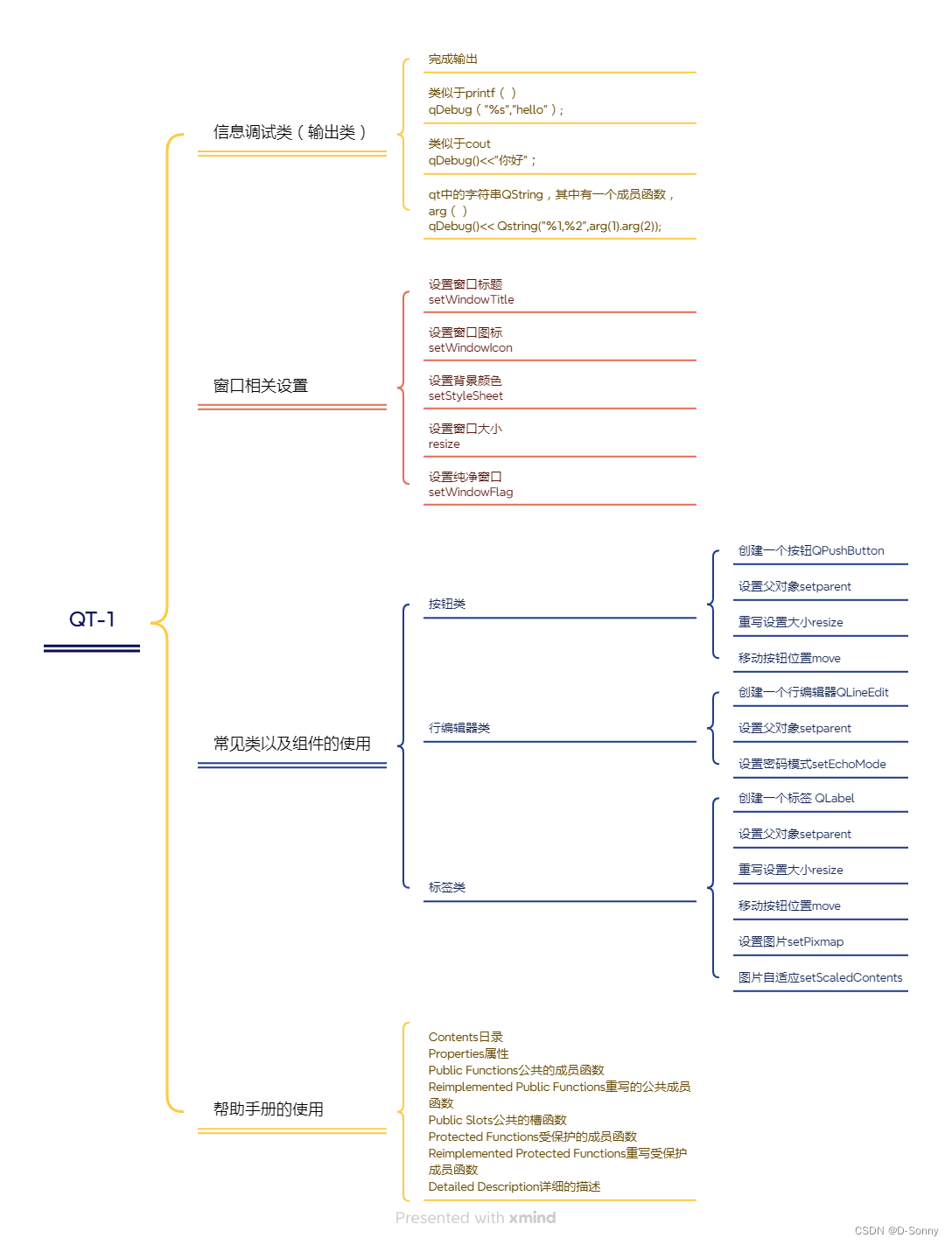
目录
内容来源:
【GUN】【uniq】指令介绍
【busybox】【uniq】指令介绍
【linux】【uniq】指令介绍
使用示例:
去除重复行 - 默认输出
去除重复行 - 跳过第n段(空格隔开),比较n+1以后的内容,去重
去除重复行 - 跳过第n个字节,比较n+1以后的内容,去重
去除重复行 - 比较指定宽度的内容,去重
去除重复行 - 打印每个行出现的次数
去除重复行 - 忽略大小写
去除重复行 - 丢弃不重复的行,只输出重复的行
去除重复行 - 丢弃重复的行,只输出不重复的行
去除重复行 - 不丢弃连续的重复输入行,而是丢弃不重复的行
去除重复行 - 可以按组把内容分开
常用组合指令:
去除重复行 - 跳过第n个字节,比较(n+1) ~ (n+m)之间的内容,去重
指令不常用/组合用法还需继续挖掘:
内容来源:
GUN : Coreutils - GNU core utilities
busybox v1.36.1 : 【busybox记录】【shell指令】基于的Busybox的版本和下载方式-CSDN博客
【GUN】【uniq】指令介绍
uniq:唯一标识文件
uniq 在给定的输入中写入唯一的行,如果没有给出任何输入,则写入标准输入,或者输入名称为' - '。
简介:
uniq [option]... [input [output]]
默认情况下,uniq打印它的输入行,但它会丢弃除了第一行以外的所有相邻的重复行,这样就没有重复的输出行了。可选地,它可以丢弃不重复的行或所有重复的行。
输入不需要排序,但只有当重复的输入行相邻时,才会检测它们。如果你想丢弃不相邻的重复行,可能需要使用sort -u。参见第7.1节[排序调用],第49页。
比较遵循LC_COLLATE区域类别指定的规则。
如果没有指定输出文件,uniq将写入标准输出。
该程序接受以下选项。参见第2章[常见选项],第2页。
‘-f n’
‘--skip-fields=n’
在检查唯一性之前,跳过每一行的n个字段。如果一行中字段少于n个,则使用null字符串进行比较。字段是空白字符和非空白字符的序列。字段编号是基于1的,即 -f 1 会跳过第一个字段(可以有前导空格)。
