23年12月,腾讯联合上海科技大学联合发布OMG:Towards Open-vocabulary Motion Generation via Mixture of Controllers,从零样本开放词汇文本提示中生成引人注目的动作。这款控制器关键思想是将 pretrain-then-finetune 范式运用到文本-运动的生成中,主要贡献是扩大了模型和数据集大小,以及引入motion ControlNet和混合控制MoC块,有效地将文本提示CLIP令牌嵌入与各种紧凑和富有表现力的运动特征对齐。
与之同期工作的MotionCtrl控制器,由腾讯联合香港大学、上海AI实验室、清华大学等机构共同推出,它能够独立地控制视频中的相机运动和物体运动视角,可以与潜在视频扩散模型协同工作,以实现对生成视频中运动视角的精确控制。
Abstract
最近看到在逼真的文本到运动生成方面取得了巨大进展。然而,现有的方法经常失败,或者使用没见过的文本输入产生难以置信的运动,这限制了应用推广。在本文中,我们提出了 OMG,这是一个新颖框架,可以从零样本开放词汇文本提示中生成引人注目的运动。我们的关键思想是将 pretrain-then-finetune 范式仔细调整到文本-运动的生成中。在预训练阶段,我们的模型通过学习丰富的域外固有运动特征来提高生成能力。为此,我们将大型无条件扩散模型扩展到 1B 参数,以便利用多达 20M 个运动实例的大规模未标记运动数据。在随后的微调阶段,我们引入了运动 ControlNet,它通过预训练模型的可训练副本和提出的新型混合控制 (MoC) 块,将文本提示合并为条件信息。MoC块利用交叉注意力机制自适应地识别各种范围的子运动,并与text-token-specific专家单独处理它们。这样的设计有效地将文本提示CLIP令牌嵌入与各种紧凑和富有表现力的运动特征对齐。大量实验表明,我们的 OMG 在零样本文本到运动生成方面优于最先进的方法。
1. Introduction
生成人类角色的生动运动是计算机视觉中一项长期的任务,在电影、游戏、机器人和 VR/AR 有着广泛的应用。文本到运动的设置旨在使新手的运动生成民主化,最近受到了实质性关注。得益于现有的文本标注运动数据集。
- Generating Diverse and Natural 3D Human Motions from Text
- AMASS: Archive of Motion Capture as Surface Shapes
最新的进展从文本提示生成了不同运动,配备各种生成模型,如VAEs、自回归模型和扩散模型。然而,这些方法严重依赖标注有限的配对文本运动数据,因此无法泛化到没见过的开放词汇文本输入。想象一下生成“Golum breakance footwork”,它需要具有丰富人类知识的域外生成能力来理解各种单词的运动特征,如角色(咕噜Gollum、忍者ninja)或技能(霹雳舞breakdance、旋转踢spinkick)。为了解决开放词汇文本,最近的工作利用大规模预训练模型(例如 CLIP )的零样本文本图像对齐能力。
