简介
c++多线程基础需要掌握这三个标准库:std::thread, std::mutex, and std::async。
1. Hello, world
#include <iostream>
#include <thread>
void hello() {
std::cout << "Hello Concurrent World!\n";
}
int main()
{
std::thread t(hello);
t.join();
}- g++编译时须加上
-pthread -std=c++11; - 管理线程的函数和类在
<thread>中声明,而保护共享数据的函数和类在其他头文件中声明; - 初始线程始于
main(),新线程始于hello(); join()使得初始线程必须等待新线程结束后,才能运行下面的语句或结束自己的线程;
2. std::thread
<thread> 和 <pthread> 都是用于多线程编程的库,但是它们针对不同的平台和编程环境。主要区别如下:
-
平台依赖性:
<thread>是 C++11 标准库的一部分,提供了跨平台的多线程支持,因此可以在任何支持 C++11 标准的编译器上使用。<pthread>是 POSIX 线程库,它是在类 Unix 操作系统上的标准库,因此在 Windows 平台上并不直接支持。
-
语言级别:
<thread>是 C++ 标准库的一部分,因此它提供了更加面向对象和现代化的接口,与 C++ 其他部分更加协同。<pthread>是 C 库的一部分,它提供了一组函数来操作线程,使用起来更加类似于传统的 C 风格。
-
使用方式:
<thread>提供了std::thread类,使用起来更加符合 C++ 的面向对象设计,比如通过函数对象、函数指针等方式来创建线程。<pthread>提供了一组函数,比如pthread_create()来创建线程,它需要传入函数指针和参数。
下面来看看标准库thread类:
// 标准库thread类
class thread
{ // class for observing and managing threads
public:
class id;
typedef void *native_handle_type;
thread() _NOEXCEPT
{ // construct with no thread
_Thr_set_null(_Thr);
}
template<class _Fn,
class... _Args,
class = typename enable_if<
!is_same<typename decay<_Fn>::type, thread>::value>::type>
explicit thread(_Fn&& _Fx, _Args&&... _Ax)
{ // construct with _Fx(_Ax...)
_Launch(&_Thr,
_STD make_unique<tuple<decay_t<_Fn>, decay_t<_Args>...> >(
_STD forward<_Fn>(_Fx), _STD forward<_Args>(_Ax)...));
}
~thread() _NOEXCEPT
{ // clean up
if (joinable())
_XSTD terminate();
}
thread(thread&& _Other) _NOEXCEPT
: _Thr(_Other._Thr)
{ // move from _Other
_Thr_set_null(_Other._Thr);
}
thread& operator=(thread&& _Other) _NOEXCEPT
{ // move from _Other
return (_Move_thread(_Other));
}
thread(const thread&) = delete;
thread& operator=(const thread&) = delete;
void swap(thread& _Other) _NOEXCEPT
{ // swap with _Other
_STD swap(_Thr, _Other._Thr);
}
bool joinable() const _NOEXCEPT
{ // return true if this thread can be joined
return (!_Thr_is_null(_Thr));
}
void join()
{ // join thread
if (!joinable())
_Throw_Cpp_error(_INVALID_ARGUMENT);
// Avoid Clang -Wparentheses-equality
const bool _Is_null = _Thr_is_null(_Thr);
if (_Is_null)
_Throw_Cpp_error(_INVALID_ARGUMENT);
if (get_id() == _STD this_thread::get_id())
_Throw_Cpp_error(_RESOURCE_DEADLOCK_WOULD_OCCUR);
if (_Thrd_join(_Thr, 0) != _Thrd_success)
_Throw_Cpp_error(_NO_SUCH_PROCESS);
_Thr_set_null(_Thr);
}
void detach()
{ // detach thread
if (!joinable())
_Throw_Cpp_error(_INVALID_ARGUMENT);
_Thrd_detachX(_Thr);
_Thr_set_null(_Thr);
}
id get_id() const _NOEXCEPT
