深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、Adagrad、Adadelta、RMSprop、Adam、Nadam、AdaMax、AdamW )
0. GD (梯度下降)
Gradient Descent(梯度下降)是一种迭代优化算法,广泛应用于机器学习和深度学习中,用于寻找目标函数(如损失函数或成本函数)的最小值。它的基本思想是沿着函数梯度(即函数在某一点的导数或者偏导数所构成的向量)的反方向逐步调整参数,因为梯度指向的是函数值增长最快的方向,那么它的反方向就是函数值减少最快的方向。
基本概念
设有一个目标函数
J
(
θ
)
J(\theta)
J(θ), 其中
θ
\theta
θ是模型的参数向量,梯度下降的目标是找到一组参数
θ
\theta
θ,使得
J
(
θ
)
J(\theta)
J(θ)达到最小。梯度下降通过以下步骤进行迭代更新:
-
1. 初始化:选择一个初始参数向量 θ 0 \theta_0 θ0。
-
2. 计算梯度:在当前参数 θ t \theta_t θt处计算目标函数的梯度 ∇ J ( θ t ) \nabla J(\theta_t) ∇J(θt),这代表了函数在该点的最陡峭上升方向。
-
3. 更新参数:按照梯度的负方向,以学习率 α \alpha α为步长来更新参数:
θ t + 1 = θ t − α ∇ J ( θ t ) \theta_{t+1} = \theta_t - \alpha \nabla J (\theta_t) θt+1=θt−α∇J(θt)
α \alpha α控制了每一步的步长,选择合适的 α \alpha α非常关键,太大会导致震荡或无法收敛,太小则会导致收敛速度过慢。 -
4. 重复: 重复步骤2和3,直到满足停止条件(如达到预设的迭代次数,或梯度的模长非常小,表明已接近最小值)
类型:
根据数据处理方式的不同,梯度下降有以下几种主要类型:
- 批量梯度下降(Batch Gradient Descent):在每一步迭代中使用所有训练样本来计算梯度。这种方法精确但计算成本高,尤其是在数据集很大的时候。
- 随机梯度下降(Stochastic Gradient Descent, SGD):在每一步迭代中仅使用单个训练样本计算梯度并更新参数。虽然收敛速度可能更快且计算资源需求低,但是由于噪声较大,路径可能会较为震荡。
- 小批量梯度下降(Mini-batch Gradient Descent):结合了前两者的优点,每次更新使用一部分(例如32、64个)随机选取的训练样本。这种方法在实践中最为常用,因为它平衡了计算效率和收敛稳定性。
1. BGD(批量梯度下降)
Batch Gradient Descent(批量梯度下降)是一种在机器学习中广泛使用的优化算法,其目的是通过迭代地调整模型参数来最小化损失函数(或成本函数),从而使得模型更好地拟合训练数据。下面是Batch Gradient Descent的详细解释:
基本原理
在机器学习任务中,我们通常有一个包含输入特征和相应输出的目标函数(或称为损失函数、误差函数),表示为 𝐽(𝜃),其中𝜃表示模型的参数。我们的目标是最小化这个函数,即找到一组参数 𝜃, 使得 𝐽(𝜃)达到最小。
计算梯度
梯度是一个向量,指向函数在某一点上增长最快的方向。在梯度下降中,我们计算损失函数关于模型参数的梯度,这代表了参数需要调整的方向和大小以减少损失。对于参数
θ
j
\theta_j
θj, 梯度分量可以表示为
∂
J
(
θ
)
∂
θ
j
\frac{\partial J(\theta)}{\partial \theta_j}
∂θj∂J(θ)。
批量更新
与随机梯度下降(每次迭代仅使用一个样本来更新参数)和小批量梯度下降不同,批量梯度下降在每次迭代时使用整个训练集来计算梯度。这意味着,它计算的是所有训练样本损失函数关于模型参数的梯度的平均值,然后根据这个平均梯度来同时更新所有参数。
更新规则
参数更新遵循以下规则:
θ
j
:
=
θ
j
−
α
1
m
∑
i
=
1
m
∂
J
(
θ
;
x
(
i
)
,
y
(
i
)
)
∂
θ
j
\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} \frac{\partial J(\theta; x^{(i)}, y^{(i)})}{\partial \theta_j}
