本文尽量从一个机器学习小白或是只对机器学习算法有一个大体浅显的视角入手,尽量通俗易懂的介绍清楚AdaBoost算法!
一、AdaBoost简介
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。AdaBoost(Adaptive Boosting)是一种集成学习算法
1.1:什么是集成学习算法?
集成学习算法其实不能理解为一种具体算法(像knn、kmeans这样十分具体的算法),它其实是一种算法策略、算法框架。它的核心是在于, 将多个弱学习器(模型)结合(集成),从而得到一个更强大的模型。提高整体的性能和稳定性。
💡说的好像很轻松,“结合”,那么具体如何结合呢?如何结合才能提到性能呢?确实,我也有这个疑问,我们继续接着往下看。
其实举个例子🌰就好理解了:其实集成学习的思想在监督学习中最为常见,比如我们知道的随机森林算法就是多个决策树的集成。
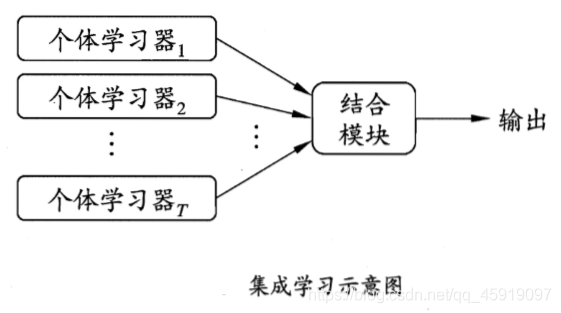
💡是不是有点get到了这种意味?结合多个模型,共同来实现目的,OK,我们再继续往下看
1.2:什么是AdaBoost算法?
AdaBoost算法,简单来说,就是把很多个不是很强大的模型组合起来,形成一个非常强大的模型。在这个过程中,AdaBoost特别关注那些之前被错误分类的数据点,确保这些点在后续的训练中得到更多的注意,从而提高整体的学习效果。
💡这里其实还不是很懂,说的文绉绉的,“得到更多的注意”,那么是如何实现的呢?还有,为什么得到注意了就可以提高整体的效果勒?
我们先来看 AdaBoost的算法流程!!! ⭐⭐⭐⭐⭐
- 首先,是初始化训练数据的权值分布D1。假设有N个训练样本数据,则每一个训练样本最开始时,都被赋予相同的权值:w1=1/N
- 然后,训练弱分类器
hi。具体训练过程中是:如果某个训练样本点,被弱分类器hi准确地分类,那么在构造下一个训练集中,它对应的权值要减小;相反,如果某个训练样本点被错误分类,那么它的权值就应该增大。权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。 - 最后,将各个训练得到的弱分类器组合成一个强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。
换而言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
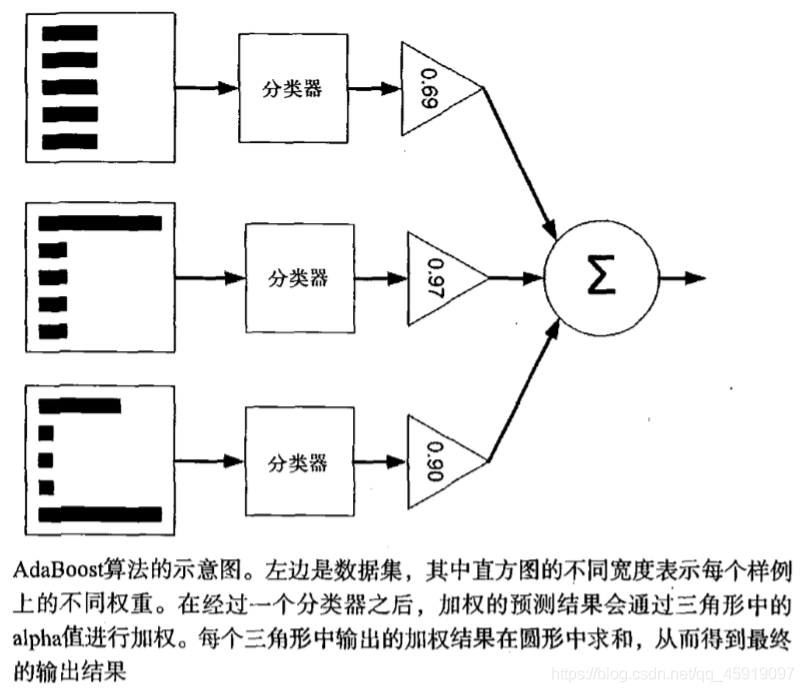
这里有几个点其实说的很抽象
- “权重”:其实就是这个数据点的系数,权重越高,那么在下次迭代时会“得到更多关注”
- “得到更多关注”,其实本质是影响的是损失函数,权重越高,在损失函数中所占比重越大,那么模型就会更加关注这个数据点(一旦被错误分类,那么会导致损失函数值加大很多,那么相应的模型也需要更多的调整以适应这个数据,根据损失函数调整的过程中其实就是对这个数据的关注)。
🛁其实到前面,就差不多能理解这个算法的主要思想了,如果这个数据越是难以被分类,那么模型对它的关注随着被分类错误而逐渐提升(自适应),一直到被分类正确。
二、 Adaboost算法流程
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例 x ∈ χ x\in \chi x∈χ,而实例空间 χ ∈ R n \chi \in R^{n} χ∈Rn,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
Adaboost的算法流程如下:
相关符号定义:
- t = 1 , 2 , . . . , T t = 1,2, ..., T t=1,2,...,T表示迭代的第多少轮
- N N N:样本个数
- D t ( i ) D_{t}(i) Dt(i):训练样本集的权值分布
- w i w_{i} wi:每个训练样本的权值大小
- h h h:弱分类器
- H H H:基本分类器
