案例背景
承接之前的案例,说要做模态分解加神经网络的模型的,前面纯神经网络的缝合模型参考数据分析案例41和数据分析案例42。
虽然我自己基于各种循环神经网络做时间序列的预测已经做烂了.....但是还是会有很多刚读研究生或者是别的领域过来的小白来问这些神经网络怎么写,怎么搭建。
什么CNN-LSTM, CNN-GRU, LSTM-GRU, 注意力机制+LSTM, 注意力机制+GRU, 模态分解+LSTM, 优化算法+模态分解+LSTM.........优化算法+模态分解+注意力机制+GRU,优化算法+模态分解+注意力机制+双向GRU。。。
算了,虽然他们确实没啥意义,但是毕业需要,做学术嘛,都懂的。都是学术裁缝。
别的不多说,模态分解我知道会用的就有5种(EMD,EEMD,CEEMDAN,VMD,SVMD),优化算法不计其数(PSO,SSA,SMR,CS,SMA,GA,SWO....等等各种动物园优化算法),然后再加上可能用上的神经网络(LSTM,GRU,CNN,BiLSTM,BiGRU),再加上注意力机制。简单来说,我可以组合出5*10*5*2=500种模型!!! , 而且我还没用上Transformer以及其他更高级的深度学习模块,还有不同的损失函数,梯度下降的方法,还有区间估计核密度估计等等,毫不夸张的说,就这种缝合模型,我可以组合上千种。够发一辈子的论文了。
我今天就演示一下学术裁缝,模态分解+神经网络的模块的排列组合,究极缝合。
神经网络我基本主流模型都会写上的,本文会用如下的神经网络模型:
['LSTM', 'GRU', 'CNN', 'MLP', 'CNN+LSTM', 'BiLSTM', 'Attention','BiGRU+Attention', 'MultiHeadAttention']
模态分解就用目前效果还可以,论文里面的常用的VMD,变分模态分解吧。
数据选取
做这个循环神经网络的数据很好找,时间序列都可以,例如天气 , 空气质量AQI,血糖浓度,交通流量,锂电池寿命(参考我的数据分析案例24),风电预测(参考我的数据分析案例25),太阳黑子,人口数量,经济GDP,冶金温度,商品销量........
再加上我前面说的上千种缝合模型,去用于这些不同的领域,可以写的论文3辈子都发不完......
我这里就用elia的风电的数据吧,这数据我发了几篇sci了.....官网上很好找,使用的是2024年1月的数据,15分钟一个点。
本次案例的全部代码文件和数据集获取可以参考:(模态分解系列演示)
需要定制各种缝合模块的代码的也可以私聊我。
代码实现
神经网络使用的还是小白最容易上手的Keras框架,pytorch现在好像也支持Keras了。
模态分解就用的是vmdpy,其他的emd,eemd,ceemdan这几个系列的模态分解都是pyemd这个包,网上都有教程的。想换成这几个模态分解也很简单。
导入包:
import os
import math
import datetime
import random as rn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
import tensorflow as tf
import keras
from keras.models import Model, Sequential
from keras.layers import Dense,Input, Dropout, Embedding, Flatten,MaxPooling1D,Conv1D,SimpleRNN,LSTM,GRU,Multiply,GlobalMaxPooling1D
from keras.layers import Bidirectional,Activation,BatchNormalization,GlobalAveragePooling1D
from keras.layers.merge import concatenate
from keras.callbacks import EarlyStopping
#from tensorflow.keras import regularizers
#from keras.utils.np_utils import to_categorical
from tensorflow.keras import optimizers
from vmdpy import VMD
from scipy.fftpack import fft读取数据:
f= pd.DataFrame(pd.read_excel("WindForecast_20240101-20240228.xls").set_index('DateTime').iloc[:1440,-1].rename_axis('Time/(15 min)'))
data=np.array(f).reshape(-1,1)
print(data.shape)
只取了1440个点,没弄很多,因为深度学习计算量很大 太费时间了,我这5年前的小游戏本跑不动.....
画个图看看:
f.plot(figsize=(14,4))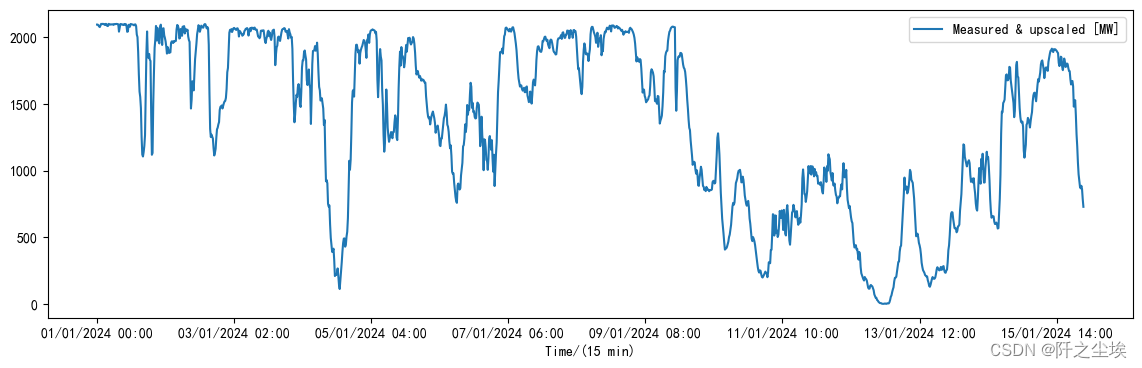
波动性很大,这种序列数据的特点都是这样。
VMD模态分解
vmd是比emd系列复杂一点的模态分解,它的参数特别多:
alpha = 7000 # moderate bandwidth constraint
tau = 0. # noise-tolerance (no strict fidelity enforcement)
K = 4 # 3 modes
DC = 0 # no DC part imposed
init = 1 # initialize omegas uniformly
tol = 1e-7
##### alpha、tau、K、DC、init、tol 六个输入参数的无严格要求;
#alpha 带宽限制 经验取值为 抽样点长度 1.5-2.0 倍;
#tau 噪声容限 ;
#K 分解模态(IMF)个数;
#DC 合成信号若无常量,取值为 0;若含常量,则其取值为 1;
#init 初始化 w 值,当初始化为 1 时,均匀分布产生的随机数;
#tol 控制误差大小常量,决定精度与迭代次数大家可以自己查一下参数的含义,我这里对分解的参数没什么要求,我随便选的一些。就是K是模态分解的数量,我这里K=4,因为我只想分解4条,太多了训练时间又要增加太麻烦了.....
