目录
- 1 总览
- 1.1 技术架构
- 1.2 其他
- 1.2.1 数据库
- 1.2.2 后端部分
- 1.2.2.1 复习feign
- 1.2.2.2 复习下网关
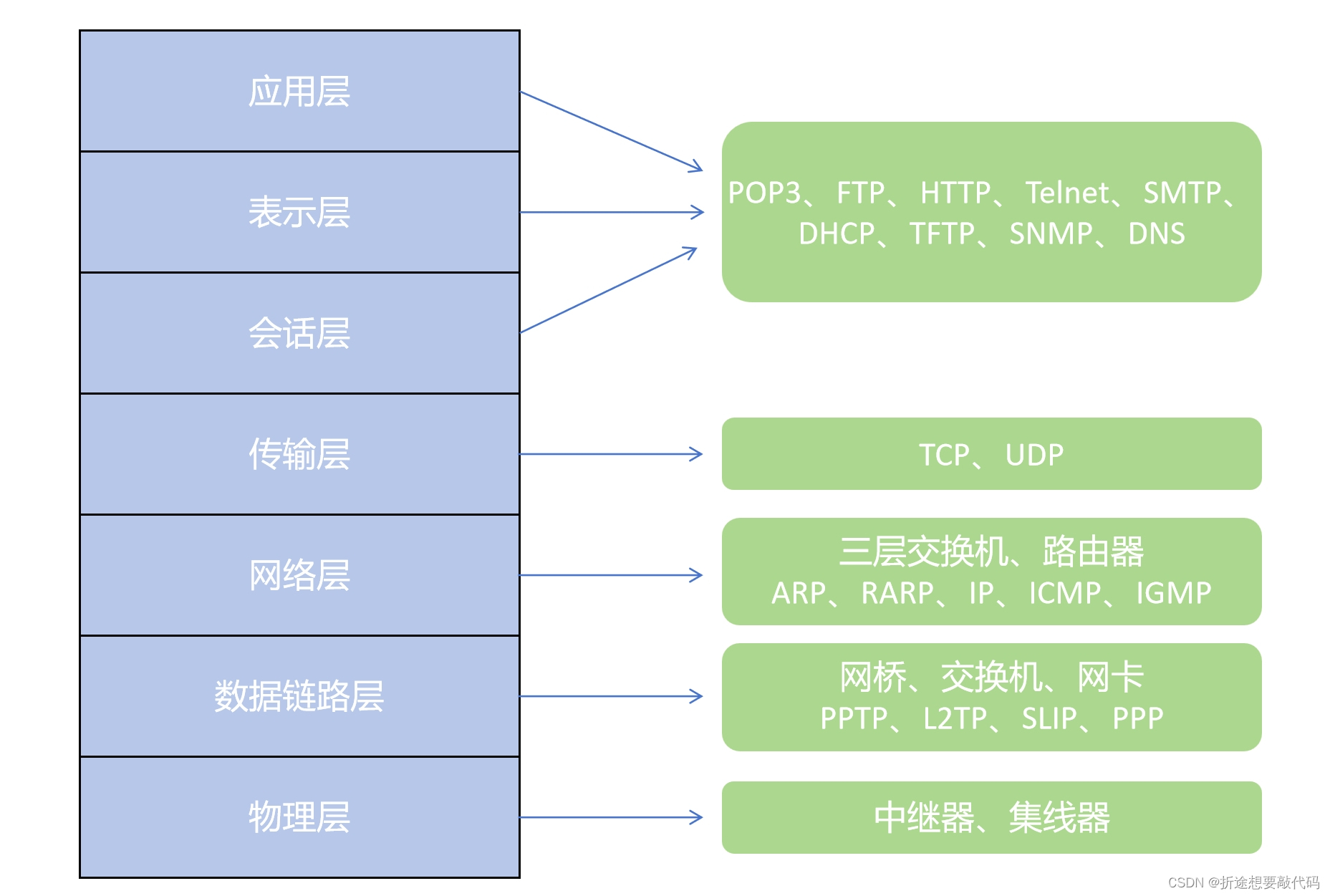
- 网关的核心功能特性:
- 网关路由的流程
- 断言工厂
- 过滤器工厂
- 全局过滤器
- 过滤器执行顺序
- 解决跨域问题
- 1.2.2.3 es部分复习
- 1.2.3 前端部分
- 2 day1 配置网关
- 2.1 任务
- 2.2 网关配置
- 3 day2 商品管理业务
- 3.1 今日需求分析
- 3.2 分页查询商品
- 3.2.1 实体类介绍
- 3.2.2 Controller Service 以及 持久层
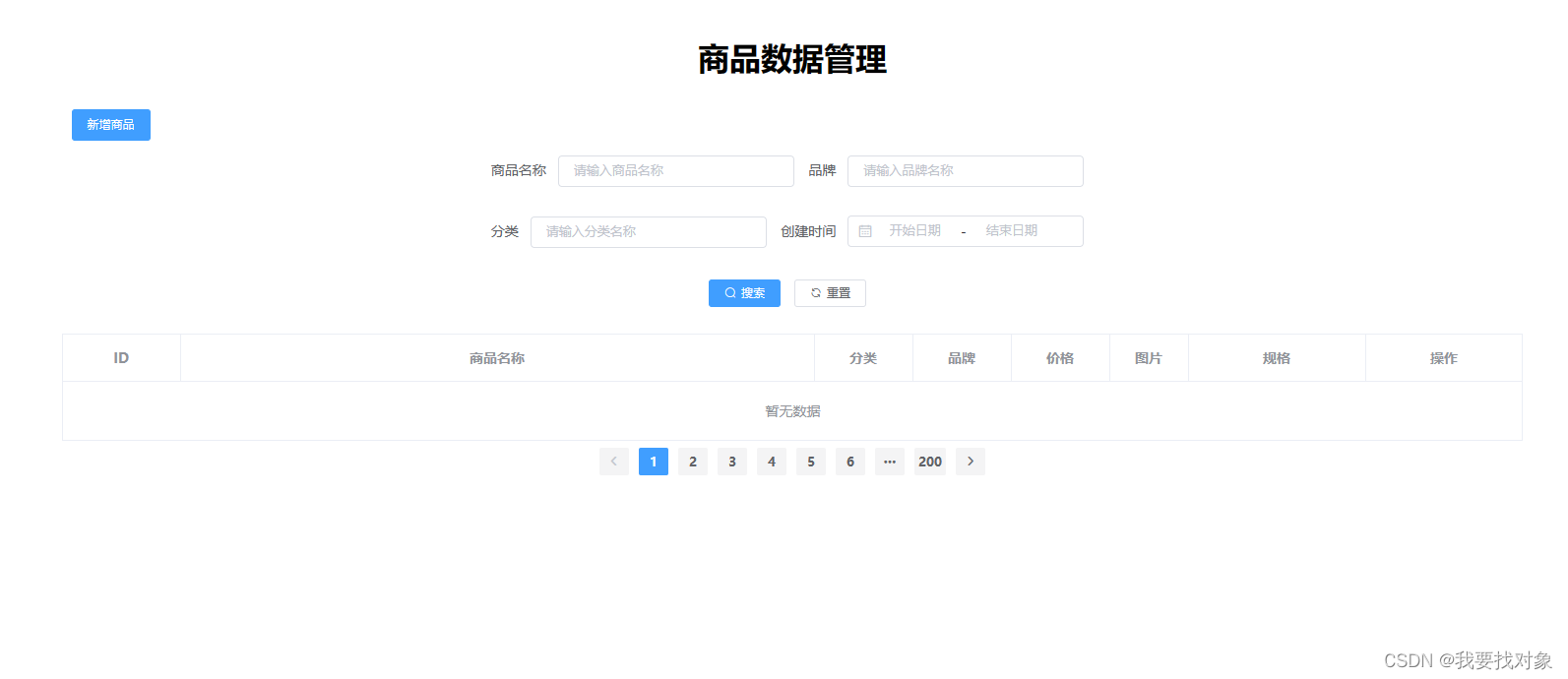
- 3.2.3 实现效果
- 3.3 根据id查询商品
- 3.4 新增商品
- 3.4.1 需求
- 3.4.2 具体实现
- 3.5 商品上架、下架
- 3.5.1 需求
- 3.5.2 实现
- 3.5 修改商品属性
- 3.5.1 需求
- 3.5.1 实现
- 3.6 删除商品
- 3.6.1 需求
- 3.6.2 实现
- 4 day3 完成User页面的搜索需求
- 4.1 设计索引库数据结构
- 索引库结构实体类:
- 4.2 mysql数据导入es的doc
- 定义FeignClient
- 将数据分批次导入doc
- 4.3 搜索栏自动补全功能
- 4.4 基本搜索功能(搜索/分页/高亮/算分查询/排序查询)
- 需求
- 具体实现
- 实现效果
- 4.5 查询选项过滤聚合
- 需求
- 具体实现
- 实现效果
- 4.6 数据同步
- 需求
- 实现
- 5 day4 完成用户登录和用户功能
- 5.1 微服务获取用户身份
- 5.2 根据用户id查询地址列表
- 需求分析
- 具体实现
- 效果展示
1 总览
一个比较简单的微服务商城项目,涉及到的技术有ssm,MybatisPlus,SpringBoot,XXL-Job,es,nacos,SpringCloud等等
五一假期期间顺便复习一下之前学过的(低情商:没有对象陪着出去玩 )
以下是完成计划:
day1 完成Idea项目的配置,网关的搭建,数据库和前端的配置
day2 完成Admin页面的商品管理需求 (ssm,SpringBoot,MybatisPlus)
day3 完成User页面的搜索需求 (Feign,elasticsearch,RabbitMQ)
day4 完成用户登录和用户功能 (gateway,SpringMvc拦截器,MybatisPlus,Feign)
day5 完成下单等功能 (XXL-JOB,ssm,MybatisPlus,Feign)
前后端代码地址:Web_shop
1.1 技术架构
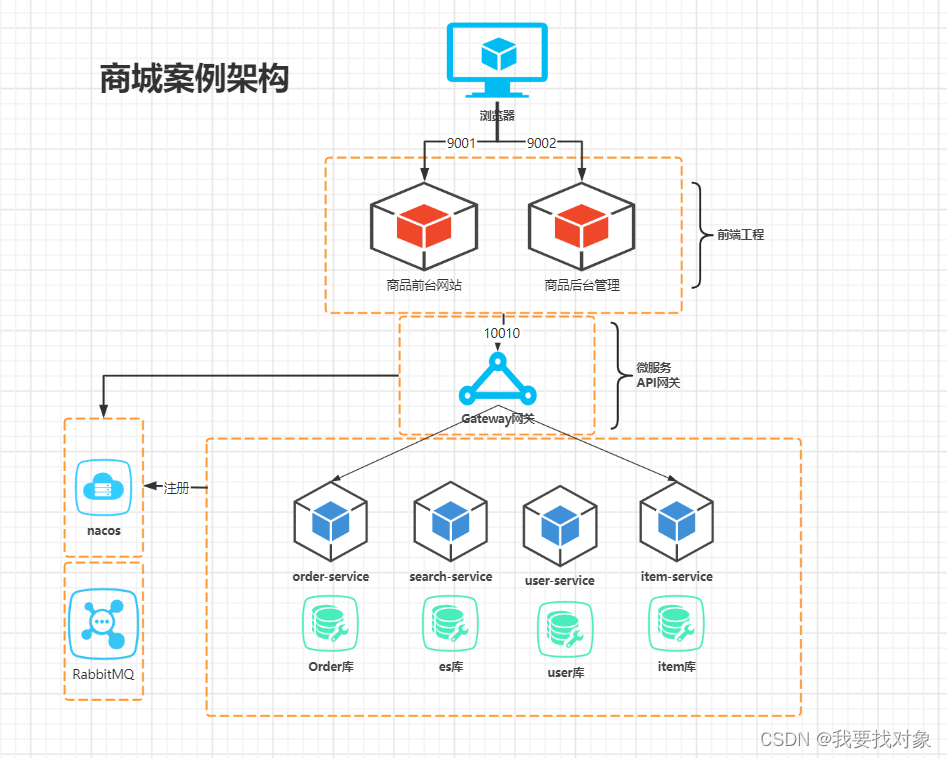
1.2 其他
1.2.1 数据库
User微服务:
- tb_address:用户地址表
- tb_user:用户表,其中包含用户的详细信息
商品微服务: - tb_item:商品表
订单微服务: - tb_order:用户订单表
- tb_order_detail:订单详情表,主要是订单中包含的商品信息
- tb_order_logistics:订单物流表,订单的收货人信息
由于本次仅作为微服务技术的练习,就不分数据库了
1.2.2 后端部分
后端的除微服务的代码在这里不解释了
前三个微服务代表feign(负责微服务调用),网关,实体
后面四个就是订单、商品、用户、es搜索的微服务
1.2.2.1 复习feign
在这里稍微复习下springcloud种的feign的内容
我们一开始,实现微服务之间相互调用使用的是RestTemplate,大概的步骤就是:

而RestTemplate有几个缺点:
•代码可读性差,编程体验不统一
•参数复杂URL难以维护
因此我们选择Feign替代RestTemplate
那么使用Feign的第一步就是引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
第二步骤:添加注解
假如某个微服务需要调用另一个微服务的内容,那么就在调用方的springboot Application类上添加注解即可
这里的案例是order微服务调用user微服务
第三步骤:编写Feign服务端
我们需要在调用方微服务下创建一个接口:
@FeignClient("userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
其中@FeignClient注解表示调用微服务的名称(在yaml文件所声明的),@GetMapping和@PathVariable与SpringMvc的用法一样,声明请求方法、请求路径 和 传入请求参数
- 服务名称:userservice
- 请求方式:GET
- 请求路径:/user/{id}
- 请求参数:Long id
- 返回值类型:User
这样,Feign就可以帮助我们发送http请求,无需自己使用RestTemplate来发送了。
第四步骤:发送请求
修改order-service中的OrderService类中的queryOrderById方法,使用Feign客户端代替RestTemplate:
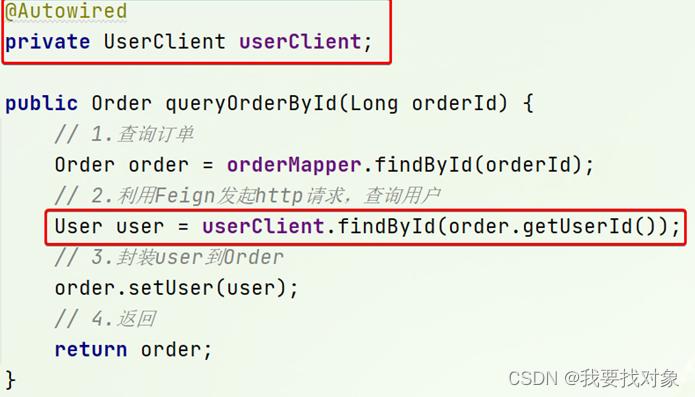
这里只回顾下基本用法,Feign的高级用法不多赘述
1.2.2.2 复习下网关
网关的核心功能特性:
-
权限控制:网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。
-
路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。当然路由的目标服务有多个时,还需要做负载均衡。
-
限流:当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。
网关的架构图如下:
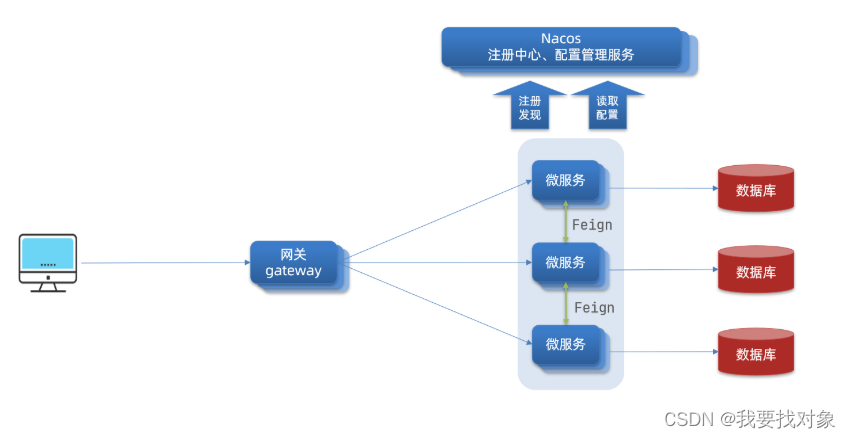
使用Gateway步骤一 引入依赖:
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
步骤二 编写SpringBoot启动类:
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
步骤三 编写基础配置和路由规则
创建配置文件application.yml,内容如下:
server:
port: 10010 # 网关端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 网关路由配置
- id: user-service # 路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址
uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
这个配置文件的功能就是将 /user/**开头的请求,代理到lb://userservice,lb是负载均衡,根据服务名拉取服务列表,实现负载均衡。
网关路由的流程
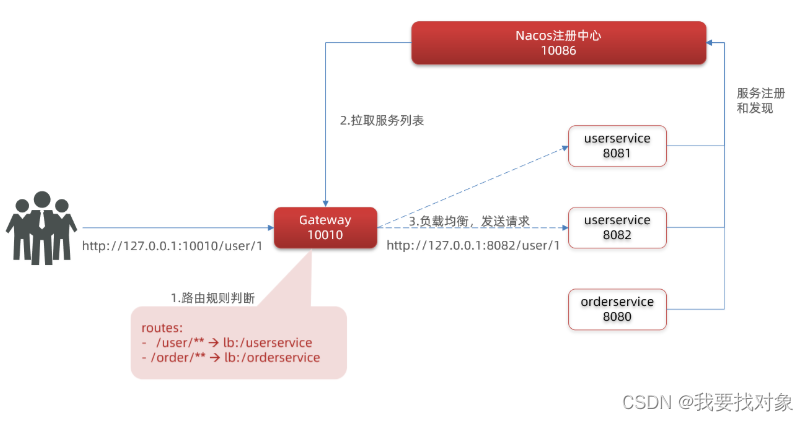
这张图就简述了网关的工作流程,首先收到用户请求,回去nacos注册中心拉去服务列表,根据用户的请求地址和routes规则进行判断,进行负载均衡,并且向目标微服务发送请求。
总结:
网关搭建步骤:
- 创建项目,引入nacos服务发现和gateway依赖
- 配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:
- 路由id:路由的唯一标示
- 路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
- 路由断言(predicates):判断路由的规则,