- H f i n a l H_{final} Hfinal:最终由弱分类器组合的强分类器
- e e e:误差率 ( H t ( x i ) H_{t}(x_{i}) Ht(xi)在训练数据集上的 误差率 e t e_{t} et就是被 H t ( x i ) H_{t}(x_{i}) Ht(xi)误分类样本的权值之和)
- α t \alpha _{t} αt:弱分类器的权重
-
Step1.:首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值: w i = 1 N w_{i} = \frac{1}{N} wi=N1, 这样得到训练样本集的初始权值分布。
D 1 ( i ) = ( w 1 , w 2 , . . . w N ) = ( 1 N , . . . . . . 1 N ) D_{1}(i) = (w_{1},w_{2},...w_{N}) = (\frac{1}{N},......\frac{1}{N}) D1(i)=(w1,w2,...wN)=(N1,......N1) -
Step2:进行多轮迭代,用
t = 1,2, ..., T表示迭代的第多少轮
⭐1. 选取一个当前误差率最低的弱分类器h作为第t个基本分类器Ht,并计算该弱分类器在分布Dt上的误差率e为:e t = P ( H t ( x i ≠ y i ) = ∑ i = 1 N w t i I ( H t ( x i ) ≠ y i ) e_{t} = P(H_{t}(x_{i}\ne y_{i}) = \sum_{i=1}^{N}w_{ti}I(H_{t}(x_{i}) \ne y_{i}) et=P(Ht(xi=yi)=i=1∑NwtiI(Ht(xi)=yi)
由上述式子可知, H t ( x ) H_{t}(x) Ht(x)在训练数据集上的 误差率 e t e_{t} et就是被 H t ( x ) H_{t}(x_) Ht(x)误分类样本的权值之和。
⭐2. 计算本次迭代的基本分类器 H t ( x ) H_{t}(x) Ht(x)的系数,即该弱分类器在最终分类器所占权重:
a t = 1 2 ln ( 1 − e t e t ) a_{t} = \frac{1}{2}\ln_{}{\left ( \frac{1-e_{t}}{e_{t}} \right ) } at=21ln(et1−et)
由上述式子可知,分类误差率越小的基本分类器在最终分类器中的作用越大。⭐3. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代
D t + 1 = D t ( i ) e x p ( − a t y i H t ( x i ) ) Z t D_{t+1} = \frac{D_{t}(i)exp(-a_{t}y_{i}H_{t}(x_{i}))}{Z_t} Dt+1=ZtDt(i)exp(−atyiHt(xi))
其中 Z t Z_t Zt为归一化常数: Z t = 2 e t ( 1 − e t ) Z_t = 2\sqrt{e_t(1-e_t)} Zt=2et(1−et) -
Step3:组合各个弱分类器
Gm(m∈1~M)(可以看到其实就是将每轮得到的弱分类器乘以其权重系数叠加)
f ( x ) = ∑ t = 1 T a t H t ( x ) f(x) = \sum_{t=1}^{T}a_tH_t(x) f(x)=t=1∑TatHt(x)
通过符号函数sign的作用,从而得到最终分类器,如下:
H f i n a l = s i g n ( f ( x ) ) = s i g n ( ∑ t = 1 T a t H t ( x ) ) H_{final} = sign(f(x)) = sign(\sum_{t=1}^{T}a_tH_t(x)) Hfinal=sign(f(x))=sign(t=1∑TatHt(x))
其实看完上面流程,我是有以下疑惑: adaboost算法的基本分类器的个数和具体形式如何确定呢?
