一、简介
在 Java web 项目中,想必很多的同学对ThreadLocal这个类并不陌生,它最常用的应用场景就是用来做对象的跨层传递,避免多次传递,打破层次之间的约束。
比如下面这个HttpServletRequest参数传递的简单例子!
public class RequestLocal {
/**
* 线程本地变量
*/
private static ThreadLocal<HttpServletRequest> local = new ThreadLocal<>();
/**
* 存储请求对象
* @param request
*/
public static void set(HttpServletRequest request){
local.set(request);
}
/**
* 获取请求对象
* @return
*/
public static HttpServletRequest get(){
return local.get();
}
/**
* 移除请求对象
* @return
*/
public static void remove(){
local.remove();
}
}
public class MyServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 存储请求对象变量
RequestLocal.set(req);
try {
// 业务逻辑...
} finally {
// 请求完毕之后,移除请求对象变量
RequestLocal.remove();
}
}
}
// 在需要的地方,通过 RequestLocal 类获取HttpServletRequest对象
HttpServletRequest request = RequestLocal.get();
看完以上示例,相信大家对ThreadLocal的使用已经有了大致的认识。
当然ThreadLocal的作用还不仅限如此,作为 Java 多线程模块的一部分,ThreadLocal也经常被一些面试官作为知识点用来提问,因此只有理解透彻了,回答才能更加游刃有余。
下面我们从ThreadLocal类的源码解析到使用方式做一次总结,如果有不正之处,请多多谅解,并欢迎批评指出。
二、源码剖析
ThreadLocal类,也经常被叫做线程本地变量,也有的叫做本地线程变量,意思其实差不多,通俗的解释:ThreadLocal作用是为变量在每个线程中创建一个副本,这样每个线程就可以访问自己内部的副本变量;同时,该变量对其他线程而言是封闭且隔离的。
字面的意思很容易理解,但是实际上ThreadLocal类的实现原理还有点复杂。
打开ThreadLocal类,它总共有 4 个public方法,内容如下!
| 方法 | 描述 |
|---|---|
| public void set(T value) | 设置当前线程变量 |
| public T get() | 获取当前线程变量 |
| public void remove() | 移除当前线程设置的变量 |
| public static ThreadLocal withInitial(Supplier supplier) | 自定义初始化当前线程的默认值 |
其中使用最多的就是set()、get()和remove()方法,至于withInitial()方法,一般在ThreadLocal对象初始化的时候,给定一个默认值,例如下面这个例子!
// 给所有线程初始化一个变量 1
private static ThreadLocal<Integer> localInt = ThreadLocal.withInitial(() -> 1);
下面我们重点来剖析以上三个方法的源码,最后总结如何正确的使用。
以下源码解析均基于jdk1.8。
2.1、set 方法
打开ThreadLocal类,set()方法的源码如下!
public void set(T value) {
// 首先获取当前线程对象
Thread t = Thread.currentThread();
// 获取当前线程中的变量 ThreadLocal.ThreadLocalMap
ThreadLocalMap map = getMap(t);
// 如果不为空,就设置值
if (map != null)
map.set(this, value);
else
// 如果为空,初始化一个ThreadLocalMap变量,其中key为当前的threadlocal变量
createMap(t, value);
}
我们继续看看createMap()方法的源码,内容如下!
void createMap(Thread t, T firstValue) {
// 初始化一个 ThreadLocalMap 对象,并赋予给 Thread 对象
// 可以发现,其实 ThreadLocalMap 是 Thread 类的一个属性变量
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// INITIAL_CAPACITY 变量的初始值为 16
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
从上面的源码上你会发现,通过ThreadLocal类设置的变量,最终保存在每个线程自己的ThreadLocal.ThreadLocalMap对象中,其中key是当前线程的ThreadLocal变量,value就是我们设置的变量。
基于这点,可以得出一个结论:每个线程设置的变量只有自己可见,其它线程无法访问,因为这个变量是线程自己独有的属性。
从上面的源码也可以看出,真正负责存储value变量的是Entry静态类,并且这个类继承了一个WeakReference类。稍有不同的是,Entry静态类中的key是一个弱引用类型对象,而value是一个强引用类型对象。这样设计的好处在于,弱引用的对象更容易被 GC 回收,当ThreadLocal对象不再被其他对象使用时,可以被垃圾回收器自动回收,避免可能的内存泄漏。关于这一点,我们在下文再详细的介绍。
最后我们再来看看map.set(this, value)这个方法的源码逻辑,内容如下!
