前言
最近心情格外不舒畅,不仅仅是对前途的迷茫,这种迷茫倒是我自己的问题还好,关键它是我们这种普通吗喽抗衡不了的。
那就换个脑子,学点新东西吧,比如 Go?
1、Go 语言入门
介绍就没必要多说了,Go 语言的作者是 B语言、C语言 和 Unix 支付联合开发的,所以可以预见这门语言不会差!而且事实也确实是这样。不得不感慨外国那群搞技术的人是真牛啊。
1.1、Go 环境安装
Go 语言官网 Go下载 - Go语言中文网 - Golang中文社区 下载安装包
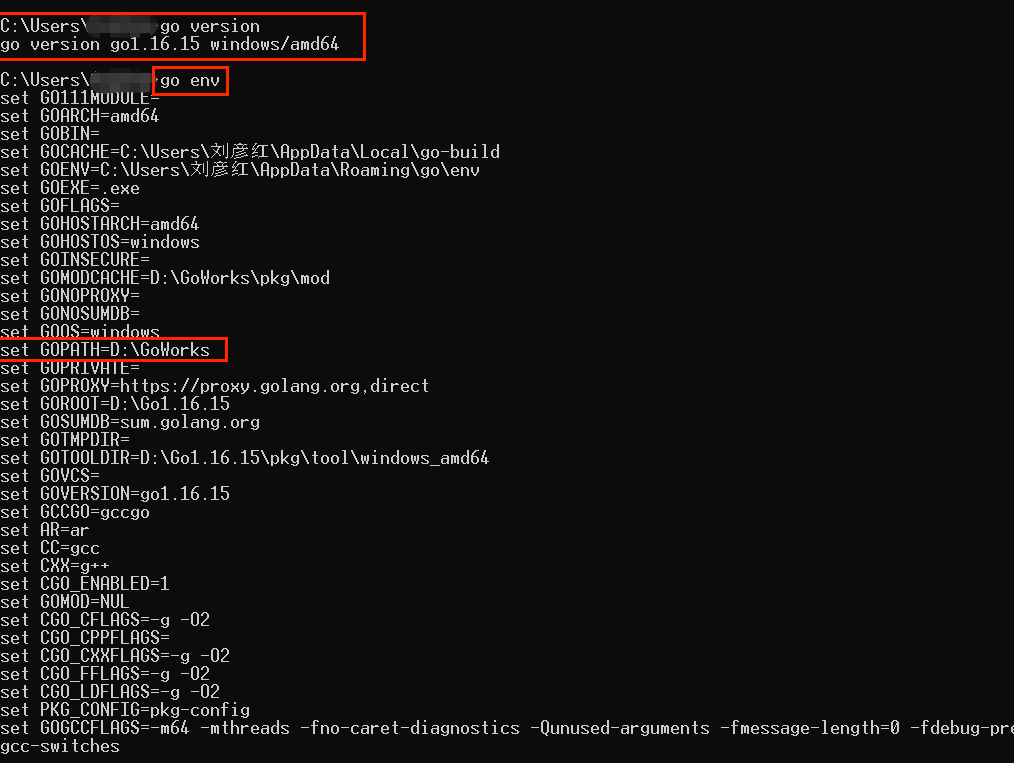
安装后使用 go version 进行安装的验证
创建 Go 的工作目录并设置为系统环境变量 GOPATH,创建下面三个目录:
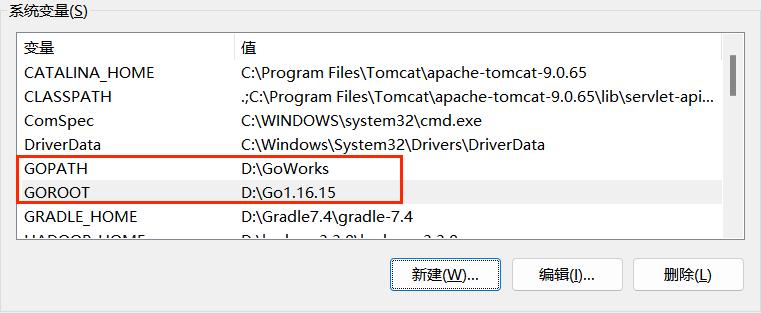
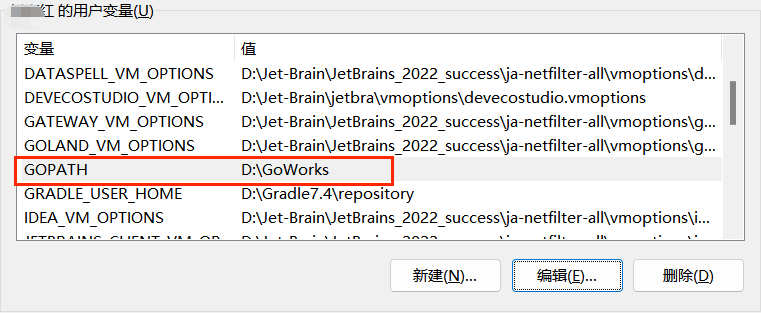
用户变量 GOPATH 默认会有一个工作目录,所以需要覆盖掉:
检查安装成功:
1.2、Hello World
Go 语言的执行必须在 main 包下 :
package main
import "fmt"
func main() {
fmt.Print("Hello World")
}注意:这个包可以是不存在的,也就是它可以不是一个目录!
运行结果:

注意:必须在 GOROOT 环境下去执行
当然,我们也可以去 go 文件所在的文件夹去打开,然后通过 go run 来执行该文件:

注意:必须要把要执行的 go 文放在 main 包下!
如果在运行过程中,出现了下面的报错:

需要关闭 go 环境变量中的 GO111MODULE :

- GO111MODULE 是一个环境变量,它用于控制Go语言的包管理方式。
在Go 1.11版本之前,Go语言使用 GOPATH 模式来管理项目和依赖包,所有的代码和依赖都需要存放在$GOPATH目录下。随着Go 1.11版本的发布,引入了一种新的包管理方式,即模块(module)系统,这个系统允许开发者在不依赖于GOPATH的情况下管理和构建项目。
具体来说,GO111MODULE 环境变量可以设置以下三个值:
- on:开启模块支持,此时Go命令行会完全使用模块机制来管理依赖,而不会去GOPATH目录下查找。
- off:关闭模块支持,go命令行将不会支持module功能,寻找依赖包的方式将会沿用旧版本那种通过vendor目录或者GOPATH模式来查找。
- auto(默认值):自动模式,go命令行将会根据当前目录来决定是否启用module功能。如果当前目录在GOPATH/src之外且该目录包含go.mod文件,或者当前文件在包含go.mod文件的目录下面,则会开启模块支持。
1.3、注释
Go 语言的注释和 Java 几乎一样
1.4、变量
Go 语言是一种静态类型和编译型语言。
- Go语言使用静态类型系统,这意味着变量的类型在编译时就已确定,有助于在编译阶段捕获错误,提高代码的安全性。
- 同时,Go语言是编译型语言,源代码在执行前需要被编译成机器码。
1.4.1、变量的定义
var name type同时定义多个变量:
var (
name string // 默认为空
age int // 默认为 0
)注意:可以不给变量赋初始值,它会有默认值。
- 此外,布尔值默认为 false,切片、函数、指针变量的默认值为 nil。
1.4.2、变量的标准初始化
// 使用 var 可以省去类型
var addr = "beijing"
// 初始化多个变量
var (
name string = "zs"
age int = 18
)
// 初始化单个变量
var addr string = "beijing"1.4.3、端变量的初始化(自动推导)
省去 var,可以使用 := 来进行变量类型的自动推导
name := "zs"
age := 18
fmt.Println(name,age)
// %T 代表变量的类型
fmt.Printf("%T,%T",name, age)运行结果:

注意:被 := 初始化过的变量不能再初始化了!
1.4.4、打印内存地址
可以使用 Pringf 的 %p 结合 &变量 来实现内存地址的打印(& 也叫取地址符),但是这种取地址的方法只适合与数值类型,因为数值类型存储的是数值,需要用取地址符来取得数值地址,而引用类型本身就是存储的就是地址,不需要再取:
name := "zs"
fmt.Println(name)
fmt.Printf("name=%s,内存地址=%p\n",name,&name)
name = "ls"
fmt.Printf("name=%s,内存地址=%p",name,&name)运行结果:

可以看到,即使一个变量的值发生了变化,但是它的内存地址是不会变化的。
1.4.5、变量交换
在别的语言中,变量的交换通常需要借助一个中间变量来实现:
var tmp int
tmp = a
a = b
b = tmp但是 Go 语言提供了一个特别简洁的语法:
var a,b int = 100,200
println("a =",a,"b =",b)
a,b = b,a
println("a =",a,"b =",b)注意:这里使用了 println 输出的,看起来简单了很多,但是它是标准错误输出!
1.4.6、匿名变量
匿名变量就是一个下划线,它可以用于变量的声明或赋值,但是任何赋给这个标识符的值都将被抛弃。
所以这个匿名变量一般用于我们不需要这个值的时候(一般是返回值)。
package main
func test()(int,int) {
return 100,200
}
func main() {
a,_ := test()
println(a)
}这里,我们不需要第二个返回值,但是接受返回值的时候又不能不写,所以直接使用匿名变量抛弃掉。
匿名变量不占用内存,不会分配内存。匿名变量和匿名之间也不会因为多次初始化而无法使用。
1.4.7、变量的作用域
Go 语言中同样是分类局部变量和全局变量,在 Go 语言中,如果全局变量名和局部变量名相同,调用时会使用就近原则:
// 全局变量
var name string = "hive"
func main() {
// 局部变量
name := "s"
println(name)
}这里我们的局部变量 name 并不是在重新初始化(在 Go 语言中一个变量只能被初始化一次,除了匿名变量),而是一个全新的变量。
1.5、常量
1.5.1、普通常量
常量就是在程序运行时,不能被修改的值。在 Go 语言中,常量只能是布尔型、数值型和字符串类型。
const URL string = "www.csdn.com" // 显示定义
const USERNAME = "lyh" // 隐式定义
const a,b,c = 1,2,3 // 同时定义多个常量 注意:在 Go 语言中,常量和全局变量不使用不会报错,但是变量定义了必须使用。
1.5.2、iota
iota 是一个特殊的常量,可以认为是一个可以被编译器修改的常量。iota 是 go 语言的常量计数器。
iota 在 const 关键字处显示会被重置为 0 ,const 中每新增一行就会 +1 。
package main
import "fmt"
func main() {
const (
a = iota // 0
b = iota // 1
c = iota // 2
)
fmt.Println(a,b,c)
const (
d = iota // 0
e // 1
f // 2
g = "hello" // iota依然会自增
h // 默认和上面的值是一样的 hello
i = iota // 5
)
fmt.Println(d,e,f,g,h,i)
}运行结果:

1.6、基本数据类型
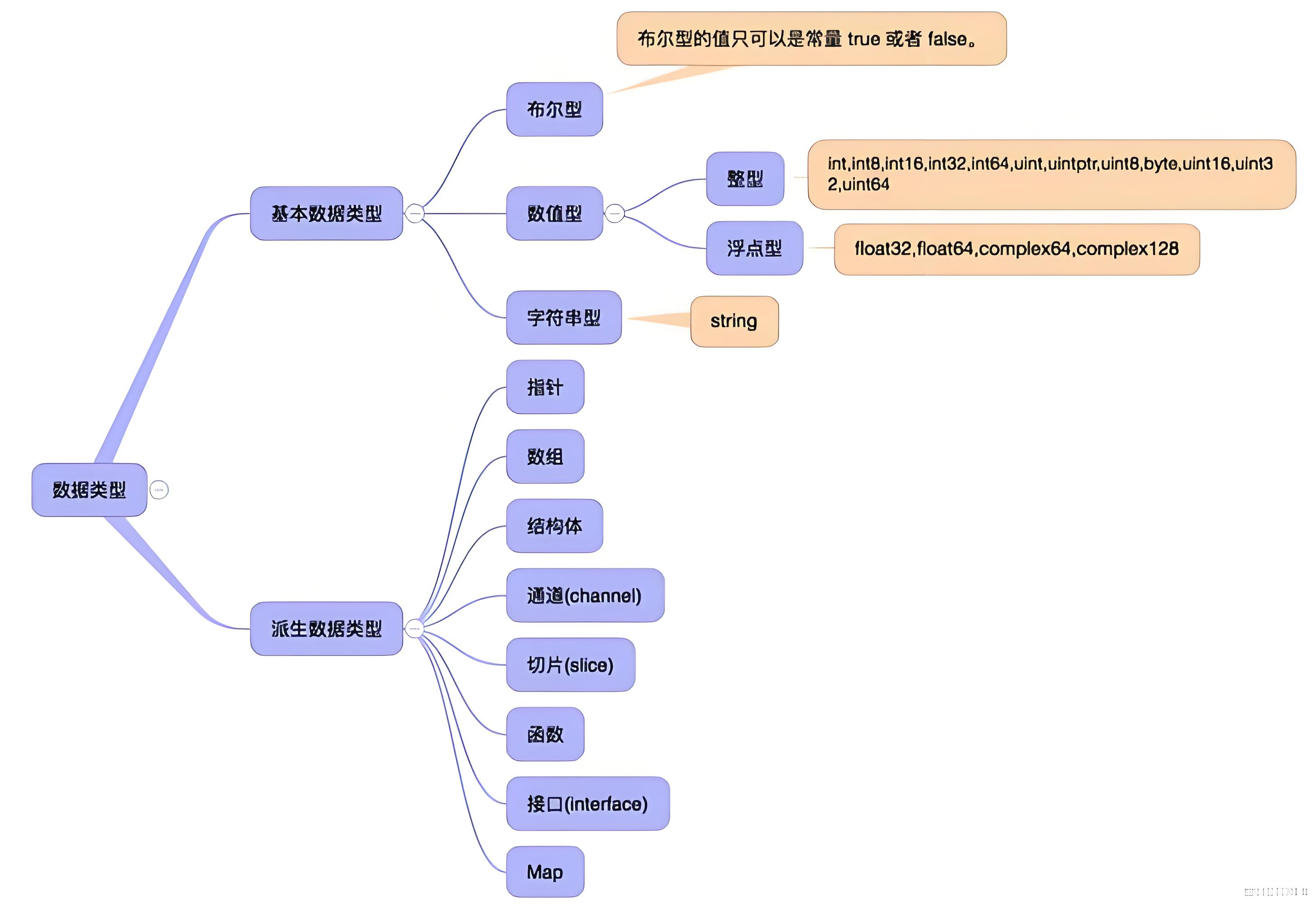
1.6.1、布尔型
var b1 bool // 默认 false
fmt.Printf("%T,%t",b1,b1)注意: %T 是输出变量类型,%t 是代表布尔类型的值
运行结果:

1.6.2、数值类型
整数类型
整数分为有符号和无符号两种类型,其中无符号包括(uint8、uint16、uint32、uint64),有符号包括(int8、int16、int32、int64)等。(无符号指的就是没有负数,有些场景下确实好用)
var ss = 100
fmt.Printf("%T",ss) // int注意:而 Go 语言默认的整型就是 int 型。
- 此外,Go 语言中的 byte 默认就是 uint8

- 从源码中可以看到,Go 语言中 int 并不等同于 int32, unit 也不等同于 unit32 。
浮点数
浮点数同样根据位数分为 float32 和 float64 。
var ss = 3.14
fmt.Printf("%T",ss) // float64
注意: Go 语言的浮点数默认为 float64。
1.6.3、字符串类型
Go 语言没有字符类型,如果要输出字符类型,需要把它用 string() 方法从 转为
var sex = '男' // 默认为 int32 类型
fmt.Printf("%T\n",sex)
fmt.Println(string(sex))运行结果:

- int32 也就是指字符的 ASCII 码的值
1.6.4、数据类型转换
上面我们已经试过用 string() 来把 int32 类型的数据转为 string 类型了。
a := 3.5
b := int(a) // 3
fmt.Println(b)- int() 默认是截取整数部分
1.7、运算符
Go 语言中的算数运算符、关系运算符、逻辑运算符等和Java基本一致,这里只介绍其他运算符:
1.7.1、其他运算符
主要有两个:
- &:返回变量存储地址,配合 %p 使用
- * :指针变量,指向一个变量的内存地址
var a int = 7
var ptr *int = &a // 指针指向内存地址
fmt.Printf("%T,%d,%p\n",a,a,&a)
fmt.Printf("%p",ptr)1.8、输入输出
下面适应 fmt.Scanln 进行输入测试:
var x int
var y int
fmt.Println("请输入两个数...")
fmt.Scanln(&x, &y)
fmt.Println(x,y)或者可以替换使用 fmtScanf 函数:
fmt.Scanf("%d %d",&x,&y)2、Go 语言基础
2.1、流程控制
无论是什么语言,流程控制都只有三种:顺序、选择(if、switch、select)、循环(for)。
2.1.1、if 语句
和 Java 相比,只是没有括号,仅此而已:
var x int
fmt.Scanf("%d",&x)
if x >= 60 {
if x >= 90 {
fmt.Println("成绩优秀")
}else {
fmt.Println("成绩及格")
}
}else {
fmt.Println("成绩不及格")
}2.1.2、switch 语句
同样和 Java 差不多,不多介绍:
var x int
fmt.Scanf("%d",&x)
switch x {
case 60:
fmt.Println("C")
case 80:
fmt.Println("B")
case 90:
fmt.Println("A")
default:
fmt.Println("Other")
}forthrough 穿透
switch 默认匹配成功后就不会去执行其他 case,如果我们需要无条件执行下面一条其他 case ,需要使用 fallthrough :
var x int
fmt.Scanf("%d",&x)
switch x {
case 60:
fmt.Println("C")
fallthrough
case 80:
fmt.Println("B")
case 90:
fmt.Println("A")
default:
fmt.Println("Other")
}测试:输入 60

可以看到,fallthrough 只能穿透下面一个 case 。
2.1.3、for 循环
var x int
fmt.Scanf("%d",&x)
// 打印 1~x
for i:=1;i<x;i++{
fmt.Println(i)
}对于 for 的三个参数,我们也可以选择省略:
count := 5
for ;count>0;count--{
fmt.Println(count)
}如果参数全部省略,则相当于Java 中的 while 循环(但是 Go 语言并没有提供 while 循环):
for{
// 无限循环
}for 循环中的 break 和 continue 的用法和 Java 中是一样的。
遍历字符串
var str = "flink"
for i:=0;i<len(str);i++{
fmt.Print(string(str[i])+" ")
}- 需要注意 Go 语言中没有字符类型,必须转为 string ,否则输出 ASCII 码。
2.2、函数
2.2.1、函数的声明
func 函数名 ( 参数... ) [返回值 返回值类型]{
函数体
[return 返回]
}求和函数:
func main() {
fmt.Println(sum(1,1)) // 2
}
func sum(x int,y int)(res int){
return x+y
}至于函数中的形参、实参太 low 了,这里就不练习了。
2.2.2、可变参数
和 Java 基本一样,就相当于传了一个 int 数组:
func main() {
fmt.Println(sum(1,1,1,1,1)) // 5
}
func sum(num ... int)(res int){
sum := 0
for i:=0;i<len(num);i++{
sum+=num[i]
}
return sum
}2.2.3、值传递
上面我们已经给函数传递过一些类型的值了,除了基本的数值类型,我们还可以传递数组类型(参数必须指定数组大小):
func main() {
// 定义一个数组
arr := [4]int{1,2,3,4}
fmt.Println(sum(arr)) // 10
}
// 如果参数是数组需要指定数组大小
func sum(arr [4]int)(res int){
sum := 0
for i:=0;i<len(arr);i++{
sum+=arr[i]
}
return sum
}可以看到,使用数组作为函数参数非常受限制,这是因为Go语言在设计上注重的是安全性、清晰性和简洁性。虽然有时这可能会牺牲一定的灵活性,但它通过提供其他机制(如切片)来补充这一点,同时保持语言的一致性和易用性。
此外,还有一些类型的值比如 struct 之后再学。
2.2.4、引用传递
Go 语言中引用类型的数据:slice、map、chan ...
func main() {
// 切片是一个可扩容的数组
s1 := []int{1,2,3,4}
update(s1)
fmt.Println(s1) // [-1 2 3 4]
}
func update(arr []int) {
arr[0] = -1
}可以看到,如果参数是值类型(包括数组和结构体!),就像在 Java 中的形参为值类型一样,进入函数的参数会开辟自己的栈空间,所以我们事实上操作的是形参而不是实参!
这里我们的参数类型是应用类型 slice,它虽然看起来像数组,但是它是一个引用类型,对于 Go 语言中的引用类型,它就像我们 Java 中的对象,所以当我们修改它的属性值的时候,修改的就是实参的值。
总之,值传递时传递的是数据的拷贝,而引用传递时传递的是引用地址。
2.2.5、递归
递归就简单了,这里玩一个斐波那契数列:
func main() {
for i:=1;i<10;i++ {
fmt.Print(feb(i)," ")
}
}
func feb(num int)(res int) {
if num==1 || num==2 {
return 1
}else {
return feb(num-1)+feb(num-2)
}
}运行结果:

2.2.6、defer 延迟
被 defer 修饰的代码总是放到最后执行,它采用的是后进先出(栈)模式:
func main() {
f("1")
f("2")
defer f("3")
f("4")
}
func f(s string) {
fmt.Println(s)
}运行结果:

因为 defer 的这个特性,我们可以用它去关闭资源。
2.3、函数高级
2.3.1、函数的本质
函数的本质就是一个引用类型,只不过它的类型为 func():
func main() {
fmt.Printf("%T",f)
}
func f(s string) {
fmt.Println(s)
}运行结果:

所以,我们可以想到,当函数不加括号的时候函数就是一个类型,所以我们是否可以定义一个函数类型的变量?
func main() {
fmt.Printf("%T\n",f)
var f2 func(s string) = f
f2("hello")
// 打印函数的地址
fmt.Println(f)
fmt.Println(f2)
}
func f(s string) {
fmt.Println(s)
}运行结果:
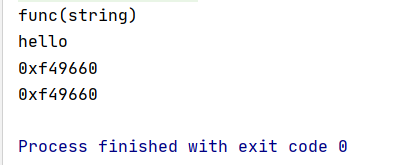
可以看到,函数 f 被赋值给了一个为函数类型的变量 f2,而且这个 f2 已经具备了 f 的功能。而且我们可以看到,f 和 f2 的地址是相同的,这更加说明函数就是一个引用类型,我们给 f2 赋值的过程其实就是将 f 的地址传递给 f2。
2.3.2、匿名函数
Go 语言是支持函数式编程的:
- 将匿名函数作为另一个函数的参数,回调函数
- 将匿名函数作为另外一个函数的返回值,形成闭包
package main
import (
"fmt"
)
func main() {
f1()
f2:=f1
f2()
// 匿名函数
f3:=func(){
fmt.Println("函数 f3")
}
f3()
// 进一步简化
func(){
fmt.Println("函数 f4")
}()
// 带参数的匿名函数
func(name string){
fmt.Println("hello " + name)
}("tom")
// 带返回值的匿名函数
sum:=func(a,b int) int{
return a+b
}(1,1)
fmt.Println(sum)
}
func f1() {
fmt.Println("函数 f1")
}2.3.3、回调函数
把一个函数作为另一个函数的参数:
比如:f2(f1())
其中,f2 就叫做高阶函数,f1 就叫做回调函数
func main(){
res2 := f2(1,1,f1)
fmt.Println(res2) // 2
}
// 高阶函数
func f2(a,b int,f1 func(int,int) int) int {
return f1(a,b)
}
// 回调函数
func f1(a,b int) int {
return a+b
}这是一个非常高级的特性, 之后我们可以对同一个对象(高阶函数的参数)进行不同的业务操作,就可以通过给高阶函数传递不同的回调函数来执行不同的业务。
2.3.4、闭包
如果一个函数包含层函数,内层函数可以操作外层函数的局部变量(当外层函数销毁,但是内存函数没有销毁,那么这个局部变量依旧存在),并且外层函数的返回值就是这个内层函数。而内层函数和外层函数的局部变量就称为闭包结构。
在闭包结构中,局部变量的生命周期会发生改变,正常的局部变量的生命周期会随着函数创建而创建,随着函数的销毁而销毁。但是闭包结构中的外层函数的局部变量并不会随着外层函数的结束而销毁,因为内层函数还在继续使用。
package main
import "fmt"
func main() {
r1 := increament()
v1 := r1()
fmt.Println("r1 => ",v1)
v2 := r1()
fmt.Println("r1 => ",v2)
r2 := increament()
fmt.Println("r2 => ",r2())
fmt.Println("r2 => ",r2())
fmt.Println("r1 => ",r1())
}
func increament() func() int {
// 局部变量
i := 0
// 内层函数
num := func() int{ // num 是 func() int 类型
i++
return i
}
return num
}运行结果:

在上面,当我们把 increament 函数赋值给 r1 的时候,相当于给了 r1 它的引用地址,所以 r1 可以直接执行。但是当我们把 increament 函数赋值给 r2 的时候,按道理给的是同一个引用地址(普通函数赋值给一个函数类型变量的时候一定是同一个地址),但事实上,它会给 r1 一个新的地址值:
package main
import "fmt"
func main() {
r:=f
fmt.Printf("r地址=%p,f地址=%p\n",r,f)
r1 := increament()
fmt.Printf("r1地址=%p,increament地址=%p\n",r1,increament)
v1 := r1()
fmt.Println("r1 => ",v1)
v2 := r1()
fmt.Println("r1 => ",v2)
r2 := increament()
fmt.Printf("r2地址=%p,increament地址=%p\n",r2,increament)
fmt.Println("r2 => ",r2())
fmt.Println("r2 => ",r2())
fmt.Println("r1 => ",r1())
}
func increament() func() int {
// 局部变量
i := 0
// 内层函数
num := func() int{ // num 是 func() int 类型
fmt.Printf("i 的地址=%p ",&i)
i++
return i
}
return num
}
func f(){
fmt.Println("f")
}运行结果:
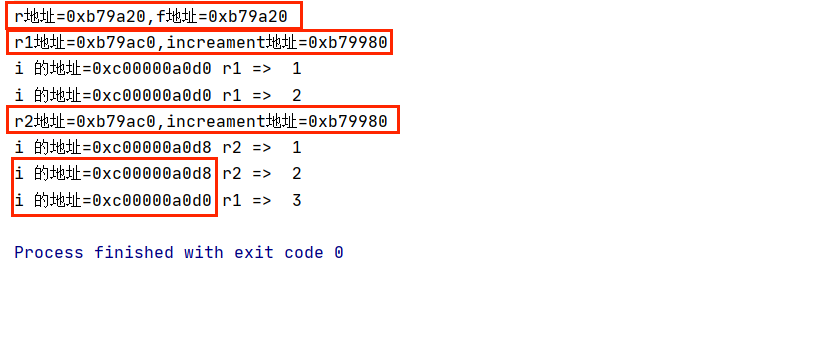
可以看到,首先,变量 r 和普通函数 f 的引用地址是完全一样的。
而 r1 和 r2 同样都是直接通过 increament 直接赋值的,但是它们和 increament 的引用地址并不相同。此外,尽管 r1 和 r2 引用地址相同,但是它俩的局部变量 i 的地址并不相同!尽管 r1 和 r2 的引用地址相同,按道理它俩操作的是一个对象(内存地址),但是事实上这个对象的局部变量地址并不相同。
总结
可以感觉到,Go 语言确实是一门简洁但是又严格的语言,它不像 Python 那种弱语言类型说来就来一个变量,什么类型都不知道。而且 Go 语言中的变量不使用就会报错、可以把不需要的值传给匿名变量抛弃掉,而且不占内存,所以也很高效。
此外,Go 同样支持函数式编程,虽然不如 Scala 的支持度高,但是性能比 Scala 是要更加高效的。