- 基本分类器的个数:
基本分类器的个数,也就是迭代次数,通常是一个超参数,需要通过交叉验证或其他模型选择技术来确定。在训练过程中,随着基本分类器数量的增加,整体模型的性能通常会提高,但也可能出现过拟合的情况。因此,需要找到一个平衡点,使得模型在验证集上有最佳的性能。过多的基本分类器不仅会导致过拟合,还会增加模型的计算复杂度。 - 基本分类器的具体形式:
AdaBoost算法可以与多种类型的弱学习器结合使用,但最常用的是决策树,尤其是一层的决策树(也称为决策树桩)。选择哪种类型的弱学习器通常取决于问题本身的特性。例如,对于文本数据,可能选择朴素贝叶斯分类器作为基本分类器;而对于有大量数值型特征的数据,使用决策树桩可能更合适。基本分类器的选择也是一个超参数,需要基于实验结果来选择。在实际应用中,会通过试验不同的基本分类器类型,然后选择在验证集上性能最好的一种。
弱分类器(单层决策树)
Adaboost一般使用单层决策树作为其弱分类器。单层决策树是决策树的最简化版本,只有一个决策点,也就是说,如果训练数据有多维特征,单层决策树也只能选择其中一维特征来做决策,并且还有一个关键点,决策的阈值也需要考虑。

三、Adaboost的一个例子
例:给定如图所示的训练样本,弱分类器采用平行于坐标轴的直线,用Adaboost算法的实现强分类过程。

数据分析:
将这10个样本作为训练数据,根据 X 和Y 的对应关系,可把这10个数据分为两类,图中用“+”表示类别1,用“O”表示类别-1。本例使用水平或者垂直的直线作为分类器,图中已经给出了三个弱分类器,即:
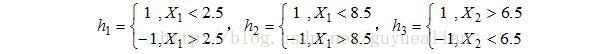
-
Step1.:首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值:1/N。
令每个权值w1i = 1/N = 0.1,其中,N = 10,i = 1,2, …, 10,然后分别对于t= 1,2,3, …等值进行迭代(t表示迭代次数,表示第t轮)
下表已经给出训练样本的权值分布情况:

-
Step2:进行多轮迭代,用t = 1,2, …, T表示迭代的第多少轮
⭐1. 选取一个当前误差率最低的弱分类器h作为第t个基本分类器Ht,并计算该弱分类器在分布Dt上的误差率e为:初试的权值分布D1为1/N(10个数据,每个数据的权值皆初始化为0.1),
D1=[0.1, 0.1, 0.1, 0.1, 0.1, 0.1,0.1, 0.1, 0.1, 0.1]
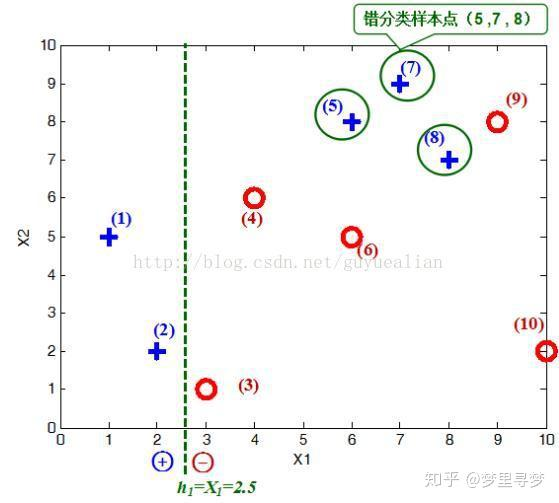
在权值分布D1的情况下,取已知的三个弱分类器h1、h2和h3中误差率最小的分类器作为第1个基本分类器H1(x)(三个弱分类器的误差率都是0.3,那就取第1个吧)
H 1 = { 1 , X 1 < 2.5 − 1 , x 1 > 2.5 H_1 = \begin{cases}1, X_1<2.5 \\-1, x1>2.5 \end{cases} H1={1,X1<2.5−1,x1>2.5ps:某个分类器的误差率为该分类器的被错分样本的权重和
⭐2. 计算本次迭代的基本分类器 H t ( x ) H_{t}(x) Ht(x)的系数,即该弱分类器在最终分类器所占权重:
分类器H1(x)=h1情况下,样本点“5 7 8”被错分,因此基本分类器H1(x)的误差率为:
e 1 = ( 0.1 + 0.1 + 0.1 ) = 0.3 e_1 = (0.1+0.1+0.1) = 0.3 e1=(0.1+0.1+0.1)=0.3
根据该分类器的误差率计算其在最终分类器中的权重:
α 1 = 1 2 ln 1 − e 1 e 1 = 1 2 ln 1 − 0.3 0.3 = 0.4236 \alpha _1 = \frac{1}{2}\ln_{}{\frac{1-e_1}{e_1} } = \frac{1}{2}\ln_{}{\frac{1-0.3}{0.3} }= 0.4236 α1=21lne11−e1=21ln0.31−0.3=0.4236ps:这个 α 1 \alpha_1 α1代表 H 1 ( x ) H_1(x) H1(x)在最终的分类函数中所占的权重为:0.4236
可见,被误分类样本的权值之和影响误差率e,误差率e影响基本分类器在最终分类器中所占的权重α。
⭐3. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代
对于正确分类的训练样本“1 2 3 4 6 9 10”(共7个)的权值更新为:
D 2 = D 1 2 ( 1 − e 1 ) = 1 10 × 1 2 × ( 1 − 0.3 ) = 1 14 D_2 = \frac{D_1}{2(1-e_1)} = \frac{1}{10}\times \frac{1}{2\times (1-0.3)}=\frac{1}{14} D2=2(1−e1)D1=101×2×(1−0.3)1=141ps:可见,正确分类的样本权值减小
而对于所有被错误分类的样本,权值变为:
D 2 = D 1 2 e 1 = 1 10 × 1 2 × 0.3 = 1 6 D_2 = \frac{D_1}{2e_1} = \frac{1}{10}\times \frac{1}{2\times 0.3}=\frac{1}{6} D2=2e1D1=101×2×0.31=61ps:可见,被错误分类的样本权值增大
这样,第1轮迭代后,最后得到各个样本数据新的权值分布:D2=[1/14,1/14,1/14,1/14,1/6,1/14,1/6,1/6,1/14,1/14]
由于样本数据“5 7 8”被H1(x)分错了,所以它们的权值由之前的0.1增大到1/6;反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到1/14,下表给出了权值分布的变换情况:
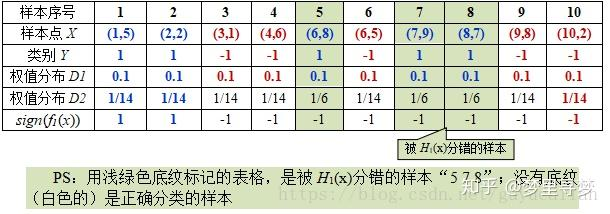
💡思考一下,这样有什么好处?这样的好处是,增大了错误样本的权重,导致下次选基本分类器时,就会尽量选错误分类样本少Or不是被经常分错的的那几个样本的分类器,这样的好处是能够自适应调整,从而提高性能。
可得分类函数:f1(x)= α1H1(x) = 0.4236H1(x)。此时,组合一个基本分类器sign(f1(x))作为强分类器在训练数据集上有3个误分类点(即5 7 8),此时强分类器的训练错误为:0.3
- Step3:组合各个弱分类器
Gm(m∈1~M)(可以看到其实就是将每轮得到的弱分类器乘以其权重系数叠加)
通过Step2的迭代3次后,可以得到3个分类器:
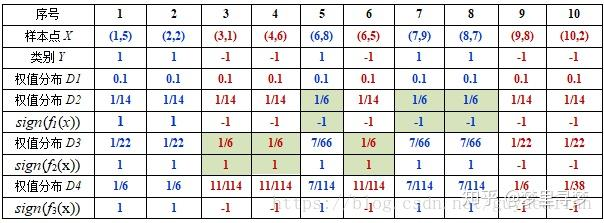
可得分类函数:f3(x)=0.4236H1(x) + 0.6496H2(x)+0.9229H3(x)。此时,组合三个基本分类器sign(f3(x))作为强分类器,在训练数据集上有0个误分类点。至此,整个训练过程结束。
整合所有分类器,可得最终的强分类器为:
H f i n a l = s i g n ( ∑ t = 1 T a t H t ( x ) ) = s i g n ( 0.4236 H 1 ( x ) + 0.6496 H 2 ( x ) + 0.9229 H 3 ( x ) ) H_{final} = sign(\sum_{t=1}^{T}a_t H_t(x)) = sign(0.4236H_1(x)+ 0.6496H_2(x) + 0.9229H_3(x)) Hfinal=sign(t=1∑TatHt(x))=sign(0.4236H1(x)+0.6496H2(x)+0.9229H3(x))
这个强分类器Hfinal对训练样本的错误率为0!
四、AdaBoost的优点和缺点
🌸优点:
- 提高准确性: AdaBoost通过组合多个简单的模型(弱学习器)来构建一个强大的模型。这种方法可以有效提高分类的准确性。
- 易于实现: 相比于一些复杂的算法,AdaBoost相对容易实现。特别是当使用决策树桩作为基本分类器时,整个模型构建过程简单直观。
- 自动处理特征选择: 在构建决策树时,AdaBoost算法会自动选择对分类最有用的特征,因此不需要手动进行特征选择。
- 不太容易过拟合: 虽然AdaBoost涉及多个学习器的组合,但实践中表现出来的是,当基本分类器设置得当时,AdaBoost不太容易过拟合。
🌲缺点:
- 对噪声和异常值敏感:AdaBoost算法在增加错误分类数据点的权重时,如果数据集中存在噪声或异常值,它们的权重也会被增加,这可能会导致模型性能下降。
- 计算强度:尽管AdaBoost算法相对容易实现,但是随着基本分类器数量的增加,模型的训练和预测过程可能会变得计算密集,尤其是在数据集很大的情况下。
- 需要调整的参数:虽然AdaBoost的参数比较少(如基本分类器的数量),但是这些参数的选择会对最终模型的性能有显著影响,需要通过交叉验证等方法来仔细选择。
五、代码实现
5.1:Python的scikit-learn库简单实现:
下面是一个简单的AdaBoost算法实现,使用Python的scikit-learn库。这个例子中,我们将使用决策树桩(DecisionTreeClassifier的max_depth=1)作为弱学习器。
