一、引入
在上一篇介绍了如何使用 pandas 处理飞书接口返回的数据,并将处理好的数据入库。最终的代码拓展性太差,本篇来探讨下如何使得上一篇的最终代码拓展性更好!
为什么上一篇的代码拓展性太差呢?我总结了几点:
- 列名是硬编码(写死的)
- pandas 和 MySQL 数据表的字段名和列名的对应关系也是硬编码
- MySQL 数据表的字段名的数据类型也是硬编码
再抽象一层,其实就是三个对象:多维表、pandas 的 DataFrame 和MySQL 数据表直接字段和数据类型的映射关系的问题。如果单独维护该映射关系,便可以做到通用性。
在飞书端口,我们可以获取到多维表的列名和对应的数据类型。
在 pandas.DataFrame 端口的字段名,需要提供一个飞书列名的映射关系进行转换,而数据类型,在这一阶段主要是根据后续要入库的数据类型来决定,参考 MySQL 的数据类型,一般使用 pandas 默认的数据类型即可。
在 MySQL 表端口的字段名可以直接引用 pandas.DataFrame 的字段名,也方便数据的插入,而数据类型,由于同一个数据类型的数据是一致的,所以可以直接基于数据类型形成一个通用的映射关系。由于 pandas 的字段名和 MySQL 的字段名保持一致,所以列名映射关系也可以定义为飞书多维表的列名与入库表对应的英文字段名的映射关系。
综上,只需要维护两个数据关系即可:多维表的列名和 pandas.DataFrame 的字段名、多维表的数据类型和 MySQL 的数据类型。而后者基本上又是固定的,所以日常只需要维护前者即可。
分析完需求,接下来开始开发。
本文结构:介绍飞书获取字段 API、优化代码逻辑,后者包含飞书各个数据类型的通用处理方案、自动构建 SQL 和链接分析三个部分。
二、飞书API-列出字段
本次要介绍的 API 叫列出字段,它的功能就是根据 app_token 和 table_id,获取数据表的所有字段。
同样,还是调出 API 调试台,左边依次查找云文档>多维表格>字段>点击列出字段,然后获取 access_token,填写多维表的路径参数,点击开始调试,便可以看到获取到的数据内容。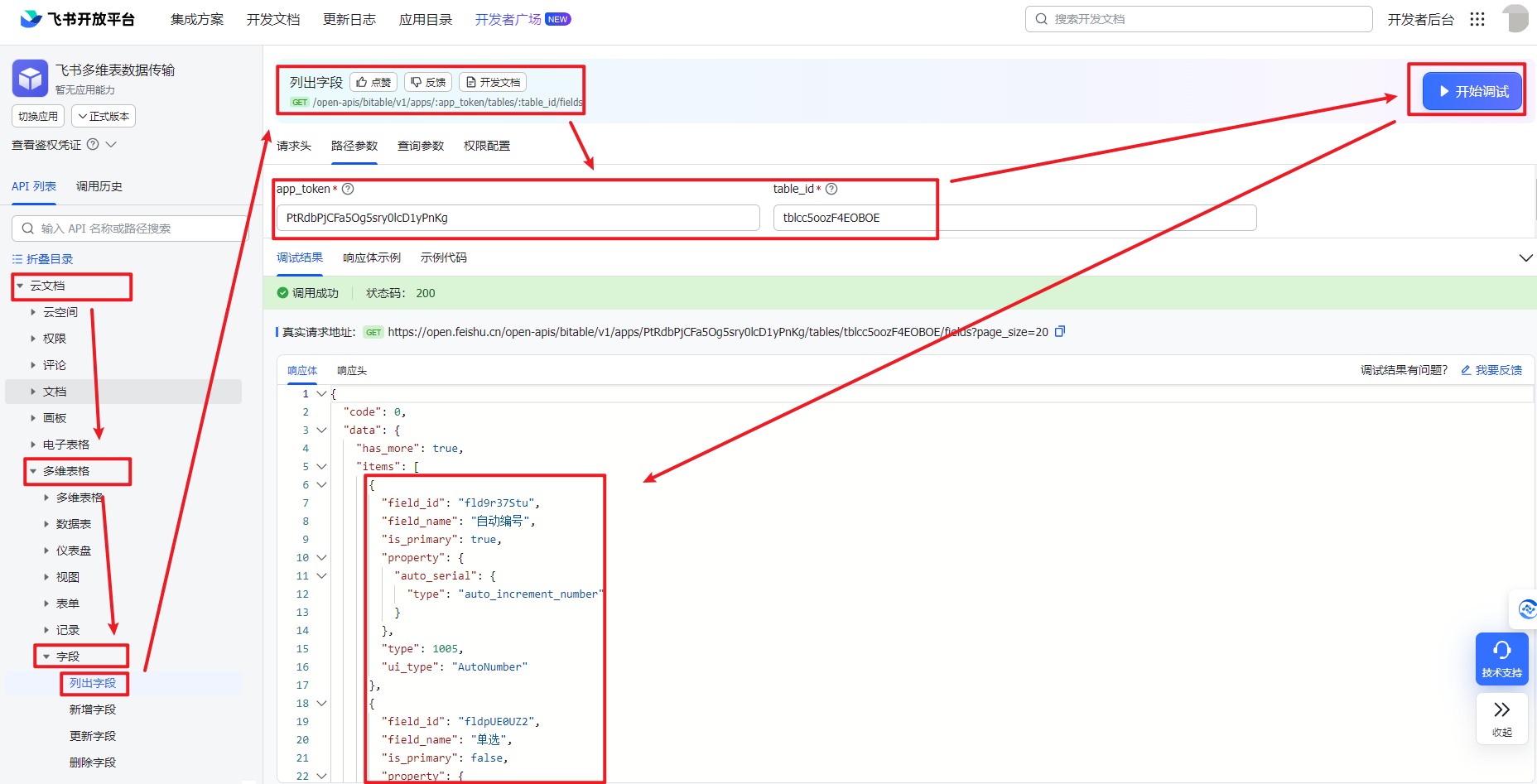
每一个列名,都包含“field_id”、“field_name”、“is_primary”、“property”、“type”和“ui_type”这 6 个参数。我们重点取“field_name”和“type”。“field_name”主要用于匹配通过查询数据接口获取的列名,“ui_type”就是前面介绍的飞书数据类型编号,这个编号用于映射 MySQL 的字段的数据类型。
{
"field_id": "fld9r37Stu",
"field_name": "自动编号",
"is_primary": true,
"property": {
"auto_serial": {
"type": "auto_increment_number"
}
},
"type": 1005,
"ui_type": "AutoNumber"
}
点击示例代码>Python Requests,获取相关 Python 代码。
将代码稍微整理一下,核心字符串,如 access_token、app_token 和 table_id 通过参数进行传递,并将接口返回的字段信息数据提取出来,示例如下:
import requests, json
def get_bitable_fields(tenant_access_token, app_token, table_id, page_size=500):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/fields?page_size={page_size}"
payload = ''
headers = {'Authorization': f'Bearer {tenant_access_token}'}
response = requests.request("GET", url, headers=headers, data=payload)
field_infos = response.json().get('data').get('items')
print('成功获取飞书字段信息,关联函数:get_bitable_fields。')
return field_infos
tenant_access_token = 'your_access_token'
app_token = 'your_app_token'
table_id = 'your_table_id'
feishu_fields = get_bitable_fields(tenant_access_token, app_token, table_id)
这里的“tenant_access_token”也可以使用前面介绍的自动获取“access_token”的方法来获取该值,再通过参数传递给tenant_access_token()方法。打印结构参考如下: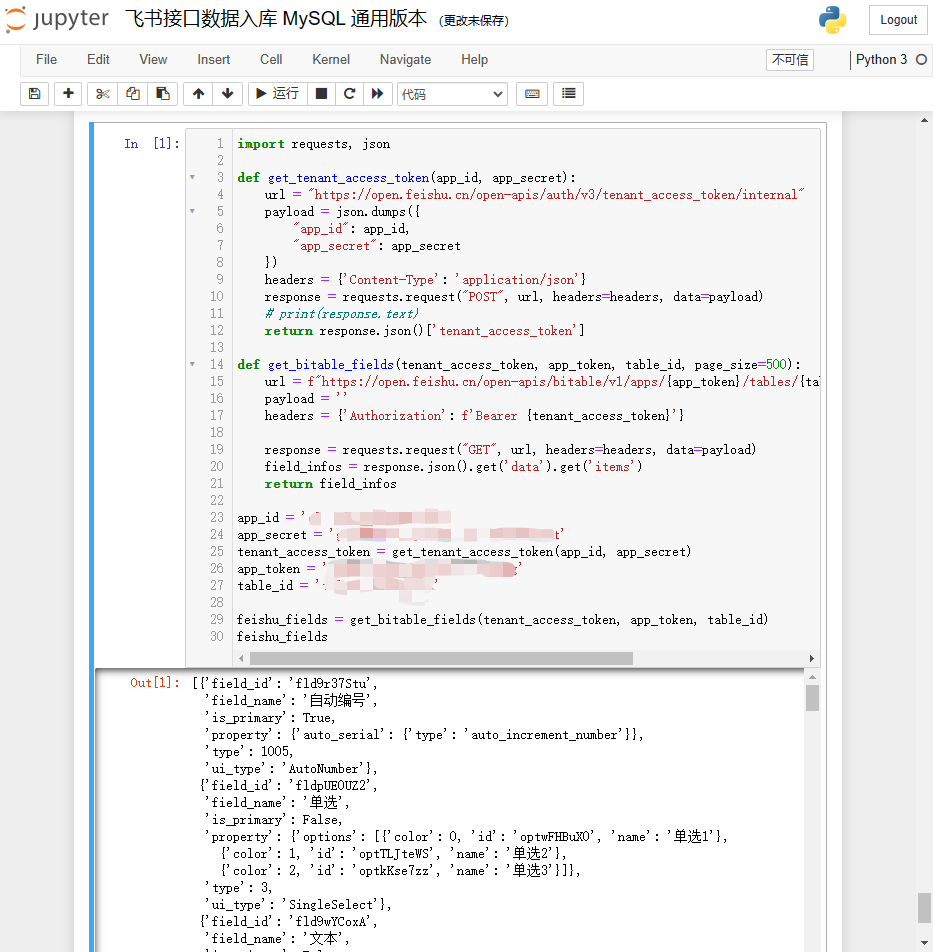
三、迭代代码逻辑
3.1 映射关系说明
映射关系主要有两个:飞书多维表的列名与入库表对应的英文字段名的映射关系、飞书数据类型与入库表对应的字段的数据类型。
给定一个列名映射关系参考如下。由于每个表的数据都不一样,所以每次有新的多维表表单需要入库时都需要指定二者的关系。
另外,由于入库字段是依赖该映射关系,也仅仅会将这里所列举的字段入库,所以当你只需要把部分列入库时,也可以仅仅指定需要入库的这部分列,而不用列举所有列。
fields_map = [{'tb_field_name': 'field_text','feishu_field_name': '文本'}
,{'tb_field_name': 'field_email','feishu_field_name': 'email'}
,{'tb_field_name': 'field_select','feishu_field_name': '单选'}
,{'tb_field_name': 'field_mobile','feishu_field_name': '电话号码'}
,{'tb_field_name': 'field_no','feishu_field_name': '自动编号'}
,{'tb_field_name': 'field_member1','feishu_field_name': '人员1'}
,{'tb_field_name': 'field_group1','feishu_field_name': '群组1'}
,{'tb_field_name': 'field_creator','feishu_field_name': '创建人'}
,{'tb_field_name': 'field_modifier','feishu_field_name': '修改人'}
,{'tb_field_name': 'field_member2','feishu_field_name': '人员2'}
,{'tb_field_name': 'field_group2','feishu_field_name': '群组2'}
,{'tb_field_name': 'field_url','feishu_field_name': '超链接'}
,{'tb_field_name': 'field_location','feishu_field_name': '地理位置'}