- 路由过滤器(filters):对请求或响应做处理
断言工厂
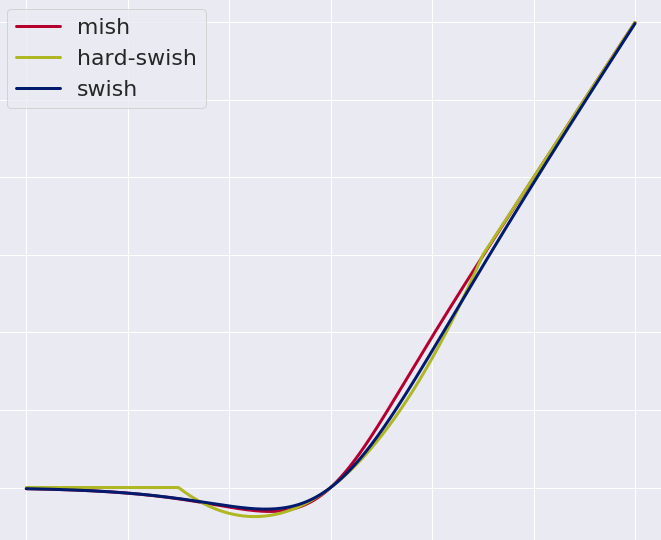
简单了解即可,我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件,例如Path=/user/**是按照路径匹配,这个规则是由
org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来处理的
过滤器工厂
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:
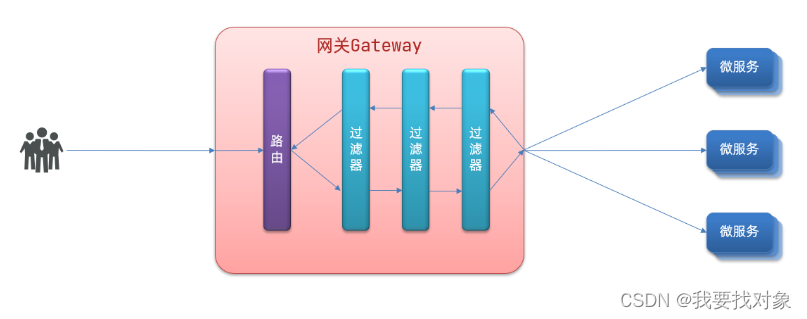
Spring提供了31种不同的路由过滤器工厂,例如:
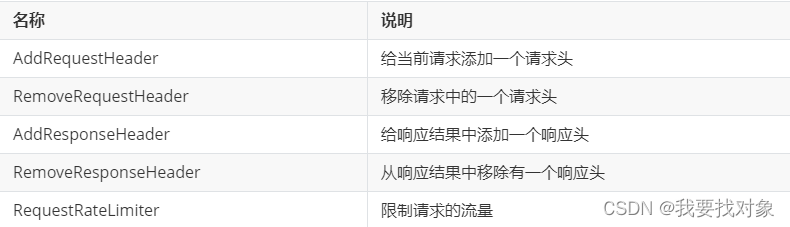
例如对于AddRequestHeader,使用非常简单,只需要修改gateway服务的application.yml文件,添加路由过滤即可:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
filters: # 过滤器
- AddRequestHeader=Truth, lihao is freaking awesome! # 添加请求头
当前过滤器写在userservice路由下,因此仅仅对访问userservice的请求有效
全局过滤器
虽然过滤器工厂提供了31种过滤器,但每一种过滤器的作用都是固定的。如果我们希望拦截请求,做自己的业务逻辑则没办法实现。
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
步骤一 全局过滤器的定义
定义方式是实现GlobalFilter接口
public interface GlobalFilter {
/**
* 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理
*
* @param exchange 请求上下文,里面可以获取Request、Response等信息
* @param chain 用来把请求委托给下一个过滤器
* @return {@code Mono<Void>} 返回标示当前过滤器业务结束
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
步骤二 自定义全局过滤器
例如:
定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:
- 参数中是否有authorization,
- authorization参数值是否为admin
如果同时满足则放行,否则拦截
实现就是在gateway中定义一个过滤器:
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求参数
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.获取authorization参数
String auth = params.getFirst("authorization");
// 3.校验
if ("admin".equals(auth)) {
// 放行
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
// 4.2.结束处理
return exchange.getResponse().setComplete();
}
}
过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
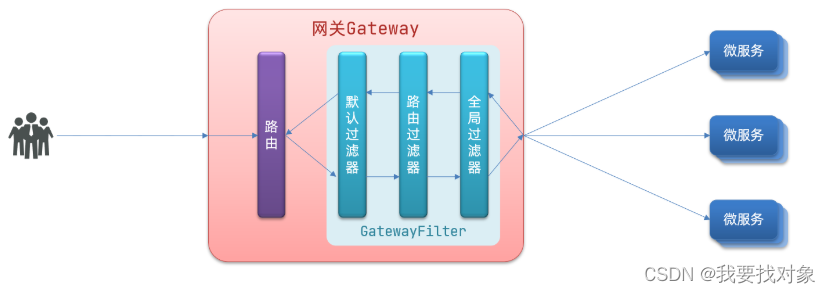
排序的规则是什么呢?
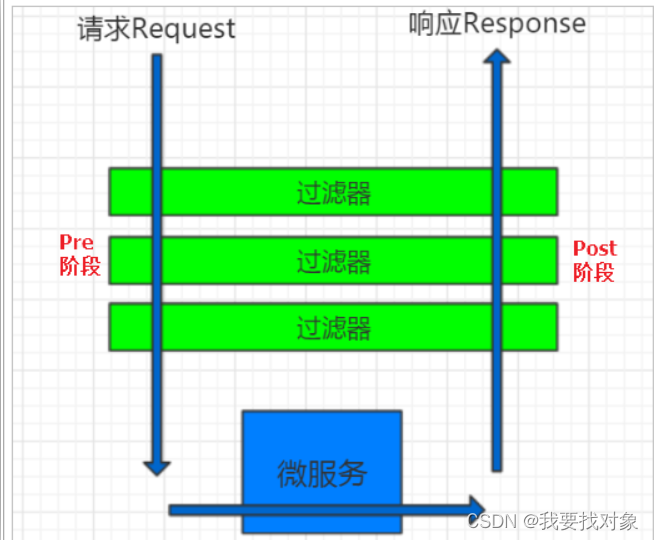
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
- 路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
- 当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。
具体执行过程如下:
解决跨域问题
跨域:域名不一致就是跨域,主要包括:
- 域名不同: www.taobao.com 和 www.taobao.org 和 www.jd.com 和 miaosha.jd.com
- 域名相同,端口不同:localhost:8080和localhost8081
跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
配置网关的yaml文件
spring:
cloud:
gateway:
# 。。。
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
- "http://localhost" //80端口要省略不写
- "http://127.0.0.1"
- "http://www.lhwebsite.com"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期-避免频繁发起跨域检测,服务端返回Access-Control-Max-Age来声明的有效期
1.2.2.3 es部分复习
因为本人刚刚复习完es项目,所以在这里不多赘述,如果有问题可以看es练习项目
1.2.3 前端部分
这里的细节也不过多赘述,通过nginx进行部署 ps:虚拟机内存不够了,就用windows的nginx部署模拟下得了

其中前端页面分为两部分:
- hm-mall-admin:后台的商品管理页面
- hm-mall-portal:用户入口,搜索、购买商品、下单的页面
具体页面展示如下:
用户端:
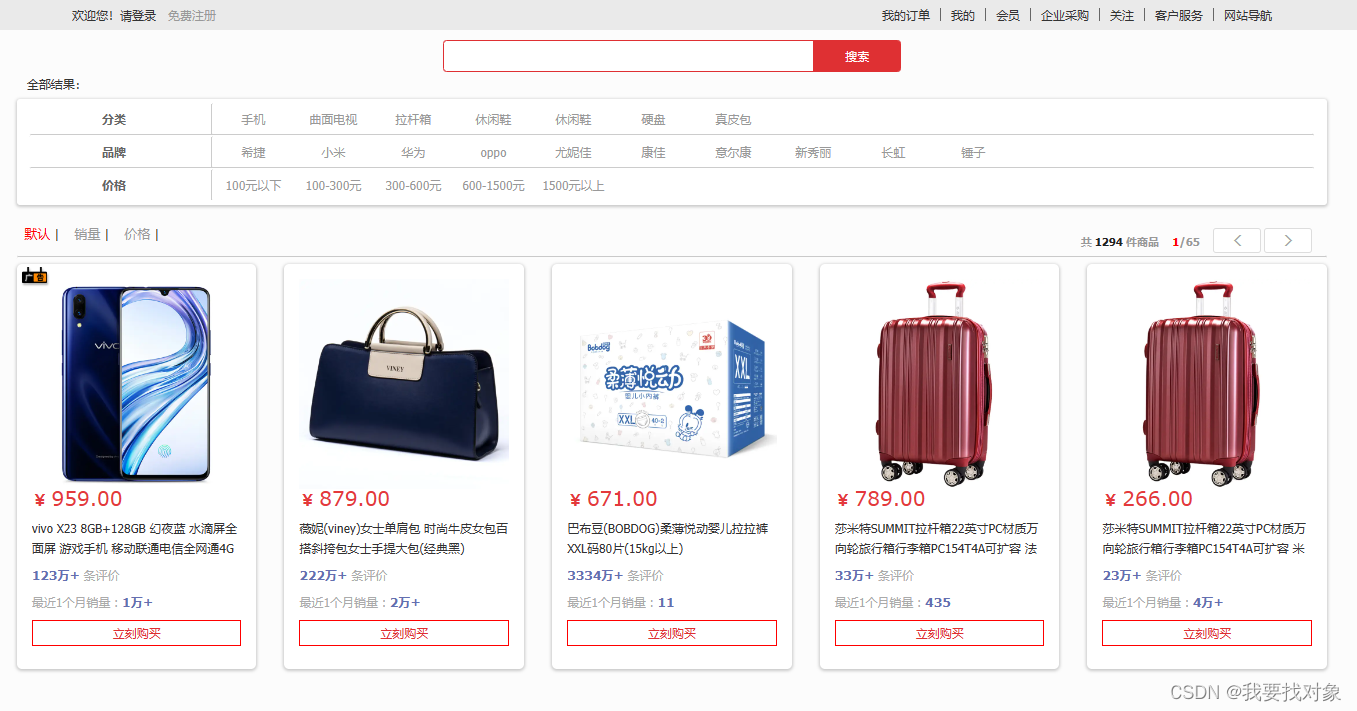
admin端:
2 day1 配置网关
2.1 任务
配置gateway网关,注册到nacos注册中心,并且在网关配置CORS
配置CORS跨域,允许4个地址跨域:
- http://localhost:9001
- http://localhost:9002
- http://127.0.0.1:9001
- http://127.0.0.1:9002
2.2 网关配置
# TODO 配置网关
server:
port: 10010
spring:
application:
name: gateway
cloud:
nacos:
server-addr: 10.5.32.199:8848
gateway:
routes:
- id: userservice
uri: lb://userservice
predicates:
- Path=/user/**,/address/**
- id: orderservice
uri: lb://orderservice
predicates:
- Path=/order/**,/pay/**
- id: itemservice
uri: lb://itemservice
predicates:
- Path=/item/**
- id: searchservice
uri: lb://searchservice
predicates:
- Path=/search/**
default-filters:
- AddRequestHeader=authorization,2
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:9001"
- "http://localhost:9002"
- "http://127.0.0.1:9001"
- "http://127.0.0.1:9002"
allowedMethods: "*"# 允许的跨域ajax的请求方式
