keys. See shuf(1)
--random-source=FILE get random bytes from FILE
-r, --reverse reverse the result of comparisons
--sort=WORD 按照WORD 指定的格式排序:
一般数字-g,高可读性-h,月份-M,数字-n,
随机-R,版本-V
-V, --version-sort 在文本内进行自然版本排序
其他选项:
--batch-size=NMERGE 一次最多合并NMERGE 个输入;如果输入更多
则使用临时文件
-c, --check, --check=diagnose-first 检查输入是否已排序,若已有序则不进行操作
-C, --check=quiet, --check=silent 类似-c,但不报告第一个无序行
--compress-program=程序 使用指定程序压缩临时文件;使用该程序
的-d 参数解压缩文件
--debug 为用于排序的行添加注释,并将有可能有问题的
用法输出到标准错误输出
--files0-from=文件 从指定文件读取以NUL 终止的名称,如果该文件被
指定为"-"则从标准输入读文件名
-k, --key=KEYDEF sort via a key; KEYDEF gives location and type
-m, --merge merge already sorted files; do not sort
-o, --output=文件 将结果写入到文件而非标准输出
-s, --stable 禁用last-resort 比较以稳定比较算法
-S, --buffer-size=大小 指定主内存缓存大小
-t, --field-separator=分隔符 使用指定的分隔符代替非空格到空格的转换
-T, --temporary-directory=目录 使用指定目录而非$TMPDIR 或/tmp 作为
临时目录,可用多个选项指定多个目录
--parallel=N 将同时运行的排序数改变为N
-u, --unique 配合-c,严格校验排序;不配合-c,则只输出一次排序结果
-z, --zero-terminated line delimiter is NUL, not newline
--help 显示此帮助信息并退出
--version 显示版本信息并退出
KEYDEF is F[.C][OPTS][,F[.C][OPTS]] for start and stop position, where F is a
field number and C a character position in the field; both are origin 1, and
the stop position defaults to the line's end. If neither -t nor -b is in
effect, characters in a field are counted from the beginning of the preceding
whitespace. OPTS is one or more single-letter ordering options [bdfgiMhnRrV],
which override global ordering options for that key. If no key is given, use
the entire line as the key. Use --debug to diagnose incorrect key usage.
SIZE may be followed by the following multiplicative suffixes:
内存使用率% 1%,b 1、K 1024(默认),M、G、T、P、E、Z、Y 等依此类推。
*** 警告 ***
地区与语言环境变量(locale)会影响排序结果。
如果希望以字节的自然值获得最传统的排序结果,
请设置环境变量 LC_ALL=C。
GNU coreutils 在线帮助:<https://www.gnu.org/software/coreutils/>
请向 <http://translationproject.org/team/zh_CN.html> 报告 sort 的翻译错误
完整文档请见:<https://www.gnu.org/software/coreutils/sort>
或者在本地使用:info '(coreutils) sort invocation'使用示例:
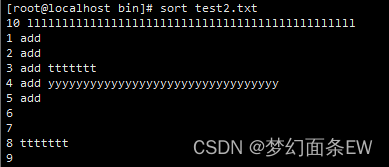
排序 - 默认排序
指令:sort test2.txt
排序 - 检查所给文件是否已经排序
小写的 -c / 大写的 -C
指令:sort -c test2.txt #未排序 - 打印第一个未排序的行,然后返回1;已排序 - 返回0
指令:sort -C test2.txt #适用于脚本使用 未排序 - 返回1;已排序 - 返回0