,{'tb_field_name': 'field_findnum','feishu_field_name': '查找引用数值'}
,{'tb_field_name': 'field_numformula','feishu_field_name': '数字公式'}
,{'tb_field_name': 'field_number','feishu_field_name': '数字'}
,{'tb_field_name': 'field_progress','feishu_field_name': '进度'}
,{'tb_field_name': 'field_money','feishu_field_name': '货币'}
,{'tb_field_name': 'field_Rating','feishu_field_name': '评分'}
,{'tb_field_name': 'field_bool','feishu_field_name': '复选框'}
,{'tb_field_name': 'field_date','feishu_field_name': '日期'}
,{'tb_field_name': 'field_createdtime','feishu_field_name': '创建时间'}
,{'tb_field_name': 'field_updatedtime','feishu_field_name': '更新时间'}
,{'tb_field_name': 'field_mulselect','feishu_field_name': '多选'}
,{'tb_field_name': 'field_singleunion','feishu_field_name': '单向关联'}
,{'tb_field_name': 'field_doubleunion','feishu_field_name': '双向关联'}
,{'tb_field_name': 'field_file','feishu_field_name': '附件'}
]
给定一个数据类型映射关系,该映射表会固定下来,作为默认映射关系处理所有需要入库的飞书数据。
data_type_map = [{"feishu_type": 1 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 2 ,"mysql_type": "FLOAT" }
,{"feishu_type": 3 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 4 ,"mysql_type": "json" }
,{"feishu_type": 5 ,"mysql_type": "datetime" }
,{"feishu_type": 7 ,"mysql_type": "BOOL" }
,{"feishu_type": 11 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 13 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 15 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 17 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 18 ,"mysql_type": "json" }
,{"feishu_type": 19 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 20 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 21 ,"mysql_type": "json" }
,{"feishu_type": 22 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 23 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 1001,"mysql_type": "datetime" }
,{"feishu_type": 1002,"mysql_type": "datetime" }
,{"feishu_type": 1003,"mysql_type": "varchar(256)" }
,{"feishu_type": 1004,"mysql_type": "varchar(256)" }
,{"feishu_type": 1005,"mysql_type": "varchar(256)" }]
3.2 迭代入库代码逻辑
迭代内容主要包含两块:处理各个飞书数据类型编号的列返回的数据和构建建表 SQL。
3.2.1 迭代一:处理飞书各个数据类型的数据
处理数据涉及飞书各个列的数据类型,需要先把飞书列出字段 API 返回的列数据和列名映射关系关联,给每一列数据都加上飞书的数据类型编号,以便根据对应的处理方案进行数据的处理。
取上面 API 的代码和“fields_map”变量,将 API 处理后的“feishu_fields”列表和“fields_map”列表都转为 pandas 的 DataFrame,然后以“fields_map”对应的 DataFrame 为主表左连接“feishu_fields”对应的 DataFrame,类似 MySQL 的“left join”。这里把两个列表转为 DataFrame 的功能封装为函数“merge_list”。最终参考代码如下:
import requests, json
import pandas as pd
def get_tenant_access_token(app_id, app_secret):
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
payload = json.dumps({
"app_id": app_id,
"app_secret": app_secret
})
headers = {'Content-Type': 'application/json'}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return response.json()['tenant_access_token']
def get_bitable_fields(tenant_access_token, app_token, table_id, page_size=500):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/fields?page_size={page_size}"
payload = ''
headers = {'Authorization': f'Bearer {tenant_access_token}'}
response = requests.request("GET", url, headers=headers, data=payload)
field_infos = response.json().get('data').get('items')
return field_infos
app_id = 'your_app_id'
app_secret = 'your_app_secret'