- Make-An-Animation: Large-Scale Text-conditional 3D Human Motion Generation
- AvatarCLlP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
- Being Comes from Not-being: Open-vocabulary Text-to-Motion Generation with Wordless Training
他们采用文本姿势对齐,从而消除了对成对文本和连续运动的依赖。然而,离散姿态不足以表示丰富的运动特征,导致运动生成不逼真。另一方面,最近的进展即使在开放词汇文本输入中也能实现令人印象深刻的可控文本驱动图像甚至视频生成。
- Video generation models as world simulators ###大名鼎鼎的Sora论文
- AnimateDiff: Animate Your Personalized Text-to-lmage Diffusion Models without Specific Tuning
- High-Resolution lmage Synthesis with Latent Diffusion Models
- Adding Conditional Control to Text-to-lmage Diffusion Models
重新审视它们的巨大成功,pretrain-then-finetune 范式以及扩大模型发挥了重要作用。然而,采用这些文本到运动生成的策略具有挑战性。首先,未配对运动数据量和配对文本运动数据之间存在巨大不平衡。其次,对于开放词汇文本,对应于各种运动特征的各种token,构成了一个复杂的多对多问题。
为了应对这些挑战,我们提出了 OMG——一种新颖的方案,用于从开放词汇文本中生成人类特征的运动(见图 1)。
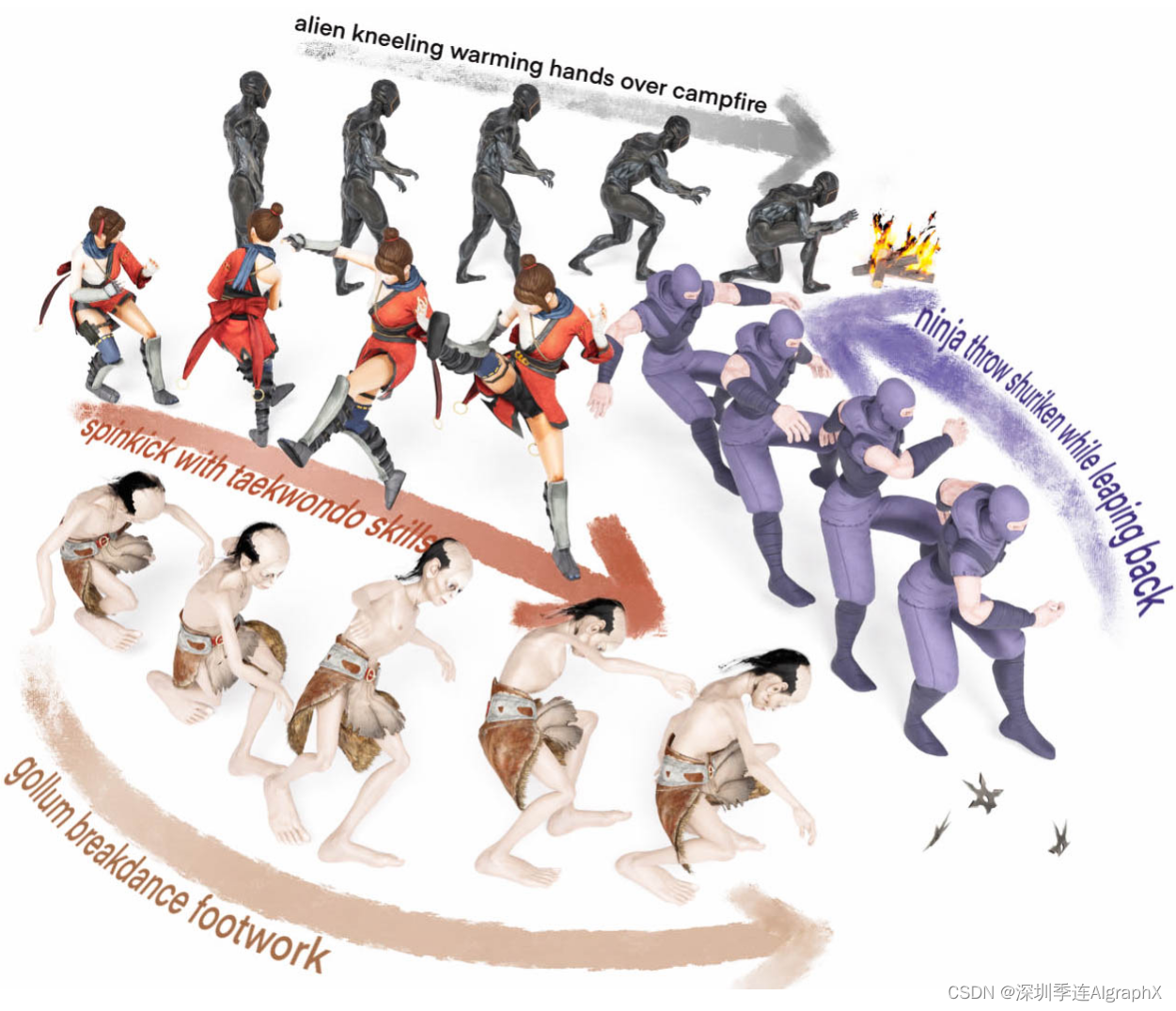
我们的关键思想是将预训练然后微调范式定制为文本到运动的生成。对于预训练,我们采用最小设计来扩展大型无条件扩散模型,以利用大量未标注运动数据。对于微调,我们首先冻结预训练的大型模型。然后采用可训练的副本,并通过一种新的设计(称为混合控制器)将文本提示视为额外的条件,以学习预测条件残差。它自适应地融合输入文本提示各种token的运动特征,以处理文本和运动模态之间的歧义。
具体而言,在预训练阶段,我们采用具有过参数化over parameterized运动表示的扩散transformer作为骨架。然后,我们使用从88M到1B的参数放大模型,利用来自13个公开可用数据集的2000多万个未标注运动实例。在训练过程中,我们还采用了滑动随机窗口策略来裁剪各种运动序列,以提高对任意长度运动的生成能力。为此,预训练模型利用大的运动流形学习丰富的固有运动特征,以确保生成运动的真实性。