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期-避免频繁发起跨域检测,服务端返回Access-Control-Max-Age来声明的有效期
3 day2 商品管理业务
3.1 今日需求分析
- 商品条件搜索以及分页查询
- 商品增删改操作
- 商品上下架操作
3.2 分页查询商品
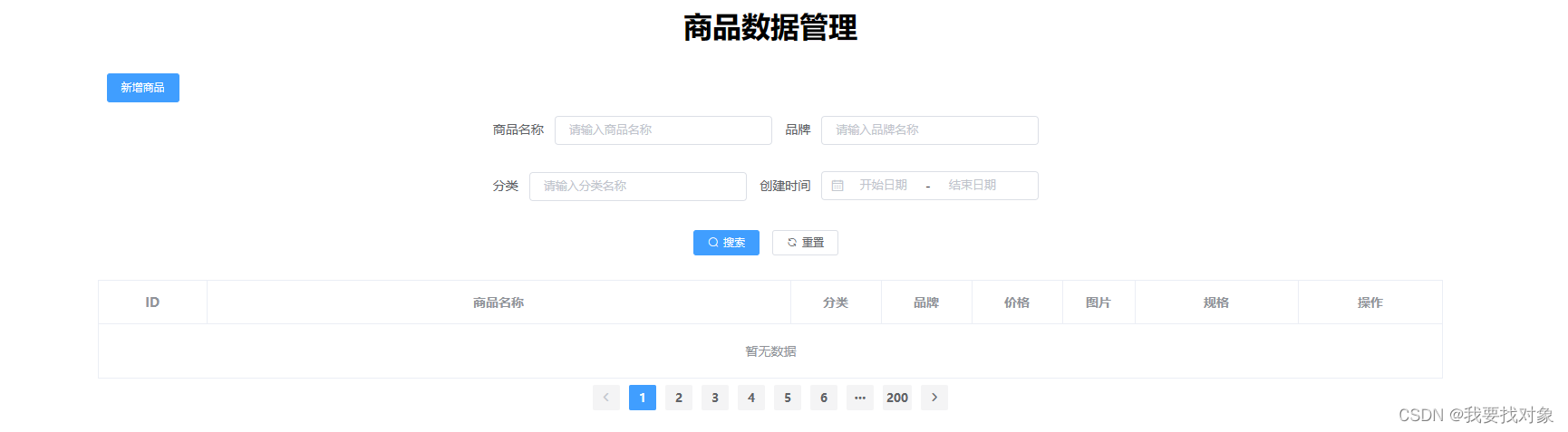
首先来分析下前端发出的request格式接受的response格式:

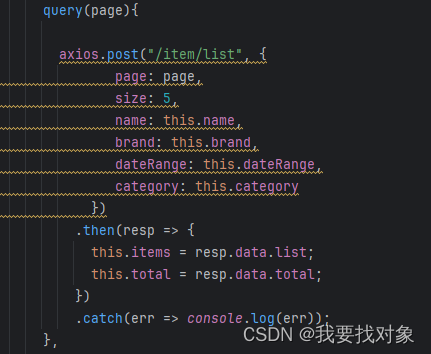 、
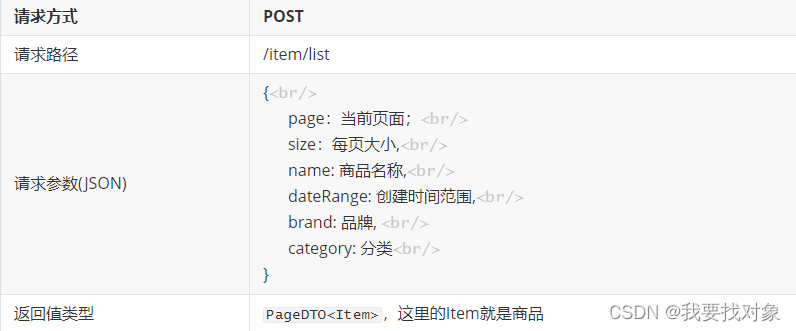
、
因此,我们可以得到请求接口的信息为:
3.2.1 实体类介绍
首先,我们看下response的pojo类,response两个参数,一个total表示查询到的数量,一个list表示商品列表
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageDTO<T> {
/**
* 总条数
*/
private Long total;
/**
* 当前页数据
*/
private List<T> list;
}
接下来再来看下request的pojo对象:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class SearchItemDTO {
private Integer page;
private Integer size;
private String name;
private Date beginDate;
private Date endDate;
private String brand;
private String category;
}
再来看下商品实体类:
@Data
@TableName("tb_item")
public class Item {
@TableId(type = IdType.AUTO)
private Long id;//商品id
private String name;//商品名称
private Long price;//价格(分)
private Integer stock;//库存数量
private String image;//商品图片
private String category;//分类名称
private String brand;//品牌名称
private String spec;//规格
private Integer sold;//销量
private Integer commentCount;//评论数
private Integer status;//商品状态 1-正常,2-下架
@TableField("isAD")
private Boolean isAD;//商品状态 1-正常,2-下架
private Date createTime;//创建时间
private Date updateTime;//更新时间
}
3.2.2 Controller Service 以及 持久层
持久层:
因为使用MP封装Service的方法,因此mapper接口只需要继承BaseMapper即可
public interface itemMapper extends BaseMapper<Item> {
}
controller层:
这里没有什么好说的
public class itemController {
@Autowired
private itemService itemservice;
/**
* 分页查询
* @param searchItemDTO
* @return
*/
@PostMapping ("/list")
public PageDTO<Item> selectList(@RequestBody SearchItemDTO searchItemDTO){
return itemservice.selectList(searchItemDTO);
}
}
Service层:
@Transactional用于数据库操作的事务管理,在使用MP封装Service的方法的过程中,Service接口的实现类需要继承ServiceImpl<?,?>,先创建LambdaQueryWrapper对象,之后对每一项进行判断,如果不为空就将条件写入wrapper,之后返回结果。
@Service
@Transactional(propagation = Propagation.REQUIRED, readOnly = false)
public class itemServiceImpl extends ServiceImpl<itemMapper,Item> implements itemService {
/**
* 实现分页查询
* @param dto
* @return
*/
@Override
@Transactional(propagation = Propagation.REQUIRED, readOnly = false)
public PageDTO<Item> selectList(SearchItemDTO dto) {
LambdaQueryWrapper<Item> wrapper = Wrappers.lambdaQuery();
if(dto.getName() != null){
wrapper.like(Item::getName,dto.getName());
}
if(dto.getBrand() != null){
wrapper.like(Item::getBrand,dto.getBrand());
}
if(dto.getCategory() != null){
wrapper.like(Item::getCategory,dto.getCategory());
}
if(dto.getBeginDate() != null){
wrapper.ge(Item::getCreateTime,dto.getBeginDate());
}
if(dto.getEndDate() != null){
wrapper.le(Item::getCreateTime,dto.getEndDate());
}
Page<Item> pages = new Page<>(dto.getPage(), dto.getSize());
Page<Item> page = this.page(pages, wrapper);
return new PageDTO<Item>(page.getTotal(),page.getRecords());
}
}
3.2.3 实现效果
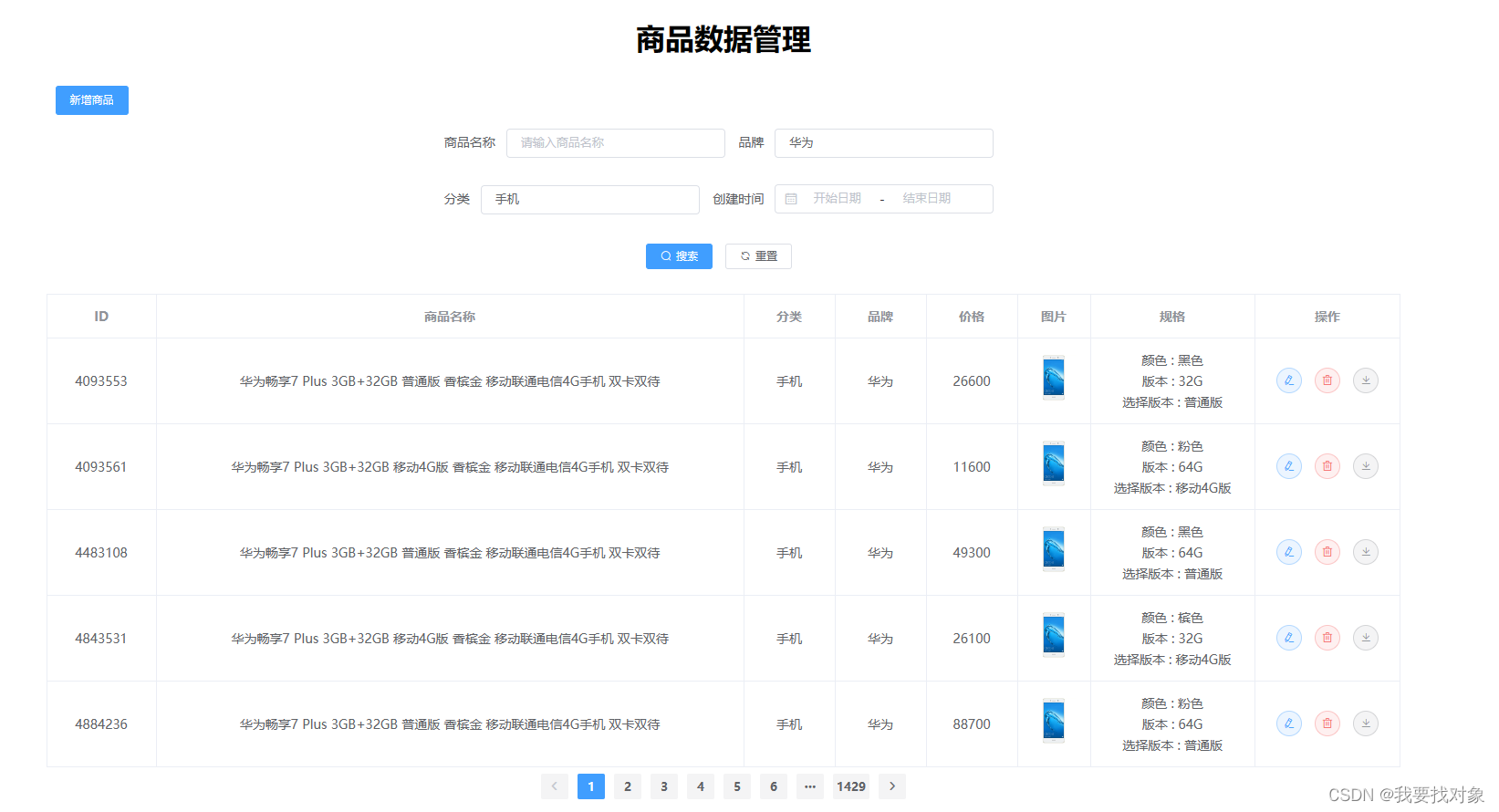
3.3 根据id查询商品
需要实现的接口如下:
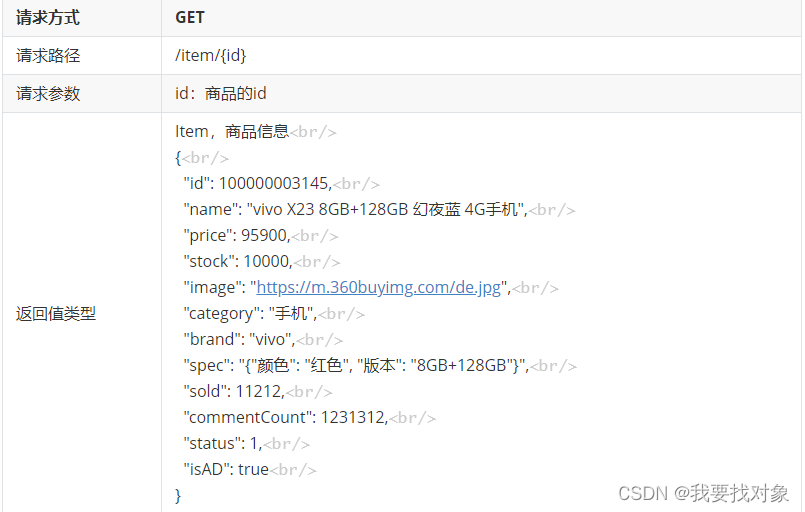
这个比较简单,直接放service代码了:
/**
* 根据id查询商品
* @param id
* @return
*/
@Override
public Item selectItemById(Long id) {
if(id == null){
throw new RuntimeException("id不能为空");
}
return this.getById(id);
}
3.4 新增商品
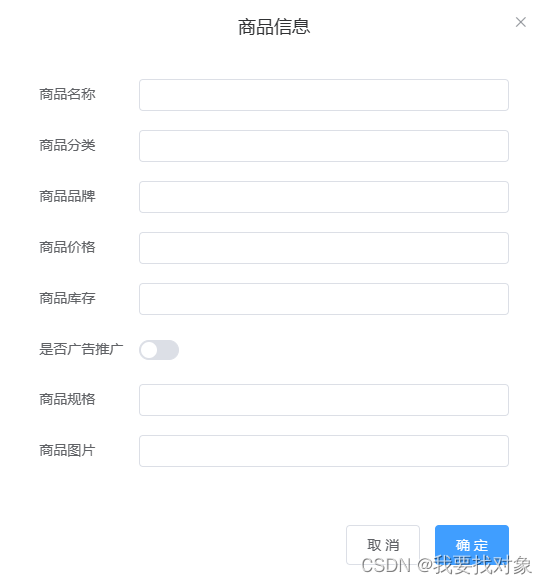
3.4.1 需求
点击admin页面的新增商品,出现以下窗口,之后填完提交成功新增即好:
那么再来分析下请求和响应格式:
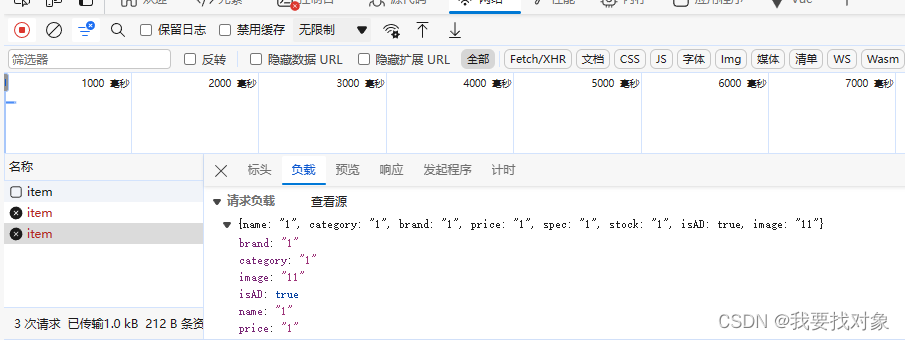
无返回值
总结下:
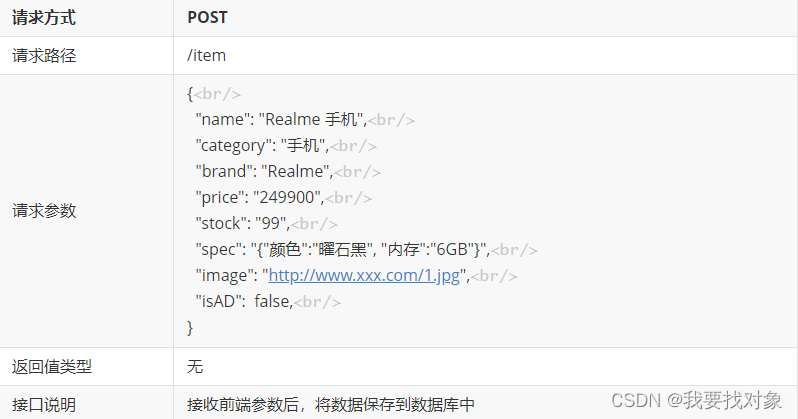
3.4.2 具体实现
这个也比较简单,直接上Service层代码了:
@PostMapping
public ResultDTO addItem(@RequestBody Item item){
itemservice.addItem(item);