分解:
然后画个图看看:
u, u_hat, omega = VMD(f.values, alpha, tau, K, DC, init, tol)
plt.figure()
plt.plot(u.T)
plt.title('VMD分解出的 Decomposed modes')
plt.show()
不太好看,因为分解出来的数据口径不是一样的,这样模态小的被挤成一条线了,下面分开画图看看:
for i in range(K):
plt.figure(figsize=(8,5), dpi=128)
plt.subplot(K,1,i+1)
plt.plot(u[i,:], linewidth=0.2, c='r')
plt.ylabel('IMF{}'.format(i+1)) 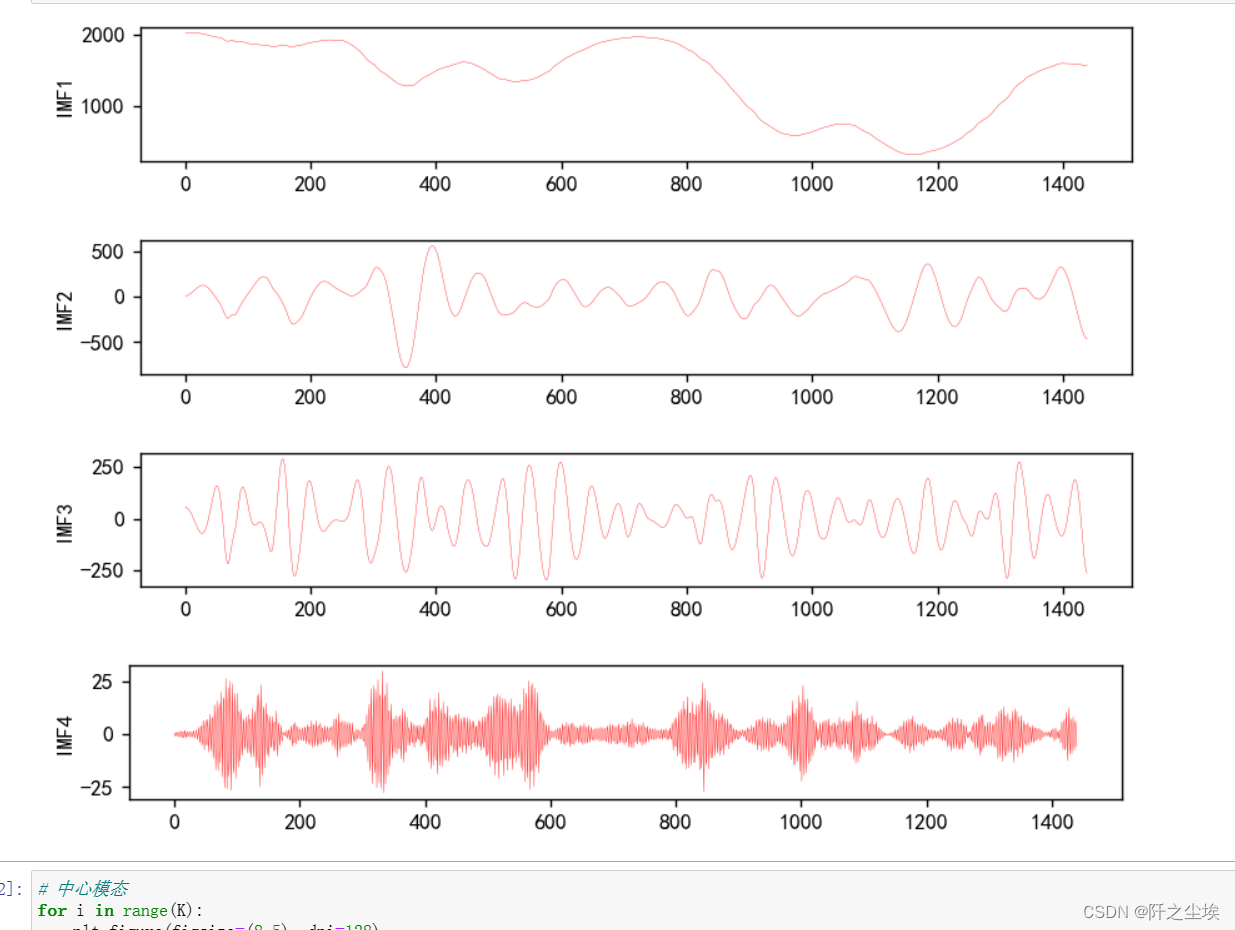
VMD还有什么中心模态,也画出来看看:
# 中心模态
for i in range(K):
plt.figure(figsize=(8,5), dpi=128)
plt.subplot(K,1,i+1)
plt.plot(abs(fft(u[i,:])))
plt.ylabel('IMF{}'.format(i+1)) 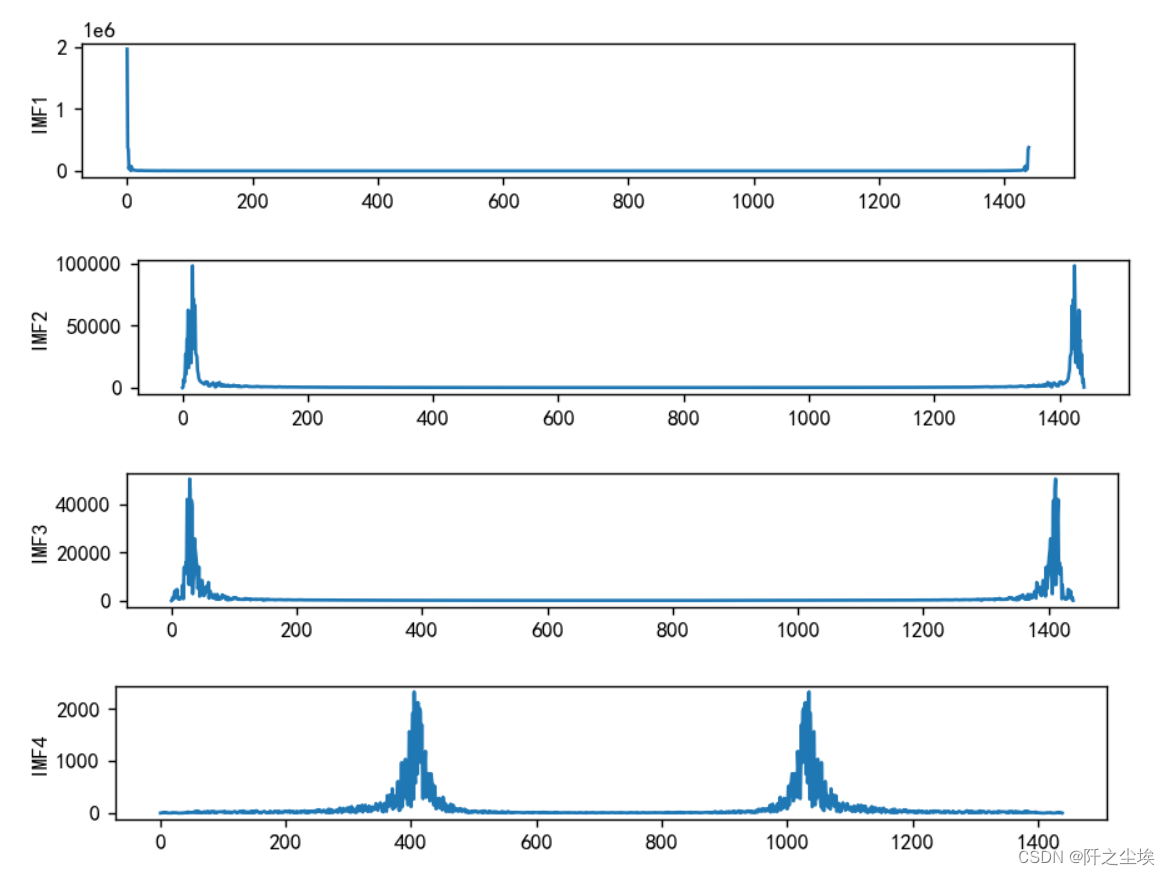
将这4个模态分入一个数据框:
df=pd.DataFrame()
for i in range(K):
a = u[i,:]
dataframe = pd.DataFrame({'v{}'.format(i+1):a})
df['imf'+str(i+1)]=dataframe查看:
df
原数据1440的长度,现在变成了4条1440的序列,模态分解的功能就是这样的。
df_names=df.columns
df_names
名称就是imf1到imf4,我们下面神经网络就是对这四条序列分开进行神经网络的预测和拟合,然后加起来就是最终的预测效果了。
神经网络
不过由于我们的神经网络模型种类很丰富(['LSTM', 'GRU', 'CNN', 'MLP', 'CNN+LSTM', 'BiLSTM', 'Attention', 'BiGRU+Attention', 'MultiHeadAttention']),所以进行神经网络之间,我们还需要自定义好很多层:
#from __future__ import print_function
from keras import backend as K
from keras.layers import Layer
class Embedding(Layer):
def __init__(self, vocab_size, model_dim, **kwargs):
self._vocab_size = vocab_size
self._model_dim = model_dim
super(Embedding, self).__init__(**kwargs)
def build(self, input_shape):
self.embeddings = self.add_weight(
shape=(self._vocab_size, self._model_dim),
initializer='glorot_uniform',
name="embeddings")
super(Embedding, self).build(input_shape)
def call(self, inputs):
if K.dtype(inputs) != 'int32':
inputs = K.cast(inputs, 'int32')
embeddings = K.gather(self.embeddings, inputs)
embeddings *= self._model_dim ** 0.5 # Scale
return embeddings
def compute_output_shape(self, input_shape):
return input_shape + (self._model_dim,)
class PositionEncoding(Layer):
def __init__(self, model_dim, **kwargs):