在接下来的阶段,为了将文本提示作为条件信息,我们采用了一种称为运动ControlNet的微调方案,类似于著名的文本图像生成任务的ControlNet。它包括大规模预训练模型的可训练副本,作为保留运动特征的强大骨干,以及一个名为混合控制器(MoC)的新块。基于运动特征和基于CLIP的文本嵌入,这种MoC块可以有效地将残差信息注入到预训练的模型中。我们在MoC块中的关键设计是文本和运动之间的交叉注意力 cross-attention 机制,以及 text-token-specific Mixture-of Experts,这些将在后面的章节中详细介绍。这样的设计有效地将文本提示 token embeddings 与各种紧凑和富有表现力的运动特征对齐,这些运动特征是由强大的预训练模型预热的。因此,我们的OMG方法从开放词汇文本中实现了令人信服的生成,显著优于现有技术。特别是,仅在HumanML3D数据集上进行微调,它就可以从Mixamo数据集中生成具有不同运动技能的各种人物的生动运动,如图 1 所示。
总而言之,我们的主要贡献包括:
- 我们提出了一种具有预训练然后微调范式的文本到运动生成方法,以扩大数据和模型,实现了最先进的零样本性能。
- 通过实验证明,在大规模未标注运动数据上进行预训练可以提高来自不同和开放词汇文本的生成结果。
- 我们提出了一种文本调节的微调方案,利用混合控制器来有效地改善文本和运动之间的对齐。
2. Related Work
Conditional Motion Synthesis
条件运动合成能够根据各种类型的条件生成逼真的、上下文相关的运动序列,在运动生成领域受到越来越多的关注。常见的条件类型包括文本、动作、音乐、语音、控制信号、动作标签、不完整的动作序列、图像和场景。扩散模型的出现对文本驱动的运动合成有很大的提升。FLAME是一个基于transformer扩散模型,该模型可以生成和编辑与给定文本很好对齐的运动。运动扩散模型MDM结合了运动生成领域已经建立的见解,在每个扩散步骤中预测样本而不是噪声。基于运动潜扩散模型MLD在潜空间上执行扩散过程。除了扩散模型之外,T2M-GPT 还研究了一种结合 VQ-VAE 和自回归模型的框架。然而,由于这些模型仅基于成对的文本运动数据集进行训练,例如 HumanML3D,因此它们不能很好地处理没见过的文本提示。
Open-vocabulary Generation
