Redis有动态字符串(sds)、链表(list)、字典(ht)、跳跃表(skiplist)、整数集合(intset)、压缩列表(ziplist) 等底层数据结构。
Redis并没有使用这些数据结构来直接实现键值对数据库,而是基于这些数据结构创建了一个对象系统,来表示所有的key-value。

文章目录
- 1.1 字符串
- 1.2 **链表linkedlist**
- 1.3 哈希表 hashtable
- 1.4 跳跃表skiplist
- 1.5 整数集合intset
- 1.6 压缩列表ziplist:压缩列表是为节约内存⽽开发的顺序性数据结构,它可以包含任意多个节点,每个节点可以保存⼀个字节数组或者整数值。
- 1.7 quicklist (3.2)
- 1.8 listpack (5.0)
我们常用的数据类型和编码对应的映射关系:

1.1 字符串
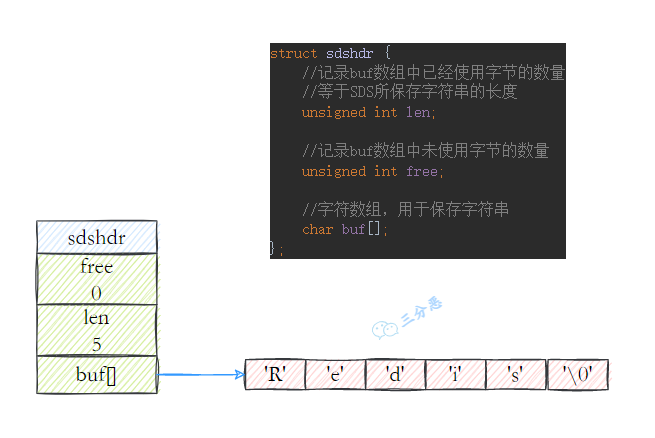
redis 没有直接使⽤ C 语⾔传统的字符串表示,⽽是⾃⼰实现的叫做简单动态字符串SDS的抽象类型。C 语⾔的字符串不记录⾃身的⻓度信息,⽽ SDS 则保存了⻓度信息,这样将获取字符串⻓度的时间由 O(N) 降低到了 O(1),同时可以避免缓冲区溢出和减少修改字符串⻓度时所需的内存重分配次数。