return ResultDTO.ok();
}
3.5 商品上架、下架
3.5.1 需求
本商城设置的需求就是,必须先把商品下架,才能对商品进行编辑和删除

下架请求:
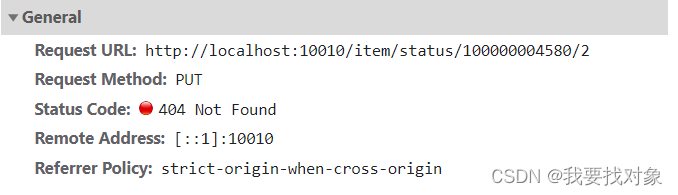
上架请求:
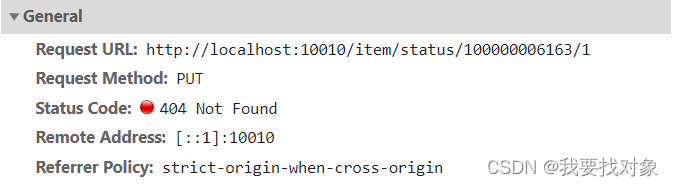
因此,接口大概为:
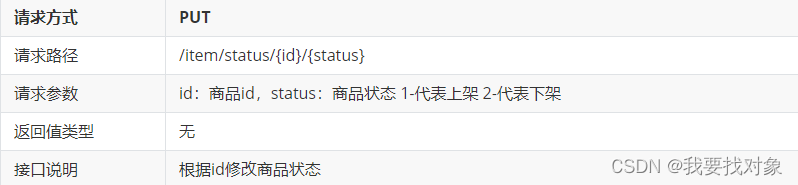
3.5.2 实现
Controller层实现如下:
@PutMapping("/status/{id}/{status}")
public ResultDTO updateStatus(@PathVariable("id") Long id,@PathVariable("status") Integer status){
try {
itemservice.updateStatus(id, status);
return ResultDTO.ok();
} catch (Exception e) {
e.printStackTrace();
return ResultDTO.error("修改上下架状态失败,原因是:" + e.getMessage());
}
}
Service层实现如下:
/**
* 上下架
* @param id
* @param status
*/
@Override
public void updateStatus(Long id, Integer status) {
if(id == null || status == null){
throw new RuntimeException("id或status不能为空");
}
if (status != 2 && status != 1) {
throw new RuntimeException("状态错误");
}
LambdaUpdateWrapper<Item> warpper = Wrappers.lambdaUpdate();
warpper.eq(Item::getId,id);
warpper.set(Item::getStatus,status);
this.update(null,warpper);
}
3.5 修改商品属性
3.5.1 需求
点击商品的编辑按钮:

对商品进行信息的编辑:
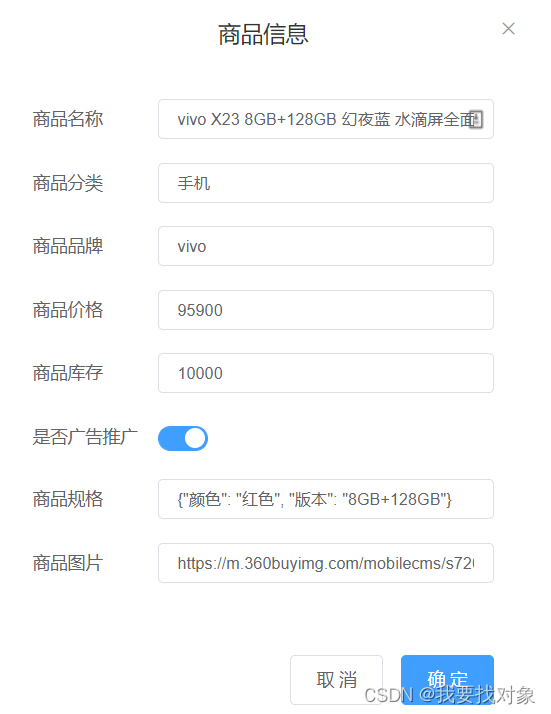
点击确定按钮后,即可提交信息。在控制台可以看到请求信息:
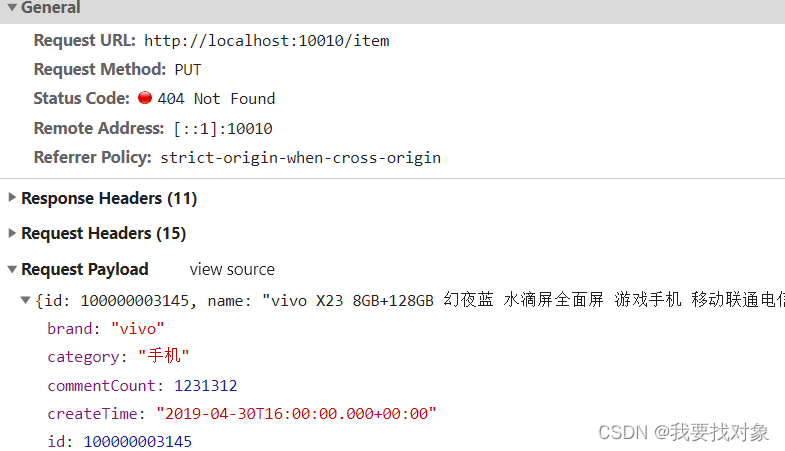
因此,我们可以得到接口需求为:
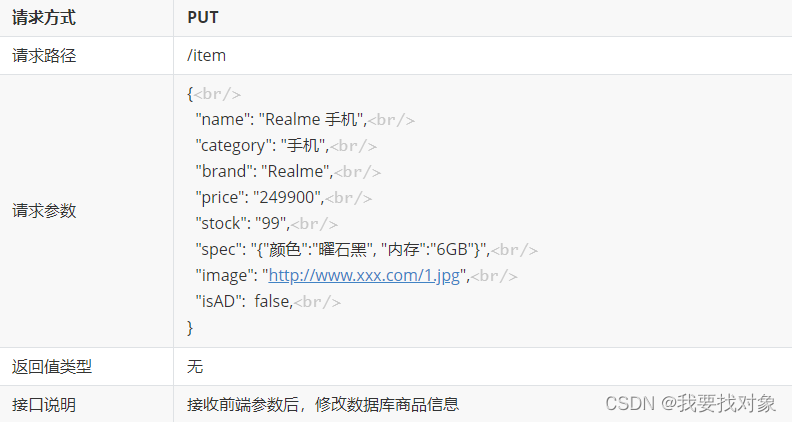
3.5.1 实现
这个实现也很简单
Controller:
/**
* 修改商品信息
* @param item
* @return
*/
@PutMapping
public ResultDTO updateItem(@RequestBody Item item){
try {
itemservice.updateItem(item);
return ResultDTO.ok();
} catch (Exception e) {
e.printStackTrace();
return ResultDTO.error("修改商品失败,原因是:" + e.getMessage());
}
}
Service:
/**
* 修改商品信息
* @param item
*/
@Override
public void updateItem(Item item) {
this.updateById(item);
}
3.6 删除商品
3.6.1 需求
点击删除按钮进行删除商品
请求如下:
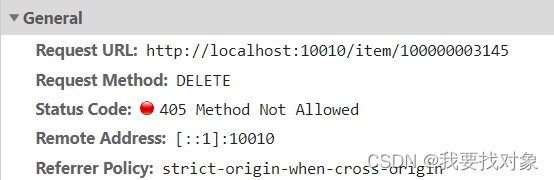
因此,接口的定义如下:
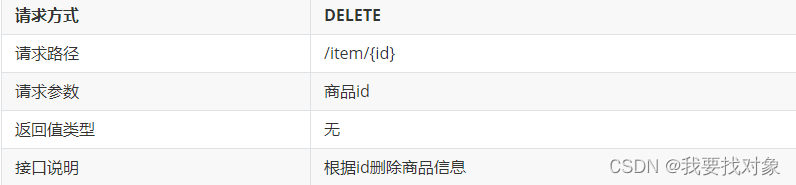
在这里先不做逻辑删除,直接删除数据库数据
3.6.2 实现
这个实现也很简单
Controller:
@DeleteMapping("/{id}")
public ResultDTO deleteItemById(@PathVariable("id") Long id){
try {
itemservice.deleteItemById(id);
return ResultDTO.ok();
} catch (Exception e) {
e.printStackTrace();
return ResultDTO.error("删除商品失败,原因是:" + e.getMessage());
}
}
Service:
/**
* 根据id删除商品
* @param id
*/
@Override
public void deleteItemById(Long id) {
this.removeById(id);
}
4 day3 完成User页面的搜索需求
首先,我们先设计一下搜索功能的架构:
- 首先将mysql数据导入es的doc
- 商品的上下架功能也需要修改:商品下架后,用户不能通过es搜索到该商品,因此,需要通过MQ通知es微服务
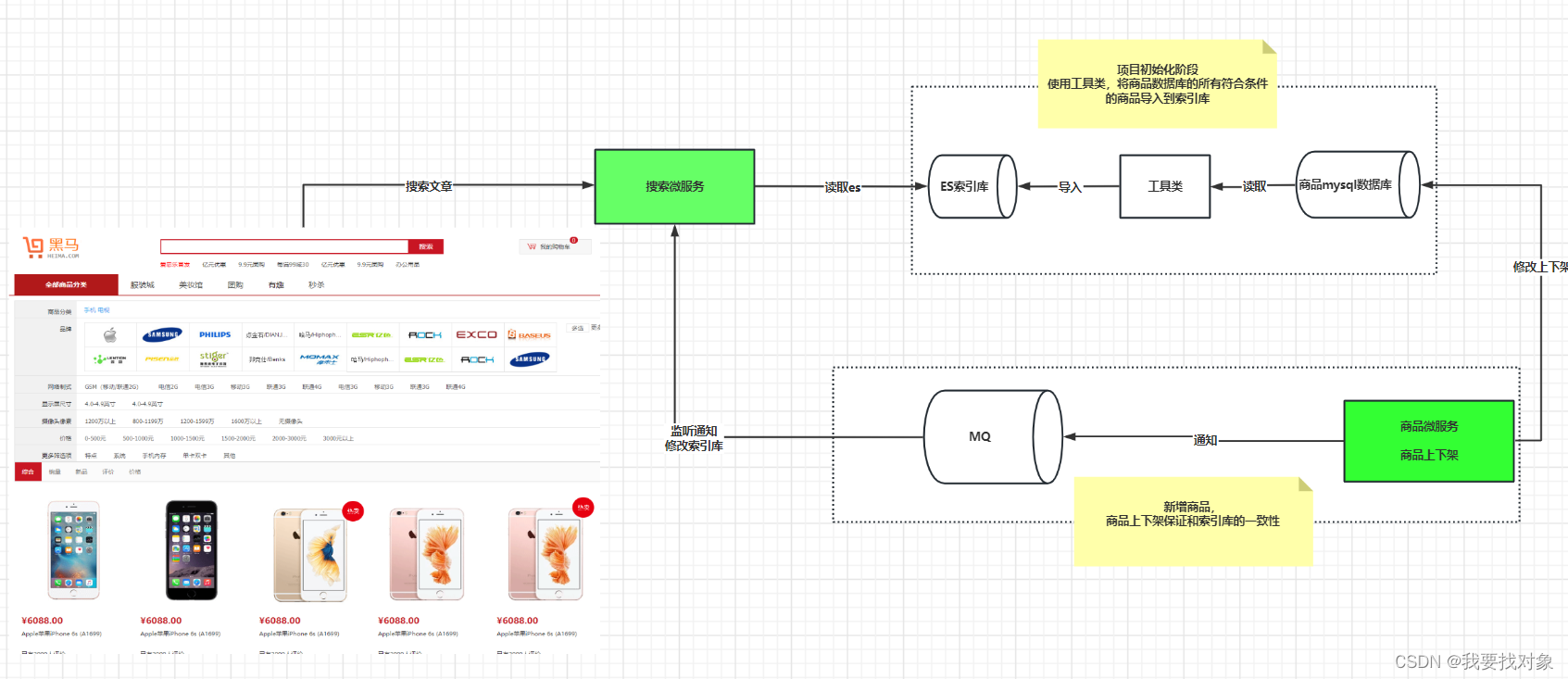
大概的业务需求为: - 设计索引库数据结构
- 完成数据导入
- 实现搜索栏自动补全功能
- 实现过滤项聚合功能
- 实现基本搜索功能
- 数据同步
4.1 设计索引库数据结构
基本字段包括:
- 分类
- 品牌
- 价格
- 销量
- id
- name
- 评价数量
- 图片
- 用于关键字全文检索的字段All,里面包含name、brand、category信息
- 用于自动补全的字段,包括brand、category信息
那么需要完成两件事情:
- 根据每个字段的特征,设计索引库结构 mapping。
- 根据索引库结构,设计文档对应的Java类:ItemDoc
索引库结构实体类:
@Data
@NoArgsConstructor
public class ItemDoc {
private Long id;
private String name;
private Long price;
private String image;
private String category;
private String brand;
private Integer sold;
private Integer commentCount;
//是否广告
private Boolean isAD;
//自动补全
private List<String> suggestion = new ArrayList<>(2);
//自动补全包括 商标 分类
public ItemDoc(Item item) {
// 属性拷贝
BeanUtils.copyProperties(item, this);
// 补全
suggestion.add(item.getBrand());
suggestion.add(item.getCategory());
}
}
创建item索引库:
PUT /item
{
"settings": {
"analysis": {
"analyzer": {
//对于属性建立倒排索引时使用的analyzer 既进行细粒度分词也进行拼音分词
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
//用于自动补全的analyzer,只对关键字进行拼音分词
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"image":{
"type": "keyword",
"index": false
},
"price":{
"type": "long"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"category":{
"type": "keyword",