θj:=θj−αm1i=1∑m∂θj∂J(θ;x(i),y(i))
这里:
- θ j \theta_j θj表示模型中第 j j j个元素。
- α \alpha α是学习率,决定了每一步参数调整的幅度。
- m m m是训练集中的样本数量。
- ∑ i = 1 m ∂ J ( θ ; x ( i ) , y ( i ) ) ∂ θ j \sum_{i=1}^{m} \frac{{\partial J(\theta; x^{(i)}, y^{(i)})}}{\partial \theta_j} ∑i=1m∂θj∂J(θ;x(i),y(i)) 表示对所有 m m m个样本的损失函数关于 θ j \theta_j θj的偏导数求和后取平均,即梯度的平均值。
迭代过程
重复上述更新步骤,直到满足停止条件,比如达到预设的最大迭代次数,或损失函数的变化小于某个阈值,表明模型已经收敛。
优点:
- 算法简单直观,易于实现。
- 对于凸优化问题,保证能找到全局最优解。
- 相较于随机梯度下降,每次迭代的梯度计算更为精确,因此迭代路径更加直接,更少震荡。
缺点:
- 当训练数据集非常大时,每次迭代的计算成本很高,因为需要遍历整个数据集。
- 训练速度慢,尤其是对于大规模数据集,可能需要很长时间才能收敛。
- 不适合实时学习和在线学习场景。
2. SGD(随机梯度下降)
随机梯度下降(Stochastic Gradient Descent, SGD)是机器学习和深度学习中常用的另一种优化算法,用于最小化目标函数(如损失函数)。与批量梯度下降不同,它在每次迭代时不是使用整个数据集来计算梯度,而是仅仅用一个样本来进行更新。下面是随机梯度下降的详细说明:
基本概念
- 核心思想:SGD的核心思想在于通过随机选择一个样本来估计整体数据集的梯度方向,然后根据这个单一样本的梯度信息即时更新模型参数。这样做的目的是减少计算成本,加快学习速度,尤其是在数据集很大的情况下。
- 迭代过程:在每次迭代中,SGD随机选取一个训练样本
(
x
(
i
)
,
y
(
i
)
)
(x^{(i)}, y^{(i)})
(x(i),y(i)), 然后基于该样本计算损失函数关于模型参数
θ
\theta
θ的梯度,并按照此梯度进行参数更新。更新规则类似于批量梯度下降,但只针对当前选中的样本:
θ j : = θ j − α ∂ J ( θ ; x ( i ) , y ( i ) ) ∂ θ j \theta_j :=\theta_j - \alpha\frac{\partial J(\theta; x^{(i)}, y^{(i)})}{\partial \theta_j} θj:=θj−α∂θj∂J(θ;x(i),y(i))
其中, α \alpha α是学习率, x ( i ) x^{(i)} x(i) 和 y ( i ) y^{(i)} y(i)分别是第 i i i个样本的特征和标签。 θ j \theta_j θj表示模型中第 j j j个元素。
优势:
- 计算效率高:由于每次迭代仅计算一个样本的梯度,大大减少了计算量,特别适合大规模数据集。
- 逃离局部极小点:由于其随机性,SGD在非凸函数中能够有助于跳出局部最小值,探索更广泛的解决方案空间。
- 在线学习和实时更新:适用于动态数据流,可以一边接收新数据一边更新模型。
缺点:
- 噪声较大:由于每次更新都是基于单个样本,梯度估计带有较大的方差,可能会导致学习过程波动较大,收敛路径曲折。
- 可能需要调整学习率:为了保证收敛,学习率可能需要随着迭代逐渐减小(学习率衰减),否则可能在最优点附近震荡而不收敛。
- 不保证全局最优:尤其在非凸函数优化中,SGD不能保证找到全局最小点。
应用场景
SGD因其高效和灵活性,广泛应用于各种机器学习模型的训练,包括但不限于线性回归、逻辑回归、神经网络等。特别是当数据集非常大时,SGD成为首选的优化策略。此外,结合动量、自适应学习率方法(如AdaGrad、RMSprop、Adam等)可以进一步改善SGD的表现,使其在实际应用中更加稳定和高效。
3. MBGD
