写在前面:
这篇文章是跟我学RISC-V的第二期,是第一期的延续,第一期主要是带大家了解一下什么是RISC-V,是比较大体、宽泛的概念。这一期主要是讲一些基础知识,然后进行RISC-V汇编语言与c语言的编程。在第一期里我们搭建了好几个环境,你可以任意选一个你喜欢的RISC-V环境(能够执行RV机器码的平台),然后进行代码编写、编译、汇编、链接、运行、观察现象的这一过程。同样地,在这一篇里我也会拿x86的知识与RISC-V进行对比,这样也可以促进对两种指令集的学习。
一、RISC-V指令集的基础信息
1、RISC-V的通用寄存器
在第一期里我讲过,无论是RV32还是RV64,它的通用寄存器的数量都是32个。32真是一个好数字,刚好是2的5次方,实际上伯克利大学的研究员在设计RV的时候就非常讲究,这么做的好处是颇多的,也体现了RISC-V指令集的特色,这个我们在学习之后再讨论这个问题。
这32个寄存器分别是x0 x1 x2 ... x31这样去编号,但是就单纯的这样去写汇编的话,是非常不方便的,因此每一个寄存器又有自己的别名,这个别名就代表了这个寄存器的含义,以及函数调用时候的规则。也就是说,你在实际汇编编程的时候,既可以使用编号名,也可以使用别名,实际上使用别名更好,这样能够把寄存器的含义和在这里的作用绑定起来,别人看你的代码就知道你要做什么了。
| 寄存器名 | 别名 | 作用 | 在函数调用过程中的维护 |
| x0 | zero | 零寄存器,永远是0 | 不需要维护 |
| x1 | ra | return address在函数调用时存放返回地址 | caller |
| x2 | sp | stack pointer栈指针寄存器 | callee |
| x3 | gp | global pointer全局寄存器(用于联接器松弛优化)经常使用基于gp的寻址模式来访问全局变量和静态数据,从而提高访问速度和效率 | caller/不需要保存 |
| x4 | tp | thread pointer线程寄存器(保存pcb的地址) | 与线程相关 |
| x5 | t0 | temporaries临时寄存器,相当于c语言的临时用一下变量,callee可能会改变他们的值,caller根据实际情况看是否要保存 | caller |
| x6 | t1 | ||
| x7 | t2 | ||
| x8 | s0 | saved保存寄存器,在函数调用过程中必须保存的寄存器 | callee |
| x9 | s1 | ||
| x10 | a0 | argumeng参数寄存器,在函数调用过程中传递参数和返回值。同时,a0和a1又会在函数返回时的传递返回值。 | caller |
| x11 | a1 | ||
| x12 | a2 | ||
| x13 | a3 | ||
| x14 | a4 | ||
| x15 | a5 | ||
| x16 | a6 | ||
| x17 | s7 | ||
| x18 | s2 | saved保存寄存器,在函数调用过程中必须保存的寄存器 | callee |
| x19 | s3 | ||
| x20 | s4 | ||
| x21 | s5 | ||
| x22 | s6 | ||
| x23 | s7 | ||
| x24 | s8 | ||