为了兼容,uniq支持传统的选项语法 -n。新的脚本应该使用-f n。
‘-s n’
‘--skip-chars=n’
在检查唯一性之前跳过n个字符。如果一行少于n个字符,则使用null字符串进行比较。如果同时使用字段和字符跳过选项,则首先跳过字段。
在不符合POSIX 1003.1-2001的系统上,uniq支持传统的option语法+n。尽管这种传统的行为可以用_ POSIX2_VERSION 环境变量控制(参见2.13节),但可移植脚本应该避免那些行为依赖于该变量的命令。例如,使用`uniq ./+10`或`uniq -s 10`,而不是模棱两可的`uniq +10`。
‘-c’
‘--count’
打印每一行出现的次数。
‘-i’
‘--ignore-case’
比较行时忽略大小写的差异。
‘-d’
‘--repeated’
丢弃不重复的行。单独使用这个选项时,uniq只打印每个重复行的第一份副本,而不打印其他内容。
‘-D’
‘--all-repeated[=delimit-method]’
不要丢弃第二个和后续重复的输入行,而是丢弃不重复的行。
这个选项主要与其他选项一起使用,例如忽略大小写或只比较选定字段。支持可选的delimit-method,用于指定如何分隔重复行的组,它必须是下列之一:
‘none’ 不要划分重复的行组。这等价于 --all-repeat (-D)。
‘prepend’ 在每组重复行之前输出一个换行符。使用--zero-terminated (-z)时,使用0字节(ASCII NUL)代替换行符作为分隔符。
‘separate’ 用一个换行符将一组重复的行分开。这与使用`prepend`相同,只是在第一组之前没有插入分隔符,因此可能更适合直接输出给用户。使用--zero-terminated (-z)时,使用0字节(ASCII NUL)代替换行符作为分隔符。
当分组被分隔,并且输入流包含空行时,输出是不明确的。为了避免这种情况,请通过 ‘tr -s '\n'’ 过滤输入以删除空行。这是一个GNU扩展。
‘--group[=delimit-method]’
输出所有行,并划分每个唯一的组。使用 --zero-terminated (-z) 时,使用0字节(ASCII NUL)代替换行符作为分隔符。可选的delimit-method指定了如何划分组,它必须是下列之一:
‘separate’ 用一个分隔符分隔唯一的组。如果没有指定,这是默认的定界方法,更适合直接输出给用户。
‘prepend’ 在每组不同的项之前输出一个定界符。
‘append’ 在每组不同的项之后输出一个定界符。
‘both’ 在每组不同的项之间输出一个定界符。
当分组被分隔,并且输入流包含空行时,输出是不明确的。为了避免这种情况,请通过 ‘tr -s '\n'’ 过滤输入以删除空行。这是一个GNU扩展。
‘-u’
‘--unique’
丢弃重复输入组的最后一行输出。当单独使用这个选项时,uniq只打印唯一的行。
‘-w n’
‘--check-chars=n’
每行最多比较n个字符(跳过任何指定的字段和字符后)。默认情况下,比较剩余的所有行。
‘-z’
‘--zero-terminated’
用0字节而不是换行符分隔项(ASCII LF)。例如,将输入视为用ASCII NUL分隔的项目,并以ASCII NUL终止输出项目。
此选项可以与‘perl -0’ 或 ‘find -print0’ 和 ‘xargs -0’一起使用,它们的作用相同,以便可靠地处理任意文件名(即使是包含空格或其他特殊字符的文件名)。使用-z,换行符被视为字段分隔符。
退出状态为零表示成功,非零值表示失败。【busybox】【uniq】指令介绍
NA
【linux】【uniq】指令介绍
[root@localhost bin]# uniq --help
用法:uniq [选项]... [文件]
Filter adjacent matching lines from INPUT (or standard input),
writing to OUTPUT (or standard output).
With no options, matching lines are merged to the first occurrence.
必选参数对长短选项同时适用。
-c, --count prefix lines by the number of occurrences
-d, --repeated only print duplicate lines, one for each group
-D print all duplicate lines
