理解相似性搜索(也称为语义搜索)的指南,这是人工智能最新阶段的关键发现之一。

最新阶段人工智能的关键发现之一是根据相似性搜索和查找文档的能力。相似性搜索是一种比较信息的方法,其基于含义而非关键字。
相似性搜索也被称为语义搜索。语义一词指的是 “在特定上下文中单词、短语或符号的含义或解释。” 使用语义搜索,用户可以提出问题,例如“哪部电影中的主角穿越了 500 英尺的臭气熏天的排泄物?” 而 AI 将回答 “肖申克的救赎”。使用关键字搜索是无法执行此类搜索的。
语义搜索打开了各种可能性,无论是研究人员试图从大学藏书中找到特定信息,还是让开发人员在查询 API 文档时获得精确信息。
语义搜索的巧妙之处在于我们可以将整个文档和文本页面转换为其含义的表示。
本文的目的是提供语义搜索的基础知识以及其背后的基本数学原理。通过深入理解,您可以利用这项新技术为用户提供极为有用的工具。
这项技术的关键在于向量的数学。
向量
你可能还记得高中或大学时向量的概念。 它们在物理学中经常使用。 在物理学中,向量被定义为大小加上方向。 例如,汽车以 50 公里/小时的速度向北行驶。
向量可以用图形表示:

向量在人工智能中具有不同的含义,我们很快就会谈到。 我将与您讨论如何从物理学中的向量转变为人工智能中的向量。
回到我们的图形表示,如果我们将其绘制在图表中,我们可以表示二维向量。
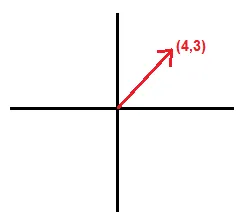
向量的末端可以用它在 x 轴和 y 轴上的值来表示。 这个向量可以用点 [4, 3] 来表示。有了这一点,我们就可以用三角学来计算它的大小和方向。
如果我们创建一个 3 维向量,我们需要三个值来表示空间中的向量。

该向量由点 [2, 3, 5] 表示。 我们再次可以应用三角学来计算幅度和方向。
我们可以对 2 维或 3 维向量执行的有趣计算之一是确定向量之间的相似性。
在物理学中,我们需要执行的计算之一是向量相似度(这导致了人工智能相似度搜索)。 例如,在材料科学的研究中,向量可用于比较负载下材料内的应力或应变向量。
在图中,如果我们有相似的应力向量,我们可以看到材料上的应变方向相同。 而相反的力会对材料施加特定的应力。
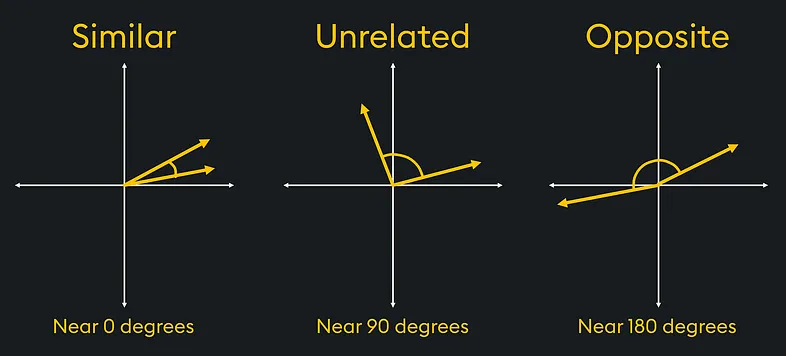
使用三角学,我们可以确定哪些向量最相似或最不相似。
人工智能中的向量
需要注意的是,向量可以用值数组来表示。 对于三维向量,由三个点 [1, 3, 4] 描述。
在人工智能中,我们使用数组来表示一组数据中的不同信息。 例如,如果我们使用机器学习来预测房价,我们可以用数组表示所有信息。
让我们看一个非常简单的例子,其中我们只有三个数据点来代表每栋房子。 数组的每个元素都代表房子的不同特征。 例如:
- 价格:一美元价值。
- 卧室数量:整数值。
- 尺寸:以平方英尺为单位测量。
假设的房子将表示为:
房屋:[300000, 3, 400]使用我们的 3 维住房数据,我们现在可以创建一个算法来创建住房推荐引擎。 这是由数据数组表示的三栋房屋:
1号屋:[300000, 3, 400]
2号楼:[320000, 3, 410]
3号楼:[900000, 4, 630]将这三所房子绘制成三维图,我们得到下图。