| x25 | s9 | ||
| x26 | s10 | ||
| x27 | s11 | ||
| x28 | t3 | 临时寄存器,总共有7个临时寄存器 | caller |
| x29 | t4 | ||
| x30 | t5 | ||
| x31 | t6 |
上图描述了32个通用寄存器在编程中作用的约定,特别是c编程时候的默认调用约定。其实这些寄存器本身来说想咋用,但是如果这样的话,你写一套使用寄存器的风格,他也有一套自己的风格,这样的话我写的函数你就没法调用了,因为寄存器安排不同,这样就非常麻烦,根本不利于开发。于是RISC-V指令集在设计之处,就把这些寄存器的作用和安排都规定好了,别名也取好了。你不需要自己想一套函数调用的法则,你只需要遵守约定就好。这样,我写的函数,你也可以直接调用,而不需要考虑参数保存在哪个寄存器,因为这都已经规定好了。
比如说A函数调用的B函数,那么caller就是A函数,callee就是B函数。
这个寄存器的别名是很有用的,你不需要去记忆x寄存器名到别名的映射,你只需要记住别名中前缀的含义,你在汇编语言编程的时候就知道该使用哪一个寄存器来保存什么信息了。
如果你是第一次看见这个表格,你可能会感觉很抽象,不过只要编程练习一下,那么也就不抽象了。不过想进行RISC-V汇编语言的编程,光是知道通用寄存器还是不够的,你还得知道一些指令,所以我在这里先分析一下RV的寄存器和x86的不同之处。
我们都知道,x86是CISC,而RISC-V在RISC,这二者在寄存器的安排上就有非常大的不同。在x86架构中,有一种说法是“寄存器较弱的体系结构”,意思就是x86架构的通用寄存器的数量是非常少的。在实模式下,也就ax,bx,cx,dx,bp,sp,si,di, 就是搞来搞去就这么几个寄存器,并且比如bx,bp还要拿来作为offset偏移量寻址、cx还要拿来作为循环次数的保存、sp还是指向栈顶。总结来说就是能够程序员使用的通用寄存器的数量是在是太少太少了,我在大一的时候学习8086汇编就比较难受,寄存器满打满算就这么几个,一下子就用掉了,总感觉不太够用(你可以看看我之前的blog)。进入IA-32e的长模式感觉就好多了,通用寄存器又加上了r8 ~ r15 ,Intel终于是不挤牙膏了。而对于RISC-V而言,有整整32个通用寄存器,其中临时寄存器的数量就有7个,相比x86真是太爽了,随便拿一个就能临时保存一下我计算过程中的数据(你可以认为是打草稿)。对程序员来说,这太方便、舒服了。
还有一些区别是,在x86中(保护模式),函数调用时候参数非常依赖于内存。也就是参数都是保存在栈里的,保存在栈里问题倒是不大,就是读写内存的速度相比读写寄存器的数据差距太大了。在RISC-V有中专门的a系列的寄存器可以用户保存函数调用时候的参数,a0 ~ a7 整整8个寄存器呢!基本上来说,你一个函数的参数也很少会超过8个,当然如果超过了那还是要保存在栈里。总的来说,参数保存在寄存器里那速度是快了好几倍。(当然在Intel IA-32e中也是使用寄存器保存参数了,Intel在多年的迭代过程中算是学聪明了,而RISC-V是一开始就这么聪明,这就是后发的优势)