self._model_dim = model_dim
super(PositionEncoding, self).__init__(**kwargs)
def call(self, inputs):
seq_length = inputs.shape[1]
position_encodings = np.zeros((seq_length, self._model_dim))
for pos in range(seq_length):
for i in range(self._model_dim):
position_encodings[pos, i] = pos / np.power(10000, (i-i%2) / self._model_dim)
position_encodings[:, 0::2] = np.sin(position_encodings[:, 0::2]) # 2i
position_encodings[:, 1::2] = np.cos(position_encodings[:, 1::2]) # 2i+1
position_encodings = K.cast(position_encodings, 'float32')
return position_encodings
def compute_output_shape(self, input_shape):
return input_shape
class Add(Layer):
def __init__(self, **kwargs):
super(Add, self).__init__(**kwargs)
def call(self, inputs):
input_a, input_b = inputs
return input_a + input_b
def compute_output_shape(self, input_shape):
return input_shape[0]
class ScaledDotProductAttention(Layer):
def __init__(self, masking=True, future=False, dropout_rate=0., **kwargs):
self._masking = masking
self._future = future
self._dropout_rate = dropout_rate
self._masking_num = -2**32+1
super(ScaledDotProductAttention, self).__init__(**kwargs)
def mask(self, inputs, masks):
masks = K.cast(masks, 'float32')
masks = K.tile(masks, [K.shape(inputs)[0] // K.shape(masks)[0], 1])
masks = K.expand_dims(masks, 1)
outputs = inputs + masks * self._masking_num
return outputs
def future_mask(self, inputs):
diag_vals = tf.ones_like(inputs[0, :, :])
tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense()
future_masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(inputs)[0], 1, 1])
paddings = tf.ones_like(future_masks) * self._masking_num
outputs = tf.where(tf.equal(future_masks, 0), paddings, inputs)
return outputs
def call(self, inputs):
if self._masking:
assert len(inputs) == 4, "inputs should be set [queries, keys, values, masks]."