零样本文本驱动生成不依赖于预先存在的数据,而是利用训练期间学习的一般知识从文本提示创建新内容。Reed等人使用DC-GAN架构来引导零样本文本到图像合成。CLIP在4亿图像-文本对上进行预训练,具有有效理解、生成与文本之间有意义关联图像的显著能力。随着CLIP强大的能力,许多工作能够生成高质量的零样本文本驱动图像或3D对象。在运动合成领域,一些工作试图研究开放词汇文本到运动的生成,并取得了良好的效果。MotionCLIP利用解码器解码CLIP运动嵌入。AvatarCLIP合成一个关键姿态,然后从数据库中检索最近的运动。[Being Comes from Not-being: Open-vocabulary Text-to-Motion Generation with Wordless Training] 预训练运动生成器,学习从具有关键姿势的掩码运动重建完整的运动。Make-An-Animation 预训练具有不同开放领域文本-姿势对生成模型。然而,由于这些方法基于文本姿态对齐,由于缺乏全局旋转和平移,生成的运动缺乏真实感。最近,MotionGPT 使用运动和文本数据预训练和微调大型语言模型。然而,它仍然很难从开放词汇文本提示生成新的运动。
Mixture-of-Experts
在深度学习领域,神经网络架构中的混合专家模型 (MoE) 将特定的模型参数分成不同的组,称为“专家”。
[Learning Factored Representations in a Deep Mixture of Experts ] 在多层网络的每一层使用不同的门控网络,通过在每一层的不同专家组合引入指数数量的路径来增加有效专家的数量。将整个模型视为专家的其他研究也取得了良好的结果。此外,FastMoE、GShard正在努力提高MoE框架内的训练和推理速度。
MoE范式不仅适用于语言处理任务,还适用于视觉模型、多模态transformer中的模态专家混合以及运动合成。
Holden等人开发了phase-functioned 专家,通过预定义的混合权重来混合以控制特定阶段的特征;也有用门控网络来预测混合权重,实现了令人印象深刻的角色控制结果。受它们的启发,我们设计了 text-token-specific 专家来控制相应的子运动。
3. Methods
我们的目标是生成逼真、多变的人体运动视频,这些人体动作以文本提示为条件,捕捉复杂和抽象的运动特征,具有零样本开放词汇描述。
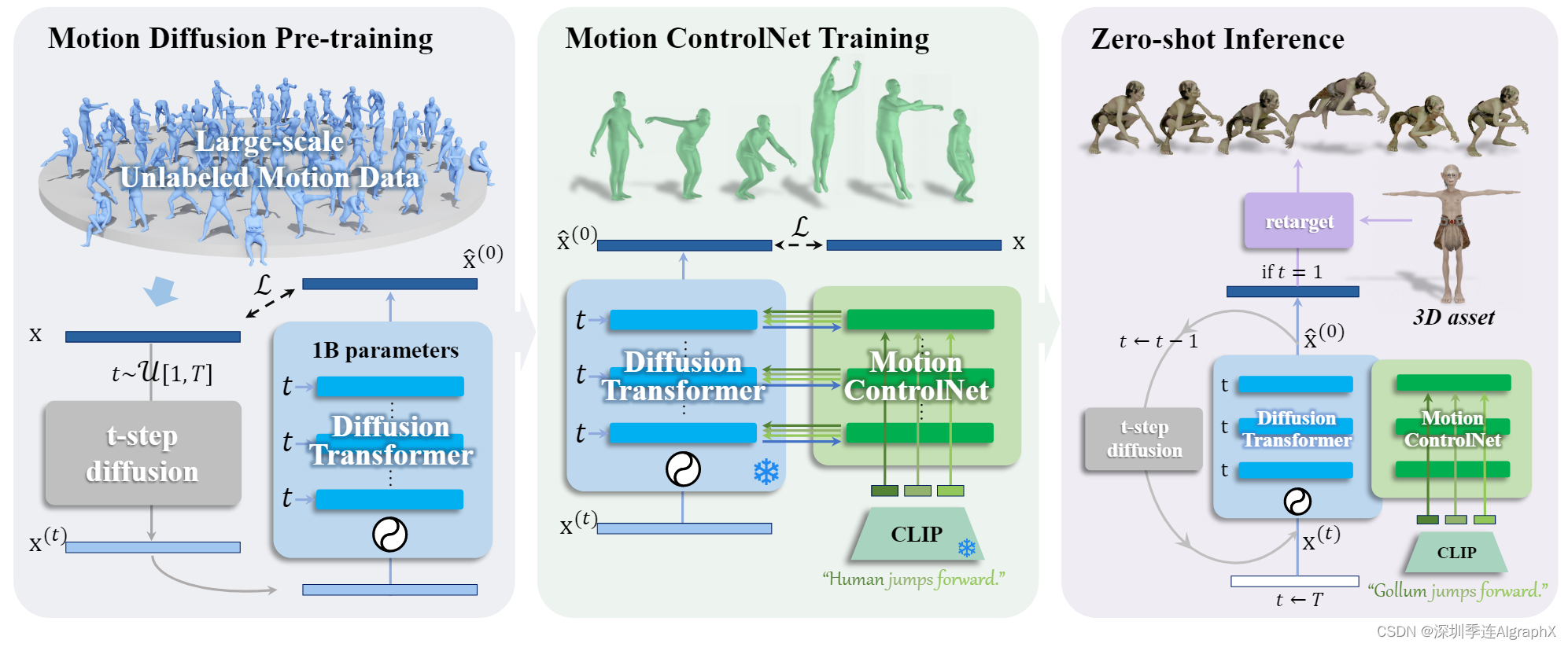
为此,我们采用 pretrain-then-finetune 范式来增强模型的能力。对于无条件降噪器(图 2 左),我们利用大规模未标注运动数据集进行运动扩散预训练并扩大模型大小(第 3.1 节)。对于条件降噪器(图 2 中间),我们设计了一种称为运动 ControlNet 的特定条件微调方案,包括一种称为混合控制器的新型条件设计,以利用 CLIP 文本嵌入的零样本能力(第 3.2 节)。在推理过程中(图 2 右),我们进一步使用无分类器指导来组合无条件去噪和条件去噪。
3.1. Motion Diffusion Pre-training
Large-scale Unlabeled Motion Dataset
