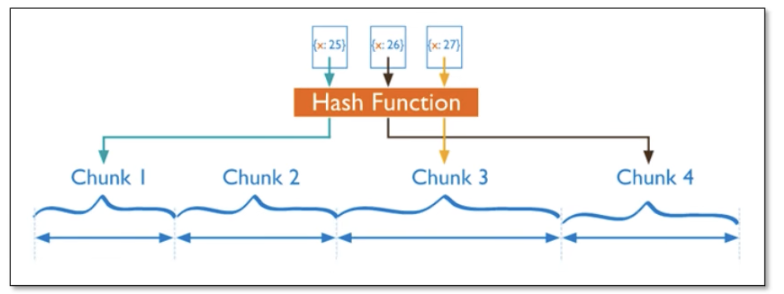
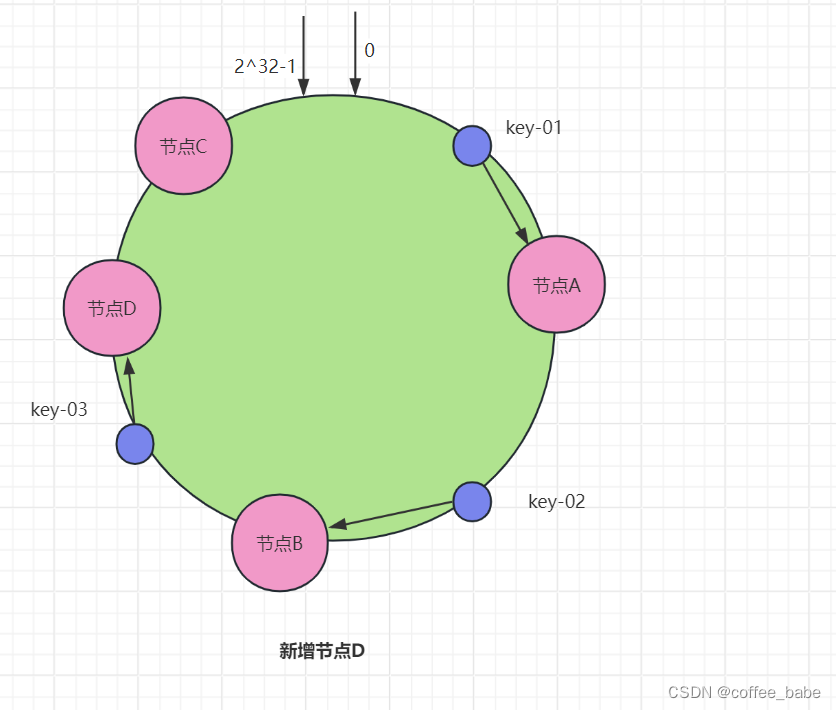
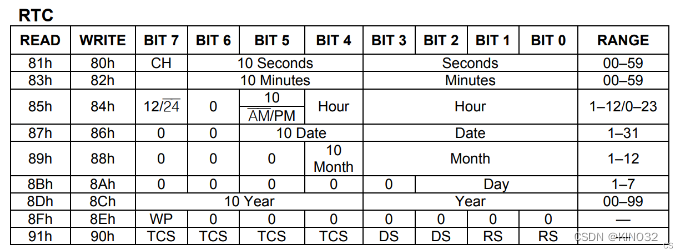
DeepVisionary 每日深度学习前沿科技推送&顶会论文&数学建模与科技信息前沿资讯分享,与你一起了解前沿科技知识!