--all-repeated[=METHOD] like -D, but allow separating groups
with an empty line;
METHOD={none(default),prepend,separate}
-f, --skip-fields=N avoid comparing the first N fields
--group[=METHOD] show all items, separating groups with an empty line;
METHOD={separate(default),prepend,append,both}
-i, --ignore-case ignore differences in case when comparing
-s, --skip-chars=N avoid comparing the first N characters
-u, --unique only print unique lines
-z, --zero-terminated line delimiter is NUL, not newline
-w, --check-chars=N 对每行第N 个字符以后的内容不作对照
--help 显示此帮助信息并退出
--version 显示版本信息并退出
若域中为先空字符(通常包括空格以及制表符),然后非空字符,域中字符前的空字符将被跳过。
提示:"uniq" 不会检查重复的行,除非它们是相邻的行。
您也许需要事先对输入排序,或使用 "sort -u" 而非 "uniq"。
另外,比较操作将服从 "LC_COLLATE" 环境变量所指定的规则。
GNU coreutils 在线帮助:<https://www.gnu.org/software/coreutils/>
请向 <http://translationproject.org/team/zh_CN.html> 报告 uniq 的翻译错误
完整文档请见:<https://www.gnu.org/software/coreutils/uniq>
或者在本地使用:info '(coreutils) uniq invocation'使用示例:
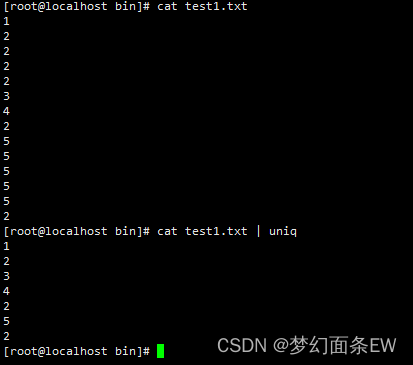
去除重复行 - 默认输出