为了便于运动域中的大规模预训练,我们收集了大量高质量的人体运动数据,这些数据来自各种来源的 20M 帧,如角色动画数据集、基于标志、基于 IMU 和多视图无标记动作捕捉数据集。然后,我们使用现成的重新定位算法将帧速率标准化,并将它们重新定位到SMPL身体模型统一参数骨架上。之后,按照之前成功的运动生成工作,我们使用过参数化over-parameterized运动表示来丰富SMPL骨架,以促进网络学习。
Model Scaling Up
我们设计了具有简约性的预训练扩散模型,只保留可扩展和高效的基本模块以适应扩展数据。为此,我们采用 Diffusion Transformer (DiT) 架构作为我们的网络主干,因为它在增加输入token和训练数据时的可扩展性和令人印象深刻的性能。唯一的区别是我们使用旋转位置嵌入来鼓励模型捕获帧之间的相对时间关系。为了研究性能对模型大小的依赖性,我们训练了 4 个不同大小的 OMG 模型,范围从 8800 万个参数到 10 亿个参数。
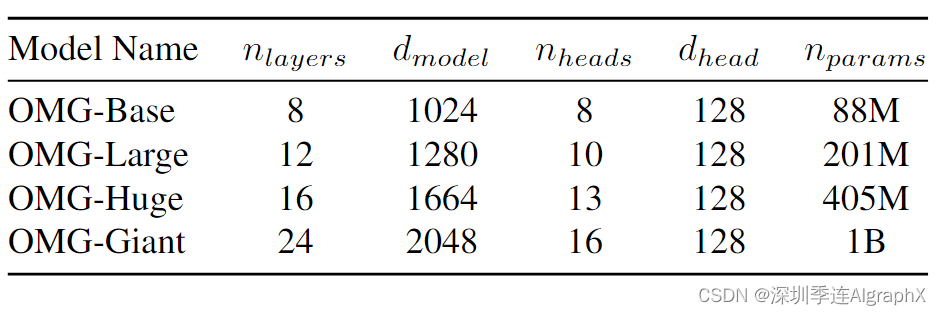
表 1 显示了我们 4 个模型的配置细节。这里nlayers层的总数,dmodel 是每个bottleneck层中的单元数,dhead 是每个注意力头的维度,nparams 是可训练参数的总数。
Training
我们用简单的目标训练无条件去噪Du,来预测给定扩散时间步长 t 的干净运动 ˆx(0):
![]()
其中 ,是 t 步噪声运动,噪声
∼ N(0,I),λt是损失加权因子。此外,我们引入了几何损失,类似于MDM,它包含速度损失Lvel和foot contact loss Lfoot来加强物理性质和反滑动。总体而言,无条件降噪器 Du 使用以下目标进行训练:
![]()
在我们的实验中,λvel = 30 和 λfoot = 30。采用余弦噪声水平时间表,扩散时间步 T 数量设置为 1,000。我们使用权重衰减为 0 的 AdamW 优化器训练所有大小为 256 的 1M 次迭代的模型,最大学习率为 10−4,余弦 LR 时间表具有 10K 线性预热步骤。模型在8 个 NVIDIA A100 GPU上,使用 ZeRO 内存冗余策略的 Pytorch 训练。最大的模型 OMG-G 需要 1500 个 GPU 小时进行预训练。
Sliding Random Windows
在训练过程中,我们提出了滑动窗口,迭代运动数据集中的每个运动状态帧xi,以从xi开始采样运动序列。具体来说,对于第 i 帧,我们使用随机窗口 [i, i + l) 随机裁剪长度为 的子序列 x,其中
∼ U[1, L] 是一个均匀变量,L 是决定我们模型的生成运动序列的最大长度的超参数。这推动模型学习单个运动状态的时间帧和空间特征之间的关系,以处理任意长度的运动,甚至是单个关键帧,以便于后续对任意长度的子运动进行细粒度控制。在我们的实验中,为了平衡分辨率和持续时间,将滑动窗口的最大长度 L 设置为 300,帧速率设置为 30。
3.2. Motion ControlNet