还有一点就是在RISC-V体系结构中,专门可以拿出一个寄存器tp, 来存放指向当前进程task_struct的指针,用于加快访问速度。而像x86这样的体系结构(通用寄存器数量不多)就只能在内存栈顶创建thread_info结构,通过计算偏移量间接的查找task_struct(也就是pcb)。也就是x86体系中每一次调用current去查找当前进程的pcb都需要访问多次内存,还要通过偏移量去找到task_struct的地址,这转来转去速度就会变慢。而RISC-V则直接通过tp寄存器直接就能找到pcb ,那访问寄存器的速度快很多,并且也不需要通过偏移量去寻址。这又是一大优势。
还有就是在x86中通用寄存器是可拆解的,比如IA-32e的rax寄存器是64位的,你可以拆解它。rax、eax、ax、ah、al, 从8位到16位到32位到64位,是可以拆分的。这都是Intel为了兼容性而设计的这么一套东西,因为早期的8088是8位的CPU,8086是16位的,老奔腾是32位的,酷睿又是64位的,它为了兼容就用这种方法,你即便进入了长模式,仍然可以使用al寄存器。但是在RISC-V中,RV32寄存器的大小就是32位的,你不可能说拆成hx和hl,没有这样的用法。所以说RISC-V指令集里面,你在使用load系列指令的时候,把一个不到32位的数值放置到32位的寄存器,会进行符号扩展或者零扩展,而不是直接把这个数直接放到寄存器里,这样会损失符号的。
在上面表格中有一个非常特殊的寄存器x0 zero寄存器,它类似于LInux里的/dev/null这个设备,你往里面写入任何数据都没用,再怎么写都是0,写入任何数都会被丢弃掉;如果你把这个寄存器的值给读出来,也还是0。你可能觉得这个寄存器好像没啥用啊,难道我就不能用立即数0去替代这个x0寄存器吗?实际上,这个x0 寄存器是非常有用的,有很多地方都会用到它。特别是伪指令在转换成汇编指令的时候,会经常用到zero寄存器,这个我会在后面讲到。
2、RISC-V的指令格式与特点
(一)RISC-V指令的特点
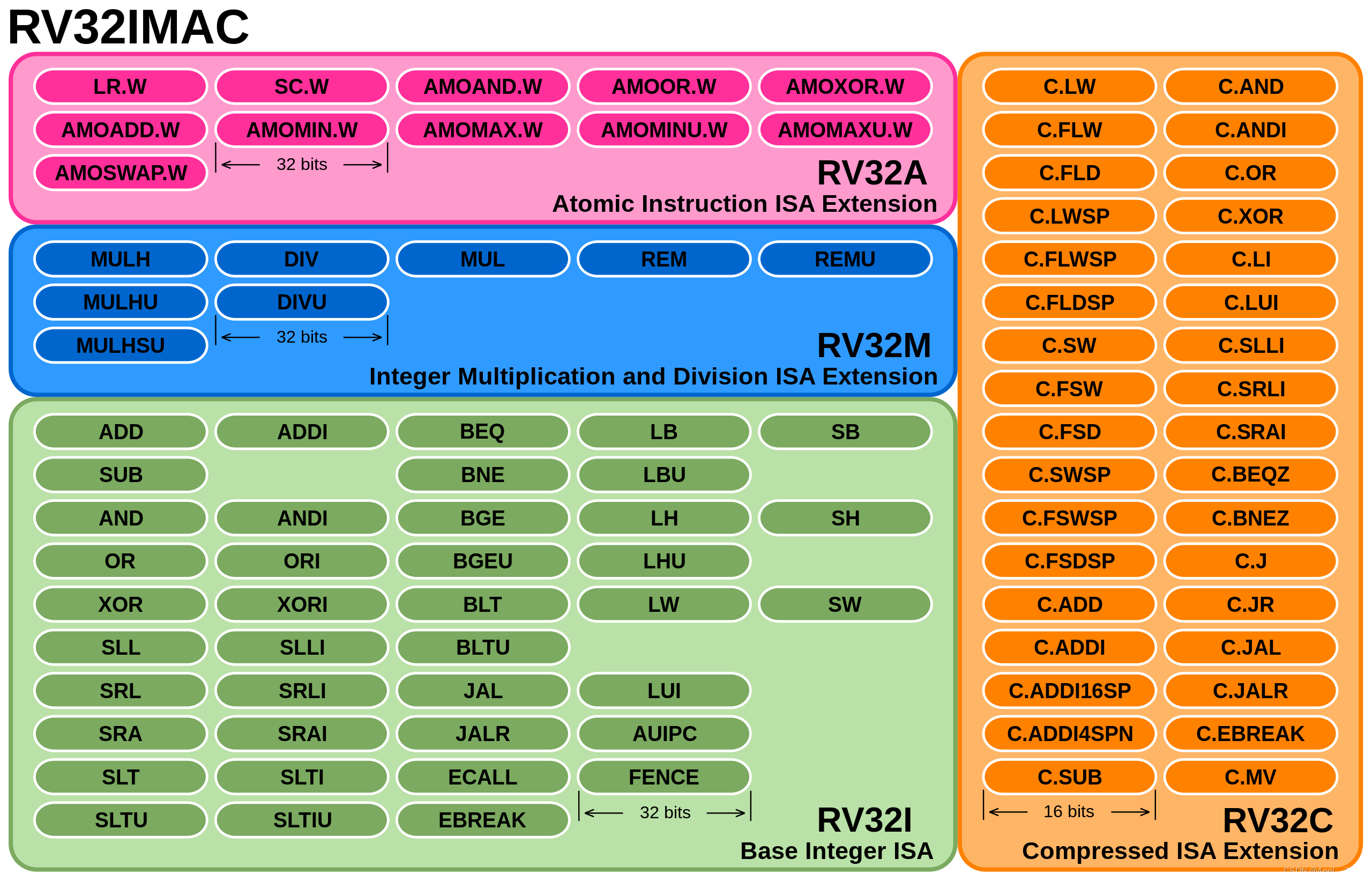
RISC-V的每条指令宽度都是32位(固定的4B),如果有c扩展使用指令压缩后会变成2B ,这个我们先不提。RV的指令格式如图所示分为6种。

- R-type:寄存器与寄存器算术指令,这里的R就是register寄存器的意思;
- I-type:寄存器与立即数算术指令或者加载指令;
- S-type:存储指令(和上面的加载指令刚好是反义词);
- B-type:条件跳转指令;
- U-type:长立即数操作指令;
- J-type:无条件跳转指令。
大家从图里可以清晰地看到:无论是什么类型的指令,确实都是4B的,并且共同点就是opcode操作码都在低7位。操作码这个概念相信学过计算机组成原理的都知道。
足够的编码空间:使用7位操作码可以提供128种不同的可能值,这允许定义多种不同的基本操作和指令格式。对于一个旨在可扩展和支持多种扩展模块(如整数、浮点、原子操作等)的现代处理器架构来说,这一点非常重要。
简化解码:RISC-V的指令长度固定为32位,这使得硬件能够更加简单和高效地解码指令。opcode位于指令的最低7位,硬件可以快速地读取这7位并确定如何进一步解析整个指令,这对提高指令解码速度和处理器整体性能至关重要。