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 创造一些模拟的二分类数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=0,
random_state=42, n_clusters_per_class=1)
# 将数据集分割成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建AdaBoost模型实例
# 使用决策树桩作为基本分类器
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5, random_state=42)
# 训练AdaBoost模型
ada_clf.fit(X_train, y_train)
# 进行预测
y_pred = ada_clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Model accuracy: {accuracy:.2f}")
代码详细注释:
- 首先,我们导入必要的库。AdaBoostClassifier是scikit-learn中的AdaBoost模型,DecisionTreeClassifier是我们选择的基本分类器。
- 接着,我们使用make_classification函数生成一个模拟的二分类数据集,其中包含1000个样本,每个样本有20个特征。
- 然后,我们使用train_test_split函数将数据集分割成训练集和测试集,测试集大小占20%。
- 创建一个AdaBoostClassifier实例,设置基本分类器为DecisionTreeClassifier,其中max_depth=1意味着每个基本分类器是一个决策树桩。n_estimators=200指定了200个弱学习器的数量,algorithm="SAMME.R"是AdaBoost的一种实现,learning_rate=0.5是学习率,random_state=42用于确保结果的可重复性。
- 使用fit方法在训练数据上训练AdaBoost模型。
- 使用训练好的模型对测试集数据进行预测。
- 计算并打印出模型在测试集上的准确率。
5.2:手写adaBoost算法
import numpy as np
def stumpClassify(dataMatrix, dimen, threshVal, threshIneq):
"""
对数据进行分类的单层决策树分类函数。
Args:
dataMatrix: 数据矩阵
dimen: 需要考虑的特征的维度
threshVal: 阈值
threshIneq: 不等式,可以是'lt'(小于)或'gt'(大于)
Returns:
retArray: 分类结果
"""
retArray = np.ones((np.shape(dataMatrix)[0], 1)) # 默认所有样本分类结果为1
# 根据阈值和不等式标记分类结果
if threshIneq == 'lt':
retArray[dataMatrix[:, dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:, dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr, classLabels, D):
"""
在加权数据集中找到最佳的单层决策树。
Args:
dataArr: 数据集
classLabels: 类别标签
D: 数据点的权重
Returns:
bestStump: 最佳的单层决策树信息
minError: 最小的错误率
bestClasEst: 最佳的分类结果
"""
dataMatrix = np.mat(dataArr)
labelMat = np.mat(classLabels).T
m, n = np.shape(dataMatrix)
numSteps = 10.0 # 在特征的所有可能值上进行遍历的步数
bestStump = {} # 存储最佳单层决策树的信息
bestClasEst = np.mat(np.zeros((m, 1)))
minError = np.inf # 初始错误率设为无穷大
# 遍历所有特征
for i in range(n):
rangeMin = dataMatrix[:, i].min()
rangeMax = dataMatrix[:, i].max()
stepSize = (rangeMax - rangeMin) / numSteps