MBGD通常是指Mini-Batch Gradient Descent(小批量梯度下降),它是批量梯度下降(Batch Gradient Descent)和随机梯度下降(Stochastic Gradient Descent)之间的一种折衷方案。Mini-Batch Gradient Descent在每次迭代时使用数据集中的一部分样本来计算梯度,这部分样本被称为“小批量”或“mini-batch”。下面是Mini-Batch Gradient Descent的详细解释:
基本原理
- 小批量选择:在每次迭代时,从整个训练数据集中随机选择一个小规模的数据子集(例如,32个、64个或128个样本),这个子集称为“小批量”。小批量的大小是一个超参数,需要手动设置。
- 梯度计算:基于这个小批量数据计算损失函数关于模型参数的梯度。与批量梯度下降相比,虽然计算的梯度仍然是一个估计,但由于包含了多个样本,其准确性通常优于随机梯度下降中的单样本梯度估计,同时又避免了批量梯度下降对整个数据集进行计算的高成本。
- 参数更新:根据计算出的小批量梯度来更新模型参数,更新规则类似于批量梯度下降,但使用的是小批量的平均梯度:
θ j : = θ j − α 1 n b a t c h ∑ i ∈ b a t c h ∂ J ( θ ; x ( i ) , y ( i ) ) ∂ θ j \theta_j := \theta_j - \alpha \frac{1}{n_{batch}} \sum_{i \in batch}^{} \frac{\partial J(\theta; x^{(i)}, y^{(i)})}{\partial \theta_j} θj:=θj−αnbatch1i∈batch∑∂θj∂J(θ;x(i),y(i))
其中, n b a t c h n_{batch} nbatch是小批量的大小,其余符号意义同前。
优势:
- 平衡效率与精度:相比于SGD,MBGD因为使用了多个样本进行梯度估计,减少了随机性,提高了学习的稳定性;而相比于BGD,它显著减少了计算资源的需求,特别是在大型数据集上。
- 并行处理:小批量数据可以方便地在现代计算硬件(如GPU)上并行处理,进一步加速训练过程。
- 并行处理:小批量数据可以方便地在现代计算硬件(如GPU)上并行处理,进一步加速训练过程。
缺点
- 超参数选择:需要选择合适的小批量大小,大小的选择会影响学习的效率和最终模型的质量,过小或过大都可能影响收敛速度和性能。
- 硬件限制:虽然相比BGD有所减少,但MBGD仍然需要一定的内存来存储每个小批量的数据,对于非常大的数据集,硬件资源限制仍然是一个问题。
应用场景
Mini-Batch Gradient Descent是目前深度学习中最常用的学习算法之一,几乎所有的深度学习框架(如TensorFlow、PyTorch等)都默认采用MBGD作为优化策略。它适用于大多数监督学习任务,包括图像分类、文本处理、语音识别等领域,尤其在处理大规模数据集时表现出色。
4. Momentum
Momentum(动量)是优化算法中的一种技术,最早由Polyak提出,后来被引入到神经网络的训练中以加速SGD(随机梯度下降)的收敛过程并减少振荡。动量项利用了过去的梯度信息,帮助优化过程在优化路径上获得“惯性”,从而更快地穿过狭窄的山谷并减少在鞍点或局部最小值附近徘徊的可能性。
原理
在标准的梯度下降中,参数更新仅依赖于当前时刻的梯度方向。而在带动量的梯度下降中,更新不仅考虑当前梯度,还会结合之前梯度的加权平均值,形成一个累积动量项。这个累积项可以看作是对参数更新方向的一种“记忆”,有助于在连续几次迭代中保持一致的移动方向,特别是在梯度方向变化不大的情况下。
更新规则
假设我们有一个参数向量 θ \theta θ,传统的梯度下降更新公式为:
θ
t
:
=
θ
t
−
1
−
α
∇
J
(
θ
t
−
1
)
\theta_t := \theta_{t-1} - \alpha \nabla J(\theta_{t-1})
θt:=θt−1−α∇J(θt−1)
加入动量后的更新规则变为:
v
t
:
=
β
v
t
−
1
+
α
∇
J
(
θ
t
−
1
)
v_t:=\beta v_{t-1} + \alpha \nabla J(\theta_{t-1})
vt:=βvt−1+α∇J(θt−1)
θ t : = θ t − 1 − v t \theta_t := \theta_{t-1} - v_t θt:=θt−1−vt