支持指令格式多样性:RISC-V使用不同的指令格式(如R、I、S、B、U、J格式)来支持不同类型的操作。这些格式有不同的字段组合和长度,opcode的7位设计帮助区分这些格式,并指导如何解析随后的字段。
扩展性:RISC-V架构被设计为可扩展的,以支持新的功能和指令集扩展。7位opcode为未来可能的指令集扩展留出了空间,使得可以轻松加入新的操作码而不会干扰现有的指令解码逻辑。
在图中的rd就是目的寄存器,rs就是源寄存器。这个概念类似于x86中的rdi和rsi。大家可以总结出来,rd要么是1个要么是0个(有的指令是不用把值输出到目的寄存器的),rs最多支持两个,就是最多放两个源寄存器进来。无论是rd还是rs,它所占用的位数都是5位。这个事情我们之前提到过,因为寄存器总共就32个,2的5次方等于32,那么设置成5位这样,是非常巧妙的。
图片中还经常出现imme,这个就是立即数的意思,immediately.
还有就是占用3位的funct3与占用7位的funct7,就是说单纯的opcode还不足以确定这条指令究竟是哪一条指令。而是要opcode和funct功能码,这二者一起才能共同决定这条指令对应的具体的汇编指令。手动反汇编的时候要用到。

实际上对照这张表格,你就很容易做到反汇编了。拿到一个4B的16进制数,你先把他转换成32位二进制数,然后对照opcode先确定是什么类型,确定好之后再根据具体的funct(如果存在)就能确定是哪一条指令了。确定指令之后,再通过rs,rd推出对应的寄存器号,有立即数的话把立即数也带进去。这样,一整条汇编指令就出现了。
(二)RISC-V每条指令详解
接下来,我要对每一条指令进行说明,大家耐心看一看吧。为了让现象更加明显,我使用c语言内联汇编的方法,把指令执行后的现象给展示出来,方便大家查看,那么大家如果能够跟着实践一遍这样更好。这里我还没有讲到c语言内联汇编的东西,不过有编程基础的应该能够看懂asm语句,我会在c代码后面讲述这么做的目的。
①加载指令
加载指令load就是把数据从内存加载到寄存器的这一过程。
| 指令格式 | 数据位宽 | 说明 |
| lb rd,offset(rs) | 8 | 把rs寄存器里的值指向的地址作为基地址,在偏移offset的地址处,加载1B的数据经过符号扩展之后放入到rd寄存器里面 |
| lbu rd,offset(rs) | 8 | 作为无符号加载,经过零扩展放入到寄存器rd |
| lh rd,offset(rs) | 16 | 符号扩展加载2B |
| lhu rd,offset(rs) | 16 | 零扩展加载2B |
| lw rd,offset(rs) | 32 | 符号扩展加载4B |
| lwu rd,offset(rs) | 32 | 零扩展加载4B |
| ld rd,offset(rs) | 64 | 直接加载到rd寄存器里,不用扩展了 |
| lui rd,imme | 64 | 把立即数imme左移12位,然后符号扩展,再把结果写入到rd寄存器(这里的u是upper的意思,不是unsigned的意思) |
RISC-V的指令都挺有规律的,l就是load加载的意思,代表数据从内存加载到寄存器;b是byte的意思,表示1个字节;h是halfword的意思,表示半字,2个字节;w表示word,一个字,4个字节;d表示double word表示双字,就是8个字节。跟在b/h/w/d后面的u是unsigned的意思,表示这是无符号数,不存在符号扩展;直接跟在l后面的是u ,表示这是upper,需要左移。记忆是比较容易的。
