安顺学院本科毕业论文(设计)题目申请表
院别:数学与计算机科学 专业:数据科学与大数据 时间:2022年 5月26日
| 题 目 情 况 | 题目名称 | 基于hive数据仓库的考研信息离线分析系统的设计与实现 | |||
| 学生姓名 | 杨娣荧 | 学号 | 201903144042 | ||
| 题目来源 | A.实 验 √B.实习实践 C.社会调查 D.作品展示/毕业汇演 E其他 | √A.学生自拟 B.教师推荐 | |||
| 题目类别 | A.论文 √B.设计 | ||||
| 选 题 可 行 性 分 析 | 经济上的可行性: 基于hive数据仓库的考研信息离线分析系统,对技术的相关方面有相应的一些要求, 特别是在hive数据仓库方面,然而经过平时的坚持学习,这已不是问题,在硬件以及软件方面的环境要求都不算太高,经济方面具有较高的可行性。 技术上的可行性: 在本系统的开发中,需对前端技术,后端,hive以及IDEA、Pycharm开发工具具有一定的编码能力和操作能力,而经过大学四年的学习,对此有一定的了解及编码实践,另外在网站上有大量的学习视频,从而,在技术上可以实现。 开发上的可行性 此系统是B/S架构的系统,只需有浏览器即可,使得本系统可以很轻松的得到硬件的支撑并且运行起来,硬件并不需要安装一些软件支撑,这降低了开发的复杂度以及成本,所以在开发上是可行的。 | ||||
| 指 导 教 师 意 见 | 指导老师签字: 年 月 日 | ||||
| 院本科毕业论文(设计)指导小组审核意见 | 组长签字: 年 月 日 | ||||
安顺学院本科毕业论文(设计)开题报告
完成时间: 年 月 日
| 论文题目 | 基于hive数据仓库的考研信息离线分析系统的设计与实现 | ||||
| 学生姓名 | 杨娣荧 | 专 业 | 数据科学与大数据技术 | ||
| 学 科 | 工学 | 电子邮箱 | 1047399243@qq.com | ||
| 联系电话 | 18786125674 | 指导教师 | 于为 | ||
| 选 题 目 的 和 意 义 | 随着互联网技术的飞速发展,人们日常所产生的数据也在日益增长,社会也步入了大数据时代,而数据多带来的不仅仅是存储方面的问题,在数据价值方面也带来了不可忽视的问题。 大量的数据中,人们很难找到所需要有价值的数据。另外,网络的发达,同时也存在不少安全隐患,人们在找寻自己想要的数据时,可能会得到虚假信息,甚者,个人信息被盗取。所以本项目通过爬取数据分析存储于数据仓库中,以最直观的方法展现出来便于查询。 | ||||
| 研 究 现 状 述 评 | |||||
| 由于大数据时代的到来,人们每天产生的数据过多且冗余,数据密度高价值低的问题,所以在大量的数据下面人们很难找出有价值的那部分数据,现目前考研的人越发的多,但最开始的小白不知道从哪里抓起,上网查询资料,数据过于大量且繁琐,耽误很多时间,而本项目则是通过爬取研招网将各大学校的招生人数,专业及需要考查的科目收集整理做一个可视化平台,供有需要的人方便查询,用户可通过注册登录进入系统搜索自己想了解的信息。 | |||||
| 拟 研 究 的 目 标 和 主 要 内 容 | |||||
| 拟研究的目标: 本系统主要是运用Python语言、hive数据仓库、大数据分析技术以及Pycharm开发工具等技术和软件展现考研信息离线分析可视化,项目要求有数据采集,数据清洗,数据存储和数据展示等功能,在整体上能够给客户最直观的看到有价值的信息。 拟研究的主要内容: 通过爬取研招网及各大高校的考研信息数据,爬取各大院校的招生专业、招生人数及往年的录取分数线等,存储于本地数据库中,再通过sqoop将数据上传到hive数据仓库对数据进行清洗及分析,最后对其呈现一个可视化平台及实现用户查询功能。 | |||||