# 遍历所有步长
for j in range(-1, int(numSteps) + 1):
# 对每个步长,都尝试大于和小于的不等式
for inequal in ['lt', 'gt']:
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)
errArr = np.mat(np.ones((m, 1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr # 计算加权错误率
# 如果当前的错误率小于最小错误率,则保存当前的单层决策树
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
def adaBoostTrainDS(dataArr, classLabels, numIt=40):
"""
使用AdaBoost算法训练模型。
Args:
dataArr: 数据集
classLabels: 类别标签
numIt: 迭代次数
Returns:
weakClassArr: 训练好的弱分类器数组
"""
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m) # 初始化权重
aggClassEst = np.mat(np.zeros((m, 1)))
# 进行numIt次迭代
for i in range(numIt):
# 构建单层决策树
bestStump, error, classEst = buildStump(dataArr, classLabels, D)
# 计算分类器权重alpha,用于更新样本权重D和最终的分类结果
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
# 更新样本权重D
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst)
D = np.multiply(D, np.exp(expon))
D = D / D.sum()
# 更新累计的类别估计值
aggClassEst += alpha * classEst
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m, 1)))
errorRate = aggErrors.sum() / m
if errorRate == 0.0: break # 如果错误率为0,则提前中止循环
return weakClassArr
def adaClassify(datToClass, classifierArr):
"""
使用AdaBoost算法对数据进行分类。
Args:
datToClass: 待分类的数据
classifierArr: 训练好的弱分类器数组
Returns:
分类结果
"""
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m, 1)))
# 遍历所有弱分类器,进行分类估计并累加
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'],
classifierArr[i]['thresh'],
classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
# 返回最终的分类结果
return np.sign(aggClassEst)
# 示例数据集,这里只有两个特征和五个样本点
dataMat = np.array([
[1.0, 2.1],
[2.0, 1.1],
[1.3, 1.0],
[1.0, 1.0],
[2.0, 1.0]
])
# 类别标签,与数据集中的样本相对应
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
# 训练AdaBoost模型,这里假设迭代次数为9
# 这将返回一个包含若干弱分类器信息的列表
classifierArray = adaBoostTrainDS(dataMat, classLabels, 9)
# 使用训练好的AdaBoost模型进行分类
# 这里我们用训练数据作为测试,实际中应使用独立的测试集
prediction = adaClassify(dataMat, classifierArray)
# 打印出预测结果
print("Predictions:", prediction)
# 打印出实际的类别标签,以便比较
print("Actual labels:", classLabels)