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 根据hash和位运算,计算出数组中的存储位置
int i = key.threadLocalHashCode & (len-1);
// 循环遍历检查计算出来的位置上是否被占用
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
// 进入循环体内,说明当前位置已经被占用了
ThreadLocal<?> k = e.get();
// 如果key相同,直接进行覆盖
if (k == key) {
e.value = value;
return;
}
// 如果key为空,说明key被回收了,重新覆盖
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 当没有被占用,循环结束之后,取最后计算的空位,进行存储
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
private static int nextIndex(int i, int len) {
// 下标依次自增
return ((i + 1 < len) ? i + 1 : 0);
}
从上面的源码分析可以看出,ThreadLocalMap和HashMap,虽然都是键值对的方式存储数据,当在数组中存储数据的下表冲突时,存储数据的方式有很大的不同。jdk1.8种的HashMap采用的是链表法和红黑树来解决下表冲突,当
ThreadLocalMap采用的是开放寻址法来解决hash冲突,简单的说就是当hash出来的存储位置相同但key不一样时,会继续寻找下一个存储位置,直到找到空位来存储数据。
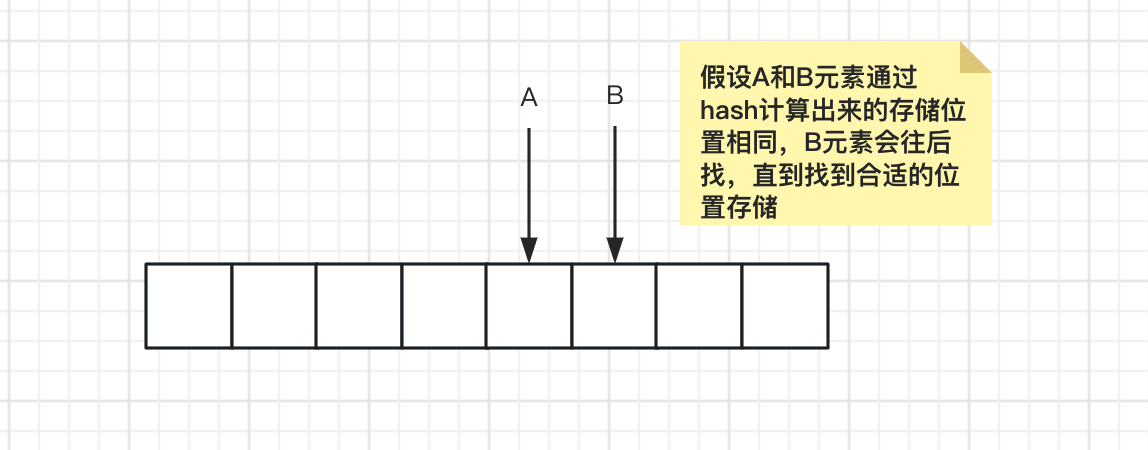
而jdk1.7中的HashMap采用的是链表法来解决hash冲突,当hash出来的存储位置相同但key不一样时,会将变量通过链表的方式挂在数组节点上。
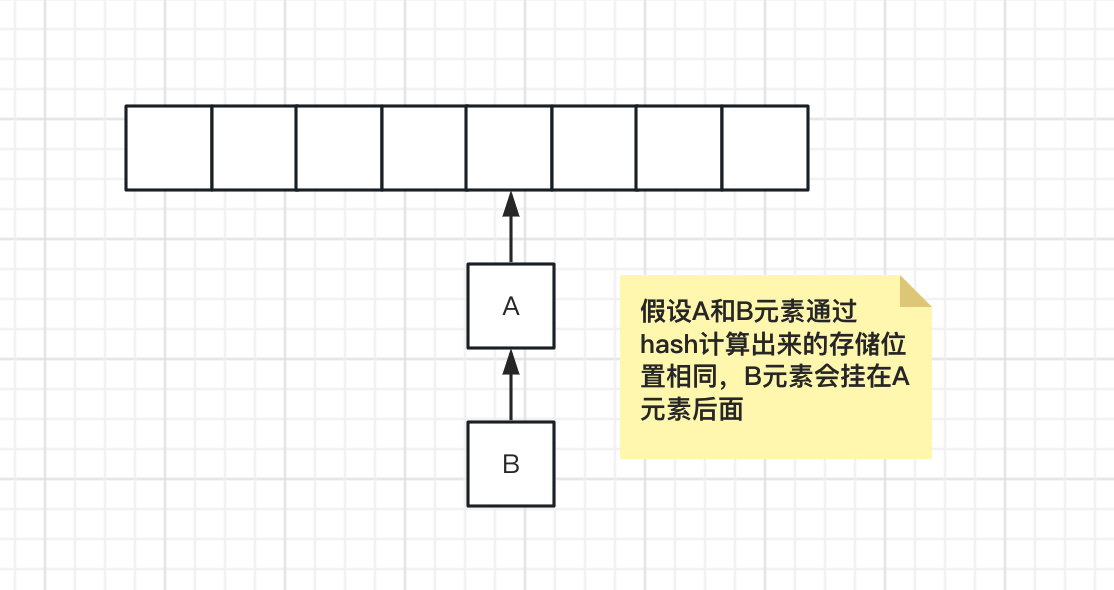
为了实现更高的读写效率,jdk1.8中的HashMap就更为复杂了,当冲突的链表长度超过 8 时,链表会转变成红黑树,在此不做过多的讲解,有兴趣的同学可以翻看关于HashMap的源码分析文章。
一路分析下来,是不是感觉set()方法还是挺复杂的,总结下来set()大致的逻辑有以下几个步骤:
- 1.首先获取当前线程对象,检查当前线程中的
ThreadLocalMap是否存在 - 2.如果不存在,就给线程创建一个
ThreadLocal.ThreadLocalMap对象 - 3.如果存在,就设置值,存储过程中如果存在 hash 冲突时,采用开放寻址法,重新找一个空位进行存储
2.2、get 方法
了解完set()方法之后,get()方法就更容易了,get()方法的源码如下!
public T get() {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 从当前线程对象中获取 ThreadLocalMap 对象
ThreadLocalMap map = getMap(t);
if (map != null) {
// 如果有值,就返回