| 研 究 的 主 要 方 法、手 段 和 途 径 及 研 究 进 度 计 划 | |||||
| 主要方法: 需求分析、结构设计、数据采集、数据库分析、数据库设计、数据库搭建、前端界面设计、大数据架构选型、大数据分析、大数据开发、后端开发、系统测试和系统运行维护。 主要手段: 通过实现各个模块方法,实现大数据架构与后端联调,前后端的构建为主要手段,先采用大数据对数据进行分析,将分析后的数据存储到数据库,后端从数据库中获取数据,传给前端,前端进行展示。 主要途径: 为实现其功能和需求,开发工具使用Pycharm、IDEA,数据库搭建使用Navicat数据库客户端连接工具,服务器使用Apache服务器,大数据开发环境为linux环境,后端使用springboot的java框架。 进度计划: 2022年05月22日至06月2日:毕业设计选题 2022年06月28日至06月30日:完成论文开题报告 2022年07月01日至07月4日:进行开题答辩 2022年07月05日至07月25日:实现系统的所有实现与设计,并且完成初稿 2022年07月28日至07月30日:进行中期检查 2022年08月01日至08月20日:修改初稿并完成论文二稿 2022年08月22日至08月28日:完成该系统的各项测试 2022年08月22日至09月16日:修改二稿并完成论文三稿 2022年09月16日至09月17日:指导教师评阅时间 2022年09月18日至09月20日:评阅教师评阅时间 2022年09月21日至09月25日:进行论文答辩 2022年09月26日至09月28日:论文定稿 | |||||
| 论 文 提 纲 | |||||
| 1.绪论 简述课题背景及来源、国内外研究现状、研究的目标和内容、和课题的意义和目的。 2.系统开发环境及相关技术 开发环境:IDEA后端开发以及大数据开发,Pycharm数据爬取,navicat数据库设计,linux大数据环境搭建。 技术选型:前端使用html,css,javascript以及echars组件进行展示,后端使用java开源框架springboot,和数据库连接框架mybatis和mysql,大数据使用zookeeper进行集群分布式协调,flume和kafka进行数据采集和传输,hbase进行数据离线存储,hive实时同步hbase数据进行离线分析,spark streaming对数据进行实时分析并且存储。 3.基于hive数据仓库的考研信息离线分析可视化平台分析 研究目标、平台需求分析、可行性分析、性能分析。 4.基于hive数据仓库的考研信息离线分析可视化平台设计 mysql,hive数据库的设计、平台总体框架。 5.基于hive数据仓库的考研信息离线分析可视化平台展现 主要实现的功能模块:前端数据展示,大数据数据获取,数据清洗,数据存储,数据展示,后端接口编写,数据库设计。 6.结语 从此项目中对项目的从0到1开发,从前端到后端再到大数据进行了一个贯通,对个人的成长极其重要。 | |||||
| 开 题 报 告 主 要 参 考 文 献 | |||||