queries, keys, values, masks = inputs
else:
assert len(inputs) == 3, "inputs should be set [queries, keys, values]."
queries, keys, values = inputs
if K.dtype(queries) != 'float32': queries = K.cast(queries, 'float32')
if K.dtype(keys) != 'float32': keys = K.cast(keys, 'float32')
if K.dtype(values) != 'float32': values = K.cast(values, 'float32')
matmul = K.batch_dot(queries, tf.transpose(keys, [0, 2, 1])) # MatMul
scaled_matmul = matmul / int(queries.shape[-1]) ** 0.5 # Scale
if self._masking:
scaled_matmul = self.mask(scaled_matmul, masks) # Mask(opt.)
if self._future:
scaled_matmul = self.future_mask(scaled_matmul)
softmax_out = K.softmax(scaled_matmul) # SoftMax
# Dropout
out = K.dropout(softmax_out, self._dropout_rate)
outputs = K.batch_dot(out, values)
return outputs
def compute_output_shape(self, input_shape):
return input_shape
class MultiHeadAttention(Layer):
def __init__(self, n_heads, head_dim, dropout_rate=.1, masking=True, future=False, trainable=True, **kwargs):
self._n_heads = n_heads
self._head_dim = head_dim
self._dropout_rate = dropout_rate
self._masking = masking
self._future = future
self._trainable = trainable
super(MultiHeadAttention, self).__init__(**kwargs)
def build(self, input_shape):
self._weights_queries = self.add_weight(
shape=(input_shape[0][-1], self._n_heads * self._head_dim),
initializer='glorot_uniform',
trainable=self._trainable,
name='weights_queries')
self._weights_keys = self.add_weight(
shape=(input_shape[1][-1], self._n_heads * self._head_dim),
initializer='glorot_uniform',
trainable=self._trainable,
name='weights_keys')
self._weights_values = self.add_weight(
shape=(input_shape[2][-1], self._n_heads * self._head_dim),
initializer='glorot_uniform',
trainable=self._trainable,
name='weights_values')
super(MultiHeadAttention, self).build(input_shape)
def call(self, inputs):
if self._masking:
assert len(inputs) == 4, "inputs should be set [queries, keys, values, masks]."
queries, keys, values, masks = inputs
else:
assert len(inputs) == 3, "inputs should be set [queries, keys, values]."
queries, keys, values = inputs
queries_linear = K.dot(queries, self._weights_queries)
keys_linear = K.dot(keys, self._weights_keys)
values_linear = K.dot(values, self._weights_values)
queries_multi_heads = tf.concat(tf.split(queries_linear, self._n_heads, axis=2), axis=0)
keys_multi_heads = tf.concat(tf.split(keys_linear, self._n_heads, axis=2), axis=0)
values_multi_heads = tf.concat(tf.split(values_linear, self._n_heads, axis=2), axis=0)
if self._masking:
att_inputs = [queries_multi_heads, keys_multi_heads, values_multi_heads, masks]
else:
att_inputs = [queries_multi_heads, keys_multi_heads, values_multi_heads]
attention = ScaledDotProductAttention(
masking=self._masking, future=self._future, dropout_rate=self._dropout_rate)
att_out = attention(att_inputs)
outputs = tf.concat(tf.split(att_out, self._n_heads, axis=0), axis=2)
return outputs
def compute_output_shape(self, input_shape):
return input_shape固定随机数种子,定义评价函数:
def set_my_seed():
os.environ['PYTHONHASHSEED'] = '0'
np.random.seed(1)
rn.seed(12345)
tf.random.set_seed(123)
def evaluation(y_test, y_predict):
mae = mean_absolute_error(y_test, y_predict)
mse = mean_squared_error(y_test, y_predict)
rmse = math.sqrt(mean_squared_error(y_test, y_predict))
mape=(abs(y_predict -y_test)/ y_test).mean()
return mae, rmse, mape构建训练集和测试集的函数:
def build_sequences(text, window_size=24):
#text:list of capacity
x, y = [],[]
for i in range(len(text) - window_size):
sequence = text[i:i+window_size]
target = text[i+window_size]
x.append(sequence)
y.append(target)
return np.array(x), np.array(y)
def get_traintest(data,train_size=len(df),window_size=24):