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 如果没有值,重新初始化默认值
return setInitialValue();
}
这里我们要重点看下map.getEntry(this)这个方法,源码如下!
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
// 如果找到key,直接返回
if (e != null && e.get() == key)
return e;
else
// 如果找不到,就尝试清理,如果你总是访问存在的key,那么这个清理永远不会进来
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
// e指的是entry ,也就是一个弱引用
ThreadLocal<?> k = e.get();
// 如果找到了,就返回
if (k == key)
return e;
if (k == null)
// 如果key为null,说明已经被回收了,同时将value设置为null,以便进行回收
expungeStaleEntry(i);
else
// 如果key不是要找的那个,那说明有hash冲突,继续找下一个entry
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
从上面的源码可以看出,get()方法逻辑,总共有以下几个步骤:
- 1.首先获取当前线程对象,从当前线程对象中获取 ThreadLocalMap 对象
- 2.然后判断
ThreadLocalMap是否存在,如果存在,就尝试去获取最终的value - 3.如果不存在,就重新初始化默认值,以便清理旧的
value值
其中expungeStaleEntry()方法是真正用于清理value值的,setInitialValue()方法也具备清理旧的value变量作用。
从上面的代码可以看出,ThreadLocal为了清楚value变量,花了不少的心思,其实本质都是为了防止ThreadLocal出现可能的内存泄漏。
2.3、remove 方法
我们再来看看remove()方法,源码如下!
public void remove() {
// 获取当前线程里面的 ThreadLocalMap 对象
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
// 如果不为空,就移除
m.remove(this);
}
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
// 循环遍历目标key,然后将key和value都设置为null
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
// 清理value值
expungeStaleEntry(i);
return;
}
}
}
remove()方法逻辑比较简单,首先获取当前线程的ThreadLocalMap对象,然后循环遍历key,将目标key以及对应的value都设置为null。
从以上的源码剖析中,可以得出一个结论:不管是set()、get()还是remove(),其实都会主动清理无效的value数据,因此实际开发过程中,没有必要过于担心内存泄漏的问题。
三、为什么要用 WeakReference?