"copy_to": "all"
},
"sold":{
"type": "integer"
},
"commentCount":{
"type": "integer"
},
"isAd":{
"type": "boolean"
},
//建立倒排索引使用text_anlyzer
//搜索时只使用ik_smart分词
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
4.2 mysql数据导入es的doc
这部分任务大概有以下步骤:
-
1)将商品微服务中的分页查询商品接口定义为一个FeignClient,放到feign-api模块
-
2)搜索服务编写一个业务,实现下面功能:
- 调用item-service提供的FeignClient,分页查询商品
PageDTO<Item> - 将查询到的商品封装为一个
ItemDoc对象,放入ItemDoc集合 - 将
ItemDoc集合批量导入elasticsearch的doc中
(注:为什么不直接findall查询所有数据一次性导入?答:可以,但是由于本人于学习阶段使用的虚拟机,因此这个操作可能机器扛不住,造成超时卡死等等)
- 调用item-service提供的FeignClient,分页查询商品
定义FeignClient
@FeignClient("itemservice")
public interface ItemClient {
/**
* 查询商品列表
* @param params
* @return
*/
@GetMapping("/item/list")
public PageDTO<Item> selectList(@RequestBody SearchItemDTO params);
/**
* 根据id 查询商品信息
* @param id
* @return
*/
@GetMapping("/item/{id}")
public Item selectItemById(@PathVariable("id")Long id);
/**
* 扣减商品库存
* @param itemId
* @param num
*/
@PutMapping("/item/stock/{itemId}/{num}")
public void deleteStock(@PathVariable("itemId") Long itemId ,@PathVariable("num")Integer num);
/**
* 增加商品库存
* @param id
* @param num
*/
@RequestMapping("/item/stock/add/{id}/{num}")
void addStock(@PathVariable("id") Long id,@PathVariable("num")Integer num);
}
将数据分批次导入doc
再复习下如何批量导入es的doc吧
首先要通过FeignClient调用item微服务的分页查询方法,设置PageSize为1000就表示一次导入1000条数据,之后将1000条数据封装到itemDoc实体类中,放入IndexRequest对象,再创建批量操作BulkRequest对象,将数据一条条的放进去,1000条全部放进去后,向es进行导入,直到调用itemClient方法取不出数据时,说明全部导入完成。
@RestController
@Slf4j
@RequestMapping("/search")
public class SearchController {
@Autowired
private ItemClient itemClient;
@Autowired
private RestHighLevelClient client;
@GetMapping("/importItemData")
public ResultDTO importItemData(){
try {
int page = 1;
int size = 1000;
while(true){
BulkRequest bulkRequest = new BulkRequest("item");
SearchItemDTO searchItemDTO = new SearchItemDTO();
searchItemDTO.setPage(page);
searchItemDTO.setSize(size);
PageDTO<Item> itemPageDTO = itemClient.selectList(searchItemDTO);
List<Item> list = itemPageDTO.getList();
if(list.size() > 0){
for (Item item : list) {
IndexRequest request = new IndexRequest("item");
ItemDoc itemDoc = new ItemDoc(item);
request.source(JSON.toJSONString(itemDoc), XContentType.JSON);
bulkRequest.add(request);
}
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println("第"+page+"批数据导入状态:"+response.status());
}else{
System.out.println("导入结束");
break;
}
page++;
}
return ResultDTO.ok();
}catch (Exception e){
e.printStackTrace();
return ResultDTO.error("批量导入es索引库数据失败");
}
}
}
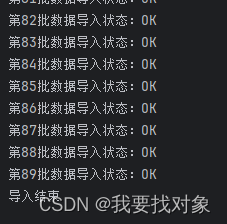

4.3 搜索栏自动补全功能
request需求如下:
再查看下前端界面,可得,要求返回的数据应该是一个列表,列表元素就是补充的内容:
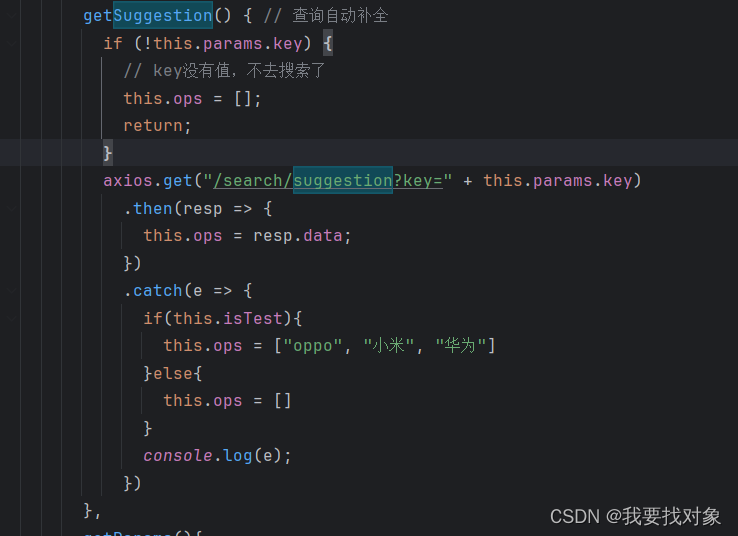
因此可以总结到:
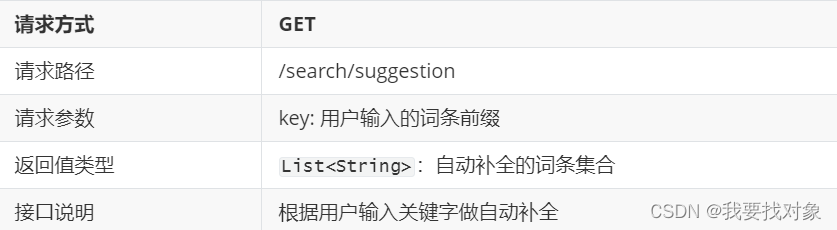
解决这个需求也非常简单,只需要获得输入框中的key,之后去item文档的suggestion字段进行查询,返回查询到的结果即可:
//补全
@Override
public List<String> getSuggestion(String key) {
try {
//准备请求
SearchRequest hotel = new SearchRequest("item");
//准备DSL
hotel.source().suggest(new SuggestBuilder().addSuggestion("suggestion",
SuggestBuilders.completionSuggestion
("suggestion").
prefix(key).//关键字
skipDuplicates(true)//跳过重复
.size(10)));
//发送请求
SearchResponse search = client.search(hotel, RequestOptions.DEFAULT);
List<String> list = new ArrayList<>();
//解析结果
Suggest suggest = search.getSuggest();
//根据补全查询名称,获取补全结果
CompletionSuggestion suggestion = suggest.getSuggestion("suggestion");
//获取options
List<CompletionSuggestion.Entry.Option> options = suggestion.getOptions();
//遍历
for (CompletionSuggestion.Entry.Option option : options) {
String text = option.getText().toString();