引言:AMR在大型语言模型中的作用
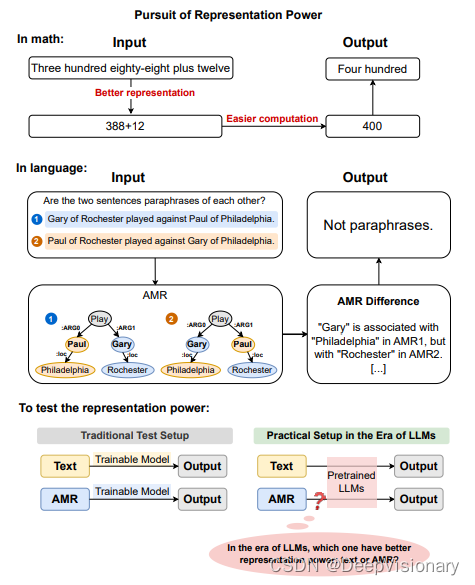
在自然语言处理(NLP)的领域中,抽象意义表示(Abstract Meaning Representation,简称AMR)作为一种语义表示方法,旨在通过提炼句子中的关键信息(如实体、关系等),以简化语义任务的处理过程。AMR通过显式表示句子的命题结构,去除了文本中与语义任务无关的信息,使得重要信息更加突出,从而理论上简化了模型学习执行这些任务的难度。这种表示方式类似于阿拉伯数字在算术运算中的应用,有助于简化计算过程。
然而,在大型语言模型(Large Language Models,简称LLMs)的应用场景中,AMR的作用并非一目了然。随着预训练大型语言模型的广泛使用,这些模型已经能够直接高效地处理原始文本,而无需依赖于中间的形式化表示。例如,通过链式思考(Chain-of-Thought)提示等方法,模型能够在没有中间语义表示的情况下,直接从非形式化的文本中提取信息并实现高性能。
尽管AMR在理论上具有将复杂语义结构形式化的优势,但在实际应用中,其对LLMs性能的贡献并不如在传统设置中那样显著。研究表明,AMR在LLMs中的应用可能仅对部分样本有所帮助,而在其他情况下可能不会带来性能提升,甚至可能因为AMR解析器的性能不足而限制了其效果。
此外,当前的趋势是利用现有的预训练模型而不进行额外的训练或微调,这种情况下,AMR的作用变得更加复杂。在不进行训练的情况下,理想的语义表示可能并不适用于所有LLMs,因为这些模型在预训练过程中已经根据其训练数据优化了特定的表示方式。
因此,AMR作为中间语义表示在大型语言模型中的角色,成为了一个值得进一步探索的问题。特别是在不涉及额外训练或微调的应用场景中,理解和评估AMR对LLMs性能的具体影响,对于推动语义表示方法的发展和优化具有重要意义。
论文标题、机构、论文链接和项目地址
1. 论文标题: Analyzing the Role of Semantic Representations in the Era of Large Language Models
2. 参与机构:
- ETH Zurich
- University of Illinois at Urbana-Champaign (UIUC)
- Max Planck Institute for Intelligent Systems (MPI)
- Carnegie Mellon University (CMU)
- University of Michigan
- New York University (NYU)
3. 论文链接: https://arxiv.org/pdf/2405.01502.pdf
4. 项目地址: 本文中未提及具体的项目地址,仅提供了论文的链接。
AMR的基本概念及其在NLP中的应用
1. AMR的定义和结构
抽象意义表示(Abstract Meaning Representation, AMR)是一种用于捕捉句子中关键语义信息的结构化表示形式。AMR通过图形结构来表示句子的语义内容,其中节点代表实体或概念,边代表它们之间的关系。这种表示形式旨在去除文本中与语义任务无关的信息,同时突出最重要的信息(如实体、关系等),使得这些信息更易于操作和理解。
2. AMR在传统NLP任务中的应用
AMR在多种自然语言处理(NLP)任务中显示出其有效性。例如,在机器翻译、文本摘要和信息抽取等领域,AMR能够提供更深层次的语义理解,从而改进模型的性能。通过将句子转换为AMR,模型能够更准确地捕捉语言的深层含义,这对于处理复杂的语言结构和含义尤为重要。
3. AMR与大型语言模型的结合
尽管大型语言模型(LLMs)如GPT和BERT在直接处理文本方面已经取得了显著的成功,但结合AMR和LLMs可以进一步提升处理语义任务的能力。研究表明,AMR作为中间表示的使用可以帮助LLMs更好地理解和生成语义上更加准确的输出。例如,在不进行额外训练的情况下,使用AMR能够帮助LLMs在特定样本上改进性能,尽管整体性能提升可能有限。此外,通过优化LLMs以更好地映射AMR表示到输出空间,可以进一步提高性能。