train=data[:train_size]
test=data[train_size-window_size:]
X_train,y_train=build_sequences(train,window_size=window_size)
X_test,y_test=build_sequences(test,window_size=window_size)
return X_train,y_train,X_test,y_test下面自定义好,我们所有的模型(['LSTM', 'GRU', 'CNN', 'MLP', 'CNN+LSTM', 'BiLSTM', 'Attention', 'BiGRU+Attention', 'MultiHeadAttention']),还有训练时画图的观察用的函数和评估函数。
def build_model(X_train,mode='LSTM',hidden_dim=[32,16]):
set_my_seed()
if mode=='RNN':
#RNN
model = Sequential()
model.add(SimpleRNN(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(SimpleRNN(hidden_dim[1]))
model.add(Dense(1))
elif mode=='MLP':
model = Sequential()
model.add(Dense(hidden_dim[0],activation='relu',input_shape=(X_train.shape[-1],)))
model.add(Dense(hidden_dim[1],activation='relu'))
model.add(Dense(1))
elif mode=='LSTM':
# LSTM
model = Sequential()
model.add(LSTM(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(LSTM(hidden_dim[1]))
model.add(Dense(1))
elif mode=='GRU':
#GRU
model = Sequential()
model.add(GRU(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(GRU(hidden_dim[1]))
model.add(Dense(1))
elif mode=='CNN':
#一维卷积
model = Sequential()
model.add(Conv1D(hidden_dim[0],17,activation='relu',input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(GlobalAveragePooling1D())
model.add(Flatten())
model.add(Dense(hidden_dim[1],activation='relu'))
model.add(Dense(1))
elif mode=='CNN+LSTM':
model = Sequential()
model.add(Conv1D(filters=hidden_dim[0], kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(hidden_dim[1]))
model.add(Dense(1))
elif mode=='BiLSTM':
model = Sequential()
model.add(Bidirectional(LSTM(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1]))))
model.add(Bidirectional(LSTM(hidden_dim[1])))
model.add(Dense(1))
elif mode=='Attention':
inputs = Input(name='inputs',shape=[X_train.shape[-2],X_train.shape[-1]], dtype='float32')
attention_probs = Dense(hidden_dim[0], activation='softmax', name='attention_vec')(inputs)
attention_mul = Multiply()([inputs, attention_probs])
mlp = Dense(hidden_dim[1])(attention_mul) #原始的全连接
fla=Flatten()(mlp)
output = Dense(1)(fla)
model = Model(inputs=[inputs], outputs=output)
elif mode=='BiGRU+Attention':
inputs = Input(name='inputs',shape=[X_train.shape[-2],X_train.shape[-1]], dtype='float64')
attention_probs = Dense(32, activation='softmax', name='attention_vec')(inputs)
attention_mul = Multiply()([inputs, attention_probs])
mlp = Dense(64)(attention_mul) #原始的全连接
gru=Bidirectional(GRU(32))(mlp)
mlp = Dense(16,activation='relu')(gru)
output = Dense(1)(mlp)
model = Model(inputs=[inputs], outputs=output)
elif mode=='MultiHeadAttention':
inputs = Input(shape=[X_train.shape[-2],X_train.shape[-1]], name="inputs")
#masks = Input(shape=(X_train.shape[-2],), name='masks')
encodings = PositionEncoding(X_train.shape[-2])(inputs)
encodings = Add()([inputs, encodings])
x = MultiHeadAttention(8, hidden_dim[0],masking=False)([encodings, encodings, encodings])
x = GlobalAveragePooling1D()(x)
x = Dropout(0.2)(x)
x = Dense(hidden_dim[1], activation='relu')(x)
outputs = Dense(1)(x)
model = Model(inputs=[inputs], outputs=outputs)
model.compile(optimizer='Adam', loss='mse',metrics=[tf.keras.metrics.RootMeanSquaredError(),"mape","mae"])
return model
def plot_loss(hist,imfname):
plt.subplots(1,4,figsize=(16,2))
for i,key in enumerate(hist.history.keys()):
n=int(str('14')+str(i+1))
plt.subplot(n)
plt.plot(hist.history[key], 'k', label=f'Training {key}')
plt.title(f'{imfname} Training {key}')
plt.xlabel('Epochs')
plt.ylabel(key)
plt.legend()
plt.tight_layout()
plt.show()
def evaluation_all(df_eval_all,mode,show_fit=True):
df_eval_all['all_pred']=df_eval_all.iloc[:,1:].sum(axis=1)