这里:
-
v
t
v_t
vt 是动量项,也称
速度向量,表示累积的梯度方向和大小。 - β \beta β是动量系数(通常设置为0.9左右),控制着历史梯度信息的保留程度,值越接近1,之前的梯度影响越大。
- α \alpha α是学习率,控制着每次更新的步长。
功能和优势
- 加速收敛:在损失函数的曲率较平坦的方向上,动量项可以帮助更快地穿越,因为之前的动量积累可以推动参数远离当前位置。
- 加速收敛:在损失函数的曲率较平坦的方向上,动量项可以帮助更快地穿越,因为之前的动量积累可以推动参数远离当前位置。
- 跳出局部极小值:在某些情况下,动量可以提供足够的“冲力”帮助算法跳出局部最小值,继续寻找全局最小值。
实现细节
在实际应用中,动量通常与SGD、Mini-Batch Gradient Descent或更先进的优化器(如Adam)结合使用,以提高训练效率和模型性能。动量优化器已成为深度学习领域中的标准配置之一,许多深度学习框架(如TensorFlow、PyTorch)都直接提供了集成动量的优化器实现。
5. AdaGrad
AdaGrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人于2011年提出,特别适合处理稀疏数据和具有特征尺度差异大的问题。它通过为每个参数维护一个单独的学习率来适应不同参数的特性,从而有效地解决了学习率选择的问题。
基本思想
AdaGrad的核心思想是累计每个参数历史梯度的平方,并在更新参数时,将学习率与这些历史梯度的平方根成反比。这意味着,对于频繁更新(即历史上梯度较大的参数),其学习率会自动减小;而对于不经常更新(梯度较小)的参数,则保持较高的学习率。这样的机制有助于在训练初期快速调整参数,并在之后的迭代中对参数进行更精细的调整。
更新规则
假设
w
w
w代表模型参数,
g
w
g_w
gw代表参数
w
w
w在当前迭代的梯度,
G
w
G_w
Gw代表到目前为止
g
w
g_w
gw的平方的累计和,
α
\alpha
α代表全局初始学习率,AdaGrad的更新规则如下:
-
1.初始化累计梯度平方项 G w G_w Gw为零向量。
-
2.在每次迭代中,计算当前梯度 g w g_w gw。
-
3.更新 G w G_w Gw的累计值:
G w : = G w + g w 2 G_w:=G_w+g^{2}_{w} Gw:=Gw+gw2 -
4.计算适应性学习率:
Δ w = − α G w + ϵ g w \Delta w = - \frac{\alpha}{\sqrt{G_w+\epsilon}} g_w Δw=−Gw+ϵαgw
其中, ϵ \epsilon ϵ是一个很小的正数(如 1 0 − 7 10^{-7} 10−7),用于避免除以零的情况。 -
5.更新参数 w w w:
w : = w + Δ w w := w+\Delta w w:=w+Δw
优点
- 自适应学习率:自动调整每个参数的学习率,减少手动调参的工作。
- 稀疏数据友好:对于稀疏特征,AdaGrad能够很好地处理,因为只有非零梯度的参数学习率才会被更新。
- 适合非平稳优化:在梯度变化较大的情况下,AdaGrad能够提供更稳定的更新路径。
缺点
- 学习率衰减:随着训练的进行, G w G_w Gw的值持续增加,导致学习率逐渐降低,可能会使训练过程提前进入饱和状态,难以继续学习。
- 累积梯度平方: 长期累积可能导致 G w G_w Gw,变得非常大,尤其是对于一些频繁更新的参数,这可能使学习率变得非常小,学习几乎停滞。
尽管存在上述缺点,AdaGrad仍然是一个里程碑式的算法,启发了许多后续的自适应学习率优化器,如RMSProp、Adam等,它们在AdaGrad的基础上进行了改进,试图解决其存在的问题。
6. RMSProp
RMSProp(Root Mean Square Propagation)是一种自适应学习率优化算法,由Geoffrey Hinton提出,主要用于解决梯度下降过程中学习率选择的难题,以及在非平稳目标函数(如神经网络的损失函数)优化中的效率问题。RMSProp结合了动量和自适应学习速率的概念,旨在通过适应每个参数的梯度历史的平方的指数移动平均值来调整学习率。
基本思想
