1. 安装驱动
1.1 查看系统是否识别显卡
lspci | grep -i vga
03:00.0 VGA compatible controller: NVIDIA Corporation GP102 [TITAN X] (rev a1)
0a:00.0 VGA compatible controller: Matrox Electronics Systems Ltd. G200eR2 (rev 01)识别出显卡为 NVIDIA 的 TITAN X。
1.2 禁用 nouveau
lsmod | grep nouveau如果有输出,说明 nouveau 已经加载,需要禁用。如果没有输出,则可以跳过此操作。
1.2.1 Ubuntu 系统
1)关闭自动更新
sed -i.bak 's/1/0/' /etc/apt/apt.conf.d/10periodic编辑配置文件:
vim /etc/apt/apt.conf.d/50unattended-upgrades去掉以下内容的注释:
Unattended-Upgrade::Package-Blacklist {
"linux-image-*";
"linux-headers-*";
};2)编辑系统 blacklist
vim /etc/modprobe.d/blacklist-nouveau.conf添加以下配置禁用 nouveau:
blacklist nouveau
options nouveau modeset=03)更新 initramfs
update-initramfs -u4)重启系统
reboot1.2.2 CentOS 系统
1)编辑系统 blacklist
vim /etc/modprobe.d/blacklist-nouveau.conf添加配置禁用 nouveau
blacklist nouveau
options nouveau modeset=02)更新 initramfs
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
dracut /boot/initramfs-$(uname -r).img $(uname -r)3)重启系统
reboot4)验证是否禁用成功
lsmod | grep nouveau此时不应该有输出。
1.3 安装驱动
1.3.1 下载驱动
访问 Official Drivers | NVIDIA 选择对应的驱动版本下载。这里以 Linux 64-bit 的 TITAN X 驱动为例:
wget https://cn.download.nvidia.com/XFree86/Linux-x86_64/535.146.02/NVIDIA-Linux-x86_64-535.146.02.run1.3.2 安装驱动
chmod +x NVIDIA-Linux-x86_64-535.146.02.run
./NVIDIA-Linux-x86_64-535.146.02.run1.3.3 重启系统
reboot1.3.4 验证是否安装成功
nvidia-smi2. 安装 nvidia-container-runtime
2.1 安装 nvidia-container-runtime
2.1.1 Ubuntu 系统
curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | sudo apt-key add -distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
sudo apt-get updateapt-get install -y nvidia-container-runtime2.1.2 CentOS 系统
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.repo | sudo tee /etc/yum.repos.d/nvidia-container-runtime.repo
yum install -y nvidia-container-runtime2.2 Docker 配置
2.2.1 更新 Docker 配置
1)配置 Docker 开启 GPU 支持
vim /etc/docker/daemon.json添加以下内容:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
2)重启 Docker
systemctl daemon-reload
systemctl restart docker3)验证安装结果
docker run --rm --gpus all ubuntu nvidia-smi此时可以看到输出的 GPU 信息。
2.3 Containerd 配置
1)更新 Containerd 配置
vim /etc/containerd/config.toml在与 plugins."io.containerd.grpc.v1.cri".containerd.runtimes 中添加:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
CriuImagePath = ""
CriuPath = ""
CriuWorkPath = ""
IoGid = 0
IoUid = 0
NoNewKeyring = false
NoPivotRoot = false
Root = ""
ShimCgroup = ""
SystemdCgroup = true将默认的 runtime 设置为 nvidia
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
2)重启 Containerd
systemctl daemon-reload