{ // return id for this thread
return (_Thr_val(_Thr));
}
static unsigned int hardware_concurrency() _NOEXCEPT
{ // return number of hardware thread contexts
return (_Thrd_hardware_concurrency());
}
native_handle_type native_handle()
{ // return Win32 HANDLE as void *
return (_Thr._Hnd);
}通过查看thread类的公有成员,我们得知:
- thread类包含三个构造函数:一个默认构造函数(什么都不做)、一个接受可调用对象及其参数的explicit构造函数(参数可能没有,这时相当于转换构造函数,所以需要定义为explicit)、和一个移动构造函数;
- 析构函数会在thread对象销毁时自动调用,如果销毁时thread对象还是joinable,那么程序会调用terminate()终止进程;
- thread类没有拷贝操作,只有移动操作,即thread对象是可移动不可拷贝的,这保证了在同一时间点,一个thread实例只能关联一个执行线程;
- swap函数用来交换两个thread对象管理的线程;
- joinable函数用来判断该thread对象是否是可加入的;
- join函数使得该thread对象管理的线程加入到原始线程,只能使用一次,并使joinable为false;
- detach函数使得该thread对象管理的线程与原始线程分离,独立运行,并使joinable为false;
get_id返回线程标识;hardware_concurrency返回能同时并发在一个程序中的线程数量,当系统信息无法获取时,函数也会返回0。注意其是static修饰的,应该这么使用–std::thread::hardware_concurrency()。
由于thread类只有一个有用的构造函数,所以只能使用可调用对象来构造thread对象。
可调用对象包括:
- 函数
- 函数指针
- lambda表达式
- bind创建的对象
- 重载了函数调用符的类
3. join和detach
使用 join() 的示例:
#include <iostream>
#include <thread>
void threadFunction() {
std::cout << "Thread is running..." << std::endl;
// Simulate some work
std::this_thread::sleep_for(std::chrono::seconds(3));
std::cout << "Thread completed." << std::endl;
}
int main() {
std::thread t(threadFunction);
// 等待线程完成
t.join();
std::cout << "Main thread continues..." << std::endl;
return 0;
}
在这个例子中,join() 方法用于等待线程 t 完成。主线程会被阻塞,直到线程 t 执行完毕。
运行结果:
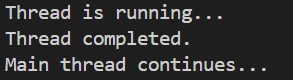
使用 detach() 的示例:
#include <iostream>
#include <thread>
void threadFunction() {
std::cout << "Thread is running..." << std::endl;
// Simulate some work
std::this_thread::sleep_for(std::chrono::seconds(3));
std::cout << "Thread completed." << std::endl;
}
int main() {
std::thread t(threadFunction);
// 分离线程,使得线程可以在后台运行
t.detach();
std::cout << "Main thread continues..." << std::endl;
// 由于线程被分离,这里不等待线程完成,直接返回
return 0;
}
在这个例子中,detach() 方法用于将线程 t 分离,使得线程可以在后台运行而不受主线程的控制。因此,主线程不会被阻塞,直接继续执行。
![]() 然后main已经结束
然后main已经结束
4. 线程间共享数据
条件竞争(race condition):当一个线程A正在修改共享数据时,另一个线程B却在使用这个共享数据,这时B访问到的数据可能不是正确的数据,这种情况称为条件竞争。
数据竞争(data race):一种特殊的条件竞争,并发的去修改一个独立对象。
多线程的一个关键优点(key benefit)是可以简单的直接共享数据,但如果有多个线程拥有修改共享数据的权限,那么就会很容易出现数据竞争(data race)。
std::mutex
C++保护共享数据最基本的技巧是使用互斥量(mutex):访问共享数据前,使用互斥量将相关数据锁住,当访问结束后,再将数据解锁。当一个线程使用特定互斥量锁住共享数据时,其他线程要想访问锁住的数据,必须等到之前那个线程对数据进行解锁后,才能进行访问。
在C++中使用互斥量
- 创建互斥量:即构建一个
std::mutex实例; - 锁住互斥量:调用成员函数
lock(); - 释放互斥量:调用成员函数
unlock(); - 由于
lock()与unlock()必须配对,就像new和delete一样,所以为了方便和异常处理,C++标准库也专门提供了一个模板类std::lock_guard,其在构造时lock互斥量,析构时unlock互斥量。