1.2 链表linkedlist
redis 链表是⼀个双向⽆环链表结构,每个链表的节点由⼀个 listNode 结构来表示,每个节点都有指向前置节点和后置节点的指针,同时表头节点的前置和表尾的后置节点都指向NULL。

1.3 哈希表 hashtable
一个哈希表里可以有多个哈希表节点,而每个哈希表节点就保存了字典里中的一个键值对。 每个字典带有两个hash表,供平时使⽤和 rehash 时使⽤,hash表使⽤链地址法来解决键冲突,被分配到同⼀个索引位置的多个键值对会形成⼀个单向链表,在对hash表进⾏扩容或者缩容的时候,为了服务的可⽤性,rehash的过程不是⼀次性完成的,⽽是渐进式的。 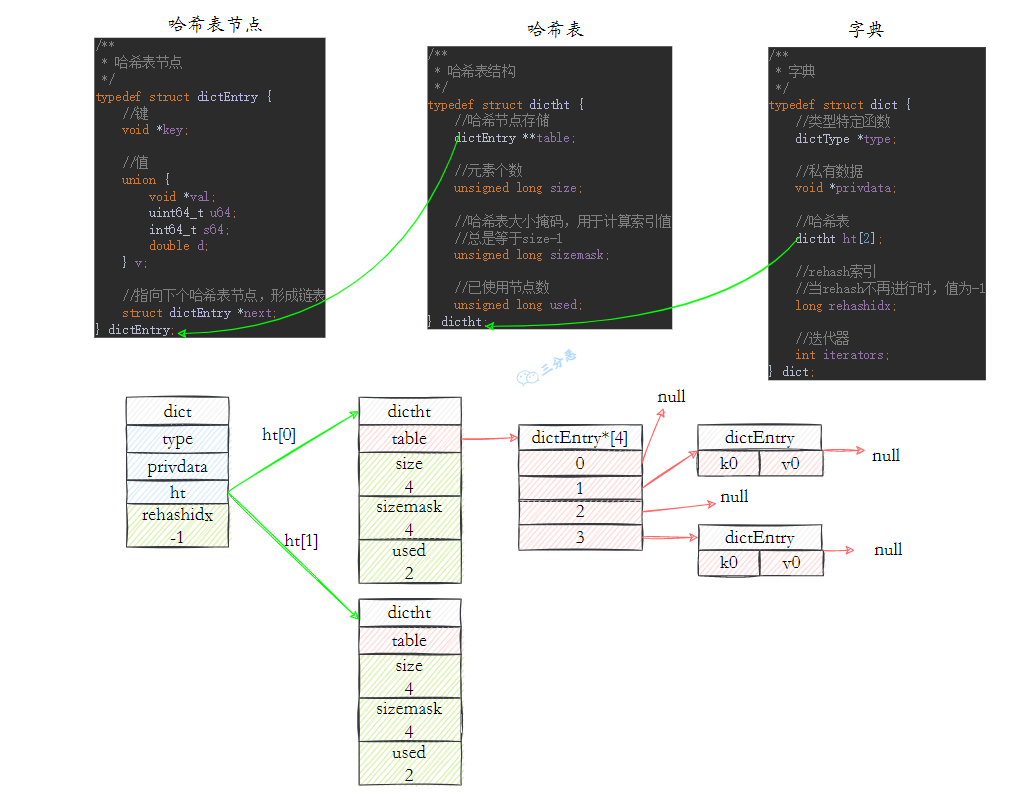
1.4 跳跃表skiplist
Redis跳跃表由 zskiplist 和 zskiplistNode 组成,zskiplist ⽤于保存跳跃表信息(表头、表尾节点、⻓度等),zskiplistNode ⽤于表示表跳跃节点,每个跳跃表节点的层⾼都是 1-32 的随机数,在同⼀个跳跃表中,多个节点可以包含相同的分值,但是每个节点的成员对象必须是唯⼀的,节点按照分值⼤⼩排序,如果分值相同,则按照成员对象的⼤⼩排序。 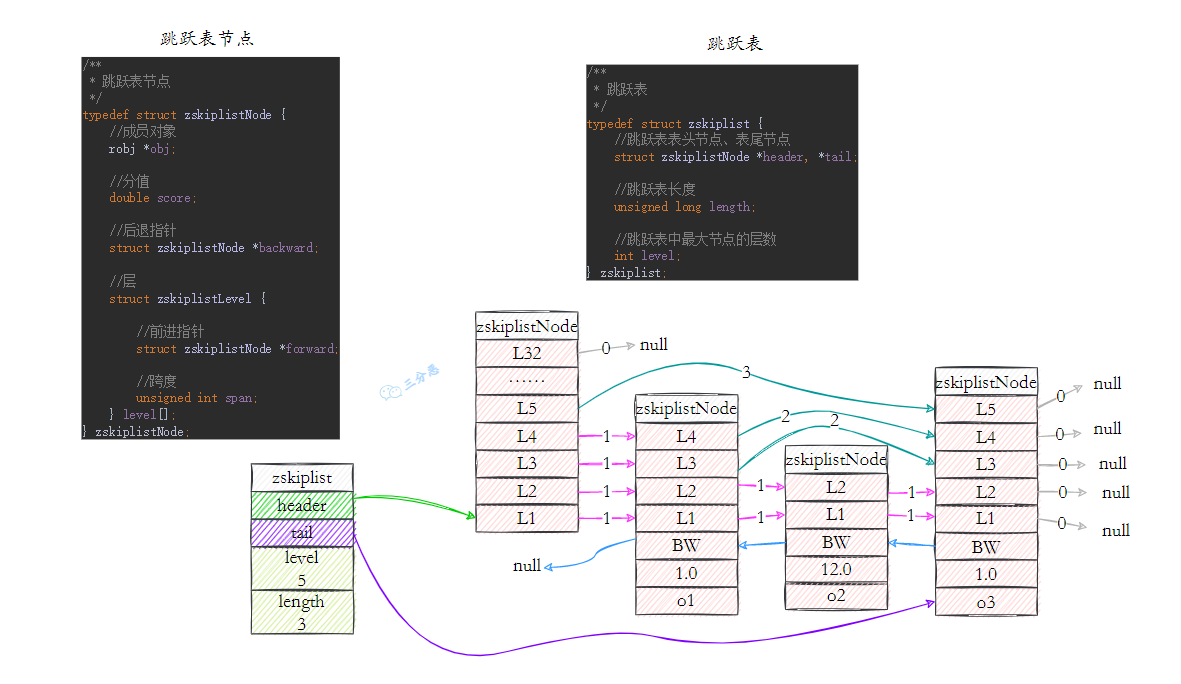