为了将文本提示 合并到预训练的运动模型中,我们采用微调方案,我们称之运动 ControlNet 来调节文本提示,灵感来自图像 ControlNet,包括原始transformer层的可训练副本和称为混合控制器 (MoC) 提出的调节块。
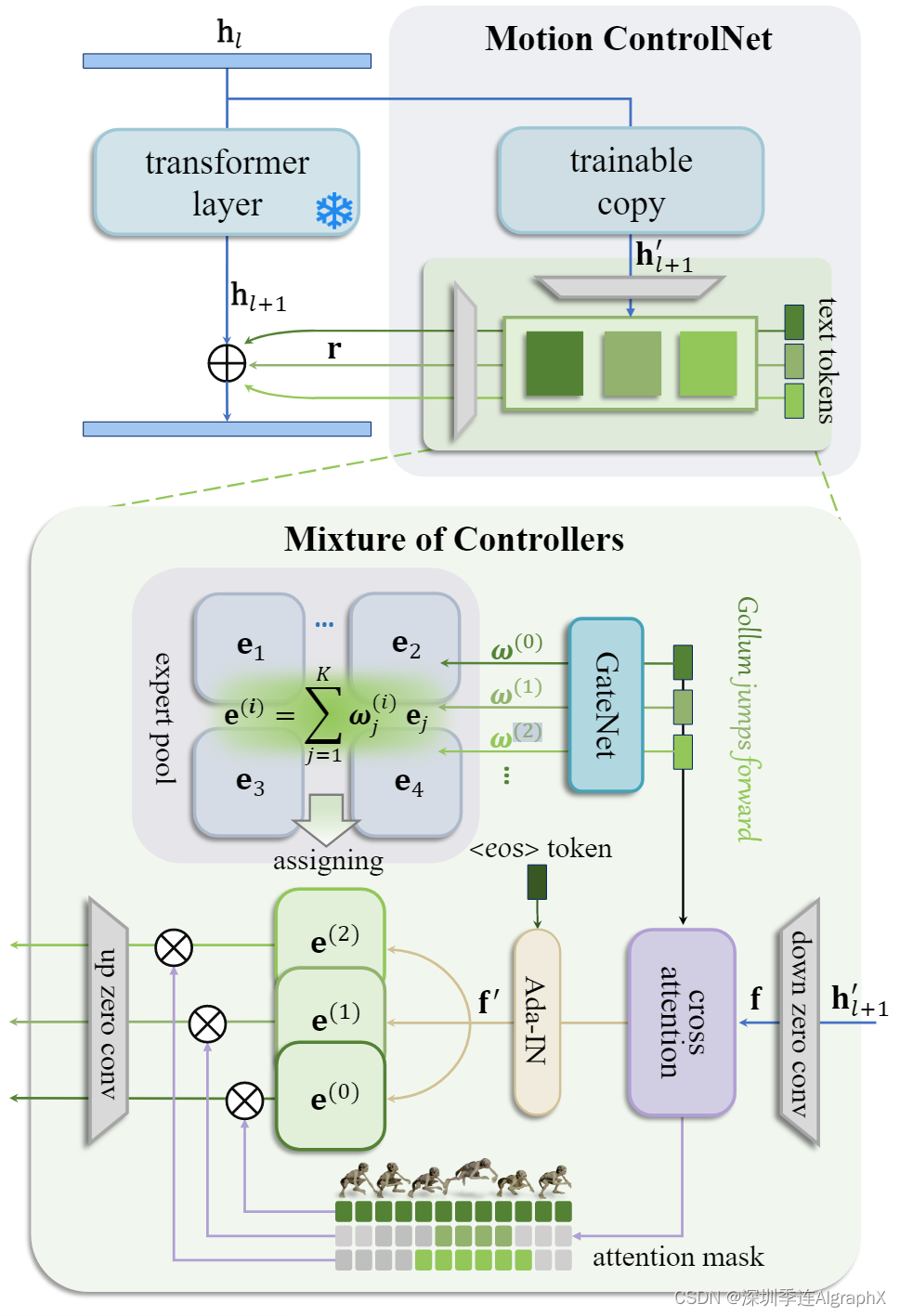
图 3. Motion ControlNet(顶部)冻结预训练 Transformer 层的参数,并将层的可训练副本与所提出的混合控制器(底部)块相结合。MoC块首先融合文本特征和运动特征,同时通过交叉注意机制确定每个文本token的子运动范围。然后它使用特定于文本token的专家对子运动进行细粒度控制。
如图 3 所示,我们冻结了预训练的 Transformer 层的参数,并将层的可训练副本与 MoC 块相结合,该块将对应于 n 个文本token的 n 个残差注入到原始 transformer 层的输出中。具体来说,冻结的参数保留了预训练的去噪能力,而可训练副本重用大规模预训练模型作为一个强大的初始主干,学习从最后一层中间表示 中提取语义运动特征。在此基础上,利用MoC块对n个文本token对应的n个条件残差 r 进行预测,然后将所有条件残差 r 添加到原始输出
中。为此,使用预先训练的CLIP文本编码器
来提取文本 token embeddings。
Mixture-of-Controllers
在 Mixture-of-Controllers 块中(图 3 底部),我们的关键思想是以 MoE 方式使用不同的专家控制器分别控制子动作序列,以便更好地将它们与 CLIP 空间中的相应文本token embedding对齐。例如,对于给定的文本提示“Gollum jumps forward”,“Gollum” token对应于整个序列,而“jumps”仅对应于他跳跃时的子序列。
为此,我们引入了两种合作设计。第一个是交叉注意机制来融合文本特征和运动特征,同时确定每个文本标记的子运动范围。第二个是从专家池中选择 text-token-specific专家来执行子运动的细粒度控制。


此外,使用下投影和上投影1-D卷积对分别处理输入和输出,以减少控制的潜在维度,从而减少可训练参数。此外,与图像ControlNet类似,我们使用零初始化卷积参数来保护可训练副本在初始训练步骤中的有害梯度噪声。
Training and Inference
条件降噪器 Dc 也使用与运动 ControlNet 中的可训练参数相同的目标 L (Eq. (2)) 进行训练。在我们的实验中,使用冻结的 CLIP-VIT-L/14 文本编码器在维度为 dc = 768 的最后一层归一化中提取文本嵌入,并以最大令牌数 77 截断文本标记。我们将 MoC 块的向下投影潜在维度 dm 设置为 256,专家池大小 K = 12,注意掩码锐度 γ = 24,阈值 β = 0.25。我们使用权重衰减为 的 AdamW 优化器训练所有 500 个 epoch 的运动 ControlNets,最大学习率为