tenant_access_token = get_tenant_access_token(app_id, app_secret)
app_token = 'your_app_token'
table_id = 'your_table_id'
feishu_fields = get_bitable_fields(tenant_access_token, app_token, table_id)
fields_map = [{'tb_field_name': 'field_text','feishu_field_name': '文本'}
,{'tb_field_name': 'field_email','feishu_field_name': 'email'}
,{'tb_field_name': 'field_select','feishu_field_name': '单选'}
,{'tb_field_name': 'field_mobile','feishu_field_name': '电话号码'}
,{'tb_field_name': 'field_no','feishu_field_name': '自动编号'}
,{'tb_field_name': 'field_member1','feishu_field_name': '人员1'}
,{'tb_field_name': 'field_group1','feishu_field_name': '群组1'}
,{'tb_field_name': 'field_creator','feishu_field_name': '创建人'}
,{'tb_field_name': 'field_modifier','feishu_field_name': '修改人'}
,{'tb_field_name': 'field_member2','feishu_field_name': '人员2'}
,{'tb_field_name': 'field_group2','feishu_field_name': '群组2'}
,{'tb_field_name': 'field_url','feishu_field_name': '超链接'}
,{'tb_field_name': 'field_location','feishu_field_name': '地理位置'}
,{'tb_field_name': 'field_findnum','feishu_field_name': '查找引用数值'}
,{'tb_field_name': 'field_numformula','feishu_field_name': '数字公式'}
,{'tb_field_name': 'field_number','feishu_field_name': '数字'}
,{'tb_field_name': 'field_progress','feishu_field_name': '进度'}
,{'tb_field_name': 'field_money','feishu_field_name': '货币'}
,{'tb_field_name': 'field_Rating','feishu_field_name': '评分'}
,{'tb_field_name': 'field_bool','feishu_field_name': '复选框'}
,{'tb_field_name': 'field_date','feishu_field_name': '日期'}
,{'tb_field_name': 'field_createdtime','feishu_field_name': '创建时间'}
,{'tb_field_name': 'field_updatedtime','feishu_field_name': '更新时间'}
,{'tb_field_name': 'field_mulselect','feishu_field_name': '多选'}
,{'tb_field_name': 'field_singleunion','feishu_field_name': '单向关联'}
,{'tb_field_name': 'field_doubleunion','feishu_field_name': '双向关联'}
,{'tb_field_name': 'field_file','feishu_field_name': '附件'}
]
# 将两个[{},{}]结构的数据合并
def merge_list(ls_from, ls_join, on=None, left_on=None, right_on=None):
df_from = pd.DataFrame(ls_from)
df_join = pd.DataFrame(ls_join)
if on is not None:
df_merge = df_from.merge(df_join, how='left', on=on)
else:
df_merge = df_from.merge(df_join, how='left', left_on=left_on, right_on=right_on) # , suffixes=('', '_y')
return df_merge
# 以 fields_map 为准
store_fields_info_df = merge_list(fields_map, feishu_fields, left_on='feishu_field_name', right_on='field_name')
store_fields_info_df
执行结果如下,关键的三个字段名已标红,分别为:“tb_field_name”、“feishu_field_name”和“type”。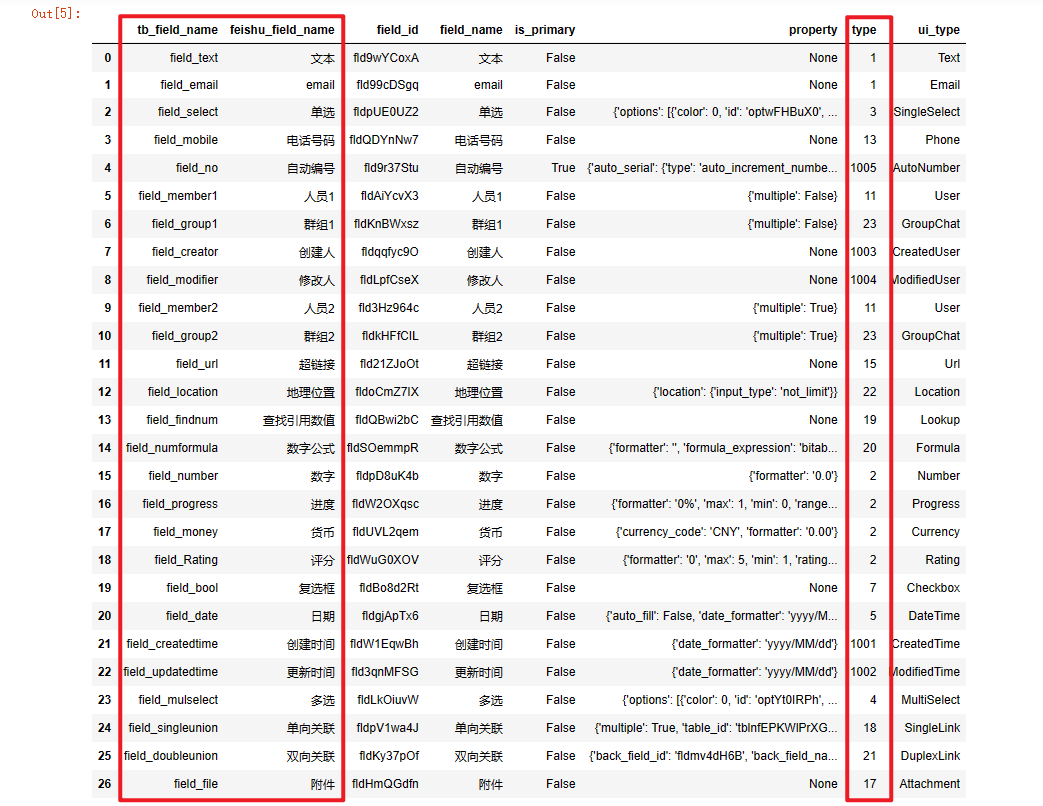
获取到每个字段名和类型之后,接下来开始迭代上一篇讲到的extract_key_fields()函数,将写固定列名的硬代码改为通过飞书数据类型识别的代码,以兼容各个数据类型。
代码如下,使用iterrows()遍历字段信息,然后对字段的数据类型编号进行判断,判断规则如下:
- 如果是编号 1(文本),取字段值中的“text”文本;
- 如果是编号 2(数字)、3(单选)、7(复选框)、13(手机号)、1005(自动编号),则直接取字段值返回;
- 如果是编号 5(日期)、1001(创建日期)、1002(更新日期),取字段值加 8 小时,再转为 datetime 类型;
- 如果是编号 11(人员)、23(群组)、1003(创建人)、1004(修改人),遍历元素,取字段值中的“name”文本,然后用逗号连接起来;
- 如果是编号 15(链接),取字段值中的“link”文本;
- 如果是编号 17(附件),遍历元素,取字段值中的“url”文本;
- 如果是编号 18(单向关联)、21(双向关联),取字段值中的“link_record_ids”文本;
- 如果是编号 4(多选)、19(引用)、20(公式),取字段值转为字符串;
- 如果是编号 22(地理位置),取字段值中的“location”文本;
- 如果是按钮和流程,由于没有返回值,不做处理,忽略即可。
- 注意:入库如果是 json 类型必须使用
json.dumps()进行格式化,否则写入数据库是会报错。
import datetime
def extract_key_fields(feishu_datas, store_fields_info_df):
"""处理飞书数据类型编号的数据"""
print('开始处理飞书多维表关键字段数据...')