我们先进行一些区分:
#include <stdio.h>
int main(void)
{
long rd = 0;
char rs[3];
rs[0] = 'a';
rs[1] = 'b';
rs[2] = 'c';
asm volatile(
"lb %0,1(%1) \n\t"
:"=r"(rd)
:"r"(rs)
);
printf("%c\n",rd);
return 0;
}
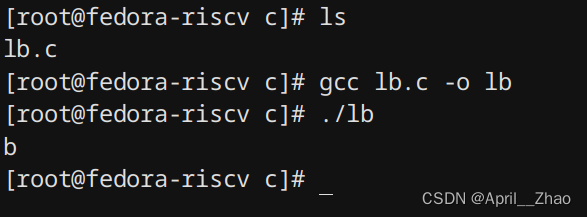
这是一段非常简单的c语言内联汇编的代码,意思就是把rs作为地址传入到寄存器里,再通过lb指令把rs指向的地址作为基地址,偏移了1B的地址里面取出来1B,把这个数据经过符号扩展放入寄存器里,在输出到rd变量。我们打印rd变量,确实是字符b.由于字符b是一个正数,因此符号扩展之后值就是本身。
lb.c
#include <stdio.h>
int main(void)
{
long rd = 0;
char rs = -20;
asm volatile(
"lb %0,0(%1) \n\t"
:"=r"(rd)
:"r"(&rs)
);
printf("%d\n",rd);
return 0;
}

lbu.c
#include <stdio.h>
int main(void)
{
long rd = 0;
char rs = -20;
asm volatile(
"lbu %0,0(%1) \n\t"
:"=r"(rd)
:"r"(&rs)
);
printf("%d\n",rd);
return 0;
}
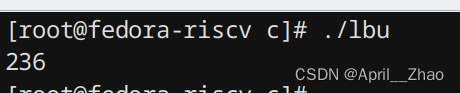
可以看见,即便rs变量的值是-20,如果你使用的是lbu指令,那么就会进行零扩展,符号位就无效了。
从以上这个例子我们不难看出:符号扩展是计算机系统中把小字节转换成大字节的规则之一,它会将符号扩展到所需要的位数。
比如一个1字节的数0x8A,它的最高位也就是第7位是1,那么就需要进行符号扩展,高字节使用1来填充。如果扩展到64位,那么它的值就是0xffff ffff ffff ff8a
而零扩展的就是当成无符号来处理,既然是无符号数,高字节部分使用0来填充。
还有一点要注意的是,符号扩展是小字节往大字节扩展的时候进行的,而ld这一条指令,它本身就是从内存加载一个64位的数到寄存器,没有从小字节到大字节的过程,因此是不需要符号扩展的。
我再测试一下lui指令:
lui.c
#include <stdio.h>
int main(void)
{
long rd = 0;
asm volatile(
"lui %0,0xff \n\t"
:"+r"(rd)
);
printf("rd = %lx\n",rd);
return 0;
}
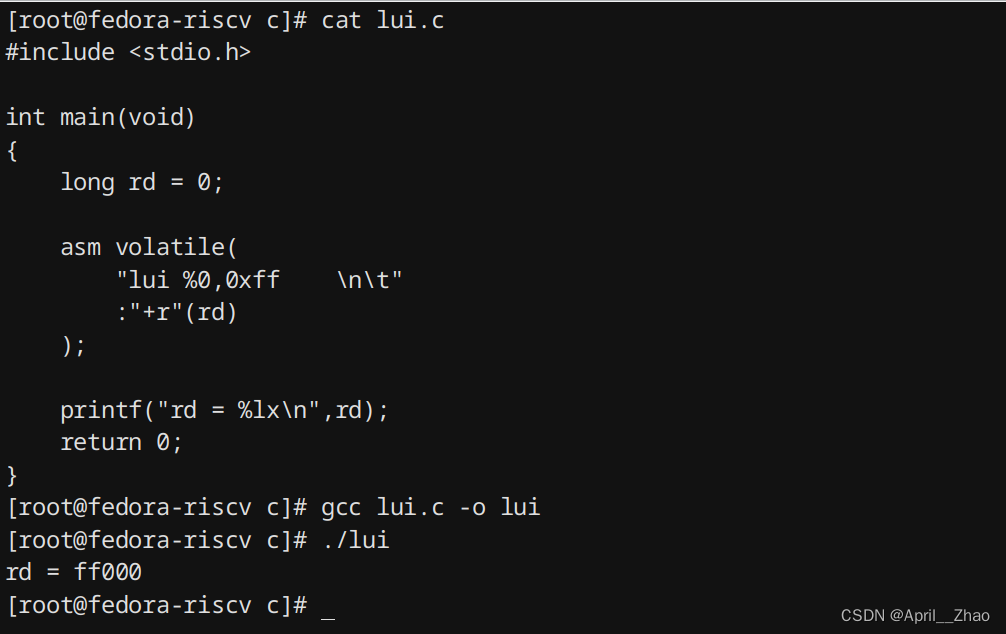
确实是左移了12位,1个16进制的0代表2进制的4位。你也许会很困惑,为什么要左移12位?为什么不是左移13位?为什么不是干脆不左移?