排序 - 输出已经排序过的文件,不会重新排序
-m 选项 将两个已经排序的文件输出
先看看原始文件内容,
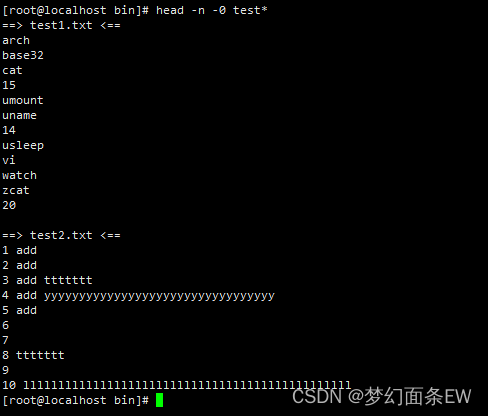
指令: sort -m test1.txt test2.txt
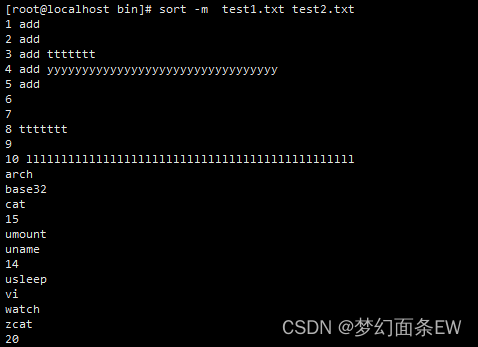
指令: sort test1.txt test2.txt

对比结果以后可以发现, test2.txt文件中的数字当带有-m选项时不会再和test1.txt中的数字重新排序。
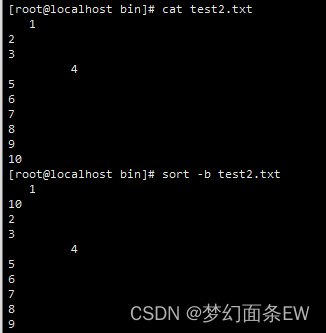
排序 - 忽略每行前面的空格
-b 选项 其实单独跑这个选项看不出区别,此选项需要和其他选项联动
指令: sort -b test2.txt
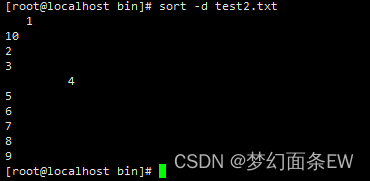
排序 - 排序时忽略除字母、数字和空格以外的所有字符
-d 选项
指令: sort -d test2.txt
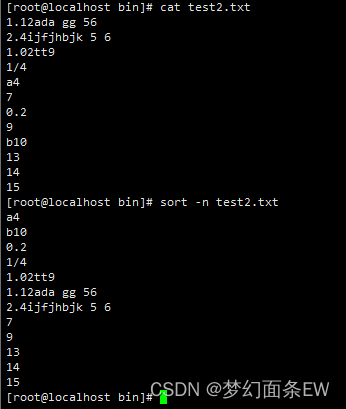
排序 - 将小写字符视为相同的大写字符
-f 选项 正常状态下,小写字符在前,使用这个参数后,大写字符在前。
除了这个变化以外,还不知道这个选项可以用在哪
指令: sort -f test2.txt
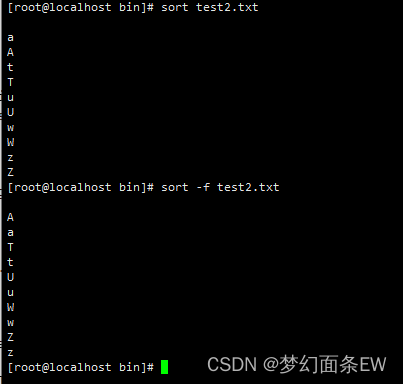
排序 - 把每行前缀转为数字进行排序
-g 选项,忽略字符和空白,以数字排序
默认排序只拍第一个字符,按照数字排序以后就可以正确排出来
指令: sort -g test2.txt
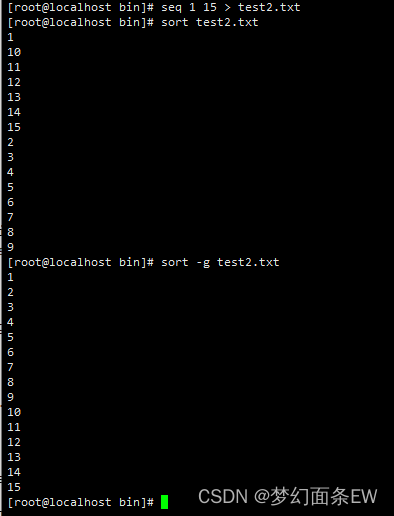
排序 - 把每行前缀转为数字进行排序,同时也判断后缀
-h 选项,适用于比较1K和1M的大小,不带后缀解释为b
指令: sort -h test2.txt
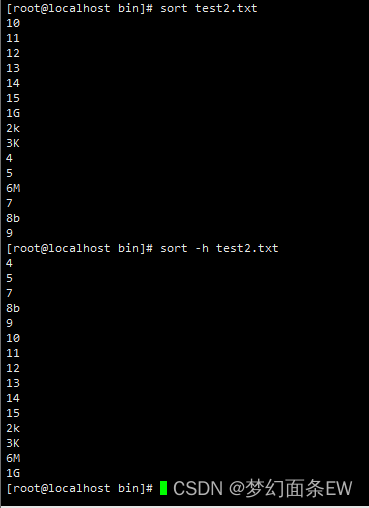
排序 - 把每行前缀转为数字进行排序2
-n 选项,忽略字符和空白,以数字排序
默认排序只拍第一个字符,按照数字排序以后就可以正确排出来
指令: sort -n test2.txt
排序 - 显示详细的排序过程,用于调试
--debug 突出每行中用于排序的部分。还对标准错误的可疑用法发出警告。
指令: sort -n --debug test2.txt

