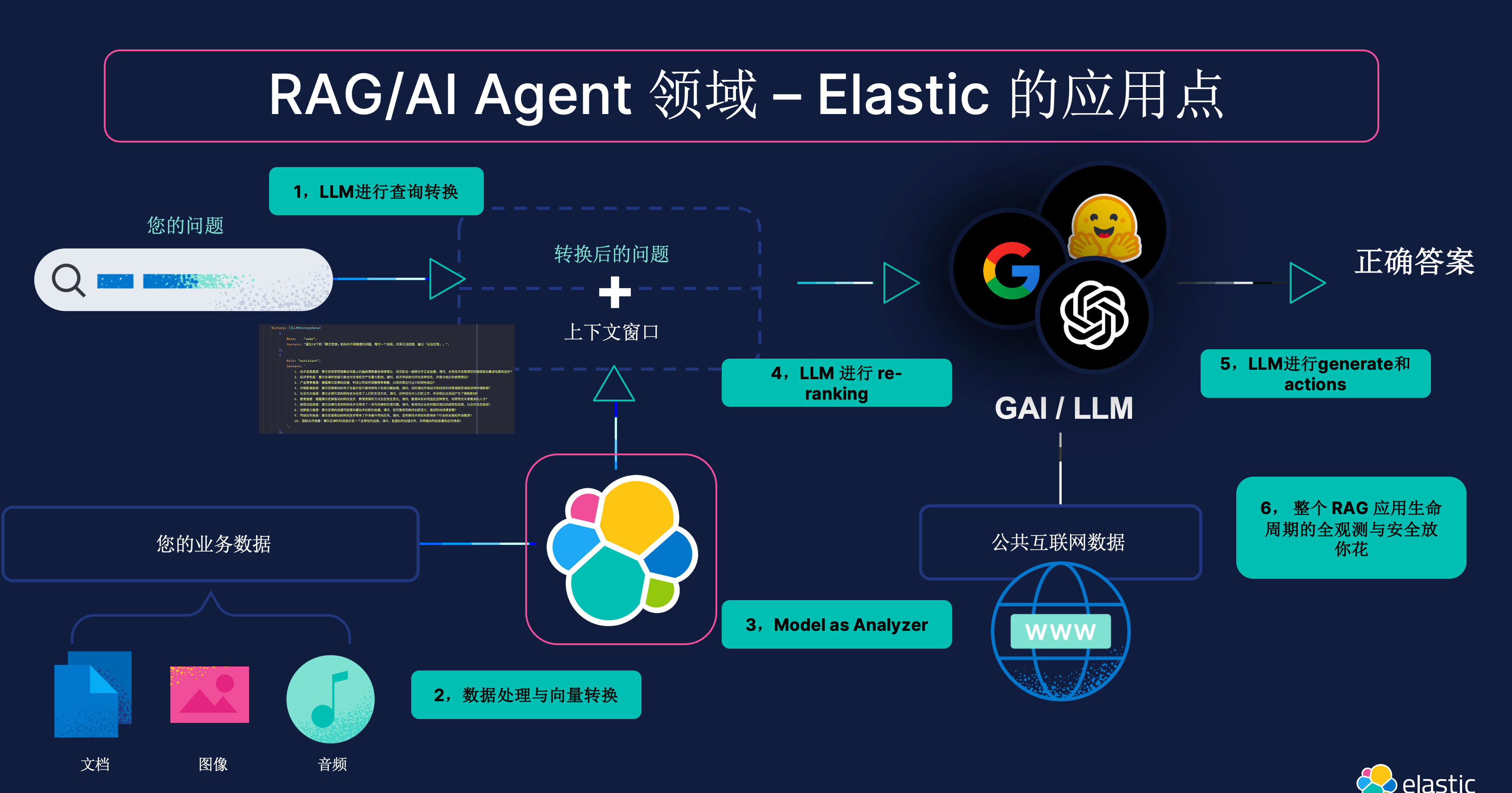
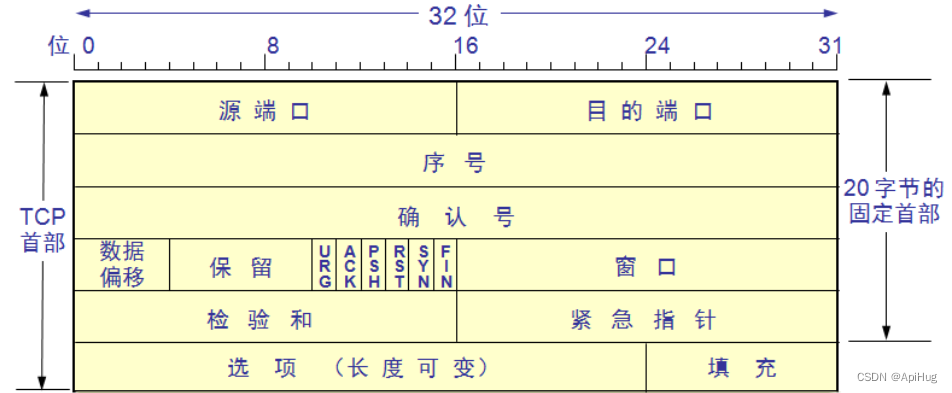
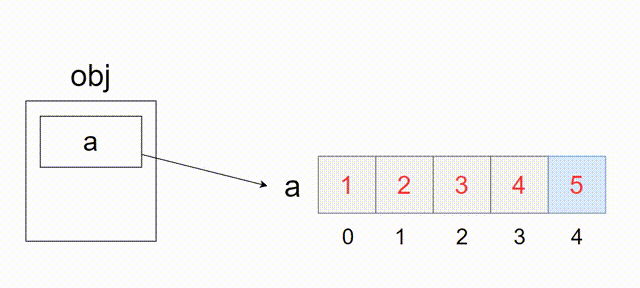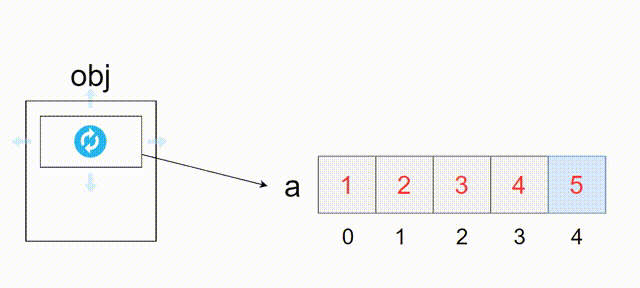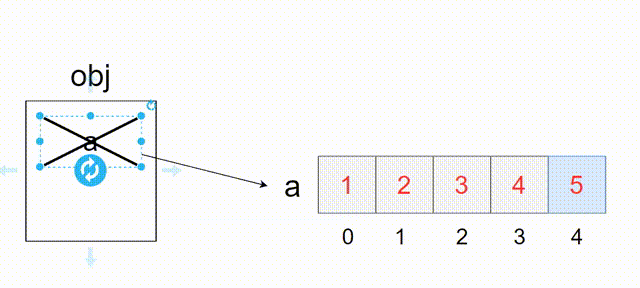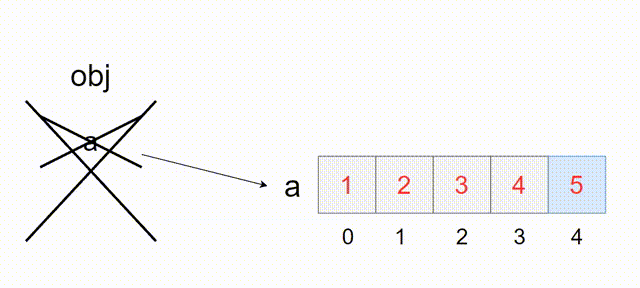
Embedding(嵌入)是一种在计算机科学中常用的技术,尤其是在自然语言处理(NLP)领域。在NLP中,embedding通常指的是将文本中的单词、短语或句子转换为固定维度的向量(vector)。这些向量代表了文本中的语义和上下文信息。