总体而言,AMR提供了一种强大的工具,用于增强NLP模型对文本的语义理解。尽管在大型语言模型的时代,直接处理文本已经非常有效,但AMR仍然在某些情况下显示出其独特的价值,特别是在需要深层语义理解的应用场景中。未来的研究可以探索如何更好地整合AMR与LLMs,以充分利用两者的优势,提高NLP系统的整体性能和灵活性。
实验设计:AMRCOT方法的介绍
1. AMRCOT的概念和设计原理
AMRCOT是一种基于抽象意义表示(AMR)的NLP任务提示方法。AMR通过提取文本中的关键语义信息(如实体、关系等),为语言模型提供了一种中间语义表示。这种表示旨在帮助语言模型更有效地理解和处理复杂的语言任务。AMRCOT方法通过将输入文本与其对应的AMR一起呈现给预训练的大型语言模型(LLM),来探索AMR在没有模型训练的情况下,对LLM性能的潜在影响。
2. 选择的五个NLP任务和数据集
在我们的实验中,选择了五个不同的NLP任务来测试AMRCOT方法的效果,这些任务包括:
- Paraphrase Detection:使用PAWS数据集,测试模型是否能识别两个句子是否为同义重述。
- Machine Translation:使用WMT16数据集,评估模型将文本从一种语言翻译成另一种语言的能力。
- Logical Fallacy Detection:使用自定义的逻辑谬误检测数据集,探索模型识别逻辑错误的能力。
- Event Extraction:从特定文本中提取事件信息,使用自定义的事件提取数据集。
- Text-to-SQL Generation:使用SPIDER数据集,测试模型将自然语言查询转换为SQL查询的能力。
这些任务被选中是因为它们依赖于复杂的句子结构,且在预训练语言模型时代之前,AMR已被证明在这些任务中具有潜在的帮助。
3. AMRCOT与基线模型(BASE)的比较
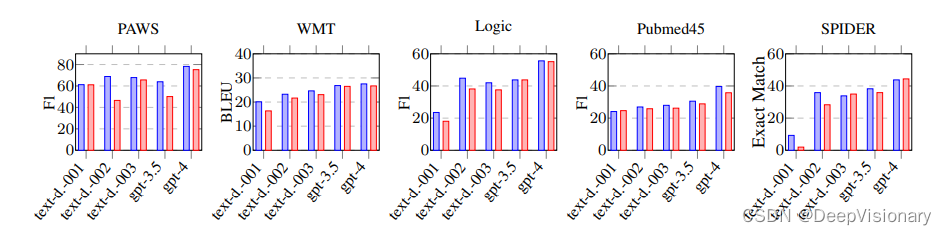
在实验中,我们将AMRCOT的表现与直接使用LLMs进行任务(基线模型,简称BASE)的表现进行了比较。实验结果显示,尽管AMRCOT在某些样本中显示出帮助LLM的潜力,但整体上,AMRCOT对LLM的性能影响并不显著。例如,在文本到SQL的生成任务中,AMRCOT相较于BASE模型仅显示出轻微的性能提升(增加了0.61个百分点),而在其他任务中,性能有时甚至会略有下降。
这些发现提示我们,尽管AMR作为一种中间语义表示有其独特的优势,但在当前的LLM应用场景中,其作用可能并不如预期的显著。这可能是因为LLM已经通过大规模的数据预训练,学会了从原始文本中直接提取和处理复杂信息。因此,未来的研究可能需要探索如何改进AMR的表现,或者如何更好地将AMR与LLM的处理能力结合起来。
实验结果与分析
1. AMRCOT在各任务上的表现
在五个不同的自然语言处理任务上,AMRCOT与基础模型(BASE)的表现进行了比较。根据实验数据(见表3),AMRCOT在大多数任务上的表现并没有显示出显著的改善。例如,在文本到SQL的代码生成任务中,AMRCOT相较于BASE模型仅显示出微小的性能提升(增加了0.61个百分点)。而在其他任务如机器翻译和逻辑推理检测中,AMRCOT的引入甚至导致了性能的轻微下降(-1到-3个百分点)。这些结果表明,尽管AMR作为一种中间语义表示被期望能够提升模型性能,但在实际应用中其效果并不如预期显著。
2. AMR的帮助与不帮助的案例分析
尽管总体表现不一,AMRCOT在某些特定样本上确实帮助了性能的提升。通过对比AMRCOT和BASE的输出,我们发现在某些案例中AMR的引入确实帮助模型做出了更准确的预测。例如,在处理包含多义词或复杂句子结构的文本时,AMR能够提供更清晰的语义结构,帮助模型理解深层的语义关系。然而,也有案例显示AMR的引入反而使得模型性能下降,特别是在处理含有大量专有名词或数字的文本时,AMR的简化和抽象可能丢失了重要的上下文信息,导致性能下降。
3. 不同大型语言模型中AMR的效果