# 需要record_id 和 订单号,用于和数据库数据匹配
df_feishu = pd.DataFrame(feishu_datas)
df_return = pd.DataFrame()
#根据列的数据类型,分别处理对应的数据。注意:仅返回以下列举的数据类型,如果fields_map的内容包含按钮、流程等数据类型的飞书列,忽略。
for index, row in store_fields_info_df.iterrows():
if row['type'] == 1: #文本
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name'],[{}])[0].get('text'))
elif row['type'] in (2, 3, 7, 13, 1005): #数字、单选、复选框、手机号、自动编号
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name']))
elif row['type'] in (5, 1001, 1002): #日期(包含创建和更新),需要加 8 小时,即 8*60*60*1000=28800 秒
df_return[row['tb_field_name']] = pd.to_datetime(df_feishu['fields'].apply(lambda x:28800 + int(x.get(row['field_name'],1000)/1000)), unit='s')
elif row['type'] in(11, 23, 1003, 1004): #人员、群组、创建人、修改人,遍历取name
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x: ','.join([i.get('name') for i in x.get(row['field_name'],[{"name":""}])])) # 需要遍历
elif row['type'] == 15: #链接
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name'],{}).get('link'))
elif row['type'] == 17: #附件,遍历取url
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:json.dumps([i.get('url') for i in x.get(row['field_name'],[{}])])) #需要遍历
elif row['type'] in(18, 21): #单向关联、双向关联,取link_record_ids
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:json.dumps(x.get(row['field_name'],{}).get('link_record_ids')))
elif row['type'] in(4, 19, 20): #多选、查找引用和公式
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:json.dumps(x.get(row['field_name'])))
elif row['type'] == 22: #地理位置
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name'],{}).get('location'))
#加上record_id
df_return['record_id'] = df_feishu.record_id
#加上表更新字段
df_return['last_modified_time'] = datetime.datetime.now()
return df_return
# 已知:feishu_datas 和 store_fields_info_df
# feishu_datas 通过 API 获取到的所有飞书的数据, store_fields_info_df 上一小节得到的变量
feishu_df = extract_key_fields(feishu_datas, store_fields_info_df)
feishu_df
最终结果如下,由于列数太多,此处分成三段展示: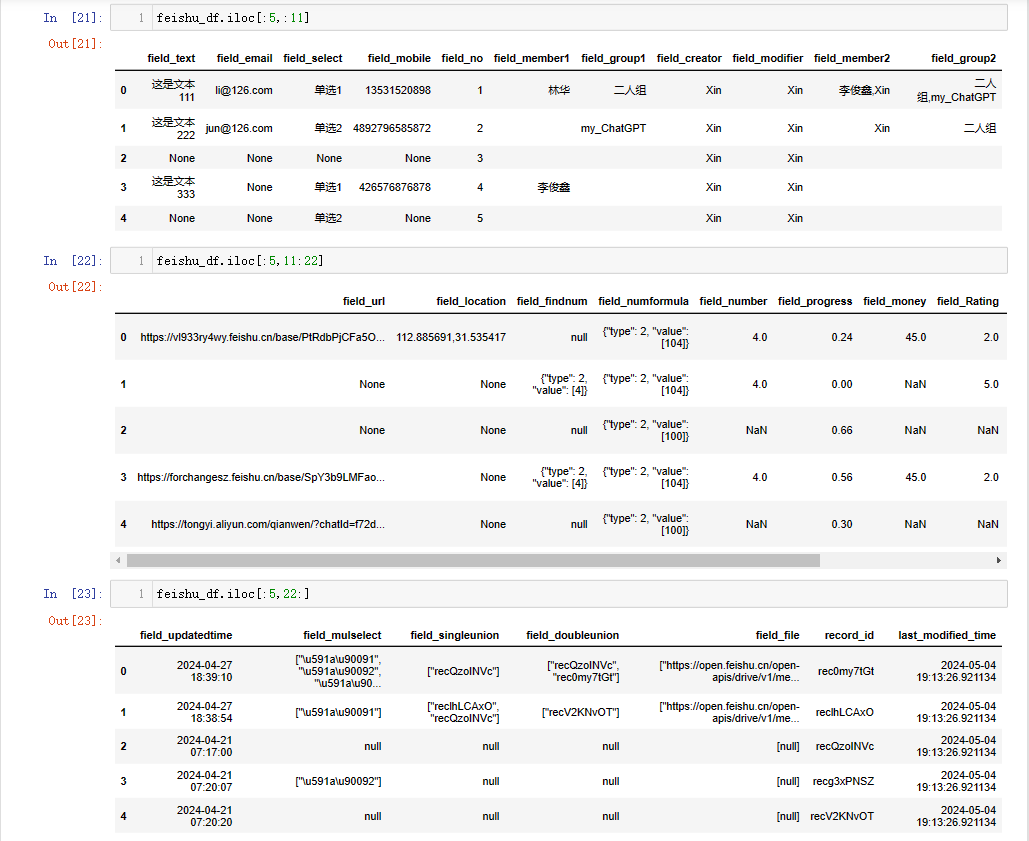
由于数据类型相对比较稳定,所以该逻辑作为固定的处理逻辑写入代码。如果临时需要调整,可以通过定制化处理,下一篇介绍。
3.2.2 迭代二:构建建表 SQL
构建建表 SQL 涉及数据类型映射关系,需要先把该关系和列名映射关系关联,给每一个入库的字段名加上 MySQL 的数据类型。
借用3.2.1 中的merge_list()函数,以“store_fields_info_df”为主表,左连接匹配“data_type_map”中的“mysql_type”。