1.embedding 介绍
1.1 为什么需要Embedding?
在传统的文本处理方法中,单词通常被表示为整数ID或稀疏的one-hot向量。这种表示方式难以捕捉单词之间的语义关系和上下文信息。Embedding通过将单词转换为稠密的向量,使得单词之间的关系和上下文信息可以被更好地捕捉和利用。

1.2 常见的Embedding方法
- Word2Vec:这是一种将单词转换为固定维度向量的方法,它包括CBOW(连续词袋模型)和Skip-Gram两种模型。
- GloVe:这是一种基于全局矩阵分解的方法,旨在学习单词之间的关系。
- BERT:这是一种基于Transformer的预训练语言模型,可以学习单词的上下文信息。

1.3 Embedding的应用
Embedding在NLP中有着广泛的应用,包括但不限于:
- 文本分类:通过学习单词的embedding,可以对文本进行分类。
- 情感分析:通过分析文本的embedding,可以判断文本的情感倾向。
- 命名实体识别:通过embedding,可以识别文本中的命名实体,如人名、地点等。
- 机器翻译:使用embedding可以提高机器翻译的准确性。
1.4 总结
Embedding是一种将文本中的单词转换为向量的技术,它能够更好地捕捉单词之间的语义关系和上下文信息。在NLP领域,embedding的应用非常广泛,可以帮助解决许多文本处理任务。



![[VulnHub靶机渗透] Hackademic: RTB1](https://img-blog.csdnimg.cn/direct/85926679e44140de8d1d2fc264b1736c.png)