如果用户想要找到与房屋 1 最相似的房屋,则可以快速确定房屋 2 是最相似的,并且推荐引擎可以将该房产的详细信息返回给用户。
在机器学习中,房屋数组被称为向量。 向量之所以如此有趣,是因为物理向量中使用的数学同样适用于数字数组。 因此,我们使用术语向量。
当向量包含三个以上数据点时,就无法可视化了。 房屋向量可以包含许多数据点,例如位置、质量得分、年龄、浴室数量等。 一个完整的房子向量可能如下所示:
[300000, 3, 400, 122.2, 83.4, 87, 43, 3]这被称为高维向量。 在这种情况下,维度是指数据的一个特征。 价格是一个维度。 尺寸是另一个维度,所以也是如此。 高维向量无法在 3 维空间中表示,但是,相同的概念和数学适用。 我们仍然可以通过查找最相似的高维向量来运行我们的推荐引擎。
更多阅读:
- Elasticsearch:什么是向量和向量存储数据库,我们为什么关心?
-
Elasticsearch:语义搜索 - Semantic Search in python
将文本转换为向量
当我们开始将文本转换为向量时,事情开始变得真正有趣。 现代人工智能的天才之处在于能够将单词、短语甚至文本页面转换为代表该信息含义的向量。
让我们从一个词开始:“cat”。
专门的人工智能模型可以将 “cat”一词转化为向量。 该向量代表了单词 cat 的含义,因为它与训练数据中的其他单词相关。 这些专门的人工智能使用预先训练的模型,这些模型已经学会了如何将文本表示为高维向量。 这些向量根据文本在训练数据中的使用情况来捕获文本之间的语义和关系。
将文本转换为向量称为向量嵌入 (vector embedding)。
“cat” 可能由 300 维向量表示。
[ 0.49671415, -0.1382643 , 0.64768854, 1.52302986, -0.23415337, -0.23413696, 1.57921282, …]另一方面,“dog” 可以用向量表示:
[ 1.69052570, -0.46593737, 0.03282016, 0.40751628, -0.78892303, 0.00206557, -0.00089039, …]如果我们将 Cat 和 Dog 向量简化为二维,它可能看起来像这样。
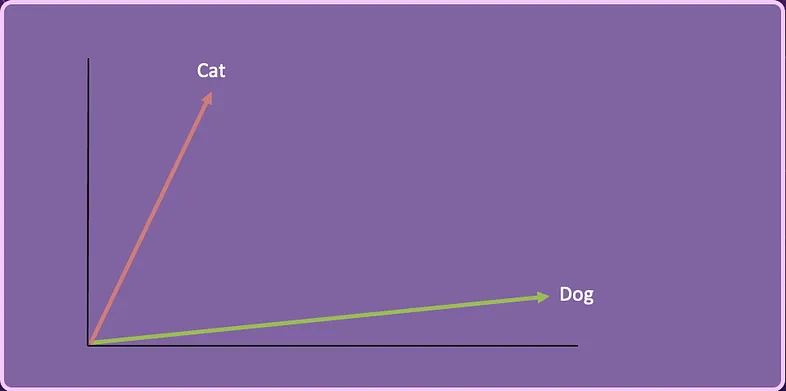
我们可以采用第三个单词 “Kitten”,创建向量嵌入并将其表示在这个二维空间中。Kittend 的向量表示为:
[-0.05196425, -0.11119605, 1.0417968, -1.25673929, 0.74538768, -1.71105376, -0.20586438, …]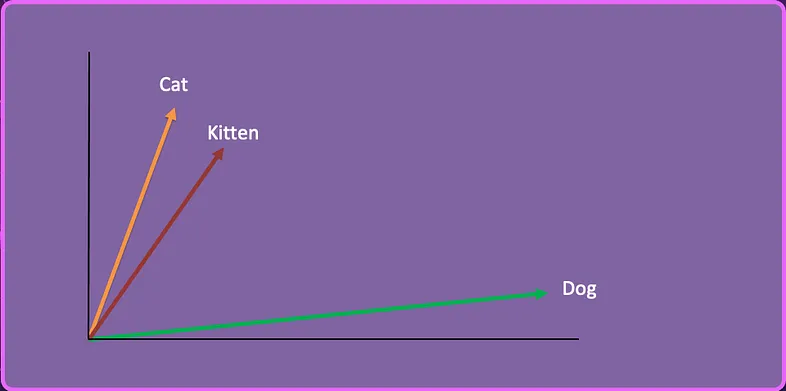
假设我们有一系列有关喂养猫和狗的文章,我们的用户提出以下问题:
How do I feed my kitten?通过使用相似性搜索,人工智能确定小猫在语义上更接近猫而不是狗,因此返回有关如何喂养猫的文章。