寻址能力的扩展:
lui指令将 20 位立即数置于寄存器的高 20 位。这样做的目的是允许程序能够引用位于较高地址范围内的内存地址或数据。考虑到 RISC-V 的寄存器是 32 位的,这种设计使得使用lui加上一个后续的加法或其他指令(比如addi),可以访问整个 32 位地址空间。
高效的常数加载:
通过将立即数左移 12 位,
lui指令可以快速地设置寄存器中的高位,这对设置大的常数值非常有效。如果需要加载的立即数不仅仅是高位,可以通过随后的addi(Add Immediate)等指令来设置剩余的低 12 位。
指令编码的简化:
在 RISC-V 的指令格式中,立即数字段(imm字段)经常被复用以适应不同类型的指令。
lui指令的设计使得指令的立即数字段直接对应于寄存器的高 20 位,从而简化了指令的解码和执行过程。
支持编译器优化:
这种左移 12 位的设计也有助于编译器生成更优化的代码,尤其是在进行全局地址或大范围数据定位的时候。编译器可以更容易地生成用于初始化大数组或访问静态变量的代码。
总之就是,在RISC-V中一条指令总共就4B,能够分配给立即数imme的部分是很有限的,为了能够寻址到“高地址的地方”,于是很多指令都是具有upper的性质,即把其中的立即数左移12位,然后低于12位的部分你可以使用add系列的指令加上来,这样你的寻址能力大大提升,不用再受限于4B指令有限的imme位数能够表示的最大值了。此时你可能会觉得这也太麻烦了,我寻址一下难道还要把一个完成的地址给拆分成高位和低12位,这样组合成地址吗?实际上,你可以手动这样去组合、去拼凑,因为精简指令集本身就是多条指令的组合才能完成一个功能的,而不像x86那样,一条MOV指令打天下。当然,RISC-V的设计者为了程序员方便,它提供了大量的“伪指令”,你使用伪指令之后,伪指令会再拆分成真正的RISC-V汇编指令。有了这些伪指令,编程是不会太麻烦了。
在这个例子你,你可以使用一条伪指令叫做li,这个li就可以把一个立即数放进寄存器里。
li.c
#include <stdio.h>
int main(void)
{
long rd = 0;
asm volatile(
"li %0,0xff \n\t"
:"+r"(rd)
);
printf("rd = %lx\n",rd);
return 0;
}

不过你的记得,这是一条伪指令,它不是真正的RISC-V汇编指令,它是多条指令的组合。
②存储指令
存储指令就是加载指令的反义词 --把数据从寄存器移动到内存里。只是它更加简单了,没有符号扩展,直接移动数据即可。
| 指令 | 位宽 | 说明 |
| sb rs2,offset(rs1) | 8 | 把rs2寄存器的低8位的值存储到以rs1寄存器的值为基地址,offset为偏移量的地址处。 |
| sh rs2,offset(rs1) | 16 | 低16位 |
| sw rs2,offset(rs1) | 32 | 低32位 |
| sd rs2,offset(rs1) | 64 | 整个rs2寄存器的值 |
这个存储指令就是store,把寄存器的值往内存里存,对应的指令类型是S-type.