RMSProp的核心思想是跟踪每个参数的梯度平方的平均值,以此来调整每个参数的学习率,而不是在整个网络中使用单一的学习率。具体来说,它保持了一个称为“均方根(Root Mean Square, RMS)”的变量,该变量反映了过去梯度的平方的衰减平均值。这有助于在梯度较大的维度上减缓学习率,而在梯度较小的维度上加速学习率,从而在不同尺度的特征上取得更好的平衡。
更新规则
假设
w
w
w代表参数模型,
g
w
g_w
gw代表参数
w
w
w在当前迭代的梯度,
E
[
g
2
]
w
E[g^2]_w
E[g2]w代表
g
w
g_w
gw的平方的历史平均值(RMS),
α
\alpha
α是学习率,
ρ
\rho
ρ是衰减因子(通常设置为0.9),RMSProp的更新规则如下:
-
1.计算当前梯度 g w g_w gw的平方。
-
2.更新 g w g_w gw的平方的历史平均值 E [ g 2 ] w E[g^2]_w E[g2]w:
E [ g 2 ] w : = ρ E [ g 2 ] w + ( 1 − ρ ) g w 2 E[g^2]_w :=\rho E[g^2]_w + (1-\rho)g^{2}_{w} E[g2]w:=ρE[g2]w+(1−ρ)gw2
这里, ρ \rho ρ控制了历史梯度平方的遗忘速度。 -
3.计算适应性学习率:
Δ w = α E [ g 2 ] w + ϵ g w \Delta w=\frac{\alpha}{\sqrt{E[g^2]_w + \epsilon}}g_w Δw=E[g2]w+ϵαgw
其中, ϵ \epsilon ϵ是一个很小的正数(如10^{-8}),用于防止分母为零的情况。 -
4.更新参数 w w w:
w : = w − Δ w w := w - \Delta w w:=w−Δw
优点
- 自适应学习率:RMSProp能够自动调整每个参数的学习率,这对于具有不同尺度或不同梯度特性的参数非常有效。
- 减少振荡:通过在梯度较大时减小学习率,有助于避免在山谷底部或平坦区域的振荡,从而加速收敛。
- 通用性:适用于多种类型的深度学习模型和损失函数,是训练深度神经网络的常用优化器之一。
缺点
- 超参数选择:RMSProp依然依赖于学习率 α \alpha α和衰减因子 ρ \rho ρ的选择,这些超参数的选择会影响优化性能。
- 可能的不稳定:在某些特定情况下,如果初始化不当或超参数选择不合适,RMSProp也可能导致训练过程不稳定。
RMSProp在AdaGrad之后提出,是对AdaGrad的改进,主要解决了学习率过早衰减的问题,从而在实践中往往能获得更好的性能。
RMSProp使用了指数加权移动平均(EWMA)来代替AdaGrad中的累积梯度平方和,这意味着它对历史梯度的重视程度随时间指数级递减,从而缓解了AdaGrad学习率过早衰减的问题。RMSProp通过一个衰减因子(如0.9)来控制历史梯度的遗忘速度,使得学习率可以在训练过程中更加稳定,既不会增长也不会无限制地下降。
指数加权移动平均(Exponentially Weighted Moving Average,简称EWMA)是一种统计方法,用于平滑时间序列数据,给近期数据分配更高的权重,而对远期数据分配较低的权重。这种加权方式使得EWMA能够快速反应数据的最新变化,同时保留一定的历史趋势信息。
7. AdaDelta
AdaDelta是一种自适应学习率优化算法,由Matthew D. Zeiler在2012年提出,是对AdaGrad的进一步发展,旨在解决后者学习率随时间逐渐减小至接近零的问题。AdaDelta不需要手动设置全局学习率,而是通过历史梯度信息动态调整每个参数的学习率,从而在训练过程中自动保持合适的学习率大小。
工作原理
AdaDelta的核心思想是同时维护两个状态变量:一个是梯度平方的指数加权移动平均(类似RMSProp),另一个是参数更新的平方的指数加权移动平均。通过这两个变量来动态调整每个参数的步长,而不是直接依赖于全局学习率。
具体更新规则如下:
-
1.计算梯度的平方平均值:类似于RMSProp,维护一个关于梯度平方的指数加权移动平均 E [ g 2 ] t E[g^2]_t E[g2]t:
E [ g 2 ] t = ρ E [ g 2 ] t − 1 + ( 1 − ρ ) g t 2 E[g^2]_t=\rho E[g^2]_{t-1} + (1-\rho)g^{2}_{t} E[g2]t=ρE[g2]t−1+(1−ρ)gt2
其中, g t = ∇ J ( θ ) g_t=\nabla J(\theta) gt=∇J(θ)是当前时间步的梯度, ρ \rho ρ是衰减因子(通常设置为0.9)。 -
2.计算参数更新量:
Δ θ t = − E [ Δ θ 2 ] t − 1 + ϵ E [ g 2 ] t + ϵ g t \Delta \theta_t = - \frac{\sqrt{E[\Delta \theta^2]_{t-1}+ \epsilon }}{\sqrt{E[g^2]_t + \epsilon}}g_t Δθt=−E[g2]t+ϵE[Δθ2]t−1+ϵgt
分子 E [ Δ θ 2 ] t − 1 + ϵ \sqrt{E[\Delta \theta^2]_{t-1}+ \epsilon } E[Δθ2]t−1+ϵ是之前所有时间步参数更新平方的累加值的平方根,用于缩放当前的梯度。 -
3.更新参数:使用计算出的更新量来更新参数:
θ t = θ t − 1 + Δ θ t \theta_t = \theta_{t-1} + \Delta \theta_t θt=θt−1+Δθt -
4.更新参数更新平方的累加值:
E [ Δ θ 2 ] t = ρ E [ θ 2 ] t − 1 + ( 1 − ρ ) Δ θ t 2 E[\Delta \theta^2]_t = \rho E[\theta^2]_{t-1} + (1-\rho) \Delta \theta^{2}_{t} E[Δθ2]t=ρE[θ2]t−1+(1−ρ)Δθt2
这个累加值将在下一个时间步用来计算参数更新量的缩放因子。
优点
- 自动适应:自动调整每个参数的学习率,减少手动调参的工作量。
- 减少振荡:通过结合考虑历史梯度和参数更新的信息,有助于平滑训练过程,减少训练过程中的振荡现象。
- 内存效率:只存储最近的梯度和更新的平方信息,相比其他一些算法,内存占用较小。
缺点
- 敏感于衰减系数的选择:AdaDelta算法中有一个衰减系数 ρ \rho ρ,这个系数的选择对算法的性能有很大影响。如果 ρ \rho ρ设置得太大,可能会导致算法在训练过程中过早地“忘记”历史信息,从而影响收敛性。如果 ρ \rho ρ设置得太小,算法可能会过分依赖于旧的信息,导致难以快速适应新的数据特征。
- 收敛速度:与一些其他优化算法(如Adam或Nesterov动量)相比,AdaDelta没有动量项来加速训练。在某些情况下,动量可以帮助算法更快地穿过平坦区域并加速收敛。
8. Adam
Adam(Adaptive Moment Estimation)是一种用于深度学习中的优化算法,它结合了两种扩展的梯度下降算法:Momentum和RMSprop。Adam 优化器在实践中被证明是有效的,并且已经成为许多深度学习模型的默认优化器之一。
Adam 优化器的关键特点包括:
- 1.自适应学习率:Adam 通过计算梯度的一阶矩估计(即均值)和二阶矩估计(即未中心化的方差)来调整每个参数的学习率。这意味着每个参数都有独立的学习率,这些学习率基于参数的更新历史自动调整。
- 2.动量(Momentum):Adam 结合了动量方法,它考虑了过去的梯度以加速学习。
- 3.平方梯度(RMSprop):Adam 同时使用了平方梯度的概念,这有助于调整学习率,使其更加稳定。
Adam 优化器的更新规则如下:
-
- 初始化:对于每个参数 θ \theta θ,初始化一阶矩估计 m 0 m_0 m0和二阶矩估计 v 0 v_0 v0为0,以及时间步 t t t为0。此外,还需要设置两个超参数:衰减系数 β 1 \beta_1 β1和 β 2 \beta_2 β2,通常分别设为0.9和0.999,以及一个小的常数 ϵ \epsilon ϵ(例如 1 0 − 8 10^{-8} 10−8),避免除以0的错误。
- 2.计算梯度:在时间步 t t t时,计算损失函数 J ( θ ) J(\theta) J(θ)关于参数 θ \theta θ的梯度 g t g_t gt。
- 3.更新一阶矩估计(动量):