systemctl restart containerd3)验证安装结果
nerdctl run --rm --gpus all registry-1.docker.io/library/ubuntu nvidia-smi3. 安装 CUDA Toolkit
CUDA 是 NVIDIA 推出的通用并行计算架构,用于在 GPU 上进行通用计算。CUDA Toolkit 是 CUDA 的开发工具包,包含了编译器(NVCC)、库、调试器等工具。
3.1 检查系统是否支持
参考 CUDA Installation Guide for Linux 有最新的 CUDA 对 CPU 架构、操作系统、GCC 版本、GLIBC 版本的依赖要求。
1)检查系统版本
uname -m && cat /etc/os-release2)检查 GCC 版本
gcc --versionUbuntu 下可以使用以下命令安装 GCC 9
apt install build-essential gcc-9 g++-9
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 90 --slave /usr/bin/g++ g++ /usr/bin/g++-9 --slave /usr/bin/gcov gcov /usr/bin/gcov-93)检查 GLIBC 版本
ldd --version3.2 兼容性说明
使用 nvidia-smi 命令可以看到一个 CUDA 的版本号,但这个版本号是 CUDA driver libcuda.so 的版本号,不是 CUDA Toolkit 的版本号。
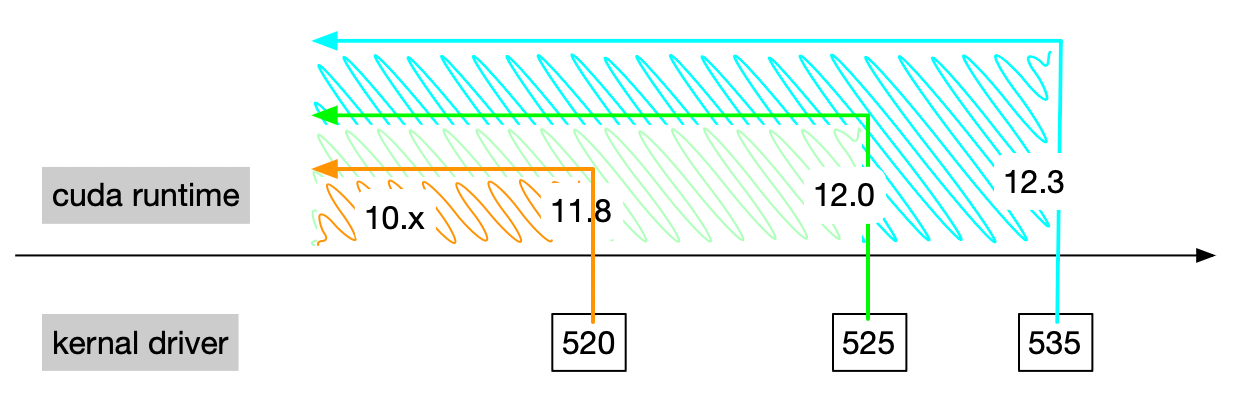
如上图 CUDA driver 是向后兼容的,即支持之前的 CUDA Toolkit 版本。
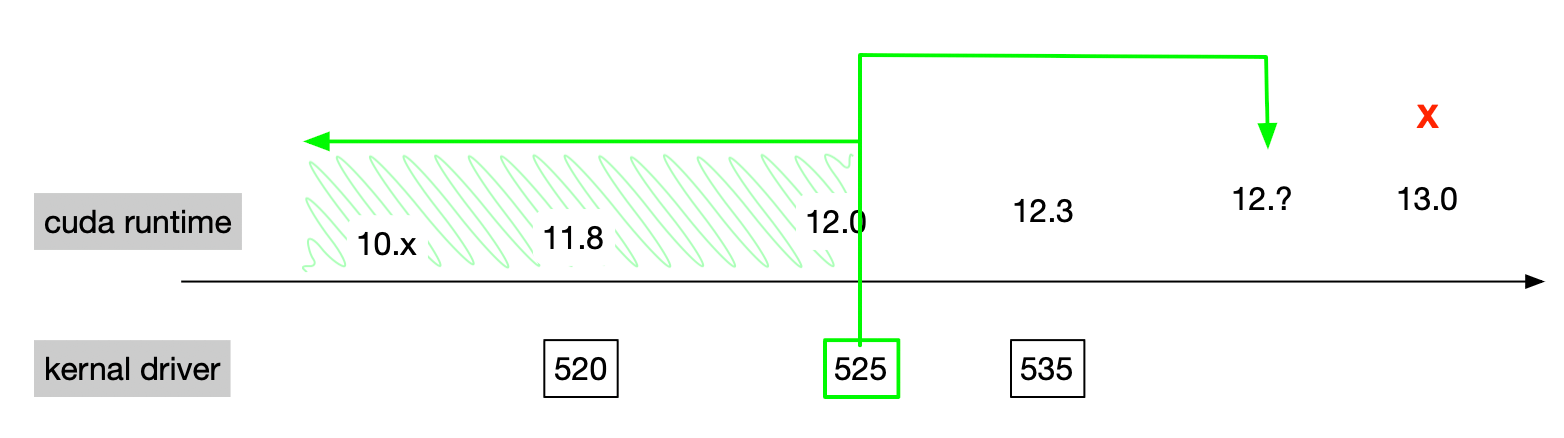
如上图,CUDA driver 支持向前的次要版本兼容,即大版本号相同就支持。参考[2]。
3.3 安装 CUDA
1)下载 CUDA
前往 CUDA Toolkit 12.4 Update 1 Downloads | NVIDIA Developer 选择对应的版本下载。这里以 Ubuntu 20.04 的 runfile(local) 为例:
wget https://developer.download.nvidia.com/compute/cuda/12.3.1/local_installers/cuda_12.3.1_545.23.08_linux.run2)安装 CUDA
sh cuda_12.3.1_545.23.08_linux.run3)添加环境变量
vim ~/.bashrc增加以下内容:
export PATH=$PATH:$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda使环境变量立即生效:
source ~/.bashrc4)验证安装结果
nvcc -V4. 安装 cuDNN
cuDNN 是 NVIDIA 基于 CUDA 开发的深度神经网络加速库。
1)检查 cuDNN 依赖
前往 Support Matrix — NVIDIA cuDNN v9.1.1 documentation 查看 cuDNN 与 CUDA、Driver、操作系统的兼容性是否满足要求。
2)下载 cudnn
前往 cuDNN Archive | NVIDIA Developer 下载对应的版本,选择 Local Installer for Linux x86_64 (Tar) ,会得到一个 tar.xz 的压缩包。
3)解压 cudnn
tar -xvf cudnn-linux-*-archive.tar.xz4)安装 cudnn
cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*5. 开启持久模式
使用 nvidia-smi -pm 1 能够开启持久模式,但重启后会失效,同时使用 nvidia-smi 的方式已经被归档,推荐使用 nvidia-persistenced 常驻进程。
开启持久模式之后,驱动一直会被加载,会消耗更多能源,但能有效改善各种显卡故障。
1)新建配置文件
cat <<EOF > /lib/systemd/system/nvidia-persistenced.service
[Unit]
Description=NVIDIA Persistence Daemon
After=syslog.target
[Service]
Type=forking
PIDFile=/var/run/nvidia-persistenced/nvidia-persistenced.pid
Restart=always
ExecStart=/usr/bin/nvidia-persistenced --verbose
ExecStopPost=/bin/rm -rf /var/run/nvidia-persistenced/*
TimeoutSec=300
[Install]
WantedBy=multi-user.target
EOF2)启动持久模式
systemctl start nvidia-persistenced3)查看服务状态
systemctl status nvidia-persistenced4)开机启动持久模式
systemctl enable nvidia-persistenced6. 安装 NVLink 和 NVSwitch 驱动
如果装配了 NVLink 或者 NVSwitch ,还需要安装 nvidia-fabricmanager,否则无法正常工作。
1)下载 nvidia-fabricmanager