排序 - 反向输出排序结果
-r 选项
指令: sort -n -r test2.txt

排序 - 指定排序字段
字段和字符位置从1开始编号;
-k pos1[,pos2] 指定在哪个编号进行排序
指令: sort -k 1,3 test2.txt #按照编号1 ~ 3之间排序
指令: sort -k 1,1 test2.txt #按照编号1 ~ 1之间排序
排序 - 将结果输出到指定文件
-o 选项
指令: sort -o test.log test2.txt
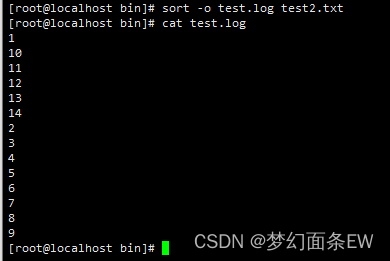
排序 - 使用给定大小的主内存排序缓冲区,默认1024字节
-S size 选项,指定初始内存缓冲区大小,如果后续遇到超过了指定大小的行,那么缓冲区会超过size
指令:sort -S 16 test2.txt
排序 - 忽略非打印字符
-i 选项
排序 - 排序月份
-M 选项
排序 - 指定分割符
-t 选项
指令: sort -t " " test2.txt
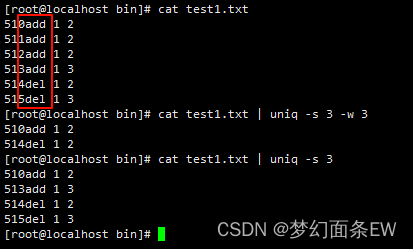
排序 - 结果去掉重复行
-u 选项, 但是一般用uniq来会好些
指令: sort -u test2.txt
也可以这么写
指令: sort test2.txt | uniq
这个指令一次整理不出来,后续碰到了继续更新
常用组合指令:
NA



![[蓝桥杯]真题讲解:班级活动(贪心)](https://img-blog.csdnimg.cn/direct/1d9e87f0d59b457fbade46069f56c543.png)




![[Maven]IDEA报错-xxx is referencing itself](https://img-blog.csdnimg.cn/direct/1c6ce326555b4c82888cdb6bab56914d.png)

![error code [1449]; The user specified as a definer (‘root‘@‘%‘) does not exist](https://img-blog.csdnimg.cn/direct/c47c3d63d15540f984d1a6b9bf29dda8.png)