MAE2,RMSE2,MAPE2=evaluation(df_eval_all['actual'],df_eval_all['all_pred'])
df_eval_all.rename(columns={'all_pred':'predict'},inplace=True)
if show_fit:
df_eval_all.loc[:,['predict','actual']].plot(figsize=(12,4),title=f'VMD+{mode}的拟合效果')
print('总体预测效果:')
print(f'VMD+{mode}的效果为mae:{MAE2}, rmse:{RMSE2} ,mape:{MAPE2}')
df_allmodel[mode]=df_eval_all['predict'].to_numpy()
准备一个空数据框,存放预测的结果:
df_allmodel=pd.DataFrame()然后自定义训练函数,我的训练函数会遍历每个模态,然后对每个模态进行划分训练集和测试集,,归一化,然后训练模型,预测,再逆归一化回去,把所有模态的预测结果相加得到最终的预测结果,然后计算评价指标打印出来,等等,其中还会对模型的训练过程中的损失变化画图。
def train_fuc(mode='LSTM',train_rat=0.8,window_size=24,batch_size=32,epochs=100,hidden_dim=[32,16],show_imf=True,show_loss=True,show_fit=True):
df_all=df.copy()
train_size=int(len(df_all)*train_rat)
df_eval_all=pd.DataFrame(f.values[train_size:],columns=['actual'])
for i,name in enumerate(df_names):
print(f'正在训练第:{name}条分量')
data=df_all[name]
X_train,y_train,X_test,y_test=get_traintest(data.values,window_size=window_size,train_size=train_size)
#归一化
scaler = MinMaxScaler()
scaler = scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
scaler_y = MinMaxScaler()
scaler_y = scaler_y.fit(y_train.reshape(-1,1))
y_train = scaler_y.transform(y_train.reshape(-1,1))
if mode!='MLP':
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
print(X_train.shape, y_train.shape, X_test.shape,y_test.shape)
set_my_seed()
model=build_model(X_train=X_train,mode=mode,hidden_dim=hidden_dim)
start = datetime.datetime.now()
hist=model.fit(X_train, y_train,batch_size=batch_size,epochs=epochs,verbose=0)
if show_loss:
plot_loss(hist,name)
#预测
y_pred = model.predict(X_test)
y_pred =scaler_y.inverse_transform(y_pred)
#print(y_pred.shape)
end = datetime.datetime.now()
if show_imf:
df_eval=pd.DataFrame()
df_eval['actual']=y_test
df_eval['pred']=y_pred
df_eval.plot(figsize=(7,3))
plt.show()
mae, rmse, mape=evaluation(y_test=y_test, y_predict=y_pred)
time=end-start
df_eval_all[name+'_pred']=y_pred
print(f'running time is {time}')
print(f'{name} 该条分量的效果:mae:{mae}, rmse:{rmse} ,mape:{mape}')
print('============================================================================================================================')
evaluation_all(df_eval_all,mode=mode,show_fit=True)初始化超参数:
window_size=48 #滑动窗口大小
train_rat=0.8 #训练集比例
batch_size=32 #批量大小
epochs=50 #训练轮数
hidden_dim=[32,16] #隐藏层神经元个数
show_fit=True
show_loss=True
mode='LSTM' #RNN,GRU,CNN可能有小伙伴看到这里已经晕了,这些函数都是我自己写的,但是我使用的时候也不会去仔细看的,因为每个函数的功能都很清楚。我封装得很好,所以使用起来就很简单,例如下面开始训练lstm的模型:
LSTM预测
mode='LSTM'
set_my_seed()
train_fuc(mode=mode,window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)就这么一行代码就行,就能得到如下所有的训练效果图:

四条小模态的单独的预测效果,拟合图,评价指标,还有全部加一起的总的的效果图,评价指标都打印出来了,就一行代码,很简单。
这里的lstm在这些默认的参数情况下的最终预测效果是:
mae:63.6764175025622, rmse:86.68976515618272 ,mape:0.228000752359303
如果想修改参数的话,就在这个函数里面改就行,很便捷,我还是对lstm进行训练:
#改变滑动窗口大小等参数
set_my_seed()
train_fuc(mode=mode,window_size=96,train_rat=train_rat,batch_size=15,epochs=60,hidden_dim=[64,32])图太长我就不截完了,我们看看最终的效果:

可以看到评价指标是:
mae:59.25879243718254, rmse:79.92821805096699 ,mape:0.20615518
比起上面的默认参数的lstm,误差变小了,效果是好了一点点的。
大家可以自己调试,修改参数,去获取更好的预测效果:
## 还可以自己多试试别的参数
train_fuc(mode='LSTM',window_size=window_size,train_rat=train_rat,batch_size=16,epochs=80,hidden_dim=[64,32])这里就截图不展示了。
GRU预测
想使用不同的模型也很简单,就修改mode参数,例如这里使用gru进行预测:
set_my_seed()
train_fuc(mode='GRU',window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)
GRU的效果也还不错:
总体预测效果: VMD+LSTM的效果为mae:59.25879243718254, rmse:79.92821805096699 ,mape:0.20615518445171077
RNN预测
然后是RNN:
set_my_seed()
train_fuc(mode='RNN',window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)不展示了
一维CNN预测
我每次训练之间都加上:set_my_seed()这个函数是为了固定随机数种子,让模型能复现。
(深度学习就是这么玄学,就算你所有参数都一样,设备也一样,跑出来的效果可能也是有差异的.....)