指令: cat test1.txt | uniq
去除重复行 - 跳过第n段(空格隔开),比较n+1以后的内容,去重
-f 选项
先看看原始文件
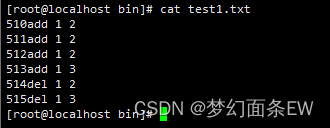
我们跳过51{x}add 这个字段,只比较后面的段
指令: cat test1.txt| uniq -f 1

结果如上,会发现 511add 和 512add 行被去掉了,因为增加-f 1选项后,比对是从后面的(1 2)/(1 3)开始的
去除重复行 - 跳过第n个字节,比较n+1以后的内容,去重
-s 选项
先看看原始文件
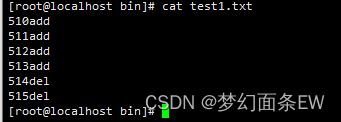
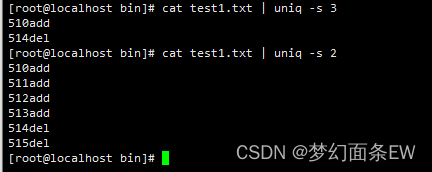
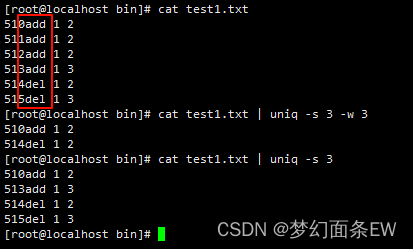
指令:cat test1.txt | uniq -s 3
指令:cat test1.txt | uniq -s 2
去除重复行 - 比较指定宽度的内容,去重
-w 选项
指令: cat test1.txt | uniq -w 2

去除重复行 - 打印每个行出现的次数
-c 选项
结合上面的-s -f 选项一起看看输出
指令:cat test1.txt | uniq -s 3 -c

指令:cat test2.txt | uniq -f 2 -c

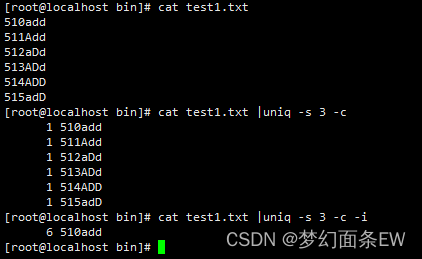
去除重复行 - 忽略大小写
-i 选项
指令:cat test1.txt |uniq -s 3 -c -i
去除重复行 - 丢弃不重复的行,只输出重复的行
-d 选项
指令:cat test1.txt | uniq -d
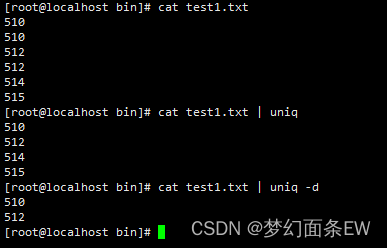
去除重复行 - 丢弃重复的行,只输出不重复的行
-u 选项
指令:cat test1.txt | uniq -u
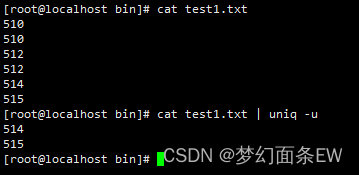
去除重复行 - 不丢弃连续的重复输入行,而是丢弃不重复的行
-D 选项
--all-repeated[=delimit-method] 选项