data_type_map = [{"feishu_type": 1 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 2 ,"mysql_type": "FLOAT" }
,{"feishu_type": 3 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 4 ,"mysql_type": "json" }
,{"feishu_type": 5 ,"mysql_type": "datetime" }
,{"feishu_type": 7 ,"mysql_type": "BOOL" }
,{"feishu_type": 11 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 13 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 15 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 17 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 18 ,"mysql_type": "json" }
,{"feishu_type": 19 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 20 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 21 ,"mysql_type": "json" }
,{"feishu_type": 22 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 23 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 1001,"mysql_type": "datetime" }
,{"feishu_type": 1002,"mysql_type": "datetime" }
,{"feishu_type": 1003,"mysql_type": "varchar(256)" }
,{"feishu_type": 1004,"mysql_type": "varchar(256)" }
,{"feishu_type": 1005,"mysql_type": "varchar(256)" }]
store_fields_info_df = merge_list(store_fields_info_df, data_type_map, left_on='type', right_on='feishu_type')
store_fields_info_df
结果如下: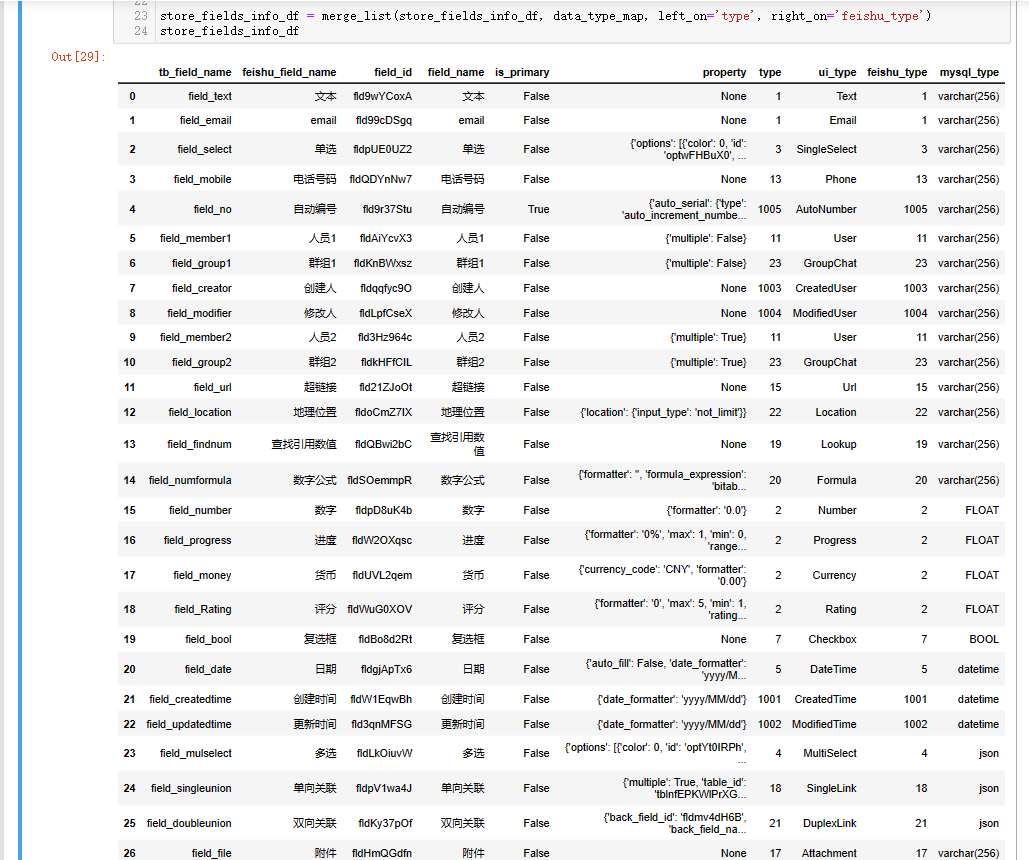
接下来,根据“store_fields_info_df”和表名生成建表语句,参考如下:
def generate_create_ddl(db_table_name, store_fields_info_df):
"""生成DDL还需要另外去建表,直接一条龙服务,使用Pyodps建表,并写入数据。下面代码二"""
# 代码一:生成DDL语句
cre_ddl = f"CREATE TABLE for_ods.{db_table_name} (\n"
for index, row in store_fields_info_df.iterrows():
cre_ddl += f" {row['tb_field_name']} {row['mysql_type']} comment '{row['feishu_field_name']}',\n"
default_fields = " record_id varchar(20) comment '行record_id',\n last_modified_time datetime comment '数据更新时间' \n);"
# cre_ddl = cre_ddl[:-2] + "\n);"
cre_ddl = cre_ddl + default_fields
# print(cre_ddl)
return cre_ddl
#已知:store_fields_info_df
db_table_name = 'feishu_data_type_test'
cre_ddl = generate_create_ddl(db_table_name, store_fields_info_df)
cre_ddl
执行结果如下:
看看打印的效果: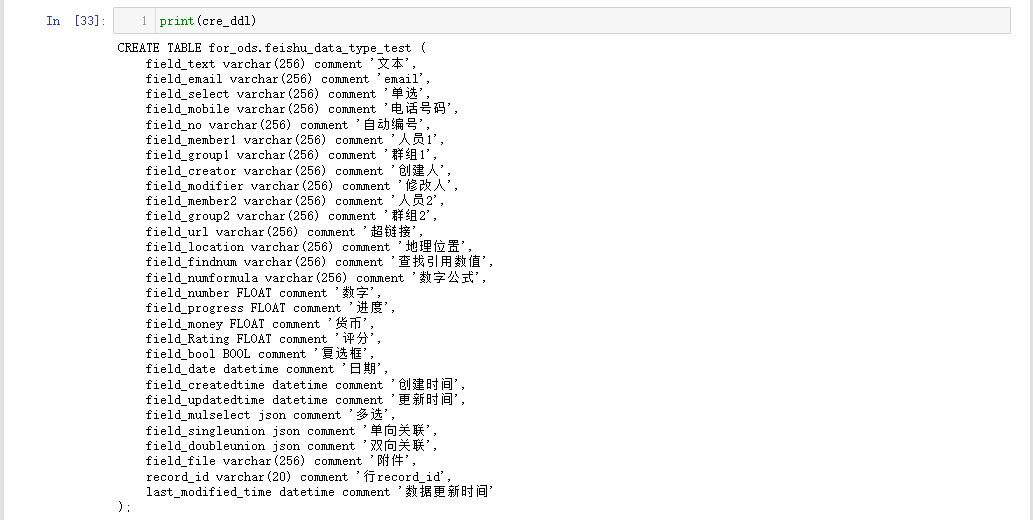
3.2.3 迭代三:传递链接自动提取 app_token、table_id、view_id
迭代完上面两个之后,便可以替换上一篇代码中的extract_key_fields()方法,使得代码拓展性更好!