5. 异步好帮手:std::async
你可以使用 std::async 来在后台执行一个函数,并且可以通过 std::future 对象来获取函数的返回值。
#include <iostream>
#include <future>
int taskFunction() {
return 42;
}
int main() {
// 使用 std::async 异步执行任务
std::future<int> future = std::async(std::launch::async, taskFunction);
// 获取任务的结果
int result = future.get();
std::cout << "Result: " << result << std::endl;
return 0;
}
另一个例子:
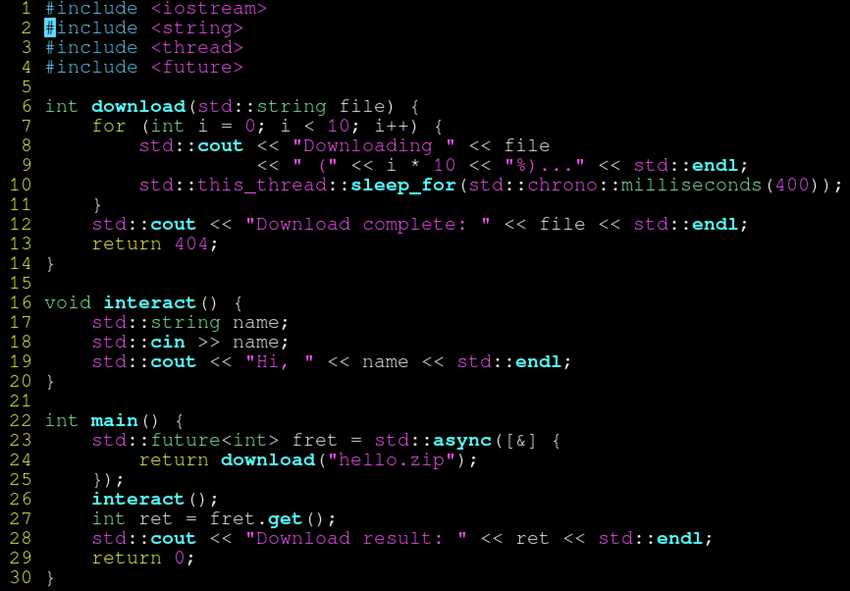
运行结果:
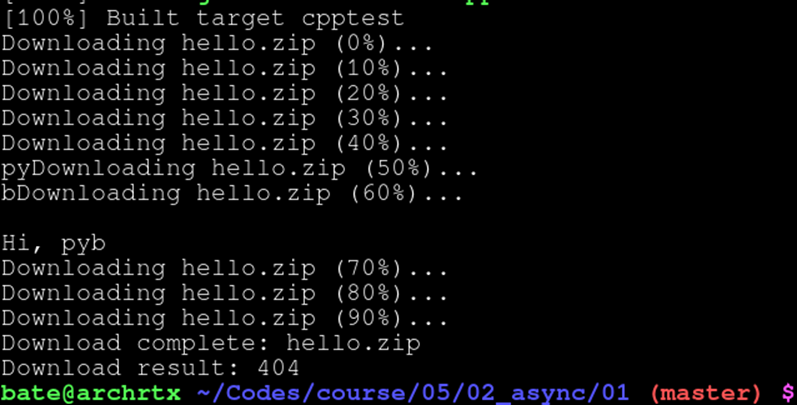
6. 应用例子:线程池(thread pool)
如果你是一个程序员,那么你大部分时间会待在办公室里,但是有时候你必须外出解决一些问题,如果外出的地方很远,就会需要一辆车,公司是不可能为你专门配一辆车的,但是大多数公司都配备了一些公用的车辆。你外出的时候预订一辆,回来的时候归还一辆;如果某一天公用车辆用完了,那么你只能等待同事归还之后才能使用。
线程池(thread pool)与上面的公用车辆类似:在大多数情况下,为每个任务都开一个线程是不切实际的(因为线程数太多以致过载后,任务切换会大大降低系统处理的速度),线程池可以使得一定数量的任务并发执行,没有执行的任务将被挂在一个队列里面,一旦某个任务执行完毕,就从队列里面取一个任务继续执行。
线程池通常由以下几个组件组成:
- 1.任务队列(Task Queue):用于存储待执行的任务。当任务提交到线程池时,它们被放置在任务队列中等待执行。
- 2.线程池管理器(Thread Pool Manager):负责创建、管理和调度线程池中的线程。它控制着线程的数量,可以动态地增加或减少线程的数量,以适应不同的工作负载。
- 3.工作线程(Worker Threads):线程池中的实际执行单元。它们不断地从任务队列中获取任务并执行。
- 4.任务接口(Task Interface):定义了要执行的任务的接口。通常,任务是以函数或可运行对象的形式表示。
使用线程池的好处
-
不采用线程池时:
创建线程 -> 由该线程执行任务 -> 任务执行完毕后销毁线程。即使需要使用到大量线程,每个线程都要按照这个流程来创建、执行与销毁。
虽然创建与销毁线程消耗的时间 远小于 线程执行的时间,但是对于需要频繁创建大量线程的任务,创建与销毁线程 所占用的时间与CPU资源也会有很大占比。
为了减少创建与销毁线程所带来的时间消耗与资源消耗,因此采用线程池的策略:
程序启动后,预先创建一定数量的线程放入空闲队列中,这些线程都是处于阻塞状态,基本不消耗CPU,只占用较小的内存空间。
接收到任务后,线程池选择一个空闲线程来执行此任务。
任务执行完毕后,不销毁线程,线程继续保持在池中等待下一次的任务。
线程池所解决的问题:
(1) 需要频繁创建与销毁大量线程的情况下,减少了创建与销毁线程带来的时间开销和CPU资源占用。(省时省力)
(2) 实时性要求较高的情况下,由于大量线程预先就创建好了,接到任务就能马上从线程池中调用线程来处理任务,略过了创建线程这一步骤,提高了实时性。(实时)
简单的ThreadPool 类实现
参考GitHub - progschj/ThreadPool: A simple C++11 Thread Pool implementation
ThreadPool.h:
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include <vector>
#include <queue>
#include <memory>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>
class ThreadPool {
public:
ThreadPool(size_t);
template<class F, class... Args>
auto enqueue(F&& f, Args&&... args)
-> std::future<typename std::result_of<F(Args...)>::type>;
~ThreadPool();
private:
// need to keep track of threads so we can join them
std::vector< std::thread > workers;
// the task queue
std::queue< std::function<void()> > tasks;
// synchronization
std::mutex queue_mutex;
std::condition_variable condition;
bool stop;
};
// the constructor just launches some amount of workers
inline ThreadPool::ThreadPool(size_t threads)
: stop(false)
{
for(size_t i = 0;i<threads;++i)
workers.emplace_back(
[this]
{
for(;;)
{
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->queue_mutex);
