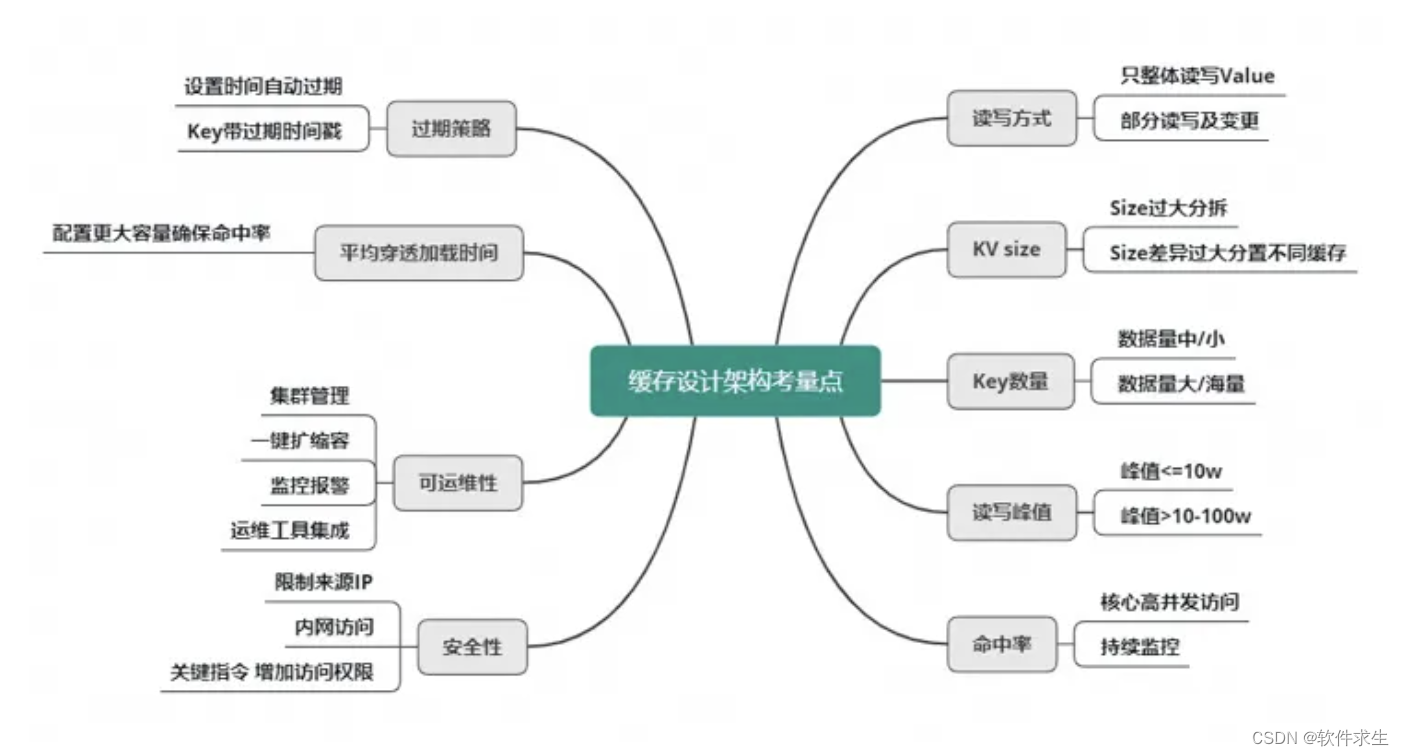
在inter-studio平台上,下载模型,体验lmdeploy
下载模型
这里是因为平台上已经有了internlm2模型,所以建立一个符号链接指向它,没有重新下载
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/
如果是在自己的机子上,可以通过git clone的方式下载原模型。
主目录下多了一个模型

使用huggingface库来体验模型推理
- 导入分词器和模型(通过float16格式加载,节省显存)
- 将模型设置为eval模式,避免参数更新
- 通过模型的chat格式进行聊天
- 计算各模块所耗费的时间
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
tokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model_load_time_start = time.time()
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()
model_load_time_end = time.time()
inp = "hello"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=[])
print("[OUTPUT]", response)
inference1_end = time.time()
inp = "please provide three suggestions about communicate with my dog"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=history)
print("[OUTPUT]", response)
inference2_end = time.time()
print("模型加载时长",model_load_time_end - model_load_time_start)
print("第一次推理耗费时长", inference1_end - model_load_time_end)
print("第二次推理耗费时长", inference2_end - inference1_end)
执行如下:
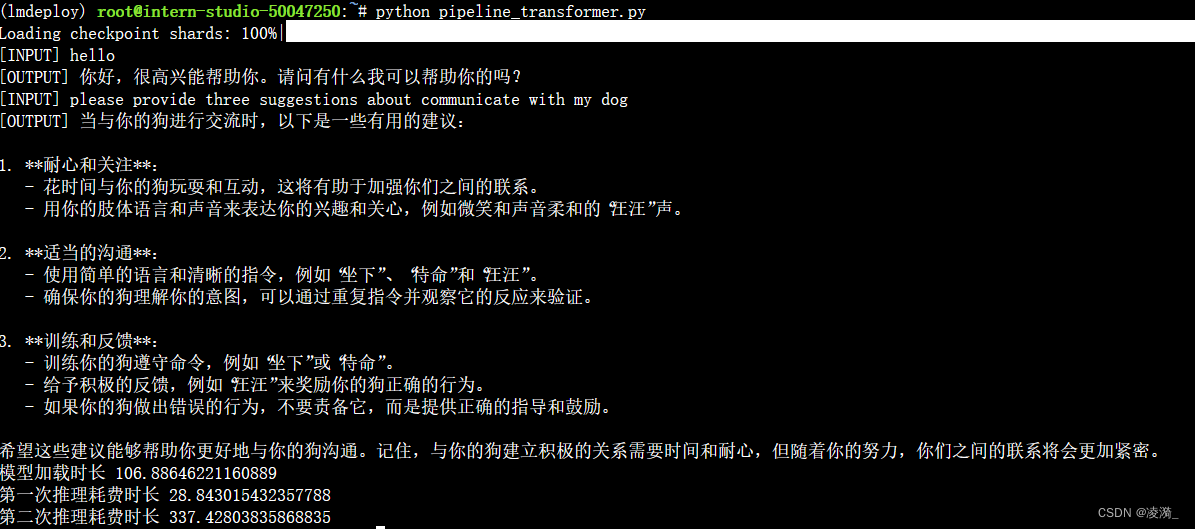
不知道为什么,怎么会要这么久啊…
使用lmdeploy进行推理
lmdeploy chat + 模型路径即可
需要注意的是,lmdeploy推理需要TurboMind格式的模型,但是它会自动将hf格式转换为turboMind格式,我们不需要管
lmdeploy chat /root/internlm2-chat-1_8b

这个推理非常快速,基本上是秒回,不知道这个推理框架背后是怎么做到的。
有采取kv8和W4A16的量化技术。
显存占用的来源有三部分:模型本身,kv cache,以及中间计算结果
kv cache是存储键值对方便复用,理想状态下全都放在显存里,但是如果显存不够的话,可以放在内存里,把需要的部分移动到显存中。
调整kv cache占用显存的比例为0.4,(默认为0.8),降低kv cache占用显存的最高比例,代价是降低了速度,好处是节省了显存。
在运行推理的代码后面加上参数 --cache-max-entry-count 0.4 即可