不过,每次要入库一个多维表都需要手动填写表单的 app_token 和 table_id,为了使得操作更加便捷,通过传递链接,然后从链接中解析对应的字段来完成这两个字段的自动填充。
另外,实际生产中,一个多维表中可能会有多个视图,每个视图可能都会做不同的筛选,以便查看不同维度或颗粒度的数据,所以,通常,我们需要指定视图 ID,避免因为数据被筛选之后取不到完整数据导致数据一致性出问题。同样,也通过链接解析出视图 ID,然后传递给接口。
解析参考代码如下:
from urllib.parse import urlparse, parse_qs
def get_table_params(bitable_url):
# bitable_url = "https://feishu.cn/base/aaaaaaaa?table=tblccc&view=vewddd"
parsed_url = urlparse(bitable_url) #解析url:(ParseResult(scheme='https', netloc='feishu.cn', path='/base/aaaaaaaa', params='', query='table=tblccc&view=vewddd', fragment='')
query_params = parse_qs(parsed_url.query) #解析url参数:{'table': ['tblccc'], 'view': ['vewddd']}
app_token = parsed_url.path.split('/')[-1]
table_id = query_params.get('table', [None])[0]
view_id = query_params.get('view', [None])[0]
return app_token, table_id, view_id
bitable_url = "https://xxxx.feishu.cn/base/PtRdbPjCFa5Og5sry0lcD1yPnKg?table=tblcc5oozF4EOBOE&view=vewVaEFMO6"
app_token, table_id, view_id = get_table_params(bitable_url)
app_token, table_id, view_id
执行结果如下: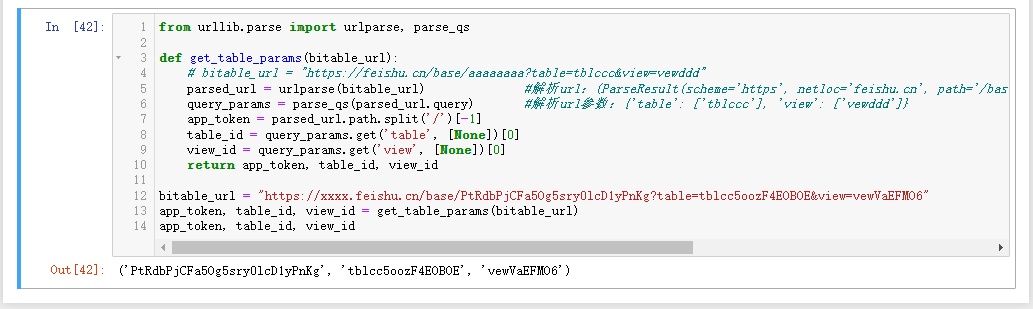
由于上一篇的代码中没有涉及“view_id”,所以需要迭代相关的函数,目前相关的函数有两个:get_bitable_datas()。修改的地方,主要有两个,一个是函数的参数传递,一个是接口的参数传递。前者直接加个参数,保证调用的时候位置对齐即可。后者则是修改下“payload”,修改后的内容参考如下:
def get_bitable_datas(tenant_access_token, app_token, table_id, view_id, page_token='', page_size=20):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search?page_size={page_size}&page_token={page_token}&user_id_type=user_id"
payload = json.dumps({"view_id": view_id})
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return response.json()
3.3 整合通用版代码
将以上的代码组合到一起,并局部调整顺序,完整代码参考如下,几点说明:
- 循环获取飞书多维表每一页的数据的代码逻辑单独提取出来封装到新函数
get_all_bitable_datas()中; - 函数
merge_list()不仅仅只是支持两个列表通过 DataFrame 合并在一起,也可以是一个 DataFrame 和一个列表 -
import requests
import json
import datetime
import pandas as pd
from sqlalchemy import create_engine, text
from urllib.parse import urlparse, parse_qs
def get_table_params(bitable_url):
# bitable_url = "https://feishu.cn/base/aaaaaaaa?table=tblccc&view=vewddd"
parsed_url = urlparse(bitable_url) #解析url:(ParseResult(scheme='https', netloc='feishu.cn', path='/base/aaaaaaaa', params='', query='table=tblccc&view=vewddd', fragment='')
query_params = parse_qs(parsed_url.query) #解析url参数:{'table': ['tblccc'], 'view': ['vewddd']}
app_token = parsed_url.path.split('/')[-1]
table_id = query_params.get('table', [None])[0]
view_id = query_params.get('view', [None])[0]
print(f'成功解析链接,app_token:{app_token},table_id:{table_id},view_id:{view_id}。关联方法:get_table_params。')
return app_token, table_id, view_id
def get_tenant_access_token(app_id, app_secret):
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
payload = json.dumps({
"app_id": app_id,
"app_secret": app_secret
})
headers = {'Content-Type': 'application/json'}
response = requests.request("POST", url, headers=headers, data=payload)
tenant_access_token = response.json()['tenant_access_token']
print(f'成功获取tenant_access_token:{tenant_access_token}。关联函数:get_table_params。')
return tenant_access_token
def get_bitable_datas(tenant_access_token, app_token, table_id, view_id, page_token='', page_size=20):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search?page_size={page_size}&page_token={page_token}&user_id_type=user_id"
payload = json.dumps({"view_id": view_id})
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(f'成功获取page_token为【{page_token}】的数据。关联函数:get_bitable_datas。')
return response.json()
def get_all_bitable_datas(tenant_access_token, app_token, table_id, view_id, page_token='', page_size=20):
has_more = True
feishu_datas = []
while has_more:
response = get_bitable_datas(tenant_access_token, app_token, table_id, view_id, page_token, page_size)
if response['code'] == 0:
page_token = response['data'].get('page_token')
has_more = response['data'].get('has_more')
# print(response['data'].get('items'))
# print('\n--------------------------------------------------------------------\n')
feishu_datas.extend(response['data'].get('items'))
else:
raise Exception(response['msg'])
print(f'成功获取飞书多维表所有数据,返回 feishu_datas。关联函数:get_all_bitable_datas。')
return feishu_datas
def get_bitable_fields(tenant_access_token, app_token, table_id, page_size=500):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/fields?page_size={page_size}"
payload = ''
headers = {'Authorization': f'Bearer {tenant_access_token}'}
response = requests.request("GET", url, headers=headers, data=payload)
field_infos = response.json().get('data').get('items')
print('成功获取飞书字段信息,关联函数:get_bitable_fields。')
return field_infos
def merge_list(ls_from, ls_join, on=None, left_on=None, right_on=None):
"""将两个[{},{}]结构的数据合并"""
df_from = pd.DataFrame(ls_from)