在不同的大型语言模型(LLMs)中,AMR的效果也表现出一定的差异。通过在多个预训练模型上运行相同的AMRCOT实验,我们观察到一些模型能够更好地利用AMR中的信息,而其他模型则可能因为预训练任务和目标的不同而未能有效利用AMR。例如,一些专门为理解复杂语义结构调优的模型在使用AMR时表现更佳,而那些主要侧重于表面文本匹配的模型则可能不会从AMR中获得同样程度的益处。
总体而言,这些实验结果表明,虽然AMR作为一种中间语义表示在理论上具有潜力,但其在实际应用中的效果受到多种因素的影响,包括任务的性质、模型的预训练特性以及输入数据的特点。未来的研究可以进一步探索如何优化AMR的生成和应用,以更好地发挥其在自然语言处理中的潜力。
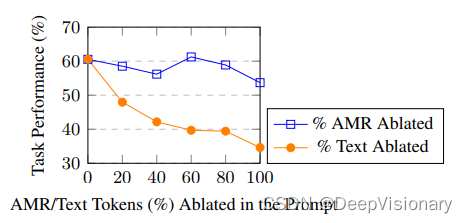
讨论:AMR在LLM中的表现和挑战
1. AMR的优势和局限性
Abstract Meaning Representation (AMR) 通过提炼句子的命题结构,去除与语义任务无关的信息,同时突出显示最重要的信息(实体、关系等),理论上应该使得模型更容易学习执行这些任务。然而,AMR的学习和操作并非易事,特别是在AMR数据有限的情况下。此外,现代大型语言模型(LLM)通过直接操作文本已经非常有效,而不需要使用中间形式的表示,这表明AMR在实际应用中可能不如直接文本操作有效。
2. AMR对LLM性能的具体影响
根据实验数据,AMR在LLM的应用中并没有显示出比传统设置更大的贡献。在五种不同的NLP任务中,AMR对性能的影响仅在-3到+1百分点之间波动。虽然在某些样本子集中AMR有所帮助,但总体上,AMR并没有显著提高LLM的性能。这可能是因为预训练的LLM已经能够有效地处理和理解原始文本,而不需要额外的语义表示。
3. 如何改进AMR以提高LLM的表现
研究表明,提高AMR的表现可能不在于改进AMR解析器的性能,而在于提高LLM将AMR表示映射到输出空间的能力。这意味着未来的研究应该集中在如何优化LLM处理AMR的方法上,而不仅仅是改进AMR本身。此外,实验发现,AMR在没有训练的情况下帮助LLM性能的情况有限,这提示我们在实际应用中可能需要重新考虑AMR的角色和有效性。
总结与未来展望
1. AMR在现代NLP中的角色和重要性
抽象意义表示(AMR)在自然语言处理(NLP)中的应用已经显示出其独特的价值,尤其是在语义任务中。AMR通过显式地表达句子的命题结构,去除了文本中与语义任务无关的信息,同时突出了最重要的信息(如实体、关系等),使得这些信息更易于操作。理论上,这意味着使用AMR作为中间表示应该能够简化模型学习执行这些任务的过程,类似于阿拉伯数字在算术运算中的作用。
然而,尽管AMR在传统NLP设置中表现出较好的性能,但在大型语言模型(LLM)的时代,AMR的作用似乎并不如预期。研究表明,AMR在LLM中的应用并没有带来显著的性能提升,这可能是因为LLM已经能够直接处理原始文本,并且在没有特定训练的情况下,已经具备了处理复杂语义任务的能力。
2. 对AMR进一步研究和应用的建议
尽管AMR在LLM中的直接应用效果有限,但它在特定样本和任务中仍显示出潜力。未来的研究可以集中在如何改进AMR的解析性能,以及如何提高LLM对AMR表示的映射能力。此外,研究可以探索在不进行模型训练的情况下,如何利用AMR来辅助LLM执行更复杂的语义任务,例如通过改进AMR的结构来更好地捕捉语义等价性和多词表达(MWE)。
3. LLM与语义表示的未来发展方向
在LLM的背景下,语义表示的研究可能需要转向探索如何使这些表示更适合预训练模型的使用。例如,通过链式思考(Chain-of-Thought)提示的方式,可以探索如何设计中间表示来更好地发挥LLM的能力。此外,未来的研究可以探索不同的语义表示方法,如何与LLM结合,以及如何通过这些方法提高模型在特定任务上的解释性和鲁棒性。
总之,AMR作为一种语义表示工具,在现代NLP的应用中显示出了其独特的价值和潜力。尽管在LLM的应用中面临挑战,但通过进一步的研究和改进,有望在未来的NLP应用中发挥更大的作用。
关注DeepVisionary 获取更多数模细节资讯,了解更多深度学习前沿科技信息&顶会论文分享!