大家其实也发现了,这个store指令系列对于load来说,简单太多了,没有什么又是u啊又是i的,就是非常单纯的把寄存器值的一部分或者整个寄存器的值,放置到指定的内存地址里面去。这里不需要什么符号扩展、零扩展的。
#include <stdio.h>
int main(void)
{
char rs[3] = {0};
asm volatile(
"li t0,'b' \n\t"
"sb t0,1(%0) \n\t"
:
:"r"(rs)
:"t0","memory"
);
printf("rs[1] = %c\n",rs[1]);
return 0;
}
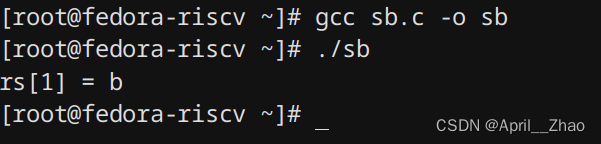
注意这里我们在扩展内联汇编里直接使用到了寄存器t0,因此在损坏部分要把它写进去,这样在asm嵌入的代码块执行结束的时候会把t0原先的值给恢复回去。
③算术指令
算术指令相对来说是比较重要、用到的场景也是比较多的。
| 指令 | 指令格式 | 说明 |
| add | add rd,rs1,rs2 | 把rs1寄存器的值和rs2寄存器的值相加,并把加法的结果放到rd寄存器里 |
| addi | add rd,rs,imme | 把rs寄存器的值和立即数imme相加,把结果放到rd寄存器里 |
| addw | addw rd,rs1,rs2 | 截取rs1和rs2寄存器的低32位,相加后把结果进行符号扩展并放到rd寄存器里 |
| addiw | addiw rd,rs,imme | 截取rs寄存器的低23位并与imme立即数相加,把结果进行符号扩展并放到rd寄存器里 |
| sub | sub rd,rs1,rs2 | 把rs1寄存器里的值减去rs2寄存器里的值,把结果放到rd寄存器里 |
| subw | subw rd,rs1,rs2 | 把rs1寄存器的低32位减去rs2寄存器的低32位,把结果放到rd寄存器里 |
这个看起来比较简单,实践起来也不复杂。
add.c
#include <stdio.h>
int main(void)
{
long rs1 = 20;
long rs2 = 30;
long rd = 0;
asm volatile(
"add %0,%1,%2 \n\t"
:"=r"(rd)
:"r"(rs1),"r"(rs2)
);
printf("rd = %d\n",rd);
return 0;
}
sub.c
#include <stdio.h>
int main(void)
{
long rs1 = 20;
long rs2 = 30;
long rd = 0;
asm volatile(
"sub %0,%1,%2 \n\t"
:"=r"(rd)
:"r"(rs1),"r"(rs2)
);
printf("rd = %d\n",rd);
return 0;
}

怎么样,这样的汇编风格写起来,相比x86来说是不是简单太多了。
到目前为止,我们已经学习了load加载指令和store存储指令,这些都是真汇编指令,但有的时候,这些指令用起来会不太方便,毕竟不像x86那样一个MOV就能够达到目的。因此,对伪指令的学习也是非常重要的。
程序计数器(Program Counter,PC)是用来指示下一条指令的地址。为了保证CPU能够正确地执行程序的指令代码。就会使用一套PC寄存器来存储这个地址,那么硬件上就只需要把PC指针指向的地址里面的数据当作是代码,然后由指令领取单元IFU把指令送入预译码器并进行预译码。在这里面我们可以看到这个PC寄存器的重要作用,不同指令集给出的PC实现方式也不太一样。比如在x86架构中是使用CS:IP这一对寄存器来指定代码段的位置。而在RISC-V中简化了这一过程,它单纯使用PC寄存器来指定下一条指令的地址。这个PC寄存器,我们不能去读它的位置,但是可以用别的指令去相对PC寄存器进行寻址。
auipc rd,immeauipc指令就是这么一条,通过PC寄存器进行相对寻址的指令。它的英文名是Add upper immediate to PC.
其中有upper,也就是说这里面的imme立即数也是要左移12位的,这里和上面是一样的。因此它只能寻址到与4KB对齐的地址,如果一个地址是在4KB内存块的内部,则auipc寻址不到它。不过我们也有相应的伪指令可以很方便地去寻址。这个auipc指令,我们用到的其实不太多,程序员用到的更多的是基于它的伪指令,当然这些基于它的伪指令展开还是auipc.
| 伪指令 | 指令组合 | 说明 |