df_join = pd.DataFrame(ls_join)
if on is not None:
df_merge = df_from.merge(df_join, how='left', on=on)
else:
df_merge = df_from.merge(df_join, how='left', left_on=left_on, right_on=right_on) # , suffixes=('', '_y')
print(f'成功合并列表或DataFrame。关联方法:merge_list。')
return df_merge
def extract_key_fields(feishu_datas, store_fields_info_df):
"""处理飞书数据类型编号的数据"""
print('开始处理飞书多维表关键字段数据...')
# 需要record_id 和 订单号,用于和数据库数据匹配
df_feishu = pd.DataFrame(feishu_datas)
df_return = pd.DataFrame()
#根据列的数据类型,分别处理对应的数据。注意:仅返回以下列举的数据类型,如果fields_map的内容包含按钮、流程等数据类型的飞书列,忽略。
for index, row in store_fields_info_df.iterrows():
if row['type'] == 1: #文本
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name'],[{}])[0].get('text'))
elif row['type'] in (2, 3, 7, 13, 1005): #数字、单选、复选框、手机号、自动编号
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name']))
elif row['type'] in (5, 1001, 1002): #日期(包含创建和更新),需要加 8 小时,即 8*60*60*1000=28800 秒
df_return[row['tb_field_name']] = pd.to_datetime(df_feishu['fields'].apply(lambda x:28800 + int(x.get(row['field_name'],1000)/1000)), unit='s')
elif row['type'] in(11, 23, 1003, 1004): #人员、群组、创建人、修改人,遍历取name
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x: ','.join([i.get('name') for i in x.get(row['field_name'],[{"name":""}])])) # 需要遍历
elif row['type'] == 15: #链接
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name'],{}).get('link'))
elif row['type'] == 17: #附件,遍历取url
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:json.dumps([i.get('url') for i in x.get(row['field_name'],[{}])])) #需要遍历
elif row['type'] in(18, 21): #单向关联、双向关联,取link_record_ids
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:json.dumps(x.get(row['field_name'],{}).get('link_record_ids')))
elif row['type'] in(4, 19, 20): #多选、查找引用和公式
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:json.dumps(x.get(row['field_name'])))
elif row['type'] == 22: #地理位置
df_return[row['tb_field_name']] = df_feishu['fields'].apply(lambda x:x.get(row['field_name'],{}).get('location'))
#加上record_id
df_return['record_id'] = df_feishu.record_id
#加上表更新字段
df_return['last_modified_time'] = datetime.datetime.now()
print(f'成功提取入库字段的数据。关联方法:extract_key_fields。')
return df_return
def generate_create_ddl(db_table_name, store_fields_info_df):
"""生成DDL还需要另外去建表,直接一条龙服务,使用Pyodps建表,并写入数据。下面代码二"""
# 代码一:生成DDL语句
cre_ddl = f"CREATE TABLE if not exists {db_table_name} (\n"
for index, row in store_fields_info_df.iterrows():
cre_ddl += f" {row['tb_field_name']} {row['mysql_type']} comment '{row['feishu_field_name']}',\n"
default_fields = "record_id varchar(20) comment '行record_id',\nlast_modified_time datetime comment '数据更新时间' \n);"
# cre_ddl = cre_ddl[:-2] + "\n);"
cre_ddl = cre_ddl + default_fields
print(f'成功生成 mysql 建表 DDL。关联方法:generate_create_ddl。')
return cre_ddl
def cre_mysql_table(create_table_sql, connection_conf_info):
"""注意:该函数支持执行任意SQL,而不仅仅是建表 SQL。"""
# from sqlalchemy import create_engine, text
# 创建 SQLAlchemy engine 对象,这里以 MySQL 为例
# engine = create_engine('mysql://username:password@host:port/dbname')
# engine = create_engine('mysql://root:password@127.0.0.1:3306/test')
engine = create_engine(connection_conf_info)
# 定义一个建表的 SQL 语句
# create_table_sql = ''''''
# 使用 execute() 方法执行 SQL 语句
with engine.connect() as connection:
connection.execute(text(create_table_sql))
print(f'成功执行 mysql 建表语句。关联方法:cre_mysql_table。')
def insert_mysql_table(feishu_df, table_name, connection_conf_info):
# from sqlalchemy import create_engine
# 创建 SQLAlchemy engine 对象,这里以 MySQL 为例
# engine = create_engine('mysql://username:password@host:port/dbname')
# engine = create_engine('mysql://root:password@127.0.0.1:3306/test')
engine = create_engine(connection_conf_info)
# 将 DataFrame 直接写入 MySQL 数据库
feishu_df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
print(f'成功将飞书数据写入 mysql 数据表。关联方法:insert_mysql_table。')
def main(connection_conf_info, mysql_table_name, bitable_url, fields_map):
# 基本配置
app_token, table_id, view_id = get_table_params(bitable_url)
app_id = 'your_app_id'
app_secret = 'your_app_secret'
tenant_access_token = get_tenant_access_token(app_id, app_secret)
page_size = 5
# 获取飞书多维表所有数据
feishu_datas = get_all_bitable_datas(tenant_access_token, app_token, table_id, view_id, page_size=page_size)
#获取飞书字段信息
feishu_fields = get_bitable_fields(tenant_access_token, app_token, table_id)
# 以 fields_map 为准关联数据
store_fields_info_df = merge_list(fields_map, feishu_fields, left_on='feishu_field_name', right_on='field_name')
# 处理入库字段数据
feishu_df = extract_key_fields(feishu_datas, store_fields_info_df)
# 关联入库数据类型
data_type_map = [{"feishu_type": 1 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 2 ,"mysql_type": "FLOAT" }