另外细心的同学可能会发现,ThreadLocal中真正负责存储key和value变量的是Entry静态类,并且它继承了一个WeakReference类。
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
关于WeakReference类,我们在上文只是简单的说了一下,可能有的同学不太清楚,这个再次简要的介绍一下。
了解过WeakHashMap类的同学,可能对WeakReference有印象,它表示当前对象为弱引用类型。
在 Java 中,对象有四种引用类型,分别是:强引用、软引用、弱引用和虚引用,级别从高依次到低。
不同引用类型的对象,GC 回收的方式也不一样,对于强引用类型,不会被垃圾收集器回收,即使当内存不足时,另可抛异常也不会主动回收,防止程序出现异常,通常我们自定义的类,初始化的对象都是强引用类型;对于软引用类型的对象,当不存在外部强引用的时候,GC 会在内存不足的时候,进行回收;对于弱引用类型的对象,当不存在外部强引用的时候,GC 扫描到时会进行回收;对于虚引用,GC 会在任何时候都可能进行回收。
下面我们看一个简单的示例,更容易直观的了解它。
public static void main(String[] args) {
Map weakHashMap = new WeakHashMap();
//向weakHashMap中添加4个元素
for (int i = 0; i < 3; i++) {
weakHashMap.put("key-"+i, "value-"+ i);
}
//输出添加的元素
System.out.println("数组长度:"+weakHashMap.size() + ",输出结果:" + weakHashMap);
//主动触发一次GC
System.gc();
//再输出添加的元素
System.out.println("数组长度:"+weakHashMap.size() + ",输出结果:" + weakHashMap);
}
输出结果:
数组长度:3,输出结果:{key-2=value-2, key-1=value-1, key-0=value-0}
数组长度:3,输出结果:{}