list.add(text);
}
return list;
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
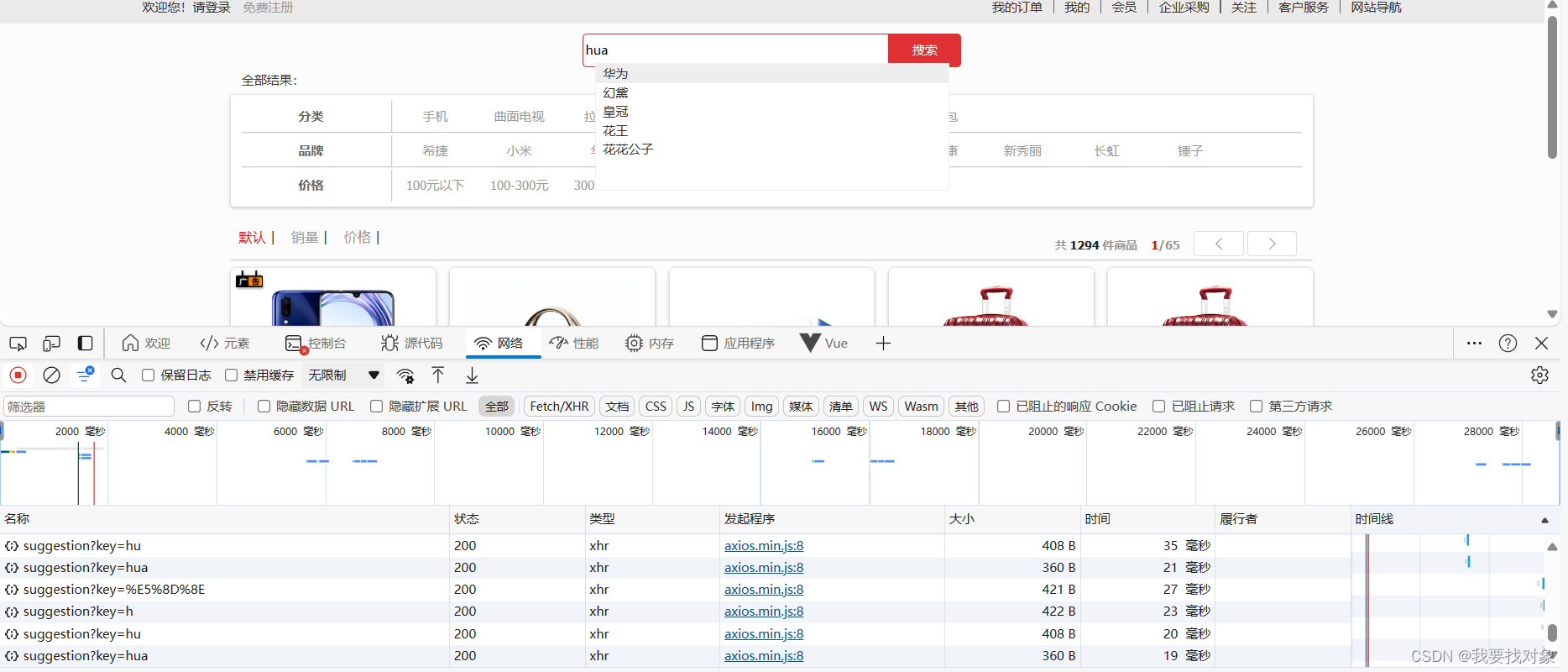
实现结果:
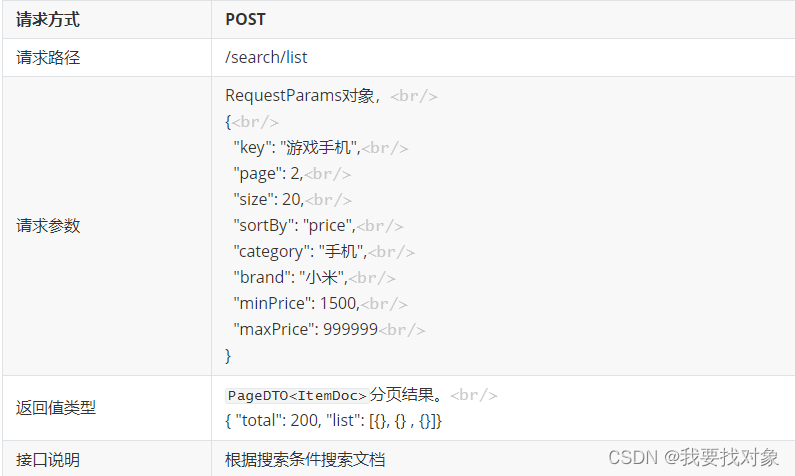
4.4 基本搜索功能(搜索/分页/高亮/算分查询/排序查询)
需求
首先还是看一下请求和响应的格式:
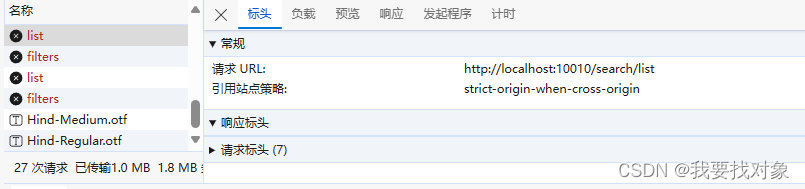


因此我们可以得到基本查询的格式为:
具体实现
首先看一下service层主代码:
@Override
public PageDTO<ItemDoc> getList(SearchReqDTO dto) {
try {
SearchRequest request = new SearchRequest("item");
buildBasicQuery(dto,request);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
return toPageResult(response);
}catch (Exception e){
throw new RuntimeException(e);
}
}
其中包含两个子函数,因为这两块代码在filters时也需要,所以封装起来了
第一个方法buildBasicQuery,通过dto中的各种条件构建request:
/**
* 根据条件构建request
* @param dto
* @param request
*/
public void buildBasicQuery(SearchReqDTO dto, SearchRequest request){
//bool查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
String key = dto.getKey();
if(!StringUtils.isNotBlank(key)){
boolQueryBuilder.must(QueryBuilders.matchAllQuery());
}else{
boolQueryBuilder.must(QueryBuilders.termQuery("all",key));
}
String category = dto.getCategory();
if(StringUtils.isNotBlank(category)){
boolQueryBuilder.filter(QueryBuilders.termQuery("category",category));
}
String brand = dto.getBrand();
if(StringUtils.isNotBlank(brand)){
boolQueryBuilder.filter(QueryBuilders.termQuery("brand",brand));
}
if(dto.getMinPrice() != null && dto.getMaxPrice() != null){
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").lte(dto.getMaxPrice()).gte(dto.getMinPrice()));
}
//算分查询 判断isAD是否为true,为true及进行加分 没有设置方法就是相乘 乘以10
//并将bool查询封装到算分查询对象中
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(
boolQueryBuilder,new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("isAD",true), ScoreFunctionBuilders.weightFactorFunction(10))
}
);
request.source().query(functionScoreQueryBuilder);
//设置高亮
if(key != null){
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
}
//设置分页
Integer page = dto.getPage();
if(dto.getPage() == null){
page = 1;
}
Integer sizes = dto.getSize();
if(dto.getPage() == null){
sizes = 10;
}
request.source().from((page-1)*sizes).size(sizes);
//设置排序
if(dto.getSortBy().equals("price")){
request.source().sort("price", SortOrder.DESC);
}
if(dto.getSortBy().equals("sold")){
request.source().sort("sold",SortOrder.DESC);
}
}
第二个方法是toPageResult,用于将response转化为返回的对象类型:
由于有高亮的需求,因此需要先拿出ItemDoc对象,并且存入数据,之后假如有高亮,就提取出response中的高亮结果放入name中,之后以此放入List,再将total和list放人分页实体类返回即可
/**
* 解析查询后的响应结果
* @param response
* @return
*/
public PageDTO<ItemDoc> toPageResult(SearchResponse response){
PageDTO<ItemDoc> itemDocPageDTO = new PageDTO<>();
SearchHits hits = response.getHits();
long total = hits.getTotalHits().value;
itemDocPageDTO.setTotal(total);
SearchHit[] hits1 = hits.getHits();
List<ItemDoc> itemDocs = new ArrayList<>();
for (SearchHit documentFields : hits1) {
String sourceAsString = documentFields.getSourceAsString();
ItemDoc itemDoc = JSON.parseObject(sourceAsString, ItemDoc.class);
Map<String, HighlightField> highlightFields = documentFields.getHighlightFields();
if(!highlightFields.isEmpty()){
HighlightField name = highlightFields.get("name");
if(name != null){
String string = name.getFragments()[0].toString();
itemDoc.setName(string);
}
}
itemDocs.add(itemDoc);
}
itemDocPageDTO.setList(itemDocs);
return itemDocPageDTO;
}
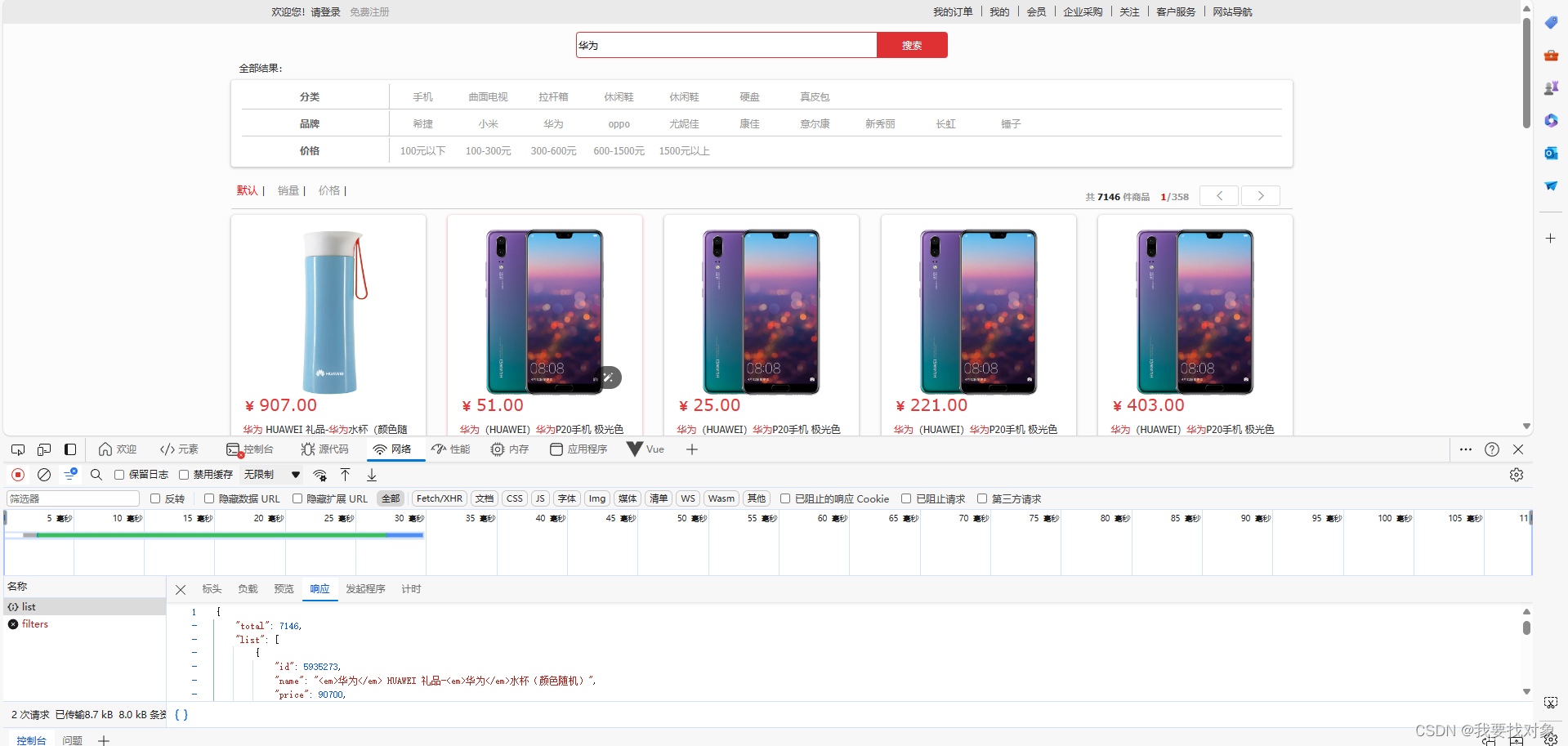
实现效果
4.5 查询选项过滤聚合
需求
我们下一步要做的这个需求如下:
可以看到,搜索框下有过滤选项,但是现在是前端写死的,即使你选择了手机,手机的品牌里面没有长虹,它也会显示长虹选项

老样子,看看请求和响应咋写:
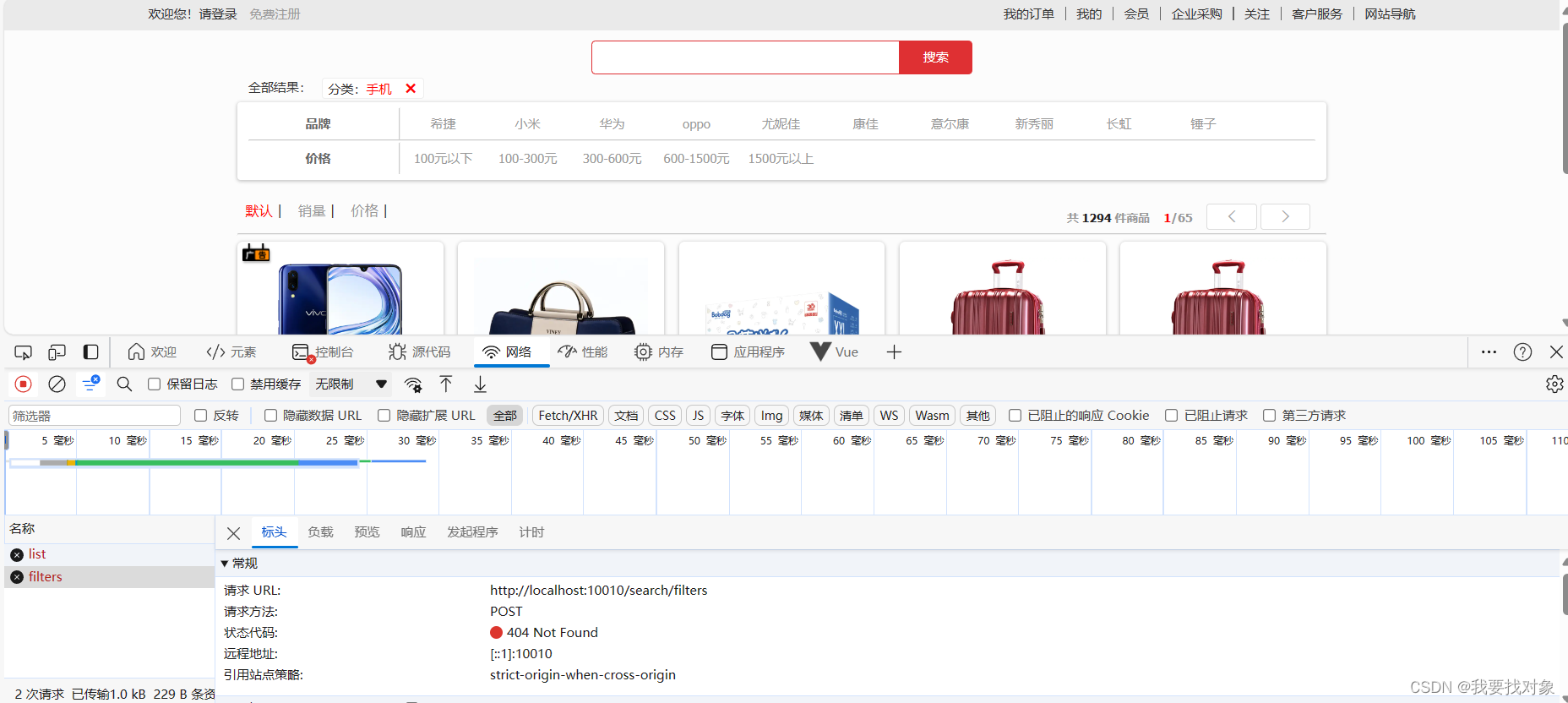