1.5 整数集合intset
⽤于保存整数值的集合抽象数据结构,不会出现重复元素,底层实现为数组。 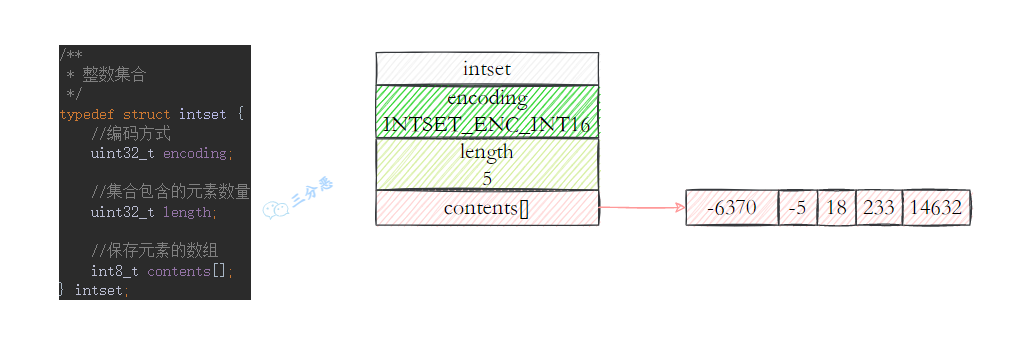
1.6 压缩列表ziplist:压缩列表是为节约内存⽽开发的顺序性数据结构,它可以包含任意多个节点,每个节点可以保存⼀个字节数组或者整数值。

1.7 quicklist (3.2)
https://github.com/redis/redis/blob/unstable/src/quicklist.h#L46
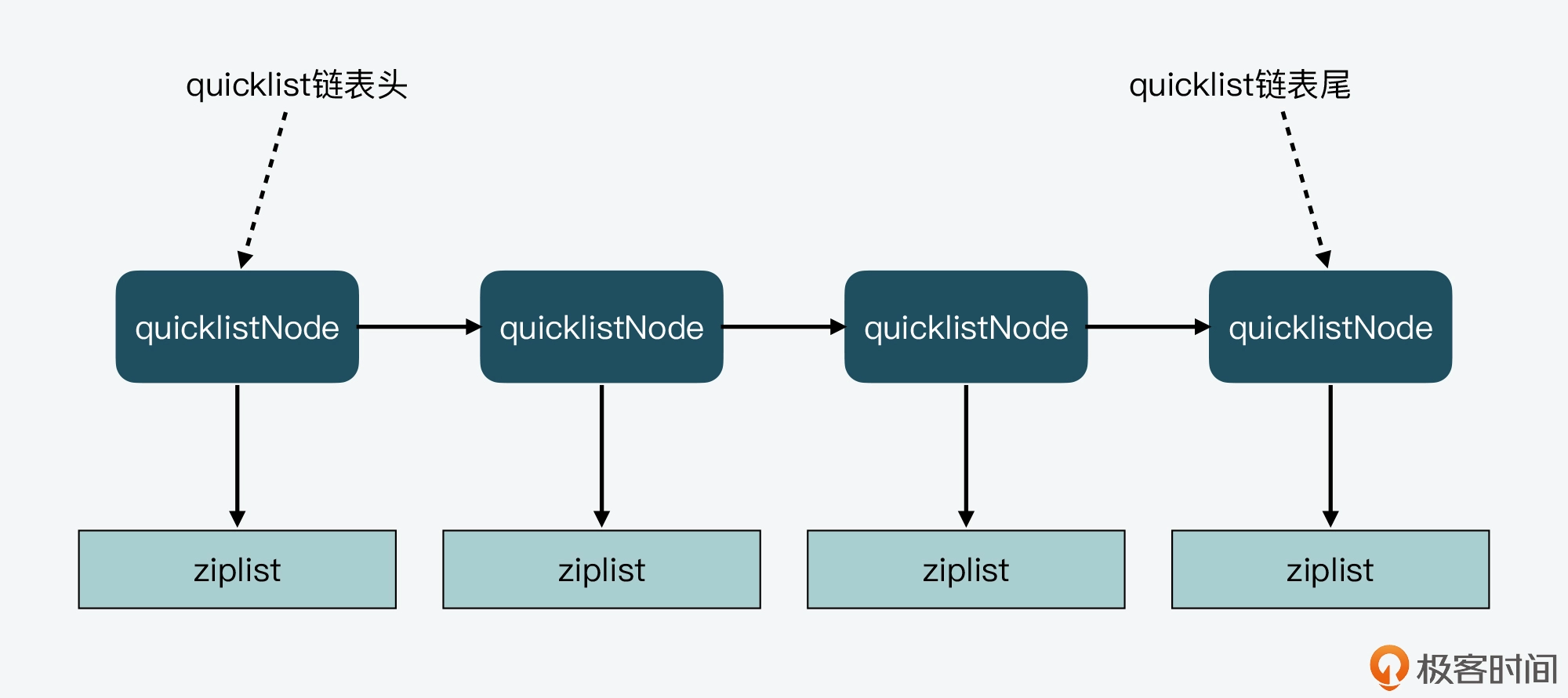
quicklist 的设计,其实是结合了链表和 ziplist 各自的优势。简单来说,一个 quicklist 就是一个链表,而链表中的每个元素又是一个 ziplist。
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklistEntry {
const quicklist *quicklist;
quicklistNode *node;
unsigned char *zi;
unsigned char *value;
long long longval;
unsigned int sz;
int offset;
} quicklistEntry;
- quicklist 是一个双向链表,head、tail分别指向头尾节点
- quicklistNode 是双向链表的节点,prev、next分别指向前驱、后继结点
- quicklistNode.zl 指向一个ziplist(或者quicklistLZF结构)
- quicklistEntry 包裹着list的每一个值,作为ziplist的一个节点
可以想象得到,当一个空的quicklist加入一个值value时,会有以下操作(不一定以这个顺序):
- 使用Entry包裹value
- 创建一个ziplist,把Entry加入到ziplist中
- 创建一个Node,Node.zl指向ziplist
- 创建quicklist,将Node加入quicklist中
1.8 listpack (5.0)
而 Redis 除了设计了 quicklist 结构来应对 ziplist 的问题以外,还在 5.0 版本中新增了 listpack 数据结构,用来彻底避免连锁更新。
listpack 也叫紧凑列表,它的特点就是用一块连续的内存空间来紧凑地保存数据,同时为了节省内存空间,listpack 列表项使用了多种编码方式,来表示不同长度的数据,这些数据包括整数和字符串。