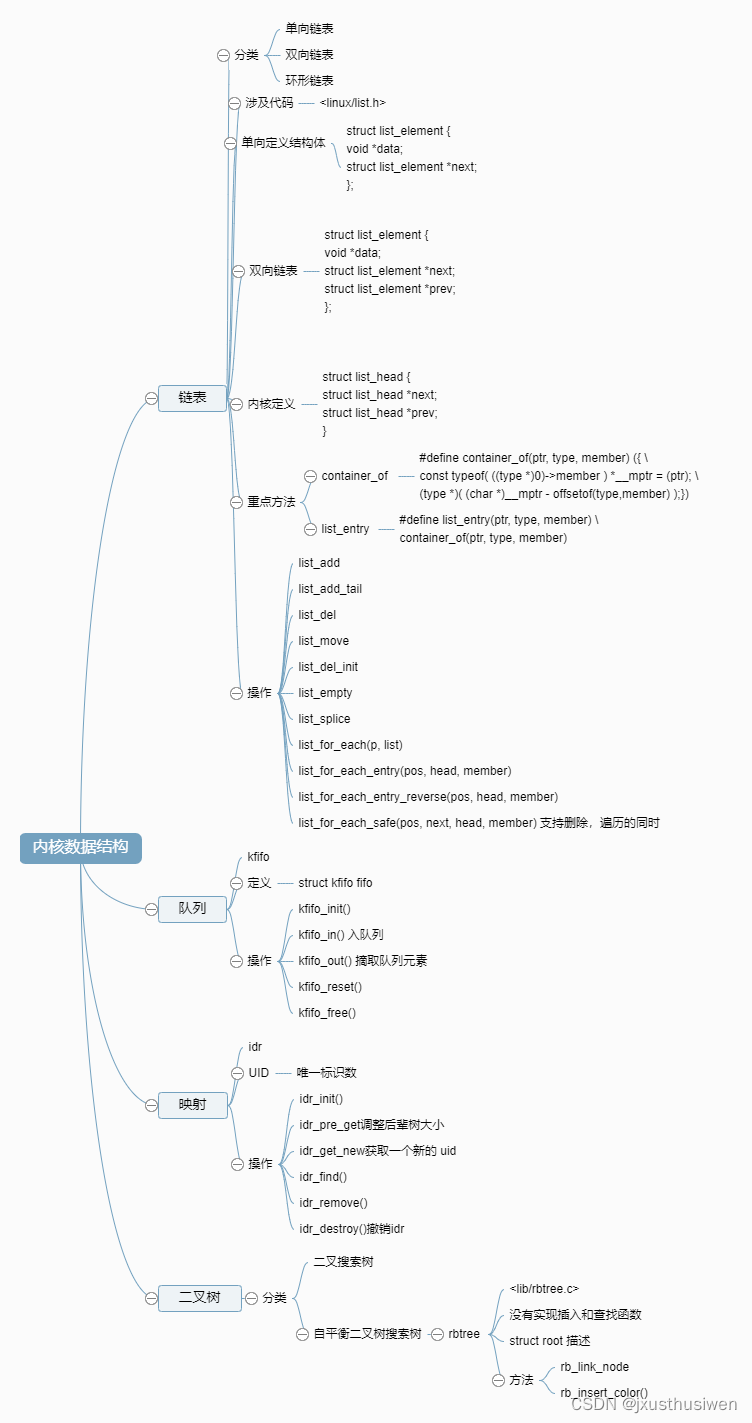
文章目录
- 1. 本质
- 2. 用Embedding产生一个10 x 5 的随机词典
- 3. 用这个词典编码两个简单单词
- 4. Embedding的词典是可以学习的
- 5. 例子完整代码
1. 本质
P y t o r c h \mathrm{Pytorch} Pytorch 的 E m b e d d i n g \mathrm{Embedding} Embedding 模块是一个简单的查找表,用于存储固定字典和大小的嵌入。 n n . E m b e d d i n g \mathrm{nn.Embedding} nn.Embedding 层本质上是一个权重矩阵,其中每一行代表词汇表中每个单词的向量表示。这个权重矩阵的大小是 [ n u m _ e m b e d d i n g s , e m b e d d i n g _ d i m ] \mathrm{[num\_embeddings, embedding\_dim]} [num_embeddings,embedding_dim],其中 n u m _ e m b e d d i n g s \mathrm{num\_embeddings} num_embeddings 是词汇表的大小, e m b e d d i n g _ d i m \mathrm{embedding\_dim} embedding_dim 是嵌入向量的维度。
2. 用Embedding产生一个10 x 5 的随机词典
先用 E m b e d d i n g \mathrm{Embedding} Embedding 产生一个维度为 10 × 5 10\times5 10×5 的词典, 10 10 10 代表有十个词向量, 5 5 5 代表有每个词向量有 5 5 5 个元素。
import torch
import torch.nn as nn
embed = nn.Embedding(num_embeddings=10, embedding_dim=5)
embedding_matrix = embed.weight.data
print(f"nn Embedding 产生的词典是:\n {embedding_matrix.data}")
# nn Embedding 产生的词典是:
# tensor([[ 0.9631, -1.4984, 1.0561, 0.4334, 1.3060],
# [ 0.1714, 0.1842, 0.0532, 0.4573, -0.7236],
# [ 0.4692, 1.2857, 0.5260, -1.0966, -1.6009],
# [-0.7893, -0.2117, 0.0158, 1.1008, 0.9786],
# [ 0.9095, -0.4467, -0.6501, 0.6469, -0.3829],
# [-0.1534, -0.0128, 1.2285, -1.4347, 0.1968],
# [-2.0171, 1.0805, -0.7189, 0.6184, 0.6858],
# [-0.1328, -1.2482, -0.2517, -0.4750, 0.3215],
# [-0.7670, -0.0462, -0.4849, -0.6647, -0.6340],
# [ 0.7415, -2.2321, 1.3444, 0.3786, -0.2909]])
上述词典如下图所示,

3. 用这个词典编码两个简单单词
现在,我们将两个单词 p y t h o n , p y t o r c h \mathrm{python,pytorch} python,pytorch 用上面的词典编码成两个词向量。
-
建立这两个单词的列表,并获取各自的 i n d e x \mathrm{index} index;
# 示例:将两个单词“python”、“pytorch”根据上面的词典编码为对应的词向量 words_to_embed = ['python', 'pytorch'] # 获取每个单词的index,很明显,'python'的index是0, 'pytorch'的index是1。 word_index = torch.LongTensor([0, 1]) -
将这两个 i n d e x \mathrm{index} index 传入词典,就可以获取对应的词向量;
# 示例:将两个单词“python”、“pytorch”根据上面的词典编码为对应的词向量 words_to_embed = ['python', 'pytorch'] # 获取每个单词的index,很明显,'python'的index是0, 'pytorch'的index是1。 word_index = torch.LongTensor([0, 1]) # 将这两个index传入词典,就可以获取对应的词向量 embedded_words = embed(word_index) print(f"编码后的词向量为:\n{embedded_words.data.numpy()}") # 编码后的词向量为: # [[ 0.96313465 -1.4984448 1.0561345 0.43344542 1.3059521 ] # [ 0.17135063 0.18418191 0.05320966 0.45726374 -0.72364354]] -
p y t h o n \mathrm{python} python 这个单词的 i n d e x \mathrm{index} index 是0,对应的就是词典的第一行, p y t o r c h \mathrm{pytorch} pytorch 这个单词 i n d e x \mathrm{index} index 是1,对应的就是词典的第二行。