这就是相似性/语义搜索的根本基础。 通过将文本转换为向量嵌入,我们有一种方法来确定与其他信息的语义相似性。有关这个英文单词的可视化问题,可以参考文章 “Elasticsearch:语义搜索 - Semantic Search in python”。
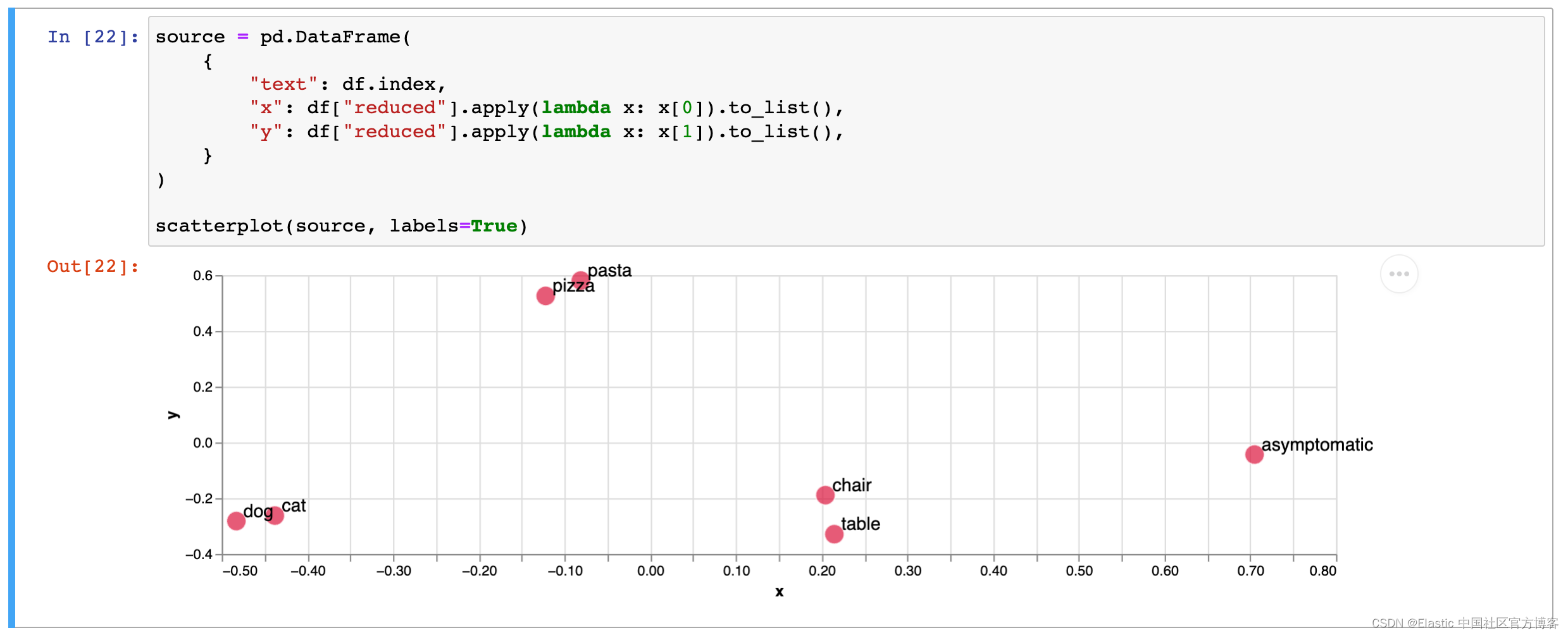
另一个例子可能是获取图书馆书籍的摘要并将其转换为向量嵌入。 下图显示了按类型分类的书籍。 您会发现这些书往往会分成几组。
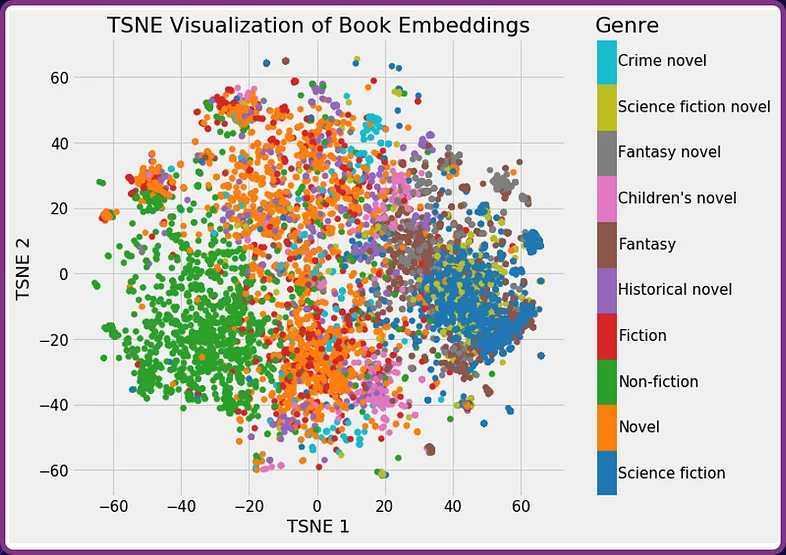
如果用户正在寻找与《沙丘 - dune》类似的书籍的推荐,它会看到《沙丘》聚集在 “science fiction - 科幻小说” 类型中,并返回诸如 “2001: A space odyssey - 2001:太空漫游”之类的推荐。
创建向量嵌入
向量嵌入是由专门的人工智能模型创建的。 OpenAI 有他们的 text-embedding-ada-002 模型。
通过简单的 API 调用,可以将文本传递到模型,该模型将生成向量嵌入。 OpenAI 向量嵌入通常在 1500 到 3500 个元素之间,具体取决于所使用的具体模型。
有关使用 OpenAI 嵌入端点的信息,请查看:https://platform.openai.com/docs/guides/embeddings
从编程的角度来看,每个嵌入人工智能模型都会以阵列的形式返回支持,这使得使用起来非常容易。
只需调用 API 即可添加支持嵌入。事实上,我们有很多的方法来生成嵌入。我们可以使用开放的 https://huggingface.co/ 上的模型来创建向量嵌入。我们可以参考我的 AI 专栏里的很多文章来生成嵌入。
存储向量嵌入
向量嵌入可以存储在任何类型的数据存储中。 我在早期测试期间使用了 CSV 文件(尽管绝对不推荐用于任何严肃的应用程序)。
然而,过去几年开始出现了专门的向量数据库。 它们与传统数据库的不同之处在于它们针对处理向量进行了优化。 这些数据库提供了有效计算这些高维向量之间相似性的机制。
让我们看看矢量数据库的架构是什么样的。 假设我们正在运营一家金融科技公司,可以访问数千份财务报表,我们希望能够使用人工智能来查询这些文档。