,余弦 LR 时间表设置为 1K 线性预热步骤。在训练过程中,我们以 50% 的概率将 〈eos〉 标记随机替换为空标记,以增加捕获文本标记中的全局语义作为替换的能力。
在推理过程中,使用无分类器指导来组合无条件降噪器和条件降噪器:
![]()
在我们的实验中,采用了具有 200 个时间步长的 DDIM 采样策略,引导强度 s = 4.5。
4. Experiments

在给出各种没见过的文本提示的情况下,我们的模型生成的定性结果。我们的模型有效地捕捉了单个短语或较长自然句子的运动特征。
4.1. Datasets and Evaluation
Metrics Training Datasets
在预训练阶段,我们利用各种公开可用的人体运动数据集,如artist-created datasets , marker-based , IMU-based and multi-view markerless motion capture datasets,总计超过2000万帧。在随后的条件微调阶段,我们使用文本运动HumanML3D数据集训练我们的motion ControlNet,以便与以前的方法进行公平比较。
Evaluation Datasets
我们在两个基准上进行了测试,HumanML3D和Mixamo测试集。HumanML3D测试集用于评估域内性能。Mixamo数据集由丰富的艺术家创作的动画和人文描述组成,提供了多种多样的动态运动,用于比较各个领域的零样本性能。
Evaluation Metrics
概括为四个部分。1) Frechet Inception Distance(FID)是我们评估生成运动和真实运动之间特征分布的主要指标。2) 运动检索精度(R-precision)计算特征空间下的文本和运动Top 3匹配精度。3) CLIP得分。借鉴文本到图像合成,我们使用CLIP评分通过测量CLIP空间中的余弦相似性来评估零样本文本运动一致性。为此,我们使用HumanML3D和Mixamo的训练集来训练运动编码器,以提取与CLIP空间中的文本嵌入对齐的运动特征。4) 通过计算特征方差来评估多样性。
4.2. Comparison
与各种方法比较,具体来说,应用了条件运动扩散模型,包括MDM、MLD、MotionDiffuse、基于VAE的模型MotionCLIP和自回归模型T2M-GPT。此外,我们还应用了基于文本姿势对齐方法的MAA和利用运动语言预训练的MotionGPT。HumanML3D上的一些结果是从他们自己的论文中借来的。定量结果如表2所示。
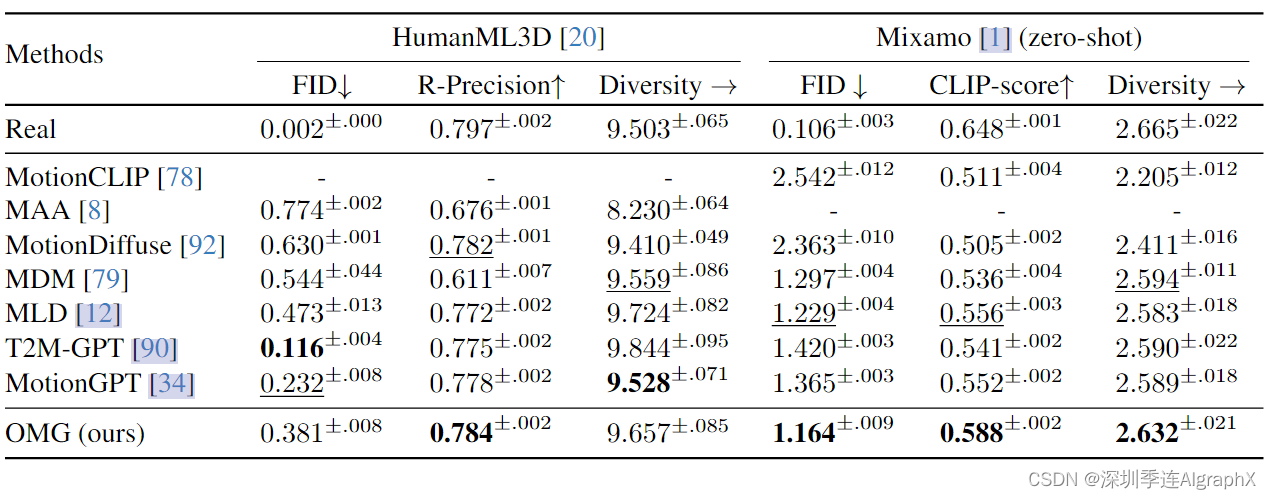
我们的方法展示了域内评估中最好的文本到运动对齐(R-Precision)。此外,在所有基于扩散的方法中,我们的模型实现了最好的FID。就零样本性能而言,我们的方法获得了最好的FID和CLIP分数,优于以前的方法。这表明了高质量运动生成的卓越能力,以及与零样本文本提示的有效匹配。