set_my_seed()
train_fuc(mode='CNN',window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)截个小图看看最终预测效果吧:
VMD+CNN的效果为mae:120.55432003868948, rmse:149.99661035695433 ,mape:1.1896740203851466
误差比lstm大了一倍多,不太行。。。
(ps:根据我的检验,一维cnn只能用于滑动窗口很小的时间序列预测,低于16以下的吧,我这里的滑动窗口是48,所以CNN效果肯定不好。)
(还有的同学会问,“那我二维CNN呢?” , 我只能说多读点书.......,CNN最初就是二维的,但是人家是用于四维的图片数据,你时间序列的三维数据和二维的表格数据用不了。。。)
MLP预测
模型对比当然不能少了最经典的mlp,其实所谓的全连接层,密集层,线性层,多层感知机,还有外行说的bp神经网络,其实都是mlp。是最简单的神经网络结构了。
set_my_seed()
train_fuc(mode='MLP',window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)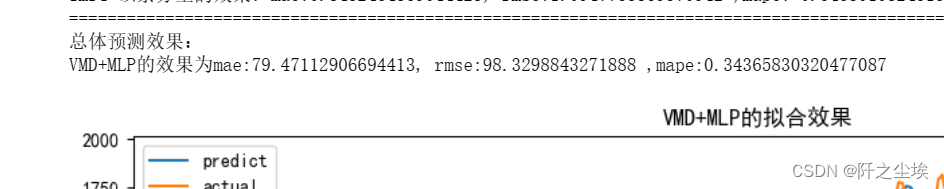
效果一般般,我后面都会一起比较的。
CNN+LSTM
set_my_seed()
train_fuc(mode='CNN+LSTM',window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim) 
效果还可以吧,但是比不过lstm。我其实最讨厌cnn+lstm这种缝合了,完全没意义,对于时间序列这种数据没得任何的逻辑和对预测的帮助,为了创新而创新。。其实都被做烂了,而且效果也一般不会更好。
BiLSTM
set_my_seed()
train_fuc(mode='BiLSTM',window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)
效果一般般
Attention
纯注意力机制
set_my_seed()
train_fuc(mode='Attention',window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)
一般
BiGRU+Attention
set_my_seed()
train_fuc(mode='BiGRU+Attention',window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)不展示了,下面统一对比
MultiHeadAttention
set_my_seed()
#多头注意力,默认用了8个头
train_fuc(mode='MultiHeadAttention',window_size=window_size,train_rat=train_rat,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)不展示了,下面统一对比
评价指标
查看每个模型预测的结果:
df_allmodel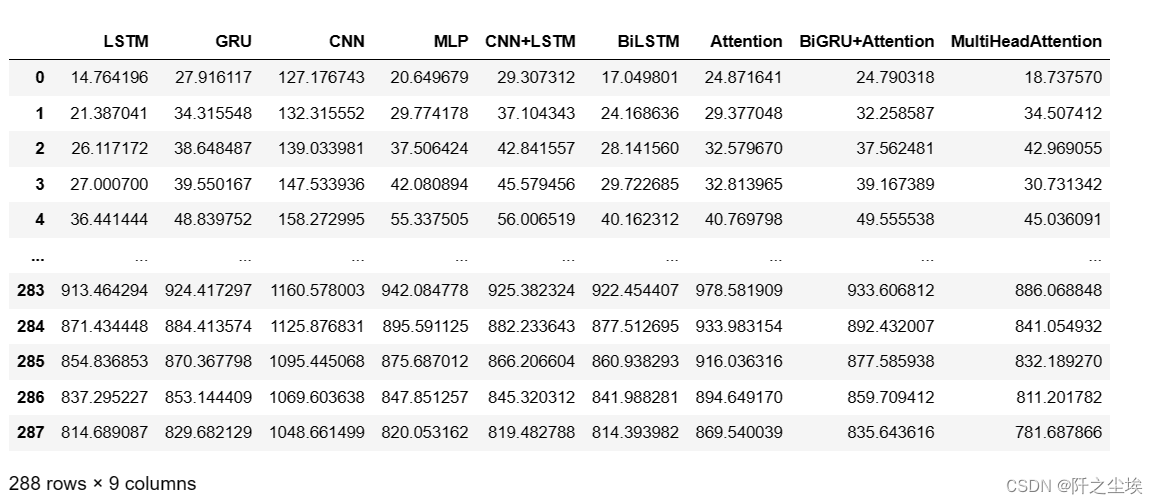
1440的20%是288个点,然后还是9个模型,没问题。
我们取出真实值的测试集部分的数据:
y_actual=data[-len(df_allmodel):,:].reshape(-1,)定义另外的评价指标计算函数,计算['MSE','RMSE','MAE','MAPE'],这四个都是回归问题常用的评价指标。
def evaluation2(y_test, y_predict):
mae = mean_absolute_error(y_test, y_predict)
mse = mean_squared_error(y_test, y_predict)
rmse = np.sqrt(mean_squared_error(y_test, y_predict))
mape=(abs(y_predict -y_test)/ y_test).mean()
#r_2=r2_score(y_test, y_predict)
return mse, rmse, mae, mape #r_2
df_eval_all=pd.DataFrame(columns=['MSE','RMSE','MAE','MAPE'])计算每个模型的预测结果和真实值之间的评价指标:
for col in df_allmodel:
s=list(evaluation2(y_actual,df_allmodel[col].to_numpy()))
df_eval_all.loc[f'{col}',:]=s
df_eval_all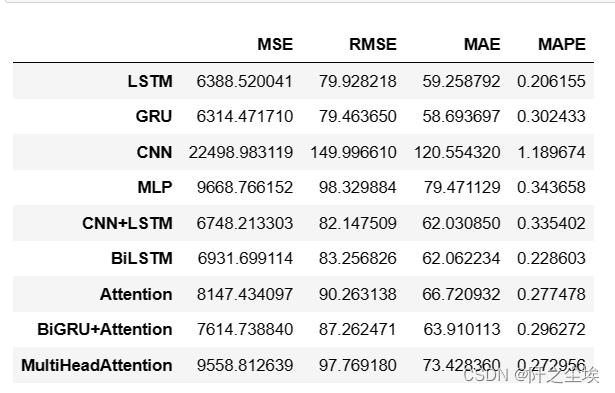
看数字不直观,画个柱状图:
bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan','gold','r']
fig, ax = plt.subplots(2,2,figsize=(10,7),dpi=128)
for i,col in enumerate(df_eval_all.columns):
n=int(str('22')+str(i+1))
plt.subplot(n)
df_col=df_eval_all[col]
m =np.arange(len(df_col))
plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)
#plt.xlabel('Methods',fontsize=12)
names=df_col.index
plt.xticks(range(len(df_col)),names,fontsize=10)
plt.xticks(rotation=40)
plt.ylabel(col,fontsize=14)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()
这个数据上,好像lstm 的效果是最好的,cnn最差。
有的同学会说,不对啊,我bilstm没有lstm效果好啊,还有加了注意力机制的gru为什么没有单独的gru效果好呢?