print(f"python 这个词对应的词向量为: \n{embedded_words.data.numpy()[0,:]}") # python 这个词对应的词向量为: # [ 0.96313465 -1.4984448 1.0561345 0.43344542 1.3059521 ] print(f"pytorch 这个词对应的词向量为: \n{embedded_words.data.numpy()[1,:]}") # pytorch 这个词对应的词向量为: # [ 0.17135063 0.18418191 0.05320966 0.45726374 -0.72364354]

4. Embedding的词典是可以学习的
- E m b e d d i n g \mathrm{Embedding} Embedding 产生的权重矩阵是可以学习的,意味着在模型的训练过程中,通过反向传播算法,嵌入向量会根据损失函数不断更新,以更好地表示数据中的语义关系。
- 在很多情况下,尤其是当训练数据较少时,使用预训练的嵌入向量(如 W o r d 2 V e c \mathrm{Word2Vec} Word2Vec)可以显著提高模型的性能。这些预训练向量通常是在非常大的文本语料库上训练得到的,能够捕捉到丰富的语义信息。在 P y t o r c h \mathrm{Pytorch} Pytorch 中,你可以通过初始化 n n . E m b e d d i n g \mathrm{nn.Embedding} nn.Embedding 层的权重为这些预训练向量来使用它们。即使使用预训练向量,你也可以选择在训练过程中进一步微调(更新)这些向量,或者保持它们不变。
5. 例子完整代码
import torch
import torch.nn as nn
import numpy as np
embed = nn.Embedding(num_embeddings=10, embedding_dim=5)
embedding_matrix = embed.weight.data
print(f"nn Embedding 产生的词典是:\n {embedding_matrix.data}")
# nn Embedding 产生的词典是:
# tensor([[ 0.9631, -1.4984, 1.0561, 0.4334, 1.3060],
# [ 0.1714, 0.1842, 0.0532, 0.4573, -0.7236],
# [ 0.4692, 1.2857, 0.5260, -1.0966, -1.6009],
# [-0.7893, -0.2117, 0.0158, 1.1008, 0.9786],
# [ 0.9095, -0.4467, -0.6501, 0.6469, -0.3829],
# [-0.1534, -0.0128, 1.2285, -1.4347, 0.1968],
# [-2.0171, 1.0805, -0.7189, 0.6184, 0.6858],
# [-0.1328, -1.2482, -0.2517, -0.4750, 0.3215],
# [-0.7670, -0.0462, -0.4849, -0.6647, -0.6340],
# [ 0.7415, -2.2321, 1.3444, 0.3786, -0.2909]])
# 示例:将两个单词“python”、“pytorch”根据上面的词典编码为对应的词向量
words_to_embed = ['python', 'pytorch']
# 获取每个单词的index,很明显,'python'的index是0, 'pytorch'的index是1。
word_index = torch.LongTensor([0, 1])
# 将这两个index传入词典,就可以获取对应的词向量
embedded_words = embed(word_index)
print(f"编码后的词向量为:\n{embedded_words.data.numpy()}")
# 编码后的词向量为:
# [[ 0.96313465 -1.4984448 1.0561345 0.43344542 1.3059521 ]
# [ 0.17135063 0.18418191 0.05320966 0.45726374 -0.72364354]]
print(f"python 这个词对应的词向量为: \n{embedded_words.data.numpy()[0,:]}")
# python 这个词对应的词向量为:
# [ 0.96313465 -1.4984448 1.0561345 0.43344542 1.3059521 ]
print(f"pytorch 这个词对应的词向量为: \n{embedded_words.data.numpy()[1,:]}")
# pytorch 这个词对应的词向量为:
# [ 0.17135063 0.18418191 0.05320966 0.45726374 -0.72364354]