,{"feishu_type": 3 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 4 ,"mysql_type": "json" }
,{"feishu_type": 5 ,"mysql_type": "datetime" }
,{"feishu_type": 7 ,"mysql_type": "BOOL" }
,{"feishu_type": 11 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 13 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 15 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 17 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 18 ,"mysql_type": "json" }
,{"feishu_type": 19 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 20 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 21 ,"mysql_type": "json" }
,{"feishu_type": 22 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 23 ,"mysql_type": "varchar(256)" }
,{"feishu_type": 1001,"mysql_type": "datetime" }
,{"feishu_type": 1002,"mysql_type": "datetime" }
,{"feishu_type": 1003,"mysql_type": "varchar(256)" }
,{"feishu_type": 1004,"mysql_type": "varchar(256)" }
,{"feishu_type": 1005,"mysql_type": "varchar(256)" }]
store_fields_info_df = merge_list(store_fields_info_df, data_type_map, left_on='type', right_on='feishu_type')
# 生成 MySQL 建表 DDL
create_table_sql = generate_create_ddl(mysql_table_name, store_fields_info_df)
# 建 mysql 数据表
cre_mysql_table(create_table_sql, connection_conf_info)
# MySQL 表插入数据
insert_mysql_table(feishu_df, mysql_table_name, connection_conf_info)
db_name = connection_conf_info.split('/')[-1]
print(f'成功将飞书多维表({bitable_url})的数据入库到 mysql 数据表:{db_name}.{mysql_table_name}。')
if __name__ == '__main__':
connection_conf_info = 'mysql://root:password@127.0.0.1:3306/test'
mysql_table_name = 'feishu_data_type_test'
bitable_url = "https://xxxx.feishu.cn/base/PtRdbPjCFa5Og5sry0lcD1yPnKg?table=tblcc5oozF4EOBOE&view=vewVaEFMO6"
fields_map = [{'tb_field_name': 'field_text','feishu_field_name': '文本'}
,{'tb_field_name': 'field_email','feishu_field_name': 'email'}
,{'tb_field_name': 'field_select','feishu_field_name': '单选'}
,{'tb_field_name': 'field_mobile','feishu_field_name': '电话号码'}
,{'tb_field_name': 'field_no','feishu_field_name': '自动编号'}
,{'tb_field_name': 'field_member1','feishu_field_name': '人员1'}
,{'tb_field_name': 'field_group1','feishu_field_name': '群组1'}
,{'tb_field_name': 'field_creator','feishu_field_name': '创建人'}
,{'tb_field_name': 'field_modifier','feishu_field_name': '修改人'}
,{'tb_field_name': 'field_member2','feishu_field_name': '人员2'}
,{'tb_field_name': 'field_group2','feishu_field_name': '群组2'}
,{'tb_field_name': 'field_url','feishu_field_name': '超链接'}
,{'tb_field_name': 'field_location','feishu_field_name': '地理位置'}
,{'tb_field_name': 'field_findnum','feishu_field_name': '查找引用数值'}
,{'tb_field_name': 'field_numformula','feishu_field_name': '数字公式'}
,{'tb_field_name': 'field_number','feishu_field_name': '数字'}
,{'tb_field_name': 'field_progress','feishu_field_name': '进度'}
,{'tb_field_name': 'field_money','feishu_field_name': '货币'}
,{'tb_field_name': 'field_Rating','feishu_field_name': '评分'}
,{'tb_field_name': 'field_bool','feishu_field_name': '复选框'}
,{'tb_field_name': 'field_date','feishu_field_name': '日期'}
,{'tb_field_name': 'field_createdtime','feishu_field_name': '创建时间'}
,{'tb_field_name': 'field_updatedtime','feishu_field_name': '更新时间'}
,{'tb_field_name': 'field_mulselect','feishu_field_name': '多选'}
,{'tb_field_name': 'field_singleunion','feishu_field_name': '单向关联'}
,{'tb_field_name': 'field_doubleunion','feishu_field_name': '双向关联'}
,{'tb_field_name': 'field_file','feishu_field_name': '附件'}
]
main(connection_conf_info, mysql_table_name, bitable_url, fields_map)
最终入库结果如下,符合预期。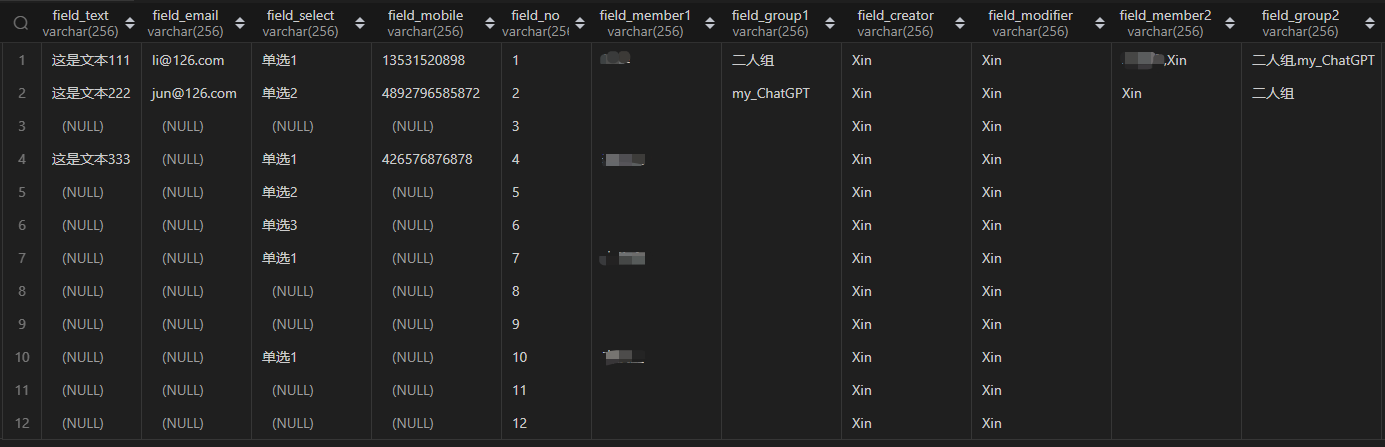
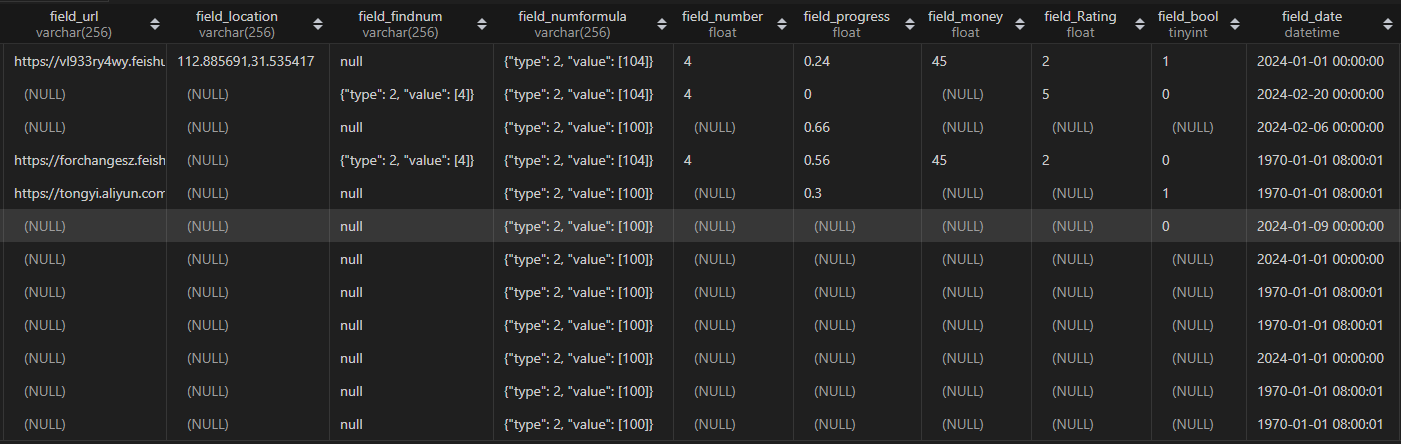
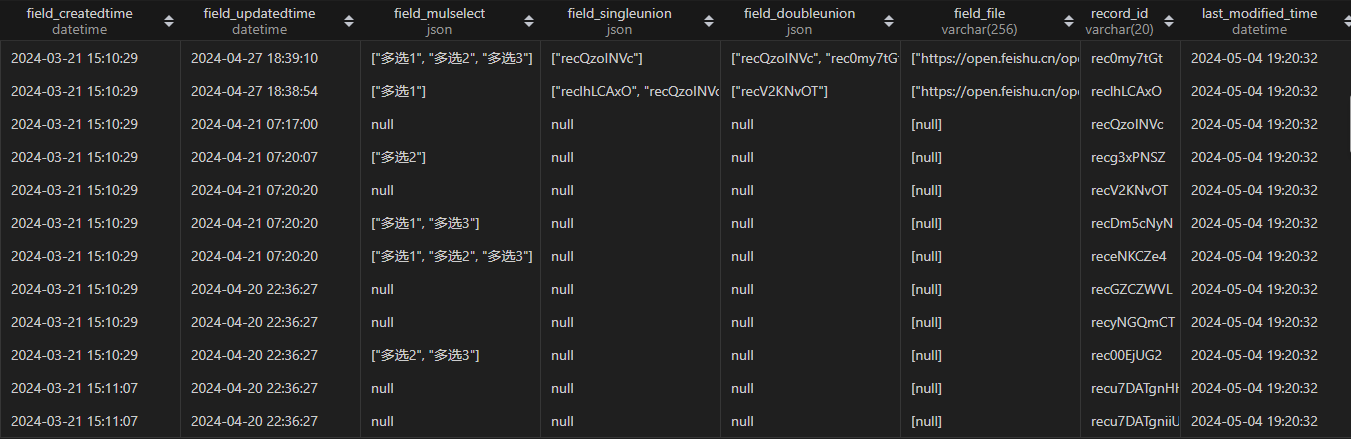
一点补充:目前该代码是追加的方式写入,会保留历史已经插入的数据,如果不要历史数据,保留最后一次插入的数据即可。可以通过者清空表数据再插入数据,或者在调用建表方法之前删表,再重建,再插入数据这两种方式。
- 清空表可以使用以下 SQL,通过调用
cre_mysql_table()函数执行 SQL;
truncate_table_sql = 'truncate table {mysql_table_name};'
cre_mysql_table(truncate_table_sql, connection_conf_info)
- 删除表可以使用以下 SQL,通过调用
cre_mysql_table()函数执行 SQL。
drop_table_sql = 'drop table if exists {mysql_table_name};'
cre_mysql_table(drop_table_sql, connection_conf_info)
- 当然,删表重建也可以直接将“if_exists”参数(是在
insert_mysql_table()函数中调用的to_sql()方法中的一个参数)改为“replace”,它会在插入数据前,先删表重建,但是它无法保证新建的 MySQL 数据表各个字段的数据类型。
四、小结
本文完成了飞书多维表数据写入 MySQL 数据库的通用版本代码的开发,经过对代码进行重构,把三组核心关系:飞书列名和数据类型、飞书列名和入库表单字段名、飞书数据类型和入库字段的数据类型解耦出来,使得代码通用性更强。
- 第一组关系借助飞书获取字段信息的接口解决;
- 第二组关系又用户使用时进行指定;
- 第三组关系比较固定,保持不变即可。
经过本文改造,目前只需要提供必备的应用信息(app_id和app_secret)、数据库连接配置、多维表链接和需要入库的列名及英文名即可完成对多维表数据进行入库。
ps:有个大前提!不要忘了给应用开通多维表的读取权限!
完整代码适用范围:
- 飞书多维表入库 MySQL 数据库,使用者需要拥有飞书应用权限、MySQL 数据库的 SELECT、INSERT、DELETE、CREATE、DROP 权限
- 写入规则是追加,如果只需保留最新版本数据,可以在插入数据前对数据进行清空,或者删表重建,参考最后的补充内容。