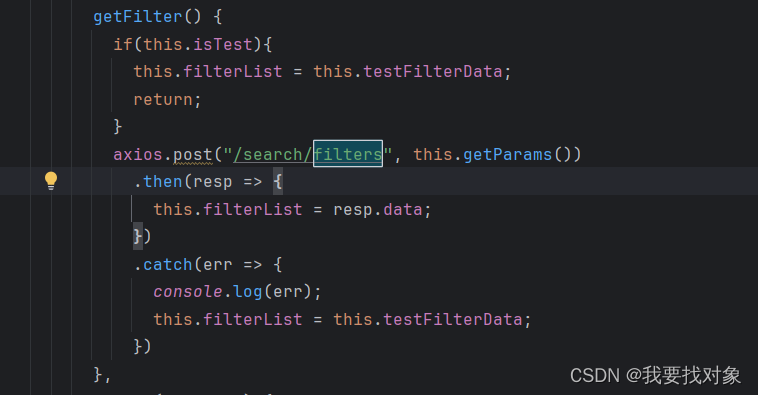

因此可以得出:
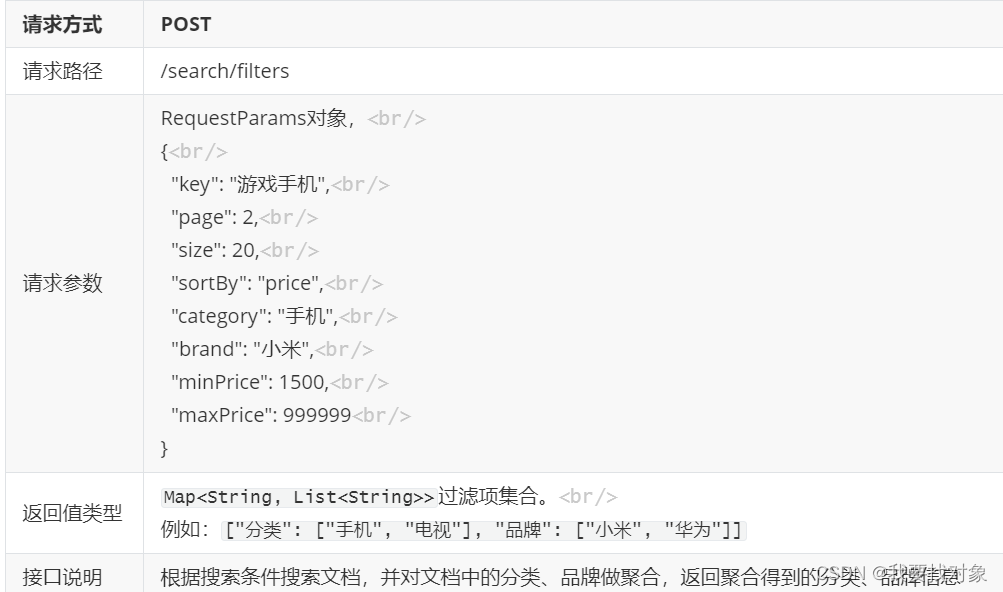
具体实现
这个需求主要就是进行下数据聚合:
/**
* 实现过滤操作
* @param reqDTO
* @return
*/
@Override
public Map<String, List<String>> getFilter(SearchReqDTO reqDTO) {
try {
SearchRequest request = new SearchRequest("item");
buildBasicQuery(reqDTO,request);
request.source().aggregation(AggregationBuilders.terms("brand").field("brand").size(10));
request.source().aggregation(AggregationBuilders.terms("category").field("category").size(10));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
List<String> brand = getAggList("brand", response);
List<String> category = getAggList("category", response);
Map<String,List<String>> map = new HashMap<>();
map.put("brand",brand);
map.put("category",category);
return map;
}catch (Exception e){
new RuntimeException(e);
}
return null;
}
其中getAggList方法会被多次调用因此为了提高可读性,封装为了方法,其方法的作用就是根据response和name取出response中聚合name种类的结果:
/**
* 解析聚合的结果
* @param name
* @param response
* @return
*/
public List<String> getAggList(String name,SearchResponse response){
List<String> list = new ArrayList<>();
Aggregations aggregations = response.getAggregations();
Terms aggregation = aggregations.get(name);
List<? extends Terms.Bucket> buckets = aggregation.getBuckets();
for (Terms.Bucket bucket : buckets) {
String string = bucket.getKeyAsString();
list.add(string);
}
return list;
}
实现效果
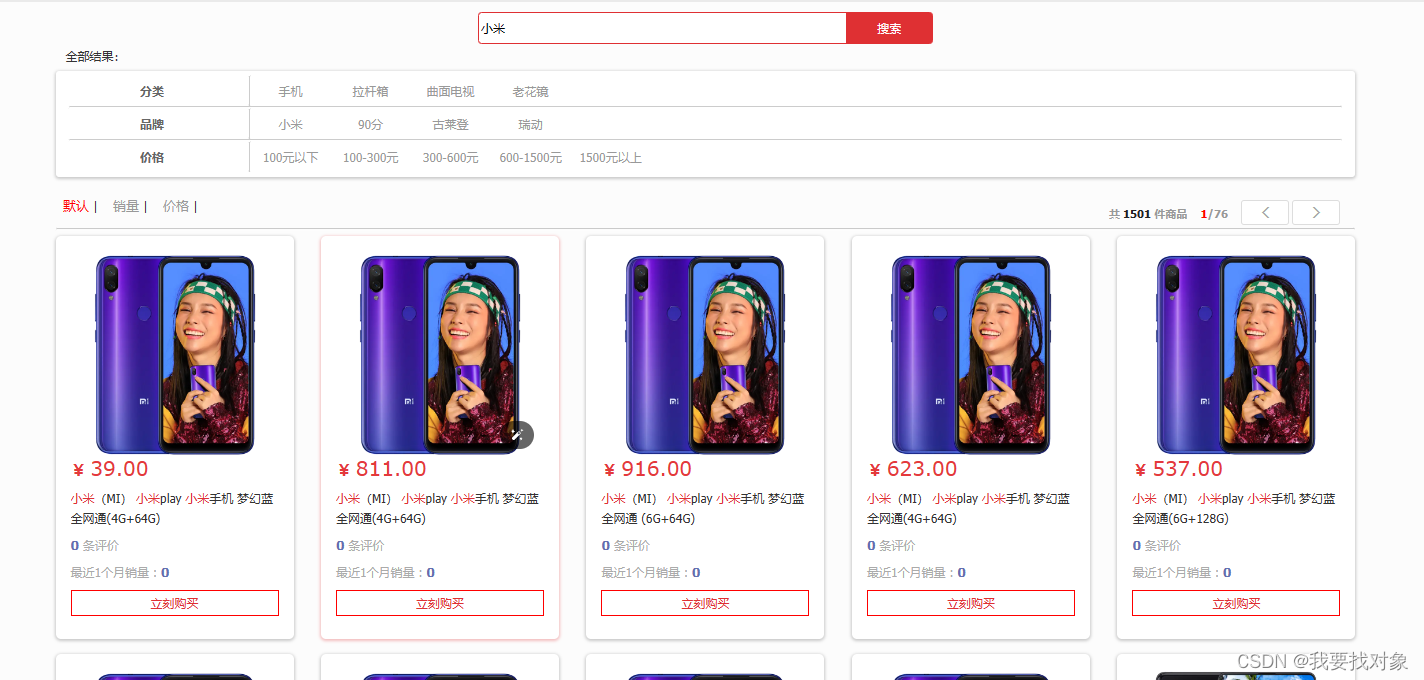
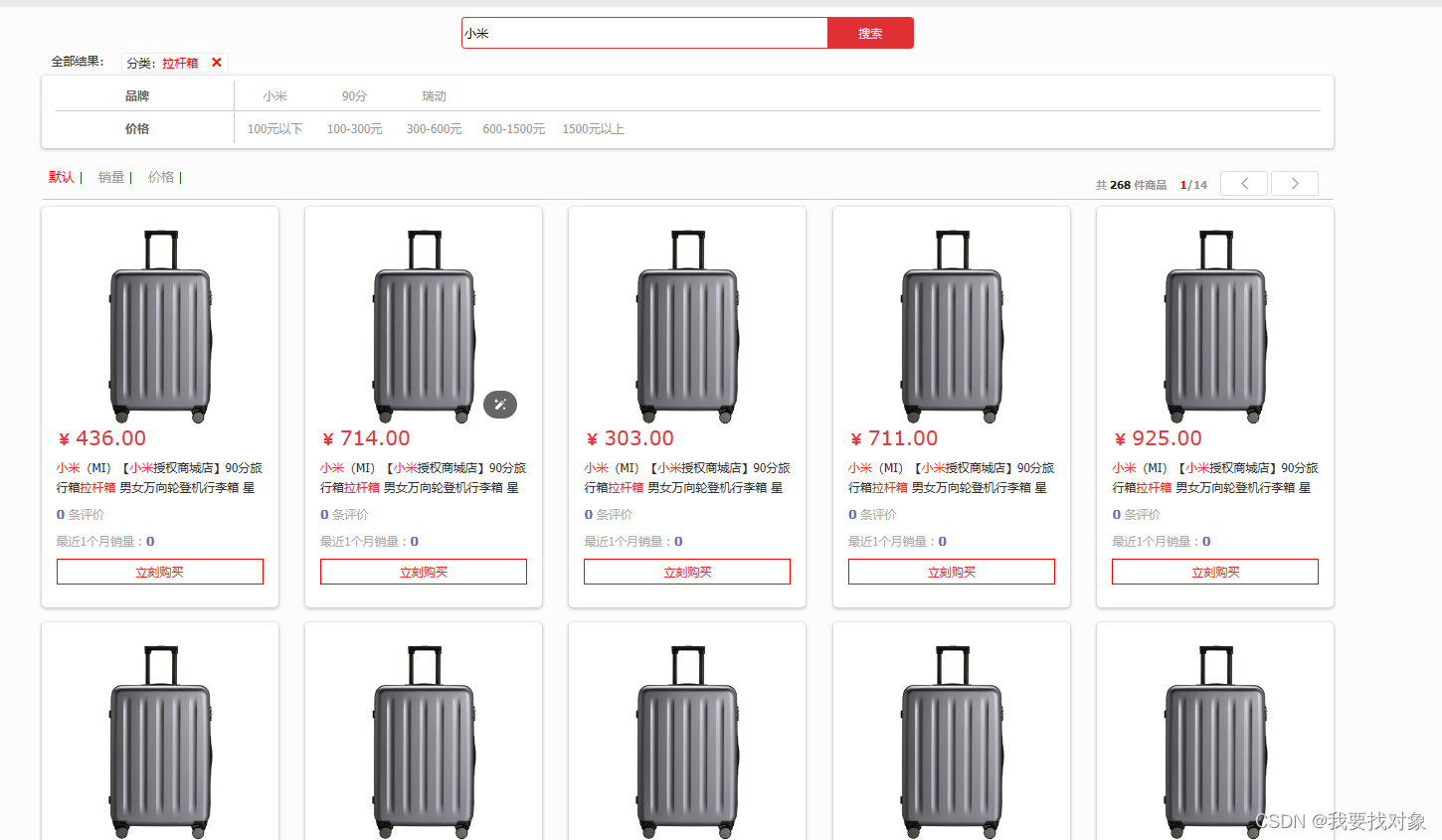
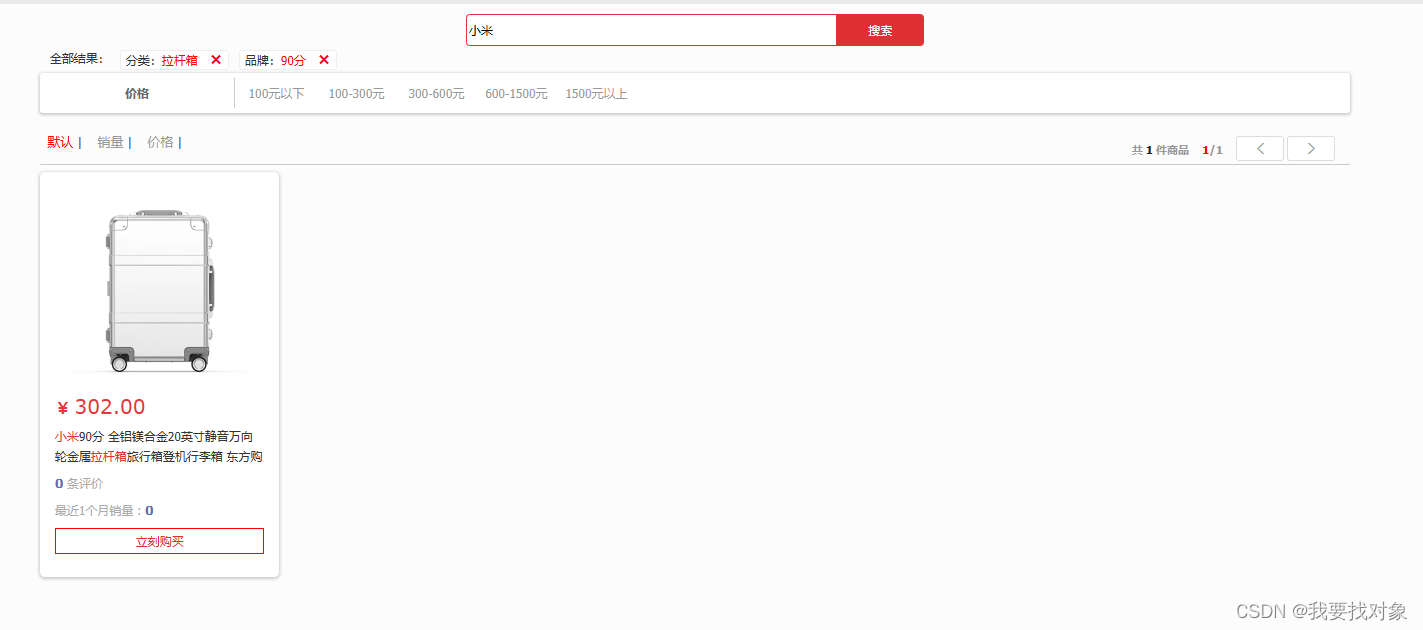
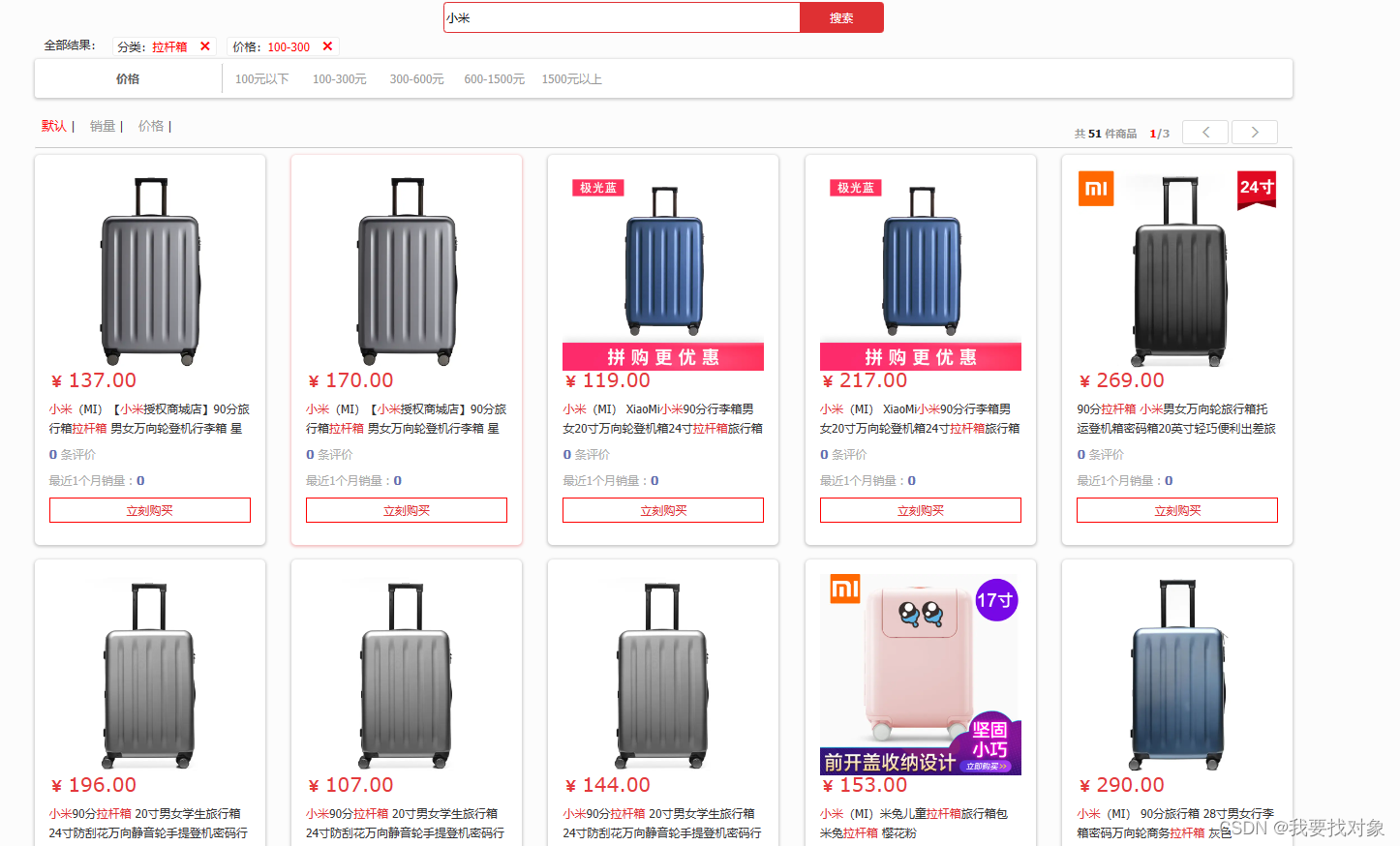
4.6 数据同步
需求
- 商品上架时:search-service新增商品到elasticsearch
- 商品下架时:search-service删除elasticsearch中的商品
实现
简单来说,以下架为例,当admin端点击下架一个商品时,ItemService会通过mq发出一条消息给SearchService,搜索微服务会将doc中的那条数据删除
其中,ItemService为生产者,SearchService为消费者,使用Topic交换机
首先在ItemService定义mq配置:
@Configuration
public class MyConfig {
/**
* 声明主题交换机
* @return
*/
@Bean
public TopicExchange topicExchange(){
return new TopicExchange("shop.topicExchange",true,false);
}
/**
* 上架队列
* @return
*/
@Bean
public Queue upItem(){
return new Queue("shop.upItem",true);
}
/**
* 下架队列
* @return
*/
@Bean
public Queue downItem(){
return new Queue("shop.downItem",true);
}
@Bean
public Binding bindingUpItem(){
return BindingBuilder.bind(upItem()).to(topicExchange()).with("up");
}
@Bean
public Binding bindingDownItem(){
return BindingBuilder.bind(downItem()).to(topicExchange()).with("down");
}
}
之后在SearchService设置监听配置:
@Component
public class MyListener {
@Autowired
private SearchService searchService;
@RabbitListener(queues = "shop.upItem")
public void listenUp(Long id){
searchService.deleteDoc(id);
}
@RabbitListener(queues = "shop.downItem")
public void listenDown(Long id){
searchService.insertDoc(id);
}
}
最后,再载service层写一下处理增删doc的代码:
@Override
public void insertDoc(Long id) {
try {
IndexRequest request = new IndexRequest("item").id(id.toString());
Item item = itemClient.selectItemById(id);
ItemDoc itemDoc = new ItemDoc(item);
request.source(JSON.toJSONString(itemDoc), XContentType.JSON);
client.index(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void deleteDoc(Long id) {
try {
DeleteRequest request = new DeleteRequest("item", id.toString());
client.delete(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
5 day4 完成用户登录和用户功能
5.1 微服务获取用户身份
由于本项目重点在于微服务,因此不做登录页面了,默认就是登陆的,只进行模拟一下获取用户信息
首先我们可以给每个用户添加一个用户id,当用户发送请求时,使用过滤器给所有经过网关的请求的请求头添加id值:
怎么做呢?来回忆下网关的GatewayFilter,其中有一种过滤器叫做AddRequestHeader可以给请求添加请求头,具体就是操作yaml配置文件:
default-filters:
- AddRequestHeader=authorization,2
那么添加了id后,订单微服务如何获取用户id呢?