以上存储的弱引用对象,与外部对象没有强关联,当主动调用 GC 回收器的时候,再次查询WeakHashMap里面的数据的时候,弱引用对象收回,所以内容为空。其中WeakHashMap类底层使用的数据存储对象,也是继承了WeakReference。
采用WeakReference这种弱引用的方式,当不存在外部强引用的时候,就会被垃圾收集器自动回收掉,减小内存空间压力。
需要注意的是,Entry静态类中仅仅只是key被设计成弱引用类型,value依然是强引用类型。
回归正题,为什么ThreadLocalMap类中的Entry静态类中的key需要被设计成弱引用类型?
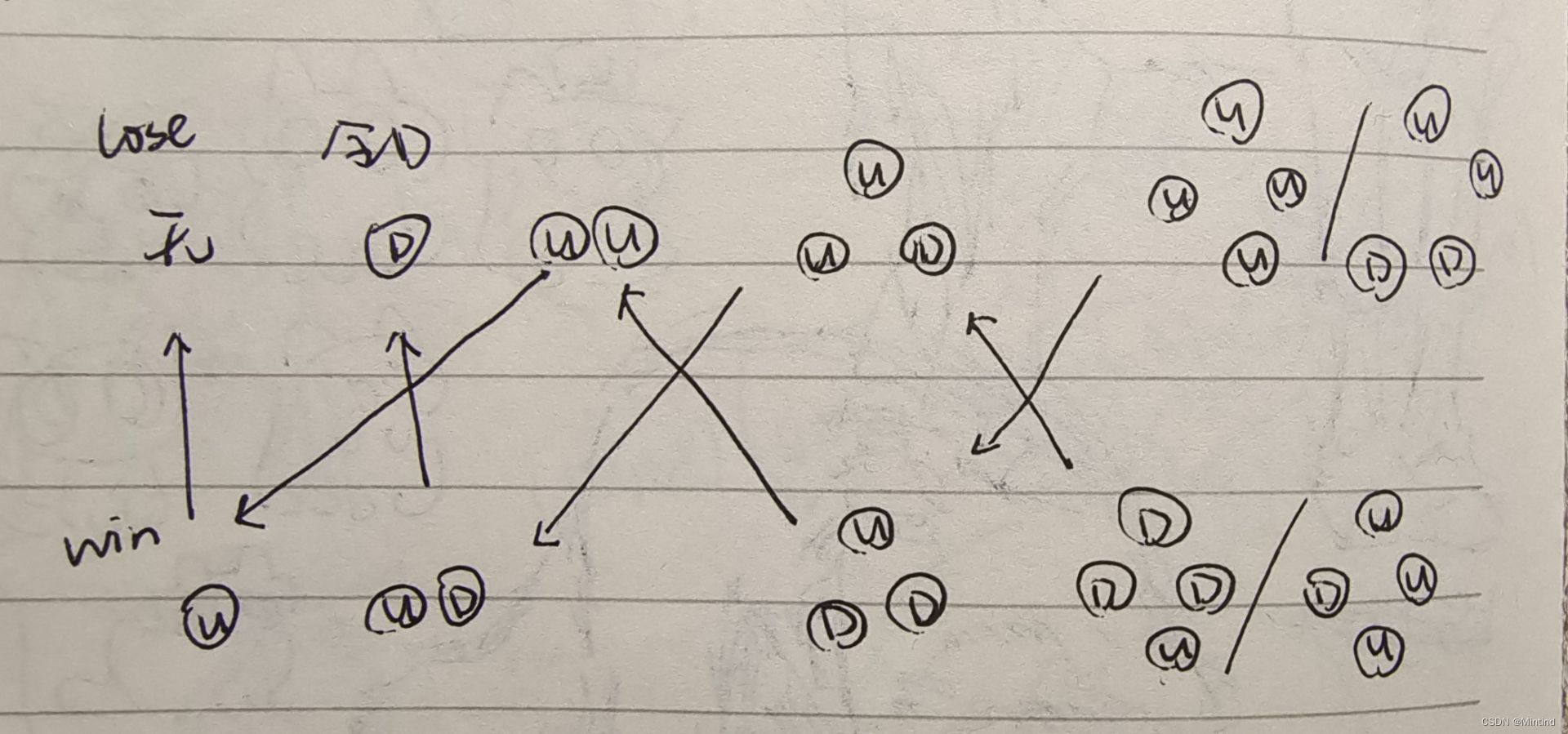
我们先看一张Entry对象的依赖图!
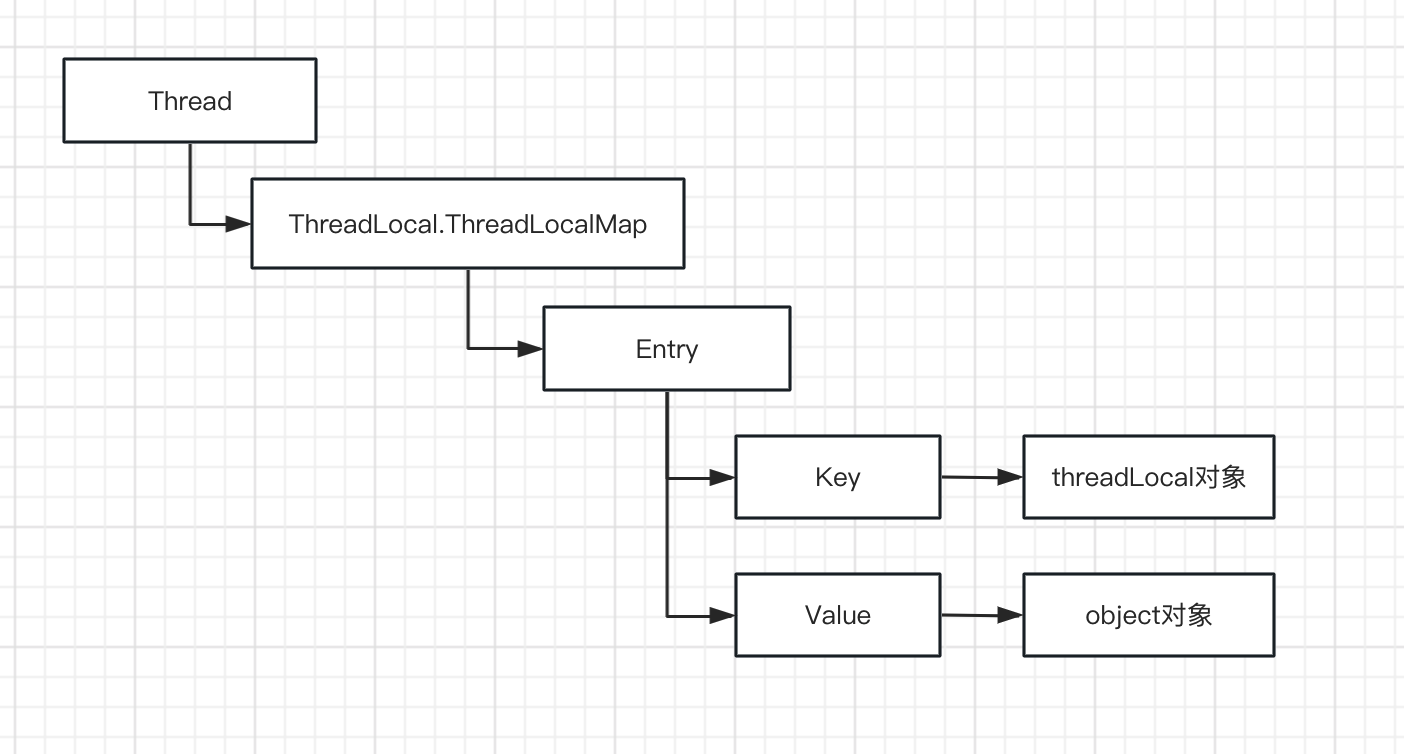
如上图所示,Entry持有ThreadLocal对象的引用,如果没有设置引用类型,这个引用链就全是强引用,当线程没有结束时,它持有的强引用,包括递归下去的所有强引用都不会被垃圾回收器回收;只有当线程生命周期结束时,才会被回收。
哪怕显式的设置threadLocal = null,它也无法被垃圾收集器回收,因为Entry和key存在强关联!
如果Entry中的key设置成弱引用,当threadLocal = null时,key就可以被垃圾收集器回收,进一步减少内存使用空间。
但是也仅仅只是回收key,不能回收value,如果这个线程运行时间非常长,又没有调用set()、get()或者remove()方法,随着线程数的增多可能会有内存溢出的风险。
因此在实际的使用中,想要彻底回收value,使用完之后可以显式调用一下remove()方法。
四、应用介绍
通过以上的源码分析,相信大家对ThreadLocal类已经有了一些认识,它主要的作用是在线程内实现变量的传递,每个线程只能看到自己设定的变量。
我们可以看一个简单的示例!
public static void main(String[] args) {
ThreadLocal threadLocal = new ThreadLocal();
threadLocal.set("main");
for (int i = 0; i < 5; i++) {
final int j = i;