我们的模型证明了生成运动的能力,无论是在句子还是短语中,这些运动都更真实,与每个运动特征描述更好地一致。
4.3. Ablation Study
Effect of Pre-training and Model Scale、Expert Pool Size

图 6. 对预培训、模型规模和专家库规模进行定量评估。(a) 与无预训练相比,带预训练的模型表现出持续改进的性能,并且受益于大规模运动数据的带预训练模型随着模型大小的增加而改进。(b) 更大的专家库大小可以提高性能。
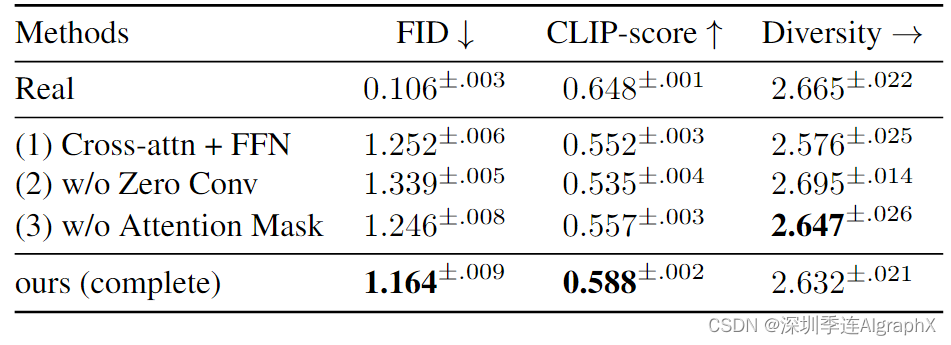
表 3. MoC块体的定量评价。模型三种变体的阻尼性能突出了MoC块技术设计的有效性。
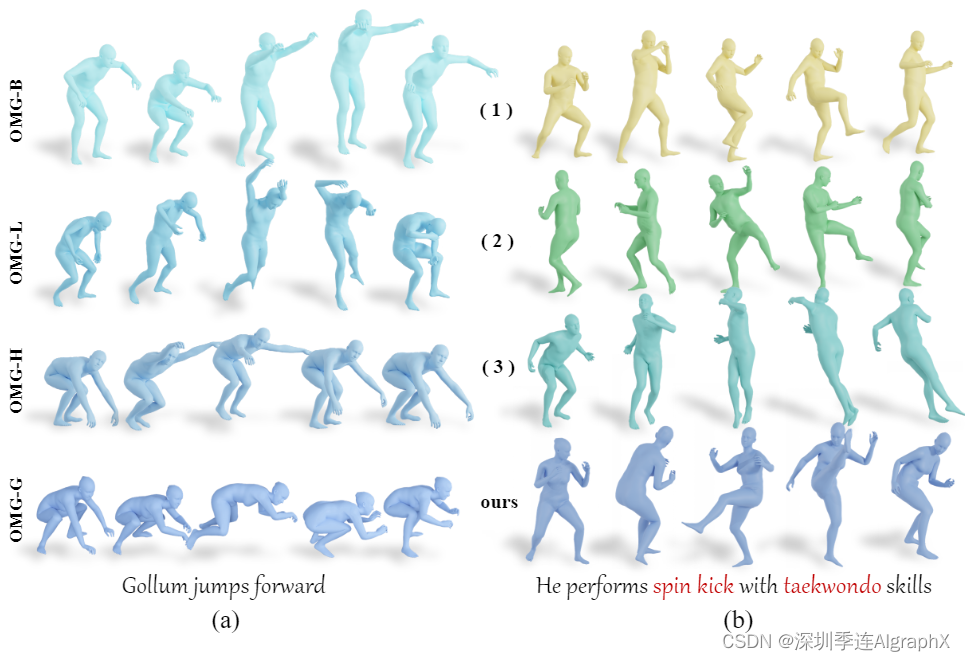
图 7. 对模型尺寸(a)和MoC区块(b)的定性评估。具有较大尺寸的模型有效地理解更丰富的域外运动特征,以呈现更好的运动表达式。此外,我们的技术设计有效地提高了与输入文本的一致性。
5. Conclusion
在本文中,我们提出了一种新颖的文本到运动生成框架OMG,它结合了条件生成模型和文本姿势对齐方法的优点。它仔细地将预训练微调范式定制为文本到运动的生成。预训练阶段利用大量未标记的运动数据来训练一个强大的无条件扩散模型,以确保生成运动的真实性和多样性。微调阶段引入了运动控制网络ControlNet,包括称为混合控制器MoC的新文本条件块。通过交叉注意机制和文本标记特定的专家,它以MoE的方式自适应地将子运动特征与CLIP空间中的文本嵌入对齐。大量实验表明,OMG在文本到运动生成方面实现了最先进的零样本性能。我们相信这是人类角色开放词汇运动生成的重要一步,在电影、游戏、机器人和 VR/AR 中有着广泛的应用。
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删。文中如有错误的地方,也请在留言区告知。
OMG-https://arxiv.org/abs/2312.08985
OMG: Towards Open-vocabulary Motion Generation via Mixture of Controllers
人体运动综述-https://arxiv.org/abs/2307.10894
![解决Pyppeteer下载chromium慢或者失败的问题[INFO] Starting Chromium download.](https://img-blog.csdnimg.cn/direct/8068d2b209ea41a98c08e9a2888e0079.png)




![[leetcode] 67. 二进制求和](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)