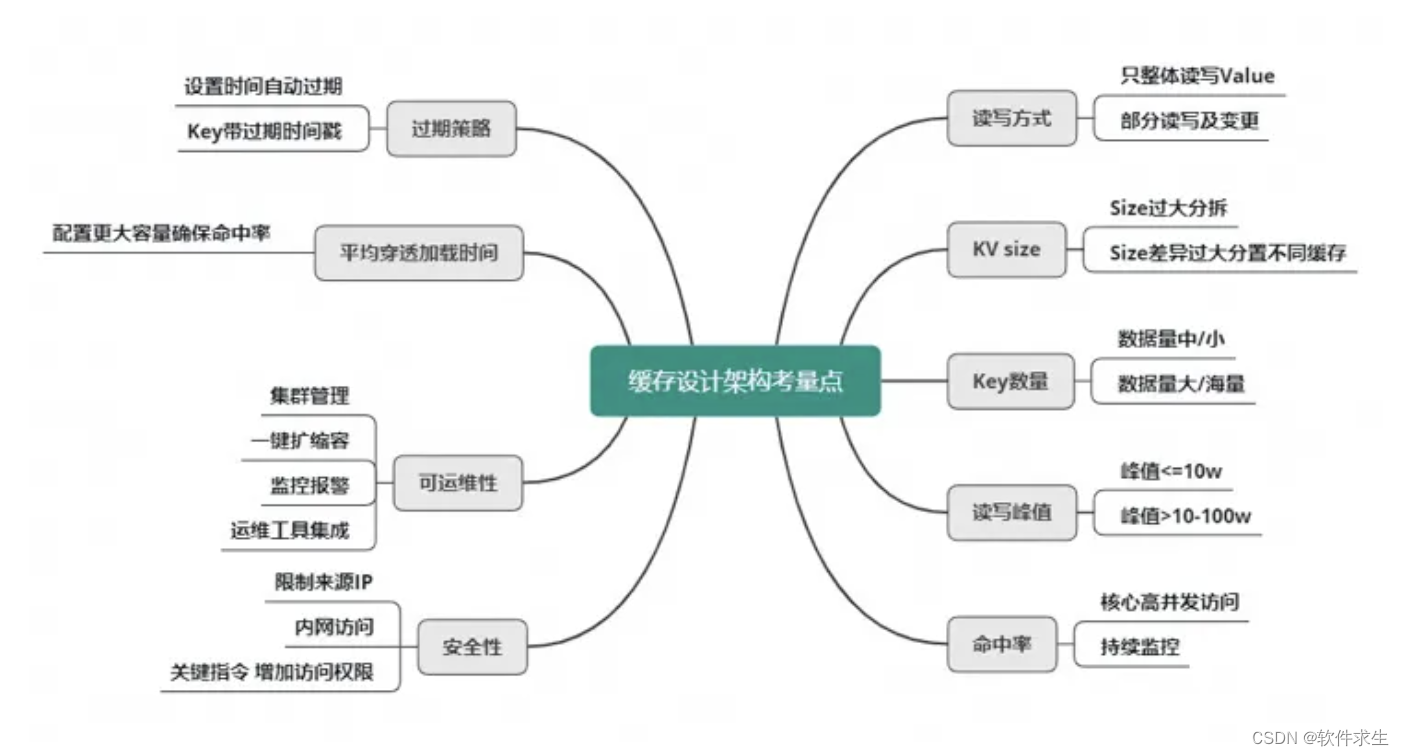
大家好!我是小米,今天和大家分享一下在Redis中如何进行优化,以提升系统性能。Redis作为一种流行的内存数据库,因其高性能、高可用和数据持久性而受到广泛应用。然而,在实际应用中,我们仍需对Redis进行优化,以满足各种业务需求。接下来,我将从读写方式、KV size、Key数量、读写峰值、命中率、过期策略、平均穿透加载时间、可运维性、安全性等方面为大家分享Redis优化的一些经验和技巧。
读写方式
在使用Redis时,选择合适的读写方式对于系统性能至关重要。不同的读写方式适用于不同类型的数据和业务场景,让我们详细了解一下这两个主要方面:
只整体读写Value
Redis常见的读写方式是整体读写Key-Value。这意味着我们使用 GET 命令读取整个Value或使用 SET 命令将整个Value写入Redis。这种方式在处理较小且整体频繁操作的数据时非常有效。例如,缓存用户信息、会话数据或其他完整数据集时,整体读写可以最大限度地利用Redis的快速数据访问性能。
整体读写的优点在于简洁高效,但也存在局限性。对于Value过大或需要部分修改的情况,这种方式可能会导致不必要的内存开销或性能损耗。为避免这些问题,我们需要选择适当的Value类型,并根据业务需求进行调整。
部分读写及变更
除了整体读写,Redis还提供了对Value进行部分读写和变更的能力。通过使用数据结构如哈希表、列表、集合和有序集合等,我们可以更灵活地操作数据。例如:
- 哈希表(Hash):使用 HSET 和 HGET 命令,可以对哈希表中的单个字段进行设置和获取。这种方式适用于复杂的数据结构,例如存储用户的详细信息或产品属性等。
- 列表(List):通过 LPUSH、RPUSH、LPOP 等命令,可以向列表添加元素或从列表中删除元素。这种方式适用于数据的有序处理,如队列或栈的应用。
- 集合(Set):使用 SADD、SREM 等命令,可以对集合中的元素进行添加或删除。这种方式适用于存储去重的数据,如用户的关注列表。
- 有序集合(Sorted Set):使用 ZADD、ZREM 等命令,可以对有序集合中的元素进行操作。这种方式适用于需要排序的数据,如排行榜或优先级队列。
部分读写和变更的优势在于更精细地控制数据操作,避免了整体读写带来的性能问题。这种方式特别适合处理复杂的数据结构和频繁变更的数据。通过选择适合的数据结构,我们可以根据业务需求优化Redis的读写性能。
KV size
在Redis中,键值对的大小(KV size)是系统性能优化的一个重要考量因素。KV size的不同会直接影响数据的存储效率和访问速度。以下是如何通过优化KV size来提升Redis性能的策略和技巧:
Size过大分拆
当单个KV size过大时,这可能会对Redis的性能产生负面影响。过大的键值对可能会导致:
- 内存浪费:大的键值对占用较多的内存,可能导致内存使用效率低下,特别是在有限内存环境下。
- 读写性能下降:处理大键值对的读写操作时间较长,可能影响整体系统性能。
为了优化大键值对的存储和访问,可以考虑将其拆分为更小的键值对。例如,将一个大型哈希表拆分为多个小型哈希表,或将一个大字符串分割成多个小字符串存储。这种拆分可以减小单个键值对的体积,提高数据的读写速度和内存使用效率。
Size差异过大分置不同缓存
当不同键值对的大小差异过大时,可以通过将不同大小的数据分配到不同的Redis实例或数据库来优化性能。例如:
- 大小分区:根据KV size的不同,将数据分配到不同的Redis实例或数据库。较大的键值对可以存储在一个实例中,较小的键值对存储在另一个实例中。这有助于平衡各个实例的负载,提高整体系统性能。
- 数据类型分区:将不同数据类型的数据(如哈希表、列表、集合等)分配到不同的Redis实例或数据库。这种方式可以针对不同数据类型进行优化,提高访问效率。
- 业务逻辑分区: 根据业务需求或数据重要性将数





![[一本Java+一本Java]5月7日简历指导直播](https://img-blog.csdnimg.cn/img_convert/d0bda41a95bdc86930276bf92c843bf4.jpeg)