new Thread(new Runnable() {
@Override
public void run() {
// 设置变量
threadLocal.set(String.valueOf(j));
// 获取设置的变量
System.out.println("thread name:" + Thread.currentThread().getName() + ", 内容:" + threadLocal.get());
}
}).start();
}
System.out.println("thread name:" + Thread.currentThread().getName() + ", 内容:" + threadLocal.get());
}
输出结果:
thread name:Thread-0, 内容:0
thread name:Thread-1, 内容:1
thread name:Thread-2, 内容:2
thread name:Thread-3, 内容:3
thread name:main, 内容:main
thread name:Thread-4, 内容:4
从运行结果上可以很清晰的看出,每个线程只能看到自己设置的变量,其它线程不可见。
ThreadLocal可以实现线程之间的数据隔离,在实际的业务开发中,使用非常广泛,例如文章开头介绍的HttpServletRequest参数的上下文传递。
五、小结
最后我们来总结一下,ThreadLocal类经常被叫做线程本地变量,它确保每个线程的ThreadLocal变量都是各自独立的,其它线程无法访问,实现线程之间数据隔离的效果。
ThreadLocal适合在一个线程的处理流程中实现参数上下文的传递,避免同一个参数在所有的方法中传递。
使用ThreadLocal时,如果当前线程中的变量已经使用完毕并且永久不在使用,推荐手动调用移除remove()方法,可以采用try ... finally结构,并在finally中清除变量,防止存在潜在的内存溢出风险。
![[redis] 说一说 redis 的底层数据结构](https://img-blog.csdnimg.cn/img_convert/77f443a14fc0321c2ca5200bf4e2af35.png)