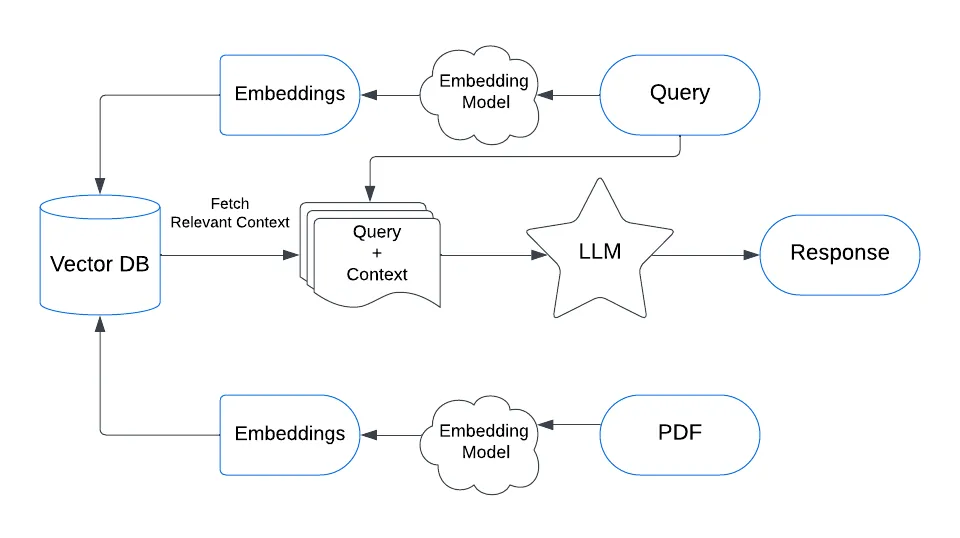
作为全球领先的 Elasticsearch,目前已经是全球下载量最大的向量数据库。我们可以可以轻松地把向量存入到 Elasticsearch 数据库中,并提供快速的向量搜索。
相似性搜索
向量数据库针对相似性搜索进行了优化。有几种不同的数学方法,其中最常见且最简单的实现方式是使用余弦相似度。
余弦相似度是一种三角测量方法,用来确定两个向量的相似程度。这种方法通过计算两个向量之间角度的余弦值来实现。小角度的余弦值接近于 1,而 90 度角的余弦值为 0。非常相似的向量将会有一个接近于 1 的余弦值。