- 在每个微服务都编写一个SpringMVC的拦截器:HandlerInterceptor
- 在拦截器中获取请求头中的authorization信息,也就是userId,并保存到ThreadLocal中
- 在后续的业务中,可以直接从ThreadLocal中获取userId
注:ThreadLocal时jdk的组件,可以存放当前线程的参数,因为一个用户访问其实就是一个线程嘛!
大概流程如下:
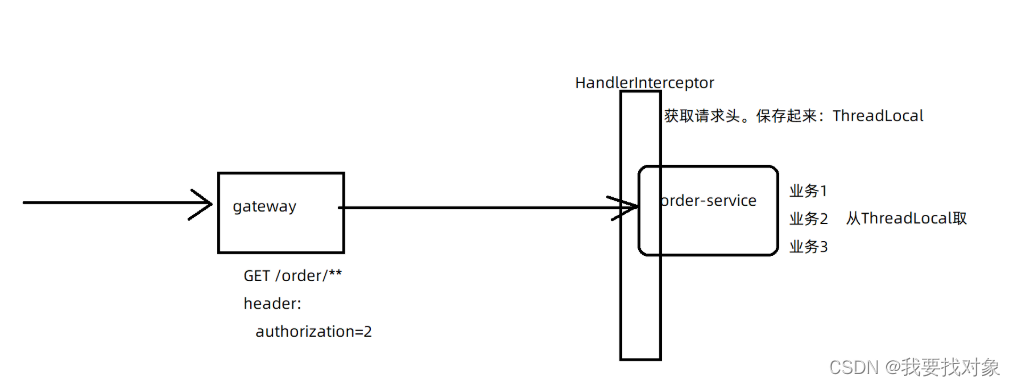
对于ThreadLocal的使用可以创建一个utils类:
/**
* 用于存储请求头中的userId信息
*/
public class ThreadLocalUtil {
private static final ThreadLocal<Long> local = new ThreadLocal<>();
/**
* 从当前线程中存储userId
* @param userId
*/
public static void setUserId(Long userId){
local.set(userId);
}
/**
* 从当前线程中获取userId
* @return
*/
public static Long getUserId(){
return local.get();
}
/**
* 从当前线程中清除userId
*/
public static void clear(){
local.remove();
}
}
那么先在订单微服务上写一个拦截器来获取用户id:
@Component
@WebFilter(filterName = "authorFilter",urlPatterns = "/*")
public class AuthorFilter extends GenericFilter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
// 获取从网关传递过来的登录用户id
String authorization = request.getHeader("authorization");
if(StringUtils.isNotBlank(authorization)){
// 如果用户id不为空 设置到ThreadLocal中
ThreadLocalUtil.setUserId(Long.valueOf(authorization));
}
filterChain.doFilter(servletRequest,servletResponse);
ThreadLocalUtil.clear();
}
}
到这里,订单微服务就可以获取到操作用户的id了
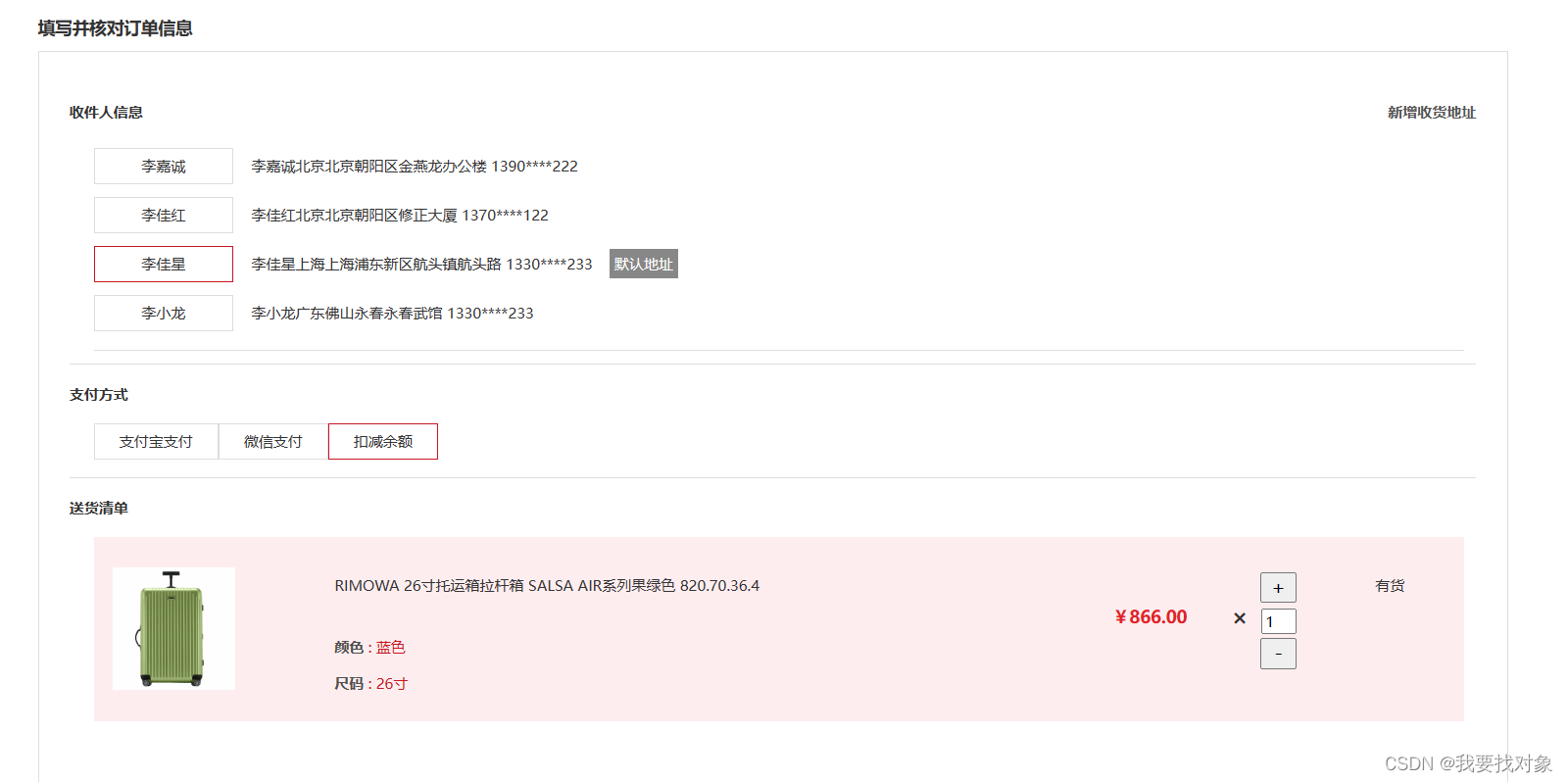
5.2 根据用户id查询地址列表
需求分析
当用户点击购买商品,跳转到用户的订单确认页面,需要出现用户的地址:
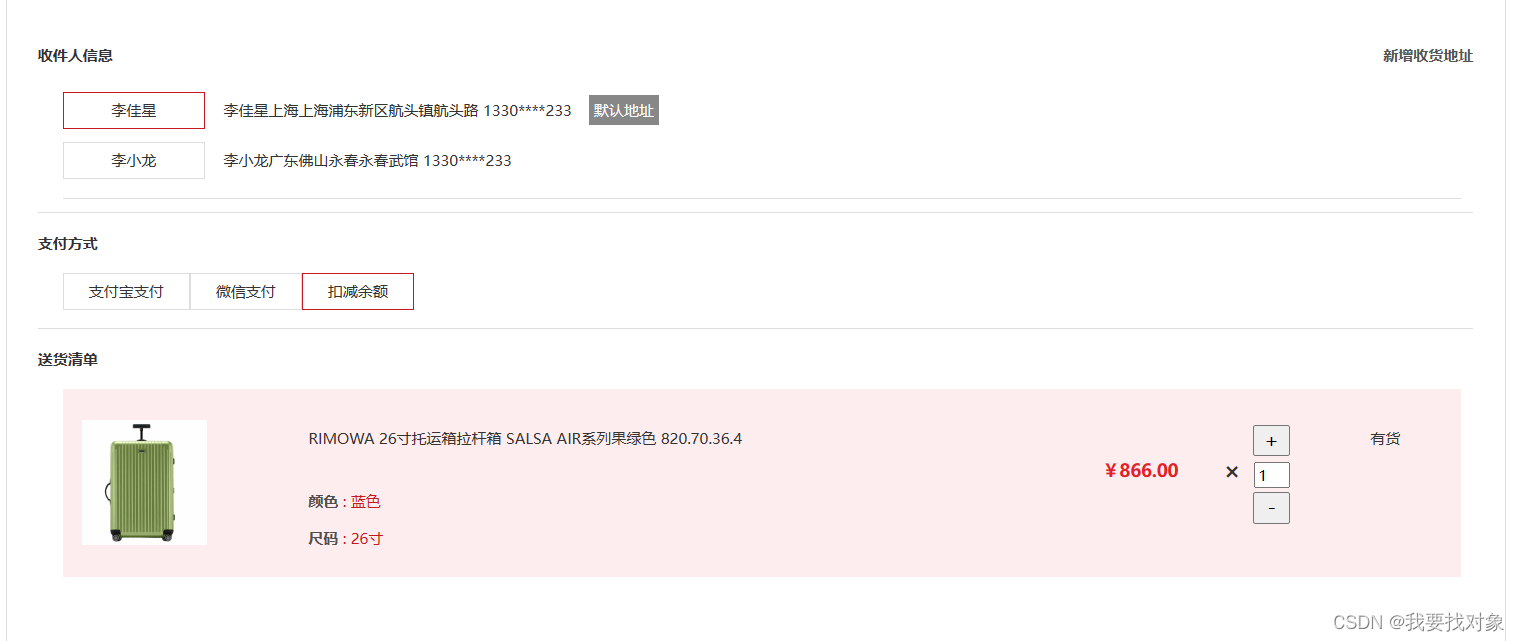
再来分析下请求和响应参数:

再看一下前端代码可知,返回一个列表即可:
data() {
return {
util,
paymentTypes: ["支付宝支付", "微信支付", "扣减余额"],
addressList: [ // 地址列表
{ "id": 61, "userId": 2, "contact": "李佳星", "mobile": "13301212233", "province": "上海", "city": "上海", "town": "浦东新区", "street": "航头镇航头路", "isDefault": true}, {"id": 63, "userId": 2, "contact": "李小龙", "mobile": "13301212233", "province": "广东", "city": "佛山", "town": "永春", "street": "永春武馆", "isDefault": false}
],
item: {}, // 商品信息
params: {
num: 1, // 商品购买数量
paymentType: 3, // 支付方式
addressId: 61, // 收货地址的id
itemId: 0, // 商品id
},
}
},
因此,总结下:
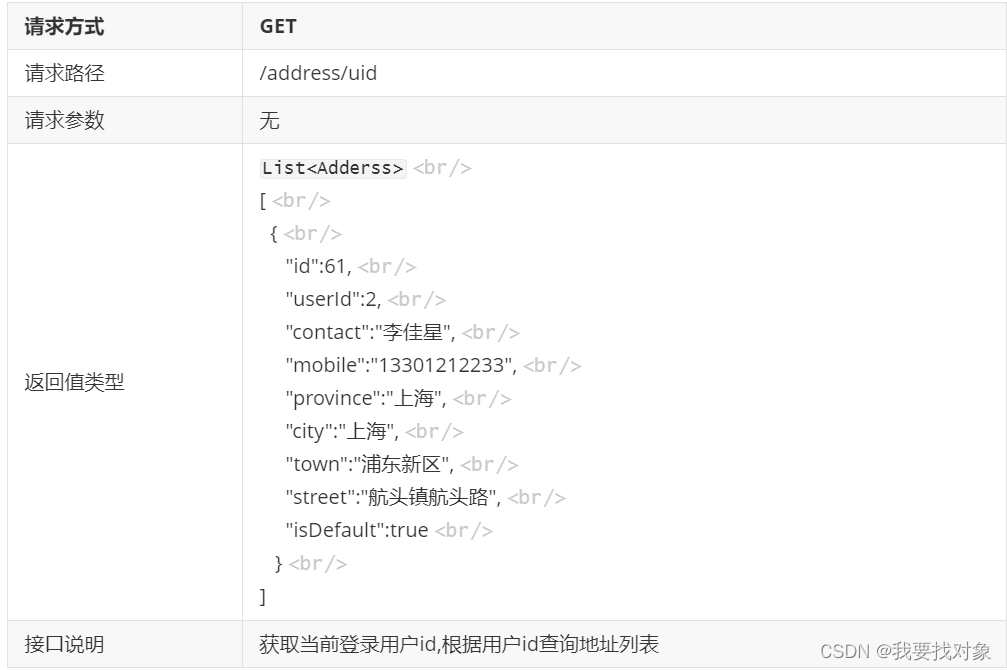
具体实现
controller:
@Autowired
private AddressService addressService;
@GetMapping("/uid")
public List<Address> getAddressByUid(){
return addressService.getAddressByUid();
}
service:
@Override
public List<Address> getAddressByUid() {
Long userId = ThreadLocalUtil.getUserId();
QueryWrapper<Address> wrapper = new QueryWrapper<>();
wrapper.eq("user_id",userId);
return this.list(wrapper);
}
效果展示