我只能说,“多做点实验就知道了....” ,深度学习都是玄学,在不同的数据集,不同的参数上,模型的效果对比有着截然不同的结论。
不要以为加的模块越多越好,加了组合模型效果一定比单一模型好,很多时候都是一顿操作猛如虎,一看效果二百五。 这是要看数据,看参数去调整的。
但是大部分时候,什么加了一堆的模态分解,优化算法,注意力,损失函数,效果都没最简单,最纯粹,最原始的LSTM, GRU的效果好。。。真的,我经验就是这样告诉我的,所以可以想象那些期刊论文的各种缝合模型是有多么水了吧。。
预测效果对比图
再画个预测值的对比图:
plt.figure(figsize=(10,5),dpi=256)
for i,col in enumerate(df_allmodel.columns):
plt.plot(df_allmodel[col],label=col) # ,color=colors[i]
plt.plot(y_actual,label='actual',color='k',linestyle=':',lw=2)
plt.legend()
plt.ylabel('',fontsize=16)
plt.xlabel('time',fontsize=14)
#plt.savefig('点估计线对比.jpg',dpi=256)
plt.show()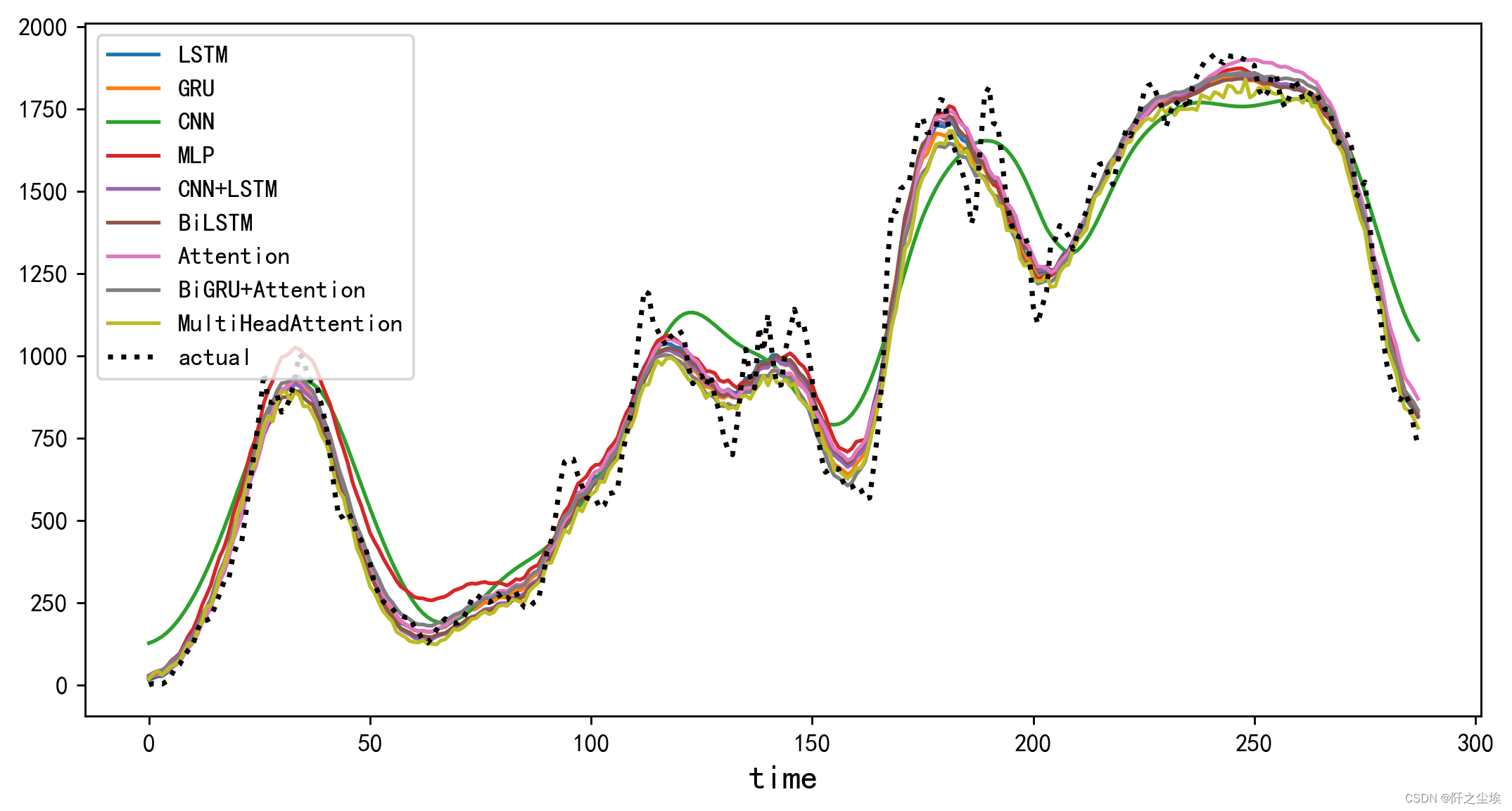
反正发论文都要这种图,但是也没啥意义,就是看看模型拟合预测的怎么样....
所以说写代码很简单,数据改一改就行。。要什么模块修改我的训练函数参数就行。效果不好调整参数改到效果好为止。
不同的模型就修改mode参数,有啥难度。。。
分析文字也可以gpt写,现在水论文的成本真的很低。。。
本次案例的全部代码文件和数据集获取可以参考:(模态分解系列演示)
这次案例是加上了模态分解,后面有时间再把优化算法,损失函数,区间估计什么的缝合手段也写一下,就各种组合,发论文都这样。。。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码可私信)