this->condition.wait(lock,
[this]{ return this->stop || !this->tasks.empty(); });
if(this->stop && this->tasks.empty())
return;
task = std::move(this->tasks.front());
this->tasks.pop();
}
task();
}
}
);
}
// add new work item to the pool
template<class F, class... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args)
-> std::future<typename std::result_of<F(Args...)>::type>
{
using return_type = typename std::result_of<F(Args...)>::type;
auto task = std::make_shared< std::packaged_task<return_type()> >(
std::bind(std::forward<F>(f), std::forward<Args>(args)...)
);
std::future<return_type> res = task->get_future();
{
std::unique_lock<std::mutex> lock(queue_mutex);
// don't allow enqueueing after stopping the pool
if(stop)
throw std::runtime_error("enqueue on stopped ThreadPool");
tasks.emplace([task](){ (*task)(); });
}
condition.notify_one();
return res;
}
// the destructor joins all threads
inline ThreadPool::~ThreadPool()
{
{
std::unique_lock<std::mutex> lock(queue_mutex);
stop = true;
}
condition.notify_all();
for(std::thread &worker: workers)
worker.join();
}
#endifmain.cpp:
#include <iostream>
#include <vector>
#include <chrono>
#include "ThreadPool.h"
int main()
{
ThreadPool pool(4);
std::vector< std::future<int> > results;
for(int i = 0; i < 8; ++i) {
results.emplace_back(
pool.enqueue([i] {
std::cout << "hello " << i << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "world " << i << std::endl;
return i*i;
})
);
}
for(auto && result: results)
std::cout << result.get() << ' ';
std::cout << std::endl;
return 0;
}这个 ThreadPool 类是一个简单的线程池实现,用于管理多线程任务的执行。下面逐步解释每个部分的功能:
-
成员变量:
workers:存储工作线程的向量。tasks:存储任务的队列,每个任务都是一个可调用对象(std::function<void()>)。queue_mutex:用于保护任务队列的互斥量。condition:用于线程间的条件变量,用于等待任务队列非空的条件。stop:标志位,用于指示线程池是否停止。
-
构造函数:
- 构造函数接受一个
size_t类型的参数threads,表示线程池中的工作线程数量。 - 在构造函数中,循环创建了
threads个工作线程,并将它们加入到workers向量中。 - 每个工作线程都是一个 lambda 表达式,它会循环等待任务队列非空,并执行队列中的任务,直到线程池被停止。
- 构造函数接受一个
-
enqueue() 方法:
enqueue()方法是一个模板函数,用于向线程池添加任务。- 它接受一个可调用对象
f和它的参数args...,并返回一个std::future对象,用于获取任务的返回值。 - 在
enqueue()方法中,首先创建了一个std::packaged_task对象,用于封装任务f,并获取了它的std::future对象。 - 然后将任务封装成一个 lambda 表达式,并加入到任务队列中。
- 最后通过条件变量
condition.notify_one()通知等待的工作线程有新的任务可执行。
-
析构函数:
- 析构函数会首先设置
stop标志位为true,然后通过条件变量condition.notify_all()通知所有等待的工作线程。 - 最后,使用
join()方法等待所有工作线程执行完毕
- 析构函数会首先设置
参考:
https://chorior.github.io/2017/04/24/C++-thread-basis/#managing_threads
C++ Concurrency In Action,Anthony Williams
GitHub - progschj/ThreadPool: A simple C++11 Thread Pool implementation