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1-\beta_1)g_t mt=β1mt−1+(1−β1)gt - 4.更新二阶矩估计(平方梯度):
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1-\beta_2)g^{2}_{t} vt=β2vt−1+(1−β2)gt2 - 5.偏差校正:由于
m
t
m_t
mt和
v
t
v_t
vt初始化为0,所以在初始阶段它们会被低估,因此需要对它们进行修正,以防止在训练初期出现偏差:
m ^ t = m t 1 − β 1 t \hat{m}_t=\frac{m_t}{1-\beta^{t}_{1}} m^t=1−β1tmt
v ^ t = v t 1 − β 2 t \hat{v}_t = \frac{v_t}{1-\beta^{t}_{2}} v^t=1−β2tvt
- 6.更新参数:
θ t = θ t − 1 − α m ^ t v ^ t + ϵ \theta_t = \theta_{t-1} - \frac{\alpha \hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon} θt=θt−1−v^t+ϵαm^t
α \alpha α是学习率。
优缺点:
Adam 优化器的优点是,结合了动量方法和自适应学习率的优点,它相对于其他类型的优化算法(如SGD、Adagrad、RMSprop)更加鲁棒,特别是在处理非平稳目标和较大的数据集或参数空间时。
然而,也有一些研究表明,在某些情况下,Adam 可能不会像预期的那样收敛到最优解,特别是在训练初期。因此,选择优化器时,最好根据具体问题和实验结果来决定。
9. Nadam
Nadam(Nesterov-accelerated Adaptive Moment Estimation)是一种结合了 Adam 优化方法和 Nesterov 加速梯度(NAG)概念的优化算法。
Adam 是一种计算每个参数的自适应学习率的优化方法。另一方面,Nesterov 加速梯度是一种有助于在正确方向上加速梯度向量的方法,从而实现更快的收敛。
简单来说,Nadam 本质上是 Adam 优化方法加上 Nesterov 技巧。下面是它的工作原理:
- 计算梯度:与 Adam 类似,Nadam 首先计算一批数据的损失函数的梯度。
- 更新移动平均线:它维护梯度(动量项)及其平方(速度项)的移动平均线,与 Adam 类似。这些平均值呈指数衰减。
- 应用 Nesterov 技巧:在更新参数之前,动量项在当前梯度的方向上微移(这是 Nesterov 技巧)。这具有增加最小方向上的步长的效果,并且可以导致更快的收敛。
- 计算参数更新:然后通过采用 Nesterov 校正的一阶矩估计与二阶矩估计的平方根的比率来更新参数(在添加一个小常数以避免被零除之后)。
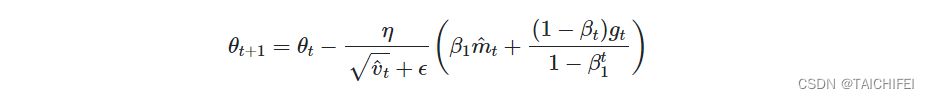
Nadam 带来了 Adam 和 NAG 的优点,因此它享有自适应学习率和 Nesterov 技巧的加速收敛的好处。这使其成为许多机器学习和深度学习应用程序中高效且强大的优化器。
10. AdaMax
AdaMax是Adam优化算法的一个变体,它对Adam中的第二矩估计进行了一些修改,以简化算法并提高性能。AdaMax与Adam类似,但使用了一种更简单的方式来估计梯度的无穷范数(infinity norm),而不是二阶动量的平均。以下是AdaMax算法的数学公式:
假设 t t t是当前迭代的步数, η \eta η 是学习率, β 1 \beta_1 β1 和 β 2 \beta_2 β2 是用于计算一阶和无穷范数的指数衰减率, ϵ \epsilon ϵ 是一个很小的数值常量以防止除零错误。
-
初始化一阶动量 ( m ) 为0,无穷范数的指数衰减量 ( u ) 为0。
m 0 = 0 , u 0 = 0 m_0 = 0, \quad u_0 = 0 m0=0,u0=0 -
在每一次迭代中,计算梯度 g t g_t gt。
-
计算一阶动量 m t m_t mt 的指数加权移动平均:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt -
计算无穷范数的指数衰减量 u t u_t ut :