| [1]邓凤明. 大数据生态系统”大数据分析与应用”实验课程体系中的应用研究[D].中央民族大学,2019. [2]A Study of Multicultural Space in Seoul : Analysing the Coverage of Foreign Communities with News Big Data Analytics ‘BigKinds’ for 27 Years[J]. Journal of Media Economics & Culture,2017,15(2): [3]李维,陈江治,程丽萍,刘雨航,魏周思宇.大数据分析对消费者行为的影响[J].商业故事,2018,{4}(20):107. [4]戴红芳,罗金光,先晓兵.基于数据仓库的数据分析探索与实践[J].中国教育信息化,2015(10):13-15. [5]高运华.基于数据仓库的数据质量分析和评估[J].黑龙江科技信息,2014(20):165. [6]王峰.基于数据仓库的大学生成绩分析与应用[J].计算机光盘软件与应用,2013,16(05):207-208. [7]刘珍珍.基于数据仓库的高中学生成绩分析模型设计[J].电脑知识与技术,2011,7(03):495-496. [8]岳晓融,张立国.大数据分析在高校精准化就业服务模式中的应用研究[J].中国教育信息化,2022,28(05):105-113. [9]Lee In,Mangalaraj George. Big Data Analytics in Supply Chain Management: A Systematic Literature Review and Research Directions[J]. Big Data and Cognitive Computing,2022,6(1). [10]程学旗,刘盛华 ,张儒清 .大数据分析处理技术新体系的思考[J].中国科学院院刊,2022,37(01):60-67.DOI:10.16418/j.issn.1000-3045.20211117005. [11]王宏,嵇绍国.大数据分析的现实应用及发展趋势研究[J].信息网络安全,2021(S1):134-138. [12]Raghotham Murthy,Rajat Goel. Peregrine: Low-latency queries on Hive warehouse data[J]. XRDS: Crossroads, The ACM Magazine for Students,2012,19(1). [13]王庆涛,吕迎丽.试论如何采用数据仓库技术建设管理信息系统[J].信息通信,2020(06):188-189. [14]方昕.数据仓库技术在高校信息系统的运用[J].信息与电脑(理论版),2019(10):143-144. [15]张军,王芬芬.数据仓库技术在高校数据统计与分析系统中的应用研究[J].智能计算机与应用,2019,9(03):122-125. | |||||
| 指 导 教 师 意 见 | 指导教师(签名):
年 月 日 | ||||
| 院 本 科 论 文 (设计) 指 导 小 组 审 核 意 见 | 审核组长(签名): 审核小组成员(签名):1. 2. 3. 4. 年 月 日 | ||||

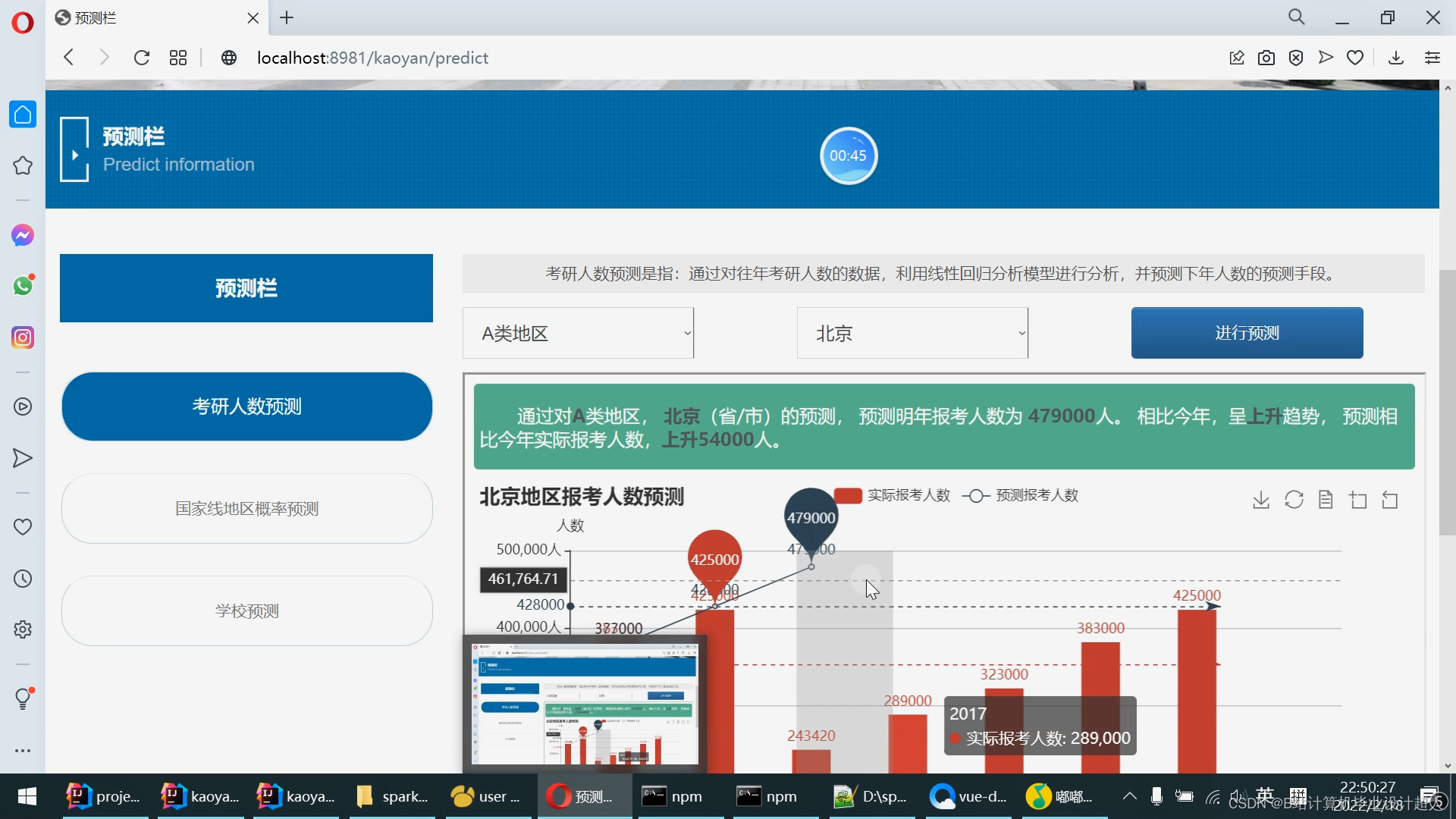

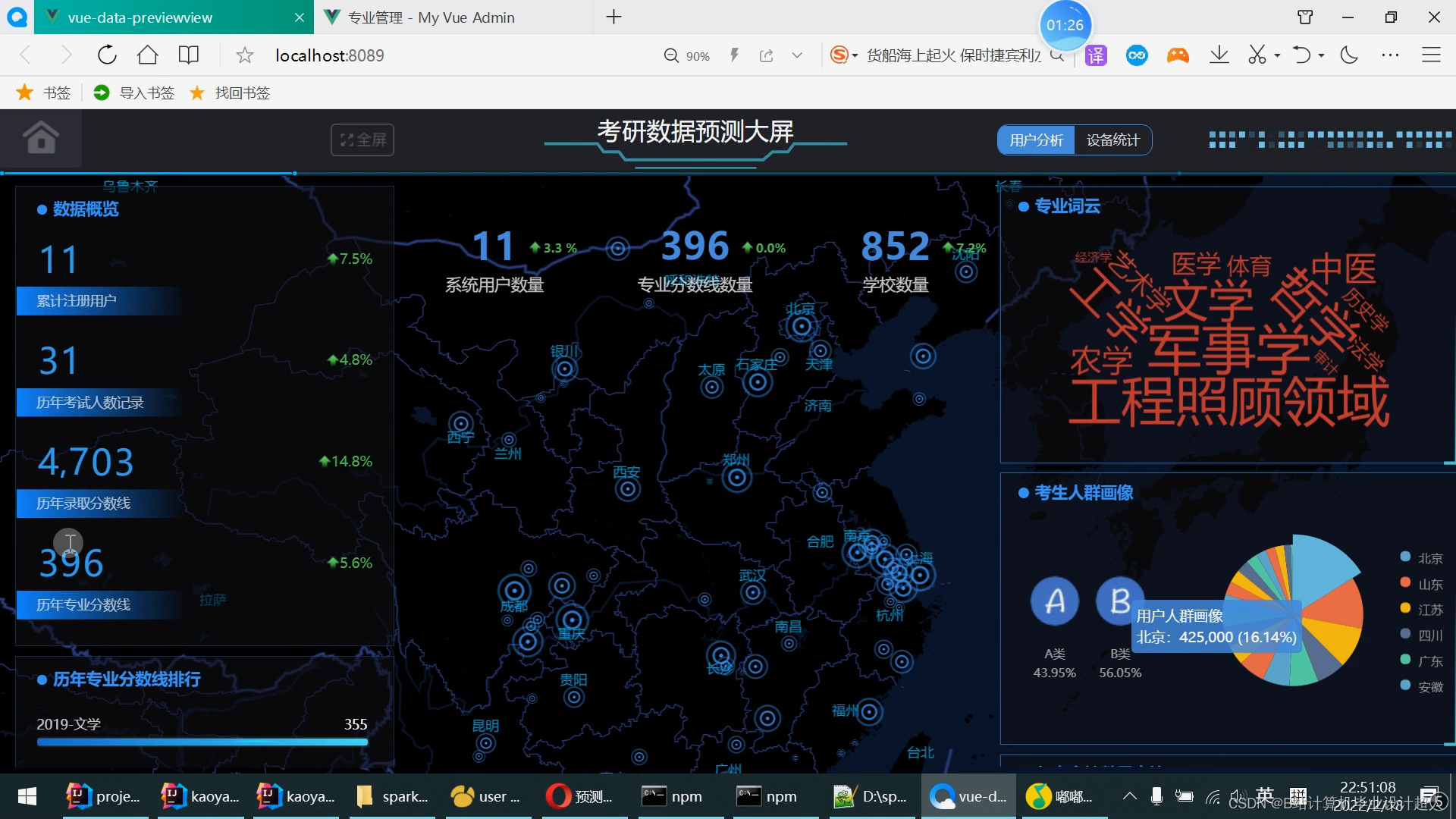
核心算法代码分享如下:
# coding=utf-8
import sys
import demjson