没有必要涵盖计算余弦相似度的数学知识,除非您是像我一样的数学极客,在这种情况下,该视频很好地解释了它。
主要结论是相似性得分越接近 1,向量就越相似。
向量数据库提供了执行相似性的函数,你可以在其中设置参数,例如要返回的结果数。 例如,你可能想要三个最接近的结果。有关余弦相似度的更多描述,请阅读 “Elasticsearch:什么是余弦相似度?”。
值得指出的是,Elasticsearch 除了上面所说的余弦相似性,它还支持其它的相似性。请详细阅读 “Elasticsearch:dense vector 数据类型及标量量化”。
执行相似性搜索
执行相似性搜索需要几个步骤。
将源文档转换为向量嵌入并将其存储在向量数据库中, 比如 Elasticsearch 向量数据库。

在此过程中,每个源文档都会被输入到嵌入人工智能中,由人工智能创建向量嵌入。 然后,这些向量嵌入连同对原始源文档的引用一起保存在向量数据库中。
对于图书馆来说,这可能是过去 100 年的报纸文章的集合。
2. 将查询转换为向量并使用余弦相似度来查找与查询最相似的文档
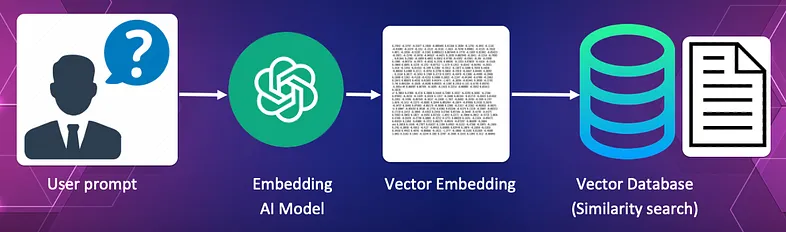
在此过程中,用户查询本身被转换为向量。 该向量用作向量数据库中的搜索向量,以查找最能回答查询的文档。
对于我们的图书馆来说,查询可能是 “我正在寻找一篇有关 1950 年 Chinchaga 火灾的报纸文章”。
该查询本身被转换为向量并传递到向量数据库,该数据库使用其相似性搜索来查找与查询含义最相似的报纸文章。 我们可能希望只返回最高的结果。
向量数据库将返回文章的名称和当前源文本的 URL。
3. 将查询连同源文档一起发送给 LLM 以验证请求

这是拼图的最后一块。 查询与原始源文本一起发送到大型语言模型以处理针对文档的查询。 使用的 LLM 可以是 Claude、OpenAI、Gemini 或任何开源模型,例如 Llama 或 Mistral。
在我们的库示例中,它将检查源文档是否确实包含有关 Chinchaga 火灾的信息。 如果是这样,将向用户提供源文档的 URL。
知识检索
整个过程被称为知识检索或检索增强生成(RAG)。
想象一下,你正在使用一个信用卡支付提供商的 API。你不必费力查找 API 端点和文档,只需问:“处理支付的端点是什么?”。
AI 将使用相似性搜索找到正确的文档,并将你的问题和文档发送给一个 LLM。LLM 将根据源文档中的信息回答问题。
然后,你可以进一步查询,问:“我如何在 Ruby 中进行这个 API 调用?” 或 JavaScript、Python、C++等。LLM 应该能够根据端点源文档生成代码。
知识检索是一种非常强大的手段,可以提高用户获取并得到准确答案的能力,而不必花时间查阅错误的信息。
知识检索可以以多种方式使用。它可以用于为用户找到并返回整篇文章。它可以在大量文档中找到非常具体的信息。它可以用于推荐。知识检索的用例仅受想象力的限制。
总结
我认为,知识检索和相似性搜索是企业成功实施人工智能的切入点。过去,关键词搜索对所有网站来说几乎是必须的,但我们很快会看到,知识检索将成为最基本的标准。当我尝试使用没有知识搜索功能的 API 文档时,我已经感到非常沮丧。
我期待看到你利用知识检索和相似性搜索提出的新颖而惊人的想法。
更多关于向量搜索的知识,请详细阅读专栏 “AI”。