在 Index of /compute/cuda/repos/ubuntu2004/x86_64 找到合适的版本。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/nvidia-fabricmanager-535_535.129.03-1_amd64.deb2)安装 nvidia-fabricmanager
apt install ./nvidia-fabricmanager-535_535.129.03-1_amd64.deb3)启动 nvidia-fabricmanager 服务
systemctl start nvidia-fabricmanager4)查看 nvidia-fabricmanager 服务
systemctl status nvidia-fabricmanager5)开机自启
systemctl enable nvidia-fabricmanager7. 安装 InfiniBand 驱动
wget https://content.mellanox.com/ofed/MLNX_OFED-4.9-5.1.0.0/MLNX_OFED_LINUX-4.9-5.1.0.0-ubuntu20.04-x86_64.tgztar zxf MLNX_OFED_LINUX-4.9-5.1.0.0-ubuntu20.04-x86_64.tgz
cd MLNX_OFED_LINUX-4.9-5.1.0.0-ubuntu20.04-x86_64
./mlnxofedinstall然后重启机器,可以查看驱动状态:
systemctl status openibd
● openibd.service - openibd - configure Mellanox devices
Loaded: loaded (/lib/systemd/system/openibd.service; enabled; vendor preset: enabled)
Active: active (exited) since Mon 2024-03-11 15:30:58 CST; 1 weeks 0 days ago
Docs: file:/etc/infiniband/openib.conf
Process: 2261 ExecStart=/etc/init.d/openibd start bootid=65648015406c4b88b831c8b907ad4ec6 (code=exited, status=0/SUCCESS)
Main PID: 2261 (code=exited, status=0/SUCCESS)
Tasks: 0 (limit: 618654)
Memory: 24.6M
CGroup: /system.slice/openibd.service通过 ibstat 可以查看设备信息:
ibstat
ibstat
CA 'mlx5_0'
CA type: MT4123
Number of ports: 1
Firmware version: 20.35.1012
Hardware version: 0
Node GUID: 0x946dae03008bcc68
System image GUID: 0x946dae03008bcc68
Port 1:
State: Active
Physical state: LinkUp
Rate: 200
Base lid: 124
LMC: 0
SM lid: 1
Capability mask: 0xa651e848
Port GUID: 0x946dae03008bcc68
Link layer: InfiniBand
CA 'mlx5_1'
CA type: MT4123
Number of ports: 1
Firmware version: 20.35.1012
Hardware version: 0
Node GUID: 0x946dae03008bcc3c
System image GUID: 0x946dae03008bcc3c
Port 1:
State: Active
Physical state: LinkUp
Rate: 200
Base lid: 126
LMC: 0
SM lid: 1
Capability mask: 0xa651e848
Port GUID: 0x946dae03008bcc3c
Link layer: InfiniBand8. 部署 k8s-rdma-shared-dev-plugin
为了让 Kubernetes 能够发现 RDMA 设备,比如 IfiniBand ,并且被多个 Pod 使用,需要安装 k8s-rdma-shared-dev-plugin。
1)安装 k8s-rdma-shared-dev-plugin
kubectl apply -f https://raw.githubusercontent.com/shaowenchen/hubimage/main/network/k8s-rdma-shared-dev-plugin.yaml2)修改配置文件
kubectl -n kube-system edit cm rdma-devices3)Pod 中配置使用
在 spec 中配置 rdma/ib 就可以使用了。
spec:
containers:
- command:
- /bin/sh
- -c
- mkdir -p /var/run/sshd; /usr/sbin/sshd;bash llama_distributed_v3.0_check.sh
resources:
limits:
cpu: "64"
memory: 950Gi
rdma/ib: "8"
tencent.com/vcuda-core: "800"
requests:
cpu: "64"
memory: 950Gi
rdma/ib: "8"
tencent.com/vcuda-core: "800"