指令: cat test1.txt | uniq -D
指令: cat test1.txt | uniq --all-repeated=none
指令: cat test1.txt | uniq --all-repeated=prepend
指令: cat test1.txt | uniq --all-repeated=separate
指令: cat test1.txt | uniq --all-repeated=separate |tr -s '\n'

去除重复行 - 可以按组把内容分开
--group[=delimit-method] 选项
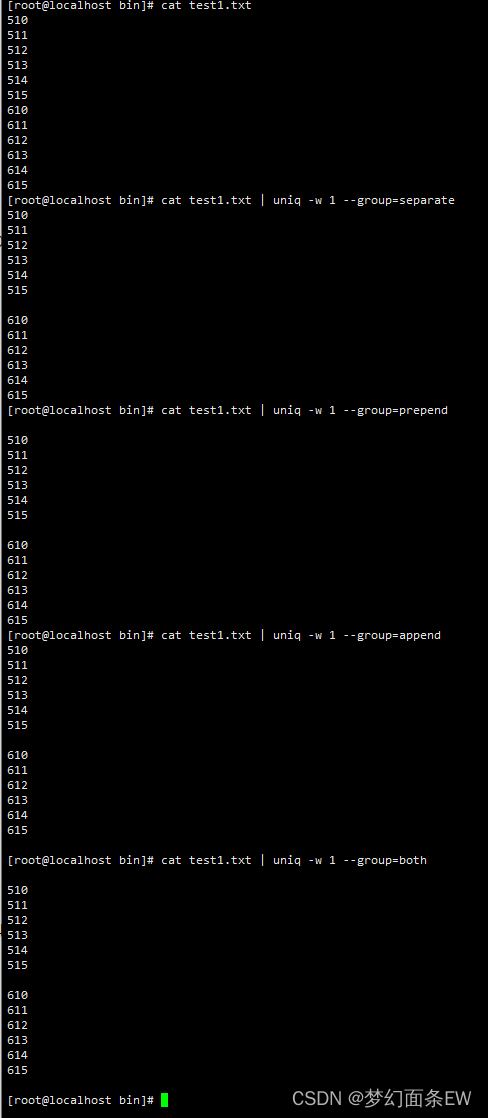
-w 1 选项是只比较每一行的第一个字符,其余字符忽略
指令: cat test1.txt | uniq -w 1 --group=separate
指令: cat test1.txt | uniq -w 1 --group=prepend
指令: cat test1.txt | uniq -w 1 --group=append
指令: cat test1.txt | uniq -w 1 --group=both
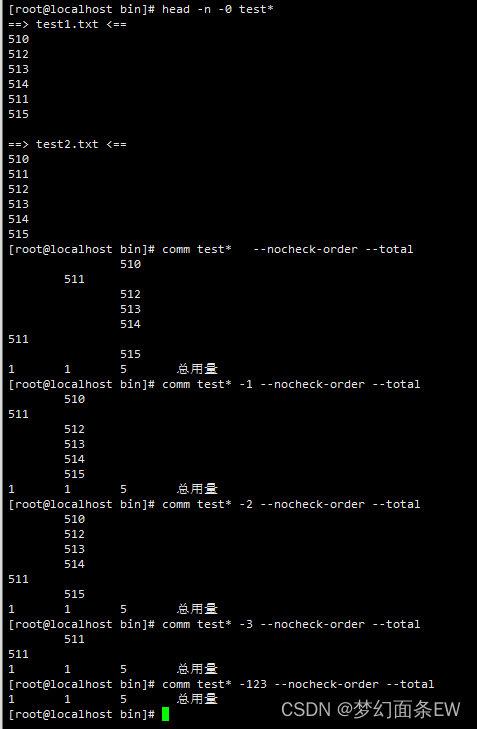
常用组合指令:
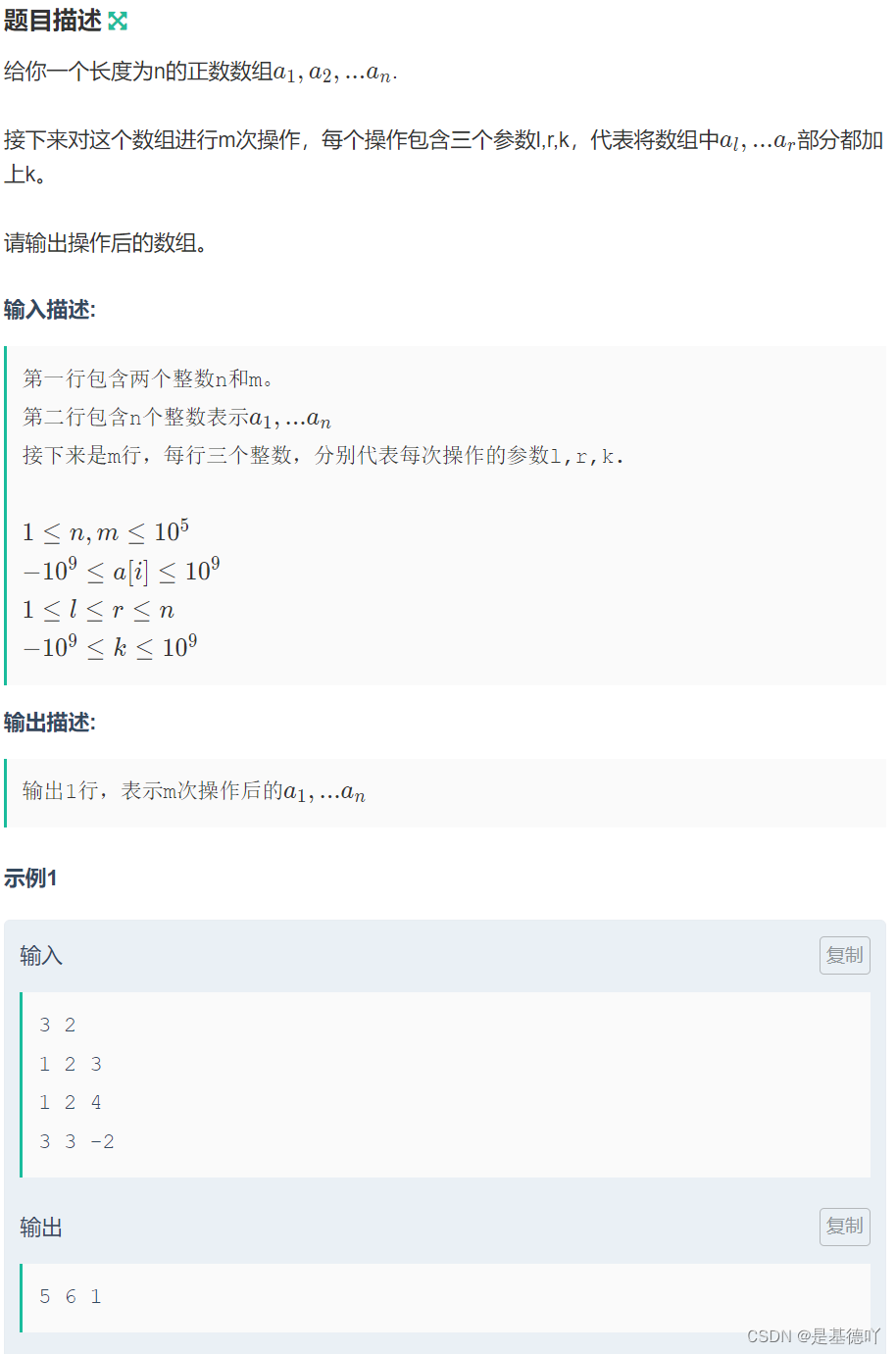
去除重复行 - 跳过第n个字节,比较(n+1) ~ (n+m)之间的内容,去重
-s 和 -w 选项
比较从第4个字节到第6个字节之间的3个字节的内容
指令: cat test1.txt | uniq -s 3 -w 3



![[Maven]IDEA报错-xxx is referencing itself](https://img-blog.csdnimg.cn/direct/1c6ce326555b4c82888cdb6bab56914d.png)

![error code [1449]; The user specified as a definer (‘root‘@‘%‘) does not exist](https://img-blog.csdnimg.cn/direct/c47c3d63d15540f984d1a6b9bf29dda8.png)