from tool import SqlHelper
"""
绘画动态国家线柱状图需要的数据
"""
# 定义结构
total_data = {}
def createJson(subject, scores):
# sql调用
sql = SqlHelper.MySQLhelper()
# 年份
years = []
# 查询年份
information = sql.fetch_all_args("select distinct year from stateline where subject = %s order by year", (subject))
for infor in information:
# 添加年份
years.append(str(infor['year']))
# 根据年份和类别查询分数
inforsA = sql.fetch_all_args("select * from stateline where subject = %s and year = %s and classifier = 'A类'",
("理学", infor['year']))
inforsB = sql.fetch_all_args("select * from stateline where subject = %s and year = %s and classifier = 'B类'",
("理学", infor['year']))
# 转换格式,添加列表
for inforA, inforB in zip(inforsA, inforsB):
datas = []
data = {}
daA = []
daB = []
daY = []
# 添加B类地区分数
daB.append(inforB['equal100'])
daB.append(inforB['greater100'])
daB.append(inforB['total'])
data['data'] = daB
datas.append(data)
data = {}
# 添加你输入的分数
daY.append(scores[0])
daY.append(scores[1])
daY.append(scores[2])
data['data'] = daY
datas.append(data)
data = {}
# 添加A类地区分数
daA.append(inforA['equal100'])
daA.append(inforA['greater100'])
daA.append(inforA['total'])
data['data'] = daA
datas.append(data)
# 添加分数数据
total_data['y' + str(infor['year'])] = datas
# 添加年份
total_data['years'] = years
# 添加专业
total_data['subject'] = subject
if __name__ == '__main__':
subject = sys.argv[1]
scores = demjson.decode(sys.argv[2])
# subject = '理学'
# scores = {'scores': [55,55,155]}
# 调用生成json函数
createJson(subject, scores['scores'])
print(total_data)