u t = max ( β 2 u t − 1 , ∣ g t ∣ ) u_t = \max(\beta_2 u_{t-1}, |g_t|) ut=max(β2ut−1,∣gt∣) -
更新参数:
θ t = θ t − 1 − η 1 − β 1 t m t u t + ϵ \theta_t = \theta_{t-1} - \frac{\eta}{1 - \beta_1^t} \frac{m_t}{u_t + \epsilon} θt=θt−1−1−β1tηut+ϵmt
在这个公式中, θ \theta θ是参数, g g g 是梯度, η \eta η 是学习率, β 1 \beta_1 β1 和 β 2 \beta_2 β2 是指数衰减率, m m m 是一阶动量, u u u 是无穷范数的指数衰减量, ϵ \epsilon ϵ 是一个很小的数以防止除零错误。
优点:
- 处理稀疏梯度:由于使用了无穷范数,AdaMax在处理稀疏数据时更为有效,因为它对极端值更为敏感,可以更快速地响应重要的梯度变化。
- 减少方差:在某些情况下,使用无穷范数代替平方和的二阶矩估计可以减少估计的方差,进而提供更稳定的更新。
- 鲁棒性:提高了对非平稳目标函数的适应性和训练过程的稳定性。
缺点:
- 计算成本:计算无穷范数在某些硬件或大规模数据上可能比计算平方和要昂贵。
总的来说,AdaMax是针对Adam在特定场景下(尤其是处理稀疏数据和非平稳问题时)的改进,通过改变二阶矩的估计方式来提升训练效率和性能。
11. AdamW
AdamW 是 Adam 优化算法的一种变体,它引入了**权重衰减(Weight Decay)**的概念。**权重衰减通常用于正则化,可以有效地控制模型的复杂度,防止过拟合。**在 AdamW 中,权重衰减被重新整合到参数更新步骤中,而不是像传统的 Adam 算法那样在更新参数之后应用。
AdamW的作者指出,权重衰减应该与梯度更新分离处理,以便更好地控制模型的行为。
在AdamW中,权重衰减是在参数更新之后应用的,而不是在梯度计算中。这样做的好处是,可以独立地调整学习率和权重衰减率,这有助于提高模型的泛化能力。
以下是 AdamW 算法的数学公式:
假设 t t t 是当前迭代的步数, η \eta η 是学习率, β 1 \beta_1 β1 和 β 2 \beta_2 β2 是用于计算一阶和二阶动量的指数衰减率, ϵ \epsilon ϵ 是一个很小的数值常量以防止除零错误, λ \lambda λ 是权重衰减因子。
- 初始化一阶动量
m
m
m 和二阶动量
v
v
v 为0。
m 0 = 0 , v 0 = 0 m_0 = 0, \quad v_0 = 0 m0=0,v0=0 - 在每一次迭代中,计算梯度 g t g_t gt。
- 计算一阶动量
m
t
m_t
mt 和二阶动量
v
t
v_t
vt 的指数加权移动平均:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2 - 更新参数:
θ t = θ t − 1 − η v t + ϵ ( m t + λ θ t − 1 ) \theta_t = \theta_{t-1} - \frac{\eta}{\sqrt{v_t} + \epsilon} \left( m_t + \lambda \theta_{t-1} \right) θt=θt−1−vt+ϵη(mt+λθt−1)
在这个公式中, θ \theta θ 是参数, g g g 是梯度, η \eta η 是学习率, β 1 \beta_1 β1 和 β 2 \beta_2 β2 是指数衰减率, m m m 是一阶动量, v v v 是二阶动量, ϵ \epsilon ϵ 是一个很小的数以防止除零错误, λ \lambda λ 是权重衰减因子。
补充:

参考:
An overview of gradient descent optimization algorithms*
深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
https://zhuanlan.zhihu.com/p/261695487
https://zhuanlan.zhihu.com/p/32626442